Redis 是記憶體資料庫,高效使用記憶體對 Redis 的實現來說非常重要。
看一下,Redis 中針對字串結構針對記憶體使用效率做的設計優化。
一、SDS的結構
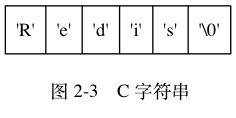
c語言沒有string型別,本質是char[]陣列;而且c語言陣列建立時必須初始化大小,指定型別後就不能改變,並且字元陣列的最後一個元素總是空字元 '\0' 。
以下展示了一個值為 "Redis" 的 C 字串:
Redis沒有直接使用C語言的字串方式,而是構建了一種簡單動態字串(Simple dynamic string, SDS)的型別,Redis中的字串底層都是使用SDS結構進行儲存,比如包含字串的鍵值對底層都是使用SDS結構實現的。
SDS結構定義在sds.h中
struct sdshdr{
int len;//SDS儲存的字串長度
int free;//buf陣列中未使用位元組數量
char buf[];//字元陣列,儲存字串
}
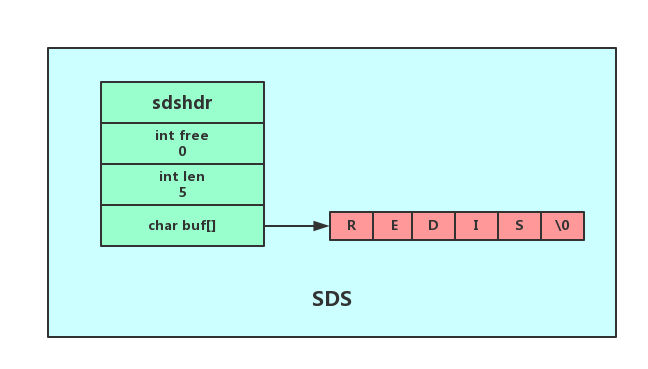
最後一個位元組儲存了空字元'\0',保留了C字串的規範,使得SDS結構的字串,可以重用一部分C函數庫的函數。
二、為什麼不使用C字串
主要是因為C字串有以下缺點:
- 獲取字串長度時間複雜度為O(N):C字串獲取長度需遍歷整個字串,遇到'\0'空字元為止。
- 緩衝區溢位:比如在進行字串追加操作時,如果沒有分配足夠的記憶體,就會造成記憶體溢位。
- 記憶體重分配:每次增長或者截短字串,程式都要對儲存C字串的陣列進行記憶體重分配操作,而記憶體重分配涉及複雜的演演算法,並可能需要執行系統呼叫,所以它通常比較耗時。
- 空字元問題:C字串中間不能儲存空格,否則程式遍歷是會誤認為是字串的末尾。這一限制導致C字串只能儲存文字資料,不能儲存像圖片、音視訊、壓縮檔案等二進位制資料。
三、怎樣解決C字串問題
1、SDS通過len屬性記錄了SDS長度,所以獲取長度的時間複雜度為O(1),即strlen命令的時間複雜度是O(1)。
2、SDS空間分配策略避免了緩衝區溢位:當對SDS進行修改時,會先檢查SDS空間是否滿足修改,不滿足會自動擴充套件到所需大小,然後才執行修改。
3、較少修改字串時記憶體重分配次數:SDS中的free記錄buf位元組陣列中未使用的位元組。
redis通過free屬性實現空間預分配、惰性空間釋放兩種優化策略。
- 空間預分配:當對SDS進行增長操作時,程式不僅會分配修改所必須得空間,還會為SDS分配額外的未使用空間。通過預分配策略,減少了連續執行字串增長操作時記憶體重分配次數。
- 惰性空間釋放:當對SDS進行截短操作時,程式並不會立即回收縮短後多出來的位元組所佔用的記憶體,而是使用free屬性記錄多出來的位元組數,以供將來使用。如果將來要對這個SDS進行增長操作,未使用空間可能就派上用場,並且增長操作也不一定會執行記憶體重分配。
SDS結構中的buf位元組陣列,是二進位制安全的,不僅可以儲存字元,也可以儲存二進位制資料。
SDS保留了C字串的慣例,將資料的末尾設定為空字元'\0',SDS中之所以保留這一規範是可以重用C字串函數庫的一部分函數,例如追加字串。
四、對字串的進一步優化
Redis string的三種編碼:
- int 儲存8個位元組的長整型(long,2^63-1 )
- embstr, embstr格式的SDS (Simple Dynamic String)
- raw, raw格式的SDS,儲存大於44個位元組的長字串
int型別就是指的是數位,那麼raw、embstr都代表的是字串有什麼異同嗎,下面我們分析下。
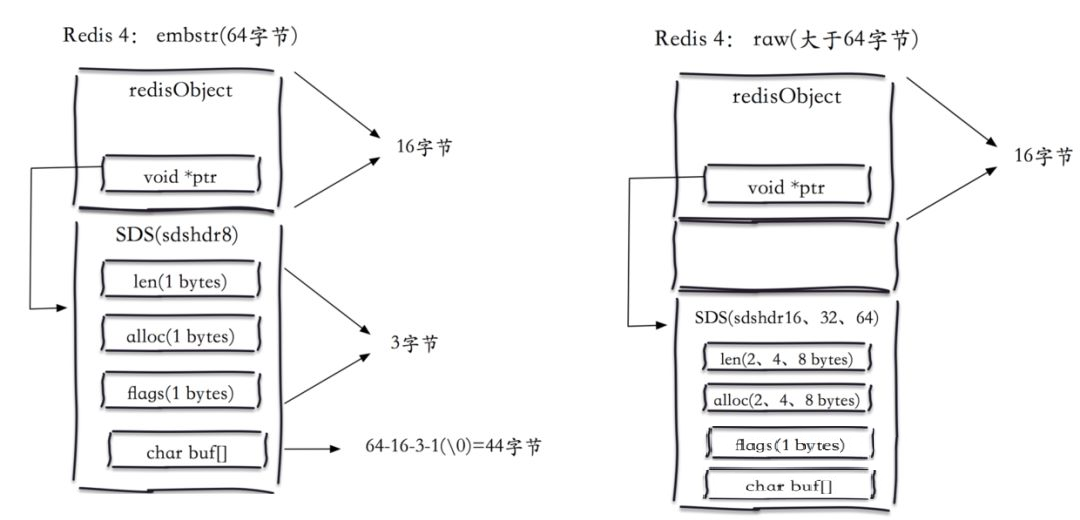
圖中展示了兩者的區別,可以看到embstr將redisObject和SDS儲存在連續的64位元組空間內,這樣可以只需要一次記憶體分配,而對於raw來說,SDS和redisObject分離,需要兩次記憶體分配,而且佔用更多的記憶體空間。

可以看到embstr在3.2+中使用了叫sdshdr8的結構,在該結構下,後設資料只需要3個位元組,而Redis需要8個位元組,所以總共64個位元組,減去redisObject(16位元組),再減去SDS的原資訊,最後的實際內容就變成了44位元組和39位元組。
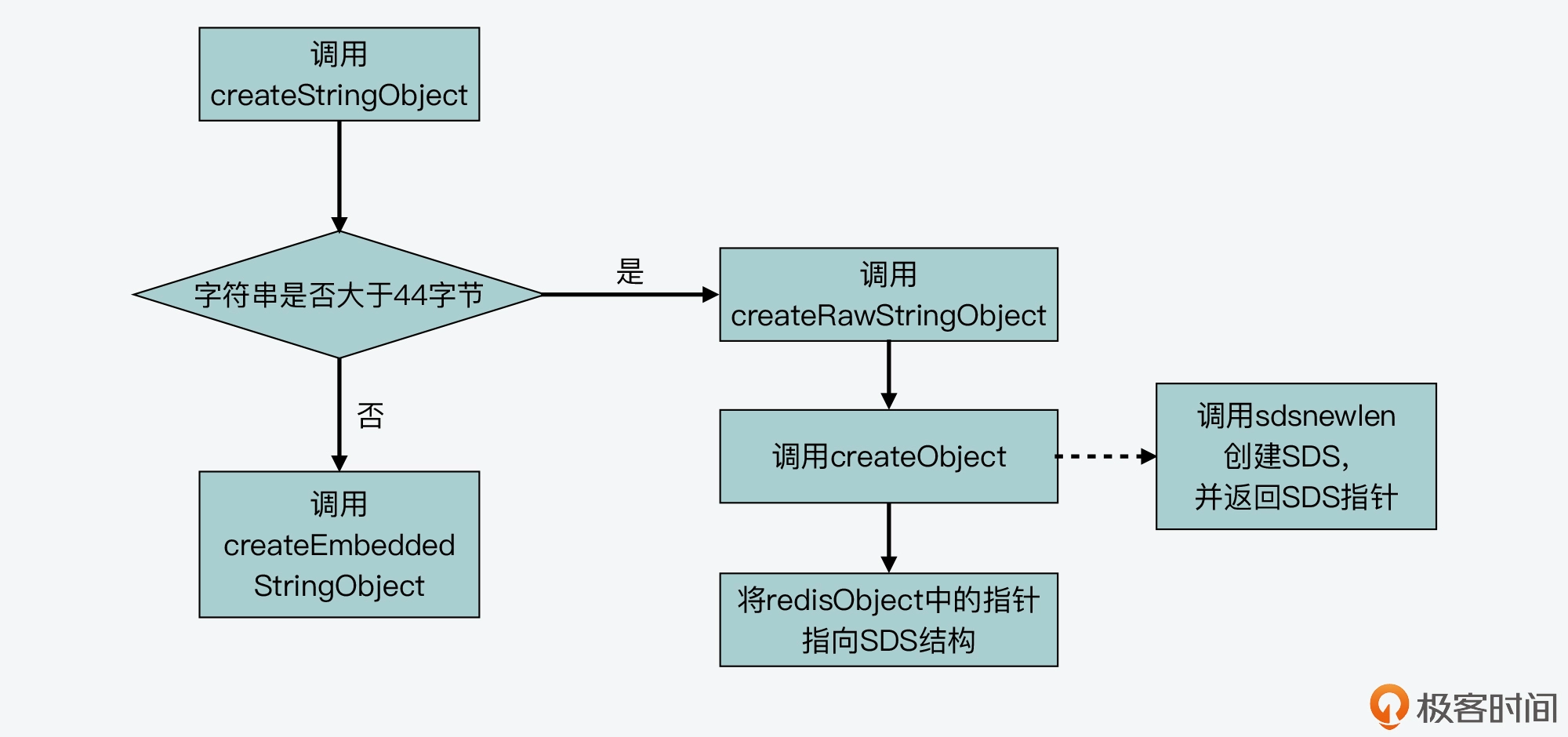
當字串小於等於 44 位元組時,Redis 就使用了嵌入式字串的建立方法,以此減少記憶體分配和記憶體碎片。
下面這張圖展示了 createEmbeddedStringObject 建立嵌入式字串的過程:
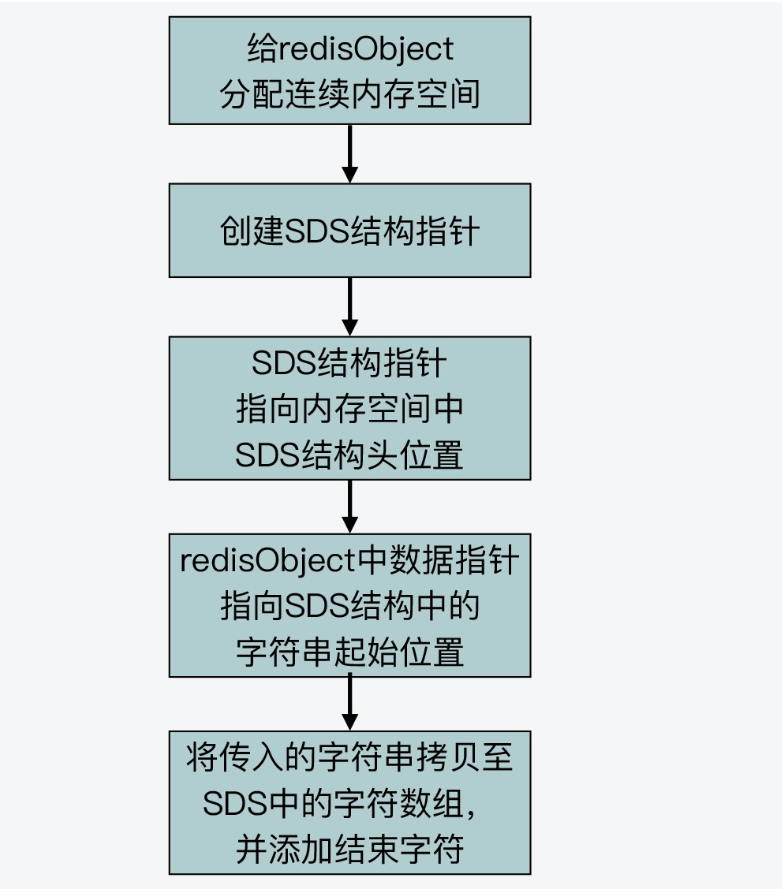
總之,只要記住,Redis 會通過設計實現一塊連續的記憶體空間,把 redisObject 結構體和 SDS 結構體緊湊地放置在一起。
這樣一來,對於不超過 44 位元組的字串來說,就可以避免記憶體碎片和兩次記憶體分配的開銷了。