解密prompt系列5. APE+SELF=自動化指令集構建程式碼實現
上一章我們介紹了不同的指令微調方案, 這一章我們介紹如何降低指令資料集的人工標註成本!這樣每個人都可以構建自己的專屬指令集, 哈哈當然我也在造資料集進行時~
介紹兩種方案SELF Instruct和Automatic Prompt Engineer,前者是基於多樣的種子指令,利用大模型的上下文和指令理解能力,以及生成的多樣性來Bootstrap生成更多樣的指令樣本,後者是prompt逆向工程,基於輸入和輸出,使用LLM來生成和挑選最優的prompt指令。
於是我把這兩個方法強行組了CP,用APE把原始任務轉化成種子指令,再用SELF去擴充,在醫學和金融NLP任務上進行了嘗試。也在huggingface上用gradio做成了視覺化的應用, 有API Key的盆友可以自己嘗試下效果:https://huggingface.co/spaces/xl2533/MakeInstruction ,記得fork到自己的space再嘗試喲~
Automatic Prompt Engineer(APE)
- paper: 2023.3, LARGE LANGUAGE MODELS ARE HUMAN-LEVEL PROMPT ENGINEERS
- github: https://github.com/keirp/automatic_prompt_engineer
- 一語道破天機: prompt逆向工程,根據輸入和輸出讓模型生成並尋找更優的prompt

指令生成
這裡作者基於原始的輸入+輸出,部分樣本只有輸出,例如自由生成類的任務,來讓大模型預測,原始指令是什麼。作者把指令生成的模板分成了3類,不過個人感覺其實只要一類即可,就是few-shot樣本在前,待生成的指令在最後的向前生成型別,如下圖

我又取樣了兩條樣本如下,模型預測:"將公司公告或新聞標題簡化成簡短的標題,包括公司名稱和主要內容"

哈哈預測的指令確實都沒毛病,只不過都是相似新聞標題生成的子集,所以你需要根據任務輸入輸出的多樣性程度來調整你的few-shot樣本數,多樣性越高你需要的few-shot樣例越多
- 構建指令樣本,說人話很重要
例如我把以上的相似標題生成任務,簡化成了判斷兩個標題是否描述同一事件的分類任務。最初我的輸入如下。看起來也沒毛病是不是?然模型的預測是:"我無法確定這個任務指令的具體內容,但它可能與文字分類或者自然語言處理相關。給出輸入文字,需要判斷該文字是否符合某種特定的模式或標準,從而得出輸出結果"
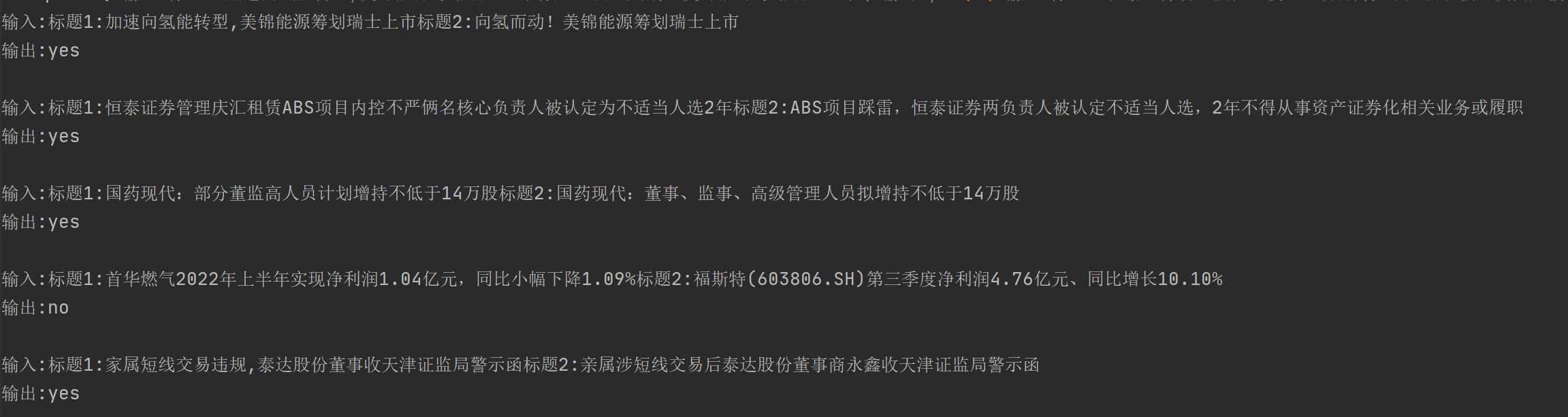
但是當我把樣本中的輸出改成符合任務語意的相同/不相同時,模型預測是:"判斷兩個新聞標題是否相同,如果相同輸出"相同",否則輸出"不相同"

當然考慮生成模型解碼的隨機性,我在第一類樣本構建上多次取樣也得到了類似相似度判斷的指令,但整體效果都差於下面的構建方式,所以和MRC構建很相似,一切以符合語意為第一標準
- 不要你以為,要模型以為!
最初我對這種機器生成指令的方式是不太感冒的,但是在醫學術語標準化這個任務上,我對比了APE得到的最優指令,和我人工寫的指令,在單測時確實是模型指令,得到正確答案的概率更高。所以我大膽猜測,因為模型之間的一致性,所以合理使用模型生成的指令,能提供更精準的上下文任務描述,且理論上都應該不差於人類指令。
指令打分
這裡作者使用了兩種打分方式,來評估多組樣本生成的多個候選指令的優劣
- Accuracy:使用模型預測的正確率,例如對於QA問題,根據不同指令在相同樣本上模型回答的準確率來評價指令的效果。
- Log Probability:使用模型預測的logprobs作為評價指標。注意這個指標有些tricky,我最初認為和上面的Accuracy一樣是讓模型去預測,把預測正確的token的logprobs求和。後來發現是把輸入+輸出+指令都餵給模型,計算模型生成原始輸出的概率,很好解決了生成類任務解碼隨機不同指令無法比較的問題。
如何調openai介面獲取輸入的logprobs:
把echo=True,logprobs=1, 就能返回所有取樣token的logprobs,logprobs取值對應TopN的返回,openai最多隻給你返回Top5 token,包括實際被取樣的token。max_tokens=0, 不讓模型生成新的文字,就可以讓模型原樣返回我們喂進去的輸入,以及對應的模型計算的每個token的條件概率啦
同時作者加入了隨機搜尋,既對模型生成的指令,過濾低分的部分,對於高分的指令集,讓模型基於以下指令模板,為高分指令生成相似的指令,和原始生成的指令一起排序選出最優指令。
這塊實現時,我把相似指令的部分拿掉了,改成人工加入,針對得到的高分指令,補充上自己認為缺少核心的資訊後使用log prob的打分方式來評估是否有提升。所以應用裡,我把Generated Prompt的視窗改成了可互動的,可以直接對生成的指令做修改,再Eval效果即可。
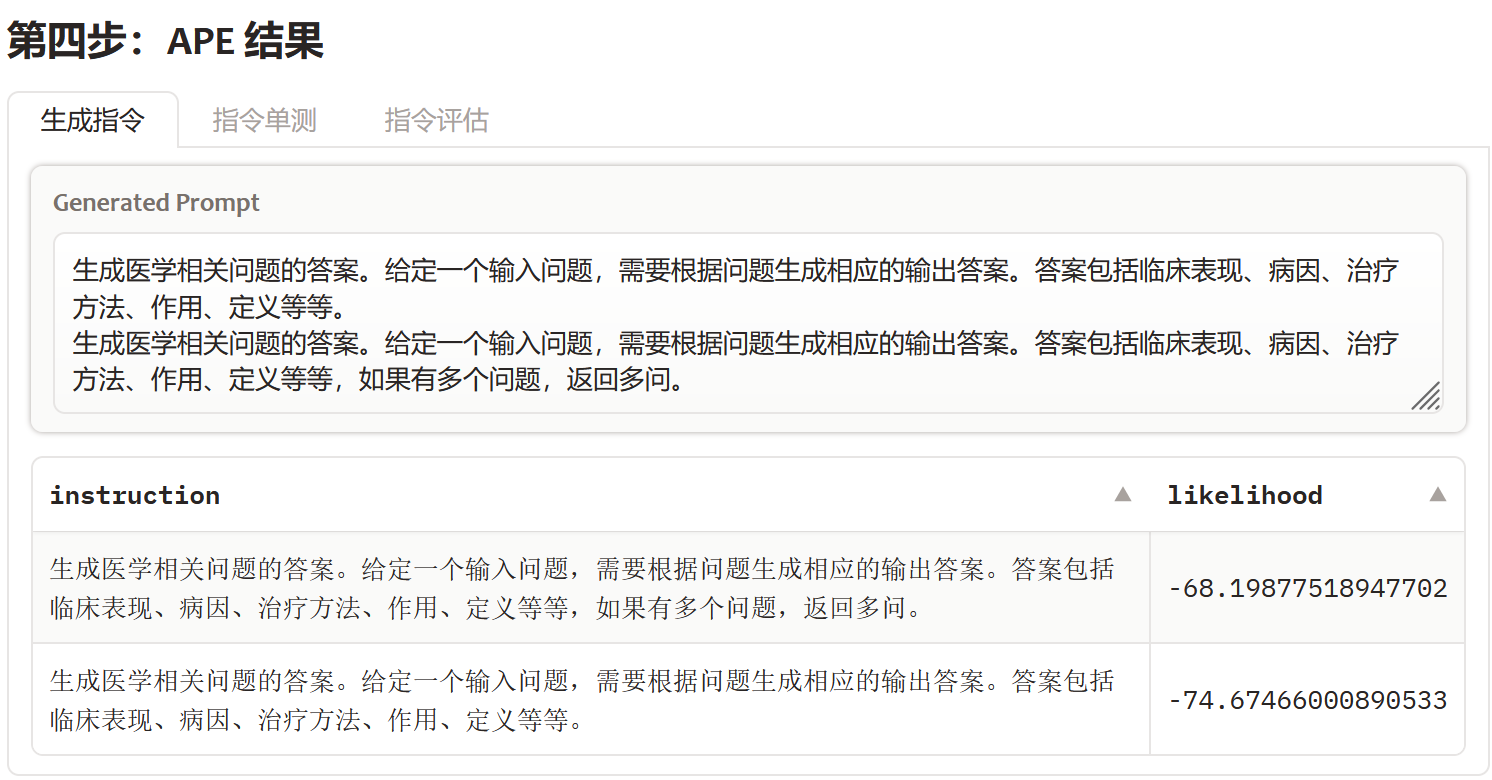
例如在醫療搜尋意圖的任務上,很明顯模型無法理解"多問"標籤是啥意思,所以最初多組樣本得到的最優指令是下圖的第二個,而我人工加入"多問"的指令後,得到了效果更好的第一個指令
效果
這裡作者使用了REF[1]裡面使用的24個指令任務,每類任務挑選5對樣本,使用以上的方案得到最優的指令,再在剩餘樣本上,和人工指令以及REF[1]論文中使用的方案(沒有搜尋和打分排序的APE)以下稱為greedy,進行效果對比。APE的效果在24個任務上基本可以打平人工模板甚至在部分任務上還要超越人工指令。在BigBench這類難度更高的樣本上,APE在17(共21)個任務上也超越了人工指令的效果。
我在4個醫學資料集上APE+人工優化得到的最優指令如下
| 任務 | 指令 |
|---|---|
| 搜尋意圖 | 生成醫學相關問題的答案。給定一個輸入問題,需要根據問題生成相應的輸出答案。答案包括臨床表現、病因、治療方法、作用、定義等等,如果有多個問題,返回多問 |
| 醫療術語標準化 | 將醫學手術名稱的術語表述標準化。輸入是醫學手術的名稱,輸出是對該手術的名稱進行修正、標準化,以供醫學專業人員更好地理解 |
| 醫療藥物功能實體抽取 | 給定藥品資訊和用途說明,根據用途說明提取出藥品的主治功能。 |
| 醫療文獻QA生成 | 訓練一個問答系統,給定一些醫學文字,能夠回答使用者提問關於該文字內容的問題。每個輸入-輸出對是一組文字和對應的問題及答案。輸出的形式是以下Json格式{"問題":\(問題, "回答":\)回答} |
以醫學術語標準化為例我簡化了APE提供的gradio應用,效果如下

SELF-Instruct
- paper: 2022.12, SELF-INSTRUCT: Aligning Language Model
with Self Generated Instructions- https://github.com/yizhongw/self-instruct
- https://github.com/tatsu-lab/stanford_alpaca
- 一語道破天機:類似非線性插值,通過LLM的生成多樣性做Bootstrap對種子指令集進行不定向擴充

上一步我們依賴APE得到了種子指令集,但是豐富度和多樣性是遠遠不夠的。這裡SELF提出了一種Bootstrap方案來讓LLM基於種子指令生成新的指令的指令擴充方案。這個方案也後續被用於Alpaca專案中生成微調指令集,主要包括以下3個步驟
1. 新指令生成
首先作者人工構建了175個種子指令,這些種子指令由1條指令和1個樣本構成。每個Step作者會從中取樣8個指令,其中6個來自以上種子,2個來自LLM生成的指令,當然step1全部都是種子指令。然後基於如下的prompt模板構建模型輸入
"""
Come up with a series of tasks:
Task 1: {instruction for existing task 1}
Task 2: {instruction for existing task 2}
Task 3: {instruction for existing task 3}
Task 4: {instruction for existing task 4}
Task 5: {instruction for existing task 5}
Task 6: {instruction for existing task 6}
Task 7: {instruction for existing task 7}
Task 8: {instruction for existing task 8}
Task 9:
"""
如果你看著這個模板,感覺和ChatGPT的模板格格不入,那就對了。因為作者是基於GPT3實現的,就是那個天真的續寫模型。
而Alpaca專案在使用SELF構建指令樣本時升級到了davinci-003模型,因為模型可以更好的理解指令,因此以上純few-shot的prompt模板也改成了如下(用ChatGPT翻成了中文),同時輸入的few-shot數量縮減到了3個
"""
你需要想出20個不同的任務指令。這些任務指令將輸入GPT模型,我們將評估GPT模型完成指令的情況。
以下是要求:
1. 儘量不要在每個指令中重複使用動詞,以最大化多樣性
2. 指令的表達形式需要多樣化。例如你可以把問題和祈使句結合起來
3. 指令的型別應該多樣化,包括但不限於開放式生成、分類、抽取、問答、文字編輯等等
4. 指令應該是GPT模型可以完成的任務。例如,指令不能是輸出影象或者視訊,另一個例子,不要讓助手在下午5點叫醒你或設定提醒,因為GPT不能執行任何動作
5. 指令必須是中文
6. 指令應該是1到2句話,可以是祈使句或問句。
20個任務的列表:
"""
我第一遍讀完SELF是一腦門子問號

大致就是這麼多,感興趣的盆友們一起玩起來(造資料的痛苦見者有份)~

更多Prompt相關論文·教學,開源資料·模型,以及AIGC相關玩法戳這裡DecryptPrompt
Reference
- Instruction induction: From few examples to natural language task descriptions.
- Fairness-guided Few-shot Prompting for Large Language Models
- Flipped Learning: Guess the Instruction! Flipped Learning Makes Language Models Stronger Zero-Shot Learners