Pytorch實現分類器
2023-04-17 18:03:15
本文實現兩個分類器: softmax分類器和感知機分類器
Softmax分類器
Softmax分類是一種常用的多類別分類演演算法,它可以將輸入資料對映到一個概率分佈上。Softmax分類首先將輸入資料通過線性變換得到一個向量,然後將向量中的每個元素進行指數函數運算,最後將指數運算結果歸一化得到一個概率分佈。這個概率分佈可以被解釋為每個類別的概率估計。
定義
定義一個softmax分類器類:
class SoftmaxClassifier(nn.Module):
def __init__(self,input_size,output_size):
# 呼叫父類別的__init__()方法進行初始化
super(SoftmaxClassifier,self).__init__()
# 定義一個nn.Linear物件,用於將輸入特徵對映到輸出類別
self.linear = nn.Linear(input_size,output_size)
def forward(self,x):
x = self.linear(x) # 傳遞給線性層
return nn.functional.softmax(x,dim=1) # 得到概率分佈
def compute_accuracy(self,output,labels):
preds = torch.argmax(output,dim=1) # 獲取每個樣本的預測標籤
correct = torch.sum(preds == labels).item() # 計算正確預測的數量
accuracy = correct / len(labels) # 除以總樣本數得到準確率
return accuracy
如上定義三個方法:
__init__(self):建構函式,在類初始化時執行,呼叫父類別的__init__()方法進行初始化forward(self):模型前向計算過程compute_accuracy(self):計算模型的預測準確率
訓練
生成訓練資料:
import numpy as np
# 生成隨機樣本(包含訓練資料和測試資料)
def generate_rand_samples(dot_num=100):
x_p = np.random.normal(3., 1, dot_num)
y_p = np.random.normal(3., 1, dot_num)
y = np.zeros(dot_num)
C1 = np.array([x_p, y_p, y]).T
x_n = np.random.normal(7., 1, dot_num)
y_n = np.random.normal(7., 1, dot_num)
y = np.ones(dot_num)
C2 = np.array([x_n, y_n, y]).T
x_n = np.random.normal(3., 1, dot_num)
y_n = np.random.normal(7., 1, dot_num)
y = np.ones(dot_num)*2
C3 = np.array([x_n, y_n, y]).T
x_n = np.random.normal(7, 1, dot_num)
y_n = np.random.normal(3, 1, dot_num)
y = np.ones(dot_num)*3
C4 = np.array([x_n, y_n, y]).T
data_set = np.concatenate((C1, C2, C3, C4), axis=0)
np.random.shuffle(data_set)
return data_set[:,:2].astype(np.float32),data_set[:,2].astype(np.int32)
X_train,y_train = generate_rand_samples()
y_train[y_train == -1] = 0
設定訓練前的前置引數,並初始化分類器
num_inputs = 2 # 輸入維度大小
num_outputs = 4 # 輸出維度大小
learning_rate = 0.01 # 學習率
num_epochs = 2000 # 訓練週期數
# 歸一化資料 將資料特徵減去均值再除以標準差
X_train = (X_train - X_train.mean(axis=0)) / X_train.std(axis=0)
y_train = y_train.astype(np.compat.long)
# 建立model並初始化
model = SoftmaxClassifier(num_inputs, num_outputs)
criterion = nn.CrossEntropyLoss() # 交叉熵損失
optimizer = optim.SGD(model.parameters(), lr=learning_rate) # SGD優化器
訓練:
# 遍歷訓練週期數
for epoch in range(num_epochs):
outputs = model(torch.tensor(X_train)) # 前向傳遞計算
loss = criterion(outputs,torch.tensor(y_train)) # 計算預測輸出和真實標籤之間的損失
train_accuracy = model.compute_accuracy(outputs,torch.tensor(y_train)) # 計算模型當前訓練週期中準確率
optimizer.zero_grad() # 清楚優化器中梯度
loss.backward() # 計算損失對模型引數的梯度
optimizer.step()
# 列印資訊
if (epoch + 1) % 10 == 0:
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}, Accuracy: {train_accuracy:.4f}")
執行:
Epoch [1820/2000], Loss: 0.9947, Accuracy: 0.9575
Epoch [1830/2000], Loss: 0.9940, Accuracy: 0.9600
Epoch [1840/2000], Loss: 0.9932, Accuracy: 0.9600
Epoch [1850/2000], Loss: 0.9925, Accuracy: 0.9600
Epoch [1860/2000], Loss: 0.9917, Accuracy: 0.9600
....
測試
生成測試並測試:
X_test, y_test = generate_rand_samples() # 生成測試資料
X_test = (X_test- np.mean(X_test)) / np.std(X_test) # 歸一化
y_test = y_test.astype(np.compat.long)
predicts = model(torch.tensor(X_test)) # 獲取模型輸出
accuracy = model.compute_accuracy(predicts,torch.tensor(y_test)) # 計算準確度
print(f'Test Accuracy: {accuracy:.4f}')
輸出:
Test Accuracy: 0.9725
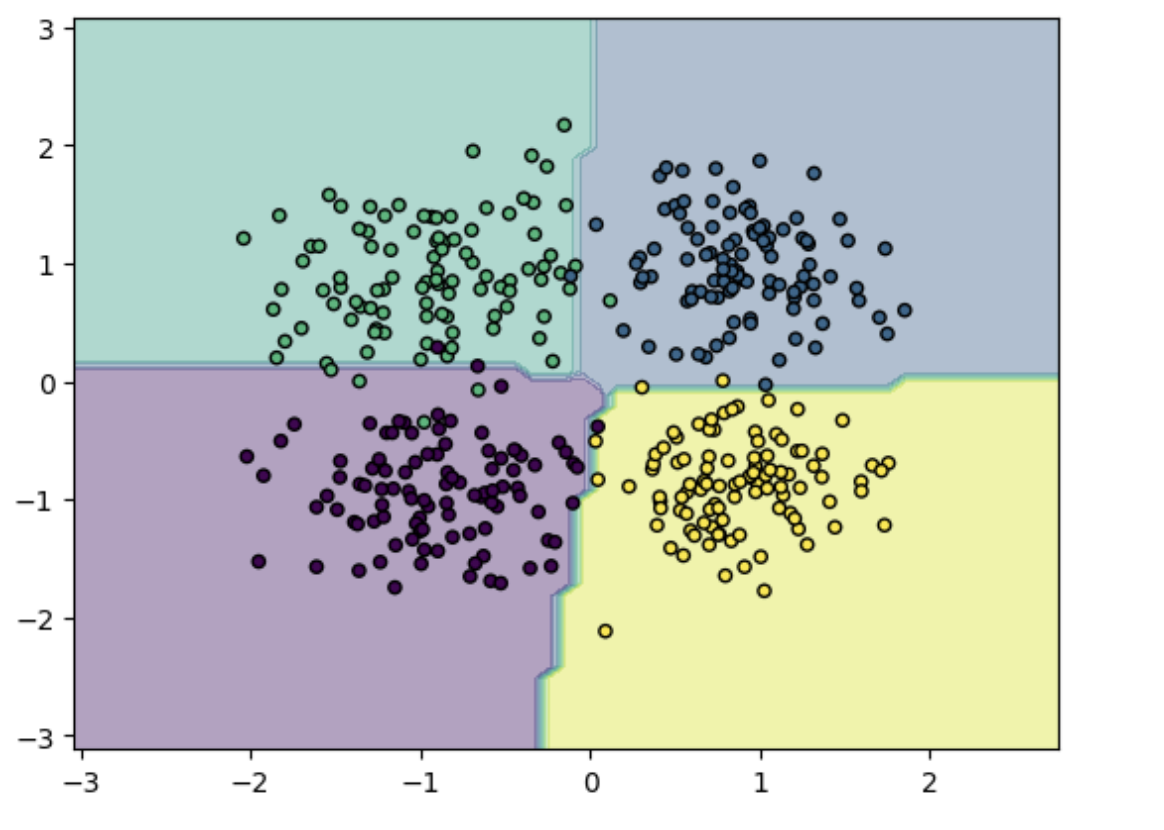
繪製影象:
# 繪製影象
x_min, x_max = X_test[:, 0].min() - 1, X_test[:, 0].max() + 1
y_min, y_max = X_test[:, 1].min() - 1, X_test[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1), np.arange(y_min, y_max, 0.1))
Z = model(torch.tensor(np.c_[xx.ravel(), yy.ravel()], dtype=torch.float32)).argmax(dim=1).numpy()
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.4)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, s=20, edgecolor='k')
plt.show()
感知機分類器
實現與上述softmax分類器相似,此處實現sigmod感知機,採用sigmod作為分類函數,該函數可以將線性變換的結果對映為0到1之間的實數值,通常被用作神經網路中的啟用函數
sigmoid感知機的學習演演算法與普通的感知機類似,也是採用隨機梯度下降(SGD)的方式進行更新。不同之處在於,sigmoid感知機的輸出是一個概率值,需要將其轉化為類別標籤。
通常使用閾值來決定輸出值所屬的類別,如將輸出值大於0.5的樣本歸為正類,小於等於0.5的樣本歸為負類。
定義
# 感知機分類器
class PerceptronClassifier(nn.Module):
def __init__(self, input_size,output_size):
super(PerceptronClassifier, self).__init__()
self.linear = nn.Linear(input_size,output_size)
def forward(self, x):
logits = self.linear(x)
return torch.sigmoid(logits)
def compute_accuracy(self, pred, target):
pred = torch.where(pred >= 0.5, 1, -1)
accuracy = (pred == target).sum().item() / target.size(0)
return accuracy
給定一個輸入向量(x1,x2,x3...xn),輸出為y=σ(w⋅x+b)=1/(e^−(w⋅x+b))
訓練
生成訓練集:
def generate_rand_samples(dot_num=100):
x_p = np.random.normal(3., 1, dot_num)
y_p = np.random.normal(3., 1, dot_num)
y = np.ones(dot_num)
C1 = np.array([x_p, y_p, y]).T
x_n = np.random.normal(6., 1, dot_num)
y_n = np.random.normal(0., 1, dot_num)
y = np.ones(dot_num)*-1
C2 = np.array([x_n, y_n, y]).T
data_set = np.concatenate((C1, C2), axis=0)
np.random.shuffle(data_set)
return data_set[:,:2].astype(np.float32),data_set[:,2].astype(np.int32)
X_train,y_train = generate_rand_samples()
X_test,y_test = generate_rand_samples()
該過程與上述softmax分類器相似:
num_inputs = 2
num_outputs = 1
learning_rate = 0.01
num_epochs = 200
# 歸一化資料 將資料特徵減去均值再除以標準差
X_train = (X_train - X_train.mean(axis=0)) / X_train.std(axis=0)
# 建立model並初始化
model = PerceptronClassifier(num_inputs, num_outputs)
optimizer = optim.SGD(model.parameters(), lr=learning_rate) # SGD優化器
criterion = nn.functional.binary_cross_entropy
訓練:
# 遍歷訓練週期數
for epoch in range(num_epochs):
outputs = model(torch.tensor(X_train))
labels = torch.tensor(y_train).unsqueeze(1)
loss = criterion(outputs,labels.float())
train_accuracy = model.compute_accuracy(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 10 == 0:
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}, Accuracy: {train_accuracy:.4f}")
輸出:
Epoch [80/200], Loss: -0.5429, Accuracy: 0.9550
Epoch [90/200], Loss: -0.6235, Accuracy: 0.9550
Epoch [100/200], Loss: -0.7015, Accuracy: 0.9500
Epoch [110/200], Loss: -0.7773, Accuracy: 0.9400
....
測試
X_test, y_test = generate_rand_samples() # 生成測試集
X_test = (X_test - X_test.mean(axis=0)) / X_test.std(axis=0)
test_inputs = torch.tensor(X_test)
test_labels = torch.tensor(y_test).unsqueeze(1)
with torch.no_grad():
outputs = model(test_inputs)
accuracy = model.compute_accuracy(outputs, test_labels)
print(f"Test Accuracy: {accuracy:.4f}")
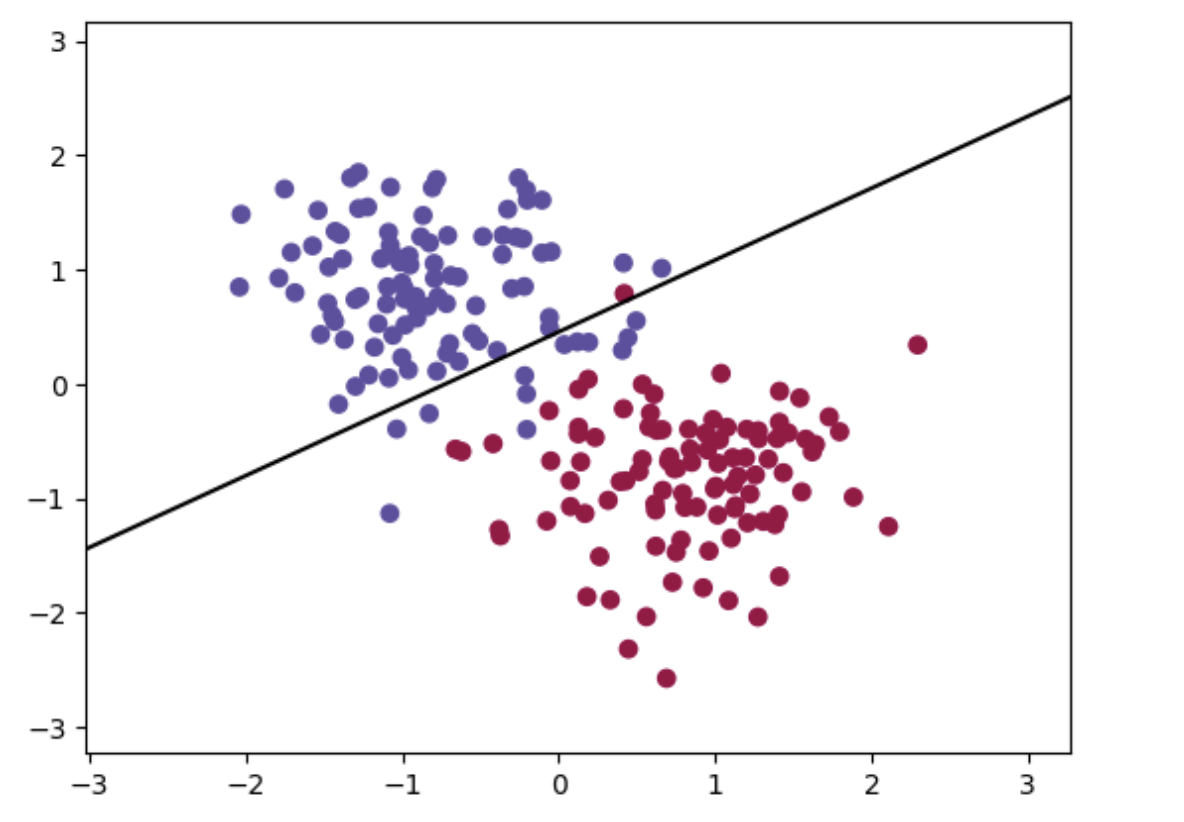
繪圖:
x_min, x_max = X_test[:, 0].min() - 1, X_test[:, 0].max() + 1
y_min, y_max = X_test[:, 1].min() - 1, X_test[:, 1].max() + 1
xx, yy = torch.meshgrid(torch.linspace(x_min, x_max, 100), torch.linspace(y_min, y_max, 100))
# 預測每個點的類別
Z = torch.argmax(model(torch.cat((xx.reshape(-1,1), yy.reshape(-1,1)), 1)), 1)
Z = Z.reshape(xx.shape)
# 繪製分類圖
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral,alpha=0.0)
# 繪製分界線
w = model.linear.weight.detach().numpy() # 權重
b = model.linear.bias.detach().numpy() # 偏置
x1 = np.linspace(x_min, x_max, 100)
x2 = (-b - w[0][0]*x1) / w[0][1]
plt.plot(x1, x2, 'k-')
# 繪製樣本點
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=plt.cm.Spectral)
plt.show()