ChatGPT研究報告:AIGC帶來新一輪正規化轉移
以ChatGPT為代表的AIGC(人工智慧生成內容)將成為新一輪正規化轉移的開始。
本文約4000字,目標是快速建立AIGC知識體系,含有大量的計算專業名詞,建議閱讀同時擴充套件搜尋。
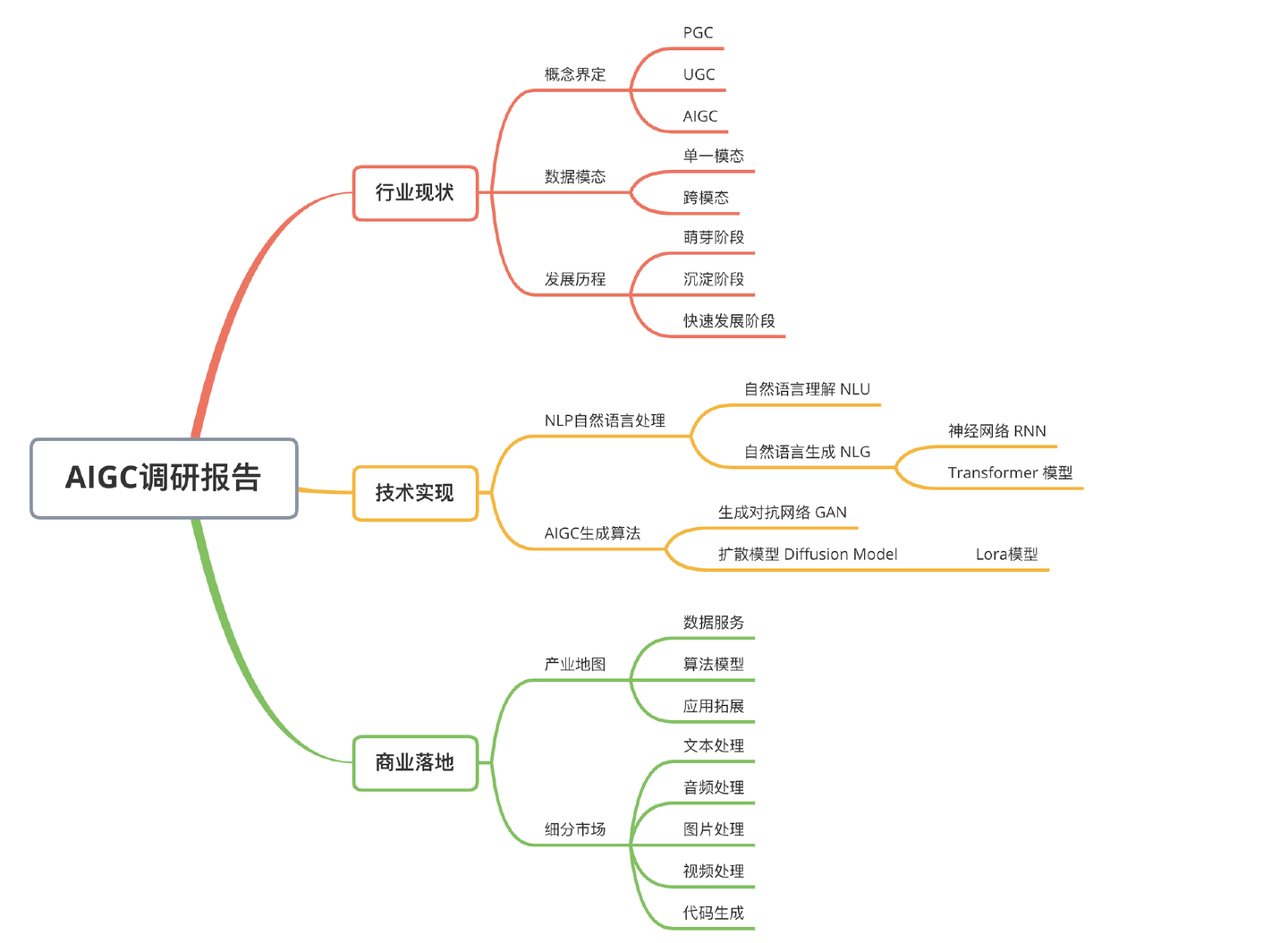
一、行業現狀
1、概念界定
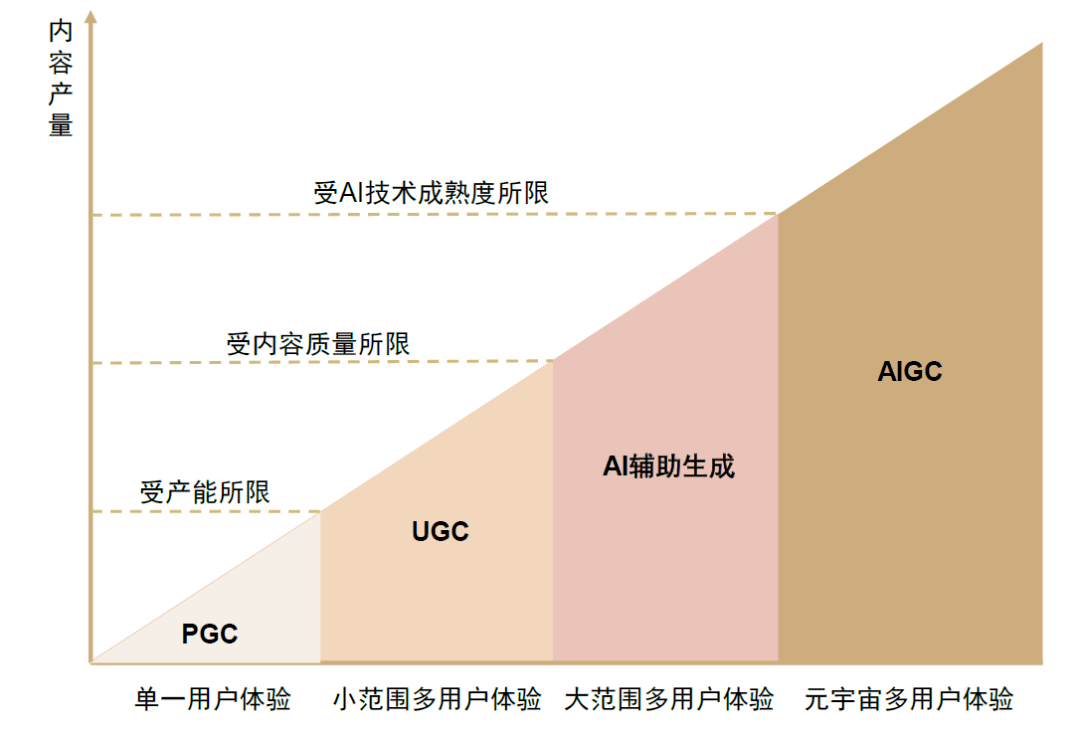
區別於PGC與UGC不同的,AIGC是利用人工智慧技術自動生成內容的新型生產方式。

2、資料模態
按照模態區分,AIGC又可分為音訊生成、文字生成、影象生成、視訊生成及影象、視訊、文字間的跨模態生成,細分場景眾多,其中跨模態生成值得重點關注。
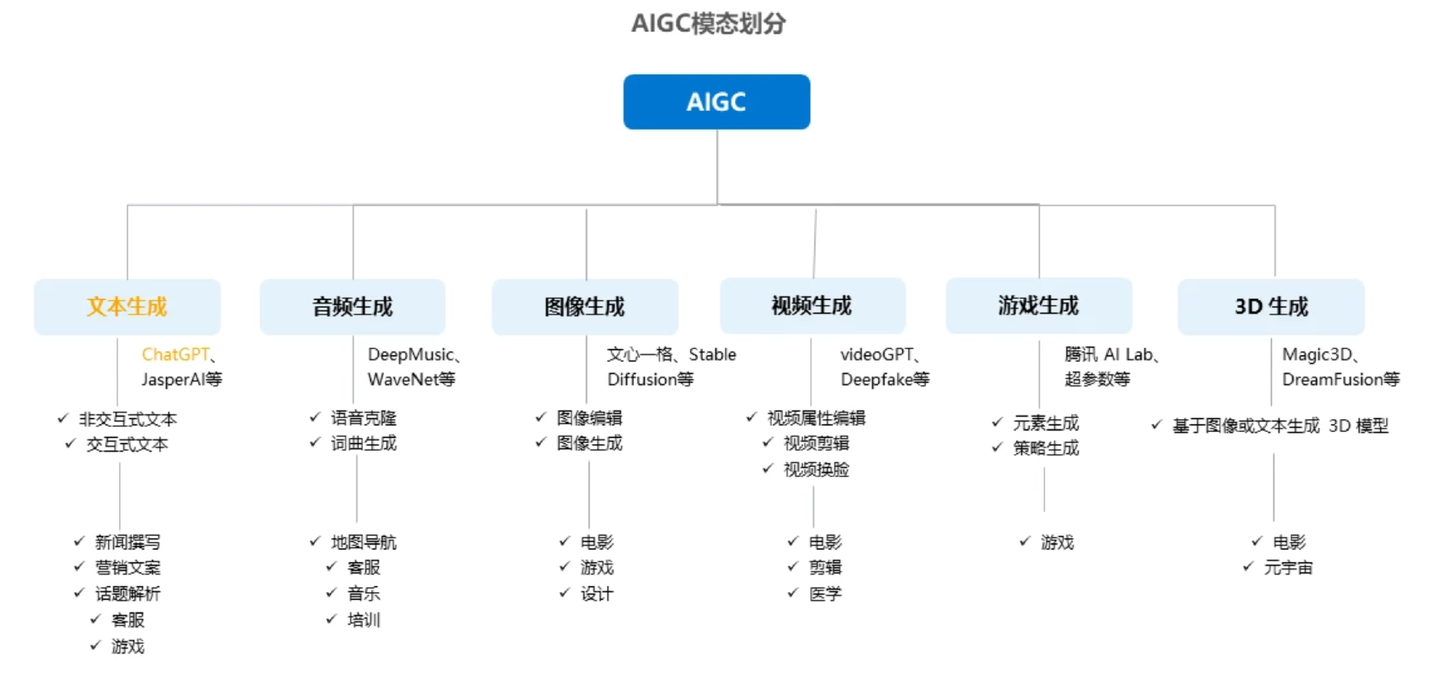
模態是指資料的存在形式,比如文字、音訊、影象、視訊等檔案格式
跨模態,指的是像以文生成圖/視訊或者以圖生成文這種情況
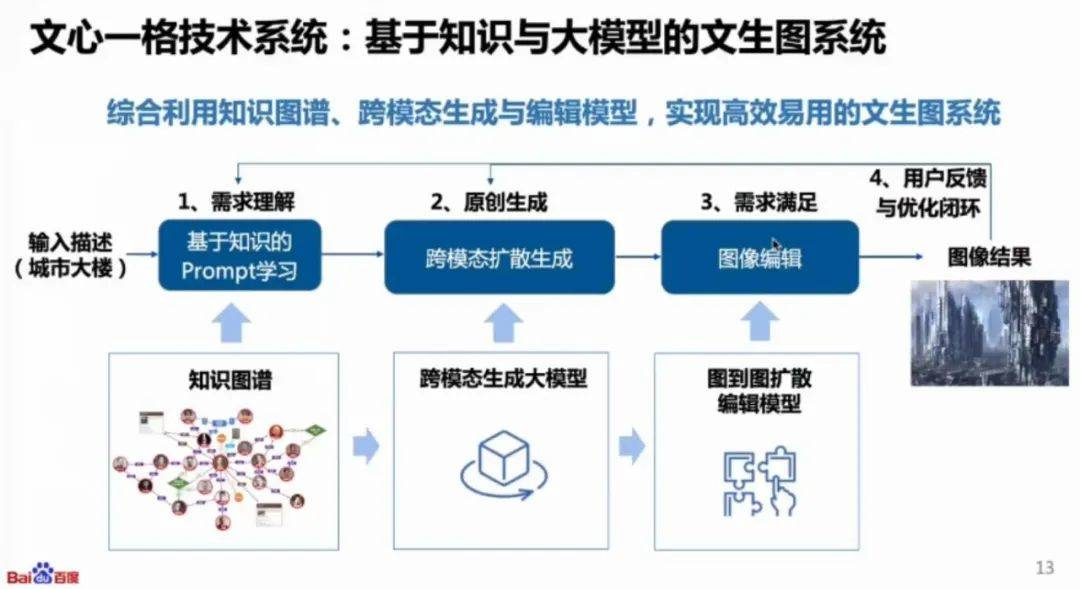
例如,百度的文心一格就是典型的以文生成圖:
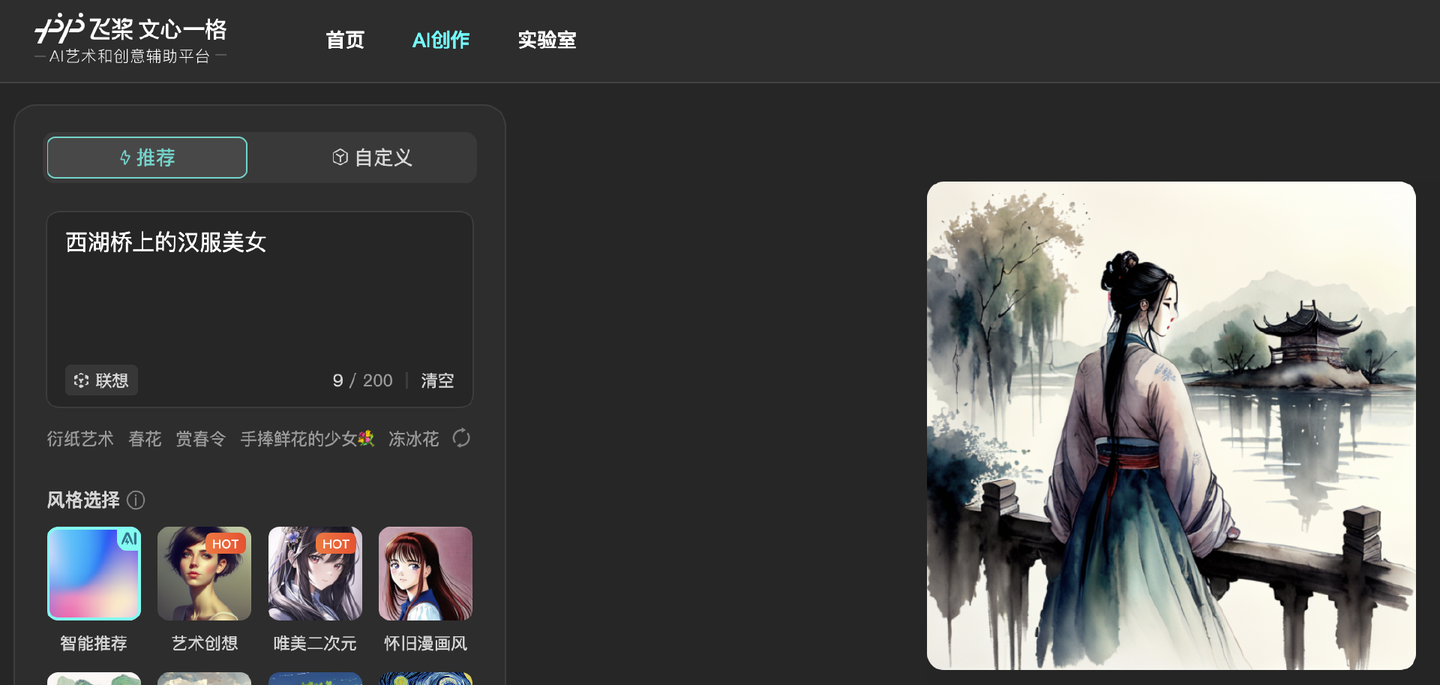
3、發展歷程
AIGC 的發展可以大致分為以下三個階段:
- 早期萌芽階段:20 世紀 50 年代—90 年代中期,受限於科技水平,AIGC 僅限於小範圍實驗
- 沉積積累階段:20 世紀 90 年代中期—21 世紀 10 年代中期,AIGC 從實驗向實用轉變,受限於演演算法,無法直接進行內容生成
- 快速發展階段:21 世紀 10 年代中期—現在,深度學習演演算法不斷迭代,AI 生成內容種類多樣豐富且效果逼真


二、技術實現
AIGC 技術主要涉及兩個方面:自然語言處理 NLP 和 AIGC 生成演演算法。
1、NLP自然語言處理
自然語言處理(NLP)賦予了AI理解和生成能力,是實現人與計算機之間如何通過自然語言進行互動的手段。
NLP技術可以分為兩個方向:NLU和NLG。
1.1 自然語言理解 NLU
NLU使得計算機能夠和人一樣,具備正常人的語言理解能力。
過去,計算機只能處理結構化的資料,NLU 使得計算機能夠識別和提取語言中的意圖來實現對於自然語言的理解。

由於自然語言的多樣性、歧義性、知識依賴性和上下文,計算機在理解上有很多難點,所以 NLU 至今還遠不如人類的表現。

自然語言理解跟整個人工智慧的發展歷史類似,一共經歷了 3 次迭代:基於規則的方法、基於統計的方法和基於深度學習的方法。

1.2 自然語言生成 NLG
NLG將非語言格式的資料轉換成人類可以理解的語言格式,如文章、報告等。
NLG 的發展經歷了三個階段,從早期的簡單的資料合併到模板驅動模式再到現在的高階 NLG,使得計算機能夠像人類一樣理解意圖,考慮上下文,並將結果呈現在使用者可以輕鬆閱讀和理解的敘述中。

自然語言生成可以分為以下六個步驟:內容確定、文字結構、句子聚合、語法化、參考表示式生成和語言實現。


1.3 神經網路 RNN
神經網路,尤其是迴圈神經網路 (RNN) 是當前 NLP 的主要方法的核心。
其中,2017 年由 Google 開發的 Transformer 模型現已逐步取代長短期記憶(LSTM)等 RNN 模型成為了 NLP 問題的首選模型。
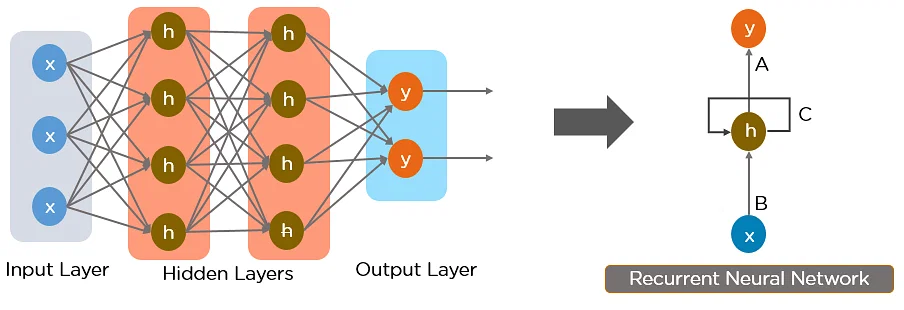
Transformer 的並行化優勢允許其在更大的資料集上進行訓練,這也促成了 BERT、GPT 等預訓練模型的發展。
相關係統使用了維基百科、Common Crawl 等大型語料庫進行訓練,並可以針對特定任務進行微調。

1.4 Transformer 模型
Transformer 模型是一種採用自注意力機制的深度學習模型,這一機制可以按輸入資料各部分重要性的不同而分配不同的權重。

與迴圈神經網路(RNN)一樣,Transformer 模型旨在處理自然語言等順序輸入資料,可應用於翻譯、文字摘要等任務。與 RNN 不同的是,Transformer 模型能夠一次性處理所有輸入資料。
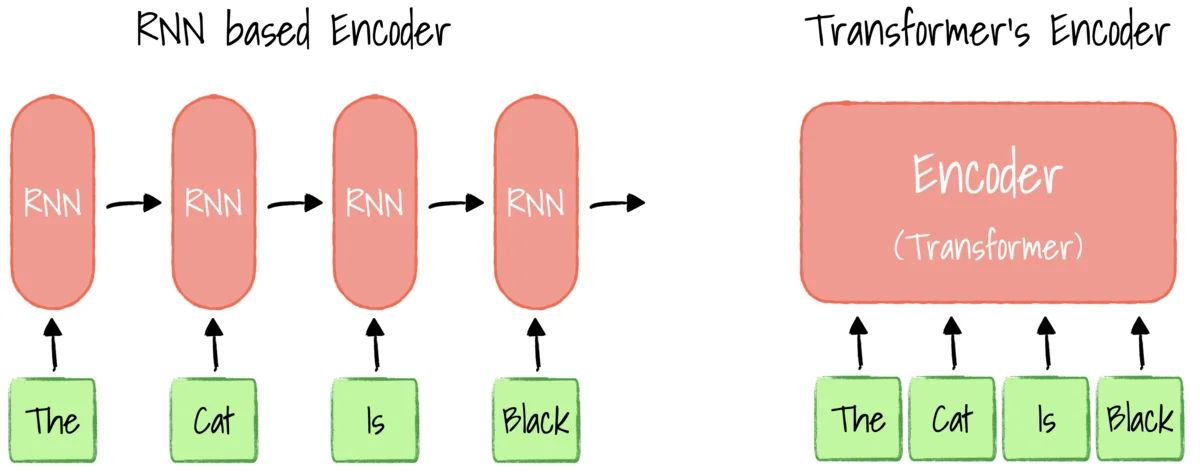
注意力機制可以為輸入序列中的任意位置提供上下文。如果輸入資料是自然語言,則 Transformer 不必像 RNN 一樣一次只處理一個單詞,這種架構允許更多的平行計算,並以此減少訓練時間。
ChatGPT是OpenAI從GPT-3.5、GPT-4系列中的模型進行微調產生的聊天機器人模型,能夠通過學習和理解人類的語言來進行對話,還能根據聊天的上下文進行互動,真正像人類一樣來聊天交流。
2、AIGC演演算法
- AIGC 生成演演算法主流的有生成對抗網路 GAN 和擴散模型
- 擴散模型已經擁有了成為下一代影象生成模型的代表的潛力
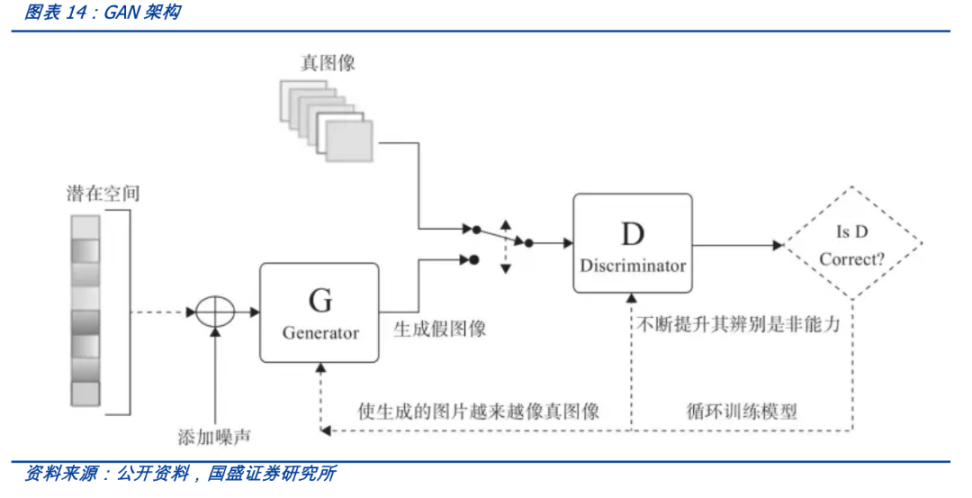
2.1 生成對抗網路 GAN
GAN是生成模型的一種,透過兩個神經網路相互博弈的方式進行學習。

GAN 被廣泛應用於廣告、遊戲、娛樂、媒體、製藥等行業,可以用來創造虛構的人物、場景,模擬人臉老化,影象風格變換,以及產生化學分子式等等。
2.2 擴散模型 Diffusion Model
GAN(生成對抗網路)有生成器和鑑別器,它們相互對抗,然後生成影象,由於模型本身具有對抗性,因此很難進行訓練,利用擴散模型可以解決這個問題。
擴散模型也是生成模型,擴散模型背後的直覺來源於物理學。在物理學中氣體分子從高濃度區域擴散到低濃度區域,這與由於噪聲的干擾而導致的資訊丟失是相似的。
Diffusion通過引入噪聲,然後嘗試通過去噪來生成影象。在一段時間內通過多次迭代,模型每次在給定一些噪聲輸入的情況下學習生成新影象。
2.3 Lora模型
LoRA是Low-Rank Adaption of large language model的縮寫,是一種大語言模型fine-tune的方法。

Lora主要思路是在固定大網路的引數,並訓練某些層引數的增量,且這些引數增量可通過矩陣分解變成更少的可訓練引數,大大降低finetune所需要訓練的引數量。

三、商業落地
1、A應用場景
- AIGC 在文字、影象、音訊、遊戲和程式碼生成中商業模型漸顯

2、產業地圖
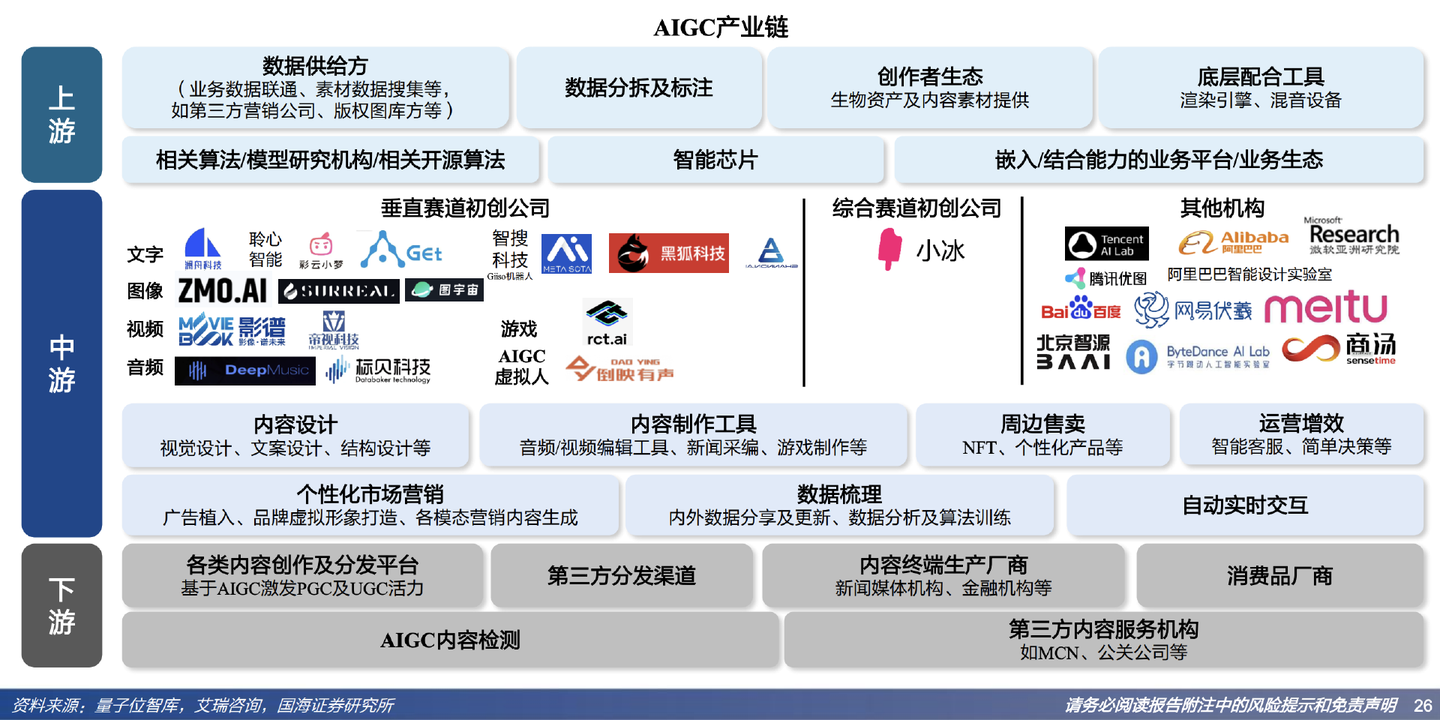
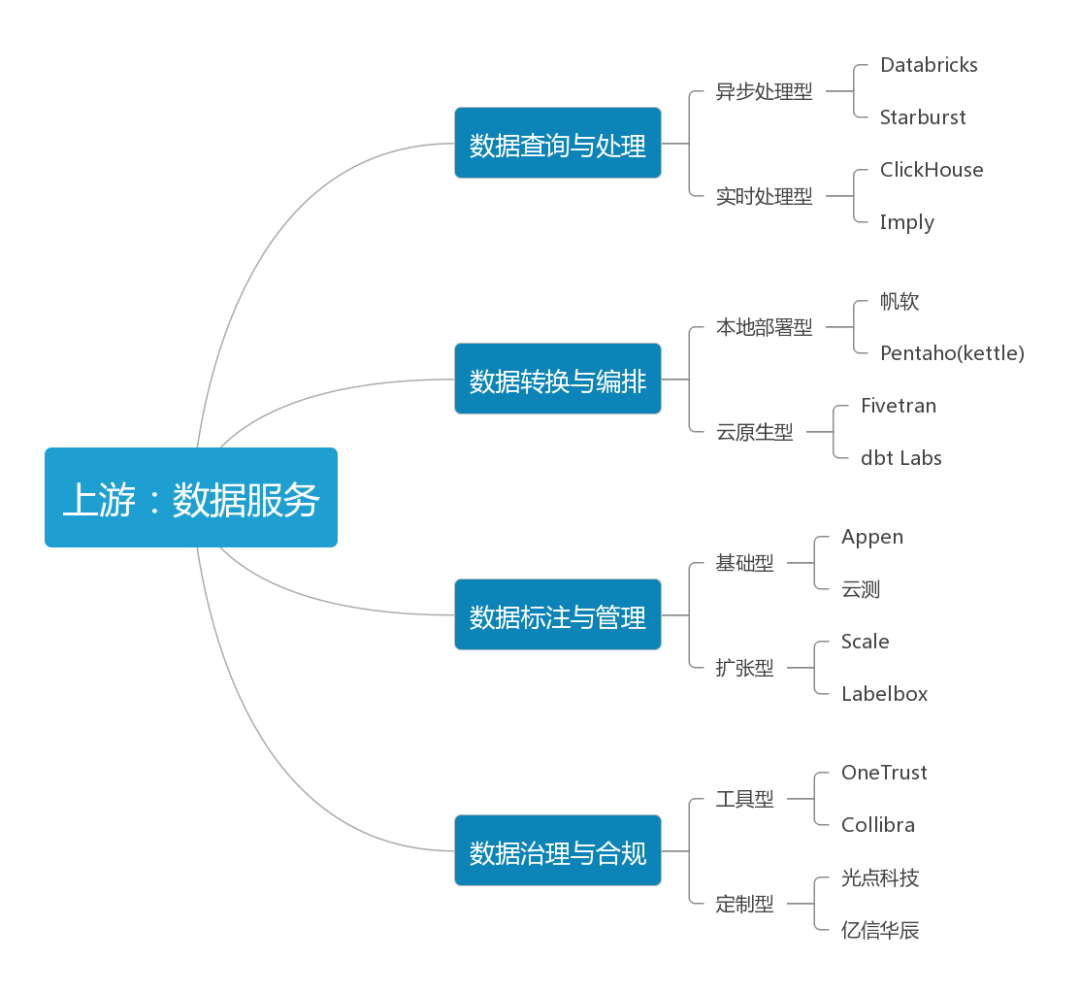
2.1 產業上游:資料服務
- 人工智慧的分析、創作、決策能力都依賴海量資料
- 決定不同機器間能力差異的就是資料的數量與質量
2.2 產業中游:演演算法模型
演演算法模型是AIGC最核心的環節,是機器學習的關鍵所在。通常包含三類參與者:專門實驗室、企業研究院、開源社群。

AI實驗室:演演算法模型在AI系統中起決策作用,是它完成各種任務的基礎,可以視為AI系統的靈魂所在。
企業研究院:一些集團型公司或企業往往會設立專注於前沿科技領域的大型研究院,下設不同領域的細分實驗室,通過學術氛圍更濃厚的管理方式為公司的科研發展添磚加瓦。
開源社群:社群對AIGC非常重要,它提供了一個共用成果、程式碼的平臺,與其他人相互合作,共同推動AIGC相關技術的進步。根據覆蓋領域的寬度和深度,這種社群可以分為綜合型開源社群和垂直型開源社群。
2.3 產業下游:應用拓展

3、細分市場
3.1 文書處理
文書處理是AIGC相關技術距離普通消費者最近的場景,技術較為成熟。
一般說來文書處理可以細分為行銷型、銷售型、續寫型、知識型、通用型、輔助型、互動型、程式碼型。

3.2 音訊處理
目前的音訊處理主要分為三類:音樂型、講話型、客製化型,AI的應用將優化供給效率,改善整體利潤水平。
3.3 圖片處理
圖片的創作門檻比文字高,傳遞資訊也更直觀,隨著AIGC應用的日益廣泛,圖片處理也就從廣告、設計、編輯等角度帶來更大更多的機遇。圖片處理可細分為生成型、廣告型、設計型、編輯型。
3.4 視訊處理
視訊日益成為新時代最主流的內容消費形態,將AIGC引入視訊將是全新的賽道,也是技術難度最大的領域。視訊處理可以細分為生成型、編輯型、客製化型、數位虛擬人視訊。


3.5 程式碼生成
以GitHub Copilot為例,Copilot是GitHub 和 OpenAI 合作產生的 AI 程式碼生成工具,可根據命名或者正在編輯的程式碼上下文為開發者提供程式碼建議。官方介紹其已經接受了來自 GitHub 上公開可用儲存庫的數十億行程式碼的訓練,支援大多數程式語言。
四、面臨挑戰
除了技術上亟待解決的算力、模型準確性之外,目前AIGC相關的挑戰主要集中在版權、欺詐、違禁內容三方面。
1、版權問題
- AIGC是機器學習的應用,而在模型的學習階段一定會使用大量資料,但目前對訓練後的生成物版權歸屬問題尚無定論
- 為什麼AI基於自己創作的作品生成的新作品卻與自己無關?而且現行法律都是針對人類的行為規範而設立的
- AI只是一種工具,不受法律約束與審判,即便證據充分,作者的維權之路通常也難言順利
- 不過對於AIGC與作者的關係將會隨著時代發展而逐漸清晰,界定也將更有條理性
2、欺詐問題
- 高科技詐騙手段層出不窮,AI經過訓練後也可以創作出以假亂真的音視訊,「換臉」「變聲」等功能,濫用危害甚大
- 部分詐騙分子利用「換臉」技術實施詐騙,也有不法分子惡意偽造他人視訊,再轉手兜售到灰色市場
3、違禁內容
- AIGC取決於使用者的引導,AI對惡意誘導會不加分辨或判斷,會根據學習到的資訊輸出極端或暴力言論
- AIGC作為內容生產的新正規化,也對國家相關法律法規機構及監管治理能力都提出了更高要求
參考資料
https://stablediffusionweb.com/
https://arxiv.org/pdf/1706.03762.pdf
https://arxiv.org/pdf/1406.2661.pdf
https://arxiv.org/pdf/1409.2329.pdf
https://arxiv.org/pdf/2112.10752.pdf
https://arxiv.org/pdf/2106.09685.pdf
https://github.com/pbloem/former
https://github.com/haofanwang/Lora-for-Diffusers/blob/main/convert_lora_safetensor_to_diffusers.py
AIGC:內容生產力的革命—國海證券
AIGC發展趨勢報告2023—騰訊研究院
2023AIGC行業研究報告—甲子光年
本文來自部落格園,作者:邴越,轉載請註明原文連結:https://www.cnblogs.com/binyue/p/17312696.html