Yolov8離譜報錯
YoloV8離譜報錯
今天下午跑資料集,用的是yolov8在恆源雲上租的4070的GPU伺服器,跑垃圾分類資料集( https://blog.csdn.net/m0_54882506/article/details/129880489 ), 結果報錯了,報錯資訊如下:
Traceback (most recent call last):
File "/usr/local/bin/yolo", line 8, in <module>
sys.exit(entrypoint())
File "/usr/local/lib/python3.8/dist-packages/ultralytics/yolo/cfg/__init__.py", line 391, in entrypoint
getattr(model, mode)(**overrides) # default args from model
File "/usr/local/lib/python3.8/dist-packages/ultralytics/yolo/engine/model.py", line 371, in train
self.trainer.train()
File "/usr/local/lib/python3.8/dist-packages/ultralytics/yolo/engine/trainer.py", line 191, in train
self._do_train(world_size)
File "/usr/local/lib/python3.8/dist-packages/ultralytics/yolo/engine/trainer.py", line 362, in _do_train
self.metrics, self.fitness = self.validate()
File "/usr/local/lib/python3.8/dist-packages/ultralytics/yolo/engine/trainer.py", line 462, in validate
metrics = self.validator(self)
File "/usr/local/lib/python3.8/dist-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/ultralytics/yolo/engine/validator.py", line 169, in __call__
self.update_metrics(preds, batch)
File "/usr/local/lib/python3.8/dist-packages/ultralytics/yolo/v8/detect/val.py", line 107, in update_metrics
correct_bboxes = self._process_batch(predn, labelsn)
File "/usr/local/lib/python3.8/dist-packages/ultralytics/yolo/v8/detect/val.py", line 158, in _process_batch
iou = box_iou(labels[:, 1:], detections[:, :4])
File "/usr/local/lib/python3.8/dist-packages/ultralytics/yolo/utils/metrics.py", line 70, in box_iou
inter = (torch.min(a2, b2) - torch.max(a1, b1)).clamp(0).prod(2)
RuntimeError:
自己把伺服器重置,重新配了好幾遍,結果都是執行一個epoch就報錯,如下:
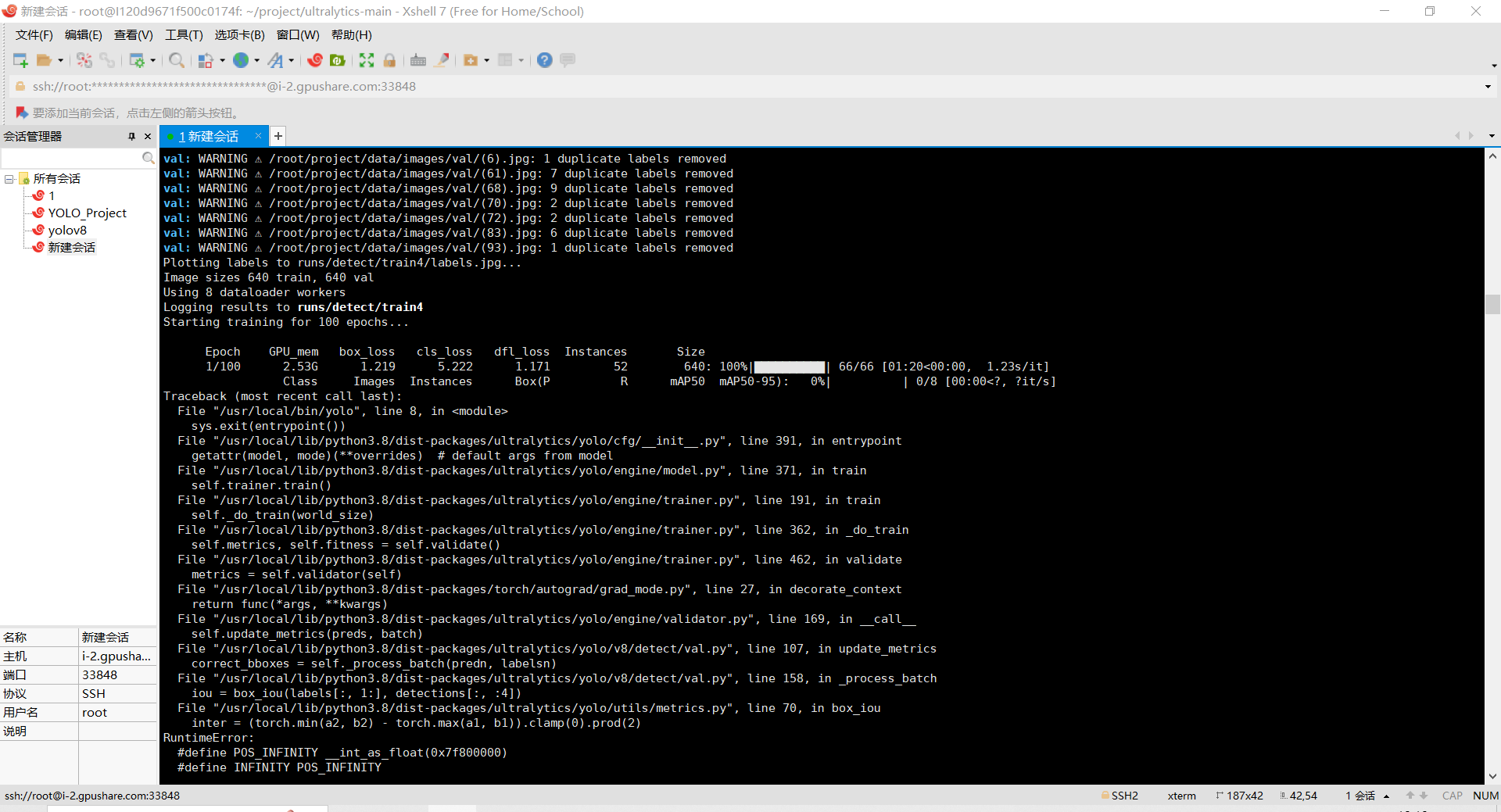
自己翻閱了很多材料,找了很多大神,都沒有正確的解決!
說一下我的解決思路(這裡特別感謝一下yaogle哥,給了我很多建議!!!YYDS):
1.懷疑環境設定有問題,自己在報錯的時候,利用官方給出的測試程式碼:yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'進行測試,結果是成功的,又將伺服器重置,重新設定,測試一邊yoloV8都是測試成功,但是跑一下資料,還是報錯,此時我排除了是環境設定的問題。
2.接下來我懷疑的是資料問題,因為這個資料集,很奇怪(*).jpg嗎,在訓練的時候有警告,我就想是不是資料的問題,我找來我萬能的人臉口罩資料集(V5 V8之前跑成功過),這個資料集很小,匯入,跑一下,結果還是一個epoch就報錯,此時排除資料的問題。
3.就在我萬念俱灰之時,我想我下午不是跑通了這個資料集的部分資料嗎?我是咋跑通的?我回憶了一下,想到下午自己省錢,租的是0.6毛一小時的3060,而我現在用的是2.5一小時的4070,我就抱著試一試的心態,開了一個3060的伺服器,跑了一下,結果如下:
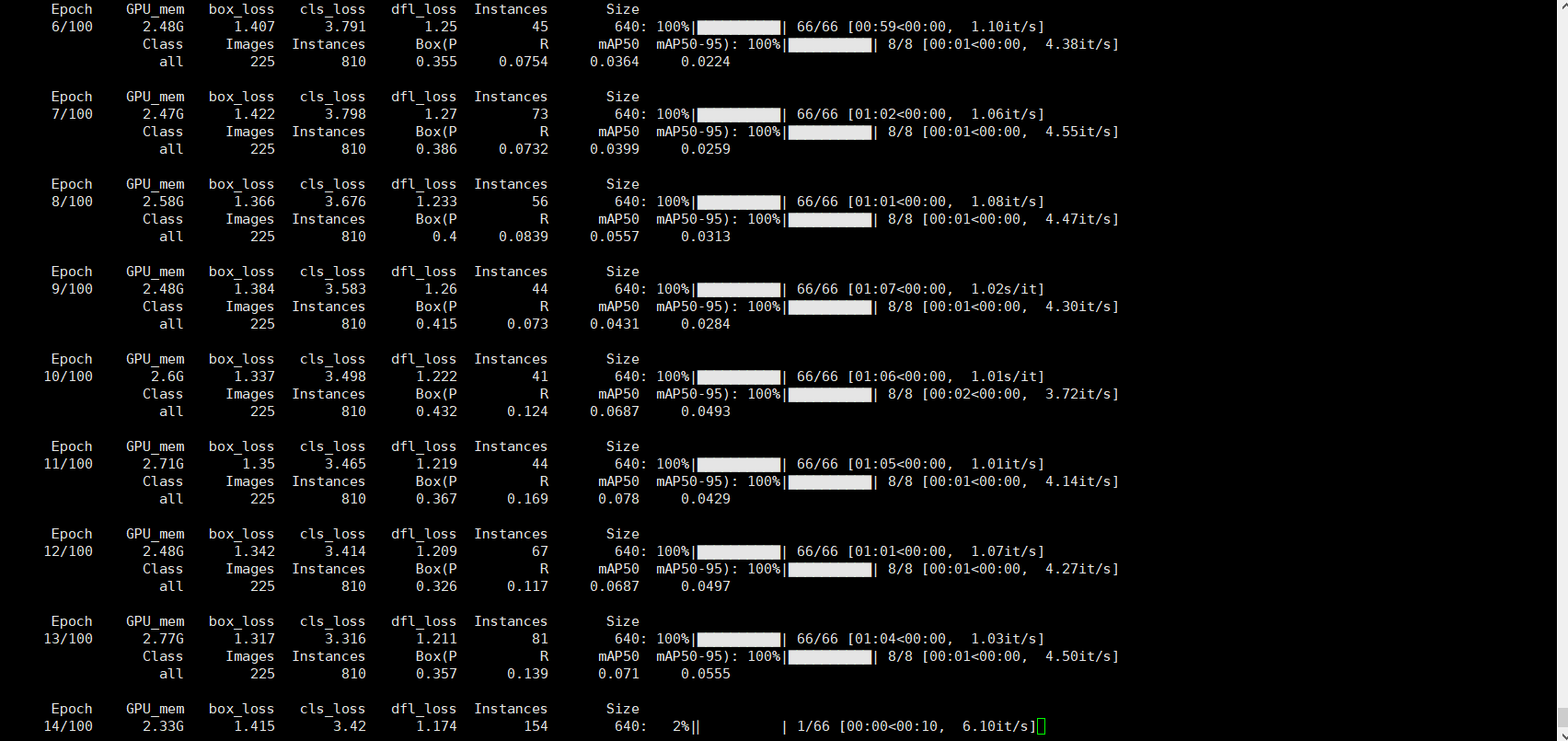
哈哈,沒想到真的跑通了,我又跑了我的萬能資料集,人臉口罩資料集和額外找的資料集測試一下,都跑通了!!!看來越新越貴的東西,未必越好,哈哈哈哈哈~ ~ ~ ~ ~ ~ ~(魔性的笑聲)
我不知道這是不是,這個問題的真正解決,但對我來說確實是目前的最優解,蕪湖起飛(還沒吃完飯,今晚點燒烤)!!!!