由 Base64 展開的知識探討
我們是袋鼠雲數棧 UED 團隊,致力於打造優秀的一站式資料中臺產品。我們始終保持工匠精神,探索前端道路,為社群積累並傳播經驗價值。。
本文作者:霜序(掘金)
前言
在我們的業務應用中越來越多的應用到編碼內容,例如在 API 中,給到後端的 SQL 都是通過 Base64 加密的資料等等。
能夠發現我們的程式碼中,使用的 window 物件上的 btoa 方法實現的 Base64 編碼,那 btoa 具體是如何實現的呢?將在下面的內容中為大家講解。
那我們就先從一些基礎知識開始深入瞭解吧~
什麼是編碼
編碼,是資訊從一種形式轉變為另一種形式的過程,簡要來說就是語言的翻譯。
將機器語言(二進位制)轉變為自然語言。
五花八門的編碼
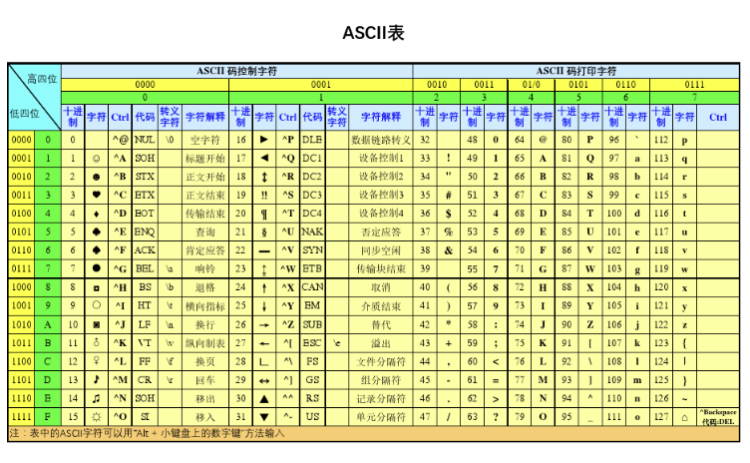
ASCII 碼
ASCII 碼是一種字元編碼標準,用於將數位、字母和其他字元轉換為計算機可以理解的二進位制數。
它最初是由美國資訊交換標準所制定的,它包含了 128 個字元,其中包括了數位、大小寫字母、標點符號、控制字元等等。
在計算機中一個位元組可以表示256眾不同的狀態,就對應256字元,從 00000000 到 11111111。ASCII 碼一共規定了128字元,所以只需要佔用一個位元組的後面7位,最前面一位均為0,所以 ASCII 碼對應的二進位制位 00000000 到 01111111。
非 ASCII 碼
當其他國家需要使用計算機顯示的時候就無法使用 ASCII 碼如此少量的對映方法。因此技術革新開始啦。
- GB2312
收錄了6700+的漢字,使用兩個位元組作為編碼字元集的空間 - GBK
GBK 在保證不和 GB2312/ASCII 衝突的情況下,使用兩個位元組的方式編碼了更多的漢字,達到了2w - 等等
全面統一的 Unicode
面對五花八門的編碼方式,同一個二進位制數會被解釋為不同的符號,如果使用錯誤的編碼的方式去讀區檔案,就會出現亂碼的問題。
那能否建立一種編碼能夠將所有的符號納入其中,每一個符號都有唯一對應的編碼,那麼亂碼問題就會消失。因此 Unicode 藉此機會統一江湖。是由一個叫做 Unicode 聯盟的官方組織在維護。
Unicode 最常用的就是使用兩個位元組來表示一個字元(如果是更為偏僻的字元,可能所需位元組更多)。現代作業系統都直接支援 Unicode。
Unicode 和 ASCII 的區別
- ASCII 編碼通常是一個位元組,Unicode 編碼通常是兩個位元組.
字母 A 用 ASCII 編碼十進位制為 65,二進位制位 01000001;而在 Unicode 編碼中,需要在前面全部補0,即為 00000000 01000001 - 問題產生了,雖然使用 Unicode 解決亂碼的問題,但是為純英文的情況,儲存空間會大一倍,傳輸和儲存都不划算。
問題對應的解決方案之UTF-8
UTF-8 全名為 8-bit Unicode Transformation Format
本著節約的精神,又出現了把 Unicode 編碼轉為可變長編碼的 UTF-8。可以根據不同字元而變化位元組長度,使用1~4位元組表示一個符號。UTF-8 是 Unicode 的實現方式之一。
UTF-8 的編碼規則
- 對於單位元組的符號,位元組的第一位設定為0,後面七位為該字元的 Unicode 碼。因此對於英文字母,UTF-8 編碼和 ASCII 編碼是相同的。
- 對於 n 位元組的符號,第一個位元組的前 n 位都是1,第 n+1 位為0,後面的位元組的前兩位均為10。剩下的位所填充的二進位制就是這個字元的 Unicode 碼
對應的編碼表格
| Unicode 符號範圍 | UTF-8 編碼方式 |
|---|---|
| 0000 0000-0000 007F (0-127) | 0xxxxxxx |
| 0000 0080-0000 07FF (128-2047) | 110xxxxx 10xxxxxx |
| 0000 0800-0000 FFFF (2048-65535) | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000-0010 FFFF (65536往上) | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxxx |
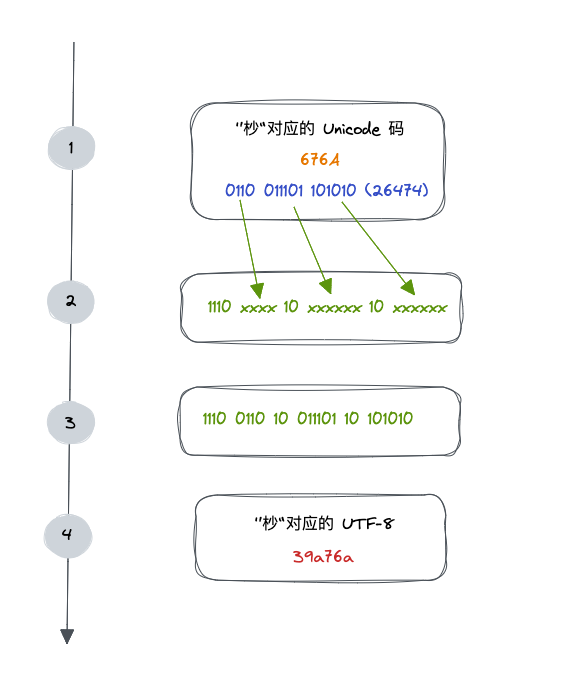
在 Unicode 對應表中查詢到「杪」所在的位置,以及其對應的十六進位制 676A,對應的十進位制為 26474(110011101101010),對應三個位元組 1110xxxx 10xxxxxx 10xxxxxx
將110011101101010的最後一個二進位制依次填充到1110xxxx 10xxxxxx 10xxxxxx從後往前的 x ,多出的位補0即可,中,得到11100110 10011101 10101010 ,轉換得到39a76a,即是杪字對應的 UTF-8 的編碼
- >> 向右移動,前面補 0, 如 104 >> 2 即 01101000=> 00011010
- & 與運算,只有兩個運算元相應的位元位都是 1 時,結果才為 1,否則為 0。如 104 & 3即 01101000 & 00000011 => 00000000,& 運算也用在取位時
- | 或運算,對於每一個位元位,當兩個運算元相應的位元位至少有一個 1 時,結果為 1,否則為 0。如 01101000 | 00000011 => 01101011
function unicodeToByte(input) {
if (!input) return;
const byteArray = [];
for (let i = 0; i < input.length; i++) {
const code = input.charCodeAt(i); // 獲取到當前字元的 Unicode 碼
if (code < 127) {
byteArray.push(code);
} else if (code >= 128 && code < 2047) {
byteArray.push((code >> 6) | 192);
byteArray.push((code & 63) | 128);
} else if (code >= 2048 && code < 65535) {
byteArray.push((code >> 12) | 224);
byteArray.push(((code >> 6) & 63) | 128);
byteArray.push((code & 63) | 128);
}
}
return byteArray.map((item) => parseInt(item.toString(2)));
}
問題對應的解決方案之UTF-16
UTF-16 全名為 16-bit Unicode Transformation Format
在 Unicode 編碼中,最常用的字元是0-65535,UTF-16 將0–65535範圍內的字元編碼成2個位元組,超過這個的用4個位元組編碼
UTF-16 編碼規則
- 對於 Unicode 碼小於 0x10000 的字元, 使用2個位元組儲存,並且是直接儲存 Unicode 碼,不用進行編碼轉換
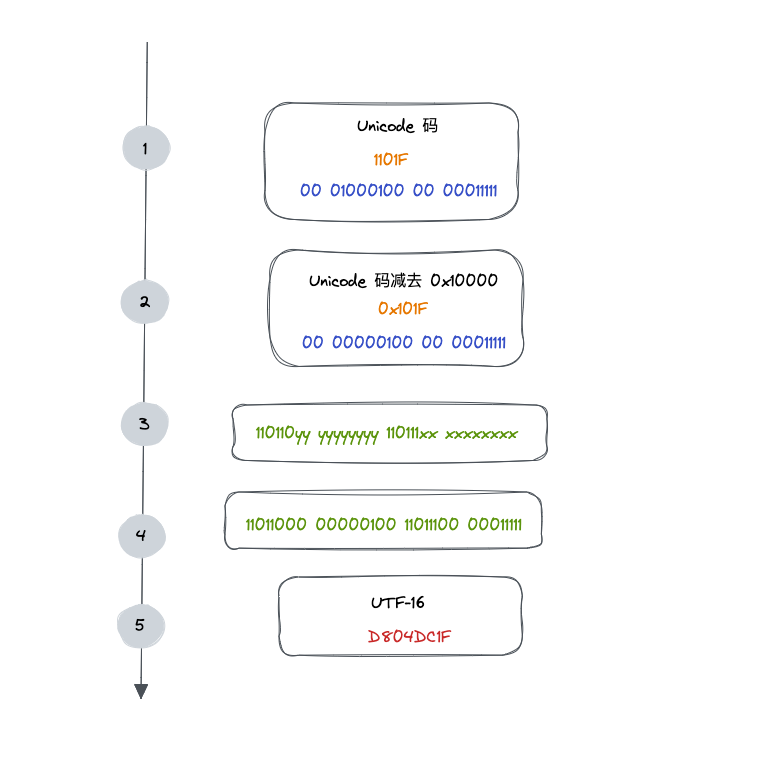
- 對於 Unicode 碼在 0x10000 和 0x10FFFF 之間的字元,使用 4 個位元組儲存,這 4 個位元組分成前後兩部分,每個部分各兩個位元組,其中,前面兩個位元組的前 6 位二進位制固定為 110110,後面兩個位元組的前 6 位二進位制固定為 110111,前後部分各剩餘 10 位二進位制表示符號的 Unicode 碼 減去 0x10000 的結果
- 大於 0x10FFFF 的 Unicode 碼無法用 UTF-16 編碼
對應的編碼表格
| Unicode 符號範圍 | 具體Unicode碼 | UTF-16 編碼方式 | 位元組 |
|---|---|---|---|
| 0000 0000-0000 FFFF (0-65535) | xxxxxxxx xxxxxxxx | xxxxxxxx xxxxxxxx | 2位元組 |
| 0001 0000-0010 FFFF (65536往上) | yy yyyyyyyy xx xxxxxxxx | 110110yy yyyyyyyy 110111xx xxxxxxxx | 4位元組 |
「杪」字的 Unicode 碼為 676A(26474),小於 65535,所以對應的 UTF-16 編碼也為 676A
找一個大於 0x10000 的字元,0x1101F,進行 UTF-16 編碼
位元組序
對於上述講到的 UTF-16 來說,它存在一個位元組序的概念。
位元組序就是位元組之間的順序,當傳輸或者儲存時,如果超過一個位元組,需要指定位元組間的順序。
最小編碼單元是多位元組才會有位元組序的問題存在,UTF-8 最小編碼單元是一個位元組,所以它是沒有位元組序的問題,UTF-16 最小編碼單元是兩個位元組,在解析一個 UTF-16 字元之前,需要知道每個編碼單元的位元組序。
為什麼會出現位元組序?
計算機電路先處理低位位元組,效率比較高,因為計算都是從低位開始的。所以,計算機的內部處理都是小端位元組序。但是,人類還是習慣讀寫大端位元組序。
所以,除了計算機的內部處理,其他的場合比如網路傳輸和檔案儲存,幾乎都是用的大端位元組序。
正是因為這些原因才有了位元組序。
比如:前面提到過,"杪"字的 Unicode 碼是 676A,"橧"字的 Unicode 碼是 6A67,當我們收到一個 UTF-16 位元組流 676A 時,計算機如何識別它表示的是字元 "杪"還是 字元 "橧"呢 ?
對於多位元組的編碼單元需要有一個標識顯式的告訴計算機,按著什麼樣的順序解析字元,也就是位元組序。
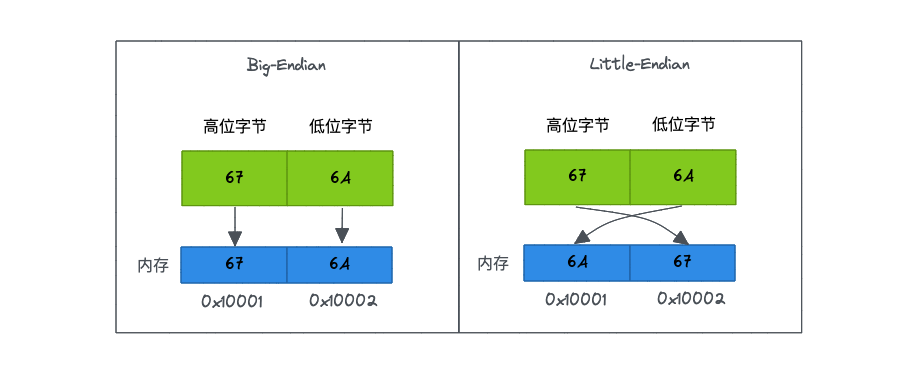
- 大端位元組序(Big-Endian),表示高位位元組在前面,低位位元組在後面。高位位元組儲存在記憶體的低地址端,低位位元組儲存在在記憶體的高地址端。
- 小端位元組序(Little-Endian),表示低位位元組在前,高位位元組在後面。高位位元組儲存在記憶體的高地址端,而低位位元組儲存在記憶體的低地址端。
簡單聊聊 ArrayBuffer 和 TypedArray、DataView
ArrayBuffer
ArrayBuffer 是一段儲存二進位制的記憶體,是位元組陣列。
它不能夠被直接讀寫,需要建立檢視來對它進行操作,指定具體格式操作二進位制資料。
可以通過它建立連續的記憶體區域,引數是記憶體大小(byte),預設初始值都是 0
TypedArray
ArrayBuffer 的一種操作檢視,資料都儲存到底層的 ArrayBuffer 中
const buf = new ArrayBuffer(8);
const int8Array = new Int8Array(buf);
int8Array[3] = 44;
const int16Array = new Int16Array(buf);
int16Array[0] = 42;
console.log(int16Array); // [42, 11264, 0, 0]
console.log(int8Array); // [42, 0, 0, 44, 0, 0, 0, 0]
使用 int8 和 int16 兩種方式新建的檢視是相互影響的,都是直接修改的底層 buffer 的資料
DataView
DataView 是另一種操作檢視,並且支援設定位元組序
const buf = new ArrayBuffer(24);
const dataview = new DataView(buf);
dataView.setInt16(1, 3000, true); // 小端序
明確電腦的位元組序
上述講到,在儲存多位元組的時候,我們會採用不同的位元組序來做儲存。那對我們的作業系統來說是有一種預設的位元組序的。下面就用上述知識來明確 MacOS 的預設位元組序。
function isLittleEndian() {
const buf = new ArrayBuffer(2);
const view = new Int8Array(buf);
view[0]=1;
view[1]=0;
console.log(view);
const int16Array = new Int16Array(buf);
return int16Array[0] === 1;
}
console.log(isLittleEndian());
通過上述程式碼我們可以得出此款 MacOS 是小端序列儲存
一個