LLaMA:開放和高效的基礎語言模型
LLaMA:開放和高效的基礎語言模型
https://arxiv.org/pdf/2302.13971.pdf
https://github.com/facebookresearch/llama
Part1前言
我們介紹了LLaMA,這是一個引數範圍從7B到65B的基礎語言模型集合。我們在數以萬億計的標記上訓練我們的模型,並表明有可能完全使用公開可用的資料集來訓練最先進的模型,而不必求助於專有的和不可獲取的資料集。特別是,LLaMA-13B 在大多數基準上超過了GPT-3(175B), LLaMA-65B與最好的模型Chinchilla-70B和PaLM-540B相比具有競爭力。我們向研究界釋出了我們所有的模型。
總結:
僅僅在公開的資料集上進行訓練了多個尺度的模型,就可以達到最先進的效果。 對模型和實現方式進行優化,加速訓練。
Part2方法
1使用的資料
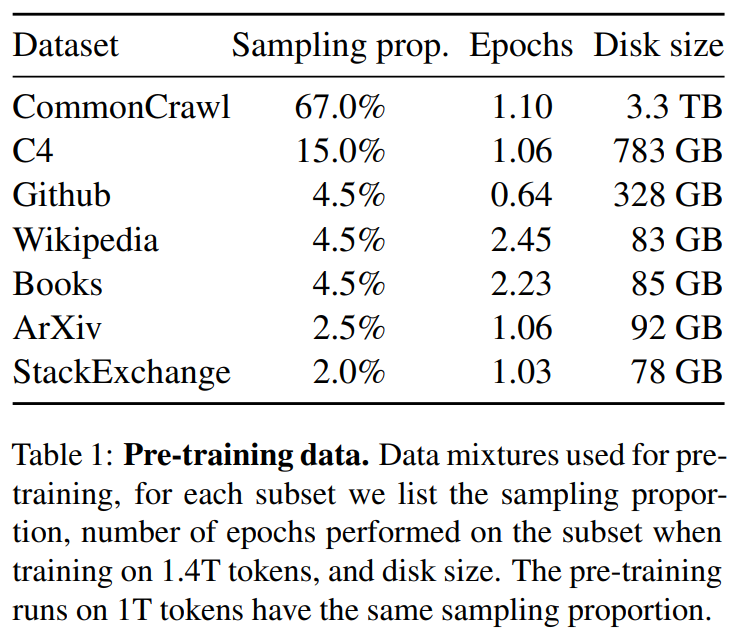
英語CommonCrawl[67%] :我們用CCNet管道( Wenzek等人 , 2020年)對五個CommonCrawl轉儲進行預處理,範圍從2017年到2020年。這個過程在行的層面上對資料進行了刪除,用fastText線性分類器進行語言識別,以去除非英語頁面,並用n-gram語言模型過濾低質量內容。此外,我們訓練了一個線性模型來對維基百科中用作參考文獻的頁面與隨機抽樣的頁面進行分類,並丟棄了未被分類為參考文獻的頁面。
C4 [15%] :在探索性的實驗中,我們觀察到,使用多樣化的預處理Com-monCrawl資料集可以提高效能。因此,我們將公開的C4資料集( Raffel等人,2020)納入我們的資料。C4的預處理也包含重複資料刪除和語言識別步驟:與CCNet的主要區別在於質量過濾,它主要依賴於標點符號的存在或網頁中的單詞和句子的數 量等判例。
Github[4.5%] :我們使用谷歌BigQuery上的GitHub公共資料集。我們只保留在Apache、BSD和MIT許可下發布的專案。此外,我們用基於行長或字母數位字元比例的啟發式方法過濾了低質量的檔案,並用規範的表示式刪除了模板,如標題。最後,我們在檔案層面上對結果資料集進行重複計算,並進行精確匹配。
維基百科[4.5%] :我們新增了2022年6月至8月期間的維基百科轉儲,涵蓋了20使用拉丁字母或西裡爾字母的語言:BG、CA、CS、DA、DE、EN、ES、FR、HR、HU、IT、NL、PL、PT、RO、RU、SL、SR、SV、UK。我們對資料進行處理,以刪除超連結、評論和其他格式化的模板。
古騰堡和Books3[4.5%] :我們的訓練資料 包括兩個書體:Guten- berg專案和TheP-ile( Gao等人,2020)的Books3部分,後者是一個用於訓練大型語言模型的公開可用資料集。我們在書籍層面上進行重複資料刪除,刪除內容重疊度超過90%的書籍。
ArXiv[2.5%] : 我們處理了arXiv的Latex檔案,將科學資料新增到我們的資料集中。按照Lewkowycz等人(2022)的做法,我們刪除了第一節之前的所有內容,以及書目。我們還刪除了.tex檔案中的註釋,以及使用者寫的內聯擴充套件的定義和宏,以提高不同論文的一致性。
Stack Exchange[2%] :我們包括了Stack Exchange的轉儲,這是一個高質量的問題和答案的網站,涵蓋了從電腦科學到化學等不同的領域。我們保留了28個最大網站的資料,重新將HTML標籤從文字中移出,並將答案按分數(從高到低)排序。
2標記器
標記器: 我們用位元組對編碼(BPE)演演算法( Sennrich等人,2015)對資料進行標記,使用 Sentence-Piece(Kudo和Richardson,2018)中的實現。值得注意的是,我們將所有數位分割成單個數位,並回退到位元組來分解未知的UTF-8字元。
總的來說,我們的整個訓練資料集在標記化之後大約包含1.4T的標記。對於我們的大多數訓練資料,每個標記在訓練過程中只使用一次,但維基百科和圖書領域除外,我們對其進行了大約兩個epochs訓練。
Part3模型結構
基本還是transformer結構,主要是以下一些不同:
預歸一化[GPT3] :為了提高訓練的穩定性,我們對每個transformer子層的輸入進行規範化,而不是對輸出進行規範化。我們使用Zhang和Sennrich(2019)介紹的RMSNorm歸一化函數。
SwiGLU啟用函數[PaLM] :我們用SwiGLU啟用函數替換ReLU的非線性,由Shazeer(2020)引入以提高效能。我們使用的維度是$\frac{2}{3}4d$,而不是PaLM中的4d。
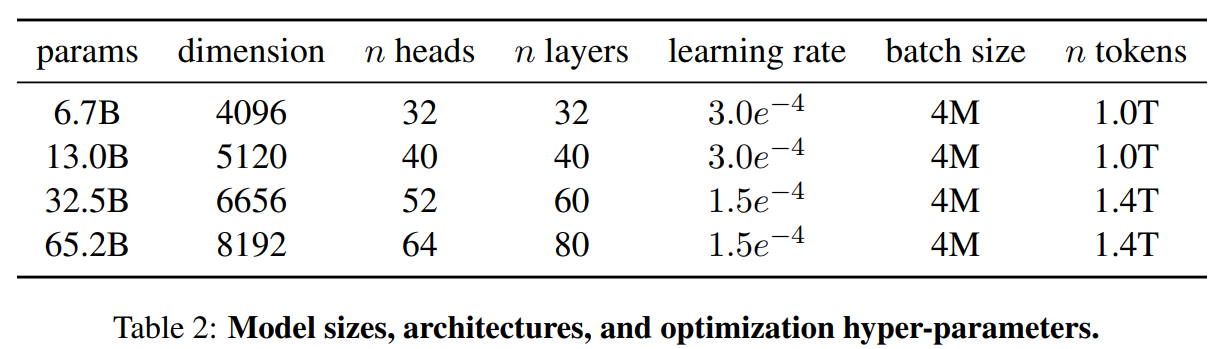
旋轉嵌入[GPTNeo] :我們刪除了絕對位置嵌入,取而代之的是在網路的每一層新增Su等人(2021)介紹的旋轉位置嵌入(RoPE)。表2中給出了我們不同模型的超引數細節。
3優化器
我們的模型使用AdamW optimizer( Loshchilov和Hutter,2017)進行訓練,超引數如下:β1 = 0.9,β2 = 0.95。我們使用一個餘弦學習率計劃,使最終的學習率等於最大的10%。我們使用0.1的權重衰減和梯度剪裁為1.0。我們使用2,000個預熱步驟,並隨著模型的大小而改變學習率和批次大小(詳見表2)。
4高效的實現
我們進行了一些優化,以提高我們模型的訓練速度。首先,我們使用causal multi-head attention,以減少記憶體使用和執行時間。這個實現可在xformers庫中找到。這是通過不儲存注意力權重和不計算由於語言建模任務的因果性質而被掩蓋的鍵/查詢分數來實現的。
為了進一步提高訓練效率,我們重新縮減了在後向傳遞過程中建議使用的啟用量。更確切地說,我們儲存了計算成本較高的啟用,如線性層的輸出。這是通過手動實現transformer層的後向函數來實現的,而不是依靠PyTorch的autograd。為了充分受益於這種優化,我們需要如Korthikanti等人(2022)所述,通過使用模 型和序列並行,減少模型的記憶體使用。此外,我們還儘可能地過度重視啟用的計算和GPU之間通過網路的通訊(由於all_reduce操作)。當訓練一個65B引數的模型時,我們的程式碼在2048個A100GPU和80GB的記憶體上處理大約380個令牌/秒/GPU。 這意味著在我們包含1.4T標記的資料集上進行訓練大約需要21天。
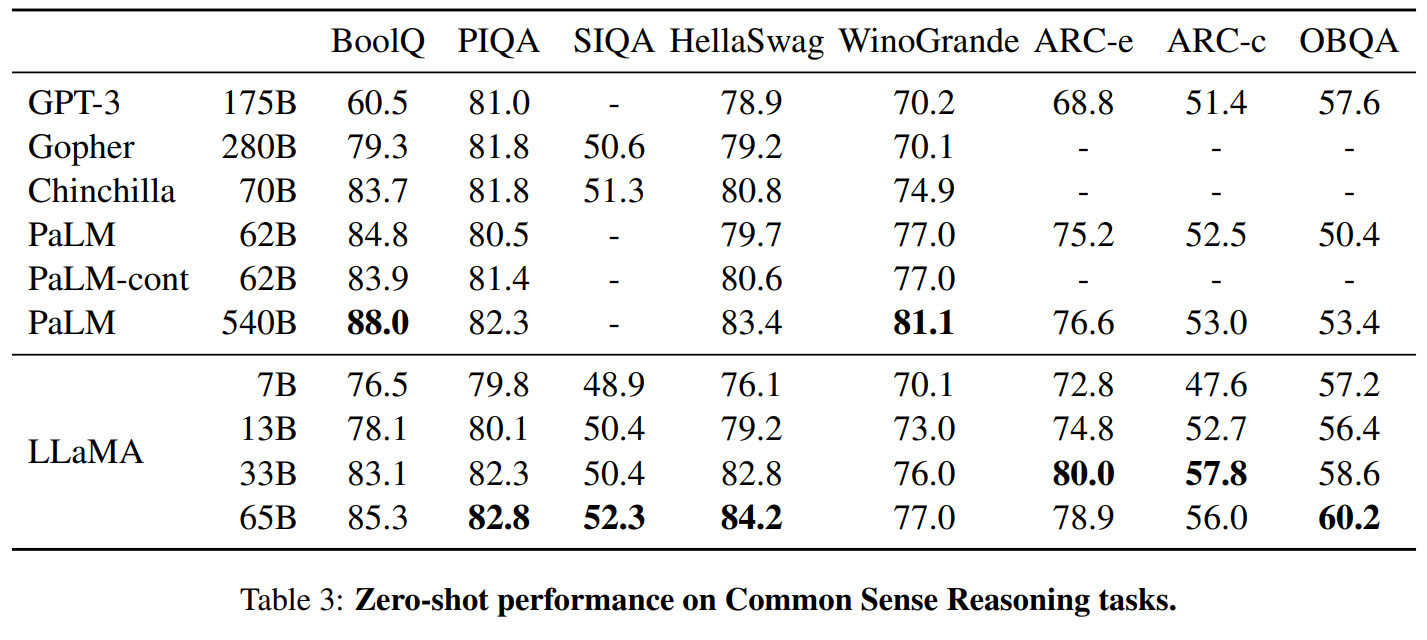
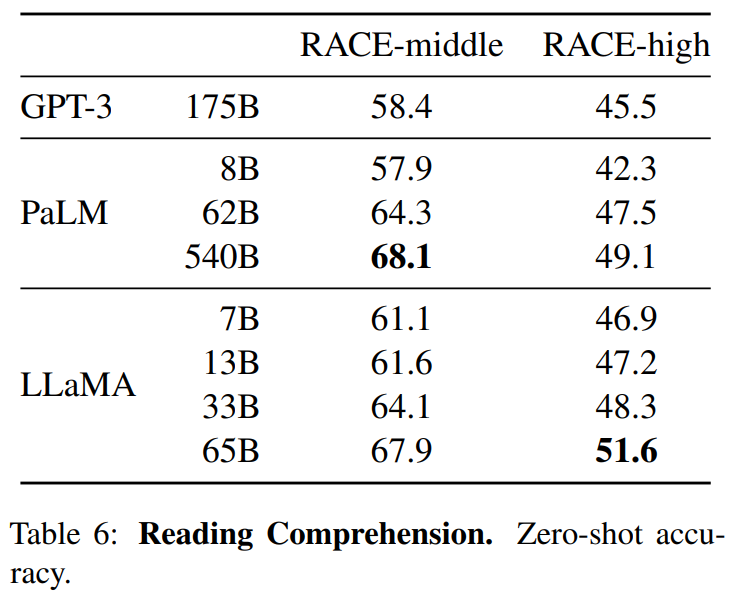
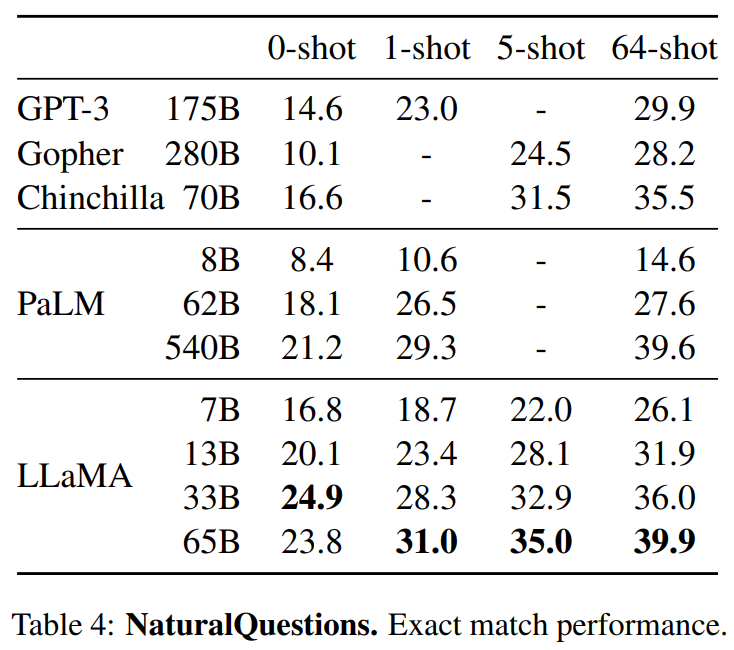
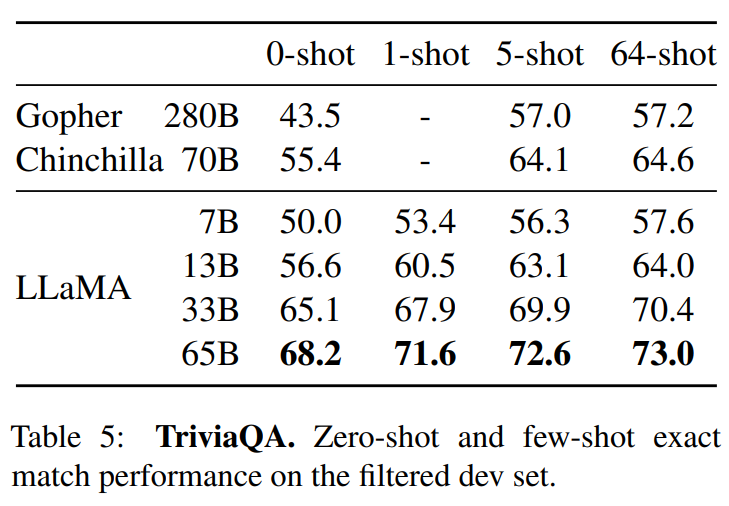
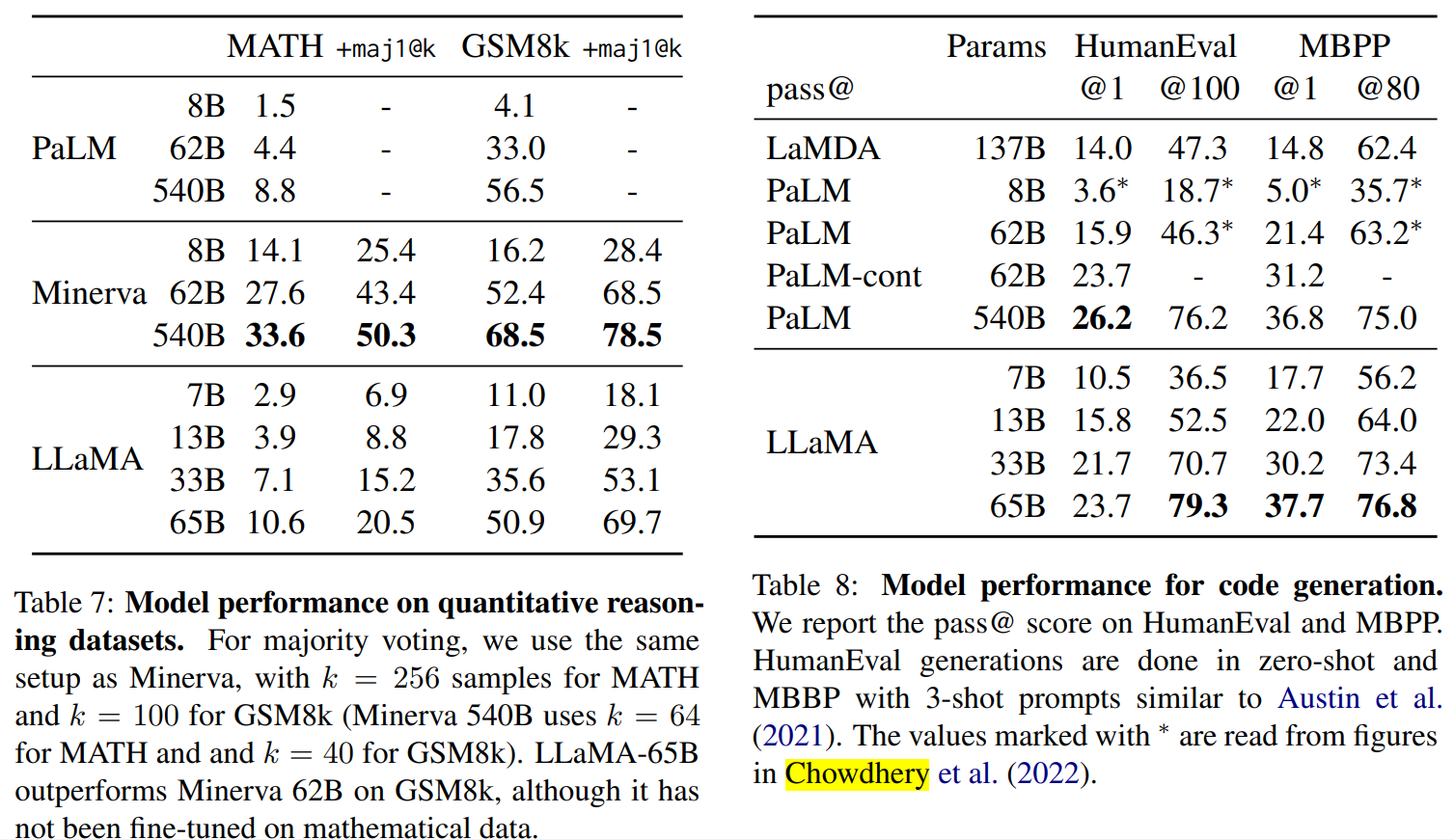
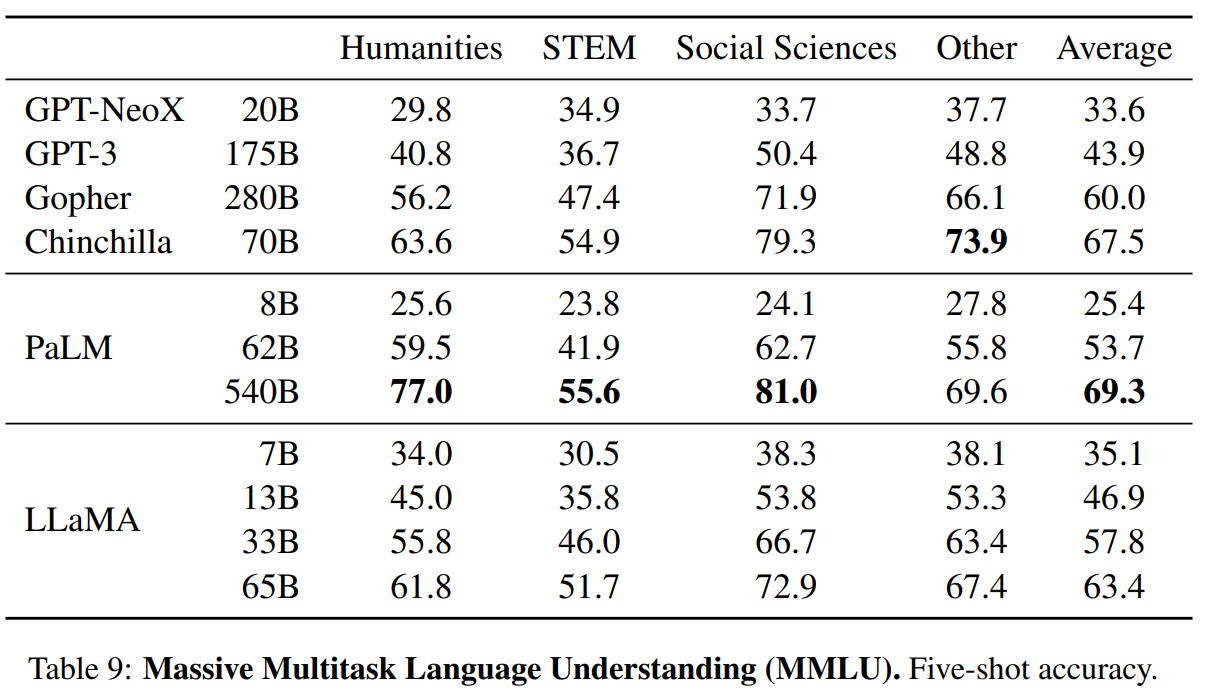
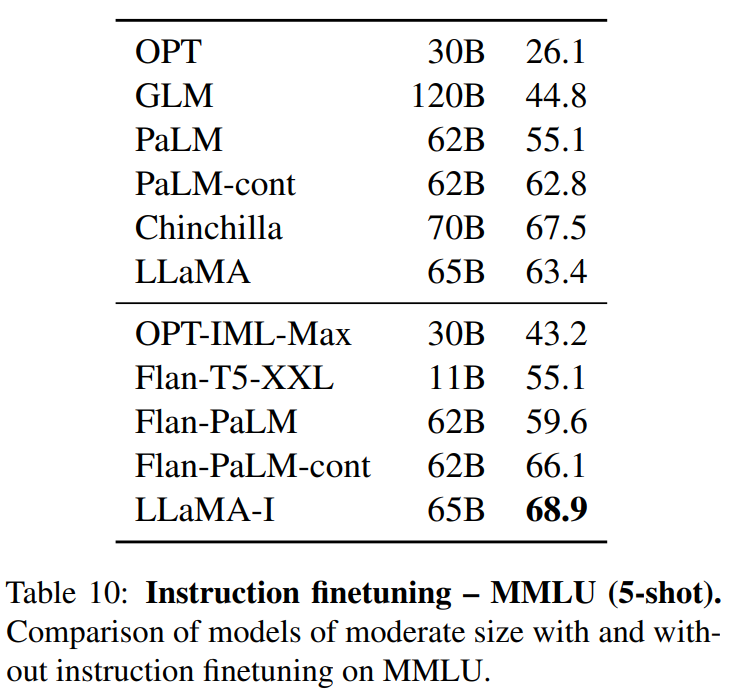
Part4結果