太坑了吧!一次某某雲上的redis讀超時排查經歷
一次排查某某雲上的redis讀超時經歷
效能排查,服務監控方面的知識往往涉及量廣且比較零散,如何較為系統化的分析和解決問題,建立其對效能排查,效能優化的思路,我將在這個系列裡給出我的答案。
問題背景
最近一兩天線上老是偶現的redis讀超時報警,並且是業務低峰期間,甚是不解,於是開始著手排查。
以下是我的排查思路。
排查思路
查閱 redis 慢查詢紀錄檔
既然是redis超時,首先想到的還是 對於redis的操作命令存在慢查詢導致的。
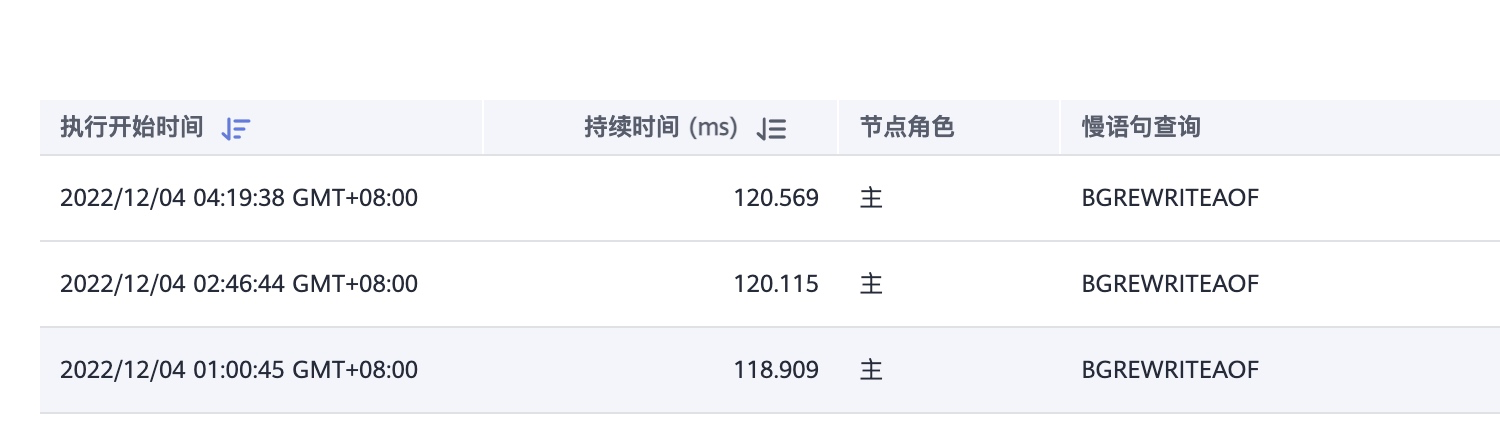
redis的慢查詢閾值是10ms,唯一的慢查詢是備份時的bgrewriteaof語句,並不是業務命令,既然從慢查詢很紀錄檔看不出端倪,那就從redis伺服器本身查詢問題,所以我又去看了redis服務機器的各項硬體指標。
檢查 報警期間 redis 各項負載指標
看了下各項監控指標,cpu,記憶體,qps等等,毫無意外的正常。(這裡就不放圖了,應為太正常了,分析意義不大)
既然伺服器端看不出毛病,那是不是使用者端的問題,於是我又去檢查了我們ecs伺服器這邊機器的情況。
檢查報警期間 ecs伺服器的各項指標資料
cpu,記憶體,頻寬等等也是正常且處於較低水平。
排查到這裡,重新思考慢查詢紀錄檔究竟是什麼?
慢查詢記錄的真的是redis命令執行的所有時間嗎?redis命令完整的執行過程究竟是怎樣的?
慢查詢紀錄檔僅僅是記錄了命令的執行時間,而整個redis命令的生命週期是這樣。
使用者端命令傳送->redis伺服器接收到命令,放入佇列排隊執行->命令執行->返回給使用者端結果
那麼有沒有辦法監控到redis的延遲呢?如何才能知道redis的命令慢不是因為執行慢,而是這個過程當中的其他流程慢導致的呢?
redis 提供了監控延遲的工具
開啟延遲,設定延遲閥值
CONFIG SET latency-monitor-threshold 100
查閱延遲原因
latency latest
但是這個工具真正實踐起來的效果並不能讓我滿意,因為似乎他並不能把網路因素考慮其中,實踐起來的效果它應該是隻能將命令執行過程中可能導致延遲的原因分析出來,但是執行前以及執行後的命令生命週期的階段並沒有考慮進去。
當我開啟這個工具監控線上redis情況,當又有讀超時出現時,latency latest 並沒有返回任何延遲異常。
再思考究竟讀超時是個什麼問題?
使用者端發出去了命令,然後阻塞等待redis伺服器端讀的結果,如果沒有結果返回,就會觸發讀超時發生。在go裡面程式碼是如何實現的。
我們用的redis使用者端是go-redis
func (c *baseClient) pipelineProcessCmds(cn *pool.Conn, cmds []Cmder) (bool, error) {
err := cn.WithWriter(c.opt.WriteTimeout, func(wr *proto.Writer) error {
return writeCmd(wr, cmds...)
})
if err != nil {
setCmdsErr(cmds, err)
return true, err
}
// 看到將讀取操作用WithReader裝飾了一下
err = cn.WithReader(c.opt.ReadTimeout, func(rd *proto.Reader) error {
return pipelineReadCmds(rd, cmds)
})
return true, err
}
讀取redis伺服器端響應的方法 是用cn.WithReader進行了裝飾。
// 讀取之前設定了超時時間
func (cn *Conn) WithReader(timeout time.Duration, fn func(rd *proto.Reader) error) error {
_ = cn.setReadTimeout(timeout)
return fn(cn.rd)
}
而cn.WithReader 裡,首先便是設定此次讀取的超時時間。如果在規定的超時時間內,需要讀取的結果沒有全部返回也會導致讀超時的發生,那麼會不會是由於返回結果過多導致讀取耗時驗證呢?
具體的分析了下報警出錯的命令,有些命令比如set命令不需要返回結果都有超時的情況,所以排除掉了返回結果過大的問題。
再次深入思考golang 裡的讀超時觸發過程
go協程在碰到網路讀取時,協程會掛起,等待網路包到達後,由go runtime喚醒協程,然後協程繼續進行讀取操作,當喚醒時會檢查超時時間,如果到達了超時限制,那麼將直接報讀超時錯誤。(有機會可以詳細分析下golang的netpoll原始碼) 原始碼如下,
src/runtime/netpoll.go:303
for !netpollblock(pd, int32(mode), false) {
errcode = netpollcheckerr(pd, int32(mode))
if errcode != pollNoError {
return errcode
}
// Can happen if timeout has fired and unblocked us,
// but before we had a chance to run, timeout has been reset.
// Pretend it has not happened and retry.
}
netpollblock 不阻塞協程時,首先執行了netpollcheckerr,netpollcheckerr檢查是否有超時情況發生。
從喚醒到協程被排程執行的這個時間稱為協程的排程延遲,如果這個延遲過高,那麼是有可能發生讀超時的。
於是我又看了go程序中協程的排程延遲,在golang裡 內建了一個/sched/latencies:seconds 指標,代表協程排程延遲,目前的prometheus client 已經對這個指標進行了相容,所以我們是直接利用它 將延遲耗時在grafana裡進行了展示。
超時期間,grafana裡的 協程排程延遲只有幾毫秒。而超時時間設定的200ms,顯然也不是協程排程延遲的問題。
用上終極武器-抓包
以上的思路都行不通了,所以只能用上終極武器,抓包。 看看觸發200ms超時時 究竟是哪些包沒有到達。因為只能在使用者端測抓包,所以接下來的抓包檔案都是使用者端測的抓包。
很對時候抓包都是解決問題特別是網路問題的最終手段,你能通過抓包清楚的看到使用者端,伺服器端在做什麼事情。
為了百分百確認並且定位問題,我一共抓取了3個檔案,首先來看下第一個檔案。
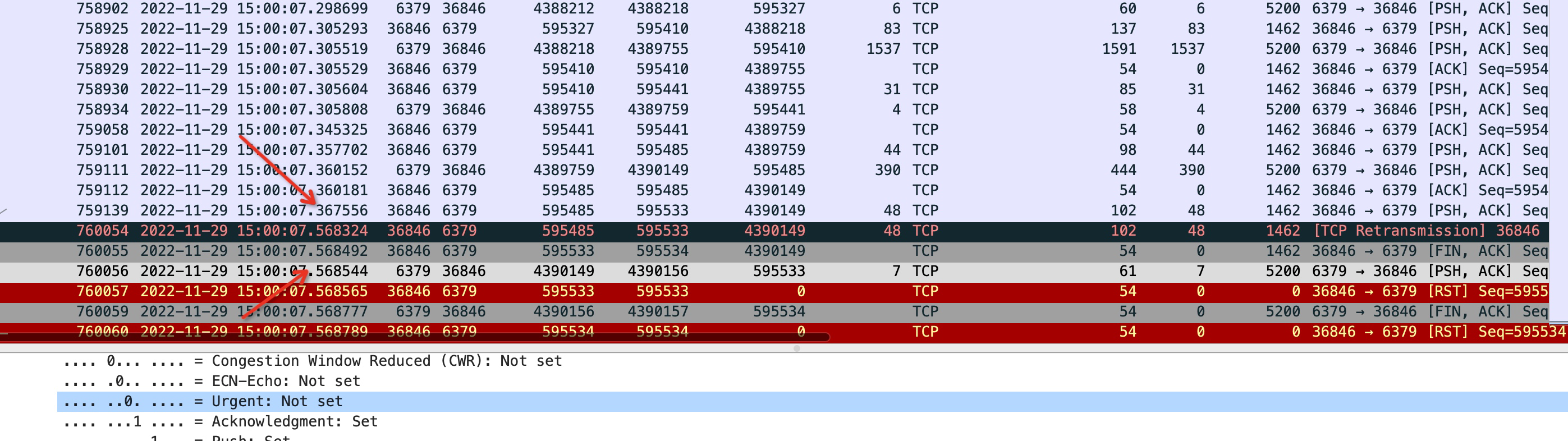
6379埠號是目的埠,也就是redis的埠,36846是我使用者端的埠。
從抓包檔案中,發現760054號報文發生了超時重傳,如果使用者端發了包,但是伺服器端沒有迴應ack訊息就會觸發超時重傳,重傳之後,使用者端也沒有收到伺服器端的訊息,並且可以看到傳送揮手訊號和前一個正常傳送的包之間剛好是隔了差不多200ms,而200ms正是使用者端設定的超時時間,應用層觸發超時後,將呼叫close方法關閉連結,所以在760055號包裡 使用者端傳送了一個fin 揮手訊號代表使用者端要關閉連結了。 使用者端傳送fin訊號揮手之後呢,伺服器端才發來攜帶資料的ack訊息,不過由於此時使用者端已經處於要關閉狀態,所以直接傳送rst訊號了。
整個發包和接包流程可以用下面的流程圖來展示。

接著來看第二個抓包檔案。
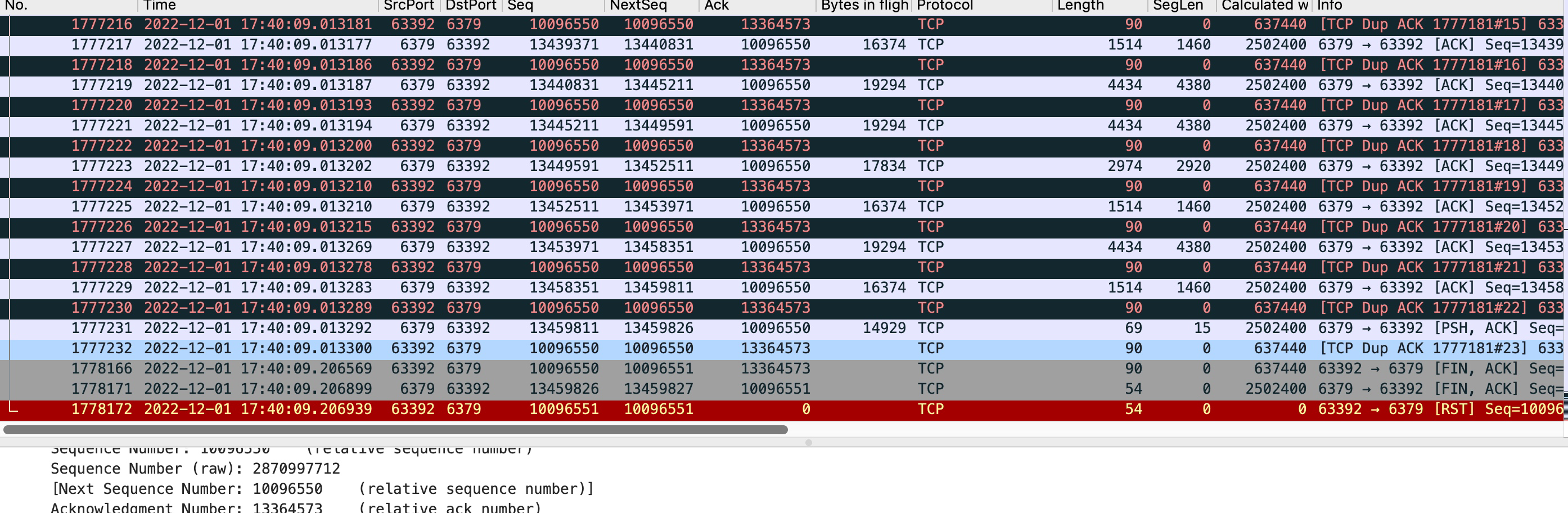
抓包中出現大量TCP Dup Ack 的訊息,使用者端一直在向埠為6379的伺服器端傳送ack的序號為 13364573,代表使用者端已經接收到伺服器端序號13364573之前的包了,然而伺服器端連續傳送的包序號seq都大於了13364573 ,所以使用者端認為伺服器端序號seq是13364573的包丟了,所以隨著伺服器端每一次傳送訊息過來,都告訴伺服器端,我應該接收序號是13364573開始的包,趕緊傳送過來。
最終在1777232號包,使用者端又一次傳送了TCP Dup Ack 訊息,催促伺服器端趕緊把丟掉的包發過來,不過這次伺服器端連回應都不迴應了,最終觸發了使用者端應用層200ms的超時時間,呼叫close方法關閉了連線。所以在1778166號包裡,可以看到使用者端傳送fin揮手訊號,1778166 號包的傳送時間和1777232號包的傳送時間正式相隔了200ms。
整個發包和接包流程可以用下面的流程圖來展示。

再來看第三個抓包檔案,第三個抓包檔案是我將使用者端超時時間設定為500ms後出現超時情況時抓到的。

首先看第一個紅色箭頭處,也就是911752號包,它被wireshark標記為 Tcp Previous segment not captured,表示這個包之前的包沒有被捕獲到,說明這個包seq序號之前的包存在丟包情況。發現它前一個包也就是911751號包也是伺服器端發來的包,並且next seq 是18428124,說明911751號包下一個包的seq應該是18428124,但是911752的seq是18429584,進一步說明 來自伺服器端的包序號在18428124到18429584之間的包存在丟包情況。
接著是使用者端對911751號包的ack訊息,說明序號是18428124之前的包已經全部接收到。然後接受到了911754號這個來自伺服器端的包,並且這包的開始seq序號是18433964,而最近一次來自伺服器端的911752號包的next seq是18432504,說明在18432504 和18433964之間,也存在伺服器端的丟包情況,所以911754號包也被標記為了Tcp Previous segment not captured。
接下來就是伺服器端重傳包,使用者端繼續迴應Ack的過程,但是這個過程直到914025號時就停止了,因為整個讀取伺服器端響應的過程從開始讀 到當前時間已經達到了應用層設定的500ms,所以在應用層直接就關閉掉了這個連結了。
看到現在,我有了充足的理由相信,是雲服務提供商那邊的問題,中間由於網路丟包的原因,且延遲較大導致了redis的讀超時。拿著這些證據也說服了他們,並最終圓滿解決。
提工單,雲服務商的排查支援
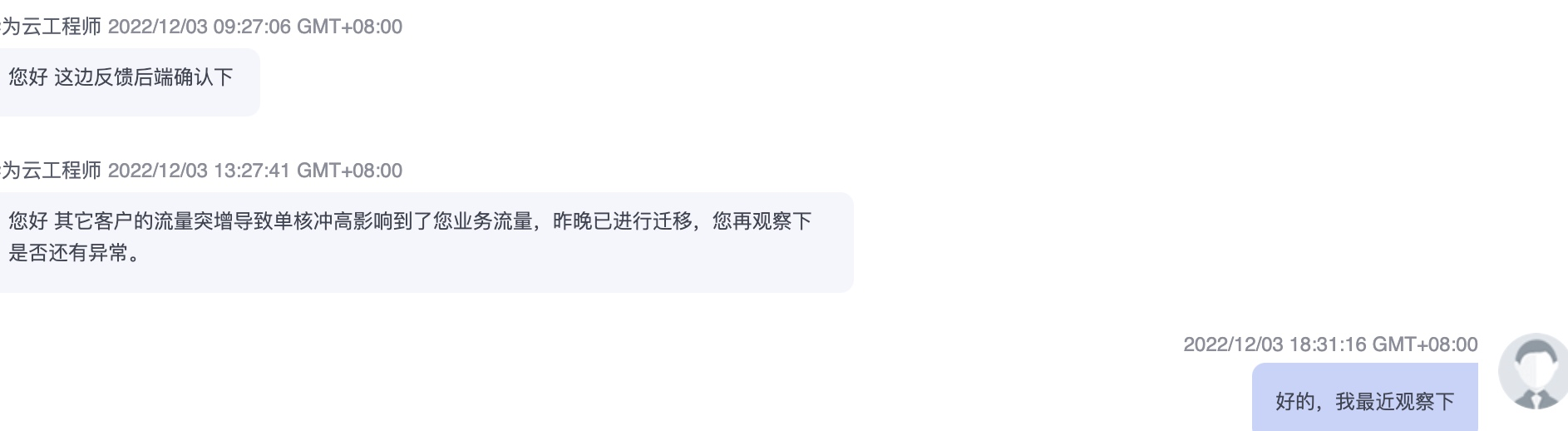
圓滿解決