一文徹底搞懂Raft演演算法,看這篇就夠了!!!
最近需要設計一個分散式系統,需要一箇中介軟體來儲存共用的資訊,來保證多個系統之間的資料一致性,調研了兩個主流框架Zookeeper和ETCD,發現都能滿足我們的系統需求。其中ETCD是K8s中採用的分散式儲存,而其底層採用了RAFT演演算法來保證一致性,所以隨便研究了下RAFT演演算法,這篇文章會從頭到尾分析Raft演演算法的方方面面。
什麼是分散式一致性 ?
分散式系統通常由非同步網路連線的多個節點構成,每個節點有獨立的計算和儲存,節點之間通過網路通訊進行共同作業。分散式一致性指多個節點對某一變數的取值達成一致,一旦達成一致,則變數的本次取值即被確定。
在大量使用者端並行請求讀/寫的情況下,維護資料多副本的一致性無疑非常重要,且富有挑戰。因此,分散式一致性在我們生產環境中顯得尤為重要。
總結來講,分散式一致性就是為了解決以下兩個問題:
-
資料不能存在單個節點(主機)上,否則可能出現單點故障。
-
多個節點(主機)需要保證具有相同的資料。
常見分散式一致性演演算法
常見的一致性演演算法包括Paxos演演算法,Raft演演算法,ZAB演演算法等,
-
Paxos演演算法是Lamport宗師提出的一種基於訊息傳遞的分散式一致性演演算法,使其獲得2013年圖靈獎。自Paxos問世以來就持續壟斷了分散式一致性演演算法,Paxos這個名詞幾乎等同於分散式一致性, 很多分散式一致性演演算法都由Paxos演變而來#
-
Paxos是出了名的難懂,而Raft正是為了探索一種更易於理解的一致性演演算法而產生的。它的首要設計目的就是易於理解,所以在選主的衝突處理等方式上它都選擇了非常簡單明瞭的解決方案。
-
ZAB 協定全稱:Zookeeper Atomic Broadcast(Zookeeper 原子廣播協定), 它應該是所有一致性協定中生產環境中應用最多的了。為什麼呢?因為他是為 Zookeeper 設計的分散式一致性協定!
本文我們主要介紹Raft演演算法,後續會對其他演演算法進行詳細介紹。
深入Raft演演算法
Raft演演算法和其他分散式一致演演算法一樣,內部採用如下圖所示的複製狀態機模型,在這個模型中,會利用多臺伺服器構成一個叢集,工作流程如下圖所示:

整個工作流程可以歸納為如下幾步:
-
使用者輸入設定指令,比如將設定y為1,然後將y更改為9.
-
叢集收到使用者指令之後,會將該指令同步到叢集中的多臺伺服器上,這裡你可以認為所有的變更操作都會寫入到每個伺服器的Log檔案中。
-
根據Log中的指令序列,叢集可以計算出每個變數對應的最新狀態,比如y的值為9.
-
使用者可以通過演演算法提供的API來獲取到最新的變數狀態。
演演算法會保證變數的狀態在整個叢集內部是統一的,並且當叢集中的部分伺服器宕機後,仍然能穩定的對外提供服務。
Raft演演算法在具體實現中,將分散式一致性問題分解為了Leader選舉、紀錄檔同步和安全性保證三大子問題,接下來我會對這三方面進行仔細講解。
Raft演演算法基礎
Raft 正常工作時的流程如下圖,也就是正常情況下紀錄檔複製的流程。Raft 中使用紀錄檔來記錄所有操作,所有結點都有自己的紀錄檔列表來記錄所有請求。演演算法將機器分成三種角色:Leader、Follower 和 Candidate。正常情況下只存在一個 Leader,其他均為 Follower,所有使用者端都與 Leader 進行互動。
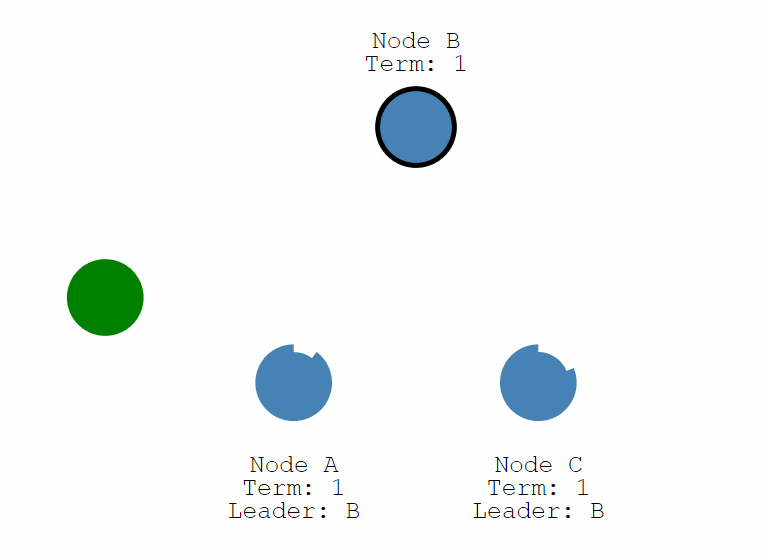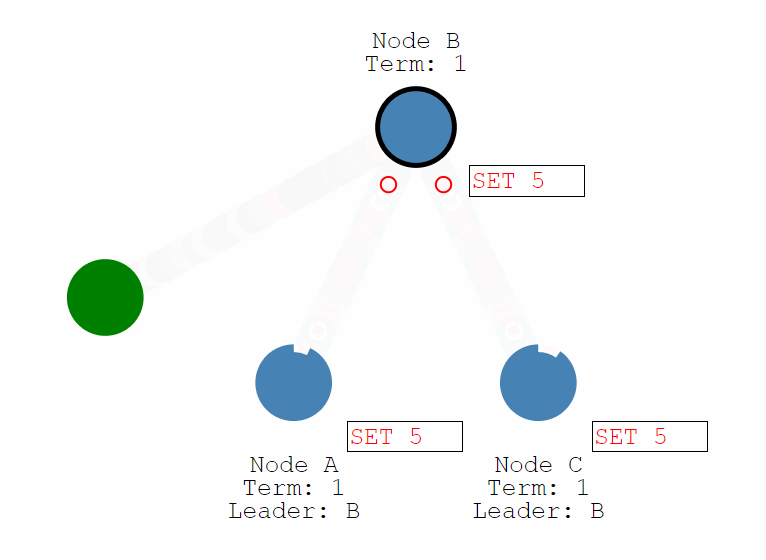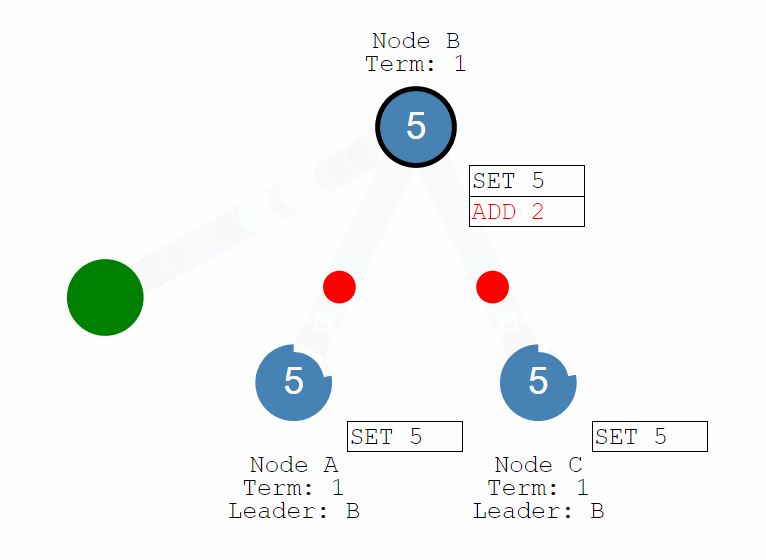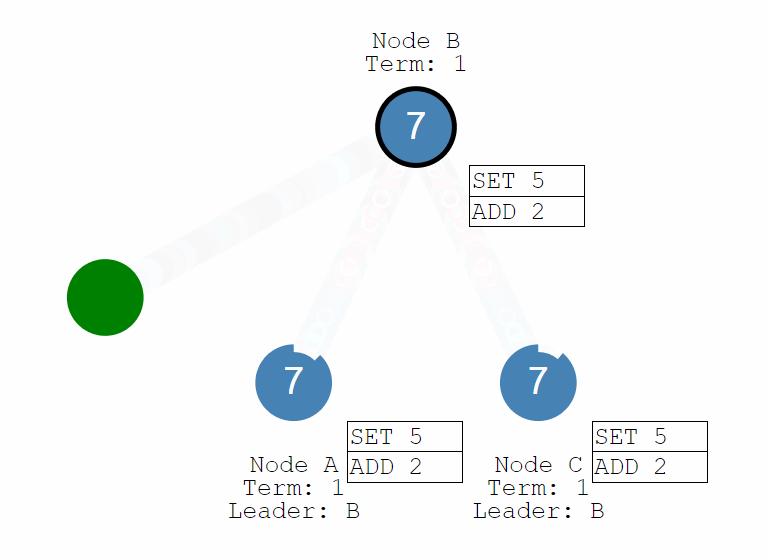
所有操作採用類似兩階段提交的方式,Leader 在收到來自使用者端的請求後並不會執行,只是將其寫入自己的紀錄檔列表中,然後將該操作傳送給所有的 Follower。Follower 在收到請求後也只是寫入自己的紀錄檔列表中然後回覆 Leader,當有超過半數的結點寫入後 Leader 才會提交該操作並返回給使用者端,同時通知所有其他結點提交該操作。
通過這一流程保證了只要提交過後的操作一定在多數結點上留有記錄(在紀錄檔列表中),從而保證了該資料不會丟失。
Raft 是一個非拜占庭的一致性演演算法,即所有通訊是正確的而非偽造的。N個結點的情況下(N為奇數)可以最多容忍(N-1)/2個結點故障。如果更多的節點故障,後續的Leader選舉和紀錄檔同步將無法進行。
子問題1:Leader選舉
在瞭解基本的工作流程之後,首先看下Rsft演演算法的第一個問題,如何選舉Leader。
1. 首次選舉

如果定時器超時,說明一段時間內沒有收到 Leader 的訊息,那麼就可以認為 Leader 已死或者不存在,那麼該結點就會轉變成 Candidate,意思為準備競爭成為 Leader。
成為 Candidate 後結點會向所有其他結點傳送請求投票的請求(RequestVote),其他結點在收到請求後會判斷是否可以投給他並返回結果。Candidate 如果收到了半數以上的投票就可以成為 Leader,成為之後會立即並在任期內定期傳送一個心跳資訊通知其他所有結點新的 Leader 資訊,並用來重置定時器,避免其他結點再次成為 Candidate。
如果 Candidate 在一定時間內沒有獲得足夠的投票,那麼就會進行一輪新的選舉,直到其成為 Leader,或者其他結點成為了新的 Leader,自己變成 Follower。
2. 再次選舉
當Leader下線或者因為網路問題產生分割區時,會導致再次選舉。
- 情況1:Leader下線,此時所有其他節點的計時器不會被重置,直到一個節點成為了 Candidate,和上述一樣開始一輪新的選舉選出一個新的 Leader。
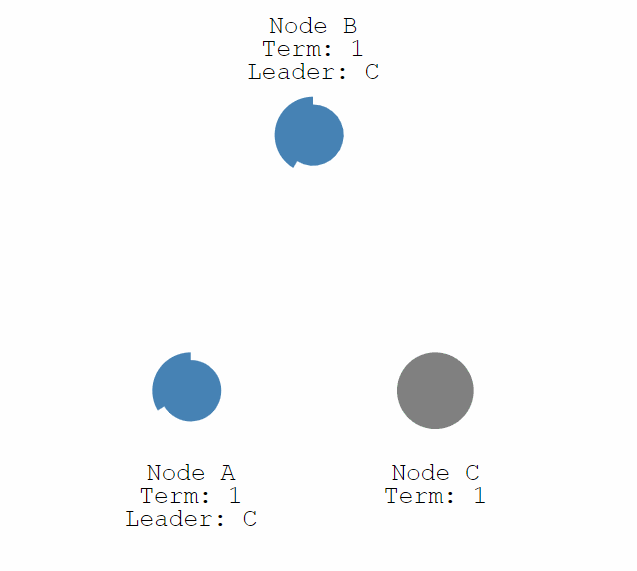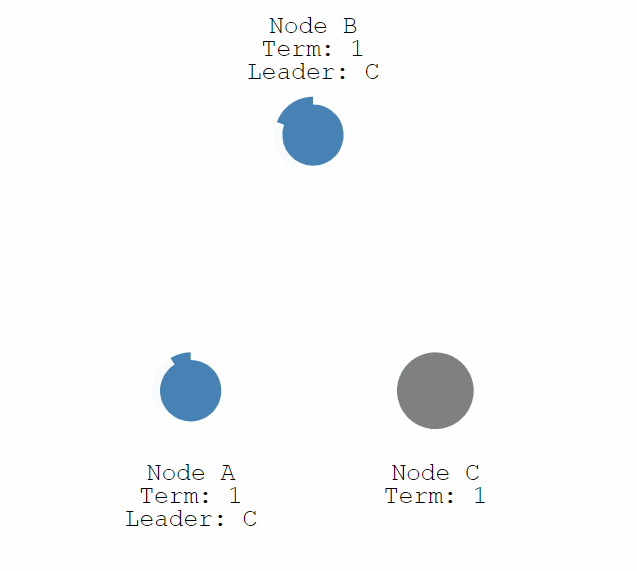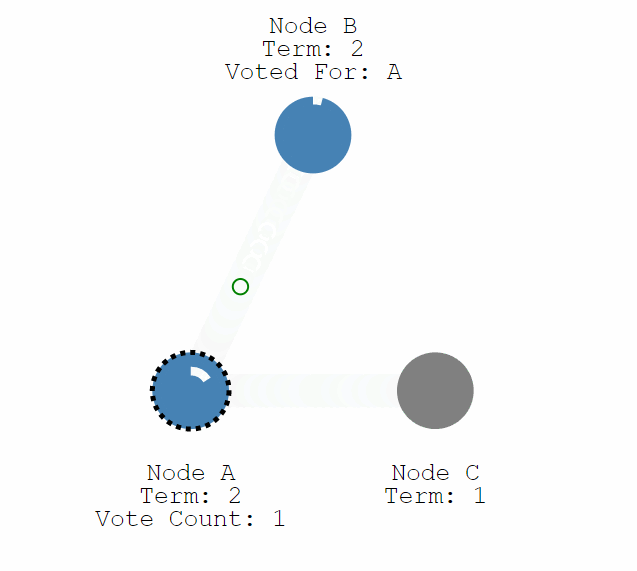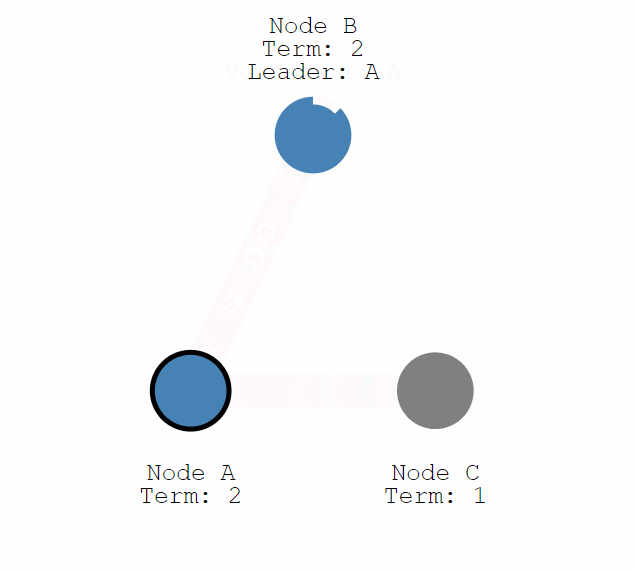
- 情況2:某一 Follower 結點與 Leader 間通訊發生問題,導致發生了分割區,這時沒有 Leader 的那個分割區就會進行一次選舉。這種情況下,因為要求獲得多數的投票才可以成為 Leader,因此只有擁有多數結點的分割區可以正常工作。而對於少數結點的分割區,即使仍存在 Leader,但由於寫入紀錄檔的結點數量不可能超過半數因此不可能提交操作。這也是為何一開始我提到Raft演演算法必須要半數以上節點正常才能工作。
下圖總結了Raft演演算法中,每個節點的狀態之間的變化:

- Leader:處理與使用者端的互動和與 follower 的紀錄檔複製等,一般只有一個 Leader;
- Follower:被動學習 Leader 的紀錄檔同步,同時也會在 leader 超時後轉變為 Candidate 參與競選;
- Candidate:在競選期間參與競選;
3. 任期Term
Raft演演算法將時間分為一個個的任期(term),每一個term的開始都是Leader選舉。
每一個任期以一次選舉作為起點,所以當一個結點成為 Candidate 並向其他結點請求投票時,會將自己的 Term 加 1,表明新一輪的開始以及舊 Leader 的任期結束。所有結點在收到比自己更新的 Term 之後就會更新自己的 Term 並轉成 Follower,而收到過時的訊息則拒絕該請求。
在成功選舉Leader之後,Leader會在整個term內管理整個叢集。如果Leader選舉失敗,該term就會因為沒有Leader而結束。

4. 投票
在投票時候,所有伺服器採用先來先得的原則,在一個任期內只可以投票給一個結點,得到超過半數的投票才可成為 Leader,從而保證了一個任期內只會有一個 Leader 產生(Election Safety)。
在 Raft 中紀錄檔只有從 Leader 到 Follower 這一流向,所以需要保證 Leader 的紀錄檔必須正確,即必須擁有所有已在多數節點上存在的紀錄檔,這一步驟由投票來限制。
在介紹投票規則之前,先簡單介紹下紀錄檔的格式,方便理解:
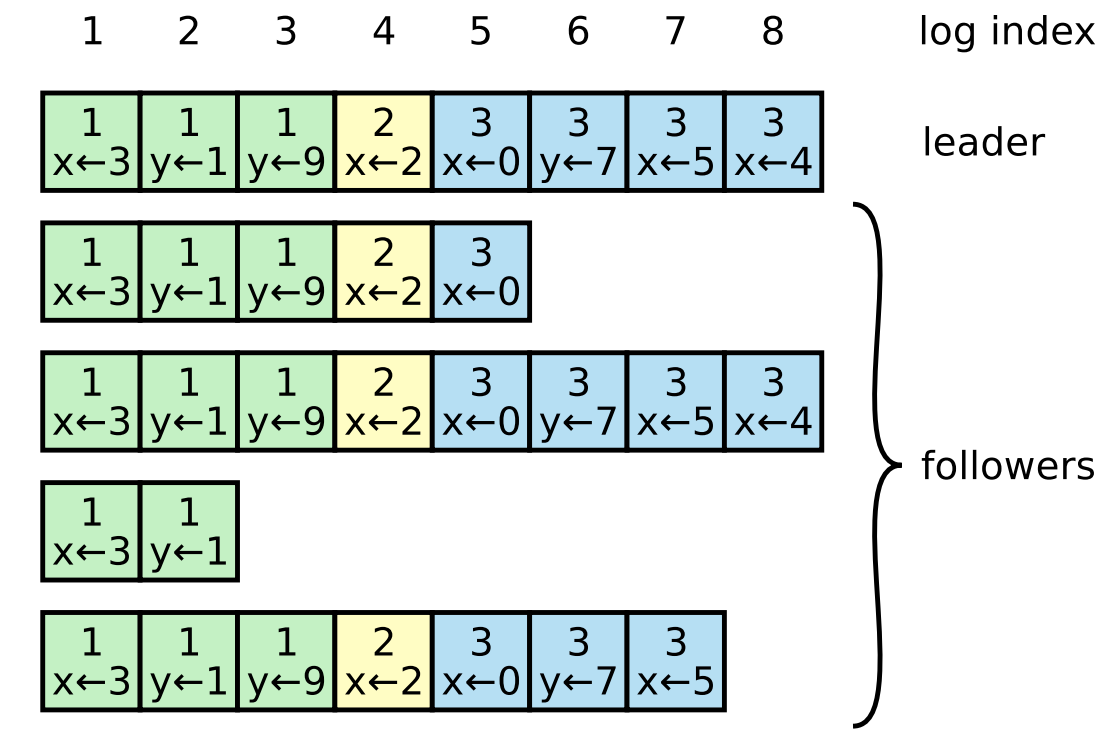
如上圖所示,紀錄檔由有序編號(log index)的紀錄檔條目組成。每個紀錄檔條目包含它被建立時的任期號(term),和用於狀態機執行的命令。如果一個紀錄檔條目被複制到大多數伺服器上,就被認為可以提交(commit)了。
投票由一個稱為 RequestVote 的 RPC 呼叫進行,請求中除了有 Candidate自己的 term 和 id 之外,還要帶有自己最後一個紀錄檔條目的 index 和 term。Candidate首先會給自己投票,然後再向其他節點收集投票資訊,收到投票資訊的節點,會利用如下規則判斷是否投票:
-
首先會判斷請求的term是否更大,不是則說明是舊訊息,拒絕該請求。
-
如果任期Term相同,則比較index,index較大則為更加新的紀錄檔;如果任期Term不同,term更大的則為更新的訊息。如果是更新的訊息,則給Candidate投票。
由於只有紀錄檔在被多數結點複製之後才會被提交併返回,所以如果一個 Candidate 並不擁有最新的已被複制的紀錄檔,那麼他不可能獲得多數票,從而保證了 Leader 一定具有所有已被多數擁有的紀錄檔(Leader Completeness),在後續同步時會將其同步給所有結點。
子問題2:紀錄檔同步
工作流程
Leader選出後,就開始接收使用者端的請求。Leader把請求作為紀錄檔條目(Log entries)加入到它的紀錄檔中,然後並行的向其他伺服器發起 AppendEntries RPC複製紀錄檔條目。當這條紀錄檔被複制到大多數伺服器上,Leader將這條紀錄檔應用到它的狀態機並向用戶端返回執行結果。
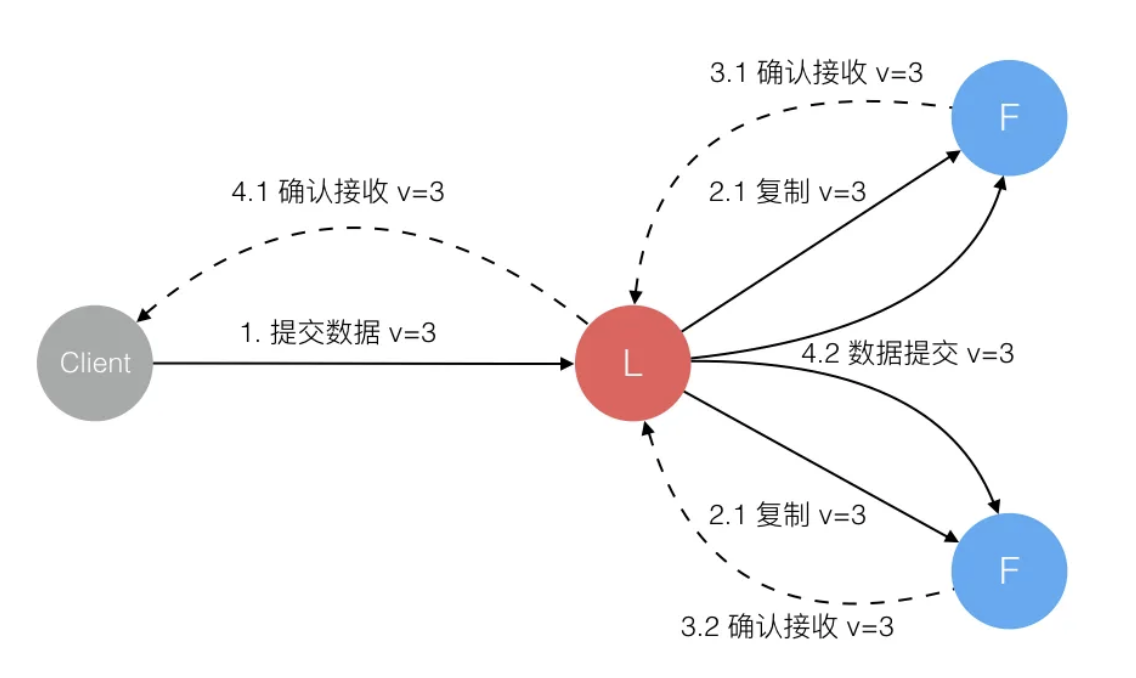
某些Followers可能沒有成功的複製紀錄檔,Leader會無限的重試 AppendEntries RPC直到所有的Followers最終儲存了所有的紀錄檔條目。
紀錄檔由有序編號(log index)的紀錄檔條目組成。每個紀錄檔條目包含它被建立時的任期號(term),和用於狀態機執行的命令。如果一個紀錄檔條目被複制到大多數伺服器上,就被認為可以提交(commit)了。
實際處理邏輯
Leader 會給每個 Follower 傳送該 RPC 以追加紀錄檔,請求中除了當前任期 term、Leader 的 id 和已提交的紀錄檔 index,還有將要追加的紀錄檔列表(空則成為心跳包),前一個紀錄檔的 index 和 term。具體可以參考官方論文中的描述:

在接到該請求後,會進行如下判斷:
-
檢查term,如果請求的term比自己小,說明已經過期,直接拒絕請求。
-
如果步驟1通過,則對比先前紀錄檔的index和term,如果一致,則就可以從此處更新紀錄檔,把所有的紀錄檔寫入自己的紀錄檔列表中,否則返回false。
這裡對步驟2進行展開說明,每個Leader在開始工作時,會維護 nextIndex[] 和 matchIndex[] 兩個陣列,分別記錄了每個 Follower 下一個將要傳送的紀錄檔 index 和已經匹配上的紀錄檔 index。每次成為 Leader 都會初始化這兩個陣列,前者初始化為 Leader 最後一條紀錄檔的 index 加 1,後者初始化為 0,每次傳送 RPC 時會傳送 nextIndex[i] 及之後的紀錄檔。
在步驟2中,當Leader收到返回成功時,則更新兩個陣列,否則說明follower上相同位置的資料和Leader不一致,這時候Leader會減小nextIndex[i]的值重試,一直找到follower上兩者一致的位置,然後從這個位置開始複製Leader的資料給follower,同時follower後續已有的資料會被清空。
這裡減少 nextIndex 的值有不同的策略,可以每次減一,也可以減一個較大的值,或者是跨任期減少,用於快速找到和該結點相匹配的紀錄檔條目。
在複製的過程中,Raft會保證如下幾點:
-
Leader 絕不會覆蓋或刪除自己的紀錄檔,只會追加 (Leader Append-Only),成為 Leader 的結點裡的紀錄檔一定擁有所有已被多數節點擁有的紀錄檔條目,所以先前的紀錄檔條目很可能已經被提交,因此不可以刪除之前的紀錄檔。
-
如果兩個紀錄檔的 index 和 term 相同,那麼這兩個紀錄檔相同 (Log Matching),第二點主要是因為一個任期內只可能出現一個 Leader,而 Leader 只會為一個 index 建立一個紀錄檔條目,而且一旦寫入就不會修改,因此保證了紀錄檔的唯一性。
-
如果兩個紀錄檔相同,那麼他們之前的紀錄檔均相同,因為在寫入紀錄檔時會檢查前一個紀錄檔是否一致,從而遞迴的保證了前面的所有紀錄檔都一致。從而也保證了當一個紀錄檔被提交之後,所有結點在該 index 上提交的內容是一樣的(State Machine Safety)。
子問題3:安全性保障(核心)
Raft演演算法中引入瞭如下兩條規則,來確保了
-
已經commit的訊息,一定會存在於後續的Leader節點上,並且絕對不會在後續操作中被刪除。
-
對於並未commit的訊息,可能會丟失。
多數投票規則
在上面投票環節也有介紹過,一個candidate必須獲得叢集中的多數投票,才能被選為Leader;而對於每條commit過的訊息,它必須是被複制到了叢集中的多數節點,也就是說成為Leader的節點,至少有1個包含了commit訊息的節點給它投了票。
而在投票的過程中每個節點都會與candidate比較紀錄檔的最後index以及相應的term,如果要成為Leader,必須有更大的index或者更新的term,所以Leader上肯定有commit過的訊息。
提交規則
上面說到,只要紀錄檔在多數結點上存在,那麼 Leader 就可以提交該操作。但是Raft額外限制了 Leader只對自己任期內的紀錄檔條目適用該規則,先前任期的條目只能由當前任期的提交而間接被提交。 也就是說,當前任期的Leader,不會去負責之前term的紀錄檔提交,之前term的紀錄檔提交,只會隨著當前term的紀錄檔提交而間接提交。
這樣理解起來還是比較抽象,下面舉一個例子,該叢集中有S1到S5共5個節點,

-
初始狀態如 (a) 所示,之後 S1 下線;
-
(b) 中 S5 從 S3 和 S4 處獲得了投票成為了 Leader 並收到了一條來自使用者端的訊息,之後 S5 下線。
-
(c) 中 S1 恢復併成為了 Leader,並且將紀錄檔複製給了多數結點,之後進行了一個致命操作,將 index 為 2 的紀錄檔提交了,然後 S1 下線。
-
(d) 中 S5 恢復,並從 S2、S3、S4 處獲得了足夠投票,然後將已提交的 index 為 2 的紀錄檔覆蓋了。
這個例子中,在c狀態,由於Leader直接根據紀錄檔在多數節點存在的這個規則,將之前term的紀錄檔提交了,當該Term下線後,後續的Leader S5上線,就將之前已經commit的紀錄檔清空了,導致commit過的紀錄檔丟失了。
為了避免這種已提交的紀錄檔丟失,Raft只允許提交自己任期內的紀錄檔,也就是不會允許c中這種操作。(c)中可能出現的情況有如下兩類:
-
(c)中S1有新的使用者端訊息4,然後S1作為Leader將4同步到S1、S2、S3節點,併成功提交後下線。此時在新一輪的Leader選舉中,S5不可能成為新的Leader,保證了commit的訊息2和4不會被覆蓋。
-
(c)中S1有新的訊息,但是在S1將資料同步到其他節點並且commit之前下線,也就是說2和4都沒commit成功,這種情況下如果S5成為了新Leader,則會出現(d)中的這種情況,2和4會被覆蓋,這也是符合Raft規則的,因為2和4並未提交。
Raft相關擴充套件
1. 紀錄檔壓縮
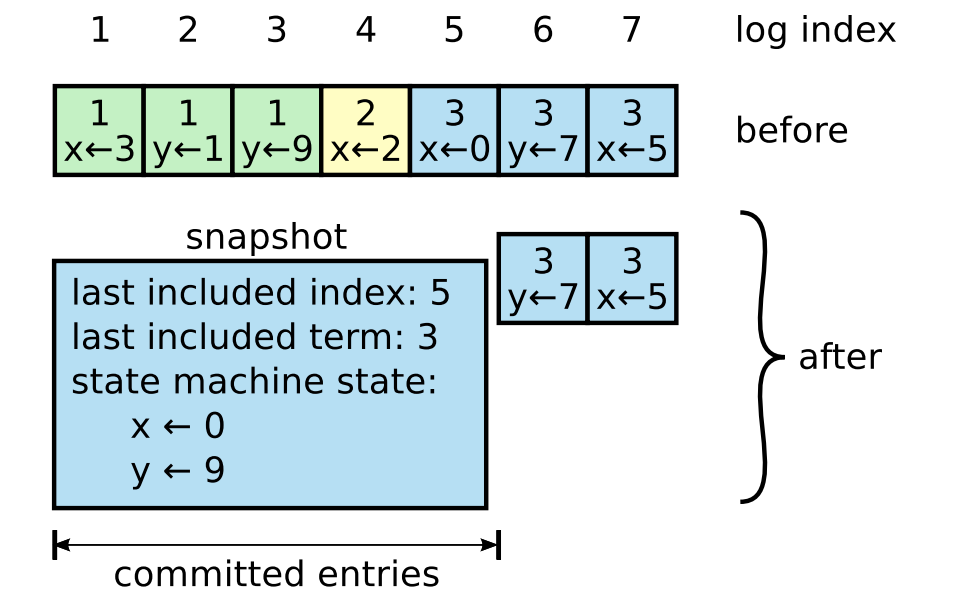
在實際的系統中,不能讓紀錄檔無限增長,否則系統重啟時需要花很長的時間進行回放,從而影響可用性。Raft採用對整個系統進行snapshot來解決,snapshot之前的紀錄檔都可以丟棄。
每個副本獨立的對自己的系統狀態進行snapshot,並且只能對已經提交的紀錄檔記錄進行snapshot。
Snapshot中包含以下內容:
-
紀錄檔後設資料。最後一條已提交的 log entry的 log index和term。這兩個值在snapshot之後的第一條log entry的AppendEntries RPC的完整性檢查的時候會被用上。
-
系統當前狀態。上面的例子中,x為0,y為9.
當Leader要發給某個紀錄檔落後太多的Follower的log entry被丟棄,Leader會將snapshot發給Follower。或者當新加進一臺機器時,也會傳送snapshot給它。
做snapshot既不要做的太頻繁,否則消耗磁碟頻寬, 也不要做的太不頻繁,否則一旦節點重啟需要回放大量紀錄檔,影響可用性。推薦當紀錄檔達到某個固定的大小做一次snapshot。
2. 叢整合員變更
很多時候,叢集需要對節點進行維護,這樣就會涉及到節點的新增和刪除。為了在不停機的情況下, 動態更改叢整合員,Raft提供了下面兩種動態更改叢整合員的方式:
-
單節點成員變更:One Server ConfChange
-
多節點聯合共識:Joint Consensus
動態成員變更存在的問題
在Raft中有一個很重要的安全性保證就是隻有一個Leader,如果我們在不加任何限制的情況下,動態的向叢集中新增成員,那麼就可能導致同一個任期下存在多個Leader的情況,這是非常危險的。
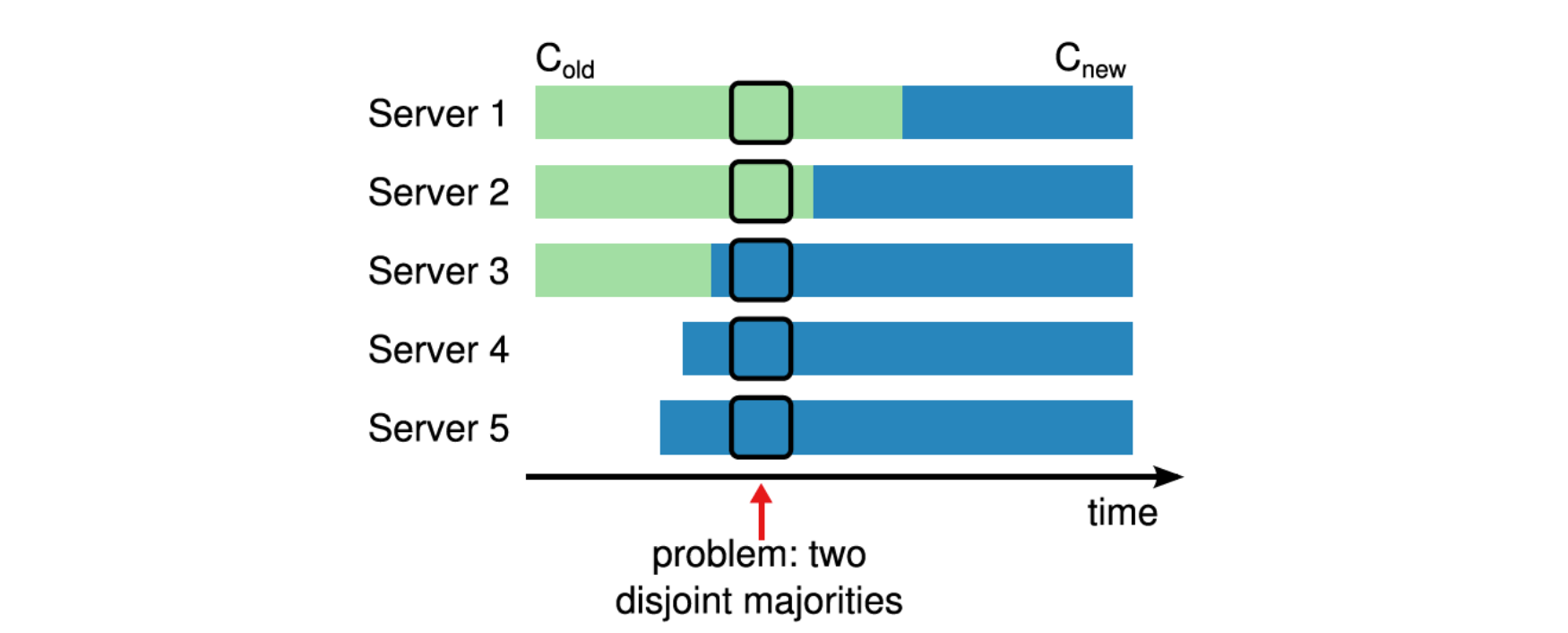
如下圖所示,從Cold遷移到Cnew的過程中,因為各個節點收到最新設定的實際不一樣,那麼肯能導致在同一任期下多個Leader同時存在。
比如圖中此時Server3宕機了,然後Server1和Server5同時超時發起選舉:
-
Server1:此時Server1中的設定還是Cold,只需要Server1和Server2就能夠組成叢集的Majority,因此可以被選舉為Leader
-
Server5:已經收到Cnew的設定,使用Cnew的設定,此時只需要Server3,Server4,Server5就可以組成叢集的Majority,因為可以被選舉為Leader
也就是說,以Cold和Cnew作為設定的節點在同一任期下可以分別選出Leader。
基於此,Raft提供了兩種叢集變更的方式來解決上面可能出現的問題。
單節點成員變更
單節點成員變更,就是保證每次只往叢集中新增或者移除一個節點,這種方式可以很好的避免在變更過程中多個Leader的問題。
下面我們可以列舉一下所有情況,原有叢集奇偶數節點情況下,分別新增和刪除一個節點。在下圖中可以看出,如果每次只增加和刪除一個節點,那麼Cold的Majority和Cnew的Majority之間一定存在交集,也就說是在同一個Term中,Cold和Cnew中交集的那一個節點只會進行一次投票,要麼投票給Cold,要麼投票給Cnew,這樣就避免了同一Term下出現兩個Leader。

變更的流程如下:
-
向Leader提交一個成員變更請求,請求的內容為服務節點的是新增還是移除,以及服務節點的地址資訊
-
Leader在收到請求以後,迴向紀錄檔中追加一條ConfChange的紀錄檔,其中包含了Cnew,後續這些紀錄檔會隨著AppendEntries的RPC同步所有的Follower節點中
-
當ConfChange的紀錄檔被新增到紀錄檔中是立即生效(注意:不是等到提交以後才生效)
-
當ConfChange的紀錄檔被複制到Cnew的Majority伺服器上時,那麼就可以對紀錄檔進行提交了
以上就是整個單節點的變更流程,在紀錄檔被提交以後,那麼就可以:
-
馬上響應使用者端,變更已經完成
-
如果變更過程中移除了伺服器,那麼伺服器可以關機了
-
可以開始下一輪的成員變更了,注意在上一次變更沒有結束之前,是不允許開始下一次變更的。
多節點聯合共識
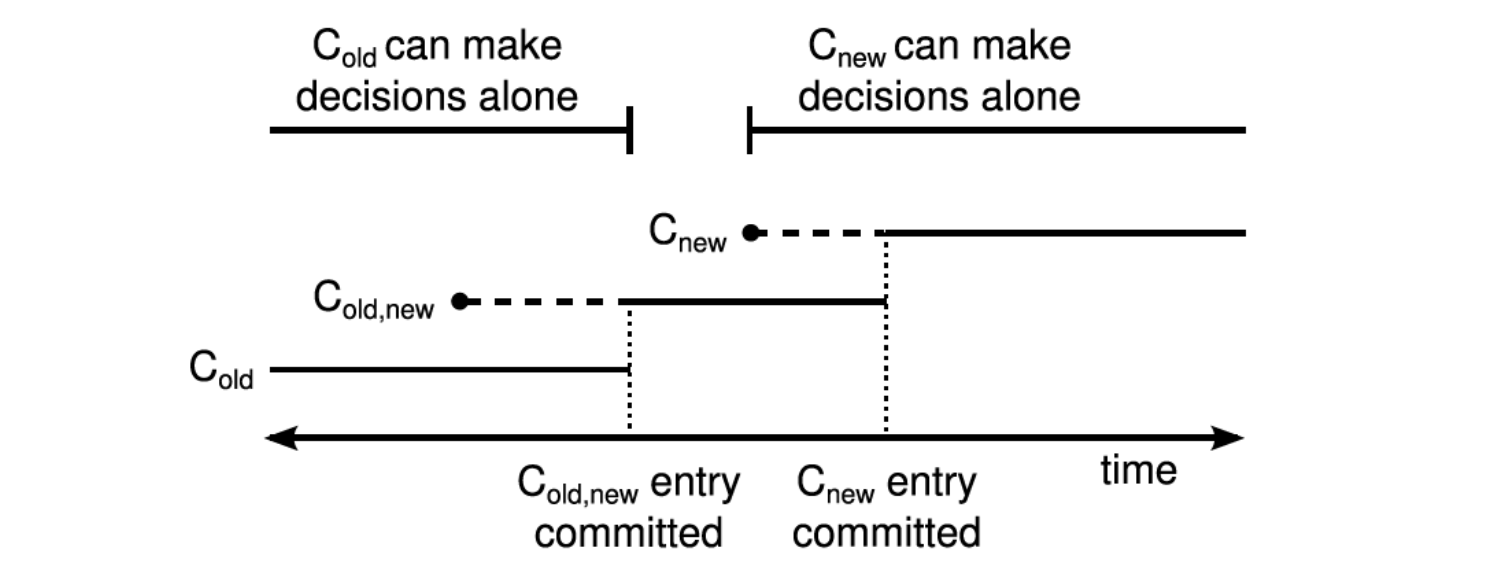
對於同時變更多個節點的情況, Raft提供了多節點的聯合共識演演算法,這裡採用了兩階段提交的思想。
主要步驟分為下面三步:
-
Leader收到Cnew的成員變更請求,然後生成一個Cold,new的ConfChang紀錄檔,馬上應用該紀錄檔,然後將紀錄檔通過AppendEntries請求複製到Follower中,收到該ConfChange的節點馬上應用該設定作為當前節點的設定。
-
在將Cold,new紀錄檔複製到大多數節點上時,那麼Cold,new的紀錄檔就可以提交了,在Cold,new的ConfChange紀錄檔被提交以後,馬上建立一個Cnew的ConfChange的紀錄檔,並將該紀錄檔通過AppendEntries請求複製到Follower中,收到該ConfChange的節點馬上應用該設定作為當前節點的設定。
-
一旦Cnew的紀錄檔複製到大多數節點上時,那麼Cnew的紀錄檔就可以提交了,在Cnew紀錄檔提交以後,就可以開始下一輪的成員變更了。
這裡有幾個概念比較拗口,這裡解釋一下:
-
Cold,new:這個設定是指Cold,和Cnew的聯合設定,其值為Cold和Cnew的設定的交集,比如Cold為[A, B, C], Cnew為[B, C, D],那麼Cold,new就為[A, B, C, D]
-
Cold,new的大多數:是指Cold中的大多數和Cnew中的大多數。
結合下面的圖,我們可以走一遍整個叢集的變更過程,在多點聯合共識的規則之下,每一個任期之中不會出現兩個Leader。
-
Cold,new紀錄檔在提交之前,在這個階段,Cold,new中的所有節點有可能處於Cold的設定下,也有可能處於Cold,new的設定下,如果這個時候原Leader宕機了,無論是發起新一輪投票的節點當前的設定是Cold還是Cold,new,都需要Cold的節點同意投票,所以不會出現兩個Leader。也就是old節點不可能同時follow兩個leader。
-
Cold,new提交之後,Cnew下發之前,此時所有Cold,new的設定已經在Cold和Cnew的大多數節點上,如果叢集中的節點超時,那麼肯定只有有Cold,new設定的節點才能成為Leader,所以不會出現兩個Leader
-
Cnew下發以後,Cnew提交之前,此時叢集中的節點可能有三種,Cold的節點(可能一直沒有收到請求), Cold,new的節點,Cnew的節點,其中Cold的節點因為沒有最新的紀錄檔的,叢集中的大多數節點是不會給他投票的,剩下的持有Cnew和Cold,new的節點,無論是誰發起選舉,都需要Cnew同意,那麼也是不會出現兩個Leader
-
Cnew提交之後,這個時候叢集處於Cnew設定下執行,只有Cnew的節點才可以成為Leader,這個時候就可以開始下一輪的成員變更了。
參考:
歡迎關注公眾號【碼老思】,第一時間獲取通俗易懂的原創技術乾貨。