bash shell 無法使用 perl 正則
哈嘍大家好,我是鹹魚。今天跟大家分享一個關於正規表示式的案例,希望能夠對你有所幫助
案例現象
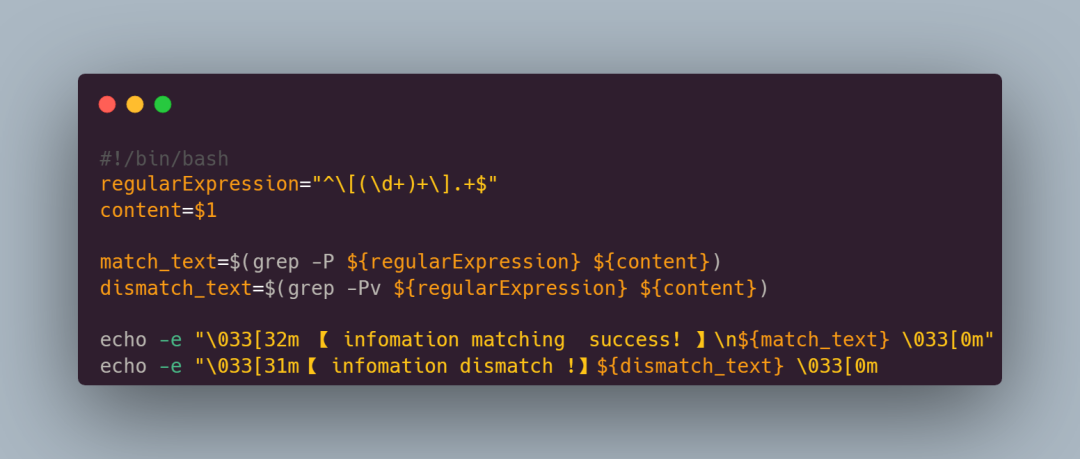
前幾天有一個小夥伴在群裡求助,說他這個 shell 指令碼有問題,讓大家幫忙看看
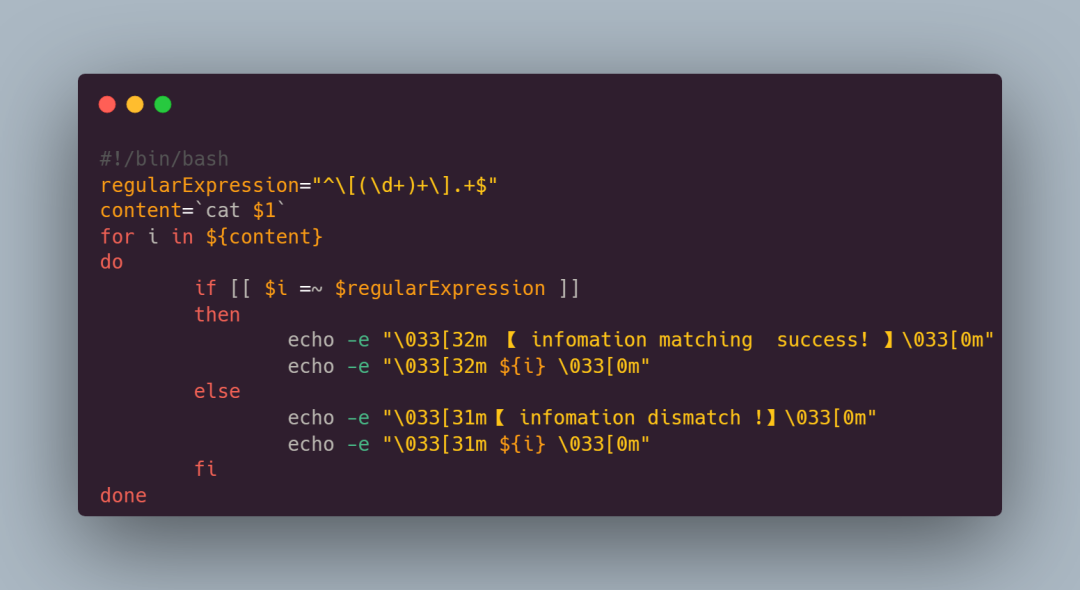
可以看到,這個指令碼首先將目標文字檔案的名字當作該指令碼的第一個引數($1)傳遞進去,然後檢視這個文字檔案的內容(cat $1),並將內容賦值給 firstLine 變數
接著對文字內容的每一行進行遍歷然後正則匹配,並將匹配到的內容綠色高亮輸出出來,不匹配的內容紅色高亮輸出,並顯示提示資訊
其中,正則匹配表示式^\[(\d+)+\].+$ 匹配一組方括號 [ ] ,方括號後還有內容且方括號之間由數位組成:
-
第一部分:
^\[(\d+)+\]-
^\[ 表示以 [ 開頭,\ 為跳脫字元
-
(\d+) +表示匹配多個數位,\ 為跳脫字元
-
\] 表示匹配右方括號,\ 為跳脫字元
-
-
第二部分:
.+$-
.+ 表示匹配任意字元
-
$ 表示結尾
-
因此上面的正規表示式可以匹配:[123] this is a test line 這樣的內容
我們來執行一下這個指令碼,首先看下目標檔案內容

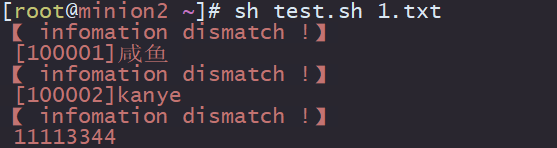
由指令碼的執行結果得知,文字檔案中的內容均沒有匹配到
奇怪,正規表示式寫的沒有問題,為啥指令碼裡面的正則不匹配呢
定位問題
在解決這個問題之前,我們先來了解一下正規表示式(Regular Expression)
什麼是正規表示式
正規表示式是一種通用的文字匹配工具
它允許你使用特定的語法來描述和匹配文字中的模式,可以說是描述文字內容組成規律的表示方式
正規表示式的發展史
正規表示式的起源,可以追溯到早期神經系統如何工作的研究
在 20 世紀 40 年代,有兩位神經生理學家(Warren McCulloch 和 Walter Pitts),研究出了一種用數學方式來描述神經網路的方法
1956 年,一位數學家(Stephen Kleene)發表了一篇標題為《神經網路事件表示法和有窮自動機》的論文。這篇論文描述了一種叫做「正則集合(Regular Sets)」的符號
隨後,大名鼎鼎的 Unix 之父 Ken Thompson 於1968年發表了文章《正規表示式搜尋演演算法》,並且將正則引入了自己開發的編輯器 qed,以及之後的編輯器 ed 中,然後又移植到了大名鼎鼎的文字搜尋工具 grep 中
自此,正規表示式被廣泛應用到 Unix 系統或類 Unix 系統 (如 macOS、Linux) 的各種工具中,但是百家爭鳴的場面使得各種語言和工具中的正則雖然功能大致類似,但仍然有不少細微差別
正規表示式兩種流派之 POSIX 流派
上個世紀八十年代,POSIX (Portable Operating System Interface) 標準公諸於世,它制定了不同的作業系統都需要遵守的一套規則
其中就包括正規表示式的規則,遵循 POSIX 標準的正規表示式,稱為 POSIX 派系正規表示式
POSIX 規範定義了正規表示式的兩種標準
-
基本正規表示式 BRE(Basic Regular Expression)
-
不支援量詞問號和加號,也不支援多選分支結構管道符
-
-
擴充套件正規表示式 ERE(Extended Regular Expression)
-
BRE 在使用花括號,圓括號時要跳脫才能表示特殊含義。由於BRE 功能不夠強大,導致了 ERE 擴充套件標準的誕生
-
像 Unix 系統或類 Unix 系統上的大部分工具,如 grep 、sed 、awk 等都屬於 POSIX 派系
BRE 標準和 ERE 標準
早期 BRE 與 ERE 標準的區別主要在於,BRE 標準不支援量詞問號和加號,也不支援多選分支結構管道符
BRE 標準在使用花括號,圓括號時要跳脫才能表示特殊含義。BRE 標準用起來這麼不爽,於是有了 ERE 標準,在使用花括號,圓括號時不需要跳脫了,還支援了問號、加號和多選分支
我們現在使用的 Linux 發行版,大多都整合了 GNU 套件。GNU 在實現 POSIX 標準時,做了一定的擴充套件,主要有以下三點擴充套件
-
GNU BRE 支援了
+、?,但跳脫了才表示特殊含義,即需要用\+、\?表示 -
GNU BRE 支援管道符多選分支結構,同樣需要跳脫,即用
\|表示 -
GNU ERE 也支援使用反參照,和 BRE 一樣,使用
\1、\2…\9表示

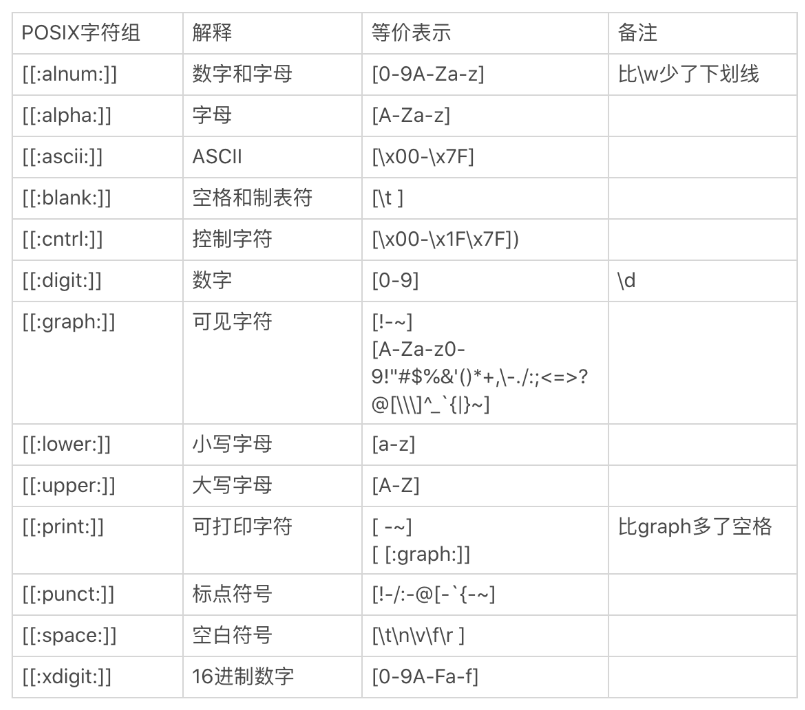
POSIX 字元組
POSIX 流派還有一個特殊的地方,就是有自己的字元組,叫 POSIX 字元組
正規表示式兩種流派之 PCRE 流派
除了 POSIX 標準外,還有一個 Perl 分支,隨著 Perl 語言的發展,Perl 語言中的正規表示式功能越來越強悍,為了把 Perl 語言中正則的功能移植到其他語言中,我們熟知的 PCRE 就誕生了
PCRE 是一個相容 Perl 語言正規表示式的解析引擎,是由 Philip Hazel 開發的,為很多現代語言和工具所普遍使用
除了 Unix 上的工具遵循 POSIX 標準,PCRE 現已成為其他大部分語言和工具隱然遵循的標準
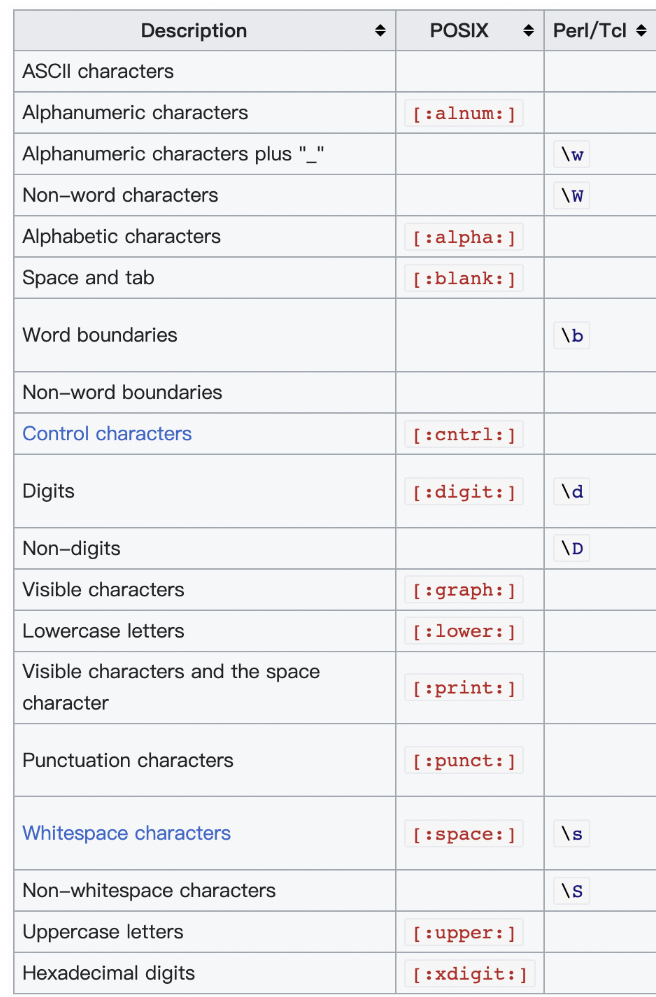
目前大部分常用程式語言都是源於 PCRE 標準,這個流派顯著特徵是有 \d、\w、\s 這類字元組簡記方式
在 UNIX/LINUX 系統裡 PCRE 流派與 POSIX 流派的對比,可以參考下表
在 Linux 中使用正則
在遵循 POSIX 規範的 UNIX/Linux 系統上,按照 BRE 標準 實現的有 grep、sed 和 vi/vim 等
而按照 ERE 標準 實現的有 egrep、awk 等
但是在 Linux 的 bash 中,原生的正規表示式語法是基於 POSIX 標準的(支援 ERE 標準和 BRE 標準),不直接支援 PCRE 標準
指令碼中的正規表示式出現了 \d ,而 \d 是屬於 PCRE 標準,而 Linux Bash (基於 POSIX 標準)不支援 PCRE 標準,所以匹配不到
3.解決問題
知道了 Linux Bash 不支援 PCRE 標準,我們將指令碼中的正規表示式由 PCRE 標準改成 ERE 標準即可
-
改成 ERE 標準

- 修改指令碼:在指令碼裡面使用 grep 進行正則匹配過濾
-
-P 參數列示支援 PCRE 正則
-
-v 參數列示取反操作
看下執行結果

參考連結:
-
https://zq99299.github.io/note-book/regular/03/03.html#正規表示式簡史
-
https://askubuntu.com/questions/1143710/regex-with-d-doesn-t-work-in-if-else-statement-with