架構師日記-如何寫的一手好程式碼
作者:京東零售 劉慧卿
一 前言
在日常工作中,我經常聽到部分同學抱怨程式碼質量問題,潛臺詞是:「除了自己的程式碼,其他人寫的都是垃圾,得送到絞刑架上,重構!」。今天就來聊一聊,如何寫的一手好程式碼。要回答這個問題之前,得先弄清楚一個問題,好程式碼的標準是什麼?易閱讀,可延伸,高內聚,低耦合,程式設計正規化,設計原則......,要求不少,卻很難度量。實則程式碼和文章一樣,正所謂文無第一,武無第二。
這裡不打算從規則寶典,最佳實踐等方面入手,因為那將陷入到無數的規則細節中去,容易不得要領。這也是很多同學,學了很多當下最新技術,掌握了N門程式語言,卻始終沒有明顯提升的原因。對於技術而言,底層的原理和執行規律是根本,它和程式語言,語法等應用層的重要程度是不一樣的,切記不要進入這個誤區。
技能的掌握一般需要經歷學習、模仿、思考、創新四個過程,下面就分幾個階段來探討一下,到底該如何快速學習成長。
二 學習出來的程式碼
學習意識
如果說人生有什麼捷徑,尋找前人走出來的路,就算是捷徑了吧。前人需要花了幾年,甚至窮其一生研究的成果,擺在那裡,用還是不用?答案應該是肯定的,接下來要做的,只是如何把它們找出來,結合當下的情形,在眾多的解決方案中選出行之有效的就可以了。 Henry Spencer曾說:「不懂 Unix 的人註定最終還要重複發明一個撇腳的 Unix」。
所以有必要建立這種意識:有效的學習是降低目標成本的最佳策略之一。這比自己摸著石頭過河,在時間成本上,會有很大的節省,這還沒考慮物質和精力上的投入,各種試錯,就更划算了。
選擇榜樣
既然是取經學習,就要學習優秀的,成功的經驗,如此,相同的精力投入,獲得的回報往往更高。半路出家,或者正在和你同行的都不是好的選擇,你不知道他們最終會不會誤入歧途。所以選擇榜樣時,一定要跳出圈子,去找你能找到的最優質的的那些,你的選擇可以涵蓋歷史上,行業裡,公司中各個維度。
學習的過程中,帶著批判的思維去消化,只有這樣才能改進創新,所有的金科玉律都有其限定範圍,當限定邊界打破了,之前的正確性,就值得你去懷疑。舉個例子,很多編碼規範裡都有那麼一條:「一行程式碼長度,不超過80個字元」。
它的來歷是這樣的:在很久很久以前,有一個很流行的人機互動介面(終端) 叫 VT100,用來處理字元/文字,後來其它的很多終端都是以它為標準。這個終端螢幕24行、80列,編輯器選單還佔了 4 行。所以,程式碼編寫建議是一個邏輯的處理程式碼,20行最佳、每行字元長度不超過80列。目的就是為了可視性(目之所能及)、可維護性。而如今顯示終端的解析度普遍提高了,所以升級調整規範並無不可,比如:「每行 120 個字元,每個函數體程式碼 80 行以內」。
所以,很多歷史經驗,瞭解其背後的執行邏輯,才能發揮出它原本的作用。
學以致用
大家常說萬事開頭難,究竟難在哪裡?難在決心上,難在門檻上。決心可以通過痛點和目標來牽引,門檻可以通過目標拆解來降低。高質量的完成某件事情,有很多科學的工具和方法,比如:PDCA迴圈,SMART原則等,有興趣的,可以拓展學習。
這裡想要表達的是,擁有痛點和目標是能夠持之以恆的前提,因為在學習實踐的過程中,能夠練習中進行應用,並能獲得真實反饋和回報,這是能夠堅持精進的原動力。否則就容易陷入,類似我們背誦四級應用單詞‘’「abandon」的魔咒,也不知道從它開始背誦了多少遍了。
再舉個例子,我們需要做系統模組解耦,調研下來,使用訊息佇列MQ中介軟體,能夠很好的解決我們目前面臨的問題。
-
第一步,開始學習有關MQ的知識,瞭解各種MQ中介軟體的適用場景,結合使用場景,給出具體中介軟體的選型;
-
第二步,將MQ中介軟體引入到我們的系統中。使用的過程,就是一個不斷髮現問題,研究原因,修復問題,總結經驗的過程。
如果沒有真實的應用場景,往往會始終停留在第一步,反覆開始,直到失去耐心,最終放棄。
小結
想要寫好程式碼,需要有學習的意識,至少能夠知道什麼樣的程式碼是好的,什麼樣的程式碼是有改進空間的。這種判斷能力,需要通過不斷的閱讀各種型別的程式碼,從中找出榜樣。資料的來源可以是經典書籍,好的開源專案,甚至是你身邊的優秀專案。同時也需要規避一些誤區:
-
工作上遇到的大部分問題,只要去尋找,都是有解決方案的。需要親自下場試錯,創造答案的場景,很少;
-
經驗都是有適用邊界的,照搬的經驗不一定就適合我們,這需要了解經驗背後的支撐邏輯,靈活的做出調整;
-
學習目標的選擇是需要時機的,要有合適的實踐場景,否則,往往會事倍功半,甚至半途而廢;
三 模仿出來的程式碼
認知陷阱
所謂程式碼模仿,不是簡單的照貓畫虎。而是遇到問題了,可以基於之前的學習積累,能夠快速的找到優秀的解決方案,並加以利用。可以是一個技術點,可以是一種模式策略,可以是一種解決方案,甚至是一種程式設計思想。
這個階段通常處於認知模型的第二層:「知道自己不知道」。也是突破認知極限,快速成長的階段。直觀感受就是一個問題接一個問題,一個概念接一個概念,要理解和學習的知識太多了。這對個人的毅力和耐心是一個考驗,很多人就是在這個階段進入認知陷阱,最終轉行了。
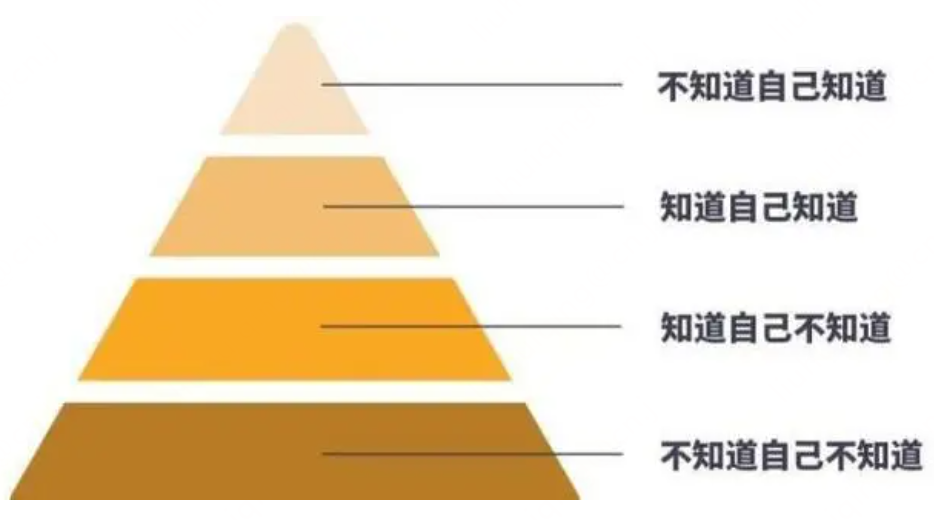
以終為始
在實踐過程中,會面臨著要學的知識,要補的課,太多了:「計算機網路,應用服務,資料儲存......」。計算機網路又包含運營商,光纖,電纜,域名,cdn,交換機,代理服務,http協定,使用者端,瀏覽器,對談...,每一個節點又可以往下拆下去,感覺沒有盡頭。
是需要全部弄懂再去動手嗎?我到底是要做一個專才,還是成為一個全才?這個問題還要以發展的眼光來看。下面就以市場人才發展觀為例,展開探討一下。
• T型人才
現實中往往是「T型人才」比較受用,"一"表示有廣博的知識面,"|"表示知識的深度。兩者的結合,就是傳說中的一專多能。特別是大公司,員工崗位分工比較細,像螺絲釘一樣,只要做好眼前的事情就好了。如果專之外加上多能,在橫向上具備比較廣泛的一般性知識修養,而且在縱向的專業知識上具有較深的理解能力和獨到見解,就有了較強的創新能力。
• π型人才
我們知道,由於行業的快速迭代,疊加各種不確定性,有些崗位的合理性受到不同程度的挑戰,失去競爭力,遭遇下崗的境遇。業內又喊出了「π型人才」的概念。
π型人才是源於新加坡的一種人才觀,在T型人才的基礎上,進一步進化。π比T多出來的一豎,一般是源於興趣愛好或工作所需,孵化出來的第二事業線。「兩條腿走路」,勢必有更強的抗風險能力,和更強的市場變化應對能力。
• 梳子型人才
梳子型人才更加形象了,多條腿走路,即在多個專業有深入的專業知識,同時在頂層保持一個終身學習的習慣。它代表著強大的底層思維和邏輯能力,它決定了你是否具有知識遷移能力,一定要先夯實它,否則很容易變成三天打魚兩天曬網。
人的精力和能力是有限的,機會也不是人人都能碰上的,所以梳子型人才往往不是我們的第一目標。我們可以先從T型人才開始努力,時機成熟之後再往π型,甚至梳子型人才上邁進。
以終為始,才能看得清腳下的路。對於技術的學習和應用也是如此,當前需要什麼,就學習什麼,深挖什麼。有餘力了,機會來了,就可以主動轉身,再創輝煌。
小結
學習實踐階段處於比較吃力的爬坡過程。考驗的是對實現目標的毅力和決心,認識到這一點至關重要。技術的研究方向,深入程度,還是建議循序漸進,結合實際應用場景,先在當前領域扎深扎透,再伺機發展,多條腿並行。
四 設計出來的程式碼
程式設計思維
所謂程式設計思維,就是「理解問題,找出路徑」的思維過程,它由分解、圖形識別、抽象、演演算法四個步驟組成。
-
一個複雜問題會先被拆解成一系列好解決的小問題;
-
每一個小問題被單獨檢視、思考,搜尋解決方案;
-
聚焦幾個重要節點,忽視小細節,形成解決思路;
-
最後,設計步驟,執行,直至問題解決。
程式設計思維並不是編寫程式的技巧,而是一種高效解決問題的思維方式。
編碼原則
計算機是人造的學科,編碼原則就三個字:好維護。如果考慮目標訴求,可能還可以追加一條:「執行快」,但目前大部分應用場景,計算機效能已經足夠快了,很多時候,第二條往往被忽略掉了。
開閉原則,KISS 原則,組合原則,依賴反轉,單一職責原則等大部分設計原則都是圍繞著這個基本原則展開的。如果你覺得你的編碼設計比較彆扭,老得騰出精力來調整維護,那麼大概率這個設計是不合理的,你得想辦法讓自己從中解放出來。
實際編碼過程中的各種規範約束,比如:程式碼規範,設計模式,紀錄檔列印規範,例外處理策略,介面設計規範,圈複雜度等,參照基本編碼原則去理解,就能想的通了。
抽絲剝繭
所有的技巧都是建立在熟悉的基礎上,對於程式設計師來說,就是程式碼。閱讀海量的程式碼,編寫海量的程式碼,在這個過程中,不斷的改進調優,是練就硬功夫的前提。下面就以案例的形式,為大家展現一下該如何閱讀原始碼,藉此提升自己的設計能力。
案例是取自RocketMQ開源專案,你能想象下面這段程式碼為什麼這麼寫嗎?

程式碼出處:org.apache.rocketmq.store.logfile.DefaultMappedFile#warmMappedFile
• 背景介紹
RocketMQ 使用檔案預熱優化後,在進行記憶體對映後,會預先寫入資料到檔案中,並且將檔案內容載入到 page cache,當訊息寫入或者讀取的時候,可以直接命中 page cache,避免多次缺頁中斷。這個方法的作用就是檔案預熱。
• 提出問題
-
什麼是缺頁中斷,對效能有怎樣的影響?
-
為什麼迴圈次數是4K,為什麼往ByteBuffer中寫0?
-
為什麼Thread.sleep程式碼塊,註釋上寫著:prevent gc?
• 刨根問底
1)先探討第一個問題,關於缺頁中斷的原理,屬於計算機組成原理的範疇,這裡不展開詳細介紹,大概流程可以參照下面這張圖:
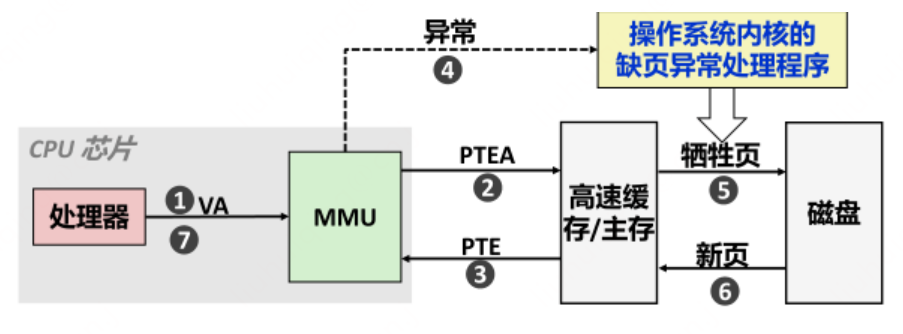
簡單解釋一下這個流程:
• 程序通過CPU存取虛擬地址VA,通過MMU找到對應的實體地址(主記憶體),當記憶體頁在實體記憶體中沒有對應的頁幀或者存在但無對應的存取許可權,在這種情況下,CPU就會報告一個缺頁的錯誤;
• 實體記憶體中沒有對應的頁幀,需要CPU開啟磁碟裝置讀取到實體記憶體中,再讓MMU建立VA和PA的對映;
• 缺頁對效能的影響,也得看具體情況,參照下圖:
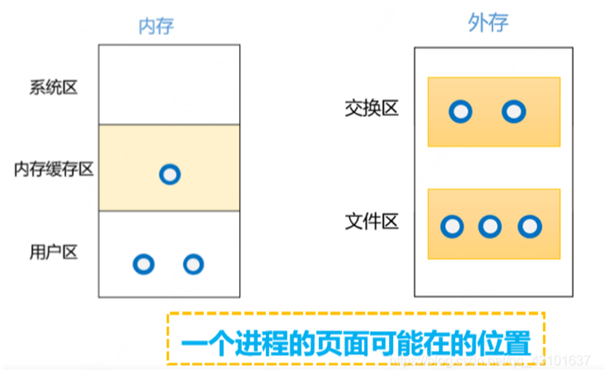
◦ 從磁碟交換區中調入缺頁:百μ s至幾十ms
◦ 從磁碟檔案區中調入缺頁;幾十甚至幾百毫秒
◦ 從磁碟緩衝區中調入缺頁:數百ns
如果不載入任何MappedFile資料至記憶體中的話,按照最壞的影響,1GB的CommitLog需要發生26w多次缺頁中斷。所以通過程式碼設計,減少缺頁的情況出現,會大大提升應用響應效率。 2)我們再來看第二個問題,為什麼迴圈次數是4K,為什麼往ByteBuffer中寫0?
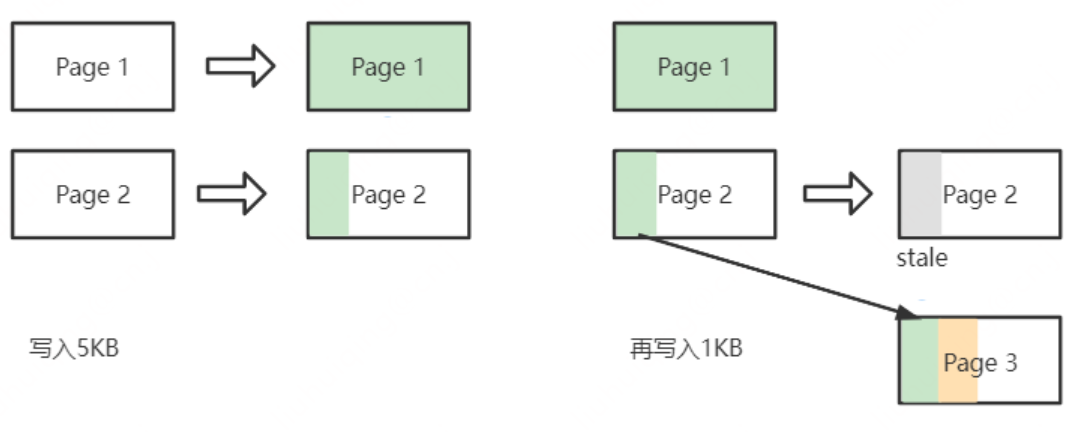
傳統HDD磁區單位一直習慣於512Byte,有些檔案系統預設保留前63個磁區,也就是前512 * 63 / 1024 = 31.5KB,假設快閃記憶體Page和簇(OS讀寫基本單位)都大小為4KB,那麼一個Page對應著8個磁區,使用者資料將於第8個Page的第3.5KB位置開始寫入,導致之後的每一個簇都會跨兩個Page,讀寫處於超界處,這對於快閃記憶體會造成更多的讀損及讀寫開銷。
除了OS層的4K對齊至關重要以外,在檔案寫入過程中仍然需要關注4K對齊的問題。假設Page大小仍然為4KB,向一個空白檔案寫入5KB資料,此時需要2個Page來儲存資料,Page 1寫滿了4KB,而Page2只寫入1KB,當再次向檔案順序寫入資料時,需要將Page2資料預先讀出來,然後與新寫入資料在記憶體中合併後再寫入新的Page 3中,之前的Page 2則標記為 stale 等待被GC。這種帶來的開銷被稱為寫入放大WA(Write Amplification)。為了防止寫入放大的情形出現,我們會提前將Page空間,用0填充寫滿。
3)最後,我們再來看第三個問題,為什麼Thread.sleep程式碼塊,註釋上寫著:prevent gc?
這段程式表達的意思很容易理解,每執行1000次迴圈,執行一次Thread.sleep(0)語句。但背後的目的確沒那麼明顯。即Thread.sleep(0)可以讓執行緒進入 Safepoint,從而觸發GC。
這就得了解一下安全點(Safepoint),使用者程式執行時,並非在程式碼指令流的任意位置都能夠停頓下來,開始垃圾收集,而是強制要求必須執行到達安全點後才能夠暫停。意思就是在可數迴圈(Counted Loop)的情況下,HotSpot 虛擬機器器有一個優化,就是等迴圈結束之後,執行緒才會進入安全點。程式碼中int型別就屬於可數迴圈,當然Long型別屬於不可數迴圈。
總結一下,這段程式碼的目的就是,在預熱資料的時候,每寫入1000個位元組,讓該執行緒立即從執行階段進入就緒佇列,釋放CPU時間,可以讓作業系統切換其他執行緒來執行,比如GC執行緒的執行。這也側面的反映出系統設計者對資料響應效率的追求,通過人工介入GC頻率,防止出現超長時間GC情況的出現,影響瞬時的吞吐效率。
小結
程式編寫,按照不同的維度視角,有很各種各樣的原則和建議。其本質還是以下兩個方面:
-
著眼於人:容易維護;
-
著眼於機器:運算速度快;
清楚的認識到程式本質,是能夠進行創新的基礎。
最後,通過一個實際案例,簡單的展現了一下如何閱讀程式碼,以及如何從別人的程式碼中學習程式設計,其核心還是要有刨根問底的好奇心,擁有舉一反三的思考與沉澱。
五 重構出來的程式碼
認識重構
重構(Refactoring)就是通過調整程式程式碼改善軟體的質量、效能,使其程式的設計模式和架構更趨合理,提高軟體的擴充套件性和維護性。更廣義的理解,就是打破原有的組織形式,按照新的標準進行重新組合。
從理論和實際經驗來講,系統或程式碼的重構往往是個人能力實現快速提升的良好契機。相同條件下,有重構經驗的同學和沒有重構經驗的同學,對很多概念和規則的理解深度會有很大區別。這就是典型的習得性經驗,通過教學很難掌握。生活場景中的游泳,騎自行車就是習得性經驗的代表。
關於重構相關的要點,以思維導圖的方式呈現,如下圖:

獨當一面
現實情況中,整個團隊梯隊建設一般是金字塔型的,即高中低職級的同學一起對專案負責。不同職級的同學,對技術的要求和標準也不一樣,要都按照高標準來執行,對低職級的同學顯然是不公平的,反之也是一樣。所以如何解決這個矛盾,是我們不得不面對的問題。
抓大放小,就是要按照業務區分核心和非核心,流程區分上游和下游,系統區分0級和n級......,重要的儘量按照高標準來執行,一般的按照普通標準來執行,並投入與之相匹配的資源。舉個例子,比如,B端的某些運營工具,我們對它的QPS,可用率要求和C端使用者的是不一樣的,影響決策的依據是邊際成本和收益。
• 常見誤區一:對效能優化的執念。「優秀的程式設計師應該榨乾每一位元組記憶體」,聽起來很有道理,不是嗎?但經濟學上來講,邊際效應決定了一次專案中,越優化價效比越低。有一個很容易被忽略的事實:硬體其實比程式設計師要便宜。
• 常見誤區二:對設計模式的崇拜。設計模式當然是好東西,但如果像強迫症一樣使用它們,就會導致按圖索驥,強行讓問題去適應設計模式,而不是讓解決方案針對問題,這就本末倒置了。
所謂「甲之蜜糖,乙之毒藥」。對於某款產品,穩定性,高吞吐就是其立身之本,直接影響著市場份額和收益,那麼投入精力去做效能優化就是划算的。如果你的產品是一個提效工具,對程式碼的效能和擴充套件性,往往就沒有那麼高的要求,過於苛求反而沒有必要。
小結
重構雖然對個人和業務都是有莫大好處,但考慮到實際成本問題,很多重構都是沒有必要的。總結一下重構的要點:
◦ 重構的前提:重構是為了滿足業務訴求而不得不做的最佳方案;
◦ 重構的最大風險就是:低估了實施難度。考慮相容現有業務,同時支撐好未來規劃。負重前行,要比重啟新專案要複雜的多,如果新專案的難度是0到1,那麼重構就是從-1到1;
◦ 重構最大難度是:目標制定和過程管理。
「知道自己知道」,就會對技術會有一些自己的思考和創新,不容易的人云亦云,能夠基於現狀和目標,做出決策,即所謂的獨當一面。
六 總結
本文主要從如何快速學習掌握編碼技能展開,強調了認知對學習的重要性,提出了選擇方向,樹立榜樣,學以致用等學習路徑。同時針對成長過程中遇到的困惑和職業發展方向,做了闡述,借事成長,擇時出發,避免進入一些認知誤區。以程式碼閱讀案例,直觀的展現瞭如何在程式碼閱讀中學習和思考。最後,介紹了重構的意義和部分原則。總體上,是按照學習成長路線來進行闡述的,希望能夠減少我們路上,那些成長的煩惱!
注:本文部分圖片和案例來自網上