DataLeap 資料資產實戰:如何實現儲存優化?
更多技術交流、求職機會,歡迎關注位元組跳動資料平臺微信公眾號,回覆【1】進入官方交流群
背景
-
DataLeap 作為一站式資料中臺套件,彙集了位元組內部多年積累的資料整合、開發、運維、治理、資產、安全等全套資料中臺建設的經驗,助力企業客戶提升資料研發治理效率、降低管理成本。
-
Data Catalog 是一種後設資料管理的服務,會收集技術後設資料,並在其基礎上提供更豐富的業務上下文與語意,通常支援後設資料編目、查詢、詳情瀏覽等功能。目前 Data Catalog 作為火山引擎巨量資料研發治理套件 DataLeap 產品的核心功能之一,經過多年打磨,服務於位元組跳動內部幾乎所有核心業務線,解決了資料生產者和消費者對於後設資料和資產管理的各項核心需求。
-
Data Catalog 系統的儲存層,依賴 Apache Atlas,傳遞依賴 JanusGraph。JanusGraph 的儲存後端,通常是一個 Key-Column-Value 模型的系統,本文主要講述了使用 MySQL 作為 JanusGraph 儲存後端時,在設計上面的思考,以及在實際過程中遇到的一些問題。
起因
實際生產環境,我們使用的儲存系統維護成本較高,有一定的運維壓力,於是想要尋求替代方案。在這個過程中,我們試驗了很多儲存系統,其中 MySQL 是重點投入調研和開發的備選之一。
另一方面,除了位元組內部外,在 ToB 場景,MySQL 的運維成本也會明顯小於其他巨量資料元件,如果 MySQL 的方案跑通,我們可以在 ToB 場景多一種選擇。
基於以上兩點,我們投入了一定的人力調研和實現基於 MySQL 的儲存後端。
方案評估
在設計上,JanusGraph 的儲存後端是可插拔的,只要做對應的適配即可,並且官方已經支援了一批儲存系統。結合位元組的技術棧以及我們的訴求,做了以下的評估。
各類儲存系統比較

-
因投入成本過高,我們不接受自己運維有狀態叢集,排除了 HBase 和 Cassandra;
-
從當前資料量與將來的可延伸性考慮,單機方案不可選,排除了 BerkeleyDB;
-
同樣因為人力成本,需要做極大量開發改造的方案暫時不考慮,排除了 Redis。
最終我們挑選了 MySQL 來推進到下一步。
MySQL 的理論可行性
-
可以支援 Key-Value(後續簡稱 KV 模型)或者 Key-Column-Value(後續簡稱 KCV 模型)的儲存模型,聚集索引 B+樹排序存取,支援基於 Key 或者 Key-Column 的 Range Query,所有查詢都走索引,且避免記憶體中重排序,效率初步判斷可接受。
-
中臺內的其他系統,最大的 MySQL 單表已經到達億級別,且 MySQL 有成熟的分庫分表解決方案,判斷資料量可以支援。
-
在具體使用場景中,對於寫入的效率要求不高,因為大量的資料都是離線任務完成,判斷 MySQL 在寫入上的效率不會成為瓶頸。
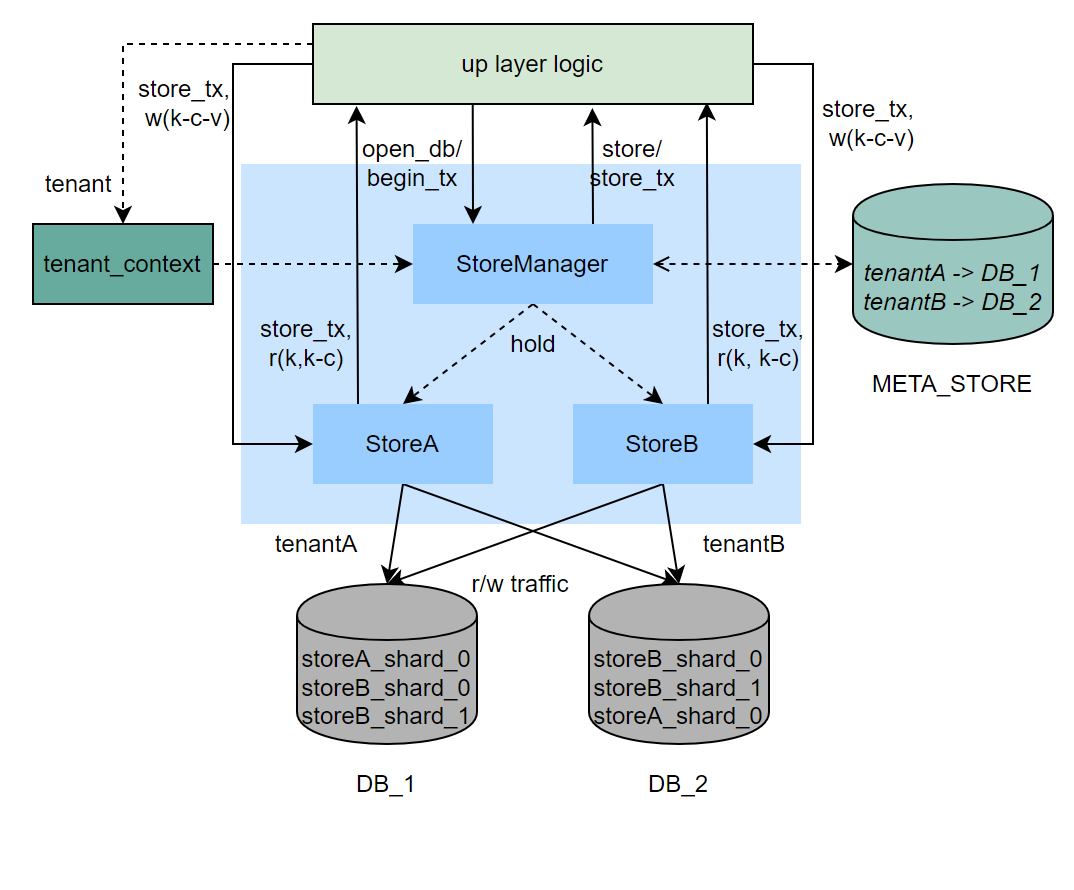
總體設計
-
維護一張 Meta 表做 lookup 用,Meta 表中儲存租戶與 DataSource(庫)之間的對映關係,以及 Shards 等租戶級別的設定資訊。
-
StoreManager 作為入口,在 openTransaction 的時候將租戶資訊注入到 StoreTransaction 中,並返回租戶級別的 DataSource。
-
StoreManager 中以 name 為 Key,維護一組 Store,Store 與儲存的資料型別有關,具有跨租戶能力
常見的 Store 有
system_properies,tx_log,graphindex,edgestore等 -
對於 MySQL 最終的讀寫,都收斂在 Store,方法簽名中傳入 StoreTransaction,Store 從中取出租戶資訊和資料庫連線,進行資料讀寫。
-
對於單租戶來說,資料可以分表(shards),對於某個特定的 key 來說,儲存和讀取某個 shard,是根據 ShardManager 來決定
典型的 ShardManager 邏輯,是根據總 shard 數對 key 做 hash 決定,預設單分片。
-
對於每個 Store,表結構是 4 列(id, g_key, g_column, g_value),除自增 ID 外,對應 key-column-value model 的資料模型,key+column 是一個聚集索引。
-
Context 中的租戶資訊,需要在操作某個租戶資料之前設定,並在操作之後清除掉。
細節設計與疑難問題
細節設計
儲存模型
JanusGraph 要求 column-family 型別儲存(如 Cassandra, HBase),也就是說,資料儲存由一系列行組成,每行都由一個鍵(key)唯一標識,每行由多個列值(column-value)對組成,也會對列進行排序和過濾,如果是非 column-family 的型別儲存,則需要另行適配,適配時資料模型有兩種方式:Key-Column-Value 和 Key-Value。

KCV 模型:
-
會將 key\column\value 在儲存中區分開來。
-
對應的介面為:
KeyColumnValueStoreManager。
KV 模型:
-
在儲存中僅有 key 和 value 兩部分,此處的 key 相當於 KVC 模型中的 key+column;
-
如果要根據 column 進行過濾,需要額外的適配工作;
-
對應的介面為:
KeyValueStoreManager,該介面有子類OrderedKeyValueStoreManager,提供了保證查詢結果有序性的介面; -
同時提供了
OrderedKeyValueStoreManagerAdapter介面,用於對 Key-Column-Value 模型進行適配,將其轉化為 Key-Value 模型。
MySQL 的儲存實現採用了 KCV 模型,每個表會有 4 列,一個自增的 ID 列,作為主鍵,同時還有 3 列分別對應模型中的 key\column\value,資料庫中的一條記錄相當於一個獨立的 KCV 結構,多行資料庫記錄代表一個點或者邊。
表中 key 和 column 這兩列會組成聯合索引,既保證了根據 key 進行查詢時的效率,也支援了對 column 的排序以及條件過濾。
多租戶
儲存層面:預設情況下,JanusGraph 會需要儲存edgestore, graphindex, system_properties, txlog等多種資料型別,每個型別在 MySQL 中都有各自對的表,且表名使用租戶名作為字首,如tenantA_edgestore,這樣即使不同租戶的資料在同一個資料庫,在儲存層面租戶之間的資料也進行了隔離,減少了相互影響,方便日常運維。(理論上每個租戶可以單獨分配一個資料庫)
具體實現:每個租戶都會有各自的 MySQL 連線設定,啟動之後會為各個租戶分別初始化資料庫連線,所有和 JanusGraph 的請求都會通過 Context 傳遞租戶資訊,以便在運算元據庫時選擇該租戶對應的連線。
具體程式碼:
-
MysqlKcvTx:實現了
AbstractStoreTransaction,對具體的 MySQL 連線進行了封裝,負責和資料庫的互動,它的commit和rollback方法由封裝的 MySQL 連線真正完成。 -
MysqlKcvStore:實現了
KeyColumnValueStore,是具體執行讀寫操作的入口,每一個型別的 Store 對應一個MysqlKcvStore範例,MysqlKcvStore處理讀寫邏輯時,根據租戶資訊完全自主組裝 SQL 語句,SQL 語句會由MysqlKcvTx真正執行。 -
MysqlKcvStoreManager:實現了
KeyColumnValueStoreManager,作為管理所有 MySQL 連線和租戶的入口,也維護了所有 Store 和MysqlKcvStore物件的對映關係。在處理不同租戶對不同 Store 的讀寫請求時,根據租戶資訊,建立MysqlKcvTx物件,並將其分配給對應的MysqlKcvStore去執行。
事務
幾乎所有與 JanusGraph 的互動都會開啟事務,而且事務對於多個執行緒並行使用是安全的,但是 JanusGraph 的事務並不都支援 ACID,是否支援會取決於底層儲存元件,對於某些儲存元件來說,提供可序列化隔離機制或者多行原子寫入代價會比較大。
JanusGraph 中的每個圖形操作都發生在事務的上下文中,根據 TinkerPop 的事務規範,每個執行緒執行圖形上的第一個操作時便會開啟針對圖形資料庫的事務,所有圖形元素都與檢索或者建立它們的事務範圍相關聯,在使用commit或者rollback方法顯式的關閉事務之後,與該事務關聯的圖形元素都將過時且不可用。
JanusGraph 提供了AbstractStoreTransaction介面,該介面包含commit和rollback的操作入口,在 MySQL 儲存的實現中,MysqlKcvTx實現了AbstractStoreTransaction,對具體的 MySQL 連線進行了封裝,在其commit和rollback方法中呼叫 SQL 連線的commit和rollback方法,以此實現對於 JanusGraph 事務的支援。
public class MysqlKcvTx extends AbstractStoreTransaction { private static final Logger log = LoggerFactory.getLogger(MysqlKcvTx.class); private final Connection connection; @Getter private final String tenant; public MysqlKcvTx(BaseTransactionConfig config, String tenant, Connection connection) { super(config); this.tenant = tenant; this.connection = connection; } @Override public synchronized void commit() { try { if (Objects.nonNull(connection)) { connection.commit(); connection.close(); } if (log.isDebugEnabled()) { log.debug("tx has been committed"); } } catch (SQLException e) { log.error("failed to commit transaction", e); } } @Override public synchronized void rollback() { try { if (Objects.nonNull(connection)) { connection.rollback(); connection.close(); } if (log.isDebugEnabled()) { log.debug("tx has been rollback"); } } catch (SQLException e) { log.error("failed to rollback transaction", e); } } public Connection getConnection() { return connection; } }
資料庫連線池
Hikari 是 SpringBoot 內建的資料庫連線池,快速、簡單,做了很多優化,如使用 FastList 替換 ArrayList,自行研發無所集合類 ConcurrentBag,位元組碼精簡等,在效能測試中表現的也比其他競品要好。
Druid 是另一個也非常優秀的資料庫連線池,為監控而生,內建強大的監控功能,監控特性不影響效能。功能強大,能防 SQL 注入,內建 Loging 能診斷 Hack 應用行為。
關於兩者的對比很多,此處不再贅述,雖然 Hikari 的效能號稱要優於 Druid,但是考慮到 Hikari 監控功能比較弱,最終在實現的時候還是選擇了 Druid。
疑難問題
連線超時
現象:在進行資料匯入測試時,服務報錯" The last packet successfully received from the server was X milliseconds ago",導致資料寫入失敗。
原因:存在超大 table(有 8000 甚至 10000 列),這些 table 的後設資料處理非常耗時(10000 列的可能需要 30 分鐘),而且在處理過程中有很長一段時間和資料庫並沒有互動,資料庫連線一直空閒。
解決辦法:
-
調整 mysql server 端的 wait_timeout 引數,已調整到 3600s。
-
調整 client 端資料庫設定中連線的最小空閒時間,已調整到 2400s。
分析過程:
-
懷疑是 mysql client 端沒有增加空閒清理或者保活機制,conneciton 線上程池中長時間沒有使用,mysql 伺服器端已經關閉該連結導致。嘗試修改使用者端 connection 空閒時間,增加 validationQuery 等常見措施,無果;
-
根據打點發現單條訊息處理耗時過高,疑似執行緒卡死;
-
新增打點發現執行緒沒卡死,只是在執行一些非常耗時的邏輯,這時候已經獲取到了資料庫連線,但是在執行那些耗時邏輯的過程中和資料庫沒有任何互動,長時間沒有使用資料庫連線,最終導致連線被回收;
-
調高了 MySQL server 端的 wait_timeout,以及 client 端的最小空閒時間,問題解決。
並行寫入死鎖
現象:執行緒 thread-p-3-a-0 和執行緒 thread-p-7-a-0 在執行過程中都出現 Deadlock。
具體紀錄檔如下:
原因:
-
結合紀錄檔分析,兩個執行緒並行執行,需要對同樣的多個記錄加鎖,但是順序不一致,進而導致了死鎖。
-
55A0這個 column 對應的 property 是"__modificationTimestamp",該屬性是 atlas 的系統屬性,當對相簿中的點或者邊有更新時,對應點或者邊的"__modificationTimestamp"屬性會被更新。在並行匯入資料的時候,加劇了資源競爭,所以會偶發死鎖問題。
解決辦法:
業務中並沒有用到"__modificationTimestamp"這個屬性,通過修改 Atlas 程式碼,僅在建立點和邊的時候為該屬性賦值,後續更新時不再更新該屬性,問題得到解決。
效能測試
環境搭建
在位元組內部 JanusGraph 主要用作 Data Catalog 服務的儲存層,關於 MySQL 作為儲存的效能測試並沒有在 JanusGraph 層面進行,而是模擬 Data Catalog 服務的業務使用場景和資料,使用業務介面進行測試,主要會關注介面的響應時間。
介面邏輯有所裁剪,在不影響核心讀寫流程的情況下,遮蔽掉對其他服務的依賴。
模擬單租戶表單分片情況下,庫表後設資料建立、更新、查詢,表之間血緣關係的建立、查詢,以此反映在相簿單次讀寫和多次讀寫情況下 MySQL 的表現。
整個測試環境搭建在火山引擎上,總共使用 6 臺 8C32G 的機器,硬體條件如下:

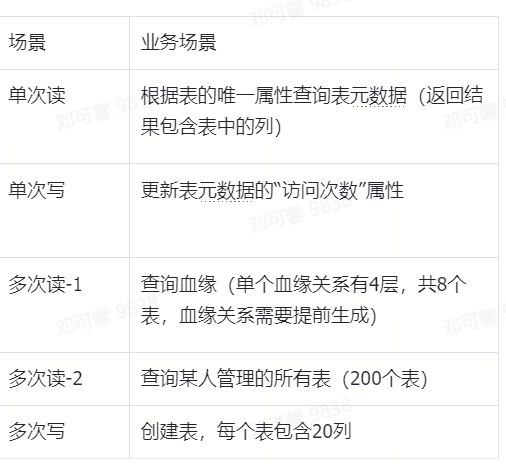
測試場景如下:
測試結論
總計 10 萬個表(庫數量為個位數,可忽略)
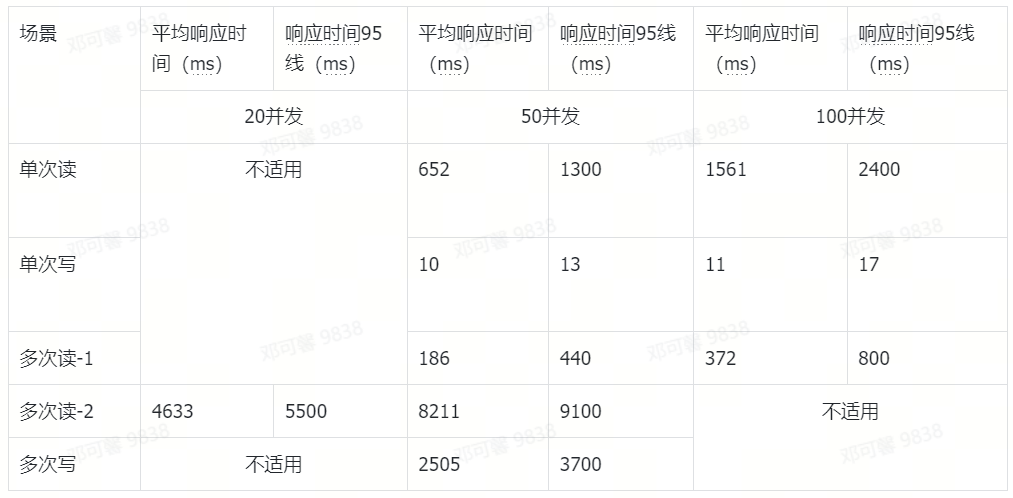
在 10 萬個表且模擬了表之間血緣關係的情況下,graphindex表的資料量已有 7000 萬,edgestore表的資料量已有 1 億 3000 萬,業務介面的響應時間基本在預期範圍內,可滿足中小規模 Data Catalog 服務的儲存要求。
總結
MySQL 作為 JanusGraph 的儲存,有部署簡單,方便運維等優勢,也能保持良好的擴充套件性,在中小規模的 Data Catalog 儲存服務中也能保持較好的效能水準,可以作為一個儲存選擇。
市面上也有比較成熟的 MySQL 分庫分表方案,未來可以考慮將其引入,以滿足更大規模的儲存需求。
火山引擎 Data Catalog 產品是基於位元組跳動內部平臺,經過多年業務場景和產品能力打磨,在公有云進行部署和釋出,期望幫助更多外部客戶創造資料價值。目前公有云產品已包含內部成熟的產品功能同時擴充套件若干 ToB 核心功能,正在逐步對齊業界領先 Data Catalog 雲產品各項能力。
點選跳轉 巨量資料研發治理DataLeap 瞭解更多