zookeeper重啟,線上微服務全部掉線,怎麼回事?
註冊中心zookeeper被重啟,線上微服務全部掉線,怎麼回事?!
最近因為一次錯誤的運維操作,導致線上註冊中心zk被重啟。而zk重啟後發現所有線上微服務開始不斷掉線,造成了持續30分鐘的P0故障。
整體排查過程深入學習了 zookeeper的session機制,以及在這種異常情況下,RPC框架應該如何處理。
好了,一起來回顧下這次線上故障吧,最佳實踐總結放在最後,千萬不要錯過。
1、現象描述
某天晚上19:43分左右,誤操作將線上zk叢集下線(stop),總共7臺節點,下線了6臺,導致zk停止工作。
在發現節點下掉後,於19:51分左右將所有zk節點進行重啟(start),期間服務正常執行,沒有收到批次業務呼叫的報錯和客訴。
直到19:56分,開始收到大面積呼叫失敗的警報和客訴,我們嘗試著依賴自研RPC框架與zk間重連後的「自動恢復」機制,希望能夠在短時間內批次恢復。
但是很不幸,過了接近8分鐘,沒有任何大面積恢復的跡象。結合zk znode節點數上升非常緩慢的情況,於是我們採取了應急措施,將所有微服務的pod原地重啟,執行重啟後效果顯著,大面積服務在短時間內逐步恢復。
2、初步分析
我們自研的RPC框架採用典型的 註冊中心+provider+consumer 的模式,通過zk臨時節點的方式做服務的註冊發現,如下圖所示。
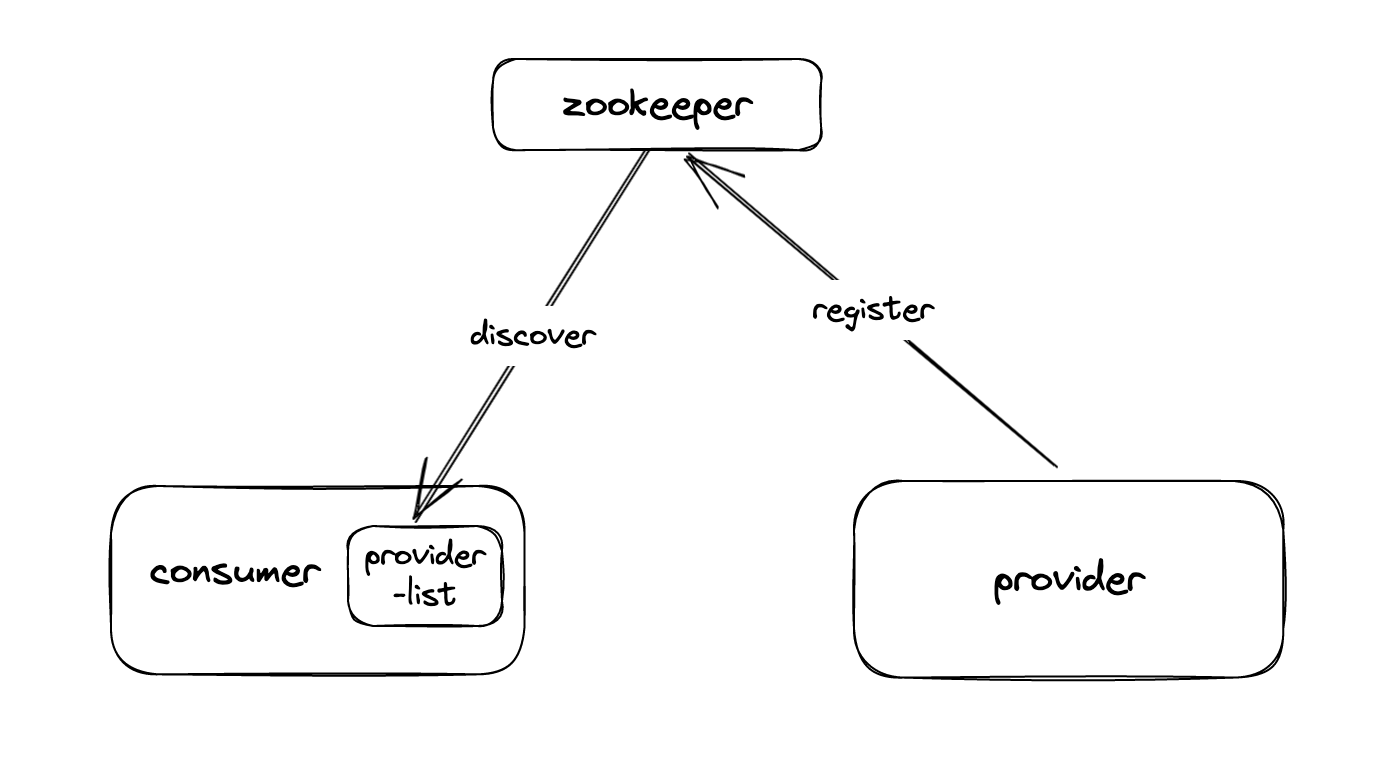
結合故障期間發生的現象,我們初步分析:
- 階段1:zk叢集停服(stop)期間,業務能夠正常呼叫。原因是consumer無法存取zk,暫時失去服務發現能力,所以在這個期間只要服務沒有重啟,就不會重新整理原生的服務發現provider快取列表provider-list,呼叫無異常。
- 階段2:zk叢集啟動完畢後,服務間立刻出現呼叫問題。原因是consumer連線上zk後,立刻進行服務發現操作,然而provider服務這時還沒重新註冊到zk,讀取到的是空地址列表,造成了業務的批次報錯。
- 階段3:zk恢復後續一段時間,provider服務仍然沒「自動重連」到zk,導致consumer持續報錯。在所有服務全量重啟後,provider服務重新註冊成功,consumer恢復。
這裡存在一個問題:
- 為什麼zk叢集恢復後,provider使用者端「自動重連」註冊中心的機制沒有生效?導致consumer被推播了空地址列表後,沒有再收到重新的provider註冊節點資訊了。
3、深入排查
3.1 問題復現
根據大量測試和真實表現,我們找到了穩定復現本次問題的方法:
zk session過期包括 「伺服器端過期」 和 「使用者端過期」,在「使用者端過期」情況下恢復zk叢集,會導致「臨時節點」丟失,且無法自動恢復的情況。
3.2 分析
1)在叢集重啟恢復後,RPC框架使用者端立刻就與zk叢集取得重連,將儲存在本地記憶體待註冊的providers節點 + 待訂閱的consumers節點 進行重建。
2)但是zk叢集此時根據snapshot恢復的「臨時節點」(包括provider和consumer) 都還在,因此重建操作返回NodeExist異常,重建失敗了。(問題1:為什麼沒有重試?)
3)在叢集重啟恢復40s後,將過期Session相關的 臨時節點全都移除了。(問題2:為什麼要移除?)
4)consumer監聽到 節點移除 的空列表,清空了本地provider列表。故障發生了。
基於這個分析,我們需要進一步圍繞2個問題進行原始碼的定位:
- 問題1:zk叢集恢復後,前40s,為什麼RPC框架的使用者端在建立臨時節點失敗後沒有重試?
- 問題2:zk叢集恢復後,40s後,為什麼zk會刪除之前所有已經恢復的臨時節點?
3.3 問題1:為什麼臨時節點建立失敗沒有重試?
通過原始碼分析,我們看到,RPC框架使用者端與伺服器端取得重連後,會將記憶體里老的臨時節點進行重新建立。
這段邏輯看來沒有什麼問題,doRegister成功之後才會將該節點從失敗列表中移除,否則將繼續定時去重試建立。
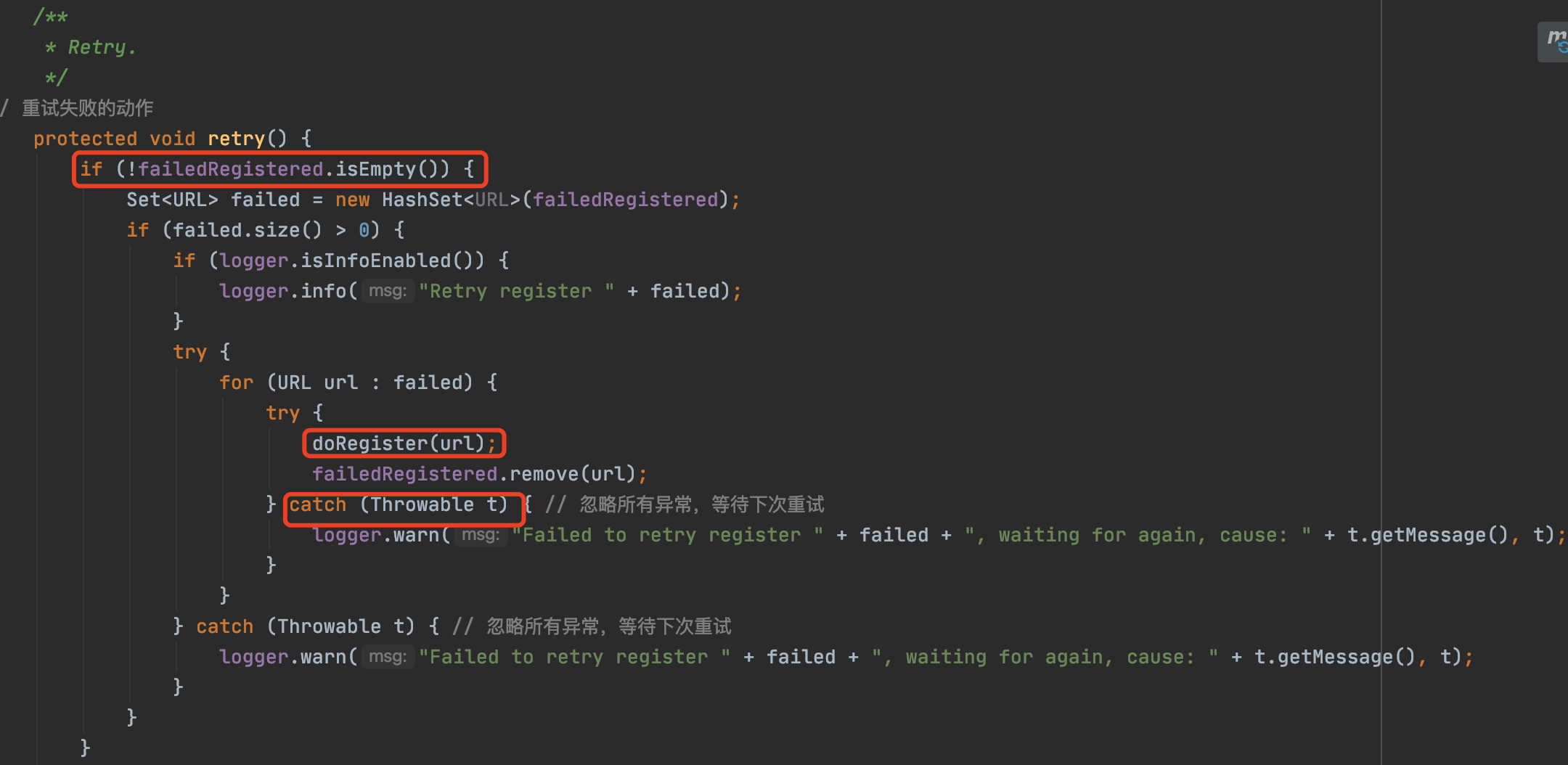
繼續往下走,關鍵點來了:
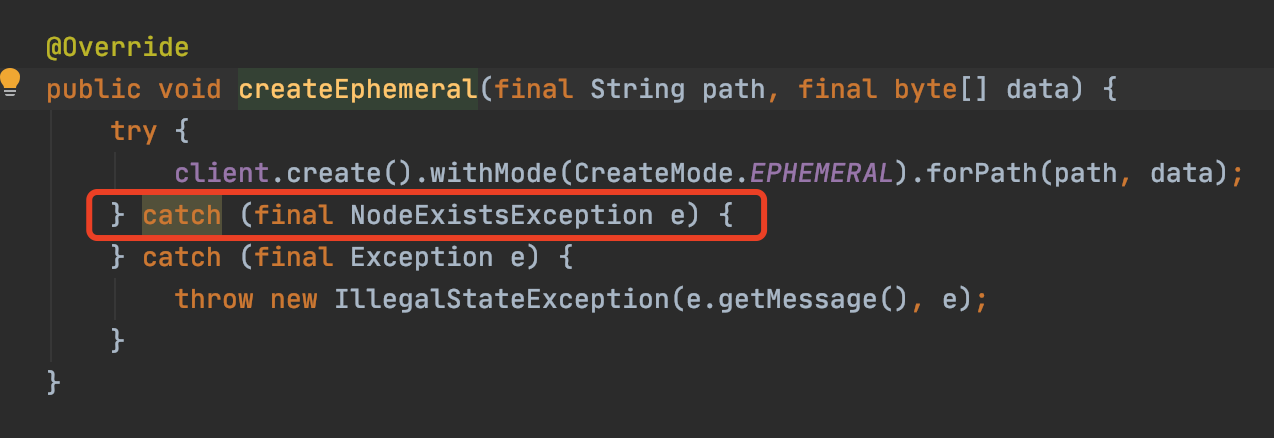
這裡我們可以看到,在建立臨時節點時,吞掉了伺服器端返回的NodeExistsException,使整個外層的doRegister和doSubscribe(訂閱)方法在這種情況下都被認為是重新建立成功,所以只建立了一次。
正如上面分析的,其實正常情況下,這裡對NodeExistsException不做處理是沒有問題的,就是節點已經存在不用再新增了,也不需要再重試了,但是伴隨伺服器端後續踢出老sessionId同時刪除了相關臨時節點,就引起了故障。
3.4 問題2:zk為什麼刪除已經恢復的臨時節點
3.4.1 從zk的session機制說起
眾所周知,zk session管理在使用者端、伺服器端都有實現,並且兩者通過心跳進行互動。
在傳送心跳包時,使用者端會攜帶自己的sessionId,伺服器端收到請求,檢查sessionId確認存活後再傳送返回結果給使用者端。
如果使用者端傳送了一個伺服器端並不知道的sessionId,那麼伺服器端會生成一個新的sessionId頒佈給使用者端,使用者端收到後本地進行sessionid的重新整理。
3.4.2 zk使用者端(curator)session過期機制
當用戶端(curator)本地sessionTimeout超時時,會進行本地zk物件的重建(reset),我們從原始碼可以看到預設將原生的sessionId重置為0了。
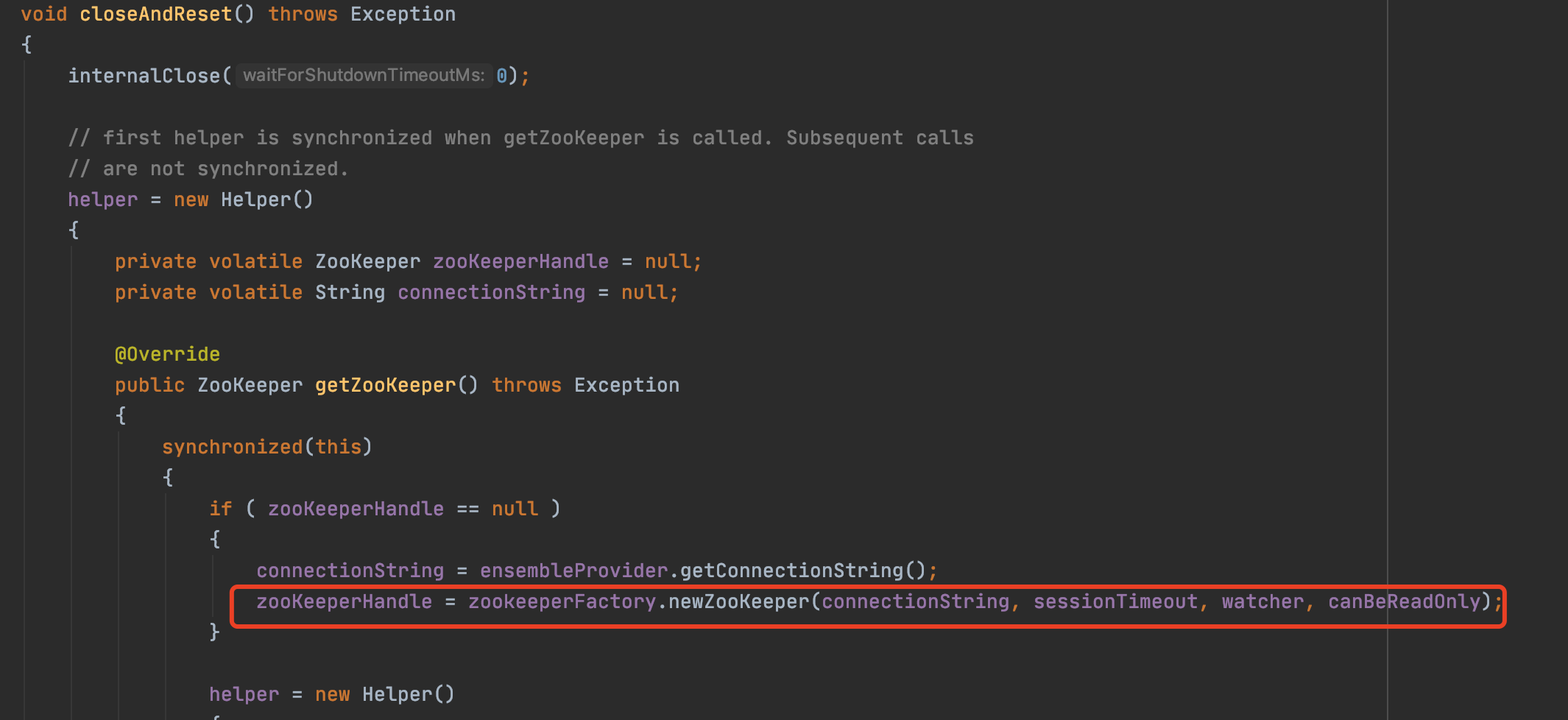

zk伺服器端後續收到這個為「0」sessionId,認為是一個未知的session需要建立,接著就為使用者端建立了一個新的sessionId。
3.4.3 伺服器端(zookeeper)session過期處理機制
伺服器端(zookeeper) sessionTimeout的管理,是在zk對談管理器中看到一個執行緒任務,不斷判斷管理的session是否有超時(獲取下一個過期時間點nextExpirationTime已經超時的對談),並進行對談的清理。
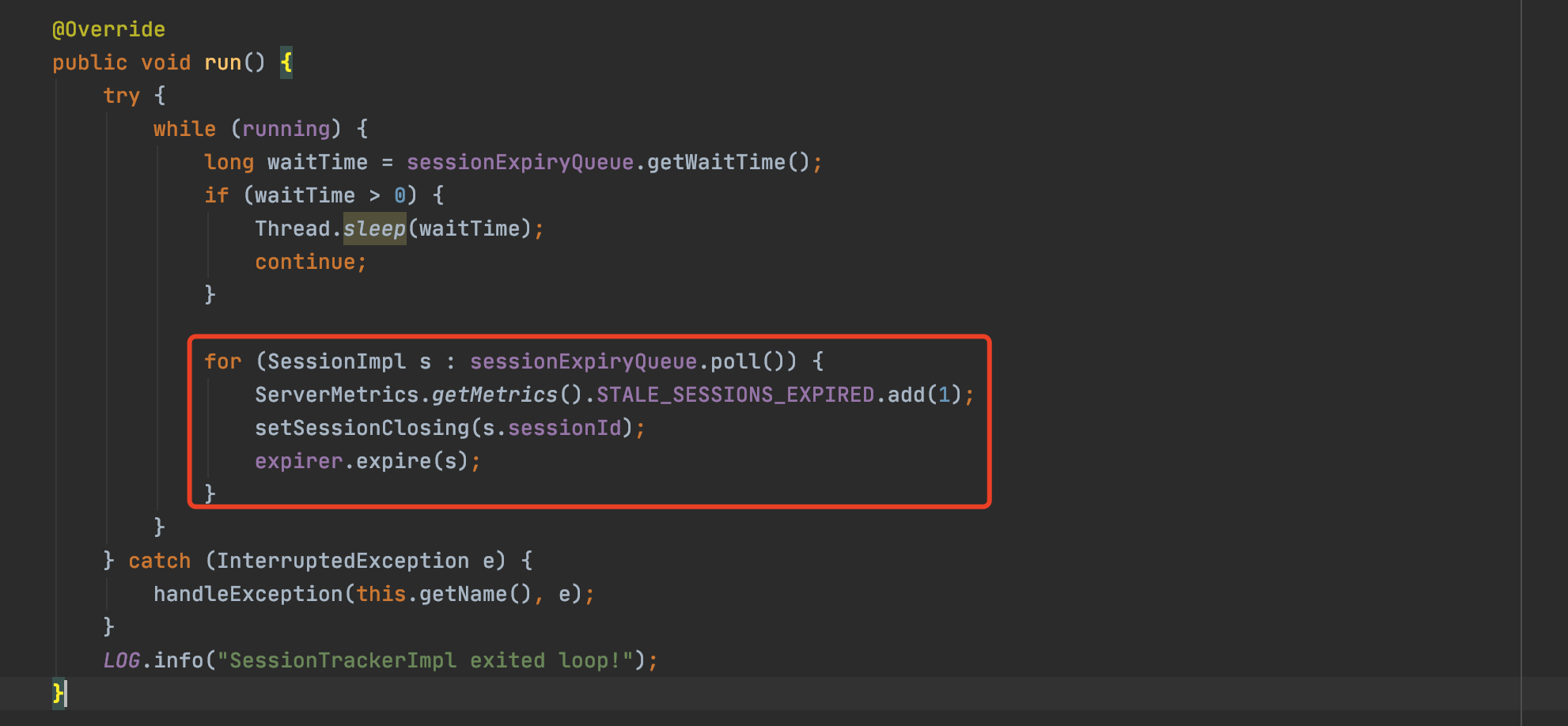
我們繼續往下走,關鍵點來了,在清理session的過程中,除了將sessionId從本地expiryMap中清除外,還進行了臨時節點的清理:
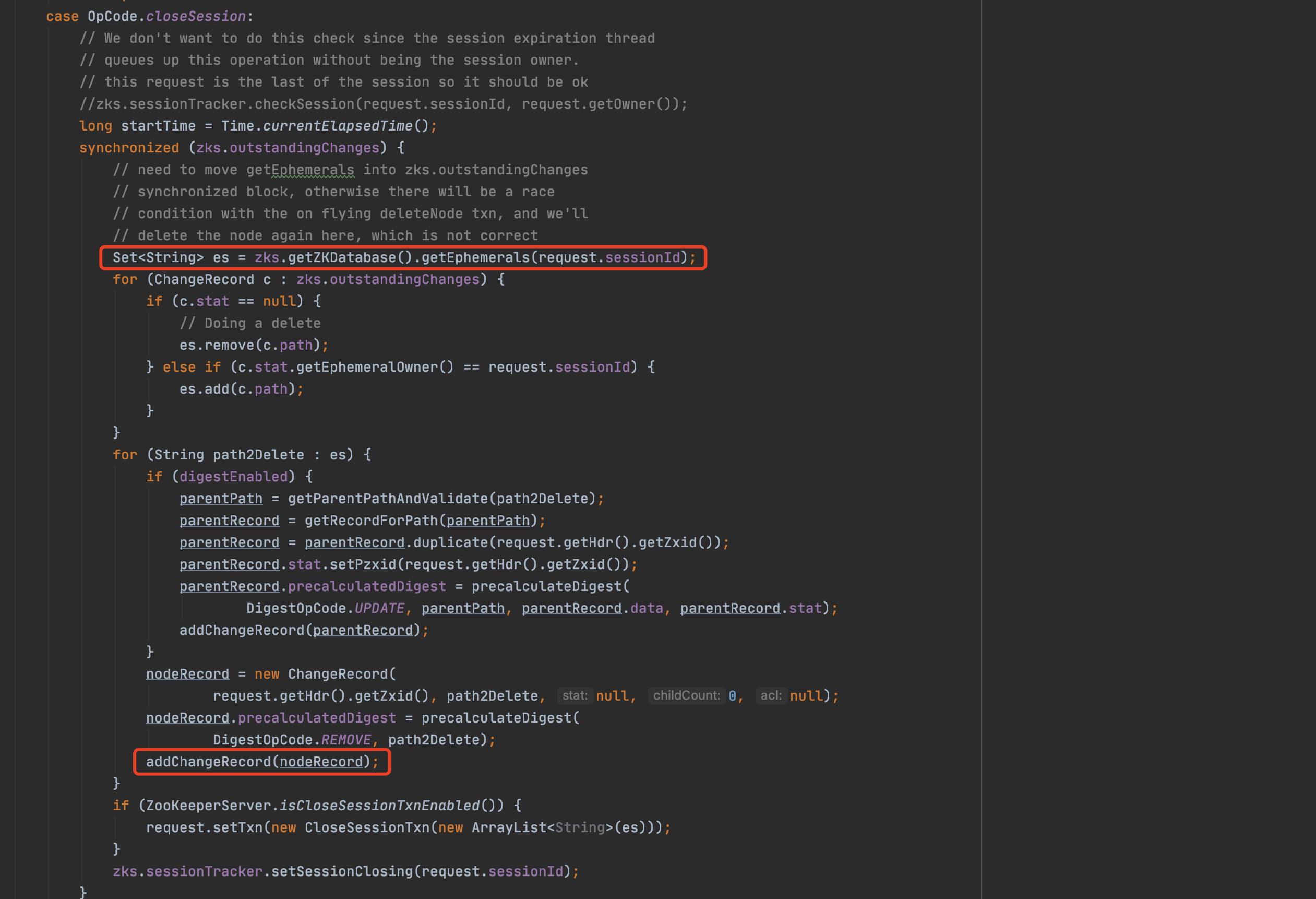
原來zkserver端是將sessionId和它所建立的臨時節點進行了繫結。伴隨著伺服器端sessionId的過期,繫結的所有臨時節點也會隨之刪除。
因此,zk叢集恢復後40s,zk伺服器端session超時,刪除了過期session的所有相關臨時節點。
4、 故障根本原因總結
1)zk叢集恢復的第一時間,對zk的snapshot檔案進行了讀取並初始化zk資料,取到了老session,進行了create session的操作,完成了一次老session的續約(重置40s)。
叢集恢復關鍵入口-重新載入snapshot:
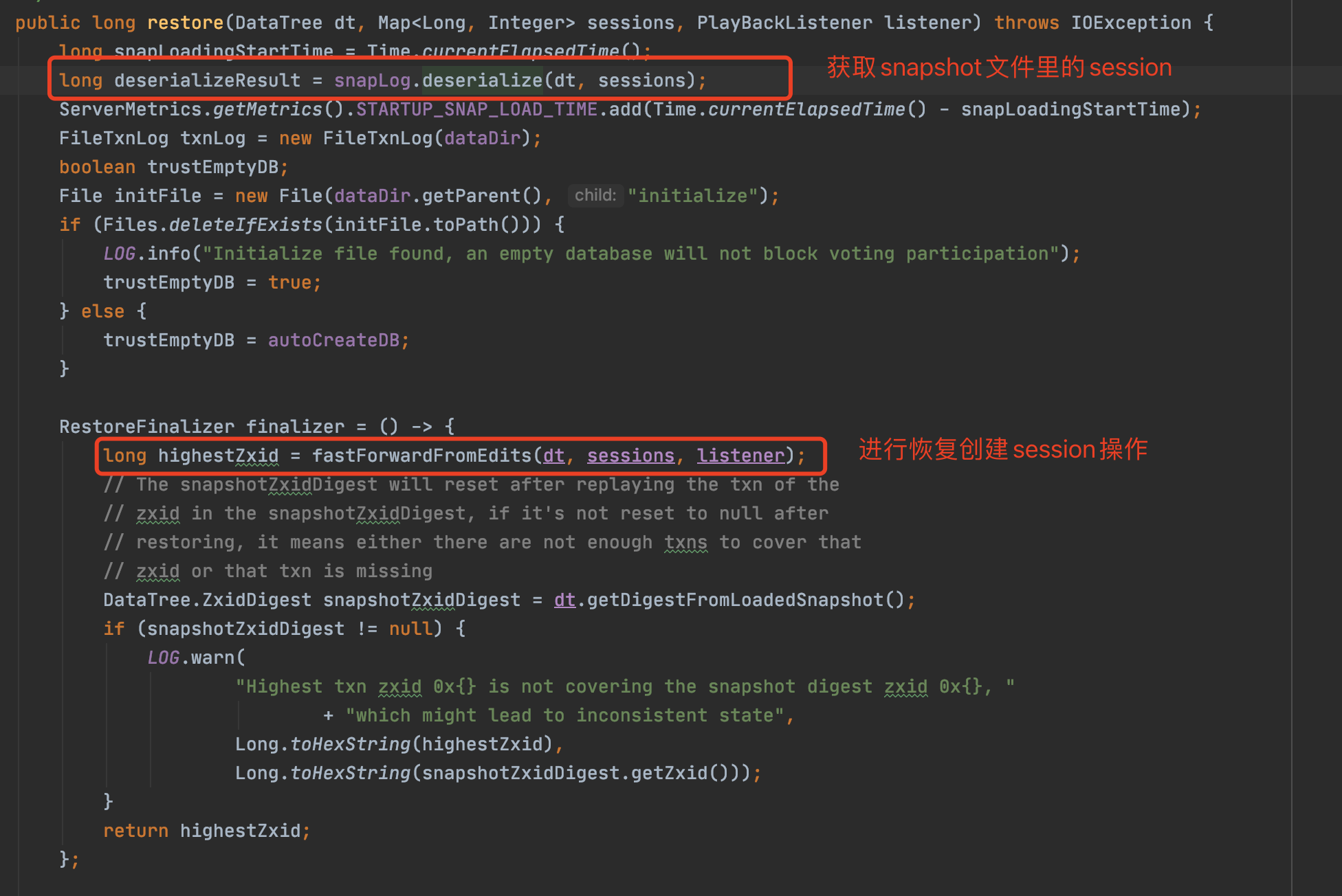
反序列化最近的snapshot檔案,並讀取session恢復到本地記憶體:
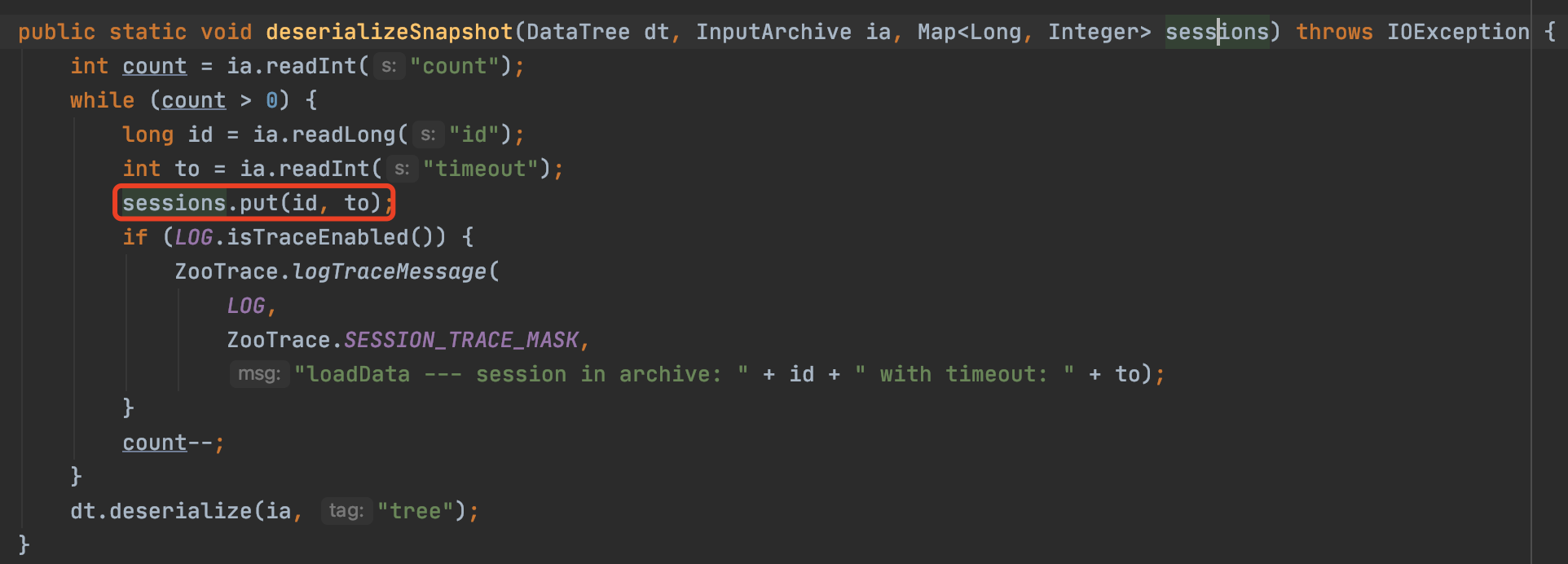
進行session恢復(建立)操作,預設session timeout 40s:
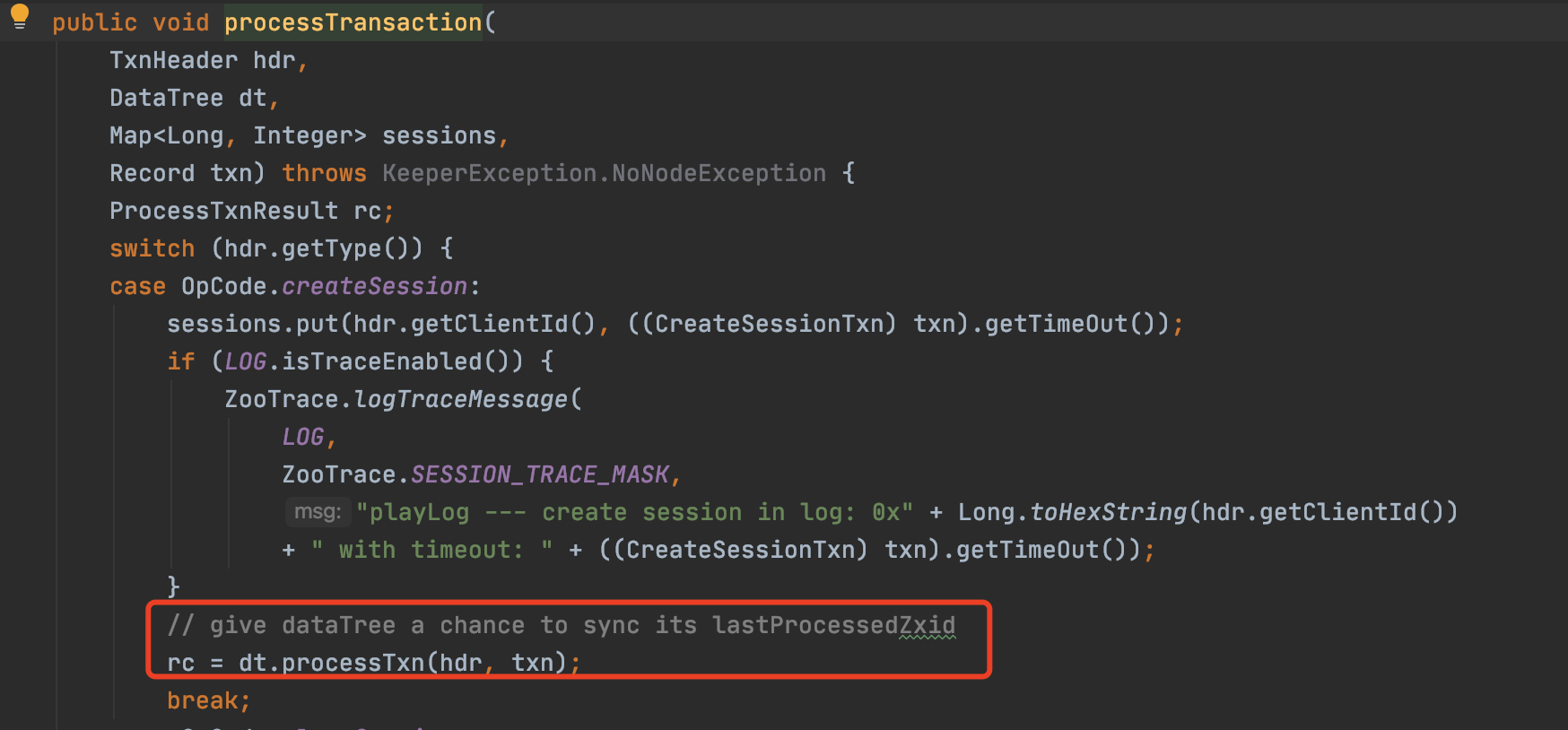
2)而此時使用者端session早已經過期,帶著空sessionid 0x0進行重連,獲得新sessionId。但是此時RPC框架在臨時節點註冊失敗後吞掉了伺服器端返回的NodeExistsException,被認為是重新建立成功,所以只建立了一次。
3)zk叢集恢復後經過40s最終因為伺服器端session過期,將過期sessionId和及其繫結的臨時節點進行了清除。
4)consumer監聽到 節點移除 的空列表,清空了本地provider列表。故障發生了。
5、解決方案
經過上面的原始碼分析和解答,解決方案有兩種:
方案1:使用者端(curator)設定session過期時間更長或者不過期,那麼叢集恢復後的前40s,使用者端帶著原本的sessionid跟伺服器端做一次請求,就自動續約了,不再過期。
方案2:使用者端session過期後,帶著空sessionid 0x0進行重連的時候,對NodeExsitException做處理,進行 刪除-重新增 操作,保證重連成功。
於是我們調研了一下業界使用zk的開源微服務架構是否支援自愈,以及如何實現的:
dubbo採用了方案2。
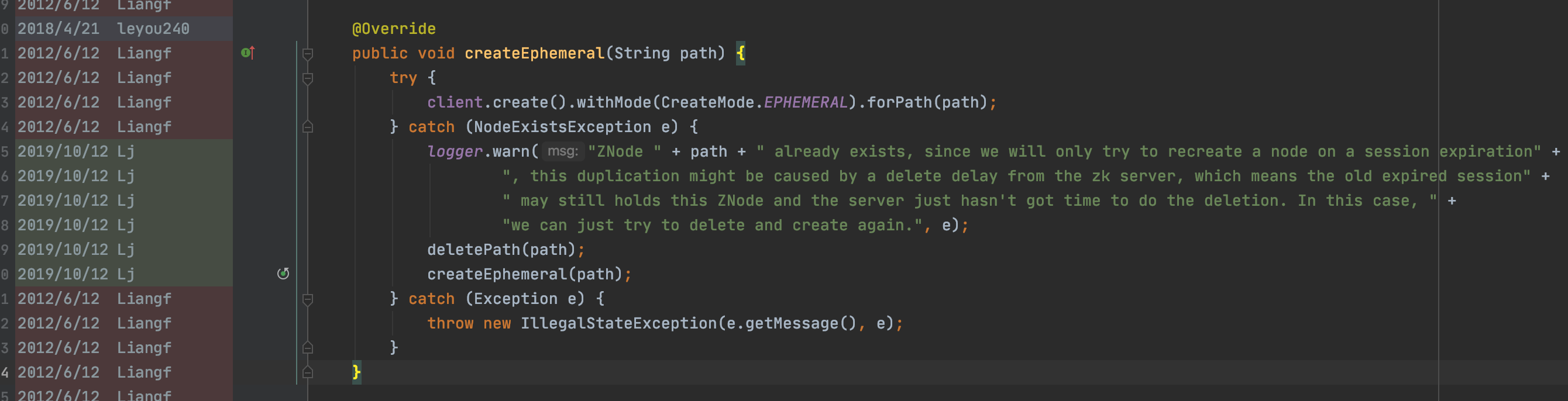
註釋也寫的非常清楚:
「ZNode路徑已經存在,因為我們只會在對談過期時嘗試重新建立節點,所以這種重複可能是由zk伺服器的刪除延遲引起的,這意味著舊的過期對談可能仍然儲存著這個ZNode,而伺服器只是沒有時間進行刪除。在這種情況下,我們可以嘗試刪除並再次建立。」
看來dubbo確實後續也考慮到這個邊界場景,防止踩坑。
所以最後我們的解決方案也是借鑑dubbo fix的邏輯,進行節點的替換:先deletePath再createPath,這麼做的原因是將zk伺服器端記憶體維護的過期sessionId替換新的sessionId,避免後續zk清理老sessionId時將所有繫結的節點刪除。
6、最佳實踐
回顧整個故障,我們其實還忽略了一點最佳實踐。
除了優化對異常的捕獲處理外,RPC框架對註冊中心的空地址推播也應該做特殊判斷,用業界的專業名詞來說,就是「推空保護」。
所謂「推空保護」,就是在服務發現監聽獲取空節點列表時,維持本地服務發現列表快取,而不是清空處理。
這樣可以完全避免類似問題。
都看到最後了,原創不易,點個關注,點個贊吧~
文章持續更新,可以微信搜尋「阿丸筆記 」第一時間閱讀,回覆【筆記】獲取Canal、MySQL、HBase、JAVA實戰筆記,回覆【資料】獲取一線大廠面試資料。
知識碎片重新梳理,構建Java知識圖譜:github.com/saigu/JavaK…(歷史文章查閱非常方便)