【機器學習入門與實踐】合集入門必看系列,含資料探勘專案實戰,適合新人入門
【機器學習入門與實踐】合集入門必看系列,含資料探勘專案實戰
專案連結合集(必看)
專案專欄合集https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc 必看
1. 【機器學習入門與實踐】合集入門必看系列
A.機器學習系列入門系列[一]:基於鳶尾花的邏輯迴歸分類預測:
邏輯迴歸(Logistic regression,簡稱LR)雖然其中帶有"迴歸"兩個字,但邏輯迴歸其實是一個分類模型,並且廣泛應用於各個領域之中。雖然現在深度學習相對於這些傳統方法更為火熱,但實則這些傳統方法由於其獨特的優勢依然廣泛應用於各個領域中。
A.機器學習演演算法入門系列(二): 基於鳶尾花資料集的素貝葉斯分類預測
樸素貝葉斯演演算法(Naive Bayes, NB) 是應用最為廣泛的分類演演算法之一。它是基於貝葉斯定義和特徵條件獨立假設的分類器方法。由於樸素貝葉斯法基於貝葉斯公式計算得到,有著堅實的數學基礎,以及穩定的分類效率。NB模型所需估計的引數很少,對缺失資料不太敏感,演演算法也比較簡單。當年的垃圾郵件分類都是基於樸素貝葉斯分類器識別的。
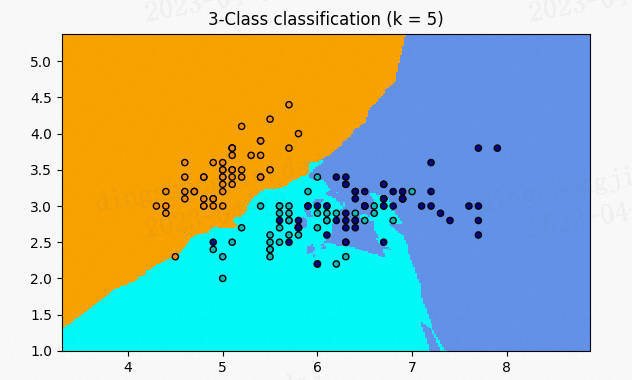
A.機器學習系列入門系列[三]:基於horse-colic的KNN近鄰分類預測:
kNN(k-nearest neighbors),中文翻譯K近鄰。我們常常聽到一個故事:如果要了解一個人的經濟水平,只需要知道他最好的5個朋友的經濟能力, 對他的這五個人的經濟水平求平均就是這個人的經濟水平。這句話裡面就包含著kNN的演演算法思想。


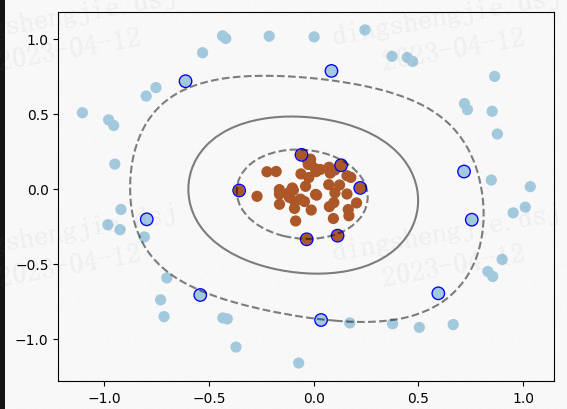
支援向量機(Support Vector Machine,SVM)是一個非常優雅的演演算法,具有非常完善的數學理論,常用於資料分類,也可以用於資料的迴歸預測中,由於其其優美的理論保證和利用核函數對於線性不可分問題的處理技巧

A.機器學習系列入門系列[五]:基於企鵝資料集的決策樹分類預測
決策樹是一種常見的分類模型,在金融風控、醫療輔助診斷等諸多行業具有較為廣泛的應用。決策樹的核心思想是基於樹結構對資料進行劃分,這種思想是人類處理問題時的本能方法。由於決策樹模型中自變數與因變數的非線性關係以及決策樹簡單的計算方法,使得它成為整合學習中最為廣泛使用的基模型。梯度提升樹(GBDT),XGBoost以及LightGBM等先進的整合模型都採用了決策樹作為基模型,在廣告計算、CTR預估、金融風控等領域大放異彩,成為當今與神經網路相提並論的複雜模型,更是資料探勘比賽中的常客。在新的研究中,南京大學周志華教授提出一種多粒度級聯森林模型,創造了一種全新的基於決策樹的深度整合方法,為我們提供了決策樹發展的另一種可能。
A.機器學習系列入門系列[六]:基於天氣資料集的XGBoost分類預測:
XGBoost是2016年由華盛頓大學陳天奇老師帶領開發的一個可延伸機器學習系統。嚴格意義上講XGBoost並不是一種模型,而是一個可供使用者輕鬆解決分類、迴歸或排序問題的軟體包。它內部實現了梯度提升樹(GBDT)模型,並對模型中的演演算法進行了諸多優化,在取得高精度的同時又保持了極快的速度,在一段時間內成為了國內外資料探勘、機器學習領域中的大規模殺傷性武器。
更重要的是,XGBoost在系統優化和機器學習原理方面都進行了深入的考慮。毫不誇張的講,XGBoost提供的可延伸性,可移植性與準確性推動了機器學習計算限制的上限,該系統在單臺機器上執行速度比當時流行解決方案快十倍以上,甚至在分散式系統中可以處理十億級的資料。

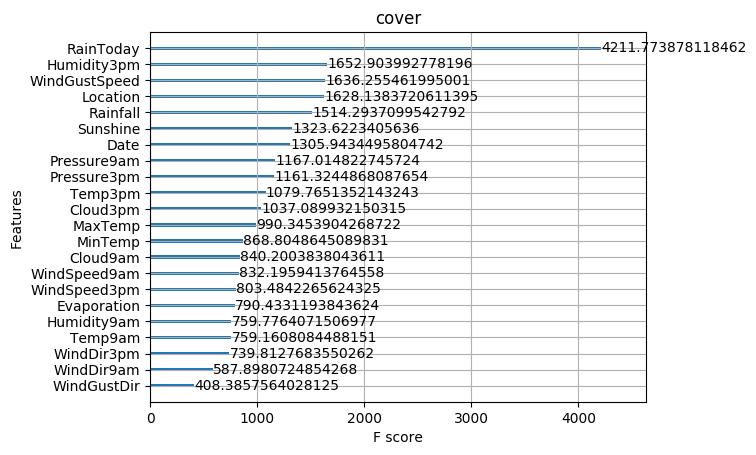

A.機器學習系列入門系列[七]:基於英雄聯盟資料的LightGBM分類預測:
LightGBM是2017年由微軟推出的可延伸機器學習系統,是微軟旗下DMKT的一個開源專案,它是一款基於GBDT(梯度提升決策樹)演演算法的分散式梯度提升框架,為了滿足縮短模型計算時間的需求,LightGBM的設計思路主要集中在減小資料對記憶體與計算效能的使用,以及減少多機器平行計算時的通訊代價。
LightGBM底層實現了GBDT演演算法,並且新增了一系列的新特性:
- 基於直方圖演演算法進行優化,使資料儲存更加方便、運算更快、魯棒性強、模型更加穩定等。
- 提出了帶深度限制的 Leaf-wise 演演算法,拋棄了大多數GBDT工具使用的按層生長 (level-wise) 的決策樹生長策略,而使用了帶有深度限制的按葉子生長策略,可以降低誤差,得到更好的精度。
- 提出了單邊梯度取樣演演算法,排除大部分小梯度的樣本,僅用剩下的樣本計算資訊增益,它是一種在減少資料量和保證精度上平衡的演演算法。
- 提出了互斥特徵捆綁演演算法,高維度的資料往往是稀疏的,這種稀疏性啟發我們設計一種無失真的方法來減少特徵的維度。通常被捆綁的特徵都是互斥的(即特徵不會同時為非零值,像one-hot),這樣兩個特徵捆綁起來就不會丟失資訊。

A.機器學習系列入門系列[八]:基於BP神經網路的乳腺癌分類預測
BP(Back Propagation)網路是1986年由Rumelhart和McCelland為首的科學家小組提出,是一種按誤差逆傳播演演算法訓練的多層前饋網路,是目前應用最廣泛的神經網路模型之一。BP網路能學習和存貯大量的輸入-輸出模式對映關係,而無需事前揭示描述這種對映關係的數學方程。它的學習規則是使用最速下降法,通過反向傳播來不斷調整網路的權值和閾值,使網路的誤差平方和最小。BP神經網路模型拓撲結構包括輸入層(input)、隱層(hide layer)和輸出層(output layer)。在模擬過程中收集系統所產生的誤差,通過誤差反傳,然後調整權值大小,通過該不斷迭代更新,最後使得模型趨於整體最佳化(這是一個迴圈,我們在訓練神經網路的時候是要不斷的去重複這個過程的)。


A.機器學習系列入門系列[九]:基於線性判別模型的LDA手寫數位分類識別:
線性判別模型(LDA)在圖形識別領域(比如臉部辨識等圖形影象識別領域)中有非常廣泛的應用。LDA是一種監督學習的降維技術,也就是說它的資料集的每個樣本是有類別輸出的。這點和PCA不同。PCA是不考慮樣本類別輸出的無監督降維技術。LDA的思想可以用一句話概括,就是「投影后類內方差最小,類間方差最大」。我們要將資料在低維度上進行投影,投影后希望每一種類別資料的投影點儘可能的接近,而不同類別的資料的類別中心之間的距離儘可能的大。即:將資料投影到維度更低的空間中,使得投影后的點,會形成按類別區分,一簇一簇的情況,相同類別的點,將會在投影后的空間中更接近方法。

2. 資料探勘專案實戰
B.機器學習實戰系列[一]:工業蒸汽量預測(最新版本上篇)含資料探索特徵工程等:
B.機器學習實戰系列[一]:工業蒸汽量預測(最新版本下篇)含特徵優化模型融合等:
-
背景介紹
火力發電的基本原理是:燃料在燃燒時加熱水生成蒸汽,蒸汽壓力推動汽輪機旋轉,然後汽輪機帶動發電機旋轉,產生電能。在這一系列的能量轉化中,影響發電效率的核心是鍋爐的燃燒效率,即燃料燃燒加熱水產生高溫高壓蒸汽。鍋爐的燃燒效率的影響因素很多,包括鍋爐的可調引數,如燃燒給量,一二次風,引風,返料風,給水水量;以及鍋爐的工況,比如鍋爐床溫、床壓,爐膛溫度、壓力,過熱器的溫度等。 -
相關描述
經脫敏後的鍋爐感測器採集的資料(採集頻率是分鐘級別),根據鍋爐的工況,預測產生的蒸汽量。 -
資料說明
資料分成訓練資料(train.txt)和測試資料(test.txt),其中欄位」V0」-「V37」,這38個欄位是作為特徵變數,」target」作為目標變數。選手利用訓練資料訓練出模型,預測測試資料的目標變數,排名結果依據預測結果的MSE(mean square error)。 -
結果評估
預測結果以mean square error作為評判標準。
在工業蒸汽量預測上篇中,主要講解了資料探索性分析:檢視變數間相關性以及找出關鍵變數;資料特徵工程對資料精進:異常值處理、歸一化處理以及特徵降維;在進行歸回模型訓練涉及主流ML模型:決策樹、隨機森林,lightgbm等。下一篇中將著重講解模型驗證、特徵優化、模型融合等。
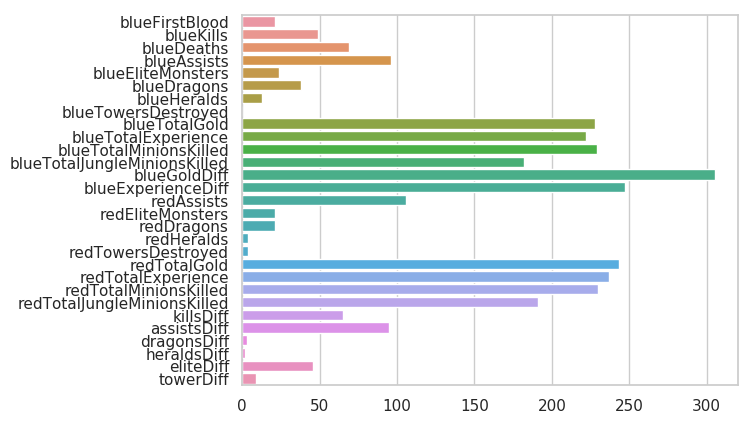
來自 Ebay Kleinanzeigen 報廢的二手車,數量超過 370,000,包含 20 列變數資訊,為了保證 比賽的公平性,將會從中抽取 10 萬條作為訓練集,5 萬條作為測試集 A,5 萬條作為測試集 B。同時會對名稱、車輛型別、變速箱、model、燃油型別、品牌、公里數、價格等資訊進行 脫敏。
3.總結
本人最近打算整合ML、DRL、NLP等相關領域的體系化專案課程,方便入門同學快速掌握相關知識。宣告:部分專案為網路經典專案方便大家快速學習,後續會不斷增添實戰環節(比賽、論文、現實應用等)
上述機器學習專案為最經典的專案,但由於原課程依賴的演演算法庫和運算元替換導致部分程式無法執行,本次貢獻點在於按照自己思路進行專案整合,其次是對bug修復保證案例全部調通,
專案連結合集(必看)
專案專欄合集https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc 必看