基於Label studio實現UIE資訊抽取智慧標註方案,提升標註效率!
基於Label studio實現UIE資訊抽取智慧標註方案,提升標註效率!
專案連結見文末
-
人工標註的缺點主要有以下幾點:
- 產能低:人工標註需要大量的人力物力投入,且標註速度慢,產能低,無法滿足大規模標註的需求。
- 受限條件多:人工標註受到人力、物力、時間等條件的限制,無法適應所有的標註場景,尤其是一些複雜的標註任務。
- 易受主觀因素影響:人工標註受到人為因素的影響,如標註人員的專業素養、標註態度、主觀判斷等,易受到人為誤差的干擾,導致標註結果不準確。
- 難以滿足個性化需求:人工標註無法滿足所有標註場景和個性化需求,無法精確地標註出所有的關鍵資訊,需要使用者自行選擇和判斷。
-
相比之下,智慧標註的優勢主要包括:
- 效率更高:智慧標註可以自動化地進行標註,能夠快速地生成標註結果,減少了人工標註所需的時間和精力,提高了標註效率。
- 精度更高:智慧標註採用了先進的人工智慧技術,能夠對影象進行深度學習和處理,能夠生成更加準確和精細的標註結果,特別是對於一些細節和特徵的標註,手動標註往往存在誤差較大的問題。
- 自動糾錯:智慧標註可以自動檢測標註結果中的錯誤,並進行自動修正,能夠有效地避免標註錯誤帶來的影響,提高了標註的準確性。
- 靈活性更強:智慧標註可以根據不同的應用場景和需求,生成不同型別的標註結果,能夠滿足使用者的多樣化需求,提高了標註的適用性。
總之,智慧標註相對於人工標註有著更高的效率、更高的精度、更強的靈活性和更好的適用性,可以更好地滿足使用者的需求。
自然語言處理資訊抽取智慧標註方案包括以下幾種:
-
基於規則的標註方案:通過編寫一系列規則來識別文字中的實體、關係等資訊,並將其標註。
- 基於規則的標註方案是一種傳統的方法,它需要人工編寫規則來識別文字中的實體、關係等資訊,並將其標註。
- 這種方法的優點是易於理解和實現,但缺點是需要大量的人工工作,並且規則難以覆蓋所有情況。
-
基於機器學習的標註方案:通過訓練模型來自動識別文字中的實體、關係等資訊,並將其標註。
- 基於機器學習的標註方案是一種自動化的方法,它使用已經標註好的資料集訓練模型,並使用模型來自動標註文字中的實體、關係等資訊。
- 這種方法的優點是可以處理大量的資料,並且可以自適應地調整模型,但缺點是需要大量的標註資料和計算資源,並且模型的效能受到標註資料的質量和數量的限制。
-
基於深度學習的標註方案:通過使用深度學習模型來自動識別文字中的實體、關係等資訊,並將其標註。
- 基於深度學習的標註方案是一種最新的方法,它使用深度學習模型來自動從文字中提取實體、關係等資訊,並將其標註。
- 這種方法的優點是可以處理大量的資料,並且具有較高的準確性,但缺點是需要大量的標註資料和計算資源,並且模型的訓練和偵錯需要專業的知識和技能。
-
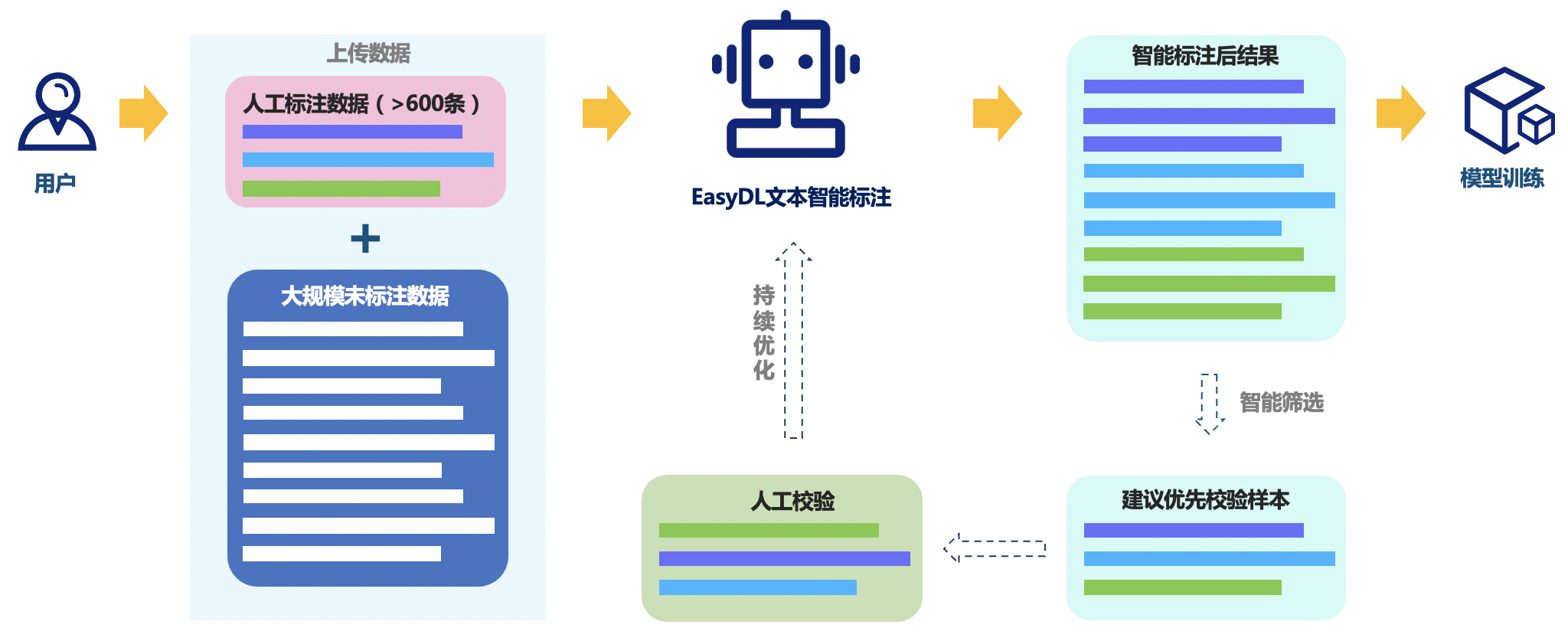
基於半監督學習的標註方案:通過使用少量的手工標註資料和大量的未標註資料來訓練模型,從而實現自動標註。
- 基於半監督學習的標註方案是一種利用少量的手工標註資料和大量的未標註資料來訓練模型的方法。
- 這種方法的優點是可以利用未標註資料來提高模型的效能,但缺點是需要大量的未標註資料和計算資源,並且模型的效能受到標註資料的質量
-
基於遠端監督的標註方案:利用已知的知識庫來自動標註文字中的實體、關係等資訊,從而減少手工標註的工作量。
本次專案主要講解的是基於半監督深度學習的標註方案。
1.UIE-base預訓練模型進行命名實體識別
from pprint import pprint
from paddlenlp import Taskflow
schema = ['地名', '人名', '組織', '時間', '產品', '價格', '天氣']
ie = Taskflow('information_extraction', schema=schema)
pprint(ie("2K 與 Gearbox Software 宣佈,《小緹娜的奇幻之地》將於 6 月 24 日凌晨 1 點登入 Steam,此前 PC 平臺為 Epic 限時獨佔。在限定期間內,Steam 玩家可以在 Steam 入手《小緹娜的奇幻之地》,並在 2022 年 7 月 8 日前享有獲得黃金英雄鎧甲包。"))
[2023-03-27 16:11:00,527] [ INFO] - Downloading model_state.pdparams from https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base_v1.0/model_state.pdparams
100%|██████████| 450M/450M [00:45<00:00, 10.4MB/s]
[2023-03-27 16:11:46,996] [ INFO] - Downloading model_config.json from https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/model_config.json
100%|██████████| 377/377 [00:00<00:00, 309kB/s]
[2023-03-27 16:11:47,074] [ INFO] - Downloading vocab.txt from https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/vocab.txt
100%|██████████| 182k/182k [00:00<00:00, 1.27MB/s]
[2023-03-27 16:11:47,292] [ INFO] - Downloading special_tokens_map.json from https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/special_tokens_map.json
100%|██████████| 112/112 [00:00<00:00, 99.6kB/s]
[2023-03-27 16:11:47,364] [ INFO] - Downloading tokenizer_config.json from https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/tokenizer_config.json
100%|██████████| 172/172 [00:00<00:00, 192kB/s]
W0327 16:11:47.478449 273 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0327 16:11:47.481654 273 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[2023-03-27 16:11:50,518] [ INFO] - Converting to the inference model cost a little time.
[2023-03-27 16:11:57,379] [ INFO] - The inference model save in the path:/home/aistudio/.paddlenlp/taskflow/information_extraction/uie-base/static/inference
[2023-03-27 16:11:59,489] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load '/home/aistudio/.paddlenlp/taskflow/information_extraction/uie-base'.
[{'產品': [{'end': 35,
'probability': 0.8595664902550801,
'start': 25,
'text': '《小緹娜的奇幻之地》'}],
'地名': [{'end': 34,
'probability': 0.30077351606695757,
'start': 26,
'text': '小緹娜的奇幻之地'},
{'end': 117,
'probability': 0.5250433327469182,
'start': 109,
'text': '小緹娜的奇幻之地'}],
'時間': [{'end': 52,
'probability': 0.8796518890642702,
'start': 38,
'text': '6 月 24 日凌晨 1 點'}],
'組織': [{'end': 2,
'probability': 0.6914450625760651,
'start': 0,
'text': '2K'},
{'end': 93,
'probability': 0.5971815528872604,
'start': 88,
'text': 'Steam'},
{'end': 75,
'probability': 0.5844303540013343,
'start': 71,
'text': 'Epic'},
{'end': 105,
'probability': 0.45620707081511114,
'start': 100,
'text': 'Steam'},
{'end': 60,
'probability': 0.5683007420326334,
'start': 55,
'text': 'Steam'},
{'end': 21,
'probability': 0.6797917390407271,
'start': 5,
'text': 'Gearbox Software'}]}]
pprint(ie("近日,量子計算專家、ACM計算獎得主Scott Aaronson通過部落格宣佈,將於本週離開得克薩斯大學奧斯汀分校(UT Austin)一年,並加盟人工智慧研究公司OpenAI。"))
[{'人名': [{'end': 23,
'probability': 0.664236391748247,
'start': 18,
'text': 'Scott'},
{'end': 32,
'probability': 0.479811241610971,
'start': 24,
'text': 'Aaronson'}],
'時間': [{'end': 43,
'probability': 0.8424644728072508,
'start': 41,
'text': '本週'}],
'組織': [{'end': 87,
'probability': 0.5550909248934985,
'start': 81,
'text': 'OpenAI'}]}]
使用預設模型 uie-base 進行命名實體識別,效果還不錯,大多數的命名實體被識別出來了,但依然存在部分實體未被識別出,部分文字被誤識別等問題。比如 "Scott Aaronson" 被識別為了兩個人名,比如 "得克薩斯大學奧斯汀分校" 沒有被識別出來。為提升識別效果,將通過標註少量資料對模型進行微調。
2.基於Label Studio的資料標註

在將智慧標註前,先講解手動標註,通過手動標註後才會感知到智慧標註的提效和互動性。
由於AI studio不支援線上標註,這裡大家在本地端進行標註,標註完畢後上傳資料集即可
2.1 Label Studio安裝
以下標註範例用到的環境設定:
- Python 3.8+
- label-studio == 1.7.1
- paddleocr >= 2.6.0.1
在終端(terminal)使用pip安裝label-studio:
pip install label-studio==1.7.1
安裝完成後,執行以下命令列:
label-studio start
在瀏覽器開啟http://localhost:8080/,輸入使用者名稱和密碼登入,開始使用label-studio進行標註。
2.2 實體抽取任務標註
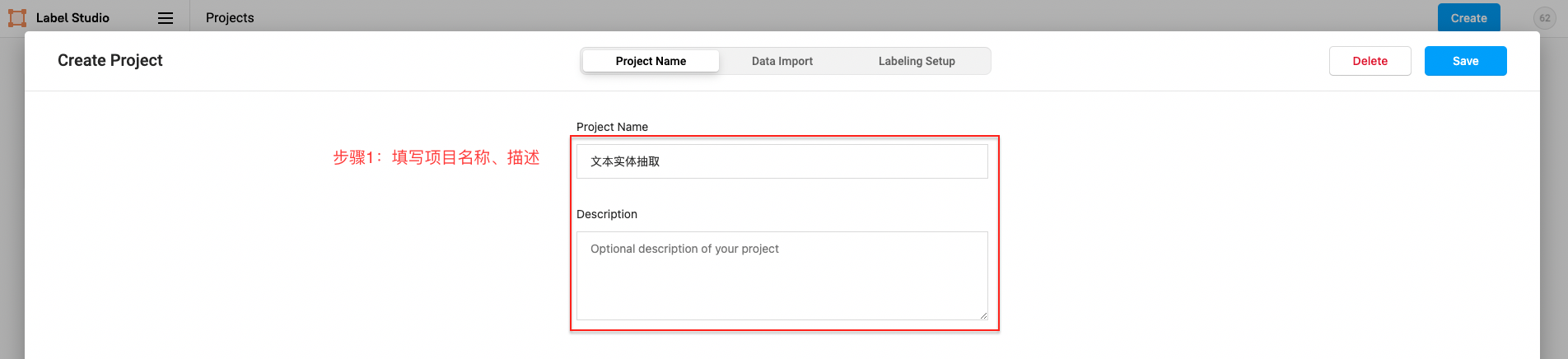
- 專案建立
點選建立(Create)開始建立一個新的專案,填寫專案名稱、描述,然後選擇Object Detection with Bounding Boxes。
填寫專案名稱、描述
- 命名實體識別任務選擇
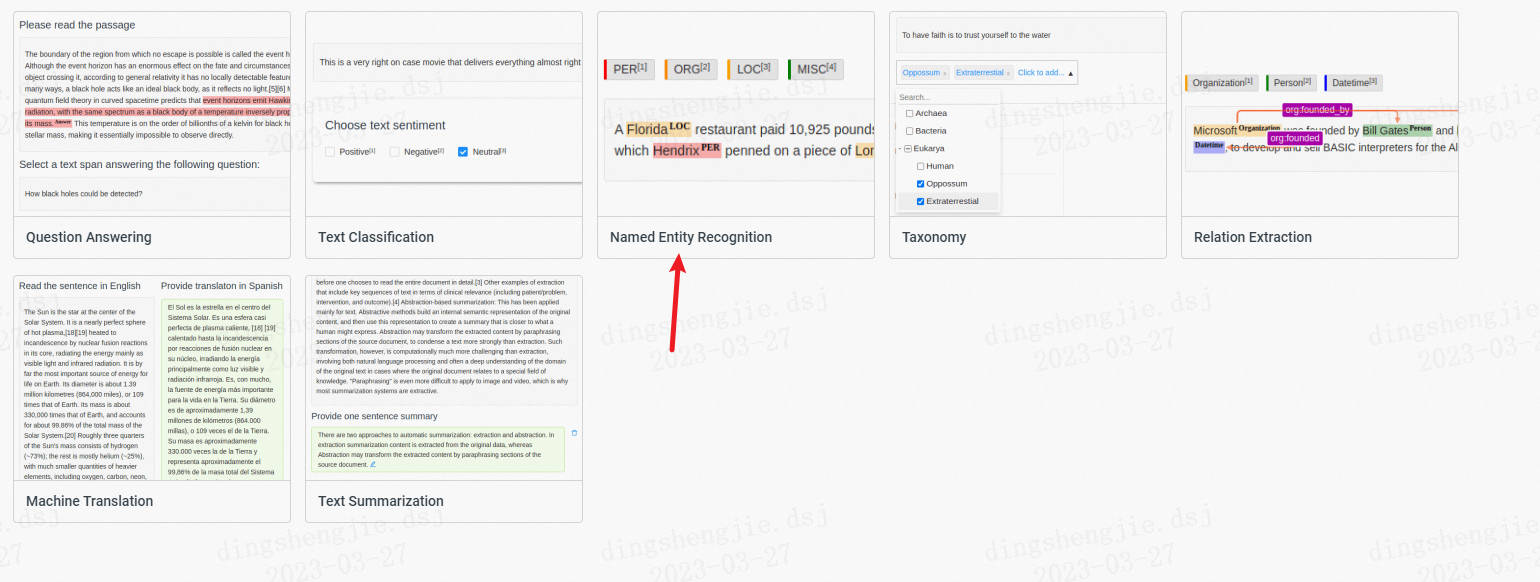
-
新增標籤(也可跳過後續在Setting/Labeling Interface中設定)
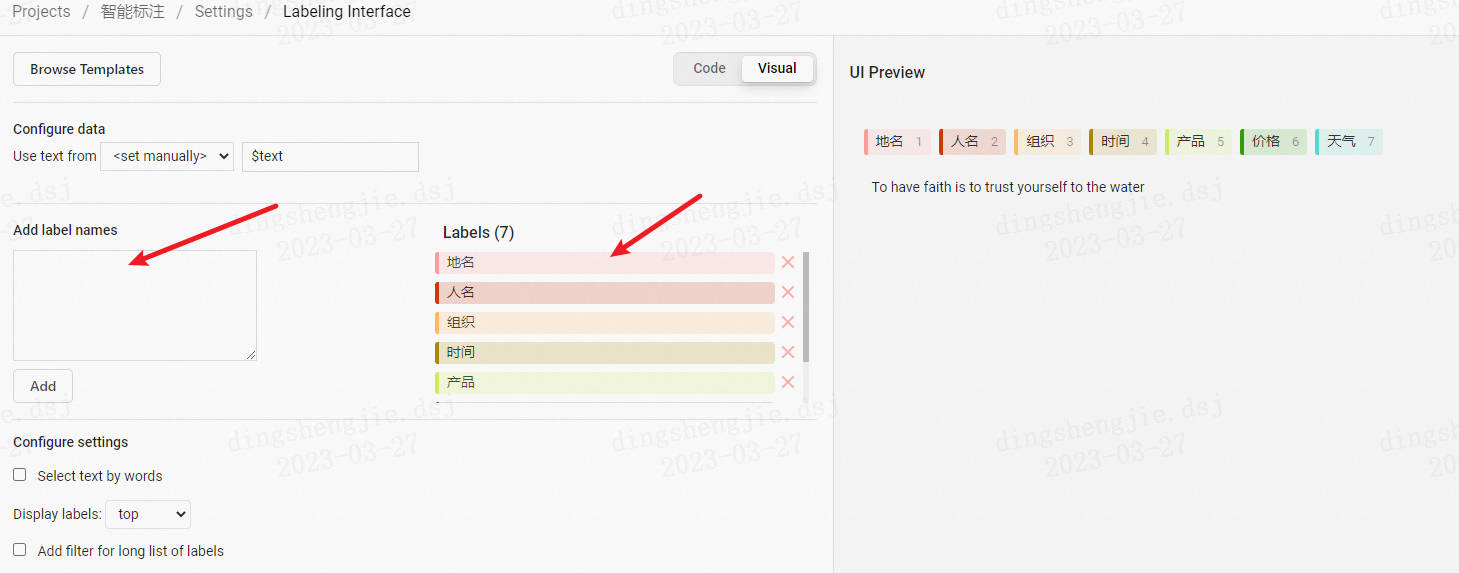
-
資料上傳
先從本地上傳txt格式檔案,選擇List of tasks,然後選擇匯入本專案。

-
實體抽取標註
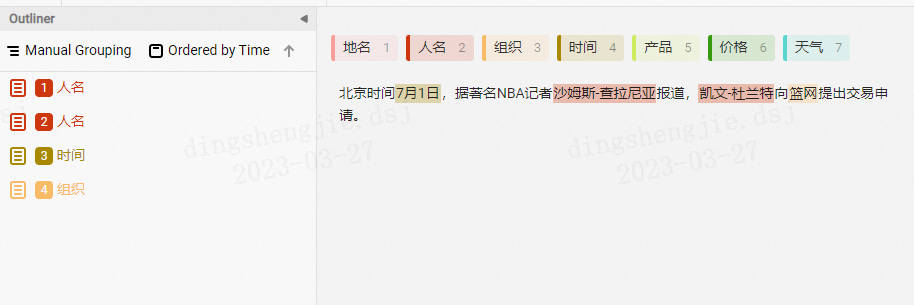
- 資料匯出
勾選已標註文字ID,選擇匯出的檔案型別為JSON,匯出資料:

3. 模型微調
3.1 資料轉換
在終端中執行以下指令碼,將 label studio 匯出的資料檔案格式轉換成 doccano 匯出的資料檔案格式。
python labelstudio2doccano.py --labelstudio_file dataset/label-studio.json
引數說明:
- labelstudio_file: label studio 的匯出檔案路徑(僅支援 JSON 格式)。
- doccano_file: doccano 格式的資料檔案儲存路徑,預設為 "doccano_ext.jsonl"。
- task_type: 任務型別,可選有抽取("ext")和分類("cls")兩種型別的任務,預設為 "ext"。
!python doccano.py \
--doccano_file dataset/doccano_ext.jsonl \
--task_type "ext" \
--save_dir ./data \
--splits 0.8 0.2 0
[2023-03-27 16:43:33,438] [ INFO] - Converting doccano data...
100%|████████████████████████████████████████| 40/40 [00:00<00:00, 29794.38it/s]
[2023-03-27 16:43:33,440] [ INFO] - Adding negative samples for first stage prompt...
100%|███████████████████████████████████████| 40/40 [00:00<00:00, 118650.75it/s]
[2023-03-27 16:43:33,441] [ INFO] - Converting doccano data...
100%|████████████████████████████████████████| 10/10 [00:00<00:00, 38095.40it/s]
[2023-03-27 16:43:33,442] [ INFO] - Adding negative samples for first stage prompt...
100%|███████████████████████████████████████| 10/10 [00:00<00:00, 130257.89it/s]
[2023-03-27 16:43:33,442] [ INFO] - Converting doccano data...
0it [00:00, ?it/s]
[2023-03-27 16:43:33,442] [ INFO] - Adding negative samples for first stage prompt...
0it [00:00, ?it/s]
[2023-03-27 16:43:33,444] [ INFO] - Save 274 examples to ./data/train.txt.
[2023-03-27 16:43:33,445] [ INFO] - Save 70 examples to ./data/dev.txt.
[2023-03-27 16:43:33,445] [ INFO] - Save 0 examples to ./data/test.txt.
[2023-03-27 16:43:33,445] [ INFO] - Finished! It takes 0.01 seconds
引數說明:
- doccano_file: doccano 格式的資料標註檔案路徑。
- task_type: 選擇任務型別,可選有抽取("ext")和分類("cls")兩種型別的任務。
- save_dir: 訓練資料的儲存目錄,預設儲存在 data 目錄下。
- negative_ratio: 最大負例比例,該引數只對抽取型別任務有效,適當構造負例可提升模型效果。負例數量和實際的標籤數量有關,最大負例數量 = negative_ratio * 正例數量。該引數只對訓練集有效,預設為 5。為了保證評估指標的準確性,驗證集和測試集預設構造全負例。
- splits: 劃分資料集時訓練集、驗證集、測試集所佔的比例。預設為 [0.8, 0.1, 0.1] 。
- options: 指定分類任務的類別標籤,該引數只對分類型別任務有效。預設為 ["正向", "負向"]。
- prompt_prefix: 宣告分類任務的 prompt 字首資訊,該引數只對分類型別任務有效。預設為 "情感傾向"。
- is_shuffle: 是否對資料集進行隨機打散,預設為 True。
- seed: 隨機種子,預設為 1000。
- separator: 實體類別/評價維度與分類標籤的分隔符,該引數只對實體/評價維度級分類任務有效。預設為 "##"。
注:
- 每次執行 doccano.py 指令碼,將會覆蓋已有的同名資料檔案。
3.2 Finetune
在終端中執行以下指令碼進行模型微調。
# 然後在終端中執行以下指令碼,對 doccano 格式的資料檔案進行處理,執行後會在 /home/data 目錄下生成訓練/驗證/測試集檔案。
!python finetune.py \
--train_path "./data/train.txt" \
--dev_path "./data/dev.txt" \
--save_dir "./checkpoint" \
--learning_rate 1e-5 \
--batch_size 32 \
--max_seq_len 512 \
--num_epochs 100 \
--model "uie-base" \
--seed 1000 \
--logging_steps 100 \
--valid_steps 100 \
--device "gpu"
[2023-03-27 16:47:58,806] [ INFO] - Downloading resource files...
[2023-03-27 16:47:58,810] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load 'uie-base'.
W0327 16:47:58.836591 13399 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0327 16:47:58.839186 13399 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
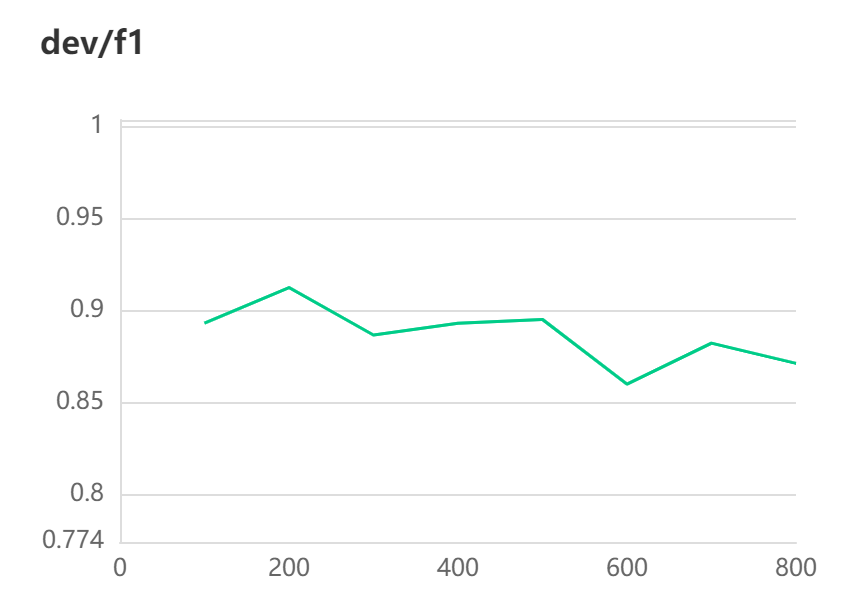
[2023-03-27 16:48:30,349] [ INFO] - global step 100, epoch: 12, loss: 0.00060, speed: 3.46 step/s
[2023-03-27 16:48:30,794] [ INFO] - Evaluation precision: 0.93878, recall: 0.85185, F1: 0.89320
[2023-03-27 16:48:30,794] [ INFO] - best F1 performence has been updated: 0.00000 --> 0.89320
[2023-03-27 16:48:58,054] [ INFO] - global step 200, epoch: 23, loss: 0.00032, speed: 3.82 step/s
[2023-03-27 16:48:58,500] [ INFO] - Evaluation precision: 0.95918, recall: 0.87037, F1: 0.91262
[2023-03-27 16:48:58,500] [ INFO] - best F1 performence has been updated: 0.89320 --> 0.91262
[2023-03-27 16:49:25,664] [ INFO] - global step 300, epoch: 34, loss: 0.00022, speed: 3.83 step/s
[2023-03-27 16:49:26,107] [ INFO] - Evaluation precision: 0.90385, recall: 0.87037, F1: 0.88679
[2023-03-27 16:49:52,155] [ INFO] - global step 400, epoch: 45, loss: 0.00017, speed: 3.84 step/s
[2023-03-27 16:49:52,601] [ INFO] - Evaluation precision: 0.93878, recall: 0.85185, F1: 0.89320
[2023-03-27 16:50:18,632] [ INFO] - global step 500, epoch: 56, loss: 0.00014, speed: 3.84 step/s
[2023-03-27 16:50:19,075] [ INFO] - Evaluation precision: 0.92157, recall: 0.87037, F1: 0.89524
[2023-03-27 16:50:45,077] [ INFO] - global step 600, epoch: 67, loss: 0.00012, speed: 3.85 step/s
[2023-03-27 16:50:45,523] [ INFO] - Evaluation precision: 0.93478, recall: 0.79630, F1: 0.86000
[2023-03-27 16:51:11,546] [ INFO] - global step 700, epoch: 78, loss: 0.00010, speed: 3.84 step/s
[2023-03-27 16:51:11,987] [ INFO] - Evaluation precision: 0.93750, recall: 0.83333, F1: 0.88235
[2023-03-27 16:51:38,013] [ INFO] - global step 800, epoch: 89, loss: 0.00009, speed: 3.84 step/s
[2023-03-27 16:51:38,457] [ INFO] - Evaluation precision: 0.93617, recall: 0.81481, F1: 0.87129
[2023-03-27 16:52:04,361] [ INFO] - global step 900, epoch: 100, loss: 0.00008, speed: 3.86 step/s
[2023-03-27 16:52:04,808] [ INFO] - Evaluation precision: 0.95745, recall: 0.83333, F1: 0.89109
結果展示:
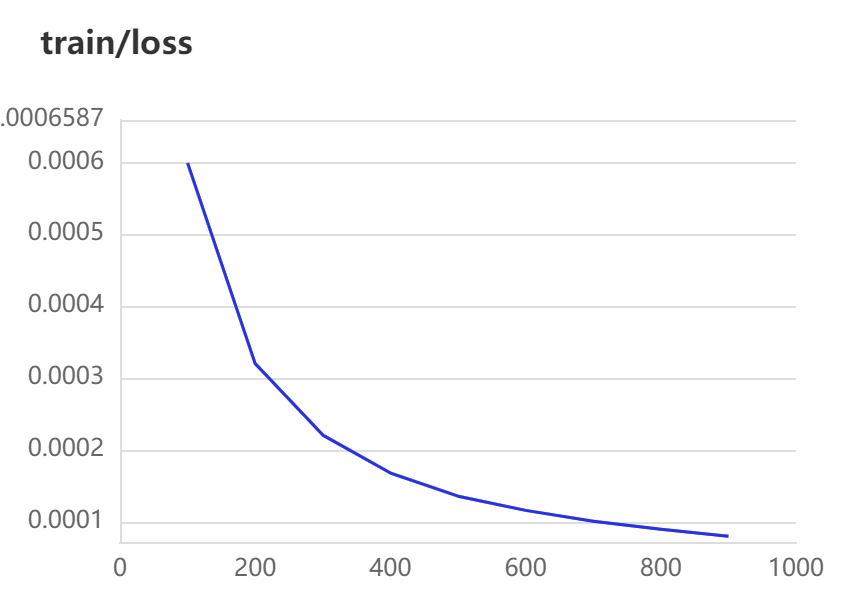
引數說明:
- train_path: 訓練集檔案路徑。
- dev_path: 驗證集檔案路徑。
- save_dir: 模型儲存路徑,預設為 "./checkpoint"。
- learning_rate: 學習率,預設為 1e-5。
- batch_size: 批次處理大小,請結合機器情況進行調整,預設為 16。
- max_seq_len: 文字最大切分長度,輸入超過最大長度時會對輸入文字進行自動切分,預設為 512。
- num_epochs: 訓練輪數,預設為 100。
- model: 選擇模型,程式會基於選擇的模型進行模型微調,可選有 "uie-base", "uie-medium", "uie-mini", "uie-micro" 和 "uie-nano",預設為 "uie-base"。
- seed: 隨機種子,預設為 1000。
- logging_steps: 紀錄檔列印的間隔 steps 數,預設為 10。
- valid_steps: evaluate 的間隔 steps 數,預設為 100。
- device: 選用什麼裝置進行訓練,可選 "cpu" 或 "gpu"。
- init_from_ckpt: 初始化模型引數的路徑,可從斷點處繼續訓練。
3.3 模型評估
在終端中執行以下指令碼進行模型評估。
輸出範例:
引數說明:
- model_path: 進行評估的模型資料夾路徑,路徑下需包含模型權重檔案 model_state.pdparams 及組態檔 model_config.json。
- test_path: 進行評估的測試集檔案。
- batch_size: 批次處理大小,請結合機器情況進行調整,預設為 16。
- max_seq_len: 文字最大切分長度,輸入超過最大長度時會對輸入文字進行自動切分,預設為 512。
- debug: 是否開啟 debug 模式對每個正例類別分別進行評估,該模式僅用於模型偵錯,預設關閉。
debug 模式輸出範例:
!python evaluate.py \
--model_path ./checkpoint/model_best \
--test_path ./data/dev.txt \
--batch_size 16 \
--max_seq_len 512
[2023-03-27 16:56:21,832] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint/model_best'.
W0327 16:56:21.863559 15278 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0327 16:56:21.866312 15278 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[2023-03-27 16:56:27,409] [ INFO] - -----------------------------
[2023-03-27 16:56:27,409] [ INFO] - Class Name: all_classes
[2023-03-27 16:56:27,409] [ INFO] - Evaluation Precision: 0.95918 | Recall: 0.87037 | F1: 0.91262
!python evaluate.py \
--model_path ./checkpoint/model_best \
--test_path ./data/dev.txt \
--debug
[2023-03-27 16:56:31,824] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint/model_best'.
W0327 16:56:31.856709 15361 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0327 16:56:31.859668 15361 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[2023-03-27 16:56:37,039] [ INFO] - -----------------------------
[2023-03-27 16:56:37,039] [ INFO] - Class Name: 時間
[2023-03-27 16:56:37,039] [ INFO] - Evaluation Precision: 1.00000 | Recall: 0.90000 | F1: 0.94737
[2023-03-27 16:56:37,092] [ INFO] - -----------------------------
[2023-03-27 16:56:37,092] [ INFO] - Class Name: 地名
[2023-03-27 16:56:37,092] [ INFO] - Evaluation Precision: 0.95833 | Recall: 0.85185 | F1: 0.90196
[2023-03-27 16:56:37,113] [ INFO] - -----------------------------
[2023-03-27 16:56:37,113] [ INFO] - Class Name: 產品
[2023-03-27 16:56:37,113] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2023-03-27 16:56:37,139] [ INFO] - -----------------------------
[2023-03-27 16:56:37,139] [ INFO] - Class Name: 組織
[2023-03-27 16:56:37,139] [ INFO] - Evaluation Precision: 1.00000 | Recall: 0.50000 | F1: 0.66667
[2023-03-27 16:56:37,161] [ INFO] - -----------------------------
[2023-03-27 16:56:37,161] [ INFO] - Class Name: 人名
[2023-03-27 16:56:37,161] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2023-03-27 16:56:37,181] [ INFO] - -----------------------------
[2023-03-27 16:56:37,181] [ INFO] - Class Name: 天氣
[2023-03-27 16:56:37,181] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2023-03-27 16:56:37,198] [ INFO] - -----------------------------
[2023-03-27 16:56:37,198] [ INFO] - Class Name: 價格
[2023-03-27 16:56:37,198] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
3.4 微調後效果
my_ie = Taskflow("information_extraction", schema=schema, task_path='./checkpoint/model_best') # task_path 指定模型權重檔案的路徑
pprint(my_ie("2K 與 Gearbox Software 宣佈,《小緹娜的奇幻之地》將於 6 月 24 日凌晨 1 點登入 Steam,此前 PC 平臺為 Epic 限時獨佔。在限定期間內,Steam 玩家可以在 Steam 入手《小緹娜的奇幻之地》,並在 2022 年 7 月 8 日前享有獲得黃金英雄鎧甲包。"))
[2023-03-27 16:59:31,064] [ INFO] - Converting to the inference model cost a little time.
[2023-03-27 16:59:38,171] [ INFO] - The inference model save in the path:./checkpoint/model_best/static/inference
[2023-03-27 16:59:40,364] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint/model_best'.
[{'產品': [{'end': 118,
'probability': 0.9860373472963602,
'start': 108,
'text': '《小緹娜的奇幻之地》'},
{'end': 35,
'probability': 0.9870597349192849,
'start': 25,
'text': '《小緹娜的奇幻之地》'},
{'end': 148,
'probability': 0.9075982731610566,
'start': 141,
'text': '黃金英雄鎧甲包'}],
'時間': [{'end': 52,
'probability': 0.9998029564426645,
'start': 38,
'text': '6 月 24 日凌晨 1 點'},
{'end': 137,
'probability': 0.9876786236837809,
'start': 122,
'text': '2022 年 7 月 8 日前'}],
'組織': [{'end': 2, 'probability': 0.988802896329716, 'start': 0, 'text': '2K'},
{'end': 93,
'probability': 0.9500440898664806,
'start': 88,
'text': 'Steam'},
{'end': 75,
'probability': 0.9819772965571794,
'start': 71,
'text': 'Epic'},
{'end': 105,
'probability': 0.7921079762008958,
'start': 100,
'text': 'Steam'},
{'end': 60,
'probability': 0.9829542747088276,
'start': 55,
'text': 'Steam'},
{'end': 21,
'probability': 0.9994613042455924,
'start': 5,
'text': 'Gearbox Software'}]}]
pprint(my_ie("近日,量子計算專家、ACM計算獎得主Scott Aaronson通過部落格宣佈,將於本週離開得克薩斯大學奧斯汀分校(UT Austin)一年,並加盟人工智慧研究公司OpenAI。"))
[{'人名': [{'end': 32,
'probability': 0.9990170436659866,
'start': 18,
'text': 'Scott Aaronson'}],
'時間': [{'end': 2,
'probability': 0.9998477751029782,
'start': 0,
'text': '近日'},
{'end': 43,
'probability': 0.9995671774285029,
'start': 41,
'text': '本週'}],
'組織': [{'end': 66,
'probability': 0.9900270615638647,
'start': 57,
'text': 'UT Austin'},
{'end': 87,
'probability': 0.9993388552686611,
'start': 81,
'text': 'OpenAI'},
{'end': 56,
'probability': 0.9968586409231648,
'start': 45,
'text': '得克薩斯大學奧斯汀分校'},
{'end': 13,
'probability': 0.8437228020724348,
'start': 10,
'text': 'ACM'}]}]
基於 50 條標註資料進行模型微調後,效果有所提升。
4.基於Label Studio的智慧標註(含自動訓練)
部分效果展示更多詳細內容檢視連結:
人工智慧知識圖譜之資訊抽取:基於Labelstudio的UIE半監督深度學習的智慧標註方案(雲端版),提效。
裡面有詳細程式碼實現
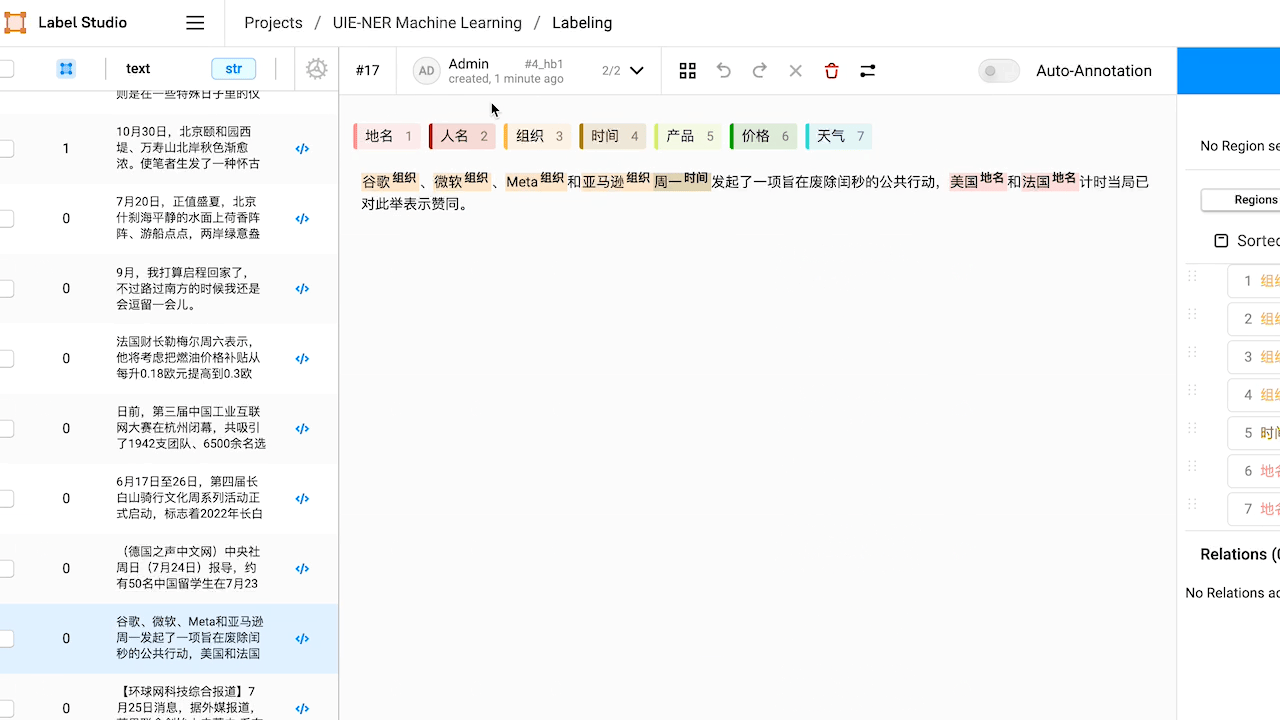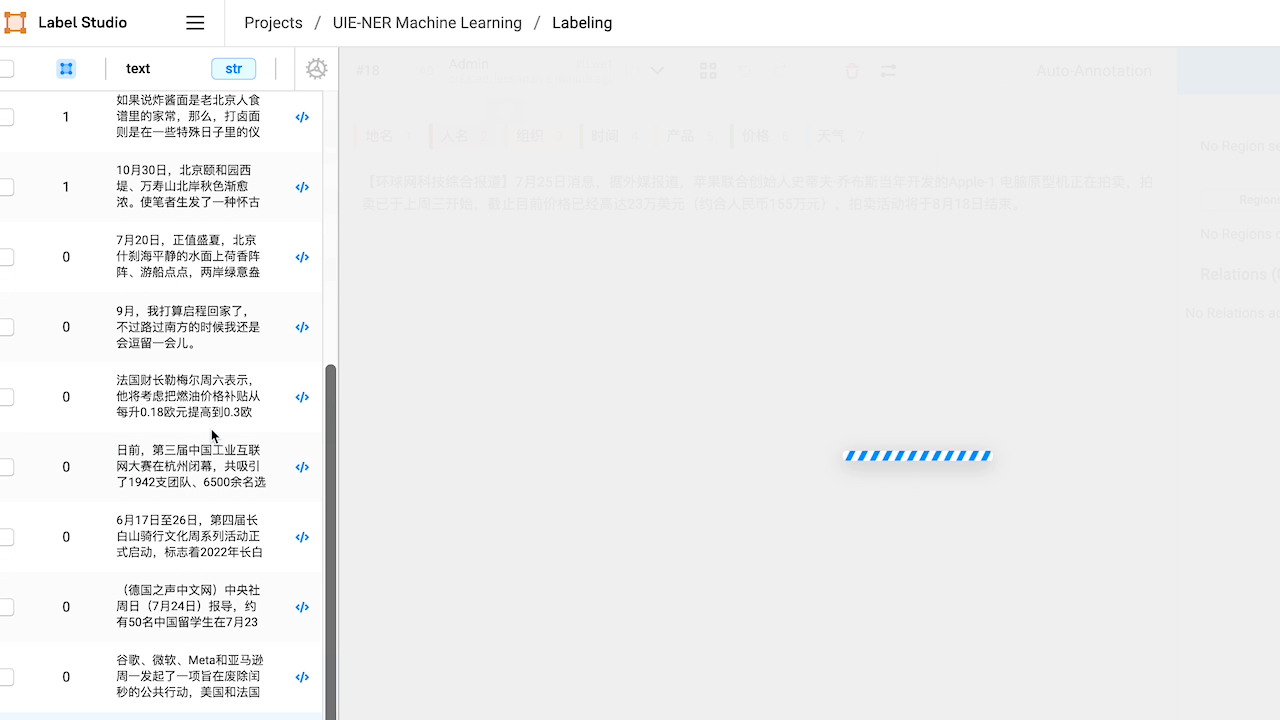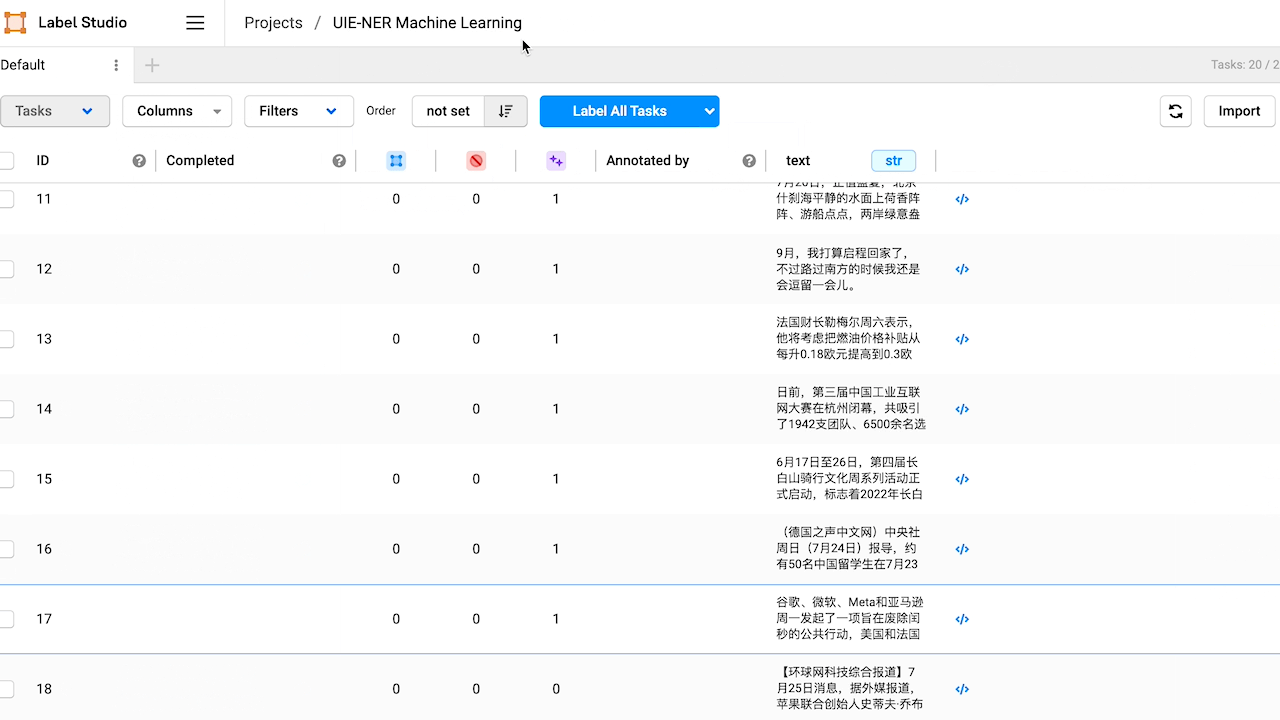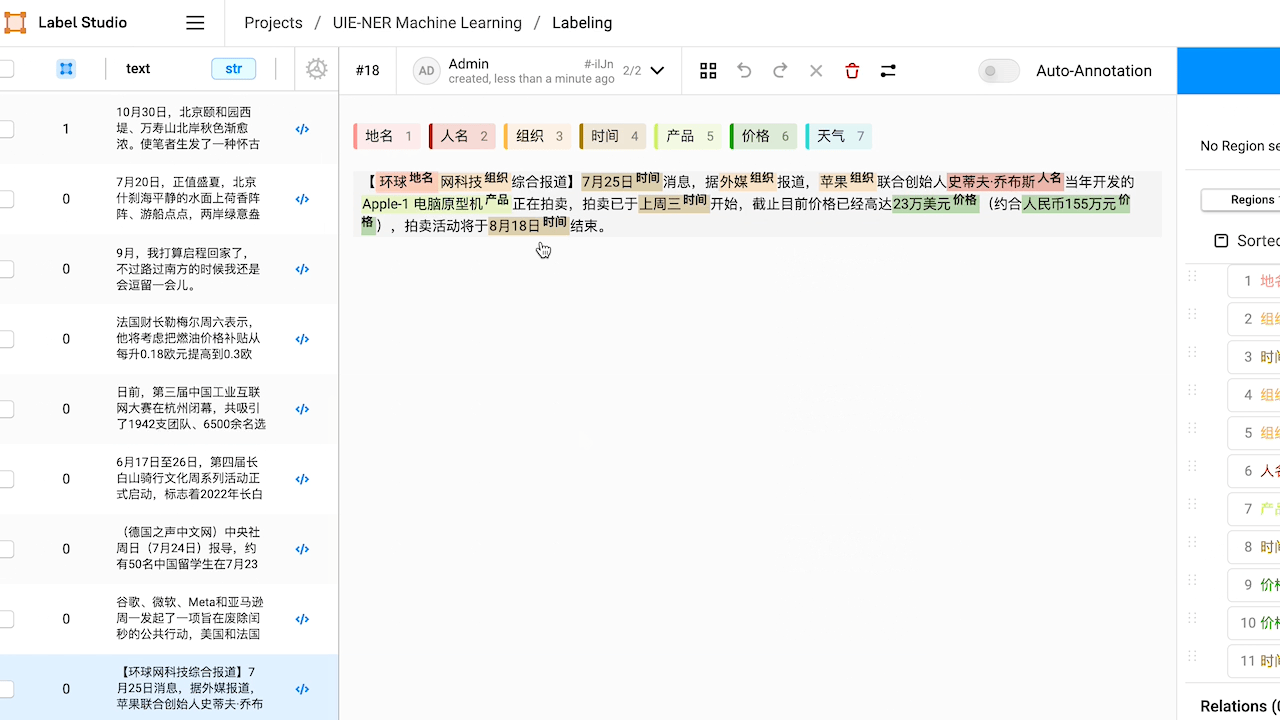
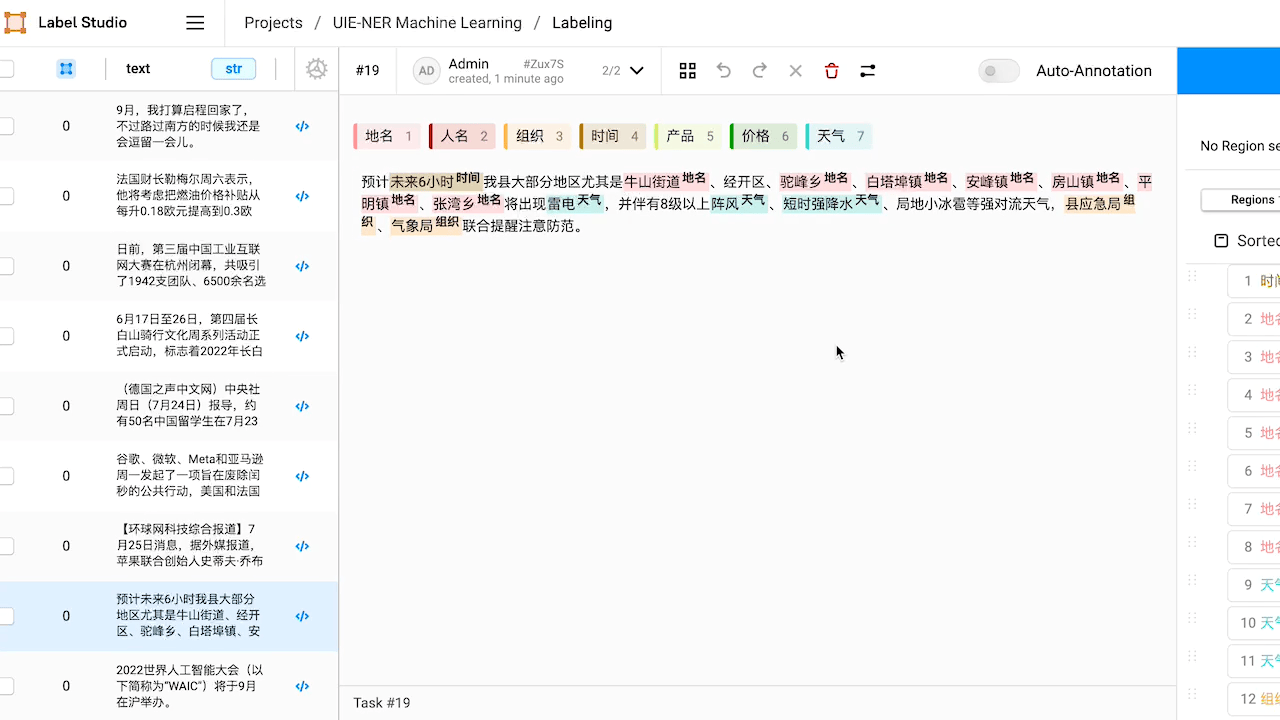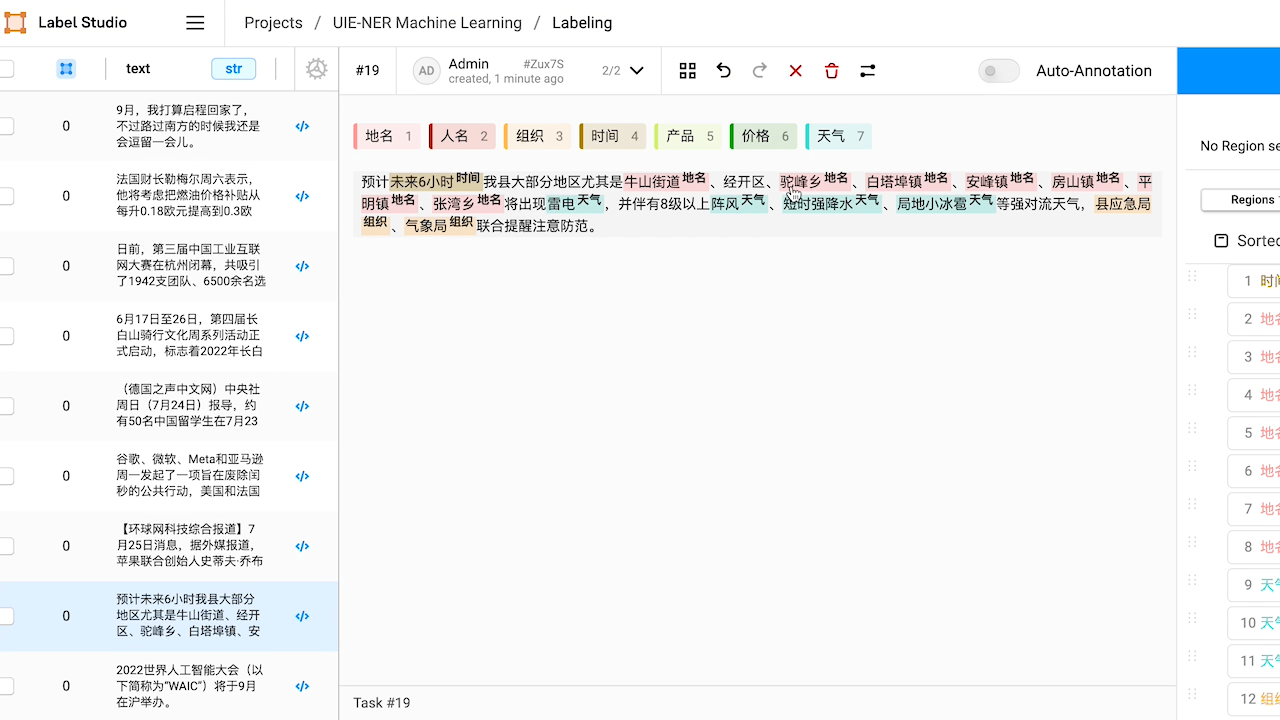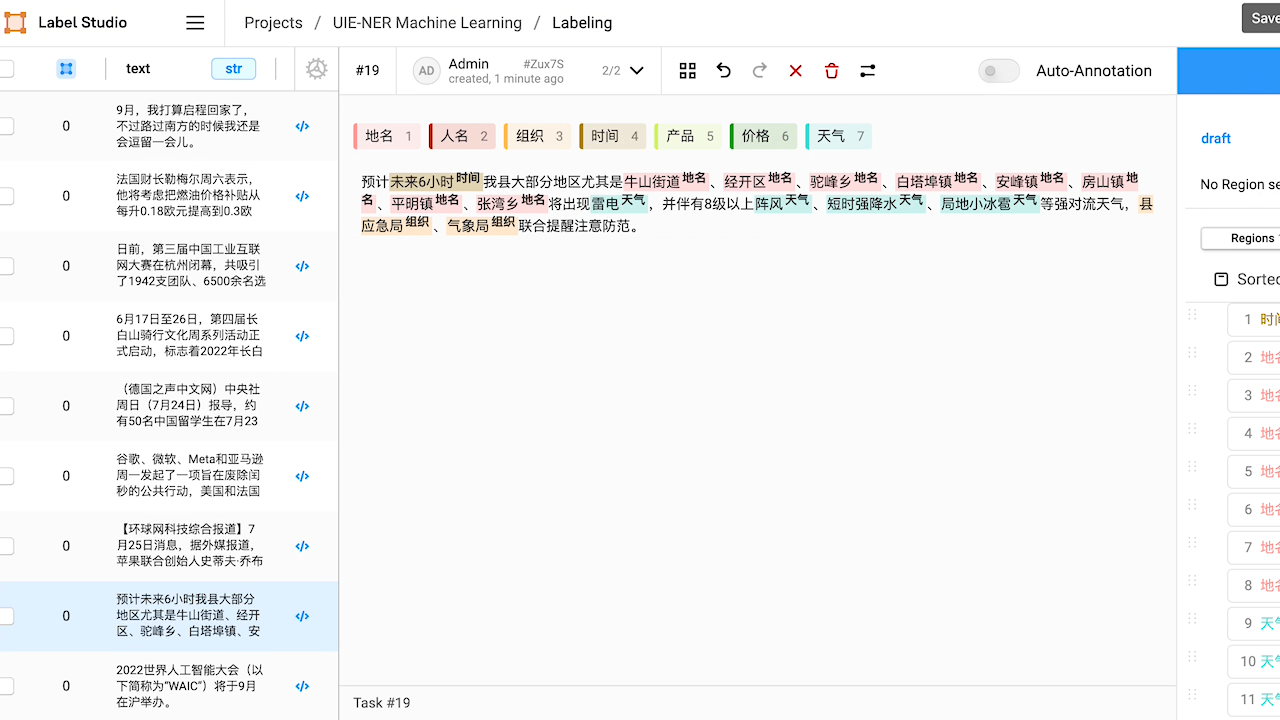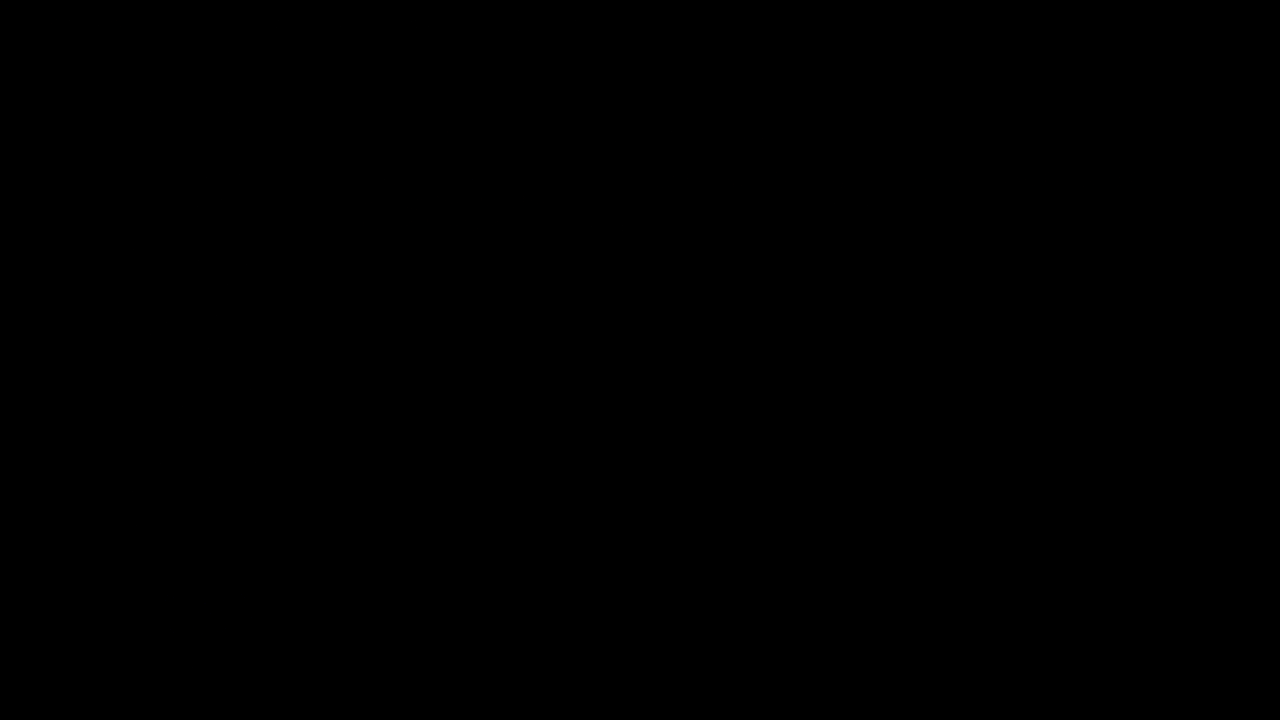
檢視預標註好的資料,如有必要,對標註進行修改。


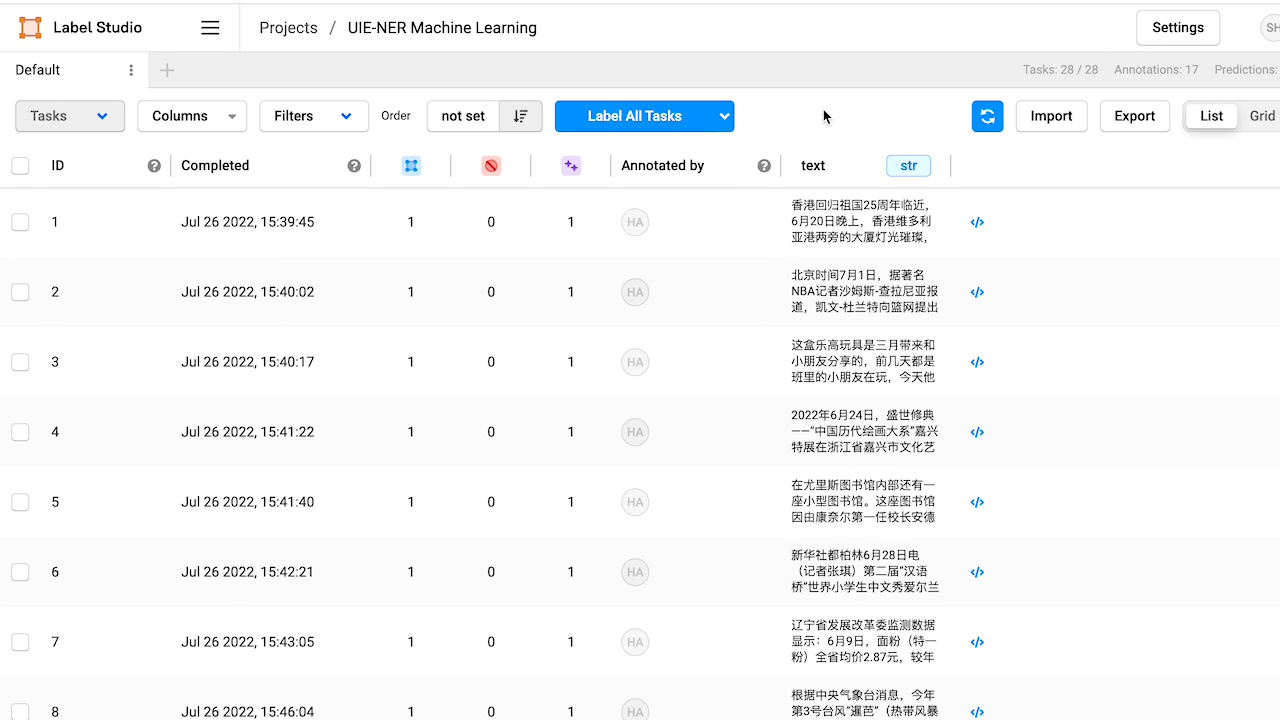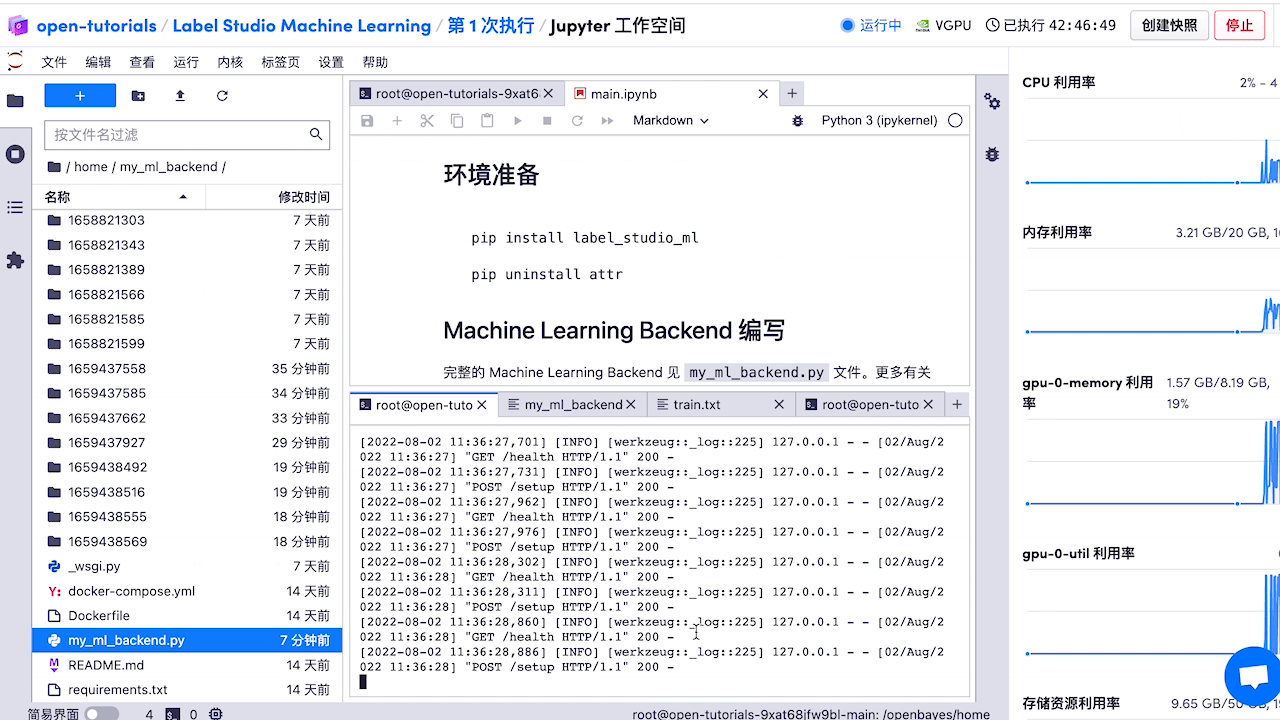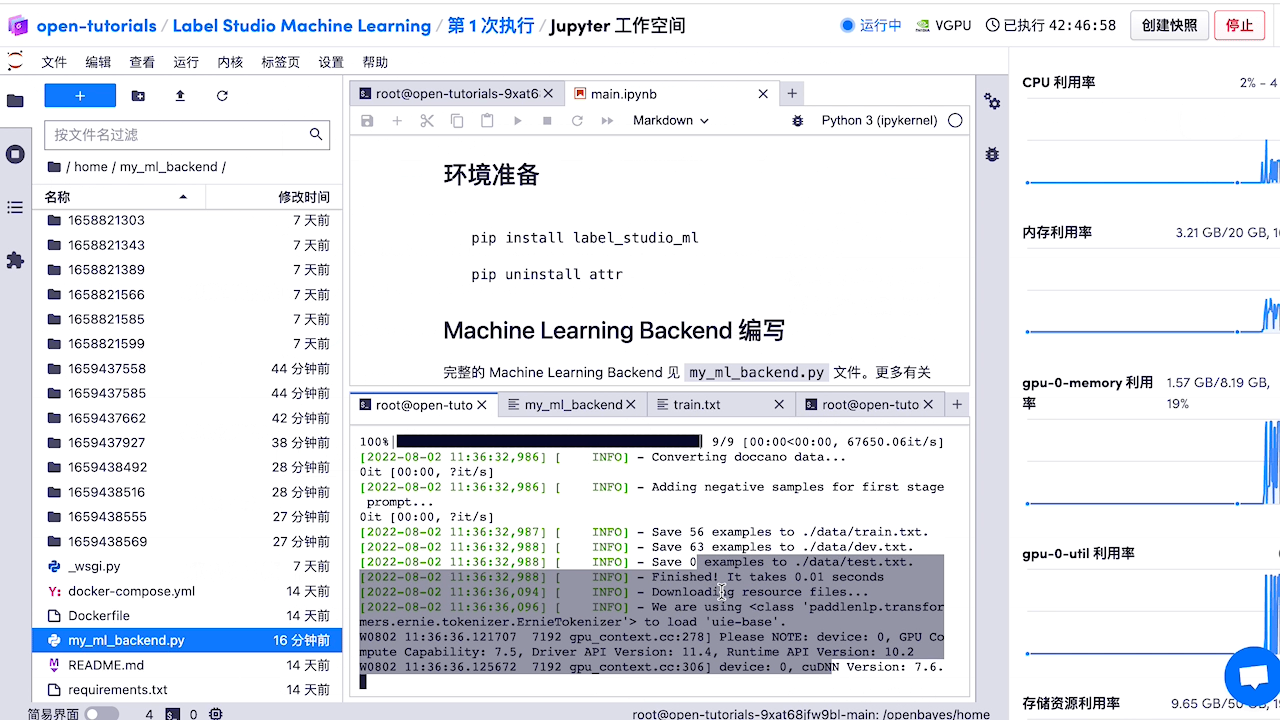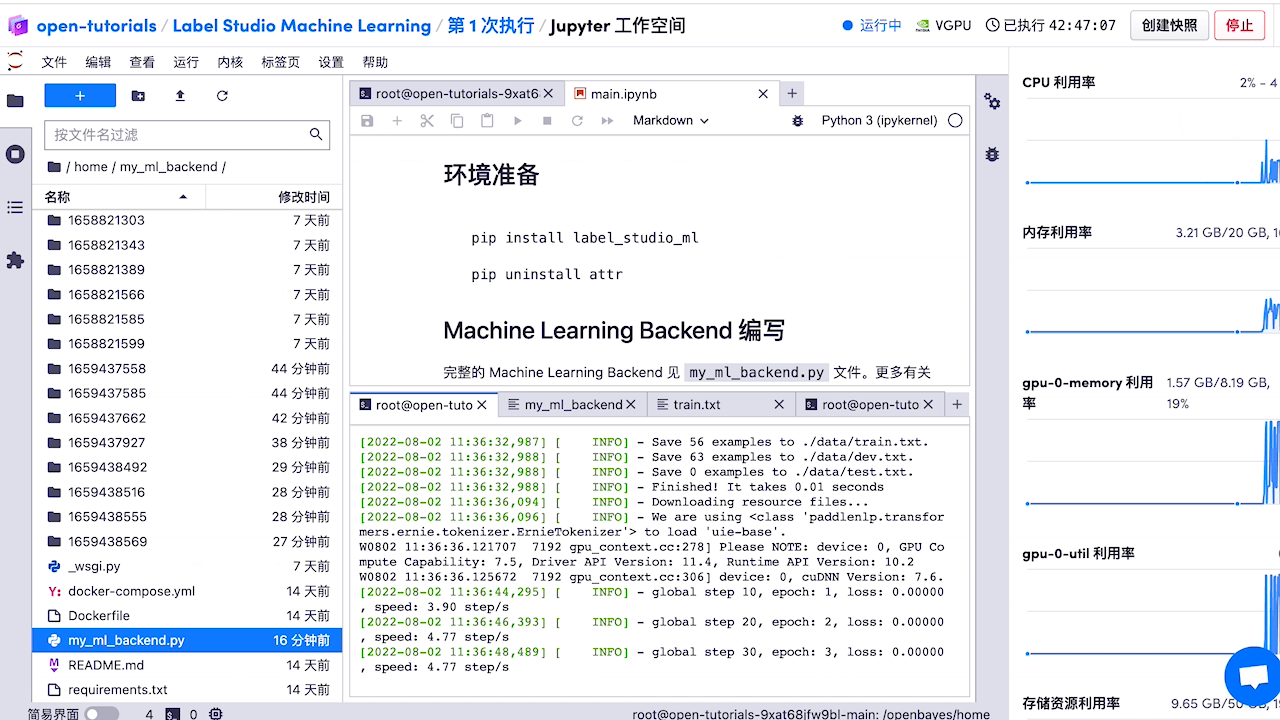
5.模型部署
以下是 UIE Python 端的部署流程,包括環境準備、模型匯出和使用範例。
5.1 UIE Python 端的部署流程
-
模型匯出
模型訓練、壓縮時已經自動進行了靜態圖的匯出以及 tokenizer 組態檔儲存,儲存路徑${finetuned_model} 下應該有 .pdimodel、.pdiparams 模型檔案可用於推理。 -
模型部署
以下範例展示如何基於 FastDeploy 庫完成 UIE 模型完成通用資訊抽取任務的 Python 預測部署。先參考 UIE 模型部署安裝FastDeploy Python 依賴包。 可通過命令列引數--device以及--backend指定執行在不同的硬體以及推理引擎後端,並使用--model_dir引數指定執行的模型。模型目錄為 model_zoo/uie/checkpoint/model_best(使用者可按實際情況設定)。
FastDeploy提供各平臺預編譯庫,供開發者直接下載安裝使用。當然FastDeploy編譯也非常容易,開發者也可根據自身需求編譯FastDeploy。
GPU端
為了在GPU上獲得最佳的推理效能和穩定性,請先確保機器已正確安裝NVIDIA相關驅動和基礎軟體,確保CUDA >= 11.2,cuDNN >= 8.1.1,並使用以下命令安裝所需依賴
5.2 Serving 服務編寫
編寫 predictor.py 檔案:
-
匯入依賴庫:除了業務中用到的庫之外,需要額外依賴serving。
-
後處理(可選):根據需要對模型返回的結果進行處理,以更好地展示。本教學中通過
format()函數和add_o()函數修改命名實體識別結果的形式。 -
Predictor 類: 不需要繼承其他的類,但是至少需要提供
__init__和predict兩個介面。- 在
__init__中定義實體抽取結構,通過Taskflow載入模型。 - 在
predict中進行預測,返回後處理的結果。
- 在
class Predictor:
def __init__(self):
self.schema = ['地名', '人名', '組織', '時間', '產品', '價格', '天氣']
self.ie = Taskflow("information_extraction", schema=self.schema, task_path='./checkpoint/model_best')
def predict(self, json):
text = json["input"]
uie = self.ie(text)[0]
result = format(text, uie)
return result
- 執行:啟動服務。
if __name__ == '__main__':
serv.run(Predictor)
在專案根目錄下已經提供了編寫好的 predictor.py 可以直接在後續使用。
# !paddlenlp server server:app --workers 1 --host 0.0.0.0 --port 8189
# !pip install --upgrade paddlenlp
# import json
# import requests
# url = "http://0.0.0.0:8189/taskflow/uie"
# headers = {"Content-Type": "application/json"}
# texts = ["近日,量子計算專家、ACM計算獎得主Scott Aaronson通過部落格宣佈,將於本週離開得克薩斯大學奧斯汀分校(UT Austin)一年,並加盟人工智慧研究公司OpenAI"]
# data = {
# "data": {
# "text": texts,
# }
# }
# r = requests.post(url=url, headers=headers, data=json.dumps(data))
# datas = json.loads(r.text)
# print(datas)
6.總結
- Label Studio 所提供的 Machine Learning Backend 提供了一個比較靈活的輔助人工標註的框架,我們通過它確實可以加快 nlp 資料的標註
- Label Studio 的 enterprise 版本提供了 Active Learning 的流程,不過從其描述看這個流程並不完美,尤其是 fit 部分,由於 Label Studio 低估了「Train」所花費的時間,所以每次標註都自動訓練的流程可能並不會那麼順滑(會在連結時候等待一段時間)
- 這次專案並沒有使用 Label Studio 所提供的「Auto-Annotation」的功能,因為它存在重複標註的問題
- 既然 Label Studio 提供了它的 api 那其實可玩的東西還是很多的,配合 webhook 等內容可能會讓這個標註和訓練的流程做的更加高效
此外目前使用的UIE碼源是前幾個版本的,最新官網更新了一些訓練升級API,後續再重新優化現有專案。
本人對容器相關技術不太瞭解,所以在一些容器化技術操作上更多就是借鑑使用了,如有疑問評論區留言即可。
更多詳情請參考Label Studio官網:
6.1 專案連結
部分效果展示更多詳細內容檢視連結:
人工智慧知識圖譜之資訊抽取:基於Labelstudio的UIE半監督深度學習的智慧標註方案(雲端版),提效。
裡面有詳細程式碼實現