記一次 MySQL 主從同步異常的排查記錄,百轉千回
你好,我是悟空。
這是悟空的第 183 篇原創文章
官網:www.passjava.cn
本文主要內容如下:
一、現象
最近專案的測試環境遇到一個主備同步的問題:
備庫的同步執行緒停止了,無法同步主庫的資料更改。
備庫報錯如下:
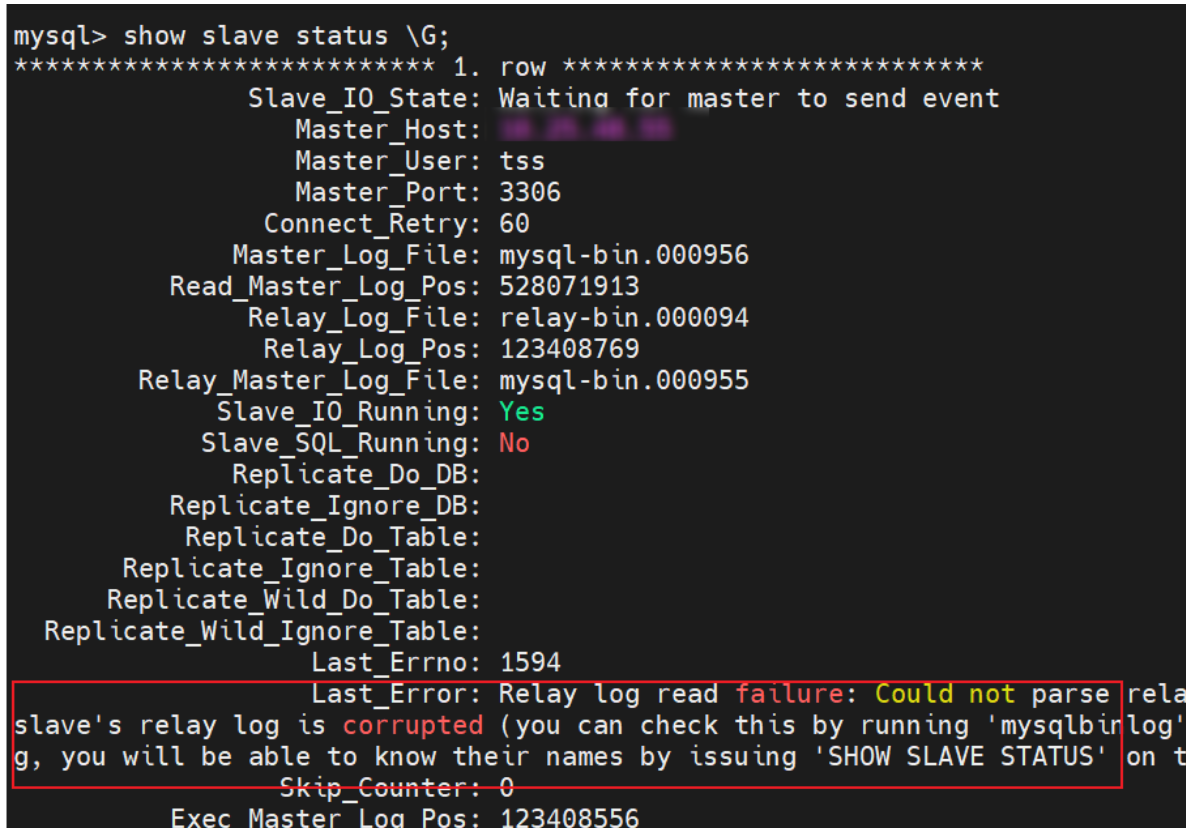 完整的錯誤資訊:
完整的錯誤資訊:
Relay log read failure: Could not parse relay log event entry. The possible reasons are: the master's binary log is corrupted (you can check this by running 'mysqlbinlog' on the binary log), the slave's relay log is corrupted (you can check this by running 'mysqlbinlog' on the relay log), a network problem, or a bug in the master's or slave's MySQL code. If you want to check the master's binary log or slave's relay log, you will be able to know their names by issuing 'SHOW SLAVE STATUS' on this slave.
上面的報錯資訊是什麼意思呢?
翻譯一下就是主庫的 binlog 或者從庫的 relay log 損壞了,造成這個問題的原因:
- 可能是網路問題。
- 也可能是主庫或備庫的程式碼 bug。
首先我們還是得複習下主從同步的原理才能更好地分析原因。
二、主從同步的原理
首先我們還是得複習下主從同步的原理才能更好地分析原因。
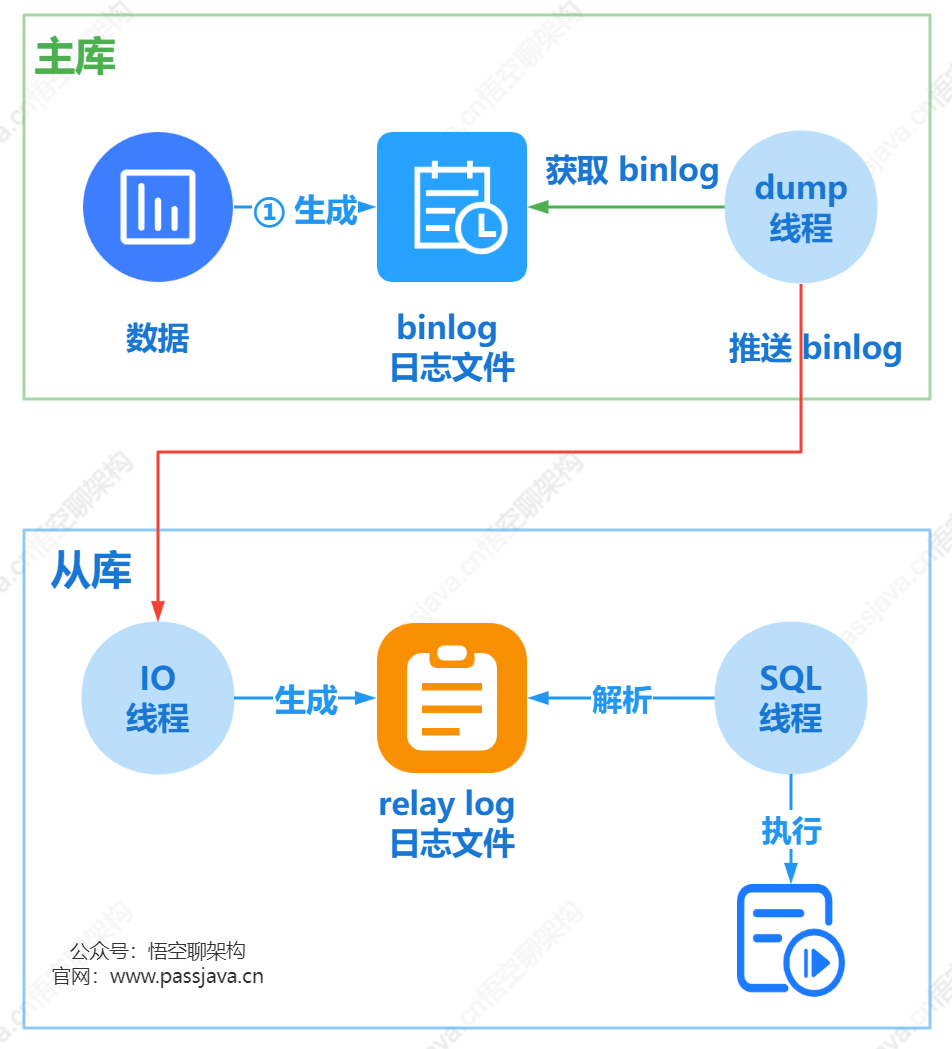
- 從庫會生成兩個執行緒,一個 I/O 執行緒,名字叫做 Slave_IO_Running,另外一個是 SQL 執行緒,名字叫做 Slave_SQL_Running;
- 從庫的 I/O 執行緒會去請求主庫的 binlog 紀錄檔檔案,並將得到的 binlog 紀錄檔檔案寫到原生的 relay-log (中繼紀錄檔)檔案中;
- 主庫會生成一個 dump 執行緒,用來給從庫 I/O 執行緒傳 binlog;
- 從庫 SQL 執行緒,會讀取 relay log 檔案中的紀錄檔,並解析成 SQL 語句逐一執行。
三、排查思路
3.1 分析從庫的同步狀態
我們可以列印下從庫的同步狀態,看到如下幾個關鍵資訊:
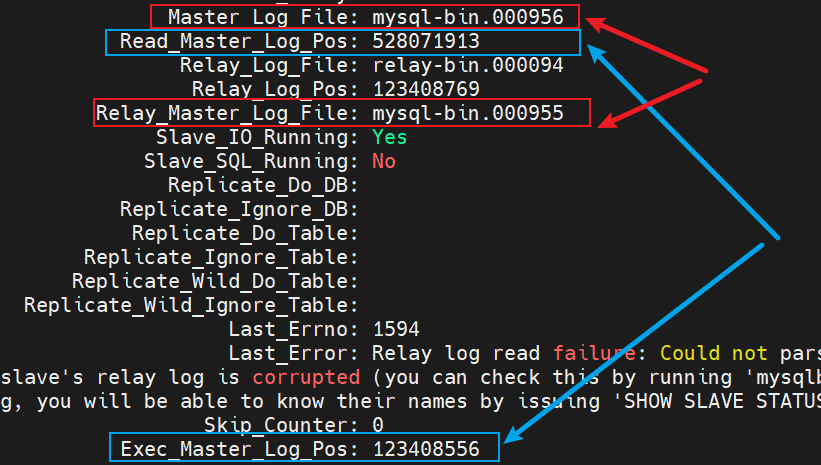
Master_Log_File: mysql-bin.000956,代表從庫讀到的主庫的 binlog file,
Read_Master_Log_Pos: 528071913,代表從庫讀到的主庫的 binlog file 的紀錄檔偏移量
Relay_Log_File: relay-bin.000094,代表從庫執行到了哪一個 relay log
Relay_Log_Pos: 123408769,代表從庫執行的 relay log file 的紀錄檔偏移量
Relay_Master_Log_File: mysql-bin.000955,代表從庫已經重放到了主庫的哪個 binlog file。
Exec_Master_Log_Pos: 123408556,代表從庫已經重放到了主庫 binlog file 的偏移量。
Slave_IO_Running: Yes,說明 I/O 執行緒正在執行,可以正常獲取 binlog 並生成 relay log。
Slave_SQL_Running: No,說明 SQL 執行緒已經停止執行,不能正常解析 relay log,也就不能執行主庫上已經執行的命令。
Master_Log_File 和 Read_Master_Log_Pos 這兩個引數合起來表示的是讀到的主庫的最新位點。
Relay_Master_Log_File 和 Exec_Master_Log_Pos,這兩個引數合起來表示的是從庫執行的最新位點。
如果紅色框起來的兩個引數:Master_Log_File 和 Relay_Master_Log_File 相等,則說明從庫讀到的最新檔案和主庫上生成的檔案相同,這裡前者是 mysql-bin.000956,後者是 mysql-bin.000955,說明兩者不相同,存在主從不同步。
如果藍色框起來的兩個引數 Read_Master_Log_Pos 和 Exec_Master_Log_Pos 相等,則說明從庫讀到的紀錄檔檔案的位置和從庫上執行紀錄檔檔案的位置相同,這裡不相等,說明主從不同步。
當上面兩組引數都相等時,則說明主從同步正常,且沒有延遲。只要有任意一組不相等,則說明主從不同步,可能是從庫停止同步了,或者從庫存在同步延遲。由於上面的 SQL 執行緒已經停止了,說明是從庫同步出現問題了。
從庫同步出現的問題在最開始的報錯資訊裡面已經提到了,可能是網路問題導致,還有可能是 binlog 或 relay log 損壞。
3.2 重啟萬能大法
先通過重啟來恢復從庫的 SQL 執行緒試試看?重啟方式就是兩種:
- 方式一:從庫重新開啟同步。就是執行 stop slave; 和 start slave; 命令。
- 方式二:重啟從庫範例。就是重啟 mysql 範例或 mysql 容器。
這兩種方式試了後,都不能恢復從庫的 SQL 執行緒。
3.3 檢視 binlog
再來看下 binlog 是否有損壞,在主庫上通過這個命令開啟 mysql-bin.000955 檔案。
mysqlbinlog /var/lib/mysql/log/mysql-bin.000955
沒有報錯資訊,如下圖所示:

3.4 檢視 relay log
看到從庫同步的 Relay_Log_File 到 relay-bin.00094 就停止同步了,如下圖所示,可能是這個檔案損壞了。

在從庫上通過 mysqlbinlog 命令開啟這個檔案
mysqlbinlog /var/lib/mysql/log/relay-bin.000094
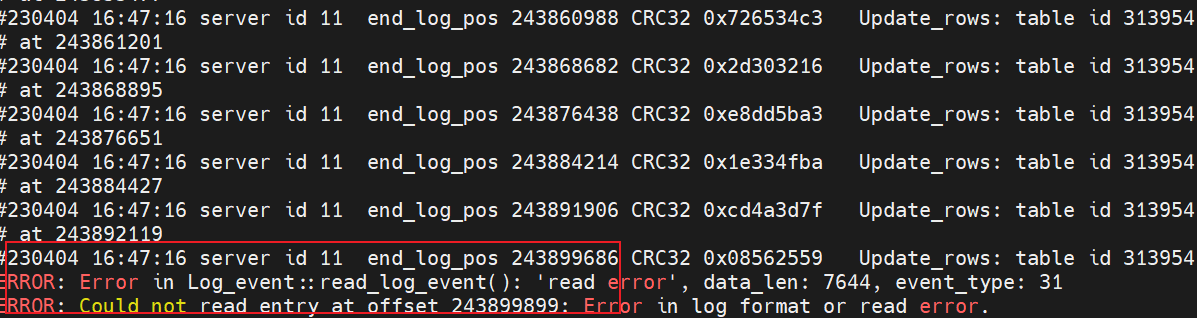
可以看到有個報錯資訊:
ERROR: Error in Log_event::read_log_event(): 'read error', data_len: 7644, event_type: 31
ERROR: Could not read entry at offset 243899899: Error in log format or read error.
這段文字翻譯過來就是讀取錯誤,資料長度 7644,在讀取偏移量為 243899899 的紀錄檔時發生了錯誤,可能是紀錄檔檔案格式錯誤或是讀取檔案錯誤。
3.5 找原因
3.5.1 猜測事務紀錄檔太大
根據這個報錯資訊可以知道這個事務紀錄檔資料太長了,data_len: 7644,而導致讀取錯誤。
而且上面還有很多 Update_rows 的操作。
猜測:會不會是主庫執行了一個大事務,造成該事務生成的一條 binlog 紀錄檔太大了,從庫生成的對應的一條 relay log 紀錄檔也很大, SQL 執行緒去解析這條 relay log 紀錄檔解析報錯。
3.5.2 驗證
到主庫上檢視下 binlog 紀錄檔裡面有沒有在那個時間點做特殊操作。
感覺快找到原因了。執行以下命令來檢視
mysqlbinlog File --stop-datetime=T --start-datetime=T
stop-datetime 指定為讀取 relay log 報錯的時刻 2023-04-04 16:47:16,
start-datetime 指定為讀取 relay log 報錯的時刻 2023-04-04 16:47:30。
發現並沒有找到 Update_rows 的操作。繼續把時間往後加一點,經過多次嘗試,把時間鎖定在了 2023-04-04 17:00:30~17:00:31。這 1s 內能找到 2023-04-04 16:47:16 的操作紀錄檔。
紀錄檔如下,這個命令會列印 N 多紀錄檔,直接把螢幕打滿了!!
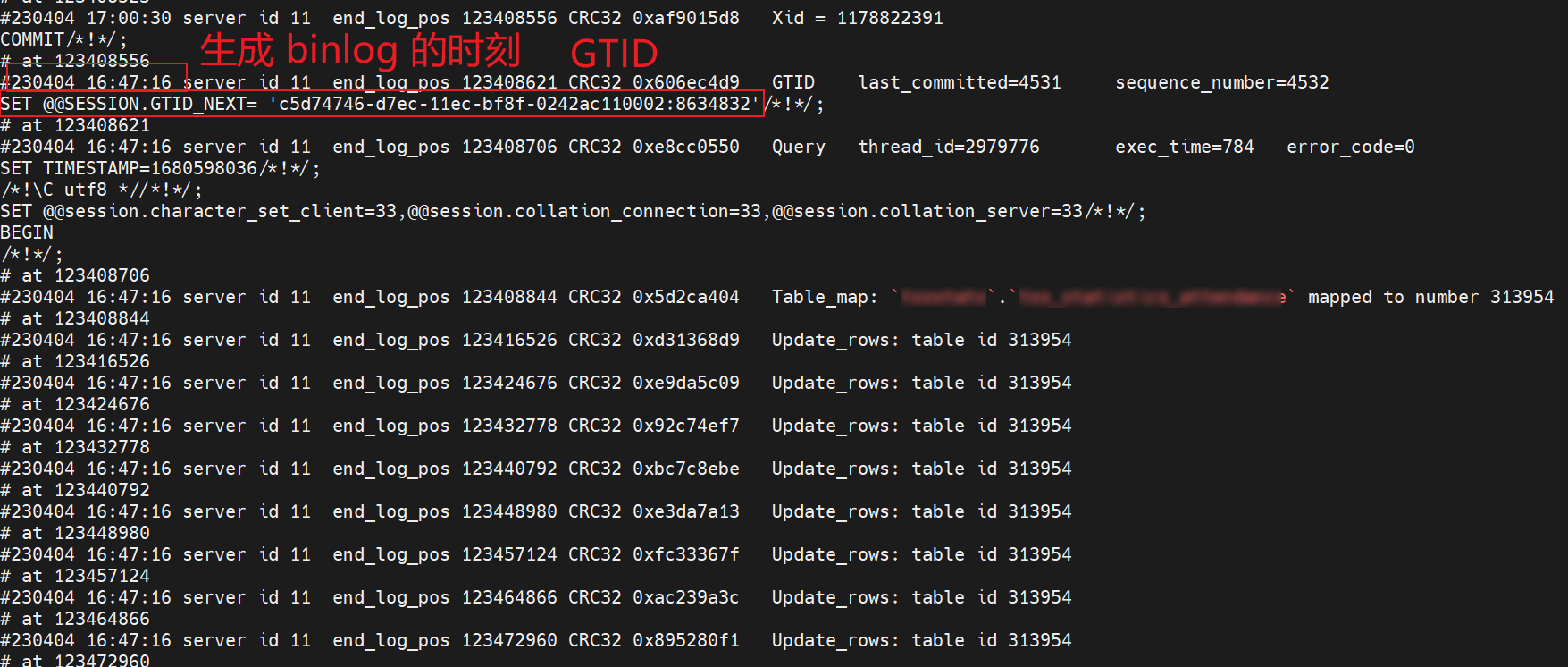 難道真的 binlog 對應的這條事務紀錄檔太大了嗎???
難道真的 binlog 對應的這條事務紀錄檔太大了嗎???
存疑: 2023-04-04 16:47:16 時刻對資料庫中的表做了某個大事務的操作,造成該事務對應的這條 binlog 紀錄檔很大很大。生成的 relay log 也很大,SQL 執行緒解析 relay log 報錯。
3.6 這是真相嗎?
問了下熟悉這張表的同事,有沒有在這個時刻做什麼大事務操作。
同事看了下程式碼,發現有個批次插入的操作,一次執行 400 條,難道是 400 條太多了???這不應該是真正的原因,400 條也不多。
不經意間問了下這張表的資料量有多大,該同事在 4月4號 16:45:25 做了一個手動備份 xx_dance 表的操作,這張表有 25 萬條資料。

這個備份操作是在一個事務裡面執行的,生成的一條 binlog 紀錄檔很大。
這裡只是一個猜測,還未得到驗證,文末會說明真正的原因。
如果真的是這樣,那我可以先恢復從庫的同步,備份表的操作在從庫上其實不需要。
3.7 GTID
不知道細心的你是否有發現上面的 binlog 裡面有一個GTID,
'c5d74746-d7ec-11ec-bf8f-0242ac110002:8634832

記住 GTID 中的數位 8634832,後面恢復從庫同步時要用到。
我們再來看下從庫的狀態,發現也有一個 GTID,如下圖所示,值為 8634831,正好相差 1,感覺這兩個 GTID 值之間有不可告人的祕密。

那麼從庫 SQL 執行緒停止執行的原因就是卡在 8634832 這裡了,我們可否跳過這個 GTID 呢?
你可能對 GTID 的原理很感興趣,可以檢視之前悟空寫的一篇文章:
四、GTID 同步方式的原理
這裡還是把主從同步採用 GTID 方式的流程拿出來看下,幫助大家快速回顧下,熟悉的同學可以跳過本節內容。
GTID 方案:主庫計算主庫 GTID 集合和從庫 GTID 的集合的差集,然後主庫推播差集 binlog 給從庫。
當從庫設定完同步引數後,假定主庫 A 的GTID 集合記為集合 x,從庫 B 的 GTID 集合記為 y。
從庫同步的邏輯如下:

- 從庫 B 指定主庫 A,基於主備協定建立連線。
- 從庫 B 把集合 y 發給主庫 A。
- 主庫 A 計算出集合 x 和集合 y 的差集,也就是集合 x 中存在,集合 y 中不存在的 GTID 集合。比如集合 x 是 1~100,集合 y 是 1~90,那麼這個差集就是 91~100。這裡會判斷集合 x 是不是包含有集合 y 的所有 GTID,如果不是則說明主庫 A 刪除了從庫 B 需要的 binlog,主庫 A 直接返回錯誤。
- 主庫 A 從自己的 binlog 檔案裡面,找到第一個不在集合 y 中的事務 GTID,也就是找到了 91。
- 主庫 A 從 GTID = 91 的事務開始,往後讀 binlog 檔案,按順序取 binlog,然後發給 B。
- 從庫 B 的 I/O 執行緒讀取 binlog 檔案生成 relay log,SQL 執行緒解析 relay log,然後執行 SQL 語句。
GTID 同步方案和位點同步的方案區別是:
- 位點同步方案是通過人工在從庫上指定哪個位點,主庫就發哪個位點,不做紀錄檔的完整性判斷。
- 而 GTID 方案是通過主庫來自動計算位點的,不需要人工去設定位點,對運維人員友好。
五、恢復從庫的同步
5.1 檢視從庫執行 GTID 的進度
在從庫上執行 show slave status \G來檢視 GTID 集合。
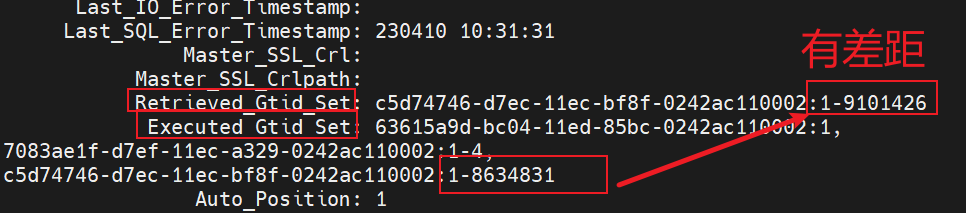
Retrieved_Gtid_Set 表示從庫收到的所有紀錄檔的 GTID 集合。
Executed_Gtid_Set 表示從庫已經執行完成的 GTID 集合。
如果 Executed_Gtid_Set 集合是包含 Retrieved_Gtid_Set,則表示從庫接收到的紀錄檔已經同步完成。
這裡 Executed_Gtid_Set 的集合為 1-8634831,而 Retrieved_Gtid_Set 為 1-9101426,說明從庫有些 GTID 是沒有執行的。從庫已經執行到了 8634831,下一個要執行的 GTID 為 8634832。
因為我們採用的同步方式是 GTID 方式,所以只要讓從庫跳過這個 GTID ,從下一個 GTID 開始同步就行。
帶來的問題就是這個 GTID 對應的事務沒有執行。因為報錯的操作是從庫備份一張大表,所以從庫跳過這個備份操作也是可以接受的。
5.2 手動設定 GTID
來,手動設定一把 GTID 試下。
5.2.1 重置從庫進度
首先重置下從庫同步的進度,這條命令會把 relog 給清理掉,不過重新開啟同步後,主庫會計算主庫 GTID 集合和從庫 GTID 的集合的差集,然後主庫推播差集 binlog 給從庫。
stop slave;
reset slave;
5.2.1 設定 GTID 為一個值
執行以下命令設定 GTID 為下一個值。
set gtid_next='c5d74746-d7ec-11ec-bf8f-0242ac110002:8634832';
begin;
commit;
set gtid_next=automatic;
start slave;
gtid_next 表示設定下一個 GTID = 8634832,這個值是在原來的 8634831 加 1。後面的 begin 和 commit 是提交了一個空事務,把這個 GTID 加到從庫的 GTID 集合中。那麼從庫的 GTID 集合就變成了
'c5d74746-d7ec-11ec-bf8f-0242ac110002:1-8634832';
5.2.2 檢視當前 GTID 集合
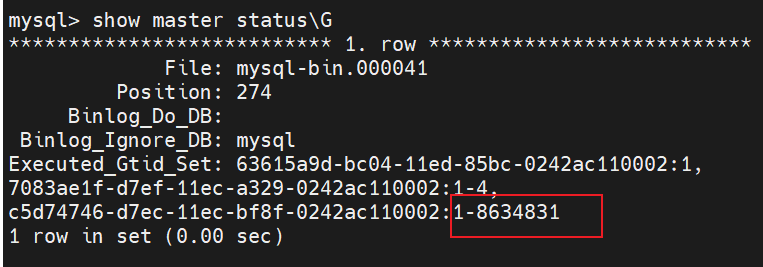
我們可以通過 show master status\G 命令來檢視從庫的 GTID 集合。下方截圖是執行上述命令之前的。GTID集合為 1-8634831。另外 GTID 集合 為 1 和 GTID 集合為 1-4 的可以忽略,因為它們前面的 Master_UUID 不是當前主庫的 uuid。
也可以通過 show slave status\G 命令來檢視 GTID 集合,結果也是一樣的。
5.3 開啟從庫同步
再次啟動從庫的同步(start slave 命令),I/O 執行緒和 SQL 執行緒的狀態都為 YES,說明啟動成功了。
而且檢視從庫的同步狀態時,觀察到從庫的同步是存在延遲的。通過觀察這個欄位 Seconds_Behind_Master 在不斷減小,說明主從同步的延遲越來越小了。
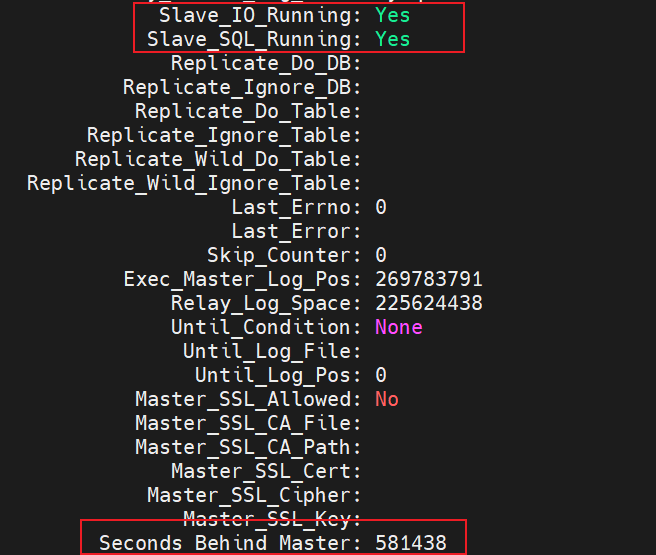

過一段時間後,執行的 GTID 等於收到的 GTID 集合,Seconds_Behind_Master = 0,說明主從完全同步了。
六、原因
上面的推測:* *備份大表造成 binlog 的一條紀錄檔太大,relay log 也跟著變大,SQL 執行緒無法正常解析**。
但這是真相嗎?
雖然從庫重新開啟了同步,且跳過了這條紀錄檔,但帶來的是從庫上就不會出現這個備用表 xx_dance_0404 。
但出現了兩個奇怪的問題:
問題 1:從庫開啟同步後,居然出現了這個備份表 xx_dance_0404。不是跳過這個備份操作了嗎?目前沒想到原因。
問題 2:為了重現這個問題,我到主庫上做了一個備份表的操作,表名為 xx_dance_0412,從庫也同步了這個新的備份表 xx_dance_0412。而且 binlog 出現的紀錄檔現象也是一樣的,對應的這條 binlog 紀錄檔也很大,但是從庫同步正常。我又備份了一張 300 萬的大表,依然沒重現。
通過問題 2 可以說明上面的推測是錯誤的,備份大表並不會影響主從同步。
那麼 relay log 報錯的原因是什麼?
只有一個原因了,relay log 檔案真的是損壞的,從庫的狀態上也說明了原因,relay log is corrupted(損壞)。SQL 執行緒去解析 relay log 時報錯了,導致 SQL 執行緒停止,從庫不能正常執行同步。
小結: relay log 損壞了,導致從庫的 SQL 執行緒解析 relay log 時出現異常。從庫恢復方式是通過手動設定當時出錯的 GTID 的下一個值,讓從庫不從主庫同步這個 GTID,最後從庫就能正常同步這個 GTID 之後的 binlog 了,後續 SQL 執行緒也能正常解析 relay log 了。
如果你對上面的排查思路、結論、恢復方式有其他想法,歡迎拍磚!
- END -