二元搜尋樹的本質
引言
打算寫寫樹形資料結構:二叉查詢樹、紅黑樹、跳錶和 B 樹。這些資料結構都是為了解決同一個基本問題:如何快速地對一個大集合執行增刪改查。
本篇是第一篇,講講搜尋樹的基礎:二元搜尋樹。
基本問題
如何在一千萬個手機號中快速找到 13012345432 這個號(以及相關聯資訊,如號主姓名)?
最笨的方案
把一千萬個手機號從頭到尾遍歷一遍,直到找到該手機號,返回對應的姓名。其時間複雜度是 O(n)————當然這肯定不是我們要的方案。
最秀的方案
用雜湊表,可以在 O(1) 的時間複雜度完成查詢。
關於雜湊表的原理和程式碼參見 演演算法(TypeScript 版本)。
雜湊表的問題
雜湊表的查詢效能非常優秀,插入和刪除的效能也不賴,但它有什麼問題呢?
我們稍微變換一下問題:如何在一千萬個手機號中快速找到在 1301111111 到 13022222222 之間所有的手機號?
和基本問題不同的是,這是個範圍查詢。
雜湊表的本質是通過對關鍵字(本例中是手機號)執行 hash 運算,將其轉換為陣列下標,進而可以快速存取。
此處講的陣列是 C 語言意義上的陣列,不是 javascript、PHP 等指令碼語言中的陣列。C 語言的陣列是一段連續的記憶體片段,對陣列元素的存取是通過記憶體地址運算進行的,可在常數時間記憶體取陣列中任意元素。
hash 運算的特點是隨機性,這也帶來了無序性,我們無法保證 hash(1301111111) < hash(1301111112)。
無序性使得我們無法在雜湊表上快速執行範圍查詢,必須一個一個比較,時間複雜度又降到 O(n)。
基於有序陣列的二分搜尋
如果這一千萬的手機號是排好序的(升序),我們有沒有更好的辦法實現上面的範圍查詢呢?
對於排好序的序列,我們如果能快速找到下限(1301111111)和上限(13022222222)所在的位置,那麼兩者之間所有的手機號就都是符合條件的。
如何才能快速找到 1301111111 的位置呢?
想想我們是怎麼玩猜數位遊戲的?
第一次猜 100,發現大了,第二次我們便傾向於猜 50 附近的數————而不是猜 99,如圖:
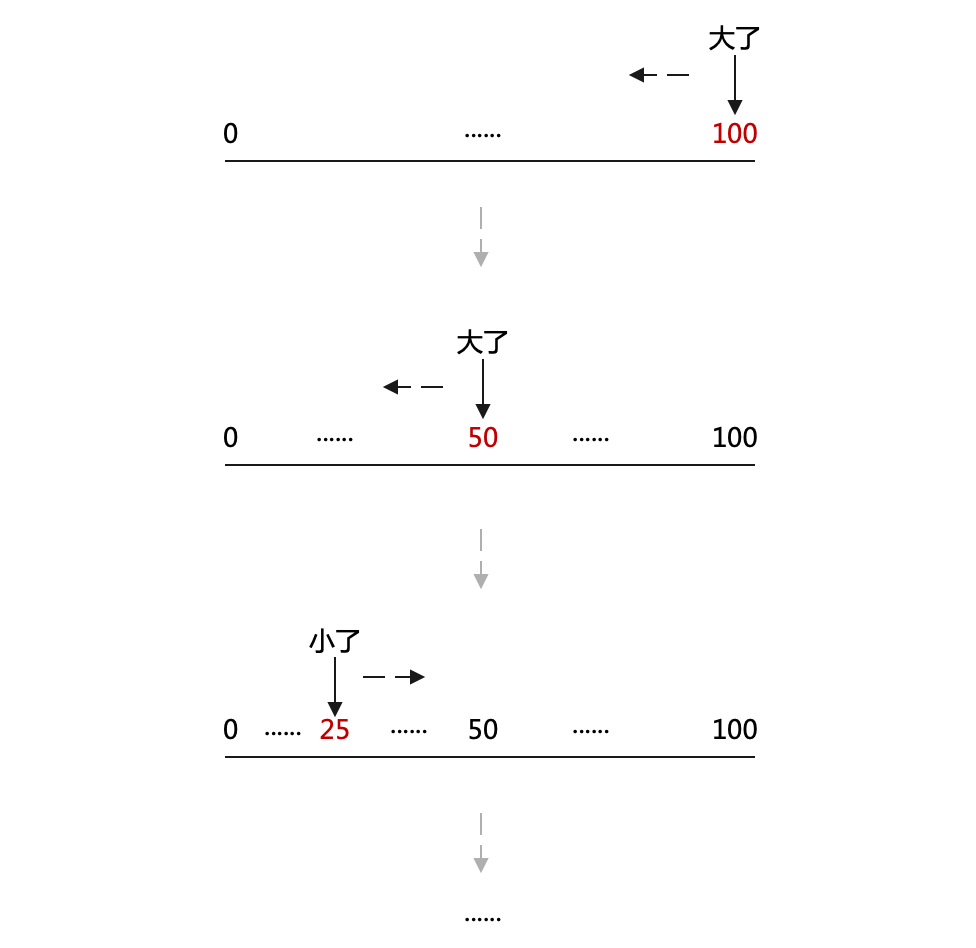
這種思想叫二分法————這種方法可以將問題範圍成倍地縮小,進而可以至多嘗試 \(\log_{2}n\) 次即可找出解。對於一千萬個手機號來說,至多隻需要比較 24 次即可找出 1301111111 的位置。相比於一千萬次,簡直是天壤之別。
程式碼如下:
interface Value {
// 為方便起見,這裡限定 key 是數值型別
key: number;
val: unknown;
}
/**
* 二分搜尋
* @param arr - 待搜尋陣列,必須是按升序排好序的(根據 Value.key)
* @param key - 搜尋鍵碼
* @reutrn 搜尋到則返回對應的 Value,否則返回 null
*/
function binSearch(arr: Value[], key: number): Value | null {
if (arr.length === 0) {
return null
}
// 子陣列左右遊標
let left = 0
let right = arr.length - 1
while (left <= right) {
// 取中
const mid = left + Math.floor((right - left) / 2)
const val = arr[mid]
if (key === val.key) {
return val
}
// key 小於 val 則在左邊找
if (key < val.key) {
right = mid - 1
} else {
left = mid + 1
}
}
return null
}
所以,如果需要對這一千萬個手機頻繁地執行範圍查詢,二分搜尋法是個不錯的選擇:先對一千萬個手機號執行排序,然後對排好序的序列執行二分搜尋。
二分搜尋的問題
二分搜尋能很快地執行精確查詢和範圍查詢,但它仍然存在問題。
對一百個元素執行二分搜尋,必須能夠在常數時間內定位到第 50 個元素————只有陣列(C 語言意義上的)這種資料結構才能做到。
也就是說,必須用陣列來實現二分搜尋。
但陣列有個很大的缺陷:對插入和刪除操作並不友好,它們都可能會造成陣列元素遷移。
比如要往有序陣列 arr = [1, 2, 3, 4, 5 ..., 100] 中插入元素 0 且繼續保證陣列元素的有序性,則必須先將既有的一百個元素都往右移一位,然後將 0 寫到 arr[0] 位置。刪除元素則會造成後續元素的左移。
倘若插入和刪除操作非常頻繁,這種遷移(複製)操作會帶來很大的效能問題。
可見,對有序陣列的查詢可以在 O(\(\log_{2}n\)) 執行,但其寫操作卻是 O(n) 複雜度的。
有沒有什麼資料結構能夠讓讀寫操作都能在 O(\(\log_{2}n\)) 內完成呢?
二分搜尋的啟發
二分搜尋的優勢是能夠在一次操作中將問題範圍縮小到一半,進而能夠在對數的時間複雜度上求得問題的解。不過其劣勢是依賴於陣列,因而其插入和刪除效能低下。
那麼,我們現在的目的便是解決二分搜尋的寫(插入和刪除)效能。
要想提高寫效能,我們的直覺是擺脫陣列這種資料結構的桎梏————是否有別的資料結構代替陣列?
一個很自然的想法是連結串列。連結串列的優勢在於其元素節點之間是通過指標關聯的,這使得插入和刪除元素時只需要變更指標關係即可,無需實際遷移資料。
// 連結串列的節點定義
interface Node {
data: Value;
next: Node;
}
然而,連結串列的劣勢是查詢:它無法像陣列那樣通過下標存取(而只能從頭節點一個一個遍歷存取),進而也就無法實現二分法。
如對於陣列 arr = [1, 2, 3, 4, 5],我們能直接通過 arr[2] 存取中間元素;但對於連結串列 link = 1 -> 2 -> 3 -> 4 -> 5,由於不是連續記憶體地址,無法通過下標存取,只能從頭開始遍歷。
那麼,我們如何解決連結串列的查詢問題呢?或者說如何用連結串列來模擬有序陣列的二分法呢?
二分法有兩個操作:
- 取中。快速定位到中間位置的元素(對於有序序列來說就是中位數)。
- 比較。根據第一步取得的元素,決定後續操作:如果相等則返回;如果比目標大,則取左半部子集繼續操作;如果比目標小,則取右半部子集繼續操作。
那麼,如何在連結串列上實現上面兩個操作?
我們先考慮操作二:比較。如果比較結果不相等,則會去左邊或者右邊繼續查詢。我們可以改造一下連結串列節點,用左右指標來表示「左邊」和「右邊」,左右指標分別指向左子連結串列和右子連結串列。改造後的節點定義如下:
// 改進的節點定義
interface Node {
data: Value;
// 左指標
left: Node;
// 右指標
right: Node;
}
由於改造後的連結串列節點有 left 和 right 兩個指標,相當於一個節點分了兩個叉,故名為二叉。
再考慮操作一:取中。取中將原陣列一分為三:當前元素(中間元素)、左子陣列、右子陣列。
我們可以將它對映到改造後的連結串列中的當前節點、左(left)子連結串列、右(right)子連結串列。查詢時,如果當前節點的值小於目標值,則通過 right 指標進入到右子連結串列中繼續查詢,反之通過 left 指標進入左子連結串列查詢。
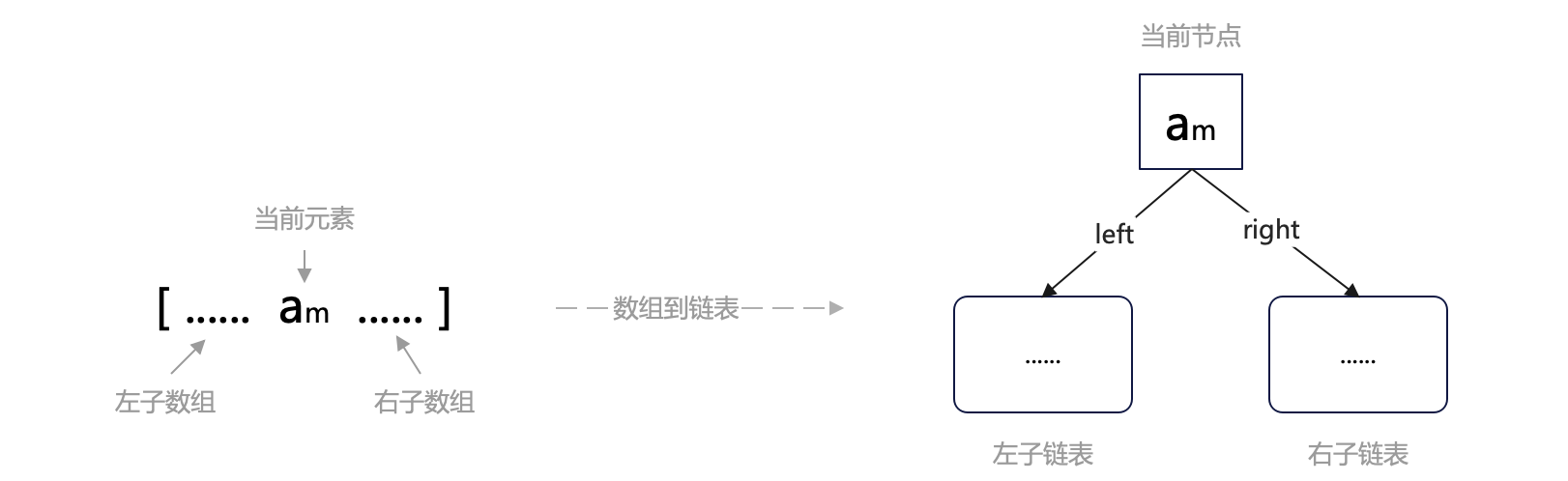
繼續分析之前,我們先從直觀上考察一下改造後的連結串列。分叉後,整個結構不再像單條鏈子,更像一棵樹,於是我們不再稱之為「二元連結串列」,而是稱作「二元樹」。對應地,左右子連結串列也更名為「子樹」。
對應陣列看,很容易知道,節點左子樹中的所有元素都小於等於節點元素,右子樹中的所有元素都大於等於節點元素————這是二元搜尋樹最重要(甚至是唯一重要)的性質。
至此,我們用連結串列的節點代替陣列的元素,用節點的左右指標(或者說左右指標指向的兩棵子樹)代替左右子陣列。
現在還剩下最後一個問題:如何將陣列中的每個元素對映到這棵二元搜尋樹(或者叫「改造後的連結串列」)中?
既然二分法是不斷地取陣列(包括左右子陣列)中間位置的元素進行比較,那麼我們將取出來的元素從上到下(從樹根開始)依次掛到這棵樹的節點上即可,如此當我們從樹根開始遍歷時,拿到的元素的順序便和從陣列中拿到的一致。
我們以陣列 arr = [1, 2, 3, 4, 5, 6, 7] 為例,看看如何生成對應的二元搜尋樹。

如上圖:
- 先取整個陣列中間元素 4,作為二元樹的根節點;
- 取左子陣列的中間元素 2,作為根節點的左子節點;
- 取右子陣列的中間元素 6,作為根節點的右子節點;
- 依此遞迴處理,直到取出陣列中所有的元素生成二元樹的節點,整棵二元樹生成完成;
我們將上面的過程轉換成程式碼:
// 二元搜尋樹
class BinSearchTree {
// 樹根節點
root: Node;
}
/**
* 基於已排好序(根據 key)的陣列 arr 構建平衡的二元搜尋樹
*/
function buildFromOrderdArray(arr: Value[]): BinSearchTree {
const tree = new BinSearchTree()
// 從樹根開始構建
tree.root = innerBuild(arr, 0, arr.length - 1)
return tree
}
/**
* 基於子陣列 arr[start:end] 構建一棵以 node 為根節點的二叉子樹,返回根節點 node
*/
function innerBuild(arr: Value[], start: number, end: number): Node {
if (start > end) {
// 空
return null
} else if (start == end) {
// 只剩下一個元素了,則直接返回一個節點
return { data: arr[start], left: null, right: null }
}
/**
* 使用二分思想構建二元樹
*/
// 中間元素
const mid = start + Math.floor((end - start) / 2)
// 當前節點
const curr: Node = { data: arr[mid], left: null, right: null }
/**
* 遞迴生成左右子樹
*/
// 左子樹
curr.left = innerBuild(arr, start, mid - 1)
// 右子樹
curr.right = innerBuild(arr, mid + 1, end)
return curr
}
二元搜尋樹的查詢
二元搜尋樹是基於二分搜尋思想構建的,其搜尋邏輯也和二分搜尋相同,只不過將左右子陣列替換成左右子樹。
以搜尋元素 13 為例:
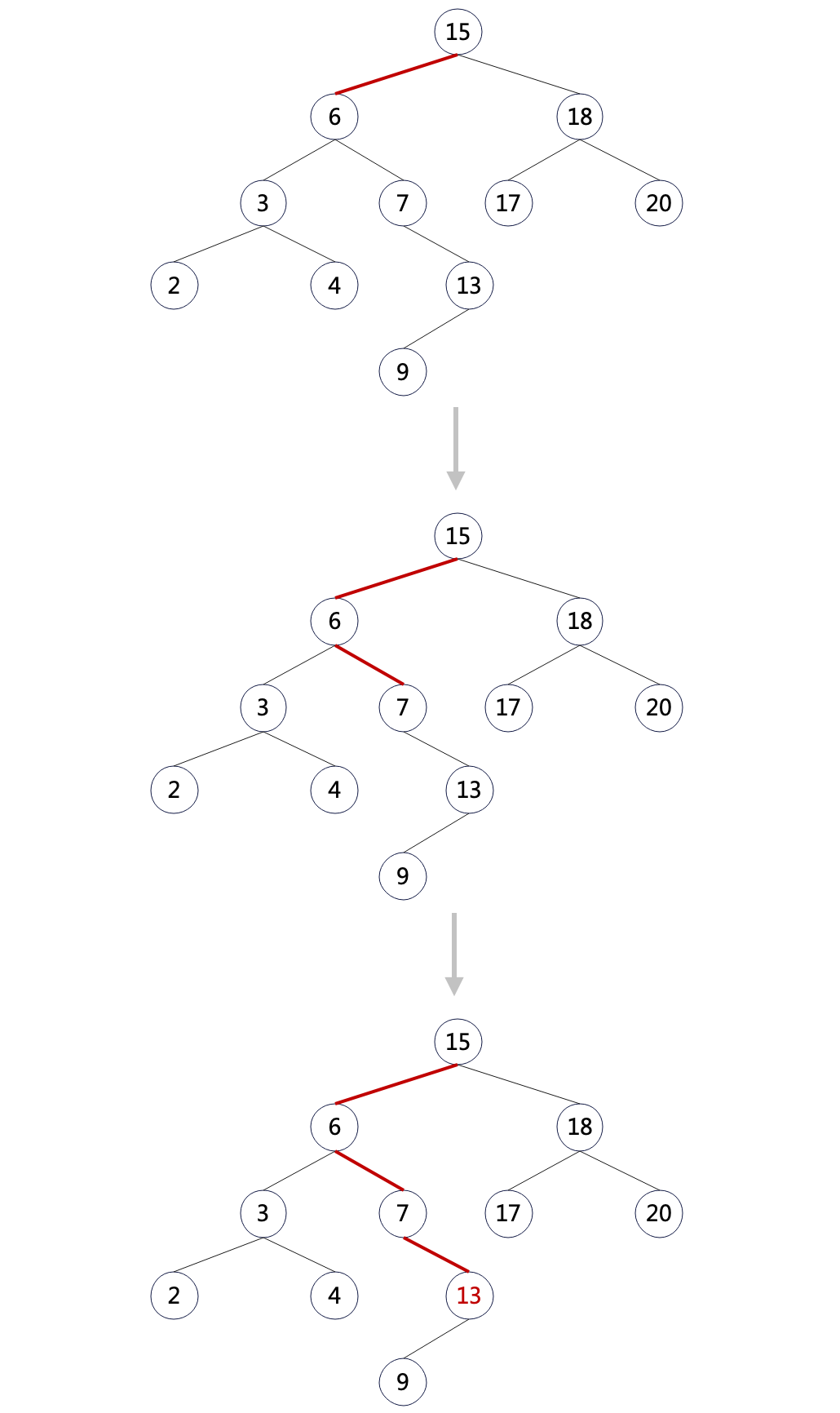
上圖中搜尋步驟:
- 從根節點開始比較,15 大於 13,到本節點的左子樹繼續搜尋;
- 節點 6 小於 13,到本節點的右子樹繼續搜尋;
- 節點 7 小於 13,到本節點的右子樹繼續搜尋;
- 節點 13 等於 13,找到目標節點,結束;
對比二分搜尋可以發現,二元搜尋樹中的 left 和 right 子樹就是對應二分搜尋中左右子陣列,兩者的搜尋邏輯本質上是一致的。
程式碼如下:
class BinSearchTree {
// 樹根節點
root: Node;
/**
* 在以 node 為根的子樹中搜尋鍵碼為 key 的節點並返回該節點
* 如果沒有找到則返回 null
*/
search(key: unknown, node: Node = undefined): Node {
// 預設取根
node = node === undefined ? this.root : node
// 遇到 null 節點,說明沒搜到,返回 null
if (!node) {
return null
}
// 先判斷當前節點
if (node.data.key === key) {
// 找到,即可返回
return node
}
// 沒有找到,則視情況繼續搜尋左右子樹
if (key < node.data.key) {
// 目標值小於當前節點,到左子樹中搜尋
return this.search(key, node.left)
}
// 目標值大於等於當前節點,到右子樹中搜尋
return this.search(key, node.right)
}
}
從圖中可見,對於任何元素的搜尋,搜尋次數不可能大於從根到所有葉節點的最長路徑中節點個數(上圖中是 5)。如果用這條路徑的邊來表達的話,搜尋次數不可能超過最長路徑邊數加 1。
這個最長路徑的邊數即是整棵樹的高。
對於一顆完美的平衡二元樹來說,這個高 h = \(\log_{2}n\),其中 n 是節點數量。因而說二元搜尋樹的查詢時間複雜度是 O(\(\log_{2}n\)),和二分搜尋是一致的。
注意上面說的是完美的平衡二元樹,但二元搜尋樹並不是天生平衡的,所以才引出了各種平衡方案,諸如 2-3 樹、紅黑樹、B 樹等。
特殊查詢:最小元素
由於二元搜尋樹中的任意一個節點,其左邊元素總小於該節點,所以要找最小元素,就是從根節點開始一直往左邊找。
如圖:

程式碼如下:
class BinSearchTree {
// 樹根節點
root: Node;
/**
* 查詢以 node 為根的子樹的最小節點並返回
*/
min(node: Node = undefined): Node {
// 預設取根節點
node = node === undefined ? this.root : node
if (node === null || !node.left) {
// 如果是空子樹,或者 node.left 是空節點,則返回
return node
}
// 存在左子樹,繼續往左子樹中找
return this.min(node.left)
}
}
相對應的是最大值,也就是遞迴地往右邊找,此處略。
按序遍歷
對於有序陣列,很容易通過迴圈從頭到尾按序遍歷陣列中元素,對應地,如何按序遍歷二元搜尋樹呢?
二元搜尋樹是根據二分法遞迴生成的,所以同樣可以用二分法來解決此問題。
對於一棵樹來說,它分為三部分:樹根節點、左子樹、右子樹,其中大小關係是:左子樹 <= 樹根節點 <= 右子樹,所以我們以這個順序遍歷整棵樹,便可以按序輸出。
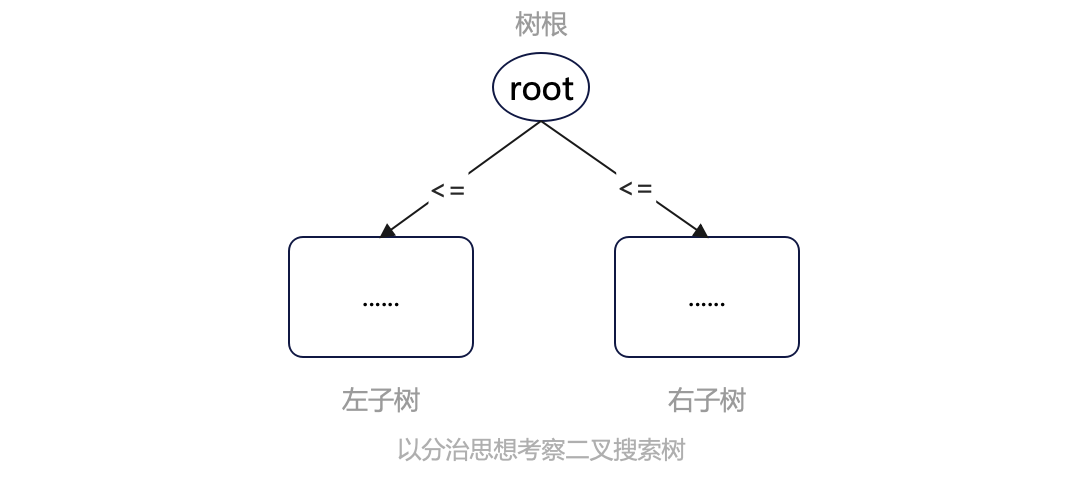
這種遍歷方式,由於是在中間步驟操作樹根節點,又稱之為中序遍歷。
相應地,按「樹根節點 -> 左子樹 -> 右子樹」的順序遍歷稱之為先序遍歷,按「左子樹 -> 右子樹 -> 樹根節點」的順序遍歷稱之為後序遍歷。
中序遍歷程式碼:
class BinSearchTree {
// 樹根節點
root: Node;
/**
* 中序遍歷
*/
inorder(): Node[] {
const arr: Node[] = []
this.innerInorder(this.root, arr)
return arr
}
/**
* 對 x 子樹執行中序遍歷,遍歷的節點放入 arr 中
*/
innerInorder(x: Node, arr: Node[]) {
if (!x) {
return
}
// 先遍歷左子樹
this.innerInorder(x.left, arr)
// 自身
arr.push(x)
// 右子樹
this.innerInorder(x.right, arr)
}
}
範圍查詢
如何在二元搜尋樹上執行範圍查詢?
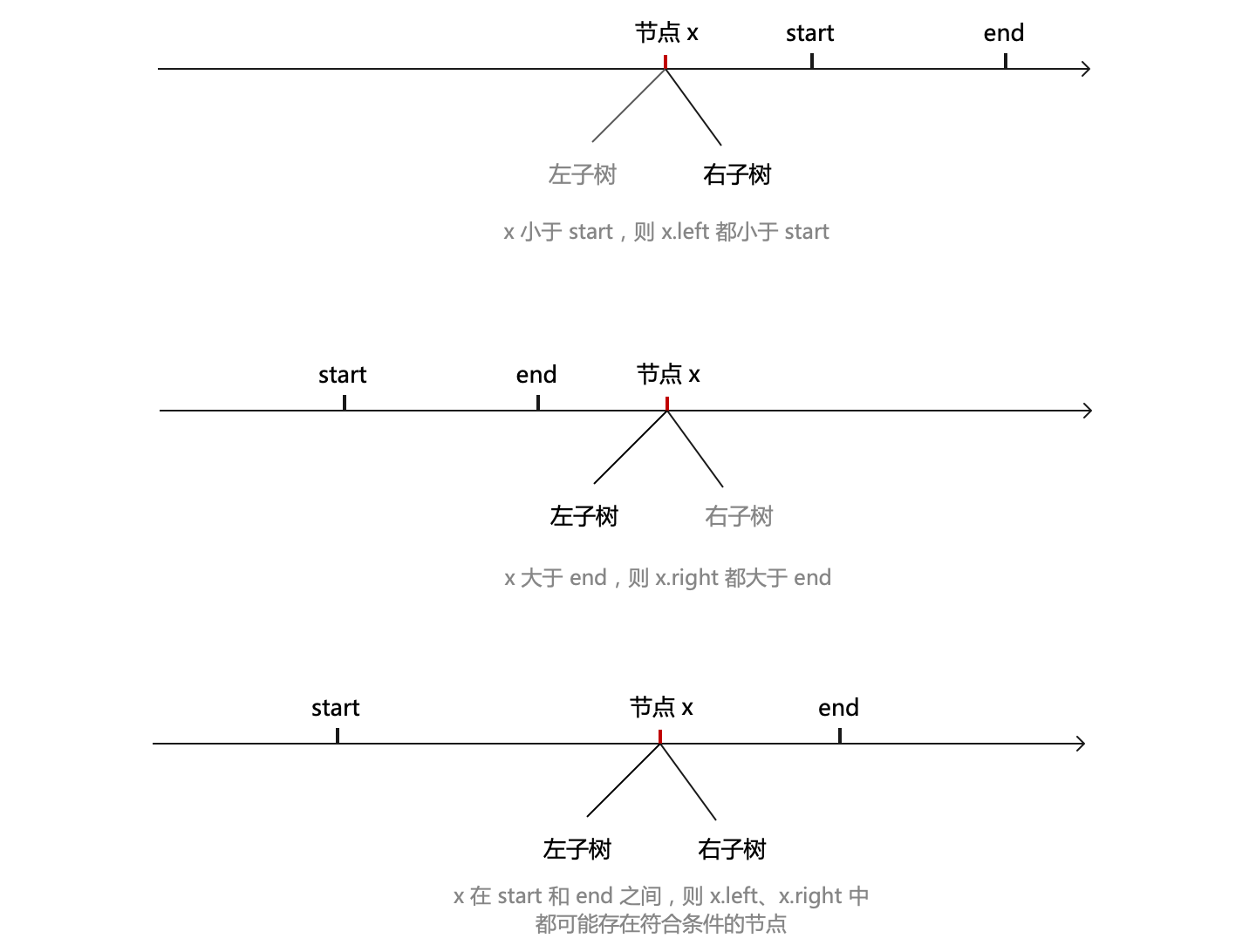
問題:按序返回二元搜尋樹中所有大於等於 start 且小於等於 end 的節點集合(即返回所有節點 x,x 滿足:start <= x <= end)。
上面的中序遍歷其實就是一種特殊的範圍查詢:min <= x <= max。所以範圍查詢的思路和中序遍歷一樣,只不過在遍歷時加上範圍限制。
具體來說,什麼時候需要去查左子樹呢?當左子樹有可能存在符合條件的元素時需要去查。如果當前節點 x 的值小於範圍下限(start),而 x 的左子樹的值都小於等於 x 的,說明此時其左子樹中不可能存在符合條件的節點,無需查詢;或者,如果 x 的值大於範圍上限(end),而 x 的右子樹的值都大於等於 x 的,說明此時其右子樹中不可能存在符合條件的節點,也無需查詢。其他情況則需要查詢。
程式碼如下:
class BinSearchTree {
// 樹根節點
root: Node;
/**
* 按序返回所有大於等於 start 且小於等於 end 的節點集合
*/
range(start: unknown, end: unknown): Node[] {
const arr: Node[] = []
this.innerRange(this.root, start, end, arr)
return arr
}
/**
* 在 x 子樹中查詢所有大於等於 start 且小於等於 end 的節點並放入 arr 中
*/
innerRange(x: Node, start: unknown, end: unknown, arr: Node[]) {
if (!x) {
return
}
// 比較節點 x 和 start、end 之間的大小關係
const greaterThanStart = x.data.key >= start
const smallerThanEnd = x.data.key <= end
// 如果當前節點大於等於 start,則需要搜尋其左子樹
if (greaterThanStart) {
this.innerRange(x.left, start, end, arr)
}
// 如果 x 在 start 和 end 之間,則符合條件,存入 arr
if (greaterThanStart && smallerThanEnd) {
arr.push(x)
}
// 如果當前節點小於等於 end,則需要搜尋其右子樹
if (smallerThanEnd) {
this.innerRange(x.right, start, end, arr)
}
}
}
插入操作
對於二元樹來說,新節點總是被插入到 null 節點(末端)處。
還是以上圖為例,插入新節點 14:
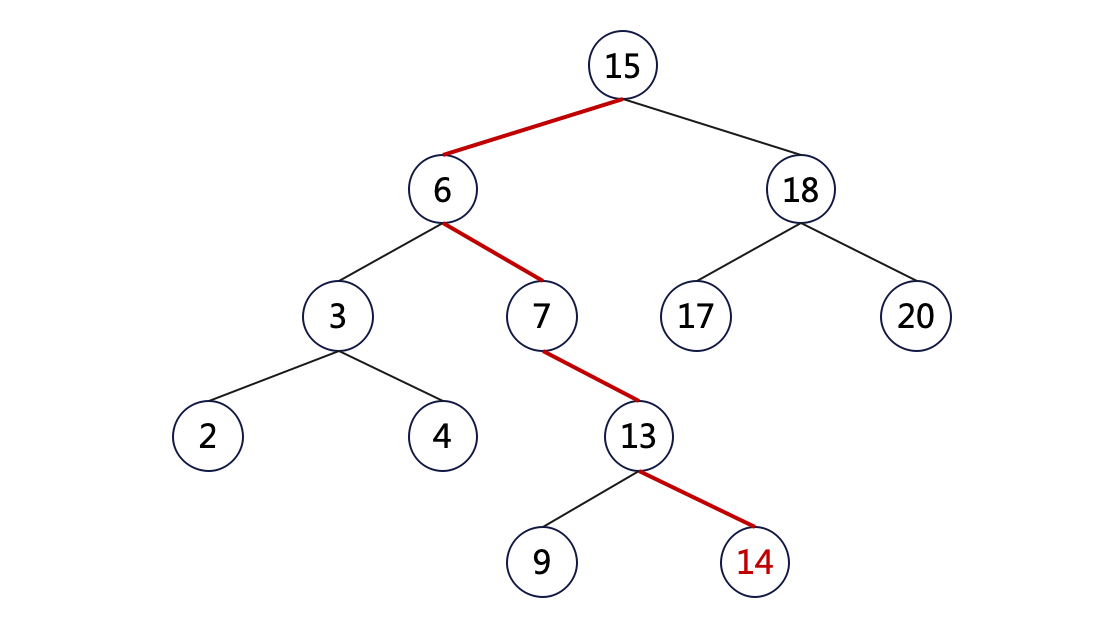
如圖所示,插入操作分兩步:
- 搜尋。這一步和查詢操作一樣,相當於是搜尋這個新節點 14,結果沒搜到,遇到了 null 節點(Node(13).right);
- 插入。生成新節點 14 並插入到節點 13 的右側(Node(13).right = Node(14));
很明顯,插入操作的時間複雜度也是 O(\(\log_{2}n\)),完美!
插入操作的程式碼如下:
class BinSearchTree {
// 樹根節點
root: Node;
/**
* 將元素 data 插入到樹中
*/
insert(data: Value) {
// 從根節點開始處理
// 插入完成後,將新根賦值給 root
this.root = this.innerInsert(data, this.root)
}
/**
* 將元素 data 插入到以 node 為根的子樹中
* 返回插入元素後的子樹的根節點
*/
innerInsert(data: Value, node: Node): Node {
if (node === null) {
// 遇到了 null 節點,說明需要插入到該位置
return { data: data, left: null, right: null }
}
// 比較 data 和 node 的值,視情況做處理
if (data.key < node.key) {
// 待插入的元素小於當前節點,需要插入到當前節點的左子樹中
node.left = this.innerInsert(data, node.left)
} else {
// 插入到右子樹中
node.right = this.innerInsert(data, node.right)
}
// 插入完成後,需返回當前節點
return node
}
}
刪除操作
刪除操作需要分幾種情況。
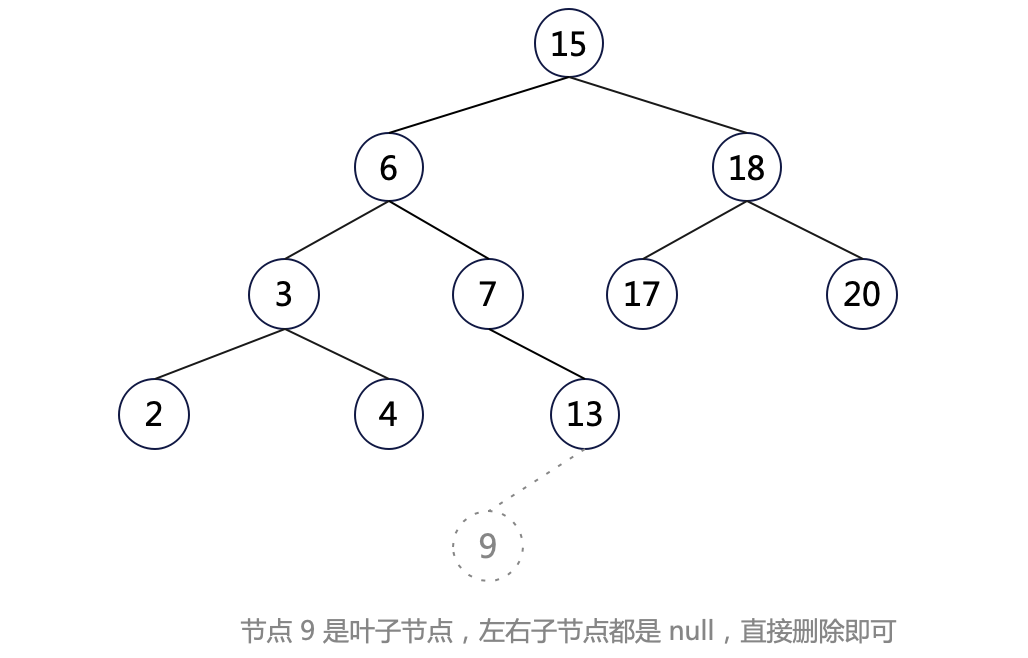
情況一:刪除葉子節點,該節點的 left 和 right 都是 null。
這種情況很簡單,直接刪掉該元素即可。如刪除節點 9:
情況二:待刪除的節點只有一個子節點,用該子節點代替該節點即可。如刪除節點 13:

以上兩種情況都比較簡單,第三種情況則稍微複雜。
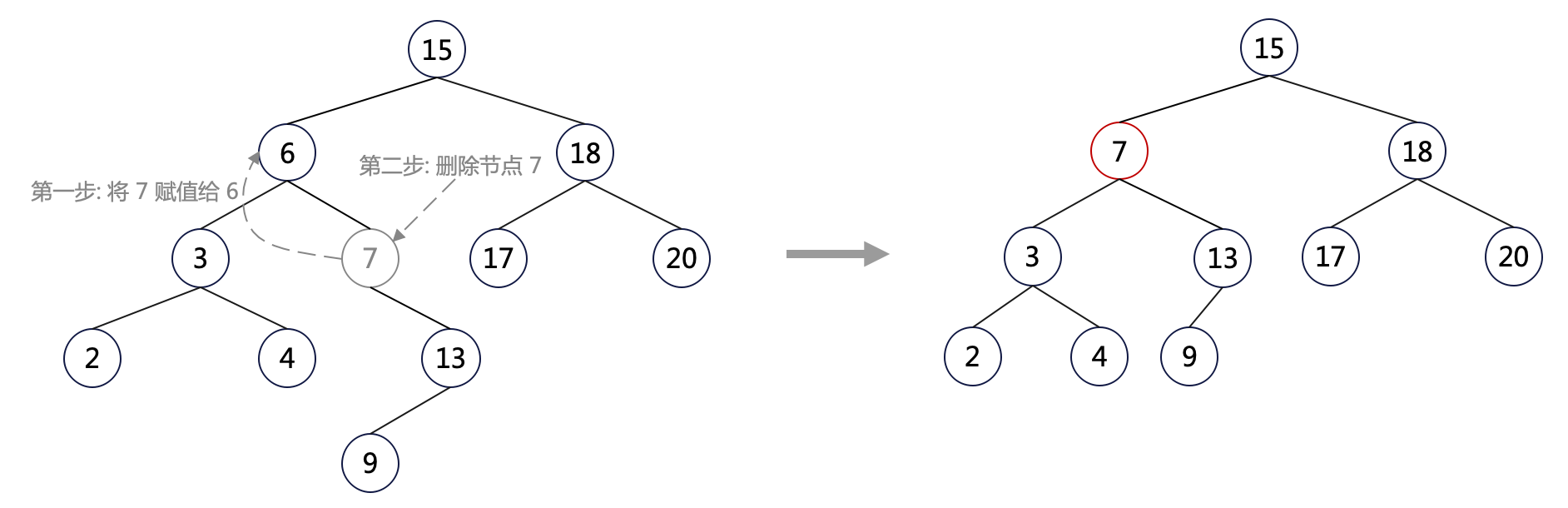
情況三:待刪除的節點有左右兩個子節點。如圖中節點 6。將 6 刪除後,我們無法簡單的用其 left 或 right 子節點替代它————因為這會造成兩棵子樹一系列的變動。
前面說過,二元搜尋樹本質上是由有序陣列演化而來,那麼我們不妨以陣列的角度看是否有所啟示。
上圖用陣列表示:arr = [2, 3, 4, 6, 7, 9, 13, 15, 18, 17, 20]。該陣列中刪掉元素 6 後,如何才能讓陣列中其他元素調整次數最少(這裡不考慮遷移,因為二元樹不存在遷移開銷)?
自然是直接用 6 的前一個(4)或者後一個(7)元素替代 6 的位置。其中 4 恰恰是 6 左邊子陣列中的最大值,而 7 恰恰是其右邊子陣列中的最小值。
我們不妨用右邊子陣列中最小值(7)來替代 6————對映到二元搜尋樹中便是節點 6 的右子樹的最小節點。
前面已經討論過二元搜尋樹中最小值的求解邏輯:順著節點左子樹(left)一直遞迴查詢,直到 node.left 等於 null,該 node 便是最小值————也就是說,一棵樹的最小節點不可能有左子節點,即最小節點最多有一個子節點,這便是情況一或者情況二。
那麼能否用右子樹中最小節點(7)替代當前節點(6)呢?無論從有序陣列還是從二元搜尋樹本身角度看,都很容易證明是可以的(替換後仍然符合二元搜尋樹的性質)。
因而,情況三可以作如下處理:
- 將右子樹中最小節點的 data 賦值給當前節點;
- 刪除右子樹中最小節點;
程式碼如下:
class BinSearchTree {
// 樹根節點
root: Node;
// ...
/**
* 刪除 key 對應的節點
*/
delete(key: unknown) {
const node = this.search(key, this.root)
if (!node) {
// key 不存在
return
}
this.root = this.innerDelete(this.root, node)
}
/**
* 刪除子樹 current 中 del 節點,並返回操作完成後的子樹根節點
*/
innerDelete(current: Node, del: Node): Node {
/**
* 當前節點即為待刪除節點
*/
if (current === del) {
// 情況一:當前節點沒有任何子節點,直接刪除
if (!current.left && !current.right) {
return null
}
// 情況二:只有一個子節點
if (current.left && !current.right) {
// 只有左子節點,用左子節點替換當前節點
return current.left
}
if (current.right && !current.left) {
// 只有右子節點,用右子節點替換當前節點
return current.right
}
// 情況三:有兩個子節點
// 取右子樹的最小節點
const minNode = this.min(current.right)
// 用最小節點的值替換當前節點的
current.data = minNode.data
// 刪除右子樹中的最小節點
current.right = this.innerDelete(current.right, minNode)
return current
}
/**
* 當前節點不是待刪除節點,視情況遞迴從左或右子樹中刪除
*/
if (del.data.key < current.data.key) {
// 待刪除節點小於當前節點,從左子樹刪除
current.left = this.innerDelete(current.left, del)
} else {
// 待刪除節點大於當前節點,繼續從右子樹刪除
current.right = this.innerDelete(current.right, del)
}
return current
}
}
很容易證明,刪除操作的時間複雜度也是 O(\(\log_{2}n\))。
二元搜尋樹的問題
由上面的插入操作可知,二元搜尋樹新增節點時總是往末端增加新節點,這種操作方式有個問題:當我們一直朝同一個方向(一直向左或者一直向右)插入時,便很容易出現傾斜。
比如我們向一棵空樹中依次插入 1, 2, 3, 4, 5:
const tree = new BinSearchTree()
tree.insert({ key: 1, data: 1 })
tree.insert({ key: 2, data: 2 })
tree.insert({ key: 3, data: 3 })
tree.insert({ key: 4, data: 4 })
tree.insert({ key: 5, data: 5 })
得到的二元樹如下:

二元樹退化成了普通連結串列,所有的操作退化為 O(n) 複雜度!
所以在插入和刪除二元樹節點時,需要執行額外的操作來維護樹的平衡性,後面將要介紹的紅黑樹和 B 樹就是兩種非常著名的解決方案。
總結
- 雜湊表能很好地解決精確查詢(O(1) 複雜度),但無法解決範圍查詢(必須 O(n) 複雜度);
- 基於有序陣列的二分搜尋能很好地解決精確查詢和範圍查詢(O(\(\log_{2}n\)) 複雜度),但無法解決插入和刪除(必須 O(n) 複雜度);
- 基於二分搜尋思想改進的連結串列(二元搜尋樹)能很好地解決查詢(包括範圍查詢)、插入和刪除,所有的操作都是 O(\(\log_{2}n\)) 的時間複雜度;
- 二元搜尋樹中以任意節點作為根的子樹仍然是一棵二元搜尋樹,這個特點很重要,它是遞迴操作的關鍵;
- 二元搜尋樹存在節點傾斜問題,會降低操作效能,極端情況下會退化成普通連結串列,所有的操作都退化到 O(n) 複雜度;
- 為解決二元搜尋樹的傾斜問題,實際應用中需引入相關平衡方案,本系列的後序文章將介紹三種常見的方案:紅黑樹、跳錶和 B 樹;
本文中的範例程式碼採用 TypeScript 語言實現,且用遞迴法寫的,完整程式碼參見二元搜尋樹(遞迴法)。非遞迴法程式碼參見二元搜尋樹(迴圈法)。
本文來自部落格園,作者:林子er,轉載請註明原文連結:https://www.cnblogs.com/linvanda/p/17283480.html