使用 diffusers 訓練你自己的 ControlNet 🧨
簡介
ControlNet 這個神經網路模型使得使用者可以通過施加額外條件,細粒度地控制擴散模型的生成過程。這一技術最初由 Adding Conditional Control to Text-to-Image Diffusion Models 這篇論文提出,並很快地風靡了擴散模型的開源社群。作者開源了 8 個不同的模型,使得使用者可以用 8 種條件去控制 Stable Diffusion 模型(包括版本 1 到 5 )。這 8 種條件包括姿態估計、深度圖、邊緣圖、素描圖 等等。

在這篇部落格中,我們首先介紹訓練 Uncanny Faces model 的步驟。這是一個基於 3D 合成人臉的人臉姿態模型(這裡的 uncanny faces 只是一個無意得到的結果,後面我們會講到)。
開始著手用 Stable Diffusion 訓練你的 ControlNet
訓練你自己的 ControlNet 需要 3 個步驟:
-
設計你想要的生成條件: 使用 ControlNet 可以靈活地「馴服」 Stable Diffusion,使它朝著你想的方向生成。預訓練的模型已經展示出了大量可用的生成條件,此外開源社群也已經開發出了很多其它條件,比如這裡 畫素化的色彩板。
-
構建你自己的資料集: 當生成條件確定好後,就該構建資料集了。你既可以從頭構建一個資料集,也可以使用現有資料集中的資料。為了訓練模型,這個資料集需要有三個維度的資訊: 圖片、作為條件的圖片,以及語言提示。
-
訓練模型: 一旦資料集建好了,就可以訓練模型了。如果你使用 這個基於 diffusers 的訓練指令碼,訓練其實是最簡單的。這裡你需要一個至少 8G 視訊記憶體的 GPU。
1. 設計你想要的生成條件
在設計你自己的生成條件前,有必要考慮一下兩個問題:
- 哪種生成條件是我想要的?
- 是否已有現存的模型可以把正常圖片轉換成我的條件圖片?
舉個例子,假如我們想要使用人臉特徵點作為生成條件。我們的思考過程應該是這樣: 1. 一般基於特徵點的 ControlNet 效果都還挺好。2. 人臉特徵點檢測也是一個很常見的任務,也有很多模型可以在普通圖片上檢測人臉特徵點。3. 讓 Stable Diffusion 去根據特徵點生成人臉圖片也挺有意思,還能讓生成的人臉模仿別人的表情。

2. 構建你自己的資料集
好!那我們現在已經決定用人臉特徵點作為生成條件了。接下來我們需要這樣構建資料集:
- 準備 ground truth 圖片 (
image): 這裡指的就是真實人臉圖片 - 準備 條件圖片 (
conditioning_image): 這裡指的就是畫出來的特徵點 - 準備 說明文字 (
caption): 描述圖片的文字
針對這個專案,我們使用微軟的 FaceSynthetics 資料集: 這是一個包含了 10 萬合成人臉的資料集。你可能會想到其它一些人臉資料集,比如 Celeb-A HQ 和 FFHQ,但這個專案我們決定還是採用合成人臉。

這裡的 FaceSynthetics 資料集看起來是個不錯的選擇: 它包含了真實的人臉圖片,同時也包含了被標註過的人臉特徵點(按照 iBUG 68 特徵點的格式),同時還有人臉的分割圖。

然而,這個資料集也不是完美的。我們前面說過,我們應該有模型可以將真實圖片轉換到條件圖片。但這裡似乎沒有這樣的模型,把人臉圖片轉換成我們特徵點標註形式(無法把特徵點轉換為分割圖)。

所以我們需要用另一種方法:
- 使用
FaceSynthetics中的真實圖片 (image) - 使用一個現有的模型把人臉圖片轉換為 68 個特徵點的形式。這裡我們使用 SPIGA 這個模型
- 使用自己的程式碼把人臉特徵點轉換為人臉分割圖,以此作為「條件圖片」 (
conditioning_image) - 把這些資料儲存為 Hugging Face Dataset
這裡 是將真實圖片轉換到分割圖的程式碼,以及將資料儲存為 Hugging Face Dataset 的程式碼。
現在我們準備好了 ground truth 圖片和「條件圖片」,我們還缺少說明文字。我們強烈推薦你把說明文字加進去,但你也可以試試使用空的說明文字來看看效果。因為 FaceSynthetics 資料集並沒有自帶說明文字,我們使用 BLIP captioning 去給圖片加上文字(程式碼在這裡)。
至此,我們就完成了資料集的構建。這個 Face Synthetics SPIGA with captions 資料集包含了 ground truth 圖片、條件圖片,以及對應的說明文字,總計有 10 萬條資料。一切就緒,我們現在可以開始訓練模型了。

3. 模型訓練
有了 資料,下一步就是訓練模型。即使這部分很難,但有了 下面的指令碼,這個過程卻變成了最簡單的部分。我們用了一個 A100 GPU去訓練(在 LambdaLabs 每小時 1.1 美元租的)。
我們的訓練經驗
我們以 batch size 為 4 訓練了 3 個 epoch。結果表明此策略有些太激進,導致結果出現過擬合現象。模型有點忘記人臉的概念了,即使提示語中包含「怪物史萊克」或「一隻貓」,模型也只會生成人臉而不是「史萊克」或貓;同時模型也對各種風格變得不敏感。
如果我們只訓練 1 個 epoch (即模型僅學習了 10 萬張照片),模型倒是能遵循輸入的姿態,同時也沒什麼過擬合。看起來還行,但由於我們用的是合成資料,模型最終生成的都是些看起來很 3D 的人臉,而不是真實人臉。當然,基於我們用的資料集,生成這樣的效果也正常。這裡是訓練好的模型: uncannyfaces_25K。
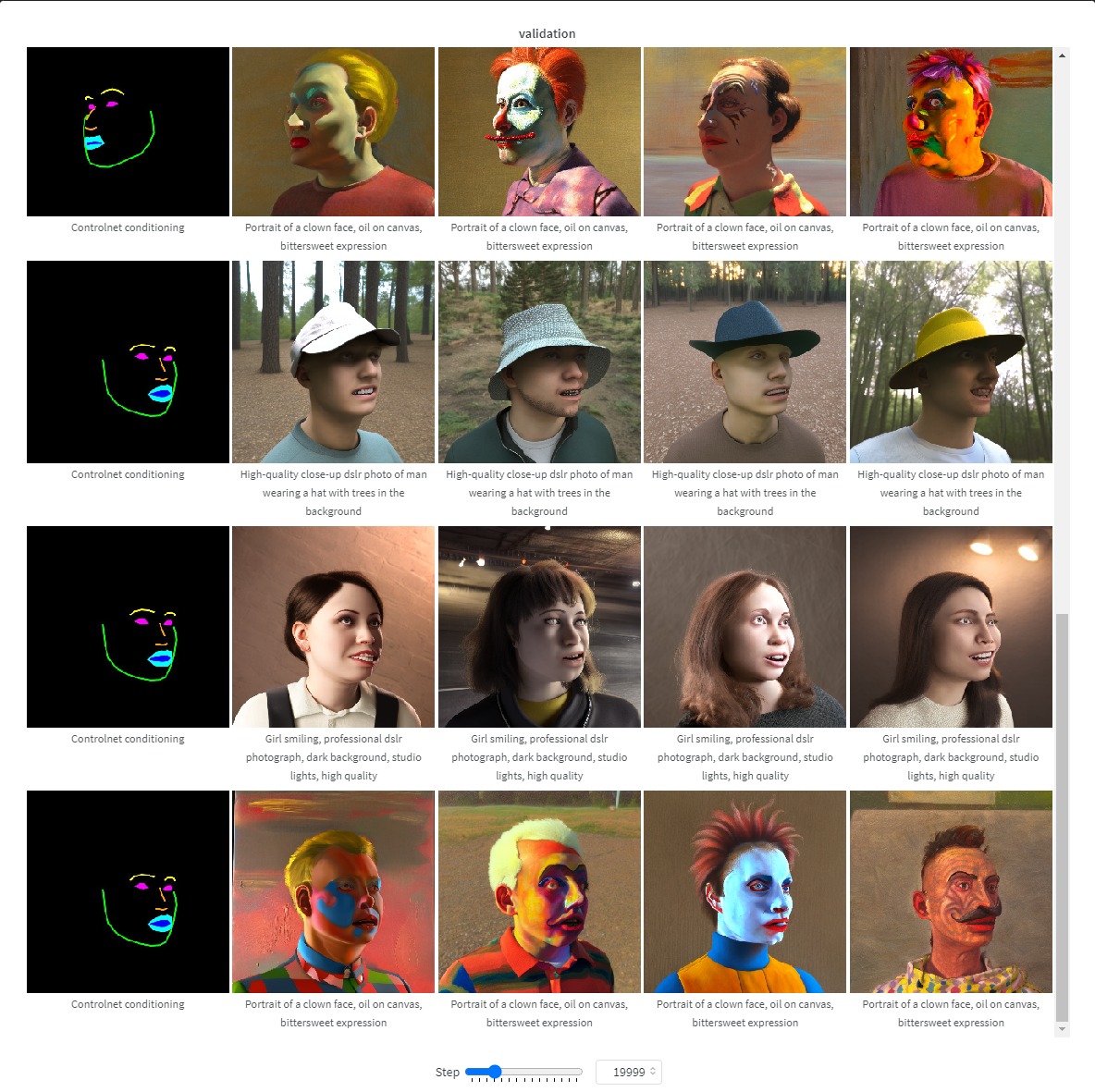
在這張可互動表格 (請存取下面的連結) 中,你可以看看不同步數下模型訓練進度如何。在訓練了大約 15k 步後,模型就已經開始學習姿態了。最終模型在 25k 步後成熟。
訓練具體怎麼做
首先我們安裝各種依賴:
pip install git+https://github.com/huggingface/diffusers.git transformers accelerate xformers==0.0.16 wandb
huggingface-cli login
wandb login
然後執行這個指令碼 train_controlnet.py
!accelerate launch train_controlnet.py \
--pretrained_model_name_or_path="stabilityai/stable-diffusion-2-1-base" \
--output_dir="model_out" \
--dataset_name=multimodalart/facesyntheticsspigacaptioned \
--conditioning_image_column=spiga_seg \
--image_column=image \
--caption_column=image_caption \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./face_landmarks1.jpeg" "./face_landmarks2.jpeg" "./face_landmarks3.jpeg" \
--validation_prompt "High-quality close-up dslr photo of man wearing a hat with trees in the background" "Girl smiling, professional dslr photograph, dark background, studio lights, high quality" "Portrait of a clown face, oil on canvas, bittersweet expression" \
--train_batch_size=4 \
--num_train_epochs=3 \
--tracker_project_name="controlnet" \
--enable_xformers_memory_efficient_attention \
--checkpointing_steps=5000 \
--validation_steps=5000 \
--report_to wandb \
--push_to_hub
我們詳細看看這些設定引數,同時也看看有哪些優化方法可以用於 8GB 以下視訊記憶體的 GPU 訓練。
pretrained_model_name_or_path: 基礎的 Stable Diffusion 模型,這裡我們使用 v2-1 版本,因為這一版生成人臉效果更好output_dir: 儲存模型的目錄資料夾dataset_name: 用於訓練的資料集,這裡我們使用 Face Synthetics SPIGA with captionsconditioning_image_column: 資料集中包含條件圖片的這一欄的名稱,這裡我們用spiga_segimage_column: 資料集中包含 ground truth 圖片的這一欄的名稱,這裡我們用imagecaption_column: 資料集中包含文字說明的這一欄的名稱,這裡我們用image_captionresolution: ground truth 圖片和條件圖片的解析度,這裡我們用512x512learning_rate: 學習率。我們發現設成1e-5效果很好,但你也可以試試介於1e-4和2e-6之間的其它值validation_image: 這裡是讓你在訓練過程中偷窺一下效果的。每隔validation_steps步訓練,這些驗證圖片都會跑一下,讓你看看當前的訓練效果。請在這裡插入一個指向一系列條件圖片的本地路徑validation_prompt: 這裡是一句文字提示,用於和你的驗證圖片一起驗證當前模型。你可以根據你的需要設定train_batch_size: 這是訓練時使用的 batch size。因為我們用的是 V100,所以我們還有能力把它設成 4。但如果你的 GPU 視訊記憶體比較小,我們推薦直接設成 1。num_train_epochs: 訓練模型使用的輪數。每一輪模型都會看一遍整個資料集。我們實驗用的是 3 輪,但似乎最好的結果應該是出現在一輪多一點的地方。當訓練了 3 輪時,我們的模型過擬合了。checkpointing_steps: 每隔這麼多步,我們都會儲存一下模型的中間結果檢查點。這裡我們設定成 5000,也就是每訓練 5000 步就儲存一下檢查點。validation_steps: 每隔這麼多步,validation_image和validation_prompt就會跑一下,來驗證訓練過程。report_to: 向哪裡報告訓練情況。這裡我們使用 Weights and Biases 這個平臺,它可以給出美觀的訓練報告。push_to_hub: 將最終結果推到 Hugging Face Hub.
但是將 train_batch_size 從 4 減小到 1 可能還不足以使模型能夠在低設定 GPU 上執行,這裡針對不同 GPU 的 VRAM 提供一些其它設定資訊:
適配 16GB 視訊記憶體的 GPU
pip install bitsandbytes
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--use_8bit_adam
這裡 batch size 設為 1,同時使用 4 步的梯度累計等同於你使用原始的 batch size 為 4 的情況。除此之外,我們開啟了對梯度儲存檢查點,以及 8 bit 的 Adam 優化器訓練,以此更多地節省視訊記憶體。
適配 12GB 視訊記憶體的 GPU
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--use_8bit_adam
--set_grads_to_none
適配 8GB 視訊記憶體的 GPU
請參考 我們的教學
4. 總結
訓練 ControlNet 的過程非常有趣。我們已經成功地訓練了一個可以模模擬實人臉姿態的模型。然而這個模型更多是生成 3D 風格的人臉圖片而不是真實人臉圖片,這是由於我們使用了合成人臉的資料執行訓練。當然這也讓生成的模型有了獨特的魅力。
試試我們的 Hugging Face Space
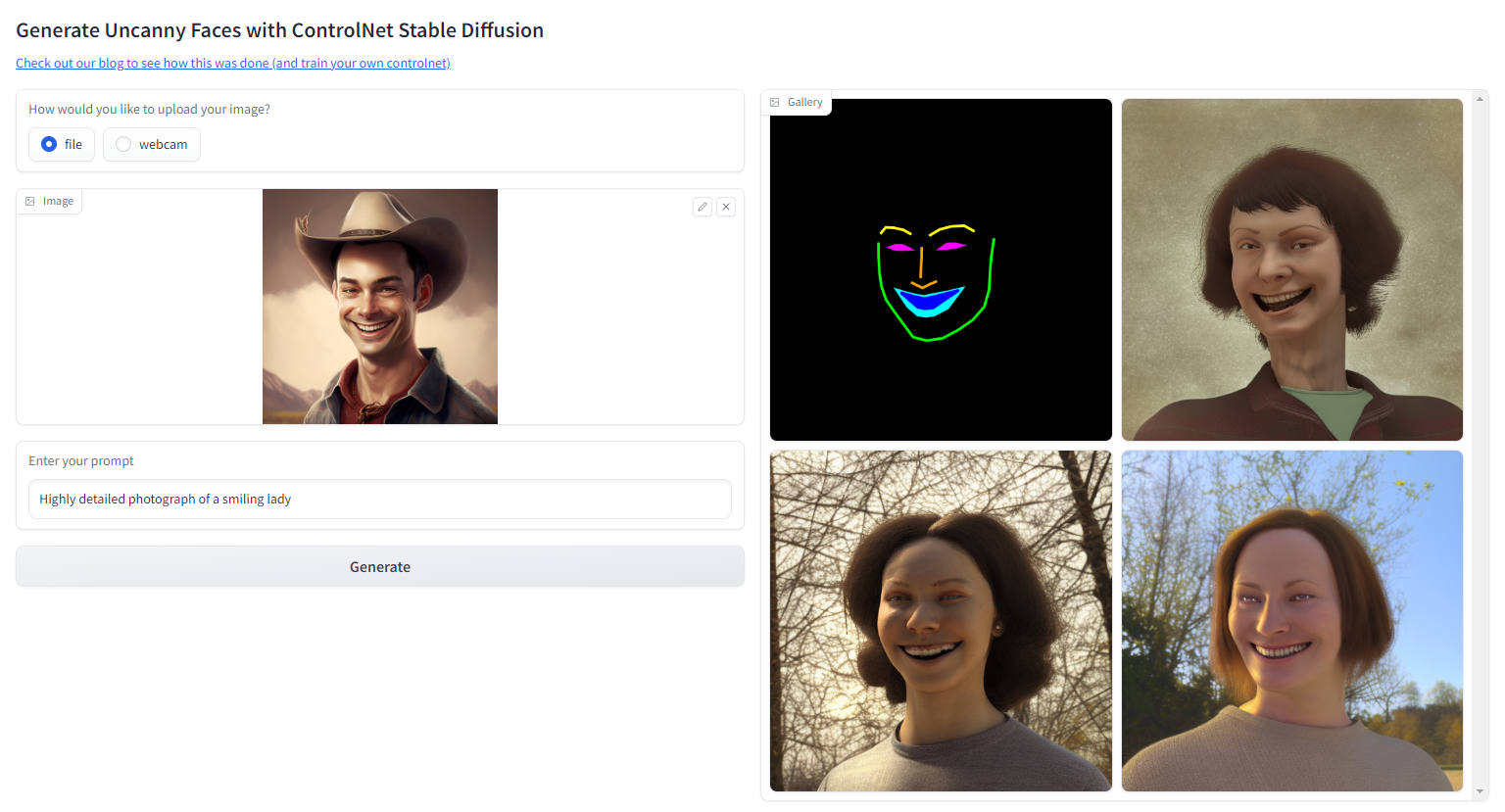
下一步,為了生成真實的人臉圖片,同時還不使用真實人臉資料集,我們可以用 Stable Diffusion Image2Image 跑一遍所有的 FaceSynthetics 圖片,把看起來很 3D 的人臉轉換成真實人臉圖片,然後再訓練 ControlNet。
請繼續關注我們,接下來我們將舉辦 ControlNet 訓練賽事。請在 Twitter 關注 Hugging Face,或者加入我們的 Discord 以便接收最新訊息!
如果您此前曾被 ControlNet 將 Lofi Girl 的動畫形象改成寫實版類真人畫面的能力折服,卻又擔心自己難以承擔高昂的訓練成本,不妨報名參加我們近期的提供免費 TPU 的 ControlNet 微調活動。試試看充滿創造力的你能有什麼樣的大作!
英文原文: https://hf.co/blog/train-your-controlnet
作者: Apolinário from multimodal AI art, Pedro Cuenca
譯者: HoiM Y, 阿東