極簡cfs公平排程演演算法
2023-04-15 06:01:25
1. 說明
1> linux核心關於task排程這塊是比較複雜的,流程也比較長,要從原始碼一一講清楚很容易看暈
2> 本篇文章主要是講清楚cfs公平排程演演算法如何將task在時鐘中斷驅動下切換排程,所以與此無關的程式碼一律略過
3> 本篇只講最簡單的task排程,略過組排程,組排程在下一篇《極簡組排程-CGroup如何限制cpu》中講解
4> 本篇原始碼來自CentOS7.6的3.10.0-957.el7核心
2. 極簡task排程核心思想
1> linux採用cfs公平排程演演算法,其用vruntime記錄task執行的cpu時長,每次用重新排程時,總是選擇vruntime最小的task進行排程
2> 所有Ready狀態的task會分配到不同cpu的rq佇列上,等待排程執行
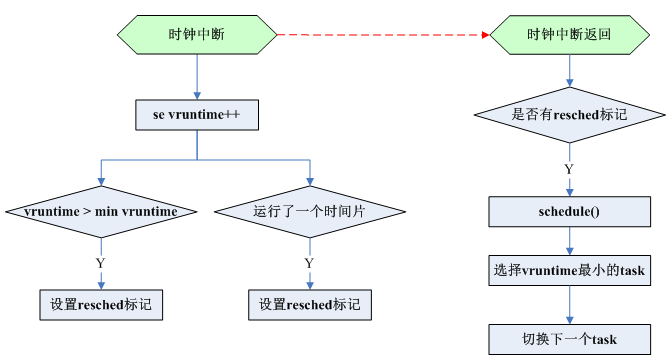
3> 時鐘中斷中,++當前task執行時間vruntime,並檢測當前task執行時間是否超過一個時間片,或者其vruntime比當前cpu rq佇列中最小的vruntime task大一個時間片,則設定resched標記(但並不立馬進行task切換,因為此時仍在中斷上下文中)
4> 所有中斷返回後(當然也包括時鐘中斷),都會jump到ret_from_intr,這裡會檢查resched標記,如果置位,則呼叫schedule()選擇vruntime最小的task進行排程
3. 極簡task排程相關資料結構
3.1 名詞解釋
|
全稱
|
說明
|
|
| se | schedule entity | 排程範例,可以是一個task,也可以是一個group(當使用組排程時),linux支援組排程後,將排程範例從原來的task,抽象為se |
| rq | run queue | cpu的執行佇列,每個cpu一個,處於Ready狀態的se掛在對應的cpu執行佇列上後,才會被選擇投入執行 |
| cfs_rq | cfs rq | 公平排程執行佇列,因為一般程序都是用cfs排程演演算法,一般程序的se都是掛在rq.cfs_rq上的 |
| vruntime | virtual runtime | se的一個重要成員,記錄排程範例的cpu執行時長,schedule時,cfs排程每次都選取vruntime最小的se投入執行,這就是cfs排程演演算法的核心原理 |
3.2 資料結構
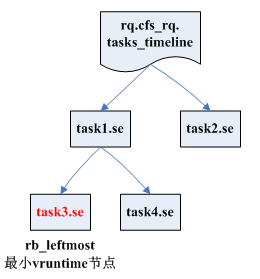
struct sched_entity { unsigned int on_rq; // se是否在rq上,不在的話即使task是Ready狀態也不會投入執行的 u64 vruntime; // cpu執行時長,cfs排程演演算法總是選擇該值最小的se投入執行 }; struct task { struct sched_entity se; // 排程範例 }; struct rq { struct cfs_rq cfs; // 所有要排程的se都掛在cfs rq中 struct task_struct* curr; // 當前cpu上執行的task }; struct cfs_rq { struct rb_root tasks_timeline; // 以vruntime為key,se為value的紅黑樹根節點,schedule時,cfs排程演演算法每次從這裡挑選vruntime最小的se投入執行 struct rb_node* rb_leftmost; // tasks_timeline紅黑樹最左的葉子節點,即vruntime最小的se,直接取這個節點以加快速度 sched_entity* curr; // cfs_rq中當前正在執行的se struct rq* rq; /* cpu runqueue to which this cfs_rq is attached */ unsigned int nr_running; // cfs_rq佇列上有多少個se };
3.3 資料結構關係
2.3 極簡task排程code
2.3.1 時鐘中斷
1> task排程的發動機時鐘中斷觸發後,會在smp_apic_timer_interrupt()中處理,經過層層呼叫,最終會到entity_tick()
entity_tick() { update_curr(); // 如果當前cfs_rq上的se大於1,則檢查是否要重新排程 if (cfs_rq->nr_running > 1) check_preempt_tick(cfs_rq, curr); }
2> update_curr()主要是++當前task se的vruntime(當然這裡還對組排程進行了處理,這裡不講組排程,先略過)
void update_curr(struct cfs_rq* cfs_rq) { struct sched_entity* curr = cfs_rq->curr; curr->vruntime += delta_exec; // 增加se的執行時間 }
3> check_preempt_tick()判定當前執行的時間大於sched_slice時,即超過了時間片,或者其vruntime比當前cpu rq佇列中最小的vruntime task大一個時間片,就會標記resched,然後等中斷返回後會呼叫schedule()進行task切換
void check_preempt_tick() { // 如果執行時間大於sched_slice,則resched if (delta_exec > ideal_runtime) resched_task(rq_of(cfs_rq)->curr); // 如果比最小vruntime大一個sched_slice,則resched se = __pick_first_entity(cfs_rq); // 選擇cfs.rb_leftmost的se,即vruntime最小的se delta = curr->vruntime - se->vruntime; if (delta > ideal_runtime) resched_task(rq_of(cfs_rq)->curr); }
4> resched_curr()非常簡單,就是設定一個resched標記位TIF_NEED_RESCHED
void resched_curr(struct rq* rq) { struct task_struct* curr = rq->curr; set_tsk_thread_flag(curr, TIF_NEED_RESCHED); }
2.3.2 schedule
1> 時鐘中斷返回後,會jump到ret_from_intr(有興趣可以去分析這段組合),如果resched標記被置位,就會呼叫schedule()進行排程
void schedule() { prev = rq->curr; put_prev_task_fair(rq, prev); // 對當前task進行處理,如果該task屬於一個group,還要對組排程進行處理,這裡不展開 // 選擇下一個task並切換執行 next = pick_next_task(rq); // 選擇一個vruntime最小的task進行排程 context_switch(rq, prev, next); }
2> pick_next_task() → pick_next_task_fair() → pick_next_entity() → __pick_first_entity(),__pick_first_entity()選擇vruntime最小的cfs_rq->rb_leftmost節點se進行排程
struct sched_entity *__pick_first_entity(struct cfs_rq *cfs_rq) { struct rb_node *left = cfs_rq->rb_leftmost; return rb_entry(left, struct sched_entity, run_node); }
本文為博主原創文章,如需轉載請說明轉至http://www.cnblogs.com/organic/