這篇文章整理自MySQL官方檔案,介紹了8.0在預寫式紀錄檔上實現上的修改,我把核心觀點總結如下:
在8.0以前,為了保證flush list的順序,redo log buffer寫入過程需要加鎖,無法實現並行,高並行的環境中,會同時有非常多的min-transaction(mtr)需要拷貝資料到Log Buffer,如果通過鎖互斥,那麼毫無疑問這裡將成為明顯的效能瓶頸。
為此,從MySQL 8.0開始,設計了一套無鎖的寫log機制,其核心思路是引入recent_written,允許不同的mtr,同時並行地寫Log Buffer的不同位置。
1、寫入RedoLog存在效能瓶頸
預寫紀錄檔 (WAL) 是資料庫最重要的元件之一,對資料檔案的所有更改都記錄在 WAL 中(在 InnoDB 中稱為Redo紀錄檔),並且推遲將修改的頁面重新整理(Flushed)到磁碟的時間,同時仍然防止資料丟失。
在寫入Redo紀錄檔時,資料密集型寫入服務的效能受到執行緒同步的限制會明顯下降。在具有多個 CPU 核心和快速儲存裝置(例如現代 SSD 磁碟)的伺服器上測試效能時,這一點尤為明顯。

我們需要一種新的設計來解決我們的客戶和使用者現在和將來面臨的問題。通過新設計,我們希望確保它可以與現有 API 一起使用,最重要的是不會破壞 InnoDB 其餘部分所依賴的契約,在這些限制條件下,這是一項具有挑戰性的任務。
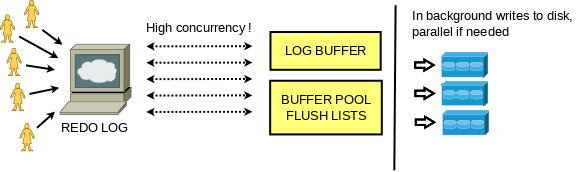
重做紀錄檔可以看作是一個生產者/消費者持久化佇列。執行更新的使用者執行緒可以看作是生產者,當 InnoDB 必須進行崩潰恢復時,恢復執行緒就是消費者。 InnoDB服務在預期內正常工作時不需要讀取Redo log。
2、多執行緒寫Redo紀錄檔的順序問題
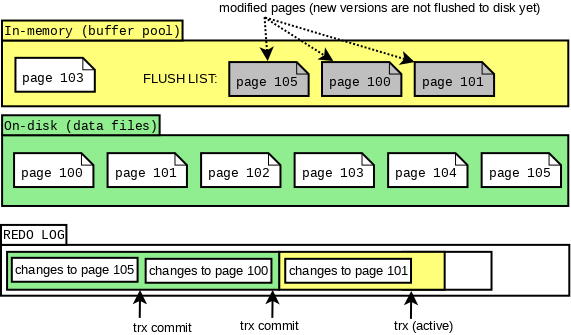
實現具有多個生產者的寫紀錄檔可延伸模型只是問題的一部分。還有一些 InnoDB 特定的細節也需要起作用。最大的挑戰是保持buffer pool中flush list上的髒頁要滿足按照LSN遞增排布。
首先, 一個buffer pool範例維護一個flush list, 由mtr(mini transaction)負責原子的應用對物理頁的修改, 因此, mtr是InnoDB對物理檔案操作的最小事務單元。 redo log由mtr產生, 通常先寫在mtr的cache裡, 在mtr提交時, 將cache中的redo log刷入log buffer(公共buffer), 同時遞增全域性維護的紀錄檔編號(LSN, Log Sequence Number)。
隨後Mtr負責將修改的髒頁(或一列表髒頁)加入到flush list上, 且滿足flush list上的髒頁是按照LSN遞增排序的。
在8.0之前的實現中, 我們通過加內部鎖log_sys_t::mutex 和 log_sys_t::flush_order_mutex 來保證flush list上頁按照寫log buffer 拿到的LSN有序。

因此, 8.0前的工作方式如下: 某個mtr將髒頁輸入flush list時, 會持有鎖flush_order_mutex, 這時, 即便另外一個執行緒A需要新增髒頁到其他bp(buffer pool)的flush list, 也必須陷入等待。 這種情況下, 這個線A程通過持有log_sys_t::mutex, 阻塞其他執行緒寫log buffer。 單純移除這兩個鎖結構, 會使得flush list中LSN遞增的約束不工作
3、解決log buffer上的LSN可能不連續
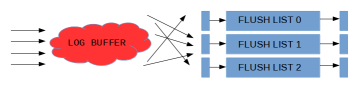
我們還面臨的第二個問題是, 由於各個事務可以交叉拷貝redolog 到 log buffer中, log buffer上的LSN可能存在空洞(如下圖所示), 所以log buffer是不可以一口氣flush full log buffer。
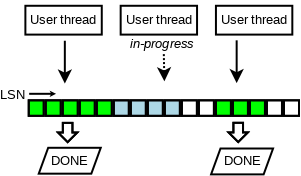
我們通過跟蹤已經完成的寫log buffer操作(如下圖所示的)來解決第二個問題。
在設計上我們引入一個新的無鎖資料結構(元素排列與原先log buffer對應關係如下圖)。
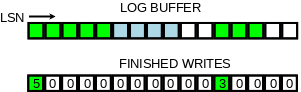
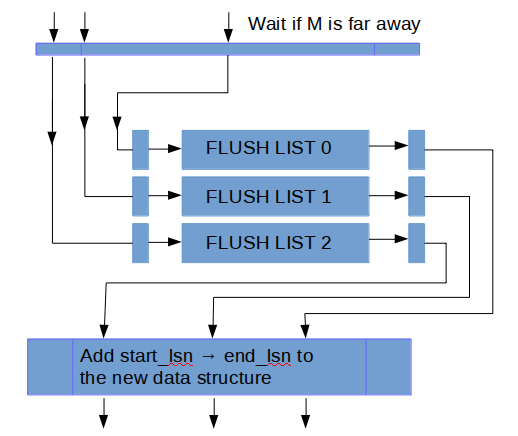
資料結構如下圖所示。 首先這是一個定長陣列, 並且保證陣列元素(slot)更新是原子的, 以環形形式複用已經釋放的空間(所以是個環形陣列啊哈)。 並啟用單獨的執行緒負責陣列的遍歷和空間回收, 執行緒在遇到空元素(empty slot)時暫停。 因此這個thread中還維護了這個資料結構中的最大可達LSN, 我們假設值為M。
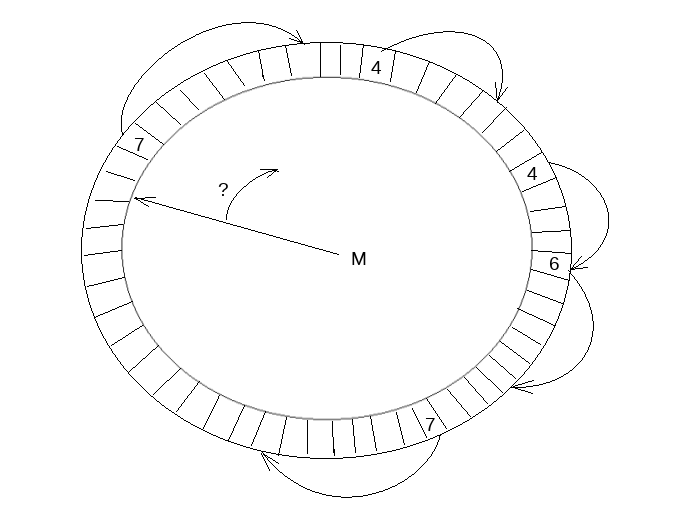
我們引入了這個資料結構的兩個變數: recent_written 和 recent_closed。 recent_written 維護寫log buffer的完成狀態, recent_written中維護的最大LSN, M表示, 所有小於這個M的LSN都已經將它的redo log寫入log buffer。 而這個M也是(如果這下crash, 可能會觸發的)崩潰恢復的截止位點, 同時也是下一個寫log buffer操作的開始位點。
刷log buffer到磁碟和遍歷recent_written是交由一個執行緒完成, 因此對log buffer的記憶體讀寫操作通過recent_written上順序存取元素(slots)形成的屏障保證。
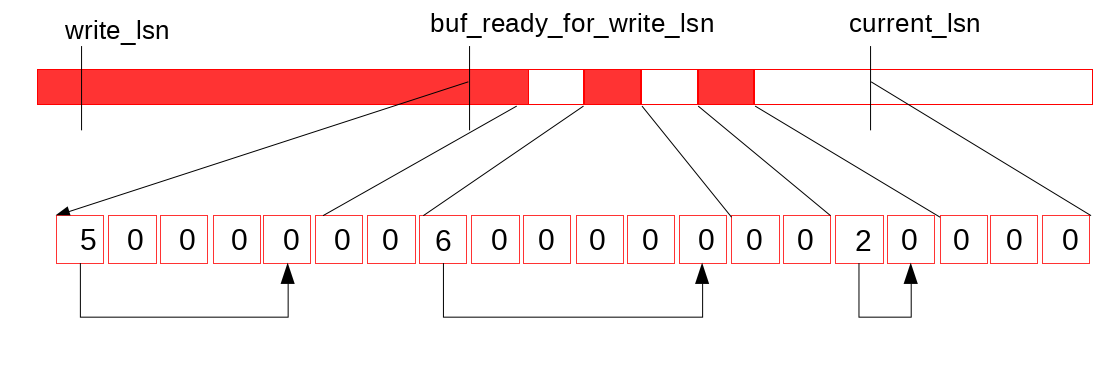
假設當前log buffer和recent_written狀態如上圖所示, 然後完成了一次buffer log 寫, 使得log buffer狀態如下圖所示。

log buffer狀態更新觸發特定執行緒(log_writter)向後掃描recent_written, (如下圖)
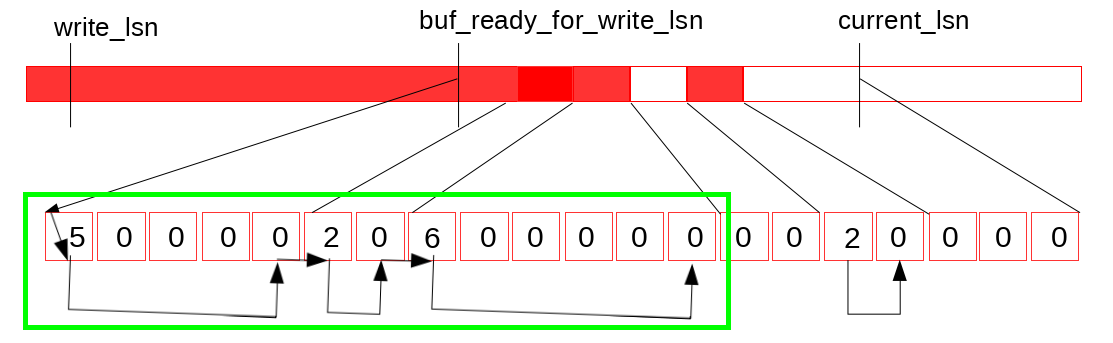
然後更新它維護的最大可達LSN值(可以保證無空洞的), 寫入到變數buf_ready_for_write_lsn (這個變數顧名思義 XD)

我們還引入另一個無鎖結構體的變數recent_closed, 用來完成原先log_sys_t::flush_order_mutex鎖所作的工作, 用來維護flush list的LSN遞增性質。 在介紹實現細節前, 我們還需要解釋一些細節來, 才能清晰的闡釋圖和使用無鎖結構維護(flush list/bp)整體的LSN單調。
4、使用CheckPoint保證flush list正確
那麼首先, 每個bp中的flush list有專門的內部鎖保護。 但是我們已經移除了了鎖結構log_sys_t::flush_order_mutex, 這就使得並行寫flush list的LSN遞增性質保證不了。
雖然如此, flush list正確工作仍然必須滿足以下兩個原生約束:
- Checkpoint - 對於檢查點推進的約束: 假設存在髒頁P1, LSN = L1, 髒頁P2, LSN = L2, 如果L2 > L1, 且P1髒頁未落盤, 不允許重新整理L2對應的髒頁到磁碟。
- FLushing - flush list 上刷髒策略約束: 每次flush必須從oldest page(即, page對應的LSN最小)開始。 這個操作保證最早被修改的也最先從flush list更新到磁碟, 同時還向後推進checkpoint_lsn。
新引入的無鎖結構recent_closed, 用來跟蹤並行寫flush list的狀態, 同時也維護一個最大LSN, 我們標記為M, 滿足, 小於當前LSN的髒頁都已經加入到flush list中。
只有在M值與當前執行緒不那麼遠的時候, 才能將它的髒頁刷flush list。 線上程將髒頁寫入flush list後, 更新recent_closed中的狀態資訊。