品味布隆過濾器的設計之美
布隆過濾器是一個精巧而且經典的資料結構。
你可能沒想到: RocketMQ、 Hbase 、Cassandra 、LevelDB 、RocksDB 這些知名專案中都有布隆過濾器的身影。
對於後端程式設計師來講,學習和理解布隆過濾器有很大的必要性。來吧,我們一起品味布隆過濾器的設計之美。
1 快取穿透
我們先來看一個商品服務查詢詳情的介面:
public Product queryProductById (Long id){
// 查詢快取
Product product = queryFromCache(id);
if(product != null) {
return product ;
}
// 從資料庫查詢
product = queryFromDataBase(id);
if(product != null) {
saveCache(id , product);
}
return product;
}
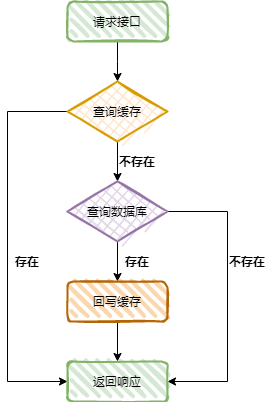
假設此商品既不儲存在快取中,也不存在資料庫中,則沒有辦法回寫快取,當有類似這樣大量的請求存取服務時,資料庫的壓力就會極大。
這是一個典型的快取穿透的場景。
為了解決這個問題呢,通常我們可以向分散式快取中寫入一個過期時間較短的空值佔位,但這樣會佔用較多的儲存空間,價效比不足。
問題的本質是:"如何以極小的代價檢索一個元素是否在一個集合中?"
我們的主角布隆過濾器出場了,它就能遊刃有餘的平衡好時間和空間兩種維度。
2 原理解析
布隆過濾器(英語:Bloom Filter)是1970年由布隆提出的。它實際上是一個很長的二進位制向量和一系列隨機對映函數。
布隆過濾器可以用於檢索一個元素是否在一個集合中。它的優點是空間效率和查詢時間都遠遠超過一般的演演算法,缺點是有一定的誤識別率和刪除困難。
布隆過濾器的原理:當一個元素被加入集合時,通過 K 個雜湊函數將這個元素對映成一個位陣列中的 K 個點,把它們置為 1。檢索時,我們只要看看這些點是不是都是 1 就(大約)知道集合中有沒有它了:如果這些點有任何一個 0,則被檢元素一定不在;如果都是 1,則被檢元素很可能在。
簡單來說就是準備一個長度為 m 的位陣列並初始化所有元素為 0,用 k 個雜湊函數對元素進行 k 次雜湊運算跟 len (m) 取餘得到 k 個位置並將 m 中對應位置設定為 1。

如上圖,位陣列的長度是8,雜湊函數個數是 3,先後保持兩個元素x,y。這兩個元素都經過三次雜湊函數生成三個雜湊值,並對映到位陣列的不同的位置,並置為1。元素 x 對映到位陣列的第0位,第4位,第7位,元素y對映到陣列的位陣列的第1位,第4位,第6位。
儲存元素 x 後,位陣列的第4位元被設定為1之後,在處理元素 y 時第4位元會被覆蓋,同樣也會設定為 1。
當布隆過濾器儲存的元素越多,被置為 1 的 bit 位也會越來越多,元素 x 即便沒有儲存過,假設雜湊函數對映到位陣列的三個位都被其他值設定為 1 了,對於布隆過濾器的機制來講,元素 x 這個值也是存在的,也就是說布隆過濾器存在一定的誤判率。
▍ 誤判率
布隆過濾器包含如下四個屬性:
-
k : 雜湊函數個數
-
m : 位陣列長度
-
n : 插入的元素個數
-
p : 誤判率
若位陣列長度太小則會導致所有 bit 位很快都會被置為 1 ,那麼檢索任意值都會返回」可能存在「 , 起不到過濾的效果。 位陣列長度越大,則誤判率越小。
同時,雜湊函數的個數也需要考量,雜湊函數的個數越大,檢索的速度會越慢,誤判率也越小,反之,則誤判率越高。
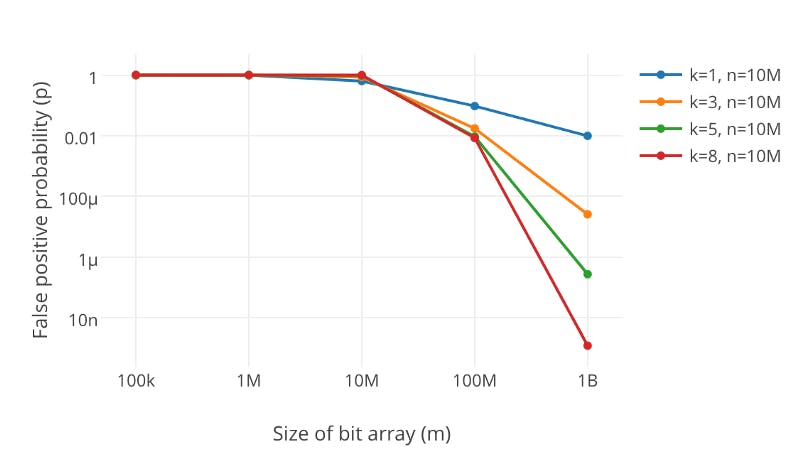
從張圖我們可以觀察到相同位陣列長度的情況下,隨著雜湊函數的個人的增長,誤判率顯著的下降。
誤判率 p 的公式是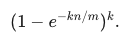
-
k 次雜湊函數某一 bit 位未被置為 1 的概率為

-
插入 n 個元素後某一 bit 位依舊為 0 的概率為
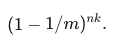
-
那麼插入 n 個元素後某一 bit 位置為1的概率為
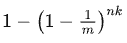
-
整體誤判率為
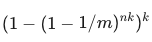 ,當 m 足夠大時,誤判率會越小,該公式約等於
,當 m 足夠大時,誤判率會越小,該公式約等於
我們會預估布隆過濾器的誤判率 p 以及待插入的元素個數 n 分別推匯出最合適的位陣列長度 m 和 雜湊函數個數 k。
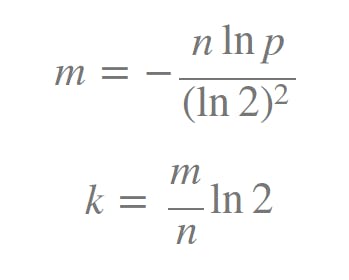
▍ 布隆過濾器支援刪除嗎
布隆過濾器其實並不支援刪除元素,因為多個元素可能雜湊到一個布隆過濾器的同一個位置,如果直接刪除該位置的元素,則會影響其他元素的判斷。
▍ 時間和空間效率
布隆過濾器的空間複雜度為 O(m) ,插入和查詢時間複雜度都是 O(k) 。 儲存空間和插入、查詢時間都不會隨元素增加而增大。 空間、時間效率都很高。
▍雜湊函數型別
Murmur3,FNV 系列和 Jenkins 等非密碼學雜湊函數適合,因為 Murmur3 演演算法簡單,能夠平衡好速度和隨機分佈,很多開源產品經常選用它作為雜湊函數。
3 Guava實現
Google Guava是 Google 開發和維護的開源 Java開發庫,它包含許多基本的工具類,例如字串處理、集合、並行工具、I/O和數學函數等等。
1、新增Maven依賴
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.0.1-jre<</version>
</dependency>
2、建立布隆過濾器
BloomFilter<Integer> filter = BloomFilter.create(
//Funnel 是一個介面,用於將任意型別的物件轉換為位元組流,
//以便用於布隆過濾器的雜湊計算。
Funnels.integerFunnel(),
10000, // 插入資料條目數量
0.001 // 誤判率
);
3、新增資料
@PostConstruct
public void addProduct() {
logger.info("初始化布隆過濾器資料開始");
//插入4個元素
filter.put(1L);
filter.put(2L);
filter.put(3L);
filter.put(4L);
logger.info("初始化布隆過濾器資料結束");
}
4、判斷資料是否存在
public boolean maycontain(Long id) {
return filter.mightContain(id);
}
接下來,我們檢視 Guava 原始碼中布隆過濾器是如何實現的 ?
static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions, double fpp, BloomFilter.Strategy strategy) {
// 省略部分前置驗證程式碼
// 位陣列長度
long numBits = optimalNumOfBits(expectedInsertions, fpp);
// 雜湊函數次數
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
try {
return new BloomFilter<T>(
new LockFreeBitArray(numBits),
numHashFunctions,
funnel,
strategy
);
} catch (IllegalArgumentException e) {
throw new IllegalArgumentException("Could not create BloomFilter of " + numBits + " bits", e);
}
}
//計算位陣列長度
//n:插入的資料條目數量
//p:期望誤判率
@VisibleForTesting
static long optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
// 計算雜湊次數
@VisibleForTesting
static int optimalNumOfHashFunctions(long n, long m) {
// (m / n) * log(2), but avoid truncation due to division!
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
Guava 的計算位陣列長度和雜湊次數和原理解析這一節展示的公式保持一致。
重點來了,Bloom filter 是如何判斷元素存在的 ?
方法名就非常有 google 特色 , 」mightContain「 的中文表意是:」可能存在「 。方法的返回值為 true ,元素可能存在,但若返回值為 false ,元素必定不存在。
public <T extends @Nullable Object> boolean mightContain(
@ParametricNullness T object,
//Funnel 是一個介面,用於將任意型別的物件轉換為位元組流,
//以便用於布隆過濾器的雜湊計算。
Funnel<? super T> funnel,
//用於計算雜湊值的雜湊函數的數量
int numHashFunctions,
//位陣列範例,用於儲存布隆過濾器的位集
LockFreeBitArray bits) {
long bitSize = bits.bitSize();
//使用 MurmurHash3 雜湊函數計算物件 object 的雜湊值,
//並將其轉換為一個 byte 陣列。
byte[] bytes = Hashing.murmur3_128().hashObject(object, funnel).getBytesInternal();
long hash1 = lowerEight(bytes);
long hash2 = upperEight(bytes);
long combinedHash = hash1;
for (int i = 0; i < numHashFunctions; i++) {
// Make the combined hash positive and indexable
// 計算雜湊值的索引,並從位陣列中查詢索引處的位。
// 如果索引處的位為 0,表示物件不在布隆過濾器中,返回 false。
if (!bits.get((combinedHash & Long.MAX_VALUE) % bitSize)) {
return false;
}
// 將 hash2 加到 combinedHash 上,用於計算下一個雜湊值的索引。
combinedHash += hash2;
}
return true;
}
3 Redisson實現
Redisson 是一個用 Java 編寫的 Redis 使用者端,它實現了分散式物件和服務,包括集合、對映、鎖、佇列等。Redisson的API簡單易用,使得在分散式環境下使用Redis 更加容易和高效。
1、新增Maven依賴
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.16.1</version>
</dependency>
2、設定 Redisson 使用者端
@Configuration
public class RedissonConfig {
Bean
public RedissonClient redissonClient() {
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379");
return Redisson.create(config);
}
}
3、初始化
RBloomFilter<Long> bloomFilter = redissonClient.
getBloomFilter("myBloomFilter");
//10000表示插入元素的個數,0.001表示誤判率
bloomFilter.tryInit(10000, 0.001);
//插入4個元素
bloomFilter.add(1L);
bloomFilter.add(2L);
bloomFilter.add(3L);
bloomFilter.add(4L);
4、判斷資料是否存在
public boolean mightcontain(Long id) {
return bloomFilter.contains(id);
}
好,我們來從原始碼分析 Redisson 布隆過濾器是如何實現的 ?
public boolean tryInit(long expectedInsertions, double falseProbability) {
// 位陣列大小
size = optimalNumOfBits(expectedInsertions, falseProbability);
// 雜湊函數次數
hashIterations = optimalNumOfHashFunctions(expectedInsertions, size);
CommandBatchService executorService = new CommandBatchService(commandExecutor);
// 執行 Lua指令碼,生成設定
executorService.evalReadAsync(configName, codec, RedisCommands.EVAL_VOID,
"local size = redis.call('hget', KEYS[1], 'size');" +
"local hashIterations = redis.call('hget', KEYS[1], 'hashIterations');" +
"assert(size == false and hashIterations == false, 'Bloom filter config has been changed')",
Arrays.<Object>asList(configName), size, hashIterations);
executorService.writeAsync(configName, StringCodec.INSTANCE,
new RedisCommand<Void>("HMSET", new VoidReplayConvertor()), configName,
"size", size, "hashIterations", hashIterations,
"expectedInsertions", expectedInsertions, "falseProbability", BigDecimal.valueOf(falseProbability).toPlainString());
try {
executorService.execute();
} catch (RedisException e) {
}
return true;
}

Redisson 布隆過濾器初始化的時候,會建立一個 Hash 資料結構的 key ,儲存布隆過濾器的4個核心屬性。
那麼 Redisson 布隆過濾器如何儲存元素呢 ?
public boolean add(T object) {
long[] hashes = hash(object);
while (true) {
int hashIterations = this.hashIterations;
long size = this.size;
long[] indexes = hash(hashes[0], hashes[1], hashIterations, size);
CommandBatchService executorService = new CommandBatchService(commandExecutor);
addConfigCheck(hashIterations, size, executorService);
//建立 bitset 物件, 然後呼叫setAsync方法,該方法的引數是索引。
RBitSetAsync bs = createBitSet(executorService);
for (int i = 0; i < indexes.length; i++) {
bs.setAsync(indexes[i]);
}
try {
List<Boolean> result = (List<Boolean>) executorService.execute().getResponses();
for (Boolean val : result.subList(1, result.size()-1)) {
if (!val) {
return true;
}
}
return false;
} catch (RedisException e) {
}
}
}
從原始碼中,我們發現 Redisson 布隆過濾器操作的物件是 點陣圖(bitMap) 。
在 Redis 中,點陣圖本質上是 string 資料型別,Redis 中一個字串型別的值最多能儲存 512 MB 的內容,每個字串由多個位元組組成,每個位元組又由 8 個 Bit 位組成。點陣圖結構正是使用「位」來實現儲存的,它通過將位元位設定為 0 或 1來達到資料存取的目的,它儲存上限為 2^32 ,我們可以使用getbit/setbit命令來處理這個位陣列。
為了方便大家理解,我做了一個簡單的測試。

通過 Redisson API 建立 key 為 mybitset 的 點陣圖 ,設定索引 3 ,5,6,8 位為 1 ,右側的二進位制值也完全匹配。
4 實戰要點
通過 Guava 和 Redisson 建立和使用布隆過濾器比較簡單,我們下面討論實戰層面的注意事項。
1、快取穿透場景
首先我們需要初始化布隆過濾器,然後當用戶請求時,判斷過濾器中是否包含該元素,若不包含該元素,則直接返回不存在。
若包含則從快取中查詢資料,若快取中也沒有,則查詢資料庫並回寫到快取裡,最後給前端返回。

2、元素刪除場景
現實場景,元素不僅僅是隻有增加,還存在刪除元素的場景,比如說商品的刪除。
原理解析這一節,我們已經知曉:布隆過濾器其實並不支援刪除元素,因為多個元素可能雜湊到一個布隆過濾器的同一個位置,如果直接刪除該位置的元素,則會影響其他元素的判斷。
我們有兩種方案:
▍計數布隆過濾器
計數過濾器(Counting Bloom Filter)是布隆過濾器的擴充套件,標準 Bloom Filter 位陣列的每一位擴充套件為一個小的計數器(Counter),在插入元素時給對應的 k (k 為雜湊函數個數)個 Counter 的值分別加 1,刪除元素時給對應的 k 個 Counter 的值分別減 1。

雖然計數布隆過濾器可以解決布隆過濾器無法刪除元素的問題,但是又引入了另一個問題:「更多的資源佔用,而且在很多時候會造成極大的空間浪費」。
▍ 定時重新構建布隆過濾器
從工程角度來看,定時重新構建布隆過濾器這個方案可行也可靠,同時也相對簡單。
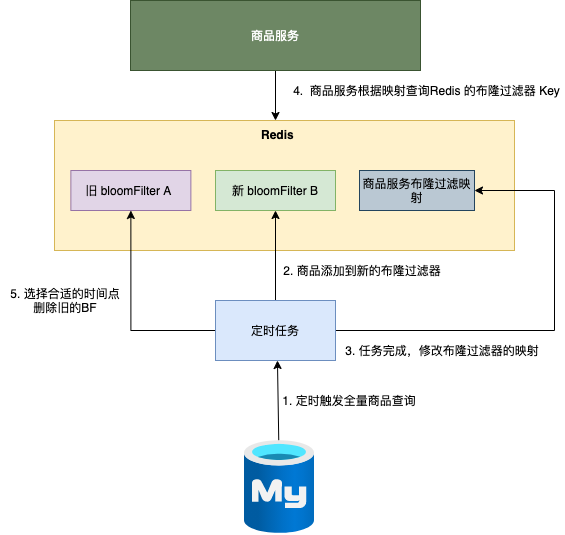
- 定時任務觸發全量商品查詢 ;
- 將商品編號新增到新的布隆過濾器 ;
- 任務完成,修改商品布隆過濾器的對映(從舊 A 修改成 新 B );
- 商品服務根據布隆過濾器的對映,選擇新的布隆過濾器 B進行相關的查詢操作 ;
- 選擇合適的時間點,刪除舊的布隆過濾器 A。
5 總結
布隆過濾器是一個很長的二進位制向量和一系列隨機對映函數,用於檢索一個元素是否在一個集合中。
它的空間效率和查詢時間都遠遠超過一般的演演算法,但是有一定的誤判率 (函數返回 true , 意味著元素可能存在,函數返回 false ,元素必定不存在)。
布隆過濾器的四個核心屬性:
-
k : 雜湊函數個數
-
m : 位陣列長度
-
n : 插入的元素個數
-
p : 誤判率
Java 世界裡 ,通過 Guava 和 Redisson 建立和使用布隆過濾器非常簡單。
布隆過濾器無法刪除元素,但我們可以通過計數布隆過濾器和定時重新構建布隆過濾器兩種方案實現刪除元素的效果。
為什麼這麼多的開源專案中使用布隆過濾器 ?
因為它的設計精巧且簡潔,工程上實現非常容易,效能高,雖然有一定的誤判率,但軟體設計不就是要 trade off 嗎 ?
參考資料:
https://hackernoon.com/probabilistic-data-structures-bloom-filter-5374112a7832
如果我的文章對你有所幫助,還請幫忙點贊、在看、轉發一下,你的支援會激勵我輸出更高質量的文章,非常感謝!
