Disruptor-原始碼解讀
前言
Disruptor的高效能,是多種技術結合以及本身架構的結果。本文主要講原始碼,涉及到的相關知識點需要讀者自行去了解,以下列出:
- 鎖和CAS
- 偽共用和快取行
- volatile和記憶體屏障
原理
此節結合demo來看更容易理解:傳送門
下圖來自官方檔案

官方原圖有點亂,我翻譯一下
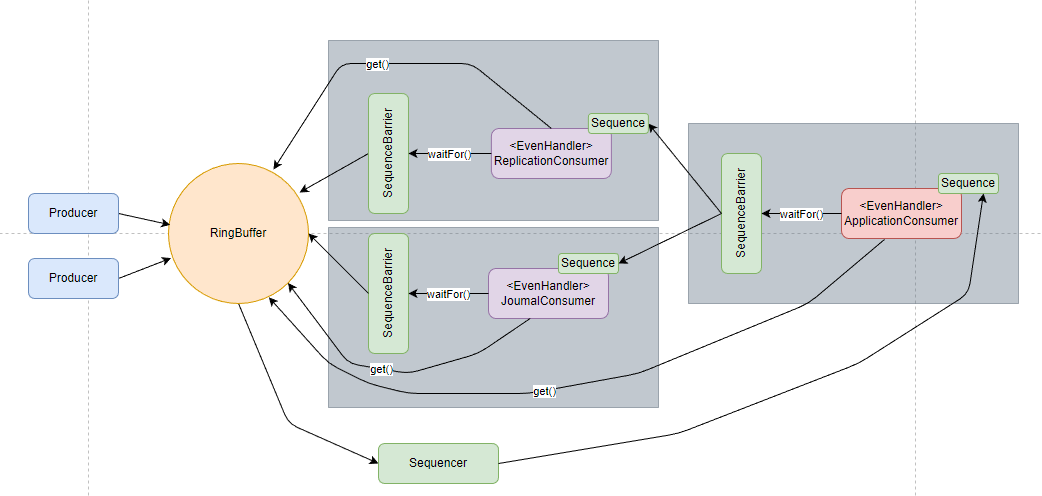
在講原理前,先了解 Disruptor 定義的術語
-
Event
存放資料的單位,對應 demo 中的
LongEvent -
Ring Buffer
環形資料緩衝區:這是一個首尾相接的環,用於存放 Event ,用於生產者往其存入資料和消費者從其拉取資料
-
Sequence
序列:用於跟蹤進度(生產進度、消費進度)
-
Sequencer
Disruptor的核心,用於在生產者和消費者之間傳遞資料,有單生產者和多生產者兩種實現。
-
Sequence Barrier
序列屏障,消費者之間的依賴關係就靠序列屏障實現
-
Wait Strategy
-
等待策略,消費者等待生產者將釋出的策略
-
Event Processor
事件處理器,迴圈從 RingBuffer 獲取 Event 並執行 EventHandler。
-
Event Handler
事件處理程式,也就是消費者
-
Producer
生產者
Ring Buffer
環形資料緩衝區(RingBuffer),邏輯上是首尾相接的環,在程式碼中用陣列來表示Object[]。Disruptor生產者釋出分兩步
- 步驟一:申請寫入 n 個元素,如果可以寫入,這返回最大序列號
- 步驟二:根據序列號去 RingBuffer 中獲取 Event,修改並行布
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
// 獲取下一個可用位置的下標(步驟1)
long sequence = ringBuffer.next();
try {
// 返回可用位置的元素
LongEvent event = ringBuffer.get(sequence);
// 設定該位置元素的值
event.set(l);
} finally {
// 釋出
ringBuffer.publish(sequence);
}
這兩個步驟由 Sequencer 完成,分為單生產者和多生產者實現
Sequencer
單生產者
如果申請 2 個元素,則如下圖所示(圓表示 RingBuffer)
// 一般不會有以下寫法,這裡為了講解原始碼才使用next(2)
// 向RingBuffer申請兩個元素
long sequence = ringBuffer.next(2);
for (long i = sequence-1; i <= sequence; i++) {
try {
// 返回可用位置的元素
LongEvent event = ringBuffer.get(i);
// 設定該位置元素的值
event.set(1);
} finally {
ringBuffer.publish(i);
}
}

next 申請成功的序列,cursor 消費者最大可用序列,gatingSequence 表示能申請的最大序列號。紅色表示待發布,綠色表示已釋出。申請相當於佔位置,釋出需要一個一個按順序釋出
如果 RingBuffer 滿了呢,在上圖步驟二的基礎上,生產者釋出了3個元素,消費者消費1個。此時生產者再申請 2個元素,就會變成下圖所示

只剩下 1 個空間,但是要申請 2個元素,此時程式會自旋等待空間足夠。
接下來結合程式碼看,單生產者的 Sequencer 實現為 SingleProducerSequencer,先看看構造方法
abstract class SingleProducerSequencerPad extends AbstractSequencer
{
protected long p1, p2, p3, p4, p5, p6, p7;
SingleProducerSequencerPad(int bufferSize, WaitStrategy waitStrategy)
{
super(bufferSize, waitStrategy);
}
}
abstract class SingleProducerSequencerFields extends SingleProducerSequencerPad
{
SingleProducerSequencerFields(int bufferSize, WaitStrategy waitStrategy)
{
super(bufferSize, waitStrategy);
}
long nextValue = Sequence.INITIAL_VALUE;
long cachedValue = Sequence.INITIAL_VALUE;
}
public final class SingleProducerSequencer extends SingleProducerSequencerFields
{
protected long p1, p2, p3, p4, p5, p6, p7;
public SingleProducerSequencer(int bufferSize, WaitStrategy waitStrategy)
{
super(bufferSize, waitStrategy);
}
}
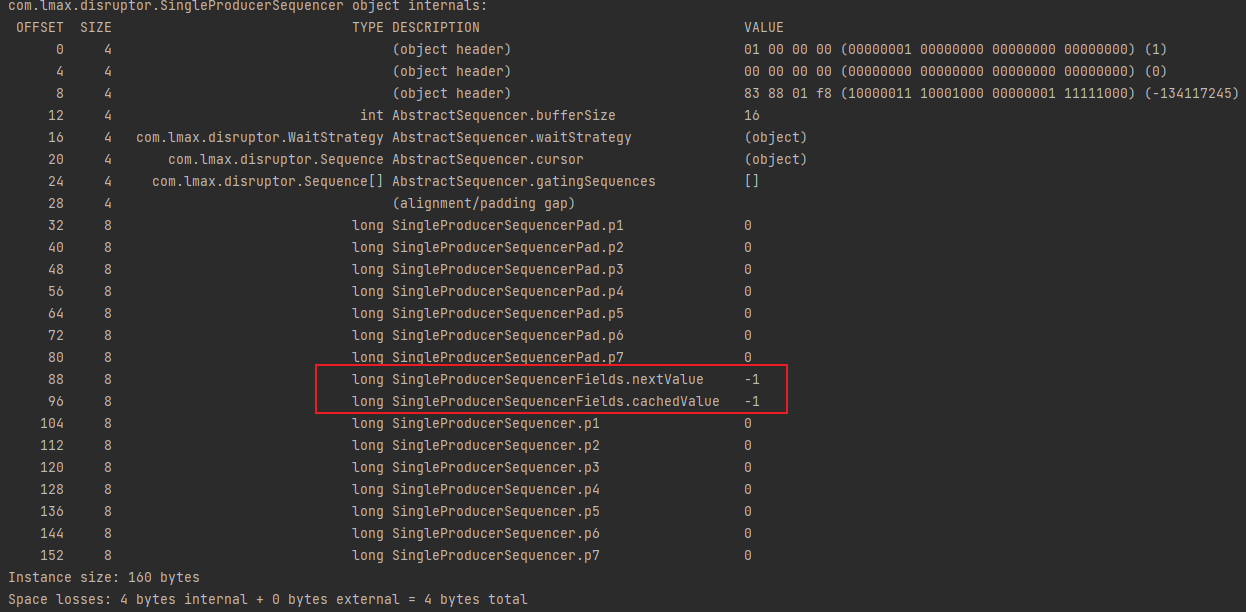
這是 Disruptor 高效能的技巧之一,SingleProducerSequencer 需要的類變數只有 nextValue 和cachedValue,p1 ~ p7 的作用是填充快取行,這能保證 nextValue 和cachedValue 必定在獨立的快取行,我們可以用ClassLayout列印記憶體佈局看看
接下來看如何獲取序列號(也就是步驟一)
// 呼叫路徑
// RingBuffer#next()
// SingleProducerSequencer#next()
public long next(int n)
{
if (n < 1)
{
throw new IllegalArgumentException("n must be > 0");
}
long nextValue = this.nextValue;
//生產者當前序號值+期望獲取的序號數量後達到的序號值
long nextSequence = nextValue + n;
//減掉RingBuffer的總的buffer值,用於判斷是否出現‘覆蓋’
long wrapPoint = nextSequence - bufferSize;
//從後面程式碼分析可得:cachedValue就是快取的消費者中最小序號值,他不是當前最新的‘消費者中最小序號值’,而是上次程式進入到下面的if判定程式碼段時,被賦值的當時的‘消費者中最小序號值’
//這樣做的好處在於:在判定是否出現覆蓋的時候,不用每次都呼叫getMininumSequence計算‘消費者中的最小序號值’,從而節約開銷。只要確保當生產者的節奏大於了快取的cachedGateingSequence一個bufferSize時,從新獲取一下 getMinimumSequence()即可。
long cachedGatingSequence = this.cachedValue;
//(wrapPoint > cachedGatingSequence) : 當生產者已經超過上一次快取的‘消費者中最小序號值’(cachedGatingSequence)一個‘Ring’大小(bufferSize),需要重新獲取cachedGatingSequence,避免當生產者一直在生產,但是消費者不再消費的情況下,出現‘覆蓋’
//(cachedGatingSequence > nextValue) : https://github.com/LMAX-Exchange/disruptor/issues/76
// 這裡判斷就是生產者生產的填滿BingBUffer,需要等待消費者消費
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > nextValue)
{
cursor.setVolatile(nextValue); // StoreLoad fence
//gatingSequences就是消費者佇列末尾的序列,也就是消費者消費到哪裡了
//實際上就是獲得處理的隊尾,如果隊尾是current的話,說明所有的消費者都執行完成任務在等待新的事件了
long minSequence;
while (wrapPoint > (minSequence = Util.getMinimumSequence(gatingSequences, nextValue)))
{
// 等待1納秒
LockSupport.parkNanos(1L); // TODO: Use waitStrategy to spin?
}
this.cachedValue = minSequence;
}
this.nextValue = nextSequence;
return nextSequence;
}
public void publish(long sequence)
{
// 更新序列號
cursor.set(sequence);
// 等待策略的喚醒
waitStrategy.signalAllWhenBlocking();
}
要解釋的都在註釋裡了,gatingSequences 是消費者佇列末尾的序列,對應著就是下圖中的 ApplicationConsumer 的 Sequence

多生產者
看完單生產者版,接下來看多生產者的實現。因為是多生產者,需要考慮並行的情況。
如果有A、B兩個消費者都來申請 2 個元素
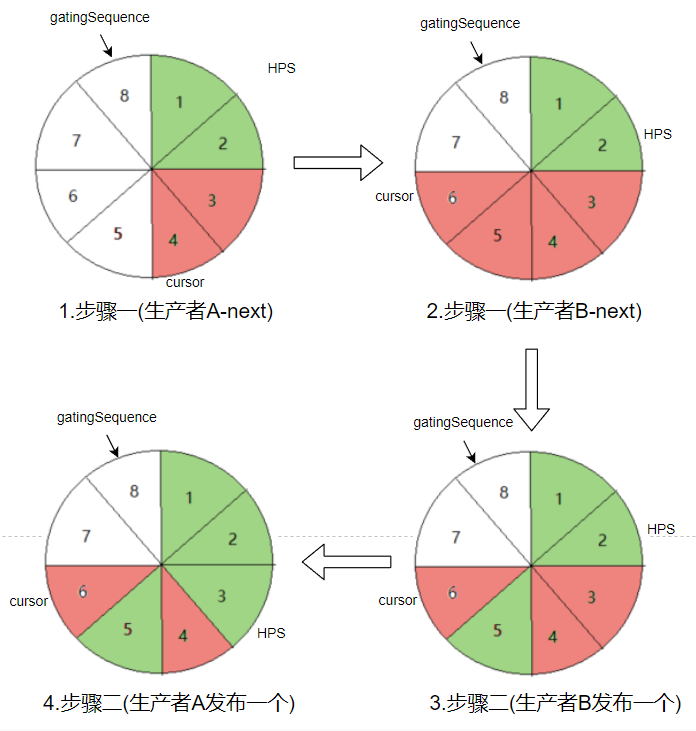
cursor 申請成功的序列,HPS 消費者最大可用序列,gatingSequence 表示能申請的最大序列號。紅色表示待發布,綠色表示已釋出。HPS 是我自己編的縮寫,表示 getHighestPublishedSequence 方法的返回值
如圖所示,只要申請成功,就移動 cursor 的位置。RingBuffer 並沒有記錄釋出情況(圖中的紅綠顏色),這個釋出情況由 MultiProducerSequencer的availableBuffer 來維護。
下面看程式碼
public final class MultiProducerSequencer extends AbstractSequencer
{
// 快取的消費者中最小序號值,相當於SingleProducerSequencerFields的cachedValue
private final Sequence gatingSequenceCache = new Sequence(Sequencer.INITIAL_CURSOR_VALUE);
// 標記元素是否可用
private final int[] availableBuffer;
public long next(int n)
{
if (n < 1)
{
throw new IllegalArgumentException("n must be > 0");
}
long current;
long next;
do
{
current = cursor.get();
next = current + n;
//減掉RingBuffer的總的buffer值,用於判斷是否出現‘覆蓋’
long wrapPoint = next - bufferSize;
//從後面程式碼分析可得:cachedValue就是快取的消費者中最小序號值,他不是當前最新的‘消費者中最小序號值’,而是上次程式進入到下面的if判定程式碼段時,被賦值的當時的‘消費者中最小序號值’
//這樣做的好處在於:在判定是否出現覆蓋的時候,不用每次都呼叫getMininumSequence計算‘消費者中的最小序號值’,從而節約開銷。只要確保當生產者的節奏大於了快取的cachedGateingSequence一個bufferSize時,從新獲取一下 getMinimumSequence()即可。
long cachedGatingSequence = gatingSequenceCache.get();
//(wrapPoint > cachedGatingSequence) : 當生產者已經超過上一次快取的‘消費者中最小序號值’(cachedGatingSequence)一個‘Ring’大小(bufferSize),需要重新獲取cachedGatingSequence,避免當生產者一直在生產,但是消費者不再消費的情況下,出現‘覆蓋’
//(cachedGatingSequence > nextValue) : https://github.com/LMAX-Exchange/disruptor/issues/76
// 這裡判斷就是生產者生產的填滿BingBUffer,需要等待消費者消費
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > current)
{
long gatingSequence = Util.getMinimumSequence(gatingSequences, current);
if (wrapPoint > gatingSequence)
{
LockSupport.parkNanos(1); // TODO, should we spin based on the wait strategy?
continue;
}
gatingSequenceCache.set(gatingSequence);
}
// 使用cas保證只有一個生產者能拿到next
else if (cursor.compareAndSet(current, next))
{
break;
}
}
while (true);
return next;
}
......
}
MultiProducerSequencer和SingleProducerSequencer的 next()方法邏輯大致一樣,只是多了CAS的步驟來保證並行的正確性。接著看釋出方法
public void publish(final long sequence)
{
// 記錄釋出情況
setAvailable(sequence);
// 等待策略的喚醒
waitStrategy.signalAllWhenBlocking();
}
private void setAvailable(final long sequence)
{
// calculateIndex(sequence):獲取序號
// calculateAvailabilityFlag(sequence):RingBuffer的圈數
setAvailableBufferValue(calculateIndex(sequence), calculateAvailabilityFlag(sequence));
}
private void setAvailableBufferValue(int index, int flag)
{
long bufferAddress = (index * SCALE) + BASE;
UNSAFE.putOrderedInt(availableBuffer, bufferAddress, flag);
// 上面相當於 availableBuffer[index] = flag 的高效能版
}
記錄釋出情況,其實相當於 availableBuffer[sequence] = 圈數,前面說了,availableBuffer是用來標記元素是否可用的,如果消費者的圈數 ≠ availableBuffer中的圈數,則表示元素不可用
public boolean isAvailable(long sequence)
{
int index = calculateIndex(sequence);
// 計算圈數
int flag = calculateAvailabilityFlag(sequence);
long bufferAddress = (index * SCALE) + BASE;
// UNSAFE.getIntVolatile(availableBuffer, bufferAddress):相當於availableBuffer[sequence] 的高效能版
return UNSAFE.getIntVolatile(availableBuffer, bufferAddress) == flag;
}
private int calculateAvailabilityFlag(final long sequence)
{
// 相當於 sequence % bufferSize ,但是位元運算更快
return (int) (sequence >>> indexShift);
}
isAvailable() 方法判斷元素是否可用,此方法的呼叫堆疊看完消費者就清楚了。
消費者
本小節介紹兩個方面,一是 Disruptor 的消費者如何實現依賴關係的,二是消費者如何拉取訊息並消費
消費者的依賴關係實現
我們看回這張圖,每個消費者前都有一個 SequenceBarrier ,這就是消費者之間能實現依賴的關鍵。每個消費者都有一個 Sequence,表示自身消費的進度,如圖中,ApplicationConsumer 的 SequenceBarrier 就持有 ReplicaionConsumer 和 JournalConsumer 的 Sequence,這樣就能控制 ApplicationConsumer 的消費進度不超過其依賴的消費者。
下面看原始碼,這是 disruptor 設定消費者的程式碼。
EventHandler journalConsumer = xxx;
EventHandler replicaionConsumer = xxx;
EventHandler applicationConsumer = xxx;
disruptor.handleEventsWith(journalConsumer, replicaionConsumer)
.then(applicationConsumer);
// 下面兩行等同於上面這行
// disruptor.handleEventsWith(journalConsumer, replicaionConsumer);
// disruptor.after(journalConsumer, replicaionConsumer).then(applicationConsumer);
先看ReplicaionConsumer 和 JournalConsumer 的設定 disruptor.handleEventsWith(journalConsumer, replicaionConsumer)
/** 程式碼都在Disruptor類 **/
public final EventHandlerGroup<T> handleEventsWith(final EventHandler<? super T>... handlers)
{
// 沒有依賴的消費者就建立新的Sequence
return createEventProcessors(new Sequence[0], handlers);
}
/**
* 建立消費者
* @param barrierSequences 當前消費者組的屏障序列陣列,如果當前消費者組是第一組,則取一個空的序列陣列;否則,barrierSequences就是上一組消費者組的序列陣列
* @param eventHandlers 事件消費邏輯的EventHandler陣列
*/
EventHandlerGroup<T> createEventProcessors(
final Sequence[] barrierSequences,
final EventHandler<? super T>[] eventHandlers)
{
checkNotStarted();
// 對應此事件處理器組的序列組
final Sequence[] processorSequences = new Sequence[eventHandlers.length];
final SequenceBarrier barrier = ringBuffer.newBarrier(barrierSequences);
for (int i = 0, eventHandlersLength = eventHandlers.length; i < eventHandlersLength; i++)
{
final EventHandler<? super T> eventHandler = eventHandlers[i];
// 建立消費者,注意這裡傳入了SequenceBarrier
final BatchEventProcessor<T> batchEventProcessor =
new BatchEventProcessor<>(ringBuffer, barrier, eventHandler);
if (exceptionHandler != null)
{
batchEventProcessor.setExceptionHandler(exceptionHandler);
}
consumerRepository.add(batchEventProcessor, eventHandler, barrier);
processorSequences[i] = batchEventProcessor.getSequence();
}
// 每次新增完事件處理器後,更新門控序列,以便後續呼叫鏈的新增
// 所謂門控,就是RingBuffer要知道在消費鏈末尾的那組消費者(也是最慢的)的進度,避免訊息未消費就被寫入覆蓋
updateGatingSequencesForNextInChain(barrierSequences, processorSequences);
return new EventHandlerGroup<>(this, consumerRepository, processorSequences);
}
createEventProcessors() 方法主要做了3件事,建立消費者、儲存eventHandler和消費者的對映關係、更新 gatingSequences
- EventProcessor 是消費者
- SequenceBarrier 是消費者屏障,保證了消費者的依賴關係
- consumerRepository 儲存了eventHandler和消費者的對映關係
gatingSequences 我們在前面說過,生產者通過 gatingSequences 知道消費者的進度,防止生產過快導致訊息被覆蓋,更新操作在 updateGatingSequencesForNextInChain() 方法中
// 為消費鏈下一組消費者,更新門控序列
// barrierSequences是上一組事件處理器組的序列(如果本次是第一次,則為空陣列),本組不能超過上組序列值
// processorSequences是本次要設定的事件處理器組的序列
private void updateGatingSequencesForNextInChain(final Sequence[] barrierSequences, final Sequence[] processorSequences)
{
if (processorSequences.length > 0)
{
// 將本組序列新增到Sequencer中的gatingSequences中
ringBuffer.addGatingSequences(processorSequences);
// 將上組消費者的序列從gatingSequences中移除
for (final Sequence barrierSequence : barrierSequences)
{
ringBuffer.removeGatingSequence(barrierSequence);
}
// 取消標記上一組消費者為消費鏈末端
consumerRepository.unMarkEventProcessorsAsEndOfChain(barrierSequences);
}
}
讓我們把視線再回到消費者的設定方法
disruptor.handleEventsWith(journalConsumer, replicaionConsumer)
.then(applicationConsumer);
journalConsumer 和 replicaionConsumer 已經設定了,接下來是 applicationConsumer
/** 程式碼在EventHandlerGroup類 **/
public final EventHandlerGroup<T> then(final EventHandler<? super T>... handlers)
{
return handleEventsWith(handlers);
}
public final EventHandlerGroup<T> handleEventsWith(final EventHandler<? super T>... handlers)
{
return disruptor.createEventProcessors(sequences, handlers);
}
可以看到,設定 applicationConsumer 最終呼叫的也是 createEventProcessors() 方法,區別就在於 createEventProcessors() 方法的第一個引數,這裡的 sequences 就是 journalConsumer 和 replicaionConsumer 這兩個消費者的 Sequence
消費者的消費邏輯
消費者的主要消費邏輯在 EventProcessor#run()方法中,下面以BatchEventProcessor舉例
// BatchEventProcessor#run()
// BatchEventProcessor#processEvents()
private void processEvents()
{
T event = null;
long nextSequence = sequence.get() + 1L;
while (true)
{
try
{
// 獲取最大可用序列
final long availableSequence = sequenceBarrier.waitFor(nextSequence);
...
// 執行消費邏輯
while (nextSequence <= availableSequence)
{
// dataProvider就是RingBuffer
event = dataProvider.get(nextSequence);
eventHandler.onEvent(event, nextSequence, nextSequence == availableSequence);
nextSequence++;
}
sequence.set(availableSequence);
}
catch ()
{
// 例外處理
}
}
}
方法簡潔明瞭,在死迴圈中通過 sequenceBarrier 獲取最大可用序列,然後從 RingBuffer 中獲取 Event 並呼叫 EventHandler 進行消費。重點在 sequenceBarrier.waitFor(nextSequence); 中
public long waitFor(final long sequence)
throws AlertException, InterruptedException, TimeoutException
{
checkAlert();
// 獲取可用的序列,這裡返回的是Sequencer#next方法設定成功的可用下標,不是Sequencer#publish
// cursorSequence:生產者的最大可用序列
// dependentSequence:依賴的消費者的最大可用序列
long availableSequence = waitStrategy.waitFor(sequence, cursorSequence, dependentSequence, this);
if (availableSequence < sequence)
{
return availableSequence;
}
// 獲取最大的已釋出成功的序號(對於釋出是否成功的校驗在此方法中)
return sequencer.getHighestPublishedSequence(sequence, availableSequence);
}
熟悉的 getHighestPublishedSequence() 方法,忘了就回去看看生產者小節。waitStrategy.waitFor() 對應著圖片中的 waitFor() 。
消費者的啟動
前面講了消費者的處理邏輯,但是 BatchEventProcessor#run() 是如何被呼叫的呢,關鍵在於disruptor.start();
// Disruptor#start()
public RingBuffer<T> start()
{
checkOnlyStartedOnce();
for (final ConsumerInfo consumerInfo : consumerRepository)
{
consumerInfo.start(executor);
}
return ringBuffer;
}
class EventProcessorInfo<T> implements ConsumerInfo
{
public void start(final Executor executor)
{
// eventprocessor就是消費者
executor.execute(eventprocessor);
}
}
還記得 consumerRepository嗎,沒有就往上翻翻設定消費者那裡的 disruptor.handleEventsWith() 方法。
所以啟動過程就是
disruptor#start() → ConsumerInfo#start() → Executor#execute() → EventProcessor#run()
課後作業:Disruptor 的消費者使用了多少執行緒?
總結
本文講了 Disruptor 大體邏輯和原始碼,當然其高效能的祕訣不止文中描述的那些。還有不同的等待策略,Sequence 中使用Unsafe而不是JDK中的 Atomic 原子類等等。