實時分散式低延遲OLAP資料庫Apache Pinot探索實操
@
概述
定義
Apache Pinot 官網地址 https://pinot.apache.org/ 最新版本0.12.1
Apache Pinot 官網檔案地址 https://docs.pinot.apache.org/
Apache Pinot 原始碼地址 https://github.com/apache/pinot
Apache Pinot是一個實時分散式OLAP資料儲存,專為低延遲高吞吐量分析而構建,非常適合面向使用者的分析的工作。Pinot 攜手 Kafka 和 Presto 提供面向使用者的分析。
Pinot可直接從流資料來源(如Apache Kafka和Amazon Kinesis)中攝取資料,基於實時事件實現即時的查詢。還可以從批次處理資料來源中攝取資料,如Hadoop HDFS、Amazon S3、Azure ADLS和谷歌雲端儲存。核心採用列式儲存,基於智慧索引和預聚合技術實現低延遲;還提供內部儀表板、異常檢測和臨時資料探索。
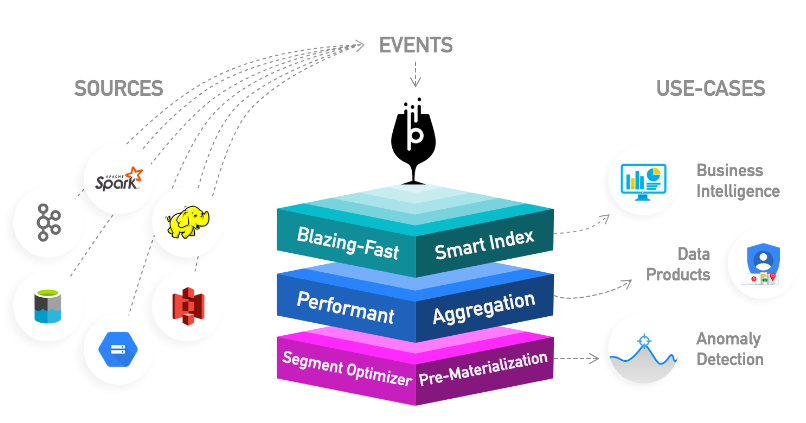
特性
Pinot最初是在LinkedIn上構建的,用於支援豐富的互動式實時分析應用程式,如Who Viewed Profile, Company Analytics, Talent Insights等等。
- 面向列:面向列的儲存技術,並提供各種壓縮方案。
- 可插索引:可插拔的索引技術,支援排序索引、點陣圖索引、倒排索引。
- 查詢優化:能夠基於查詢和段後設資料優化查詢/執行計劃。
- 來自Kafka、Kinesis等流的近實時攝取,以及來自Hadoop、S3、Azure、GCS等源的批次攝取
- 類似sql的語言,支援對資料的選擇、聚合、過濾、分組、排序和不同的查詢。
- 支援多值欄位
- 水平可延伸和容錯
何時使用
Pinot旨在為大型資料集提供低延遲查詢;為了實現這一效能,Pinot以列式格式儲存資料,並新增額外的索引來執行快速過濾、聚合和分組。原始資料被分解成小的資料碎片,每個碎片被轉換成一個稱為段的單位。一個或多個段一起形成一個表,這是使用SQL/PQL查詢Pinot的邏輯容器。Pinot非常適合查詢具有許多維度和指標的時間序列資料。Pinot不是資料庫的替代品,也即是它不能用作真值儲存的來源,不能改變資料。雖然Pinot支援文字搜尋,但它並不能取代搜尋引擎。此外,預設情況下,Pinot查詢不能跨多個表,但可以使用Trino-Pinot聯結器或preto-pinot聯結器來實現表連線和其他功能。主要使用場景如下:
- 面向使用者分析的產品
- 用於業務指標的實時儀表板
- 異常檢測
部署
Local安裝
快速啟動
# 下載Pinot發行版最新版本0.12.1,需要JDK11或以上版本,JDK16除外
PINOT_VERSION=0.12.1
wget https://downloads.apache.org/pinot/apache-pinot-$PINOT_VERSION/apache-pinot-$PINOT_VERSION-bin.tar.gz
# 解壓檔案
tar -zxvf apache-pinot-$PINOT_VERSION-bin.tar.gz
# 導航到包含啟動程式指令碼的目錄:
cd apache-pinot-$PINOT_VERSION-bin
# 有兩種方法啟動:快速啟動或手動設定叢集。
# Pinot附帶快速啟動命令,可以在同一程序中啟動Pinot元件範例,並匯入預構建的資料集。下面的快速啟動命令啟動預裝棒球資料集的Pinot,所有可用的快速入門命令列表請參見快速入門範例。
./bin/pinot-admin.sh QuickStart -type batch
手動設定叢集
# 如果想處理更大的資料集(超過幾兆位元組),可以單獨啟動Pinot各個元件,並將它們擴充套件到多個範例
# 啟動Zookeeper
./bin/pinot-admin.sh StartZookeeper \
-zkPort 2191
# 啟動Pinot Controller
export JAVA_OPTS="-Xms4G -Xmx8G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-controller.log"
./bin/pinot-admin.sh StartController \
-zkAddress localhost:2191 \
-controllerPort 9000
# 啟動Pinot Broker
export JAVA_OPTS="-Xms4G -Xmx4G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-broker.log"
./bin/pinot-admin.sh StartBroker \
-zkAddress localhost:2191
# 啟動Pinot Server
export JAVA_OPTS="-Xms4G -Xmx16G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-server.log"
./bin/pinot-admin.sh StartServer \
-zkAddress localhost:2191
# 啟動Kafka
./bin/pinot-admin.sh StartKafka \
-zkAddress=localhost:2191/kafka \
-port 19092
Docker安裝
快速啟動
# 啟動Apache Zookeeper、Pinot Controller、Pinot Broker和Pinot Server。建立baseballStats表啟動一個獨立的資料攝取作業,為baseballStats表的給定CSV資料檔案構建一個段,並將該段推到Pinot Controller。向Pinot發出範例查詢
docker run \
-p 9000:9000 \
apachepinot/pinot:0.12.1 QuickStart \
-type batch
啟動完後生成範例資料,可以通過查詢控制檯進行SQL編輯查詢,顯示查詢結果並可以匯出EXCEL和CSV格式檔案。
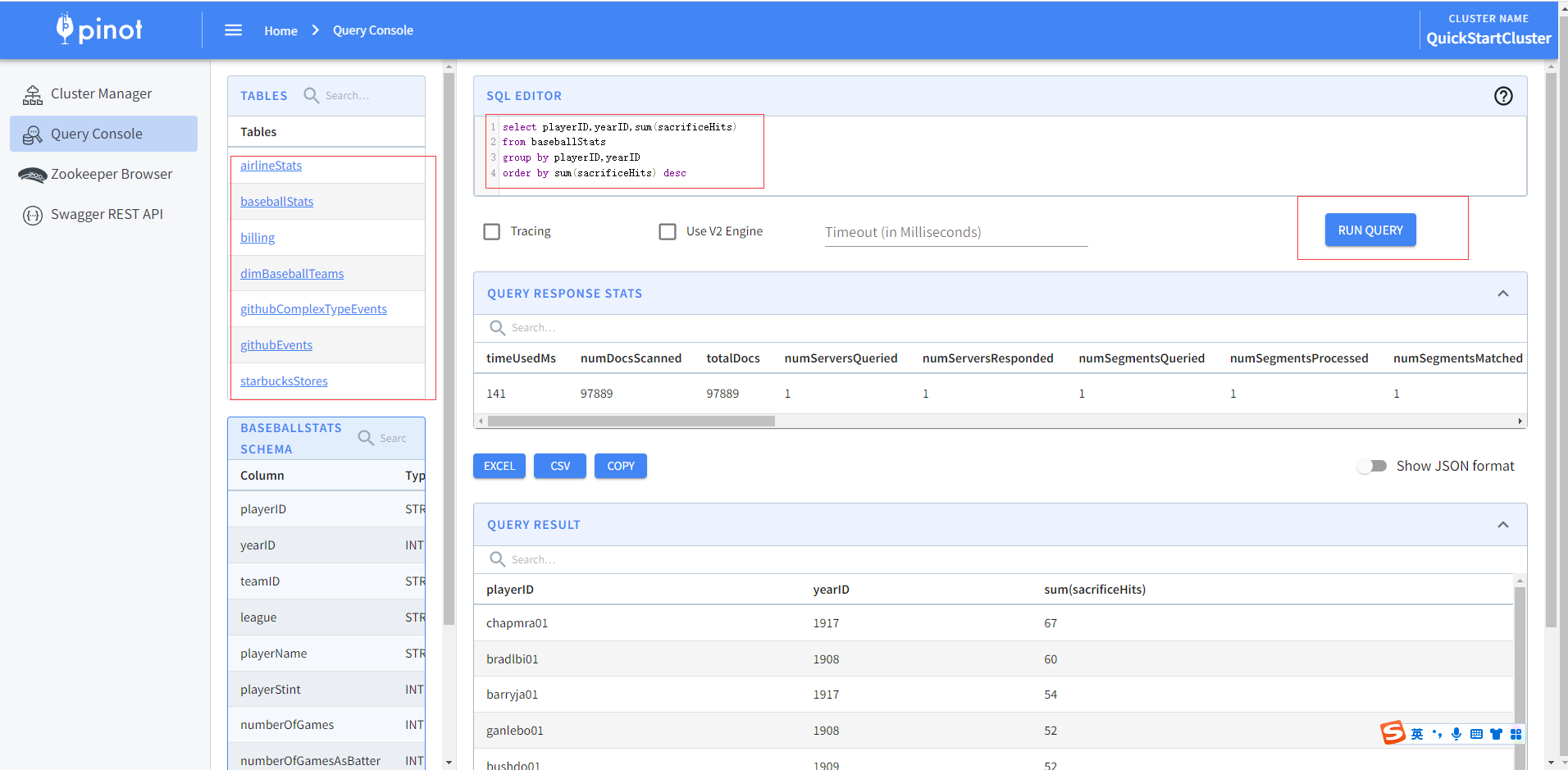
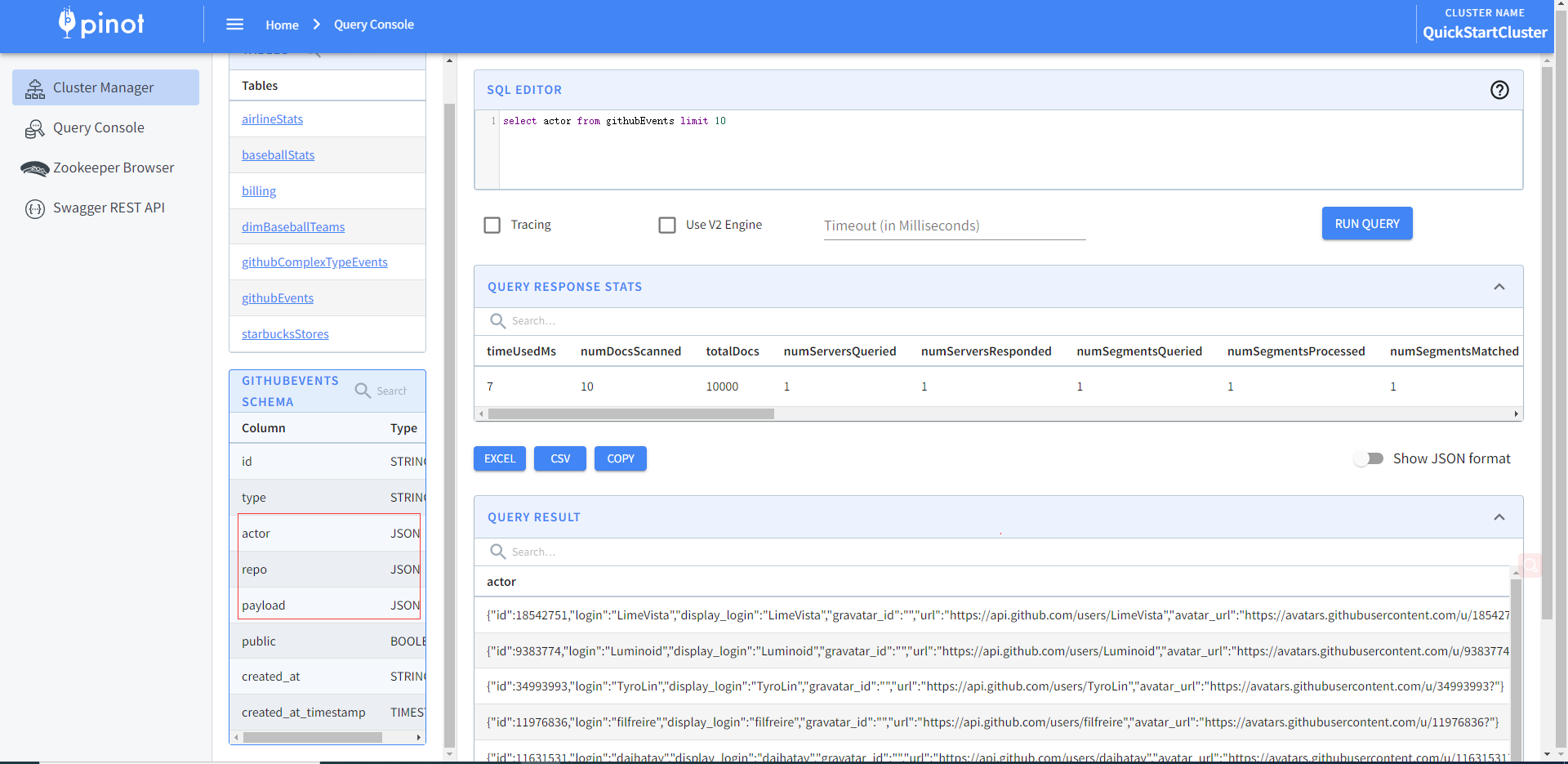
官方還提供多種多種資料型別格式樣例資料,比如JSON
# 啟動Apache Zookeeper、Pinot Controller、Pinot Broker和Pinot Server。建立githubEvents表啟動一個獨立的資料攝取作業,為githubEvents表的給定JSON資料檔案構建一個段,並將該段推到Pinot Controller。向Pinot發出範例查詢
docker run \
-p 9000:9000 \
apachepinot/pinot:0.12.1 QuickStart \
-type batch_json_index
還提供其他流式、Upsert、混合的型別,各位有興趣可以詳細檢視
docker run \
-p 9000:9000 \
apachepinot/pinot:0.12.1 QuickStart \
-type batch_complex_type
docker run \
-p 9000:9000 \
apachepinot/pinot:0.12.1 QuickStart \
-type stream
docker run \
-p 9000:9000 \
apachepinot/pinot:0.12.1 QuickStart \
-type realtime_minion
docker run \
-p 9000:9000 \
apachepinot/pinot:latest QuickStart \
-type stream_complex_type
docker run \
-p 9000:9000 \
apachepinot/pinot:latest QuickStart \
-type upsert
docker run \
-p 9000:9000 \
apachepinot/pinot:latest QuickStart \
-type upsert_json_index
docker run \
-p 9000:9000 \
apachepinot/pinot:latest QuickStart \
-type hybrid
docker run \
-p 9000:9000 \
apachepinot/pinot:latest QuickStart \
-type join
手動啟動叢集
# 建立網路,在docker中建立一個隔離的橋接網路
docker network create -d bridge pinot-demo
# 啟動 Zookeeper,以daemon模式啟動Zookeeper。這是一個單節點zookeeper設定。Zookeeper是Pinot的中央後設資料儲存,應該設定為用於生產的複製。更多資訊請參見執行復制的Zookeeper。
docker run \
--network=pinot-demo \
--name pinot-zookeeper \
--restart always \
-p 2181:2181 \
-d zookeeper:3.5.6
# 啟動 Pinot Controller,在守護行程中啟動Pinot Controller並連線到Zookeeper。下面的命令需要一個4GB的記憶體容器。如果您的機器沒有足夠的資源,那麼就調整- xms和xmx。
docker run --rm -ti \
--network=pinot-demo \
--name pinot-controller \
-p 9000:9000 \
-e JAVA_OPTS="-Dplugins.dir=/opt/pinot/plugins -Xms1G -Xmx4G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-controller.log" \
-d ${PINOT_IMAGE} StartController \
-zkAddress pinot-zookeeper:2181
# 啟動 Pinot Broker,在守護行程中啟動Pinot Broker並連線到Zookeeper。下面的命令需要一個4GB的記憶體容器。如果您的機器沒有足夠的資源,那麼就調整- xms和xmx。
docker run --rm -ti \
--network=pinot-demo \
--name pinot-broker \
-p 8099:8099 \
-e JAVA_OPTS="-Dplugins.dir=/opt/pinot/plugins -Xms4G -Xmx4G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-broker.log" \
-d ${PINOT_IMAGE} StartBroker \
-zkAddress pinot-zookeeper:2181
# 啟動 Pinot Server,在守護行程中啟動Pinot伺服器並連線到Zookeeper。下面的命令需要一個16GB的記憶體容器。如果您的機器沒有足夠的資源,那麼就調整- xms和xmx。
docker run --rm -ti \
--network=pinot-demo \
--name pinot-server \
-p 8098:8098 \
-e JAVA_OPTS="-Dplugins.dir=/opt/pinot/plugins -Xms4G -Xmx16G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-server.log" \
-d ${PINOT_IMAGE} StartServer \
-zkAddress pinot-zookeeper:2181
# 啟動 Kafka,你也可以選擇啟動Kafka來設定實時流。這會在埠9092上開啟Kafka代理。
docker run --rm -ti \
--network pinot-demo --name=kafka \
-e KAFKA_ZOOKEEPER_CONNECT=pinot-zookeeper:2181/kafka \
-e KAFKA_BROKER_ID=0 \
-e KAFKA_ADVERTISED_HOST_NAME=kafka \
-p 9092:9092 \
-d bitnami/kafka:latest
# 檢視執行容器
docker container ls -a
Docker Compose
建立docker-compose.yml檔案內容如下
version: '3.7'
services:
pinot-zookeeper:
image: zookeeper:3.5.6
container_name: pinot-zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
pinot-controller:
image: apachepinot/pinot:0.12.1
command: "StartController -zkAddress pinot-zookeeper:2181"
container_name: pinot-controller
restart: unless-stopped
ports:
- "9000:9000"
environment:
JAVA_OPTS: "-Dplugins.dir=/opt/pinot/plugins -Xms1G -Xmx4G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-controller.log"
depends_on:
- pinot-zookeeper
pinot-broker:
image: apachepinot/pinot:0.12.1
command: "StartBroker -zkAddress pinot-zookeeper:2181"
restart: unless-stopped
container_name: "pinot-broker"
ports:
- "8099:8099"
environment:
JAVA_OPTS: "-Dplugins.dir=/opt/pinot/plugins -Xms4G -Xmx4G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-broker.log"
depends_on:
- pinot-controller
pinot-server:
image: apachepinot/pinot:0.12.1
command: "StartServer -zkAddress pinot-zookeeper:2181"
restart: unless-stopped
container_name: "pinot-server"
ports:
- "8098:8098"
environment:
JAVA_OPTS: "-Dplugins.dir=/opt/pinot/plugins -Xms4G -Xmx16G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-server.log"
depends_on:
- pinot-broker
執行docker-compose命令啟動所有元件
docker-compose --project-name pinot-demo up
存取9000埠管理端點,http://mypinot:9000/
實操
批匯入資料
- 準備資料
# 建立資料目錄mkdir -p /tmp/pinot-quick-start/rawdata# 支援的檔案格式有CSV、JSON、AVRO、PARQUET、THRIFT、ORC。建立一個/tmp/pinot-quick-start/rawdata/transcript.csv檔案,內容如下studentID,firstName,lastName,gender,subject,score,timestampInEpoch200,Lucy,Smith,Female,Maths,3.8,1570863600000200,Lucy,Smith,Female,English,3.5,1571036400000201,Bob,King,Male,Maths,3.2,1571900400000202,Nick,Young,Male,Physics,3.6,1572418800000
- 建立Schema:模式用於定義Pinot表的列和資料型別。模式的詳細概述可以在schema中找到。簡單地說,將列分為3種型別
| 列型別 | 描述 |
|---|---|
| 維度列 | 通常用於過濾器和分組by,用於對資料進行切片和切塊 |
| 度量列 | 通常用於聚合,表示定量資料 |
| 時間 | 可選列,表示與每行關聯的時間戳 |
例如,在上面資料中,studententid、firstName、lastName、gender、subject列是維度列,score列是度量列,timestampInEpoch是時間列。確定了維度、指標和時間列,使用下面的參考為資料建立一個schema,建立/tmp/pinot-quick-start/transcript-schema.json
{ "schemaName": "transcript", "dimensionFieldSpecs": [ { "name": "studentID", "dataType": "INT" }, { "name": "firstName", "dataType": "STRING" }, { "name": "lastName", "dataType": "STRING" }, { "name": "gender", "dataType": "STRING" }, { "name": "subject", "dataType": "STRING" } ], "metricFieldSpecs": [ { "name": "score", "dataType": "FLOAT" } ], "dateTimeFieldSpecs": [{ "name": "timestampInEpoch", "dataType": "LONG", "format" : "1:MILLISECONDS:EPOCH", "granularity": "1:MILLISECONDS" }]}
- 建立表設定:表設定用於定義與Pinot表相關的設定。該表的詳細概述可以在表中找到。下面是上面CSV資料檔案的表設定,建立表組態檔/tmp/pinot-quick-start/transcript-table-offline.json
{ "tableName": "transcript", "segmentsConfig" : { "timeColumnName": "timestampInEpoch", "timeType": "MILLISECONDS", "replication" : "1", "schemaName" : "transcript" }, "tableIndexConfig" : { "invertedIndexColumns" : [], "loadMode" : "MMAP" }, "tenants" : { "broker":"DefaultTenant", "server":"DefaultTenant" }, "tableType":"OFFLINE", "metadata": {}}
- 上傳表設定和Schema
# 前面是通過docker網路建立,確保可以存取controllerHost(manual-pinot-controller為可以存取主機名、容器、IP)和controllerPort埠即可docker run --rm -ti \ --network=pinot-demo \ -v /tmp/pinot-quick-start:/tmp/pinot-quick-start \ --name pinot-batch-table-creation \ apachepinot/pinot:0.12.1 AddTable \ -schemaFile /tmp/pinot-quick-start/transcript-schema.json \ -tableConfigFile /tmp/pinot-quick-start/transcript-table-offline.json \ -controllerHost manual-pinot-controller \ -controllerPort 9000 -exec
可以通過檢查Rest API中的表設定和模式,以確保它已成功上傳。
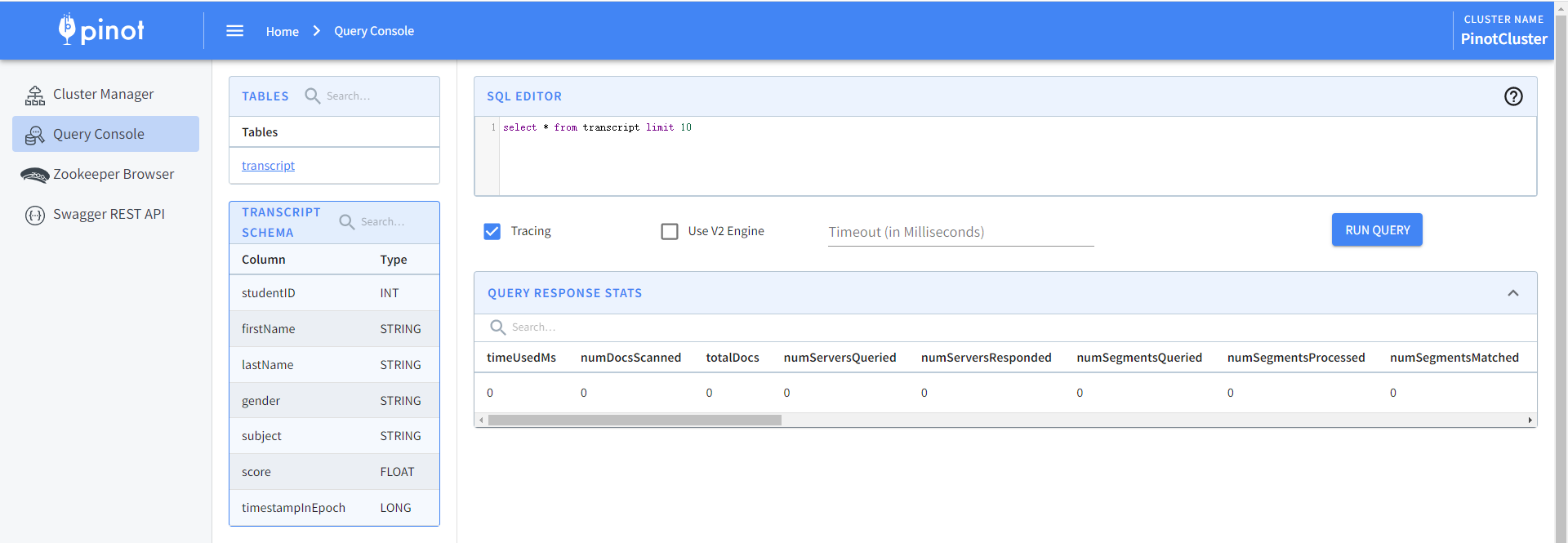
- 建立段:Pinot表的資料儲存為Pinot段。段的詳細概述可以在段中找到。為了生成一個段,首先需要建立一個作業規範yaml檔案。JobSpec yaml檔案包含有關資料格式、輸入資料位置和pinot叢集座標的所有資訊。建立/tmp/pinot-quick-start/docker-job-spec.yml檔案,內容如下
executionFrameworkSpec: name: 'standalone' segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner' segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner' segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'jobType: SegmentCreationAndTarPushinputDirURI: '/tmp/pinot-quick-start/rawdata/'includeFileNamePattern: 'glob:**/*.csv'outputDirURI: '/tmp/pinot-quick-start/segments/'overwriteOutput: truepinotFSSpecs: - scheme: file className: org.apache.pinot.spi.filesystem.LocalPinotFSrecordReaderSpec: dataFormat: 'csv' className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader' configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'tableSpec: tableName: 'transcript' schemaURI: 'http://manual-pinot-controller:9000/tables/transcript/schema' tableConfigURI: 'http://manual-pinot-controller:9000/tables/transcript'pinotClusterSpecs: - controllerURI: 'http://manual-pinot-controller:9000'
使用以下命令生成一個段並上傳
docker run --rm -ti \ --network=pinot-demo \ -v /tmp/pinot-quick-start:/tmp/pinot-quick-start \ --name pinot-data-ingestion-job \ apachepinot/pinot:0.12.1 LaunchDataIngestionJob \ -jobSpecFile /tmp/pinot-quick-start/docker-job-spec.yml
流式匯入資料
- 建立Kafka和主題
# 首先,需要設定一個流。Pinot為Kafka提供了開箱即用的實時攝取支援。在本地設定一個演示Kafka叢集,並建立一個範例主題轉錄主題docker run --rm -ti \ --network pinot-demo --name=kafka \ -e KAFKA_ZOOKEEPER_CONNECT=pinot-zookeeper:2181/kafka \ -e ALLOW_PLAINTEXT_LISTENER=yes \ -e KAFKA_BROKER_ID=0 \ -e KAFKA_ADVERTISED_HOST_NAME=kafka \ -p 9092:9092 \ -d bitnami/kafka:latest # 建立一個Kafka主題docker exec \ -t kafka \ /opt/bitnami/kafka/bin/kafka-topics.sh \ --bootstrap-server kafka:9092 \ --partitions=1 --replication-factor=1 \ --create --topic transcript-topic

- 建立表設定,建立/tmp/pinot-quick-start/transcript-table-realtime.json檔案,內容如下
{ "tableName": "transcript", "tableType": "REALTIME", "segmentsConfig": { "timeColumnName": "timestampInEpoch", "timeType": "MILLISECONDS", "schemaName": "transcript", "replicasPerPartition": "1" }, "tenants": {}, "tableIndexConfig": { "loadMode": "MMAP", "streamConfigs": { "streamType": "kafka", "stream.kafka.consumer.type": "lowlevel", "stream.kafka.topic.name": "transcript-topic", "stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder", "stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory", "stream.kafka.broker.list": "kafka:9092", "realtime.segment.flush.threshold.rows": "0", "realtime.segment.flush.threshold.time": "24h", "realtime.segment.flush.threshold.segment.size": "50M", "stream.kafka.consumer.prop.auto.offset.reset": "smallest" } }, "metadata": { "customConfigs": {} }}
- 上傳Schema和表設定
docker run \ --network=pinot-demo \ -v /tmp/pinot-quick-start:/tmp/pinot-quick-start \ --name pinot-streaming-table-creation \ apachepinot/pinot:0.12.1 AddTable \ -schemaFile /tmp/pinot-quick-start/transcript-schema.json \ -tableConfigFile /tmp/pinot-quick-start/transcript-table-realtime.json \ -controllerHost pinot-controller \ -controllerPort 9000 \ -exec
- 建立資料檔案用於kafka生產者傳送,/tmp/pinot-quick-start/rawdata/transcript.json,內容如下
{"studentID":205,"firstName":"Natalie","lastName":"Jones","gender":"Female","subject":"Maths","score":3.8,"timestampInEpoch":1571900400000}{"studentID":205,"firstName":"Natalie","lastName":"Jones","gender":"Female","subject":"History","score":3.5,"timestampInEpoch":1571900400000}{"studentID":207,"firstName":"Bob","lastName":"Lewis","gender":"Male","subject":"Maths","score":3.2,"timestampInEpoch":1571900400000}{"studentID":207,"firstName":"Bob","lastName":"Lewis","gender":"Male","subject":"Chemistry","score":3.6,"timestampInEpoch":1572418800000}{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"Geography","score":3.8,"timestampInEpoch":1572505200000}{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"English","score":3.5,"timestampInEpoch":1572505200000}{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"Maths","score":3.2,"timestampInEpoch":1572678000000}{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"Physics","score":3.6,"timestampInEpoch":1572678000000}{"studentID":211,"firstName":"John","lastName":"Doe","gender":"Male","subject":"Maths","score":3.8,"timestampInEpoch":1572678000000}{"studentID":211,"firstName":"John","lastName":"Doe","gender":"Male","subject":"English","score":3.5,"timestampInEpoch":1572678000000}{"studentID":211,"firstName":"John","lastName":"Doe","gender":"Male","subject":"History","score":3.2,"timestampInEpoch":1572854400000}{"studentID":212,"firstName":"Nick","lastName":"Young","gender":"Male","subject":"History","score":3.6,"timestampInEpoch":1572854400000}
將範例JSON推入Kafka主題,使用從Kafka下載的Kafka指令碼
bin/kafka-console-producer.sh \ --bootstrap-server kafka:9092 \ --topic transcript-topic < /tmp/pinot-quick-start/rawdata/transcript.json

- 本人部落格網站IT小神 www.itxiaoshen.com