機器學習(四):4層BP神經網路(只用numpy不調包)用於訓練鳶尾花資料集|準確率96%
題目:
-
設計四層BP網路,以g(x)=sigmoid(x)為啟用函數,
-
神經網路結構為:[4,10,6, 3],其中,輸入層為4個節點,第一個隱含層神經元個數為10個節點;第二個隱含層神經元個數為6個節點,輸出層為3個節點
-
利用訓練資料iris-train.txt對BP神經網路分別進行訓練,對訓練後的模型統計識別正確率,並計算對測試資料iris-test.txt的正確率。
參考函數:
def show_accuracy(n, X, y):
h = n.test(X)
y_pred = np.argmax(h, axis=1)
print(classification_report(y, y_pred))
解:
首先題目已經給出了3行函數,我們可以進行如下拆解:
show_accuracy(n, X, y)中n代表BP神經網路模型,採用物件導向的方式編寫,X是測試資料輸入特徵X_test,y是測試資料輸出特徵y_test,h = n.test(X)的含義是呼叫訓練好的BPNN的預測方法predict,將X輸入進行前向傳播即可獲得輸出層[0,1,2]分別的概率,然後通過np.argmax(h, axis=1)取輸出層的最大概率,返回下標0,1,2,最後呼叫sklearn的分類報告方法即可列印分類準確情況。
主要程式碼如下:
匯入包及資料
import pandas
import numpy as np
from sklearn.metrics import classification_report
# 匯入txt資料
iris_train = pandas.read_table("iris/iris-train.txt", header=None)
iris_train.columns = ['SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm', 'PetalWidthCm', 'Species']
iris_test = pandas.read_table("iris/iris-test.txt", header=None)
iris_test.columns = ['SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm', 'PetalWidthCm', 'Species']
編寫識別正確率函數
def show_accuracy(self, X, Y):
count=0
Y_pred=[]
for i in range(X.shape[0]):
h=self.update(X[i, 0:4])
y_pred=np.argmax(h)
Y_pred.append(y_pred)
if y_pred==Y[i]:
count+=1
print("準確率為:",count/X.shape[0])
print(count)
print(classification_report(Y, Y_pred))
完整程式程式碼
import pandas
import numpy as np
from sklearn.metrics import classification_report
# 匯入txt資料
iris_train = pandas.read_table("iris/iris-train.txt", header=None)
iris_train.columns = ['SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm', 'PetalWidthCm', 'Species']
iris_test = pandas.read_table("iris/iris-test.txt", header=None)
iris_test.columns = ['SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm', 'PetalWidthCm', 'Species']
#打亂順序
array = iris_train.values#
np.random.seed(1377)
np.random.shuffle(array)
#獨熱編碼
def onehot(targets, num_out):
onehot = np.zeros((num_out, targets.shape[0]))
for idx, val in enumerate(targets.astype(int)):
onehot[val, idx] = 1.
return onehot.T
#生成一個矩陣,大小為m*n,並且設定預設零矩陣
def makematrix(m, n, fill=0.0):
X_train = []
for i in range(m):
X_train.append([fill] * n)
return X_train
#函數sigmoid()
def sigmoid(x):
a = 1 / (1 + np.exp(-x))
return a
#函數
def derived_sigmoid(x):
return x * (1 - x)
# return 1.0 - x ** 2
#構造四層BP網路架構
class BPNN:
def __init__(self, num_in, num_hidden1, num_hidden2, num_out):
# 輸入層,隱藏層,輸出層的節點數
self.num_in = num_in + 1 # 增加一個偏置結點 4
self.num_hidden1 = num_hidden1 + 1 # 增加一個偏置結點 4
self.num_hidden2 = num_hidden2 + 1
self.num_out = num_out
# 啟用神經網路的所有節點
self.active_in = [1.0] * self.num_in
self.active_hidden1 = [1.0] * self.num_hidden1
self.active_hidden2 = [1.0] * self.num_hidden2
self.active_out = [1.0] * self.num_out
# 建立權重矩陣
self.wight_in = makematrix(self.num_in, self.num_hidden1)
self.wight_h1h2 = makematrix(self.num_hidden1, self.num_hidden2)
self.wight_out = makematrix(self.num_hidden2, self.num_out)
# 對權值矩陣賦初值
for i in range(self.num_in):
for j in range(self.num_hidden1):
self.wight_in[i][j] = np.random.normal(0.0, pow(self.num_hidden1, -0.5)) # 輸出num_in行,num_hidden列權重矩陣,隨機生成滿足正態分佈的權重
for i in range(self.num_hidden1):
for j in range(self.num_hidden2):
self.wight_h1h2[i][j] = np.random.normal(0.0, pow(self.num_hidden2, -0.5))
for i in range(self.num_hidden2):
for j in range(self.num_out):
self.wight_out[i][j] = np.random.normal(0.0, pow(self.num_out, -0.5))
# 最後建立動量因子(矩陣)
self.ci = makematrix(self.num_in, self.num_hidden1)
self.ch1h2 = makematrix(self.num_hidden1, self.num_hidden2)
self.co = makematrix(self.num_hidden2, self.num_out)
# 訊號正向傳播
def update(self, inputs):
a=len(inputs)
if len(inputs) != self.num_in - 1:
raise ValueError('與輸入層節點數不符')
# 資料輸入輸入層
for i in range(self.num_in - 1):
# self.active_in[i] = sigmoid(inputs[i]) #或者先在輸入層進行資料處理
self.active_in[i] = inputs[i] # active_in[]是輸入資料的矩陣
# 資料在隱藏層1的處理
for i in range(self.num_hidden1):
sum = 0.0
for j in range(self.num_in):
sum = sum + self.active_in[j] * self.wight_in[j][i]
self.active_hidden1[i] = sigmoid(sum) # active_hidden[]是處理完輸入資料之後儲存,作為輸出層的輸入資料
# 資料在隱藏層2的處理
for i in range(self.num_hidden2):
sum = 0.0
for j in range(self.num_hidden1):
sum = sum + self.active_hidden1[j] * self.wight_h1h2[j][i]
self.active_hidden2[i] = sigmoid(sum) # active_hidden[]是處理完輸入資料之後儲存,作為輸出層的輸入資料
# 資料在輸出層的處理
for i in range(self.num_out):
sum = 0.0
for j in range(self.num_hidden2):
sum = sum + self.active_hidden2[j] * self.wight_out[j][i]
self.active_out[i] = sigmoid(sum) # 與上同理
return self.active_out[:]
# 誤差反向傳播
def errorbackpropagate(self, targets, lr, m): # lr是學習率, m是動量因子
if len(targets) != self.num_out:
raise ValueError('與輸出層節點數不符!')
# 首先計算輸出層的誤差
out_deltas = [0.0] * self.num_out
for i in range(self.num_out):
error = targets[i] - self.active_out[i]
out_deltas[i] = derived_sigmoid(self.active_out[i]) * error
# 計算隱藏層2的誤差
hidden2_deltas = [0.0] * self.num_hidden2
for i in range(self.num_hidden2):
error = 0.0
for j in range(self.num_out):
error = error + out_deltas[j] * self.wight_out[i][j]
hidden2_deltas[i] = derived_sigmoid(self.active_hidden2[i]) * error
# 計算隱藏層1的誤差
hidden1_deltas = [0.0] * self.num_hidden1
for i in range(self.num_hidden1):
error = 0.0
for j in range(self.num_hidden2):
error = error + hidden2_deltas[j] * self.wight_h1h2[i][j]
hidden1_deltas[i] = derived_sigmoid(self.active_hidden1[i]) * error
# 更新輸出層權值
for i in range(self.num_hidden2):
for j in range(self.num_out):
change = out_deltas[j] * self.active_hidden2[i]
self.wight_out[i][j] = self.wight_out[i][j] + lr * change + m * self.co[i][j]
self.co[i][j] = change
# 更新隱藏層間權值
for i in range(self.num_hidden1):
for j in range(self.num_hidden2):
change = hidden2_deltas[j] * self.active_hidden1[i]
self.wight_h1h2[i][j] = self.wight_h1h2[i][j] + lr * change + m * self.ch1h2[i][j]
self.ch1h2[i][j] = change
# 然後更新輸入層權值
for i in range(self.num_in):
for j in range(self.num_hidden1):
change = hidden1_deltas[j] * self.active_in[i]
self.wight_in[i][j] = self.wight_in[i][j] + lr * change + m * self.ci[i][j]
self.ci[i][j] = change
# 計算總誤差
error = 0.0
for i in range(self.num_out):
error = error + 0.5 * (targets[i] - self.active_out[i]) ** 2
return error
# 測試
def test(self, X_test):
for i in range(X_test.shape[0]):
print(X_test[i, 0:4], '->', self.update(X_test[i, 0:4]))
# 權重
def weights(self):
print("輸入層權重")
for i in range(self.num_in):
print(self.wight_in[i])
print("輸出層權重")
for i in range(self.num_hidden2):
print(self.wight_out[i])
def train(self, train, itera=100, lr=0.1, m=0.1):
for i in range(itera):
error = 0.0
for j in range(100):#訓練集的大小
inputs = train[j, 0:4]
d = onehot(train[:,4], self.num_out)
targets = d[j, :]
self.update(inputs)
error = error + self.errorbackpropagate(targets, lr, m)
if i % 100 == 0:
print('誤差 %-.5f' % error)
def show_accuracy(self, X, Y):
count=0
Y_pred=[]
for i in range(X.shape[0]):
h=self.update(X[i, 0:4])
y_pred=np.argmax(h)
Y_pred.append(y_pred)
if y_pred==Y[i]:
count+=1
print("準確率為:",count/X.shape[0])
print(count)
print(classification_report(Y, Y_pred))
# 範例
def Mytrain(train,X_test, Y_test):
# 建立神經網路,4個輸入節點,10個隱藏層1節點,6個隱藏層2節點,3個輸出層節點
n = BPNN(4, 10, 6, 3)
# 訓練神經網路
print("start training\n--------------------")
n.train(train,itera=1000)
n.weights()
# n.test(X_test)
n.show_accuracy(X_test, Y_test)
if __name__ == '__main__':
train = array[:, :] # 訓練集
X_test = iris_test.values[:, :] # 測試集
Y_test = iris_test.values[:, 4] # 測試集的標籤
Mytrain(train, X_test, Y_test)
輸出結果:
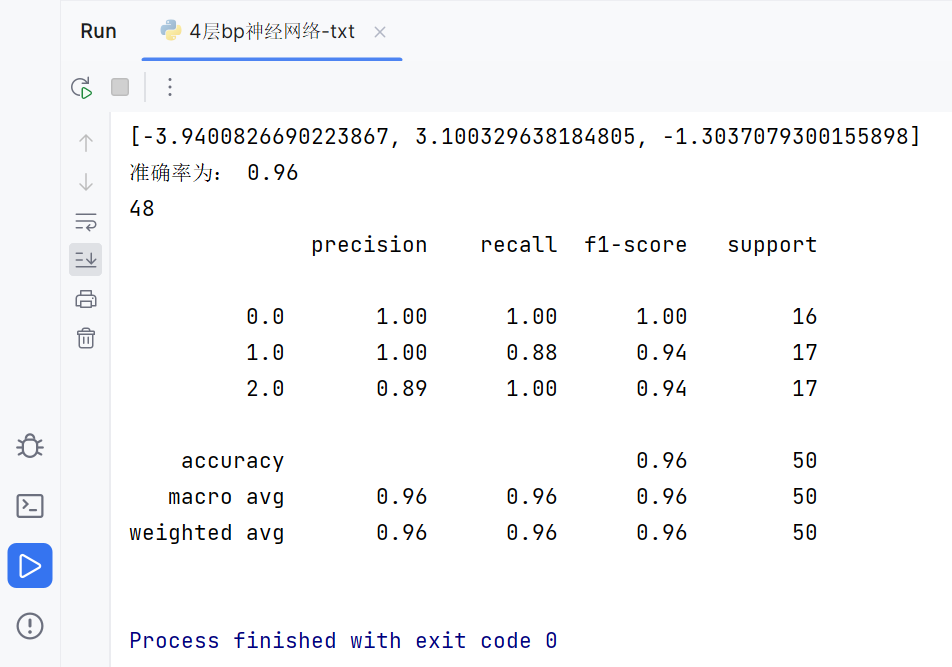
start training
--------------------
誤差 35.40337
誤差 1.43231
誤差 1.08501
誤差 1.05931
誤差 1.04053
誤差 1.02761
誤差 1.02126
誤差 1.01507
誤差 1.01000
誤差 1.00646
輸入層權重
[0.056033408540934464, 2.8041275894047875, 0.16855148969297182, 1.0200135486931827, -1.4263718396216152, 0.46417722366714737, 3.951369301666286, -1.68522617998046, -0.07767181609266427, -0.3263575324395308, 2.0699554193776044]
[-1.4377068931180876, 1.851234250520833, 0.15780177315246371, -0.05179352554189774, -2.3563287594546423, 1.7623583488440409, 3.091780632711021, -1.372026038986551, -1.726220905551624, -1.1669182260086637, 1.6321410768033273]
[0.9560967359135075, -4.531261602111315, -0.6120871721438043, 0.3990936425721157, 2.9004962990324032, -1.6411239366055017, -6.471695892441071, 2.6775054457912315, 1.4507421345886298, 1.962983608402704, -3.3617954044955485]
[0.9386911995204238, -2.5918217255311093, -0.19942943923868559, -0.12162074195611947, 2.299246125556896, -1.5047700193638123, -3.760625731974951, 2.069744371129818, 0.8219878214614533, 0.8239600952803267, -2.5028309920744243]
[-0.5943509557690846, 3.1298630885285528, 0.182341529267033, -0.3904817160983978, -1.477792159823391, 1.242189984057302, 3.993237791636666, -1.3449814648342135, -0.42506681041697547, -0.4405383184743436, 2.466930731983345]
輸出層權重
[-0.09150582827392847, 3.142269157863363, -4.641439345864634]
[-1.4871365396516583, -0.48293082562473966, -0.20849376992641952]
[-1.8532830432907033, -6.6108611902097465, 5.752994457916077]
[3.247964863909582, -3.6518302173463195, -1.7172925811709747]
[-0.9773159253935711, -0.3682438453855819, 0.09500142611662453]
[3.513238795753454, -4.578599999073612, -1.5312361861597554]
[-3.9400826690223867, 3.100329638184805, -1.3037079300155898]
準確率為: 0.96
48
precision recall f1-score support
0.0 1.00 1.00 1.00 16
1.0 1.00 0.88 0.94 17
2.0 0.89 1.00 0.94 17
accuracy 0.96 50
macro avg 0.96 0.96 0.96 50
weighted avg 0.96 0.96 0.96 50
Process finished with exit code 0
參考文獻:
[1] 四層BP網路python程式碼實現_odd~的部落格-CSDN部落格
[2] MachineLearning_Ass2/bpNetwork.py at master · wangtuntun/MachineLearning_Ass2 · GitHub
ps:參考文獻[1]程式碼對於資料處理有嚴重問題,並且沒有寫計算正確率的函數,訓練結果有嚴重錯誤,我部分參考程式碼[2]進行了修復,程式碼[2]是7年前的老程式碼,應該是基於python2的,並不能直接執行在python3.
資料集下載連結:https://wwke.lanzoub.com/i2KGW0seo4yf