計網學習筆記六 Network Layer Overview
這節課開始進入了網路層的學習,講述了網路層提供的功能,還有路由器內部是什麼樣子的,以及virtual circuit網路和datagram網路的一點比較。
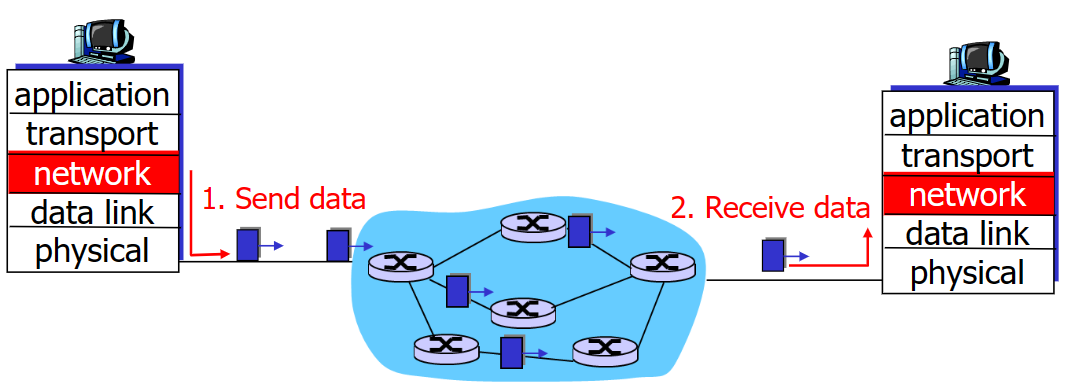
網路層有什麼作用呢?用一句話來說,就是需要負責將傳輸層的報文段從傳送端傳輸到接收端。再詳細一點點就是:
- 在傳送方將傳輸層傳下來的資料包文段封裝成網路層資料包;
- 在接收方將接收到的資料包向上送到傳輸層;
- 網路層協定在所有的host和router都有應用;
- router需要檢查流經它自身的所有資料包的header。
Network Layer Functions
網路層的功能有兩個:routing 和 forwarding。
用旅行來比喻:如果資料包是需要出門旅行的人,那麼routing就是提前決定好一條旅遊的路線(從哪到哪然後到哪再到哪……),forwarding則是在路線中的某一個站點進出的過程。
Routing
routing使用路由演演算法找到一條從src到dest的最短路徑。
routing屬於網路層的控制平面,需要多個路由器進行協調,以後慢慢闡述。
Forwarding
「Forwarding 是網路層資料平面唯一需要實現的功能。「
Forwarding通過switching,來將封包從節點入口移動到指定的節點出口,「在某個時刻一個包進來了,決定在哪個埠出去」。在這個過程還需要做error handling, queuing 和scheduling。
其中router進行switching的過程和二層交換機是十分相似的,router有一個forwarding table,起到了類似於交換機表的作用:
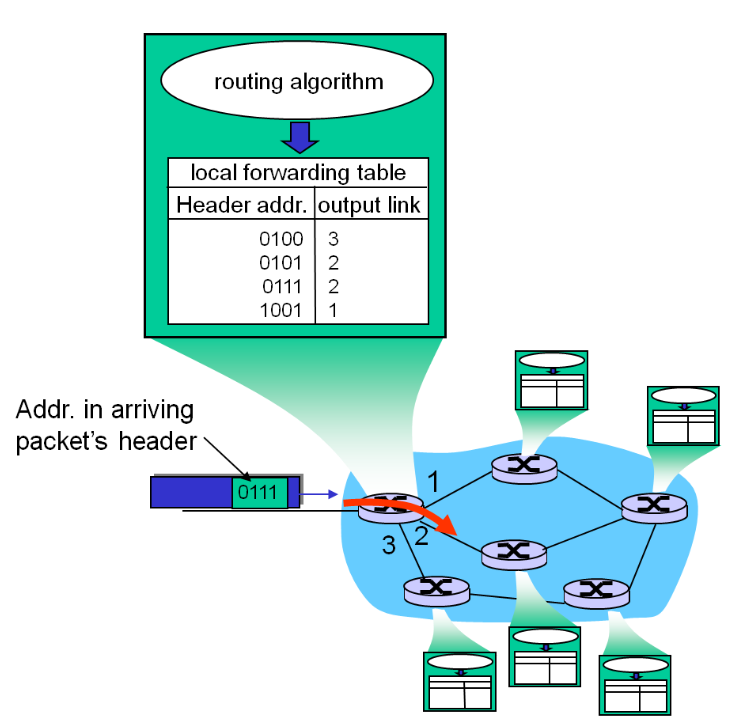
但forwarding table並不是自學習得來的,而是需要各個路由器之間的路由演演算法進行通訊後才可以設定完成。也就是說,控制平面的routing決定了資料平面需要使用的forwarding table。
forwarding 時網路層還會提供一點其它的功能,如queuing 和 scheduling,因為擁塞實時存在,所以加上這兩個功能。
Service Model
網路層的服務模型(service model)是指,如果想要傳輸一個資料包,那麼傳輸所用的"channel"應該為什麼樣子的呢?
要用的"channel"需要考慮的因素非常多,即我們的"channel"應該為傳輸提供了什麼樣的服務……例如有以下服務:

對需求做出抽象後產生的服務功能越強,那麼實現起來的代價就越大——所以作為應用最廣的協定層,便宜很重要!
先不提實現成本,來看看IP和ATM協定的對比——它們提供了什麼服務:
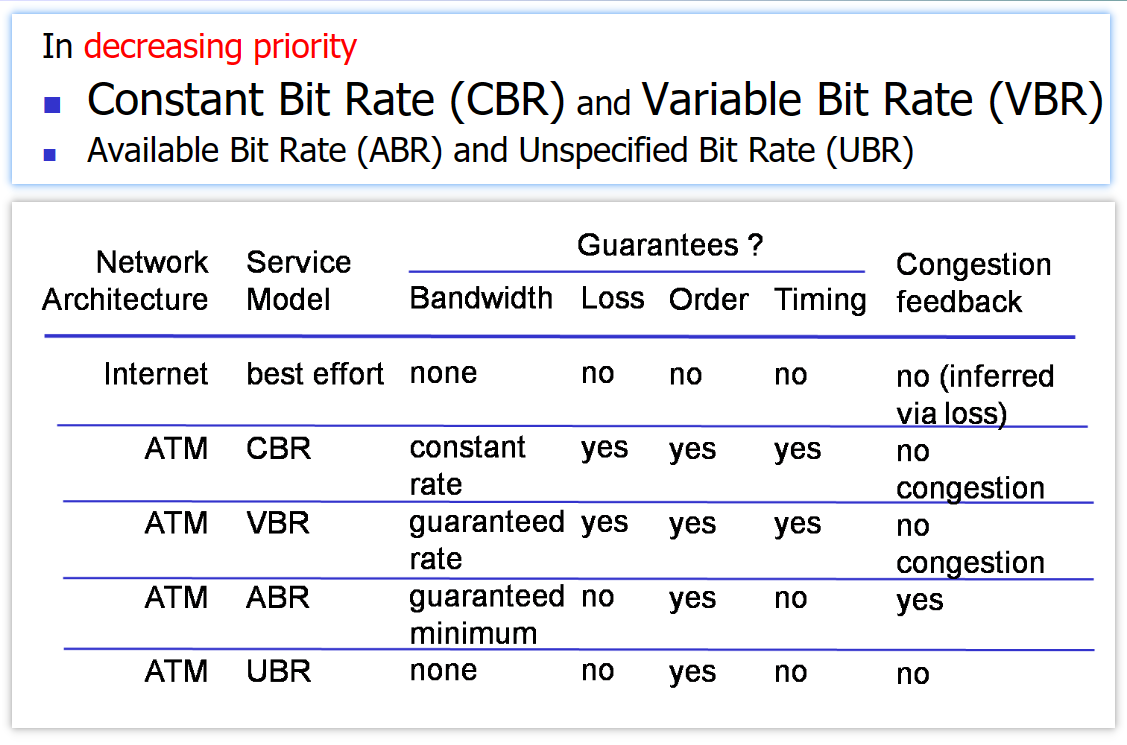
可以看到,IP協定的best effort服務真是夠鬼舞的……好像什麼都幹不了,看看ATM協定能做的還真多,還分了四種優先順序供人選擇。
但ATM協定還是敗了,就是敗在了實現成本這方面。雖然IP看上去不咋地,但在現今與適當的頻寬供給相結合已經能夠用於大量的應用,已經「足夠好」。
Inside the Router
Overview了網路層提供的功能和服務,我們來看路由器的工作原理,看它是如何進行forwarding的。
總體路由器系統容量
其中 N 為路由器的外埠數量;R 為 埠的傳輸速率 (即「line rate」);
在 RFC 8238 第五部分的定義(5.1)有:
The line rate or physical-layer frame rate is the maximum capacity to send frames of a specific size at the transmit clock frequency of the DUT.
The term "nominal value of line rate" defines the maximum speed capability for the given port -- for example (expressed as Gigabit Ethernet), 1 GE, 10 GE, 40 GE, 100 GE.
路由器的屬性差異
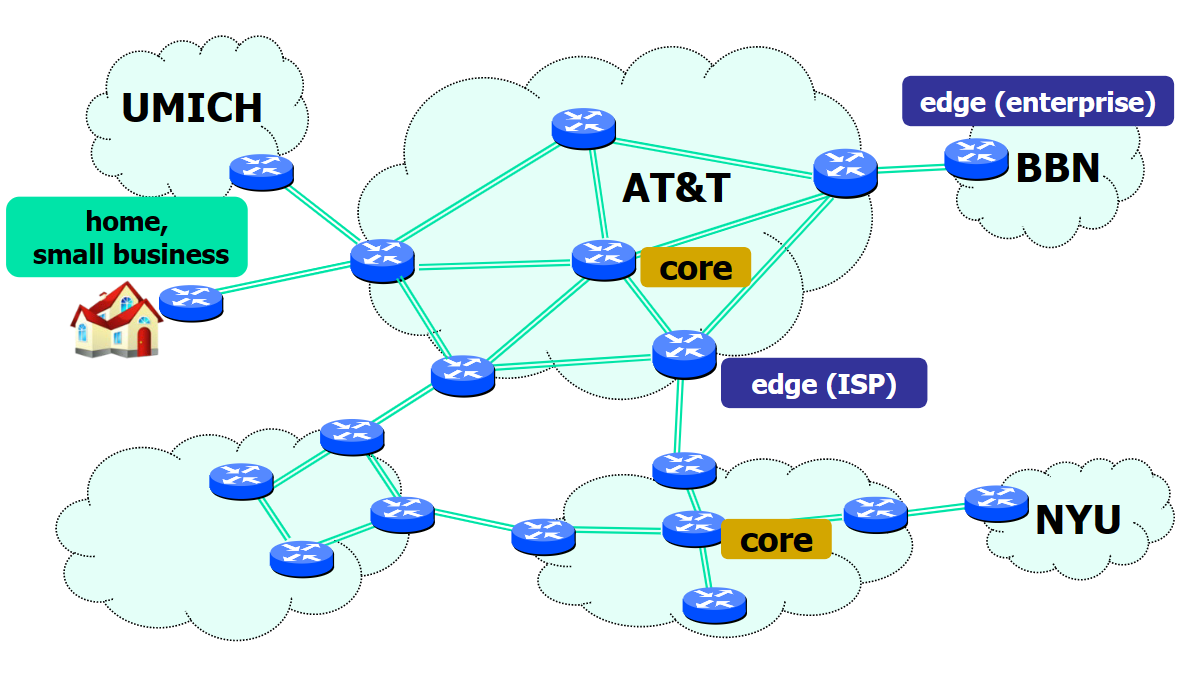
路由器是有種類區分的,在不同應用場景下的路由器的設定也有所不同:
- Core 核心路由器
- R = 10/40/100/200/400 Gbps
- NR = O(100) Tbps (Aggregated速率)
- Edge 邊緣路由器
- R = 1/10/40/100 Gbps
- NR = O(100) Gbps
- Small business 小型路由器(家用)
- R = 1 Gbps
- NR < 10 Gbps
路由器的實現機制
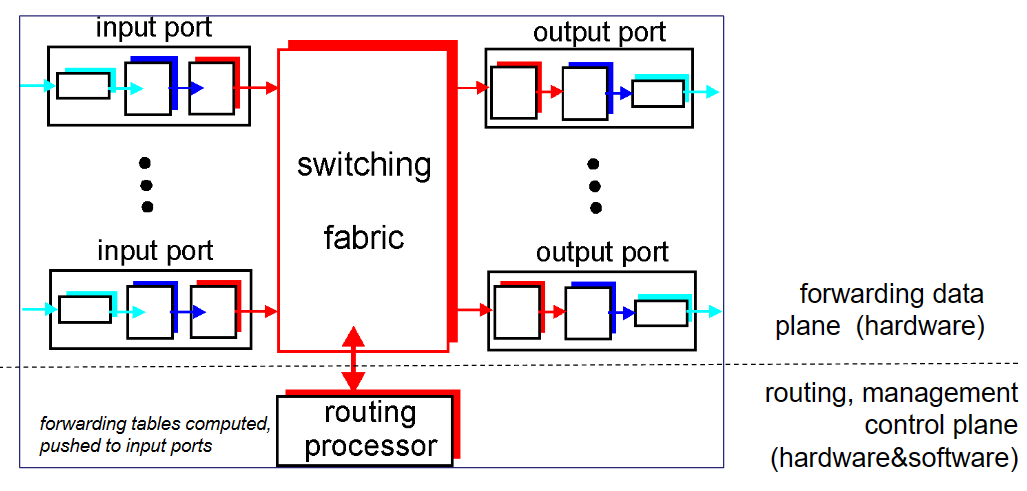
- 兩個平面:控制平面負責
routing,資料平面負責forwarding; - 控制平面由一系列處理器和軟體組成,路由器之間進行交流決定路由演演算法;
- 組成部分包括:輸入埠、交換結構、輸出埠、路由處理器。
問:為什麼輸入輸出埠以及交換結構大部分用硬體實現?
主要challenge:接收封包的速率的時間要求(例如100B大小的包要達到40Gbps的速率接收,則只有20ns時間處理)遠遠快於軟體實現;所以不用普通的x86晶片,用的更快的ASICs實現(專用的網路處理器)。
Input Port Functions
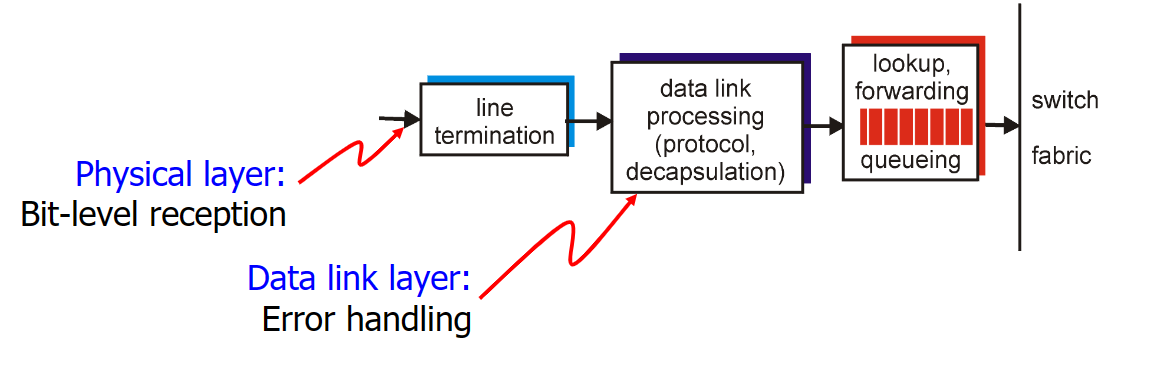
輸入埠主要有以下四個任務:

進行了線路端接和鏈路層處理後,我們來到了執行查詢輸出埠的步驟。轉發表通過路由處理器計算和更新(或者由SDN轉發過來的內容更新,SDN在控制平面會講),轉發表從路由處理器經過獨立匯流排複製到 line card中,使用副本可以使得查詢決策可以在各個輸入埠上分別執行,無須呼叫集中式路由處理器。
但問題來了,IP有四十億多的地址,一個埠對應一個地址的話,轉發表怎麼夠裝?
如何處理這樣的規模問題?採用地址聚合。(可延伸性好)我們用最長字首匹配規則 LPM rules來對地址們進行聚合。
LPM的定義如下:

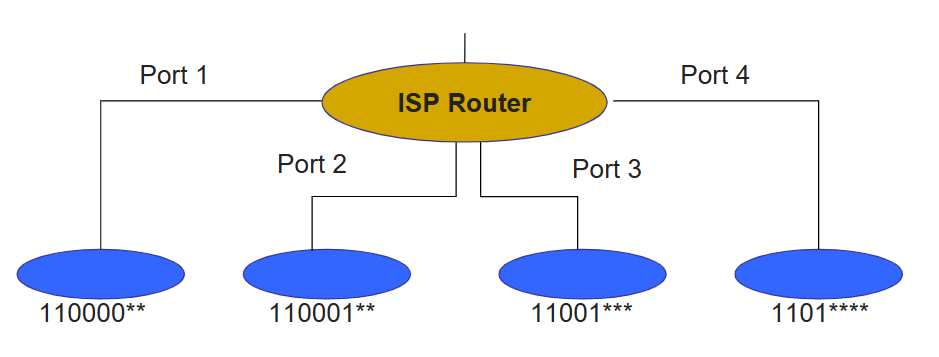
來看一個例子。假設我們的交換機有四個埠,給出各個埠接收到的packet的地址範圍(為了方便,用一個位元組);可以看到這些地址的LPM分別是藍色標記的部分:

然後我們就可以根據LPM來把地址和對應的埠寫入轉發表中,此時一個埠對應的是一個「聚合起來」的地址群,而不只是單單的一個。
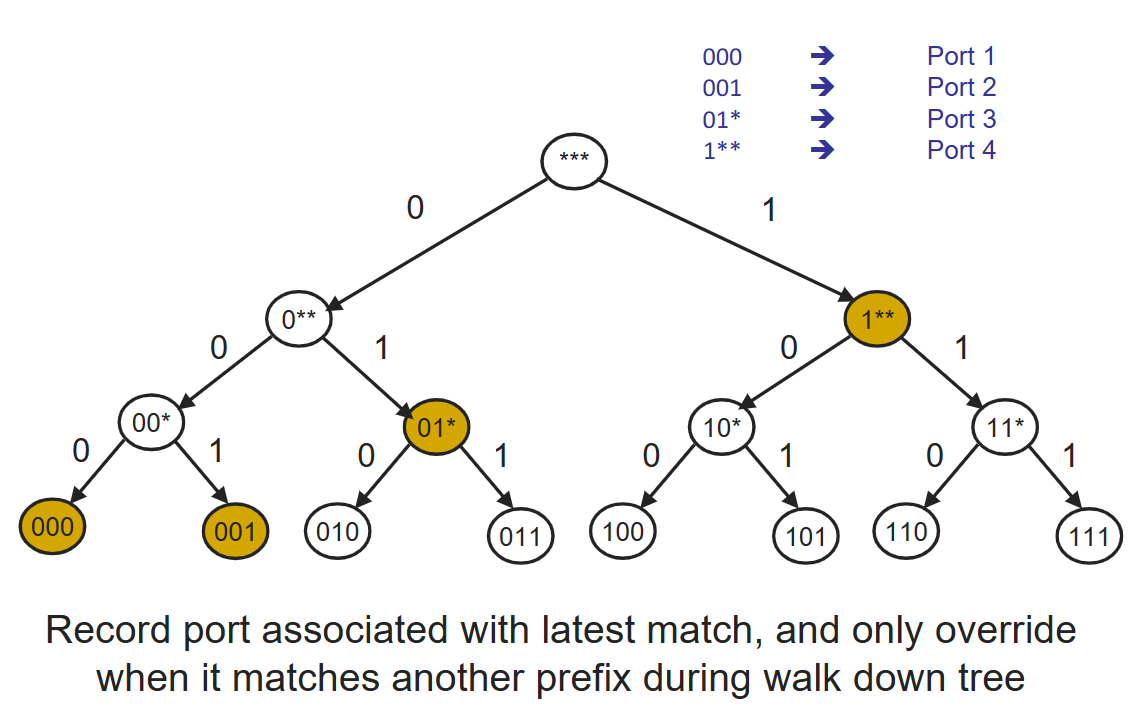
由於需要達到納秒級別執行,即使是用硬體執行查詢,簡單線性搜尋匹配還是太慢。所以我們用一個Trie tree來查詢匹配。(或者看這篇:路由查詢演演算法研究綜述)這是針對字首查詢問題的一個好方法,有點類似哈夫曼樹,可以基於字首長度而不是字首內容做線性遍歷。
除了查詢演演算法,在硬體上也需要進行對訪存消耗的優化,如TCAM(三態內容可定址記憶體,電平控制)。
Switching fabric
交換結構可以由三種不同的交換技術實現,即記憶體memory、匯流排bus和縱橫式crossbar。
交換速率switching rate是指packet從輸入埠傳輸到輸出埠的速率,通常以輸入/輸出的line rate的倍數來衡量,
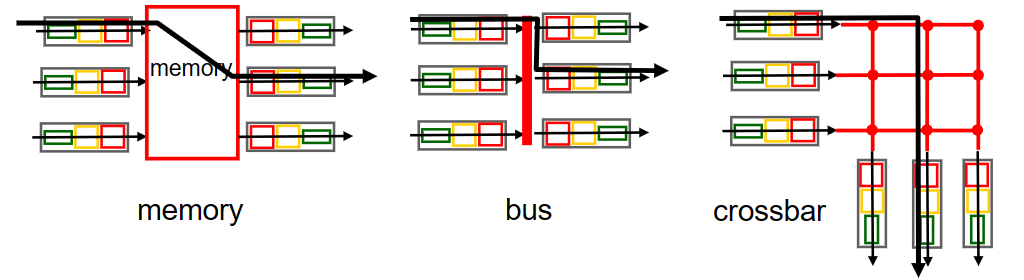
memory
早期的路由器是傳統的計算機,對packet進出的使用IO機制進行處理(即中斷--系統呼叫,packet被copy到記憶體中),在這種情況下如果記憶體頻寬每秒能讀出/寫入B個packet,那麼總的吞吐量一定小於B/2。另外還不能同時forward兩個packet,即使埠不同——因為經過系統共用匯流排一次只能進行一次記憶體讀/寫。
現代的很多路由器同樣採用memory方式,但與早期不同的是,查詢packet並將其switch進記憶體中的行為是由輸入埠的line card進行處理的。(這種方式很便宜,相對其它兩種)
bus
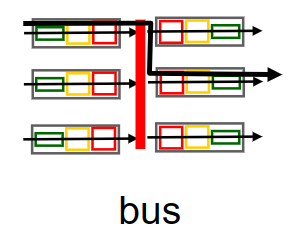
bus交換方式是通過路由器內部的背板匯流排來實現的,不需要路由處理器的操作。當packet查詢出對應的輸出埠時,packet頭部被打上一個label(相當於多加一層header),這個label記錄了對應的輸出埠;然後它被放到匯流排上傳輸,這時所有的輸出埠都能收到該packet,但只有label上記錄的輸出埠才能儲存該packet。
因為一次只有一個packet可以通過匯流排(同一時間的其餘packet需要原地等待),所以bus方式的switching rate與背板匯流排速率有關。
crossbar
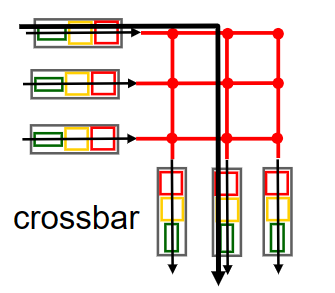
為了克服bus方式共用匯流排帶來的速率限制,我們可以用2N條匯流排來構建一個複雜的網際網路絡(對應N個輸入埠和N個輸出埠);然後匯流排的交叉點可以通過交換結構控制器來在任何時候進行開啟/關閉,由此可以實現多個packet的並行轉發。這種方式面對多個輸出埠不同的packet時,是non-blocking的。
Cisco CRS利用三級non-blocking交換策略實現對多個輸出埠相同packet進行並行switching。
Output Port Function
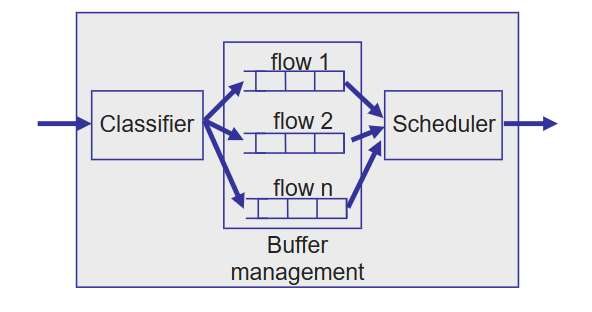
輸出埠需要做的就是選擇並取出正在queueing的packet,然後執行鏈路層功能,再進行物理層線路端接傳輸。
輸出埠有三個組成部分:
Classifier:流分類器,負責將packet分到各個流中;Buffer management:決定哪一個packet以及在什麼時候會被丟棄;Scheduler:packet排程器,在queueing的packets中決定哪一個packet以及在什麼時候會被傳輸走;
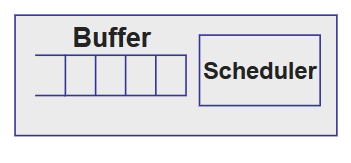
在最簡單的FIFO機制路由器裡面,沒有classification機制,buffer的management僅僅是把buffer尾部溢位的packet丟棄,scheduler也只是簡單地使用FIFO來對packet排程——誰先來誰就能先出去。FIFO機制弊端太多,我們來看看這三個組成部分可以在此之上有什麼提升:
Packet classification
Classifier可以根據packet的header來進行流分類(有意義的排程必須要先分類):

Scheduler
對於排程器來說,一個好的排程演演算法非常重要(納秒級別的處理要儘可能快)。常見的排程演演算法有FIFO、優先順序排程(Priority scheduler)、加權公平排程等。

我們來說一下優先順序排程和加權公平排程。
對於這兩個排程演演算法來說,buffer裡面的每個流都有一個buffer佇列。優先順序排程的策略很容易理解:就是優先順序越高的佇列總是比優先順序低的佇列先進行packet傳輸;而加權公平排程則是有幾種情況:最簡單的round-robin方式就是簡單的對每一個佇列都進行週期性的packet傳輸,你一下我一下;而weighted fair queue(WFQ)方式是對佇列進行加權後,按照權值來進行週期性迴圈。
PS:在早些時期,運營商可以自己調整ISP路由器中的佇列優先順序(誰給錢多,誰的packet就傳輸得越多越快),所以需要法案來規定這些東西……
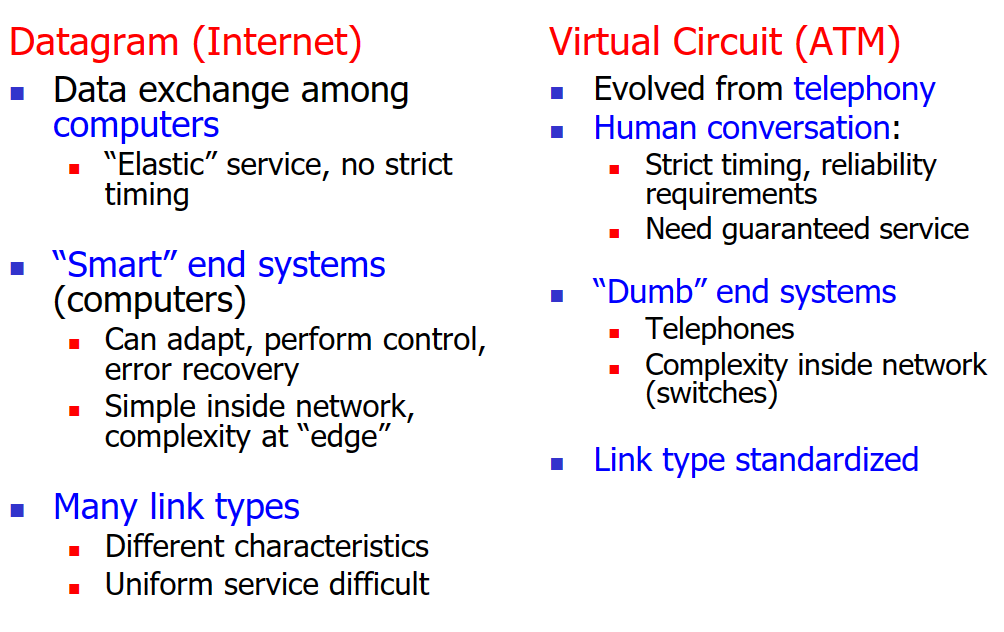
VC網路(ATM)和資料包網路(Internet)
在第一節講過我們的network的連線可以分為電路交換模式和分組交換模式。在這裡我們來說一下它們在網路層中分別對應使用的具體協定實現:電路交換(virtual circuit網路)對應的是ATM協定,而分組交換(datagram網路)對應的是IP協定。

virtual circuit網路
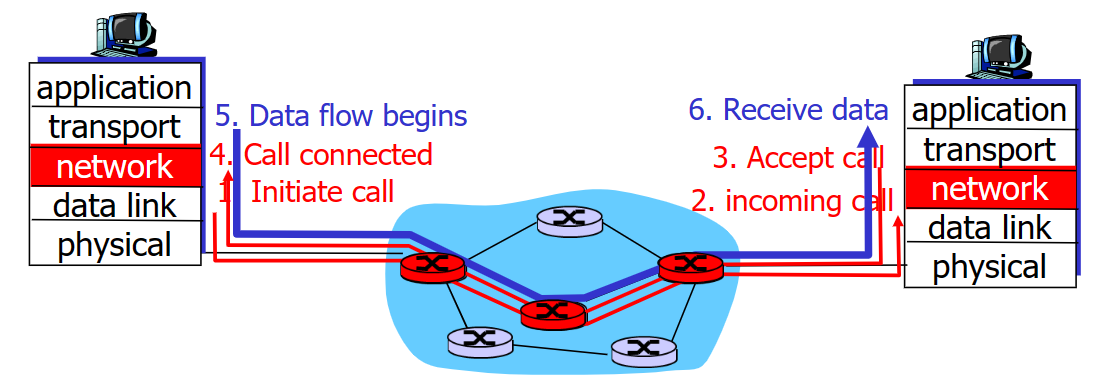
VC網路需要在傳輸資料前在src和dest之間先確立好一條路線,在這條路線上的路由器和交換機都是固定分配好後就不變的,這也表示這條路線是這次傳輸專屬的,效能可以被準確估計。這條路線需要用路由器來找出(shortest path)。
每一個在VC網路上傳輸的packet都會帶著一個VC number,VC number在路線上的每一個link存在,它在轉發表中的使用如下:
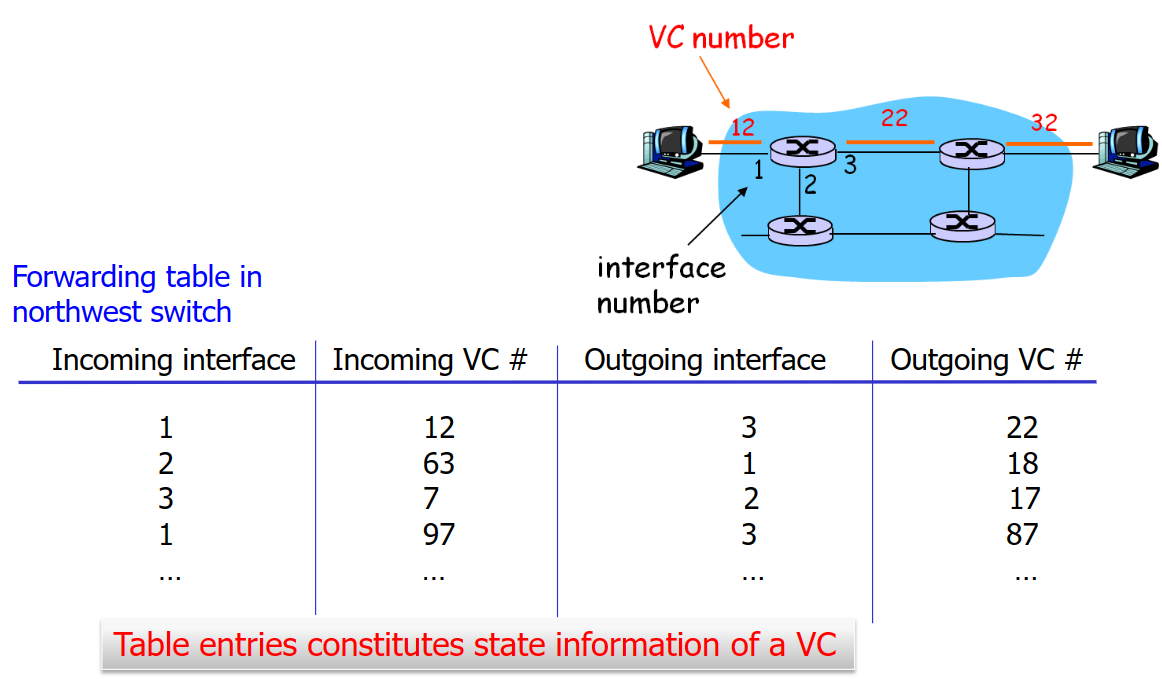
VC網路的建立和斷開就像大公司招人,正式職工一般是長期聘用的,不會斷開那麼快。它使用信令協定(Signaling Protocols)來建立、維持以及斷開VC連線,具體協定有ATM, frame-relay, X.25,但是在今天的Internet已經基本看不見了(因為實現昂貴,昂貴的原因:需要儲存途徑連線的狀態)
datagram網路
datagram網路的特點是無確定連線、無轉發狀態記錄,同樣的src-dest的packet,在網路中走的可能是不同的路線。
和VC網路的轉發表不同,datagram網路的轉發表記錄的src地址可能是switch地址,也可能是一整個subnet的地址群:

Virtual Circuits vs Datagram Networks
兩種網路的routing:VC網路(左)和datagram網路(右)。
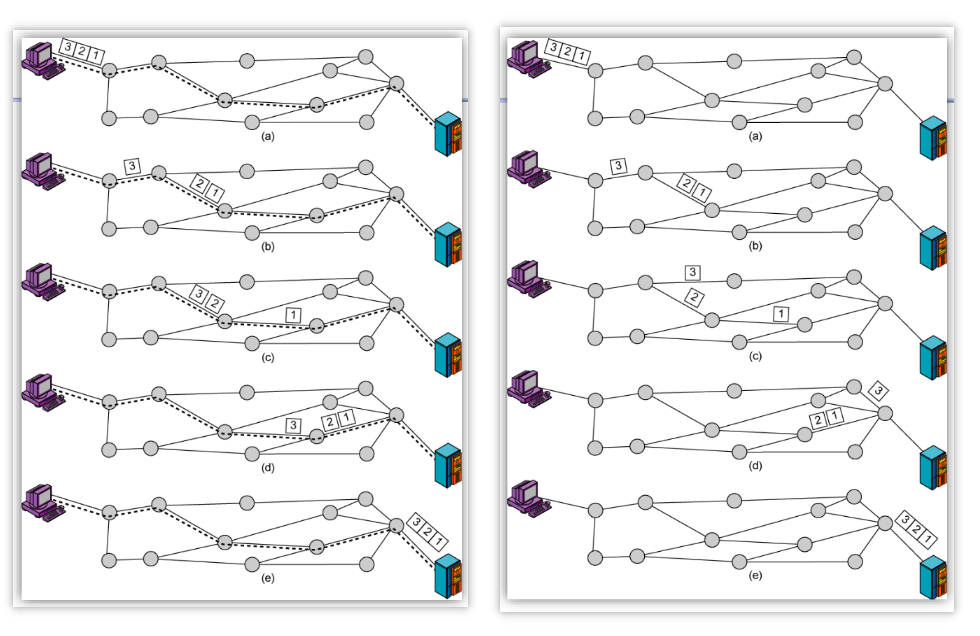
相關資料:Virtual Circuits vs Datagram Networks;有一個小的總結: