AI演演算法測試之淺談
作者:京東物流 李雲敏
一、人工智慧
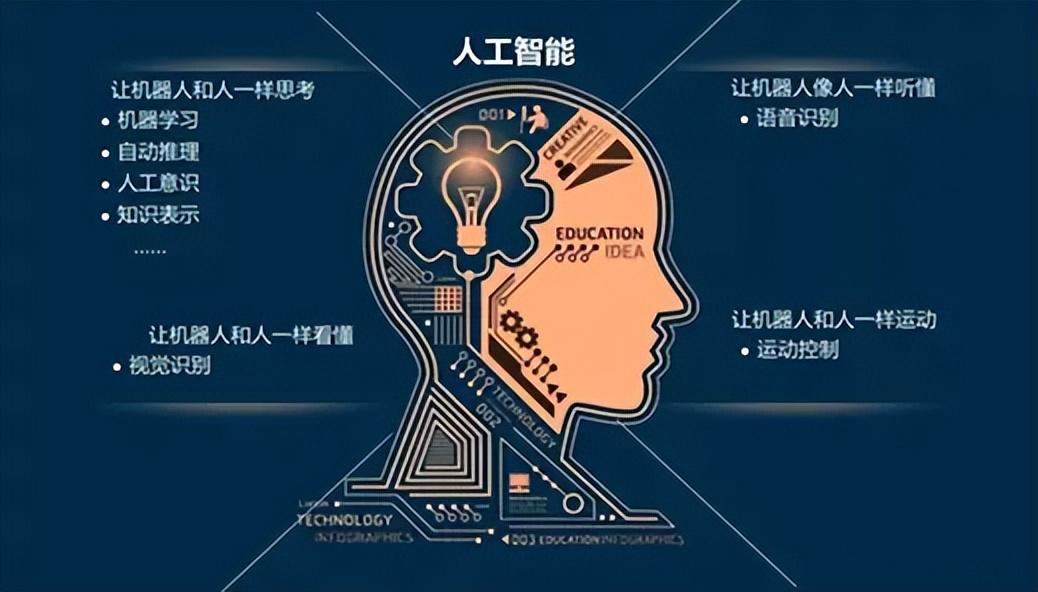
1、人工智慧(AI)是什麼
人工智慧,英文Artificial Intelligence,簡稱AI,是利用機器學習技術模擬、延伸和擴充套件人的智慧的理論、方法、技術及應用的一門新的技術科學。
人工智慧是電腦科學的一個分支,它企圖瞭解智慧的實質,並生產出一種新的能以人類智慧相似的方式做出反應的智慧機器,該領域的研究包括機器人、語言識別、影象識別、自然語言處理和專家系統等。 人工智慧可以對人的意識、思維的資訊過程的模擬。人工智慧不是人的智慧,但能像人那樣思考、也可能超過人的智慧。
通俗的說,就是讓機器可以像人類一樣有智慧,讓機器看得懂、聽得懂、會思考、能決策、能行動,實現原來只有人類才能完成的任務。
2、人工智慧(AI)的本質
AI的本質是通過軟體來實現特定的演演算法。
一個優秀的人工智慧系統,應該具有三個方面的特徵:知識運用的能力、從資料或經驗中學習的能力、處理不確定性的能力。
知識運用能力
知識是智慧體現的一個最重要的維度。聽說看能力如果不考慮內容的深度,則僅僅是停留在感知智慧的層面,只能與環境互動和獲取環境的資訊,其智慧表現的空間非常有限。一個智慧系統應該能夠很好的儲存與表示、運用知識,並基於知識進行歸納推理。
學習能力
從資料中或過去的經驗中學習的能力,這通常需要運用機器學習演演算法。具備一個不斷進化和進步的學習能力,那麼就可能具備更高的智慧水平。同時,學習過程應該能夠融入儘可能多的知識類資訊,才能夠達到支援智慧系統的要求。
不確定性處理能力
能夠很好地處理資料中不確定性,像噪聲、資料屬性缺失,模型決策的不確定性,甚至模型內部引數的不確定性。無人駕駛系統就需要處理各種各樣的不確定性如環境的不確定性、決策的不確定性。
3、人工智慧(AI)的「智力」層級
人工智慧分為弱人工智慧和強人工智慧,前者讓機器具備觀察和感知的能力,可以做到一定程度的理解和推理。而強人工智慧期待讓機器獲得自適應能力,解決一些之前沒有遇到過的問題。
也有人將人工智慧分為弱人工智慧、一般人工智慧和強人工智慧,後超級人工智慧。
人工智慧分為弱人工智慧和強人工智慧,前者讓機器具備觀察和感知的能力,可以做到一定程度的理解和推理。目前的科研都集中在弱人工智慧這部分。而強人工智慧期待讓機器獲得自適應能力,解決一些之前沒有遇到過的問題。
2017年釋出的一項針對AI研究人員的調查報告稱,高階機器智慧(HLMI)實現的總體平均估計值是到2061年。
4、人工智慧(AI)的應用領域
人工智慧涉及廣泛的技術應用
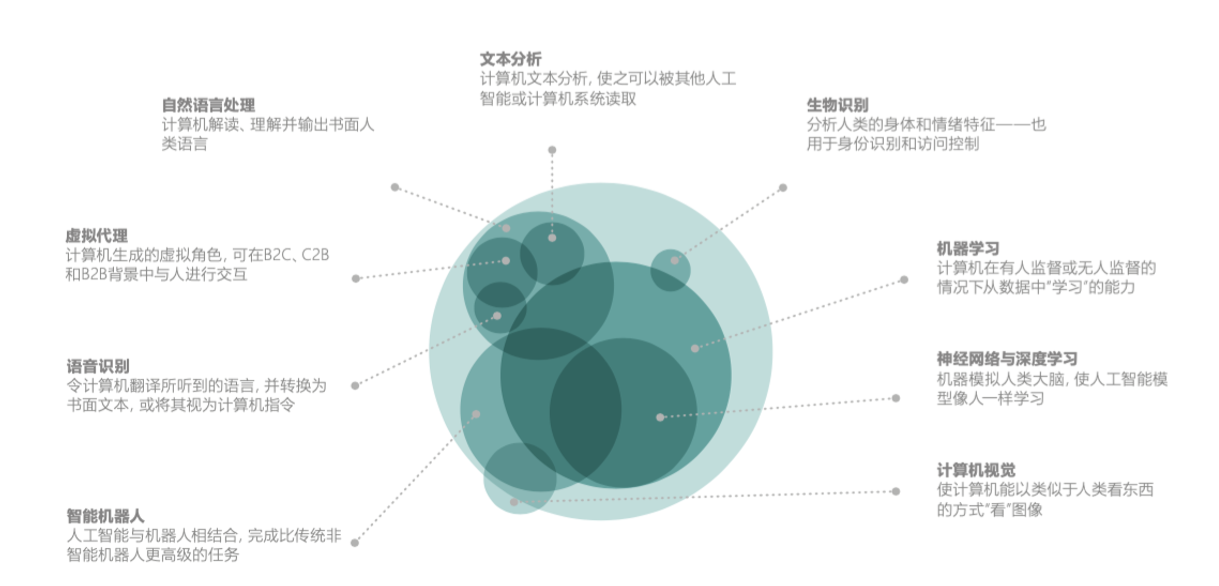
https://img-blog.csdnimg.cn/20200424151404995.gif
目前人工智慧應用最廣泛的領域主要有四個,分別是語音識別和自然語言處理、影象識別與處理、推薦系統、機器學習。
語音識別,如語音的自動翻譯、語音轉文字等。目前微軟的語音識別技術已經達到了人類同等水平,翻譯機器人已經超越專業翻譯水準。
影象識別,如高速車牌識別、臉部辨識等,目前已經廣泛應用在道路監控、停車場、門禁、金融系統存取身份識別等領域。刷臉解鎖、刷臉支付也已經進入我們生活的很多領域。
推薦系統,如電商系統根據使用者的購買習慣,推薦可能需要購買的產品;今日頭條的內容推薦演演算法等。
5G+AI開啟智慧化物流新時代
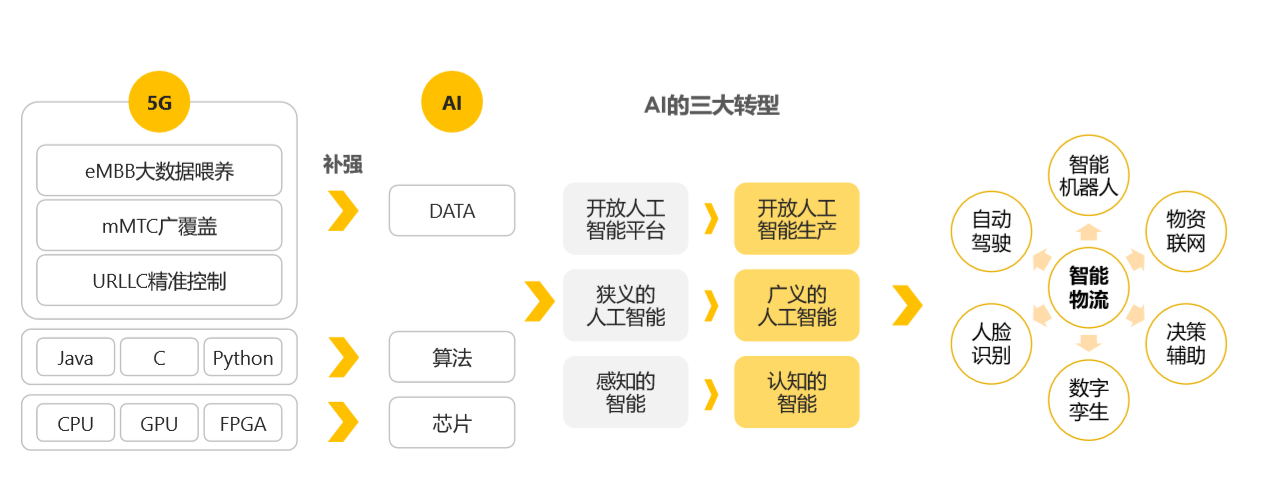
注:圖片資料來源——《2021中國物流科技發展報告》
二、人工智慧和機器學習的關係
人腦具備不斷積累經驗的能力,依賴經驗我們便具備了分析處理的能力,比如我們要去菜場挑一個西瓜,別人或者自己的經驗告訴我們色澤青綠、根蒂蜷縮、敲聲渾響的西瓜比較好吃。我們具備這樣的能力,那麼機器呢?機器不是隻接收指令,處理指令嗎?和人腦類似,可以餵給機器歷史資料,機器依賴建模演演算法生成模型,根據模型便可以處理新的資料得到未知屬性。許多機器學習系統所解決的都是無法直接使用固定規則或者流程程式碼完成的問題,通常這類問題對人類而言卻很簡單。比如,手機中的計算器程式就不屬於具備智慧的系統,因為裡面的計算方法都有清楚而固定的規程;但是如果要求一臺機器去辨別一張照片中都有哪些人或者物體,這對我們人類來講非常容易,然後機器卻非常難做到。
機器學習所研究的主要內容,是關於在計算機上從資料中產生「模型」的演演算法。即學習演演算法,有了學習演演算法,我們把資料提供給它,它就能基於這些資料產生模型;在面對新的資料時,模型會給我們提供相應的預測結果。
機器學習的按學習方式來可以劃分四類: 監督學習、無監督學習、半監督學習和強化學習。
監督學習指的就是我們給學習演演算法一個資料集。這個資料集由「正確答案」組成。關注的是對事物未知表現的預測,一般包括分類問題和迴歸問題。
無監督學習,指在資料集中沒有「正確答案」,期望從資料本身發現一些潛在的規律,無監督學習傾向於事物本身特性的分析,常用的技術包括資料降維和聚類問題。
半監督學習,訓練資料集中有一部分答案,一部分沒答案的稱為半監督學習。
強化學習相對來說比較複雜,是指一個系統和外界環境不斷地互動,獲得外界反饋,然後決定自身的行為,達到長期目標的最佳化。也就是從一開始什麼都不懂, 通過不斷地嘗試, 從錯誤中學習, 最後找到規律, 學會了達到目的的方法。比如AlphaGo用的深度強化學習。
1、機器學習
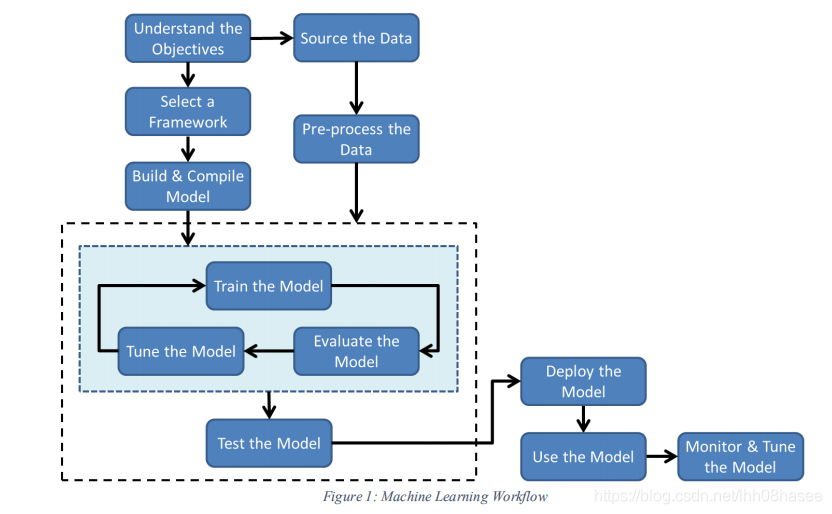
2、機器學習三要素
機器學習三要素包括資料、模型、演演算法。簡單來說,這三要素之間的關係,可以用下面這幅圖來表示
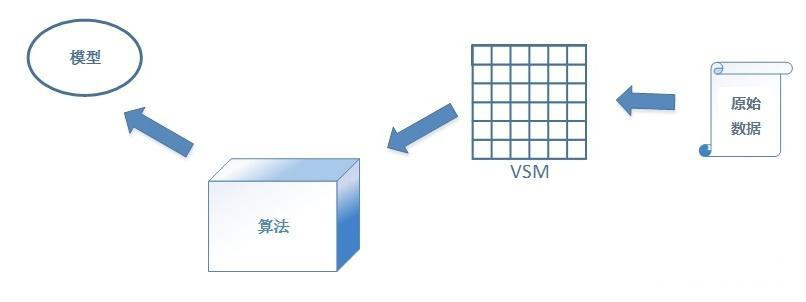
總結成一句話:演演算法通過在資料上進行運算產生模型。
3、資料標註
如圖中不同的動物,給它們分別打上正確的標記。通過演演算法訓練後,達到正確分類的目的。要進行機器學習,首先要有資料。有了資料之後,再對資料進行標註,利用人工標註的資料給到機器進行學習,使機器智慧化。
那實際專案中是怎麼給資料打標註,為什麼要給資料標註?帶著這兩個問題我們來看個視訊。
https://www.thepaper.cn/newsDetail_forward_2052136
4、什麼是模型?
大家來做下這個猜數位遊戲,1, 4, 16…()… 256… 括號裡的是什麼。為什麼是64,不是其他數位,又為什麼是數位,不是一個漢字或者一個字母。我們找到了數位之間的規律,邏輯關係,並且抽象成了模型,我們才能知道括號裡是什麼。
舉個生活中的例子,小米硬體中手機外殼,在大批次生產前需要先設計手機外殼的模具,然後所有同型號的手機外殼都按這個模具樣版生產出來。這個模具也是個硬體上的模型。
演演算法的模型又是什麼?模型是從資料裡抽象出來的,用來描述客觀世界的數學模型。通過對資料的分析,找到其中的規律,找到的規律就是模型。
機器學習的根本目的,是找一個模型去描述我們已經觀測到的資料。
5、機器學習演演算法
例如,你可能會在研究論文和教科書中看到用虛擬碼或 線性代數 描述的機器學習演演算法。你可以看到一個特定的機器學習演演算法與另一個特性演演算法相比的計算效率。
學術界可以設計出很多機器學習演演算法,而機器學習實踐者可以在他們的專案中使用標準的機器學習演演算法。這就像電腦科學的其他領域一樣,學者可以設計出全新的排序演演算法,程式設計師可以在應用程式中使用標準的排序演演算法。
•線性迴歸
•邏輯迴歸
•決策樹
•人工神經網路
•K- 最近鄰
•K- 均值
•
https://img-blog.csdnimg.cn/20200424151404995.gif
你還可能會看到多個機器學習演演算法實現,並在一個具有標準 API 的庫中提供。一個流行的例子是 scikit-learn 庫,它在 Python 中提供了許多分類、迴歸和聚類機器學習演演算法的實現。
三、AI演演算法模型測試
1、模型評估
泛化能力指的是學習方法對未知資料的預測能力。就好比運動員平時都是在訓練場進行訓練,而評估運動員的真實實力要看在大賽中的表現。
我們實際希望的,是在新樣本上能表現得很好的學習器,為了達到這個目的,應該從訓練樣本中儘可能推演出適用於所有潛在樣本的「普通規律」,這樣才能在遇到新樣本時做出正確的預測,泛化能力比較好。
當學習器把訓練樣本學得「太好」了的時候,很可能已經把訓練樣本自身的一些特點當作了所有潛在樣本都會具有的一般性質,這樣就會導致泛化效能下降。這種現象在機器學習中稱為「過擬合「,與之相對是「欠擬合」指的是對訓練樣本的一般性質尚未學習。
有多種因素可能導致過擬合,其中最常見的情況是由於學習能力過於強大,以至於把訓練樣本所包含的不太一般的特性都學到了,而欠擬合則通常是由於學習能力低下而造成的。
2、衡量標準
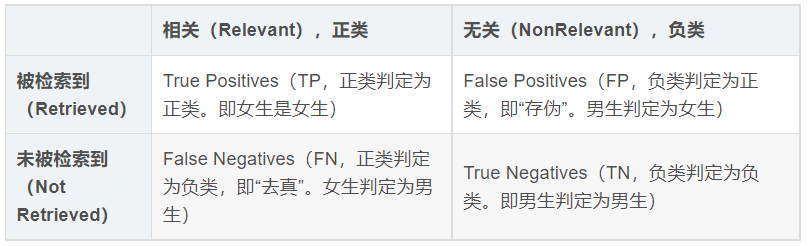
首先有關TP、TN、FP、FN的概念。大體來看,TP與TN都是分對了情況,TP是正類,TN是負類。則推斷出,FP是把錯的分成了對的,而FN則是把對的分成了錯的。
【舉例】一個班裡有男女生,我們來進行分類,把女生看成正類,男生看成是負類。我們可以用混淆矩陣來描述TP、TN、FP、FN。
混淆矩陣
準確率、召回率、F1
人工智慧領域兩個最基本指標是召回率(Recall Rate)和準確率(Precision Rate),召回率也叫查全率,準確率也叫查準率,概念公式:
◦召回率(Recall) = 系統檢索到的相關檔案 / 系統所有相關的檔案總數
◦準確率(Precision) = 系統檢索到的相關檔案 / 系統所有檢索到的檔案總數
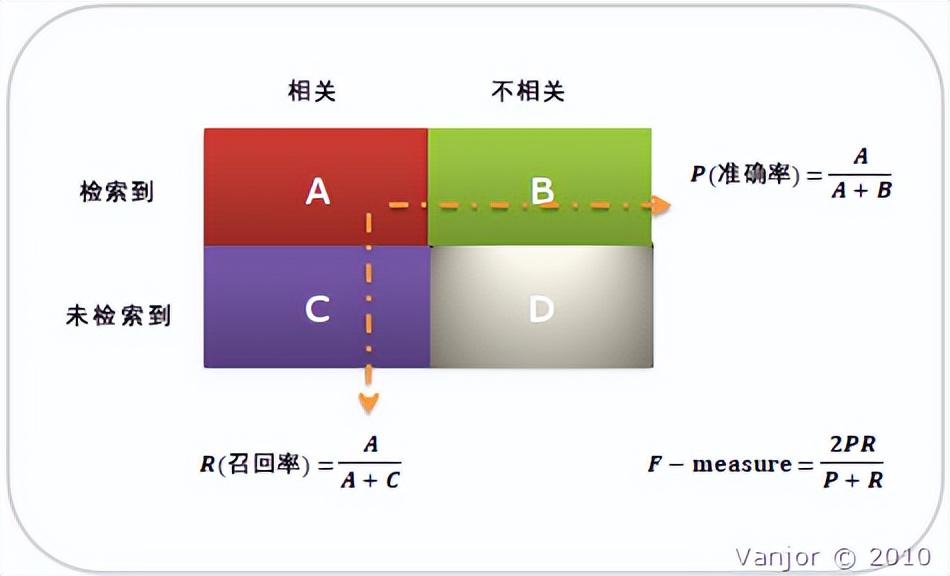
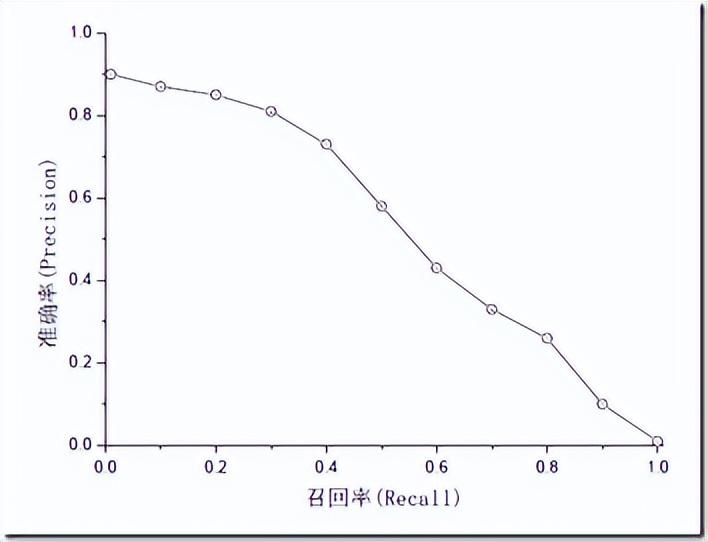
準確率和召回率是互相影響的,理想情況下肯定是做到兩者都高,但是一般情況下準確率高、召回率就低,召回率低、準確率高,當然如果兩者都低,那是什麼地方出問題了。一般來說,精確度和召回率之間是矛盾的,這裡引入F1-Score作為綜合指標,就是為了平衡準確率和召回率的影響,較為全面地評價一個分類器。F1是精確率和召回率的調和平均。F1-score越大說明模型質量更高。一般情況,用不同的閥值,統計出一組不同閥值下的精確率和召回率,如下圖:
評價指標跑出來看又怎麼評判呢?我們來看下2016年的新聞
百度自動駕駛負責人王勁 2016年9月 去年的這個時候,我們的圖象識別,識別汽車這一項,剛好也是89%。我們認為這個89%,要達到97%的準確率,需要花的時間,會遠遠超過5年。而人類要實現無人駕駛,主要靠攝像頭來實現安全的保障的話,我們認為要多少呢?我們認為起碼這個安全性的保障,要達到99.9999%,所以這個是一個非常非常遠的一條路。我們認為不是5年,10年能夠達得到的。 一般的人工智慧系統,如搜尋、翻譯等可允許犯錯,而無人駕駛系統與生命相關,模型效能要求很高。
在不同的領域,對召回率和準確率的要求不一樣。如果是做搜尋,那就是保證召回的情況下提升準確率;如果做疾病監測、反垃圾,則是保準確率的條件下,提升召回。所以,在兩者都要求高的情況下,可以用F1來衡量。
3、質量屬性
魯棒性 (robustness),也就是所說健壯性,簡單來說就是在模型在一些異常資料情況下是否也可以比較好的效果。也就是我們在最開始講人工智慧三個特徵中的 處理不確定性的能力。
比如臉部辨識,對於模糊的圖片,人帶眼鏡,頭髮遮擋,光照不足等情況下的模型表現情況。 演演算法魯棒性的要求簡單來說就是 「好的時候」要好,「壞的時候」不能太壞。 在AlphaGo 和李世石對決中,李世石是贏了一盤的。李世石九段下出了「神之一手」 Deepmind 團隊透露:錯誤發生在第79手,但AlphaGo直到第87手才發覺,這期間它始終認為自己仍然領先。這裡點出了一個關鍵問題:魯棒性。人類犯錯:水平從九段降到八段。機器犯錯:水平從九段降到業餘。
測試方法就是用盡可能多的異常資料來覆蓋進行測試。
模型安全,攻擊方法有:試探性攻擊、對抗性攻擊兩種
在試探性攻擊中,攻擊者的目的通常是通過一定的方法竊取模型,或是通過某種手段恢復一部分訓練機器學習模型所用的資料來推斷使用者的某些敏感資訊。主要分為模型竊取和訓練資料竊取
對抗性攻擊對資料來源進行細微修改,讓人感知不到,但機器學習模型接受該資料後做出錯誤的判斷。比如圖中的雪山,原本的預測準確率為94%,加上噪聲圖片後,就有99.99%的概率識別為了狗。

響應速度是指從資料輸入到模型預測輸出結果的所需的時間。對演演算法執行時間的評價。
業務測試,包括業務邏輯測試,業務 & 資料正確性測試。主要關注業務程式碼是否符合需求,邏輯是否正確,業務例外處理等情況。可以讓產品經理提供業務的流程圖,對整體業務流程有清晰的瞭解。
白盒測試,先讓演演算法工程師將程式碼的邏輯給測試人員講解,通過講解理清思路。然後測試做程式碼靜態檢查,看是否會有基本的bug。可以使用pylint工具來做程式碼分析。
模型監控,專案發布到線上後,模型線上上持續執行,需要以固定間隔檢測專案模型的實時表現,可以是每隔半個月或者一個月,通過效能指標對模型進行評估。對各指標設定對應閥值,當低於閥值觸發報警。如果模型隨著資料的演化而效能下降,說明模型已經無法擬合當前的資料了,就需要用新資料訓練得到新的模型。
巨量資料輔助,機器學習演演算法訓練和驗證是一個持續改進的過程。當資料量逐步放大時候,如何統計演演算法的準確率呢?這個時候需要引入巨量資料技術針對資料結果進行統計,根據週期性統計的準確率結果生成線性報表來反饋演演算法質量的變化。
四 、常見的機器學習平臺或者工具
1、Tensorflow已經躍居第一位,貢獻者增長了三位數。 Scikit-learn排名第二,但仍然有很大的貢獻者基礎。
TensorFlow最初是由研究人員和工程師在Google機器智慧研究組織的Google Brain團隊中開發的。該系統旨在促進機器學習的研究,並使其從研究原型到生產系統的快速和輕鬆過渡。
2、Scikit-learn是用於資料探勘和資料分析的簡單而有效的工具,可供所有人存取,並可在各種環境中重用,基於NumPy,SciPy和matplotlib,開源,商業可用 - BSD許可證。
3、K0. ,一種高階神經網路API,用Python編寫,能夠在TensorFlow,CNTK或Theano之上執行。
4、PyTorch,Tensors和Python中的動態神經網路,具有強大的GPU加速功能。
5、Theano允許您有效地定義,優化和評估涉及多維陣列的數學表示式。
6、Gensim是一個免費的Python庫,具有可延伸的統計語意,分析語意結構的純文字檔案,檢索語意相似的檔案等功能。
7、Caffe是一個深刻的學習框架,以表達,速度和模組化為基礎。它由伯克利視覺和學習中心(BVLC)和社群貢獻者開發。
8、Chainer是一個基於Python的獨立開源框架,適用於深度學習模型。 Chainer提供靈活,直觀和高效能的方法來實現全方位的深度學習模型,包括最新的模型,如遞迴神經網路和變分自動編碼器。
9、Statsmodels是一個Python模組,允許使用者瀏覽資料,估計統計模型和執行統計測試。描述性統計,統計測試,繪圖函數和結果統計的廣泛列表可用於不同型別的資料和每個估算器。
10、Shogun是機器學習工具箱,提供各種統一和高效的機器學習(ML)方法。工具箱無縫地允許輕鬆組合多個資料表示,演演算法類和通用工具。
11、Pylearn2是一個機器學習庫。它的大部分功能都建立在Theano之上。這意味著您可以使用數學表示式編寫Pylearn2外掛(新模型,演演算法等),Theano將為您優化和穩定這些表示式,並將它們編譯為您選擇的後端(CPU或GPU)。
12、NuPIC是一個基於新皮層理論的開源專案,稱為分層時間記憶(HTM)。HTM理論的一部分已經在應用中得到實施,測試和使用,HTM理論的其他部分仍在開發中。
13、Neon是Nervana基於Python的深度學習庫。它提供易用性,同時提供最高效能。
14、Nilearn是一個Python模組,用於快速簡便地統計NeuroImaging資料。它利用scikit-learn Python工具箱進行多變數統計,並使用預測建模,分類,解碼或連線分析等應用程式。
15、Orange3是新手和專家的開源機器學習和資料視覺化。具有大型工具箱的互動式資料分析工作流程。
16、Pymc是一個python模組,它實現貝葉斯統計模型和擬合演演算法,包括馬爾可夫鏈蒙特卡羅。其靈活性和可延伸性使其適用於大量問題。
17、Deap是一種新穎的進化計算框架,用於快速原型設計和思想測試。它旨在使演演算法明確,資料結構透明。它與多處理和SCOOP等並行機制完美協調。
18、Annoy是一個帶有Python繫結的C ++庫,用於搜尋空間中接近給定查詢點的點。它還建立了大型唯讀基於檔案的資料結構,這些資料結構對映到記憶體中,以便許多程序可以共用相同的資料。
19、PyBrain是一個用於Python的模組化機器學習庫。其目標是為機器學習任務和各種預定義環境提供靈活,易用且功能強大的演演算法,以測試和比較您的演演算法。
20、Fuel是一個資料管道框架,為您的機器學習模型提供所需的資料。計劃由Blocks和Pylearn2神經網路庫使用。
通過上述列出的一堆工具發現,基本上都支援python,python提供了大量的人工智慧機器學習相關的API,是首選語言。
各大廠機器學習平臺
1. 微軟的機器學習平臺
https://studio.azureml.net/
2. Facebook 的應用機器學習平臺
3. Uber的機器學習平臺
https://eng.uber.com/scaling-michelangelo/
4. Twitter的機器學習平臺
5.Databricks 開源機器學習平臺 MLflow
https://mlflow.org/docs/latest/concepts.html
6.百度機器學習 BML
https://cloud.baidu.com/doc/BML/s/Wjxbindt7
7. 阿里PAI
https://help.aliyun.com/document_detail/72285.html?spm=a2c4g.11174359.6.544.4da35d87h2vsGy
8. 騰訊機器學習平臺
https://cloud.tencent.com/document/product/851
9.京東JD neuCube
10.美團點評MLX平臺
https://www.infoq.cn/article/spark-flink-carbondata-best-practice
11. 滴滴機器學習平臺
https://www.infoq.cn/article/jJ4pjkf8Huf-WVlE7Xw7
12. 華為MLS
https://support.huaweicloud.com/productdesc-mls/zh-cn_topic_0122559740.html
13.金山雲智機器學習平臺 (KML)
https://www.ksyun.com/post/product/KML
14.第四規格化
https://blog.csdn.net/RA681t58CJxsgCkJ31/article/details/79492729
五、參考資料
1、人工智慧中RPA、NLP、OCR介紹:
https://blog.csdn.net/sdhgfhdshjd/article/details/115342671
2、機器學習入門(一):機器學習三要素之資料、模型、演演算法:
https://blog.csdn.net/liujian197905187511/article/details/104815578?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_title~default-0.essearch_pc_relevant&spm=1001.2101.3001.4242
3、AI演演算法實現:
https://blog.csdn.net/RA681t58CJxsgCkJ31/article/details/79492729