Onetable:統一的表格式後設資料表示
概括
Onehouse 客戶現在可以將他們的 Hudi 表查詢為 Apache Iceberg 和/或 Delta Lake 表,享受從雲上查詢引擎到頂級開源專案的原生效能優化。
在資料平臺需求層次結構的基礎上,存在攝取、儲存、管理和轉換資料的基本需求。 Onehouse 提供這種基礎資料基礎架構作為服務,以在客戶資料湖中攝取和管理資料。 隨著資料湖在組織內的規模和種類不斷增長,將基礎資料基礎架構與處理資料的計算引擎分離變得勢在必行。 不同的團隊可以利用專門的計算框架,例如 Apache Flink(流處理)、Ray(機器學習)或 Dask(Python 資料處理),以解決對其組織重要的問題。 解耦允許開發人員在以開放格式儲存的資料的單個範例上使用這些框架中的一個或多個,而無需將其複製到和儲存緊密耦合的另一服務中。 Apache Hudi、Apache Iceberg 和 Delta Lake 已成為領先的開源專案,為這個解耦儲存層提供一組強大的原語,這些原語在雲端儲存中圍繞開啟的檔案提供事務和後設資料(通常稱為表格式)層,像 Apache Parquet 這樣的格式。
背景
AWS 和 Databricks 在 2019 年為此類技術創造了最初的商業勢頭,分別支援 Apache Hudi 和 Delta Lake。 如今大多數雲資料供應商都支援其中一種或多種格式。 然而他們繼續構建一個垂直優化的平臺以推動對他們自己的查詢引擎的粘性,其中資料優化被鎖定到某些儲存格式, 例如要解鎖 Databricks 的 Photon 引擎的強大功能需要使用 Delta Lake。 多年來 AWS 已在其所有分析服務中預安裝 Apache Hudi,並繼續近乎實時地支援更高階的工作負載。 Snowflake 宣佈與 Iceberg 更強大的外表整合,甚至能夠將 Delta 表作為外表進行查詢。 BigQuery 宣佈與所有三種格式整合,首先是 Iceberg。
所有這些不同的選項都提供了混合支援,我們甚至還沒有開始列出各種開源查詢引擎、資料目錄或資料質量產品的支援。 這種越來越大的相容性矩陣會讓組織擔心他們會被鎖定在一組特定的供應商或可用工具的子集中,從而在進入資料湖之旅時產生不確定性和焦慮。
為什麼要建立 Onetable?
在過去的一年裡,我們釋出了開源專案之間的全面比較,展示了 Hudi 如何具有顯著的技術差異化優勢,尤其是在為 Hudi 和 Onehouse 的增量資料服務提供支援的更新繁重工作負載方面。 此外Hudi 用於管理和優化表格的自動化表格服務為資料基礎架構奠定了全面的基礎,同時完全開源。 在選擇表格格式時,工程師目前面臨著一個艱難的選擇,即哪些好處對他們來說最重要。 例如選擇 Hudi 的表服務或像 Databricks Photon 這樣快速的Spark引擎。 在 Onehouse我們會問真的有必要進行選擇嗎? 我們希望客戶在處理他們的資料時獲得儘可能好的體驗,這意味著支援 Hudi 以外的格式以利用資料生態系統中不斷增長的工具和查詢引擎集。 作為一家倡導跨查詢引擎互操作性的公司,如果我們不對後設資料格式應用相同的標準以幫助避免將資料分解成孤島,那我們的表現就很虛偽。 今天我們通過 Onetable 朝著這個方向邁出了一大步。
什麼是 Onetable?
Onehouse 致力於開放,並希望通過我們的雲產品 Onetable 上的一項新功能,幫助組織享受 Hudi 解鎖的成本效率和高階功能,而不受當前市場產品的限制。 當資料靜止在湖中時三種格式並沒有太大區別。 它們都提供了對一組檔案的表抽象,以及模式、提交歷史、分割區和列統計資訊。 Onetable 採用源後設資料格式並將表後設資料提取為通用格式,然後可以將其同步為一種或多種目標格式。 這使我們能夠將通過 Hudi 攝取的表公開為 Iceberg 和/或 Delta Lake 表,而無需使用者複製或移動用於該表的底層資料檔案,同時維護類似的提交歷史記錄以啟用適當的時間點查詢。
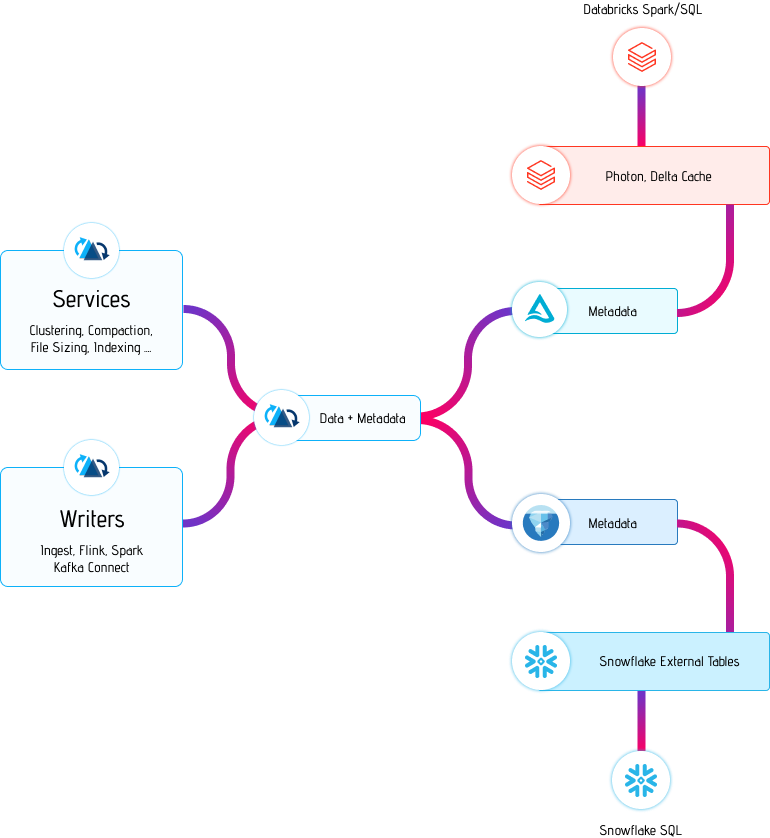
這種方法類似於 Snowflake 為 Iceberg 表保留其內部後設資料,同時為外部互操作性建立 Iceberg 後設資料的方式。 Hudi 還已經支援與 BigQuery 的整合,大型開源使用者和 Onehouse 使用者正在使用它。

我們為什麼興奮?
Onehouse 客戶可以選擇啟用 Onetable 作為目錄來自動將他們的資料公開為 Hudi 表以及 Iceberg 和/或 Delta Lake 表。 以這些不同的後設資料格式公開表使客戶能夠輕鬆地加入 Onehouse 並享受託管Lakehouse的好處,同時使用他們喜歡的工具和查詢引擎維護他們現有的工作流程。
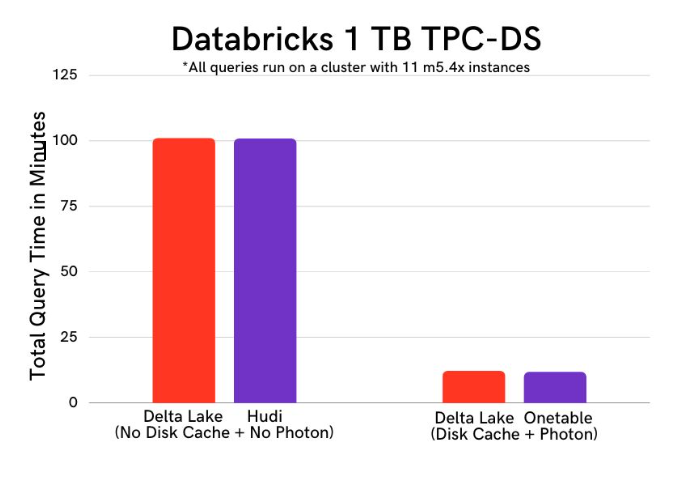
例如Databricks 是執行 Apache Spark 工作負載的一個非常受歡迎的選擇,其專有的 Photon 引擎可在使用 Delta Lake 表格式時提供效能加速。 為了確保使用 Onehouse 和 Databricks 的客戶獲得良好的體驗而沒有任何效能缺陷,我們使用 1TB TPC-DS 資料集來對查詢效能進行基準測試。 我們比較了 Apache Hudi 和 Delta Lake 表,有/沒有 Onetable 和 Databricks 的平臺加速,如磁碟快取和 Photon。 下圖顯示了 Onetable 如何通過基於 Delta Lake 協定轉換後設資料來解鎖 Onehouse/Hudi 表上 Databricks 內部的更高效能。
此外我們將 Snowflake 中的同一張表公開為外部表,該表通常用於數倉。 我們執行了類似的 1TB TPC-DS 基準測試,比較了 Snowflake 的原生/專有表、外部Parquet表和使用 Onetable 的 Hudi 表。 下圖顯示 Onetable 如何向 Snowflake 查詢公開 Hudi 表的一致快照,同時提供與 Snowflake 的 parquet 表類似的效能。
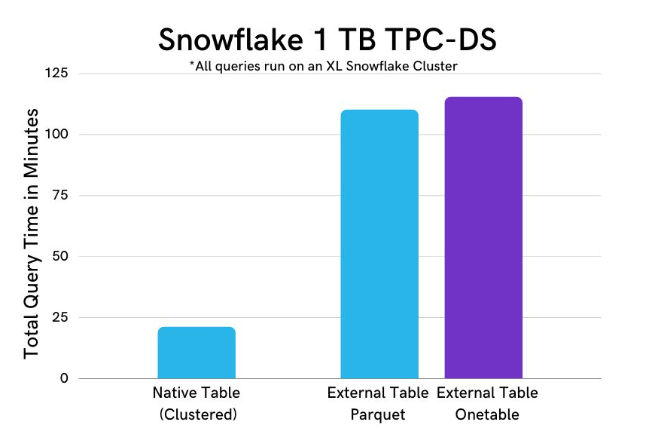
雖然上述外表的效能不如本地 Snowflake 錶快,Onetable 提供了公開 Snowflake 內部資料湖的最新檢視的功能,以幫助支援下游 ETL/轉換或在組織過渡到構建Lakehouse以補充其 Snowflake 資料倉儲時保持查詢執行。 這種方法避免了將全套資料複製到倉庫或使儲存成本加倍,同時仍允許工程師和分析師派生出更有意義的聚合原生表,以快速提供報告和儀表板,充分利用 Snowflake 的強大功能。
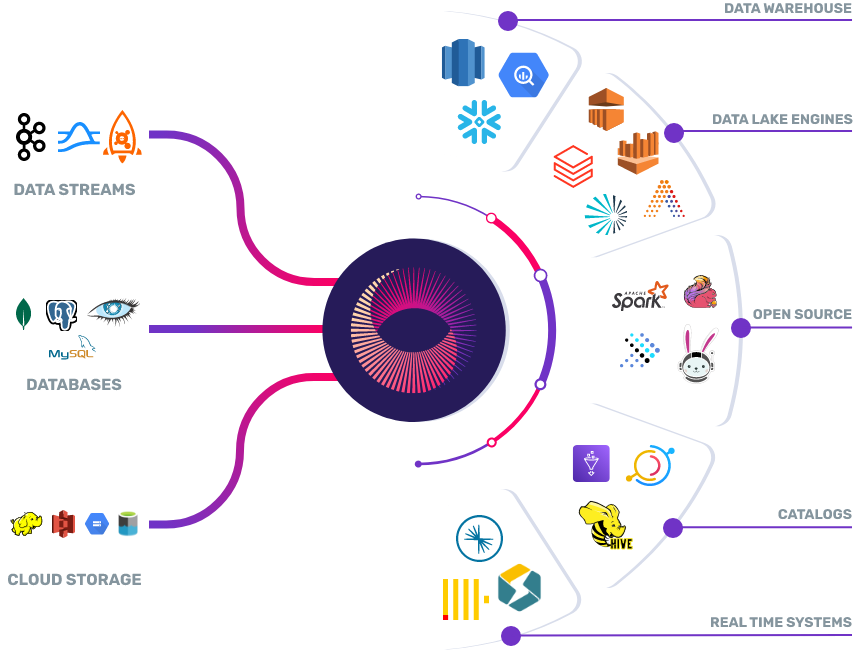
最重要的是我們很高興看到這如何幫助使用者使用靈活的分層資料架構取得成功,這種架構已經在許多大型資料組織中流行。 Apache Hudi 為資料湖上的增量攝取/etl 提供行業領先的速度和成本效益,這是 Onehouse 的基礎。 使用者利用 Hudi 將這種高效、成本優化的資料攝取到原始/銅銀表中。 Onehouse 的表管理服務可以直接在湖級別優化此資料的佈局,以獲得更好的查詢效能。 然後使用者可以使用 BigQuery、Redshift、Snowflake 等倉庫引擎或 Databricks、AWS EMR、Presto 和 Trino 等湖引擎轉換這些優化表。 然後將派生資料提供給終端使用者,以構建個性化、近實時儀表板等資料應用程式。 Onetable 為使用者提供了非常需要的可移植性,讓他們可以根據自己的需求和成本/效能權衡來選擇他們喜歡的查詢引擎。 同時使用者可以通過 Hudi 經驗證的具有挑戰性的變更資料捕獲場景的效率以及 Onehouse 的表優化/管理服務來降低計算成本。
未來工作
資料空間中查詢引擎、開源工具和新產品的格局在不斷髮展。 每年湧現的這些現有服務和新服務中的每一項都對這些表格格式提供了不同程度的支援。 Onetable 允許我們的客戶使用任何與三種格式中的至少一種整合的服務,從而為他們提供儘可能多的選擇。
Onehouse 致力於開源,其中包括 Onetable。 最初這將是為 Onehouse 客戶保留的內部功能,因為我們會迭代設計和實施。 我們正在尋找來自其他專案和社群的合作伙伴來迭代這個共用的表標準表示,並最終為整個生態系統開源該專案。 例如當底層 Hudi 表發生變化時,Hudi 的目錄同步表服務會增量維護此類目錄後設資料。 與 Onetable 的類似實現,將通過單個整合使不同引擎之間的後設資料保持同步,從而為資料湖使用者創造巨大的價值。
PS:如果您覺得閱讀本文對您有幫助,請點一下「推薦」按鈕,您的「推薦」,將會是我不竭的動力!
作者:leesf 掌控之中,才會成功;掌控之外,註定失敗。
出處:http://www.cnblogs.com/leesf456/
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連線,否則保留追究法律責任的權利。
如果覺得本文對您有幫助,您可以請我喝杯咖啡!

