使用機器學習協助災後救援
2023 年 2 月 6 日,土耳其東南部發生 7.7 級和 7.6 級地震,影響 10 個城市,截至 2 月 21 日已造成 42,000 多人死亡和 120,000 多人受傷。
地震發生幾個小時後,一群程式設計師啟動了一個 Discord 服務,推出了一個名為 afetharita 的應用程式,字面意思是 災難地圖。該應用程式將為搜救隊和志願者提供服務,以尋找倖存者併為他們提供幫助。當倖存者在社交媒體上釋出帶有他們的地址和他們需要的東西 (包括救援) 的文字截圖時,就需要這樣一個應用程式。一些倖存者還在釋出了他們需要的東西,這樣他們的親屬就知道他們還活著並且需要救援。需要從這些推文中提取資訊,我們開發了各種應用程式將它們轉化為結構化資料,並爭分奪秒的開發和部署這些應用程式。
當我被邀請到 Discord 服務時,關於我們 (志願者) 將如何運作以及我們將做什麼的問題弄得非常混亂。我們決定共同作業訓練模型,並且我們需要一個模型和資料集登入檔。我們開設了一個 Hugging Face 組織帳戶,並通過拉取請求進行共同作業,以構建基於 ML 的應用程式來接收和處理資訊。
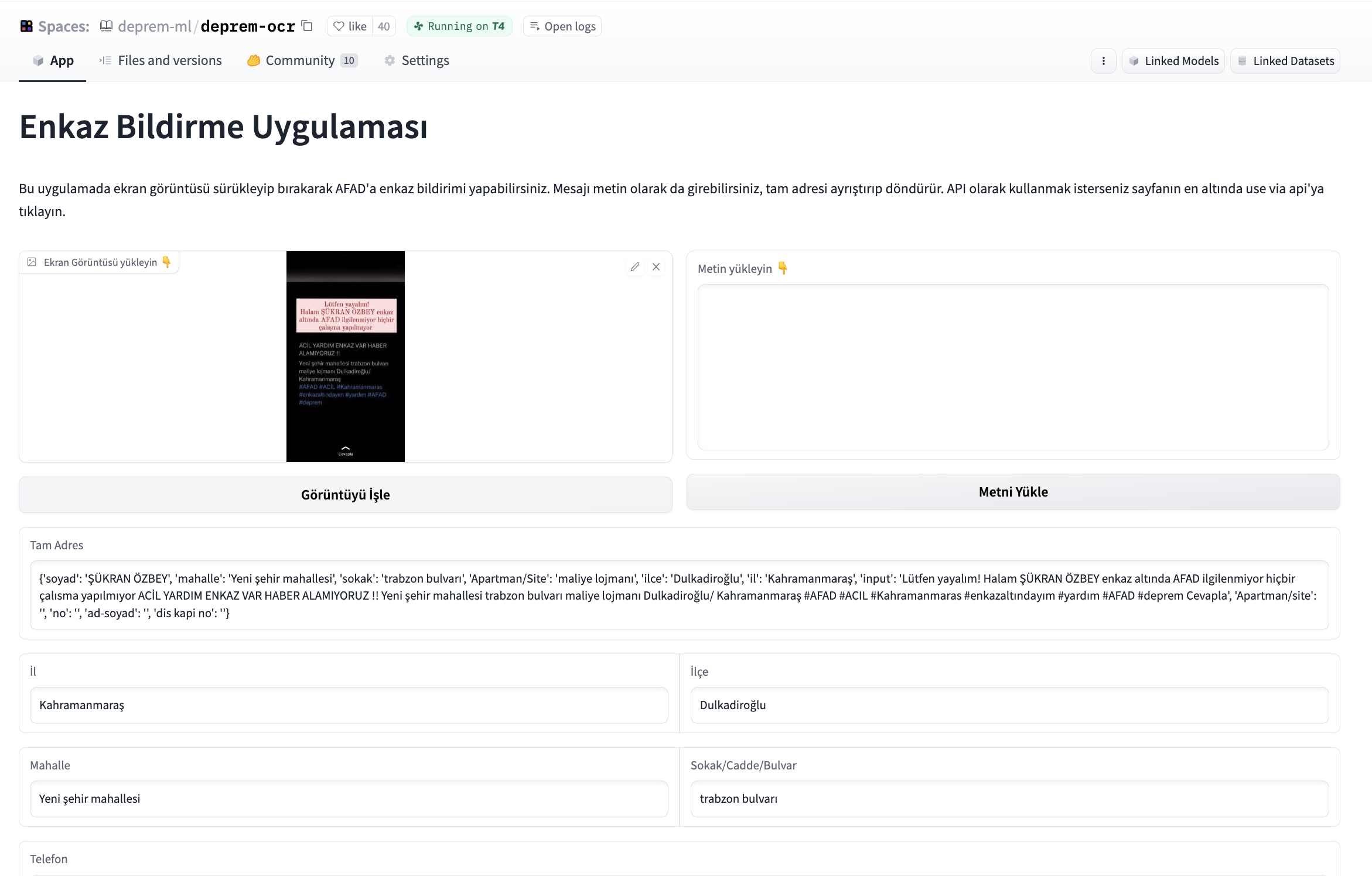
其他團隊的志願者告訴我們,需要一個應用程式來發布螢幕截圖,從螢幕截圖中提取資訊,對其進行結構化並將結構化資訊寫入資料庫。我們開始開發一個應用程式,該應用程式將拍攝給定影象,首先提取文字,然後從文字中提取姓名、電話號碼和地址,並將這些資訊寫入將交給當局的資料庫。在嘗試了各種開源 OCR 工具之後,我們開始使用 easyocrOCR 部分和 Gradio 為此應用程式構建介面。我們還被要求為 OCR 構建一個獨立的應用程式,因此我們從介面開啟了介面。使用基於 transformer 的微調 NER 模型解析 OCR 的文字輸出。
為了共同作業和改進該應用程式,我們將其託管在 Hugging Face Spaces 上,並且我們獲得了 GPU 資助以保持該應用程式的正常執行。Hugging Face Hub 團隊為我們設定了一個 CI 機器人,讓我們擁有一個短暫的環境,這樣我們就可以看到拉取請求如何影響 Space,並且幫助我們在拉取請求期間審查。
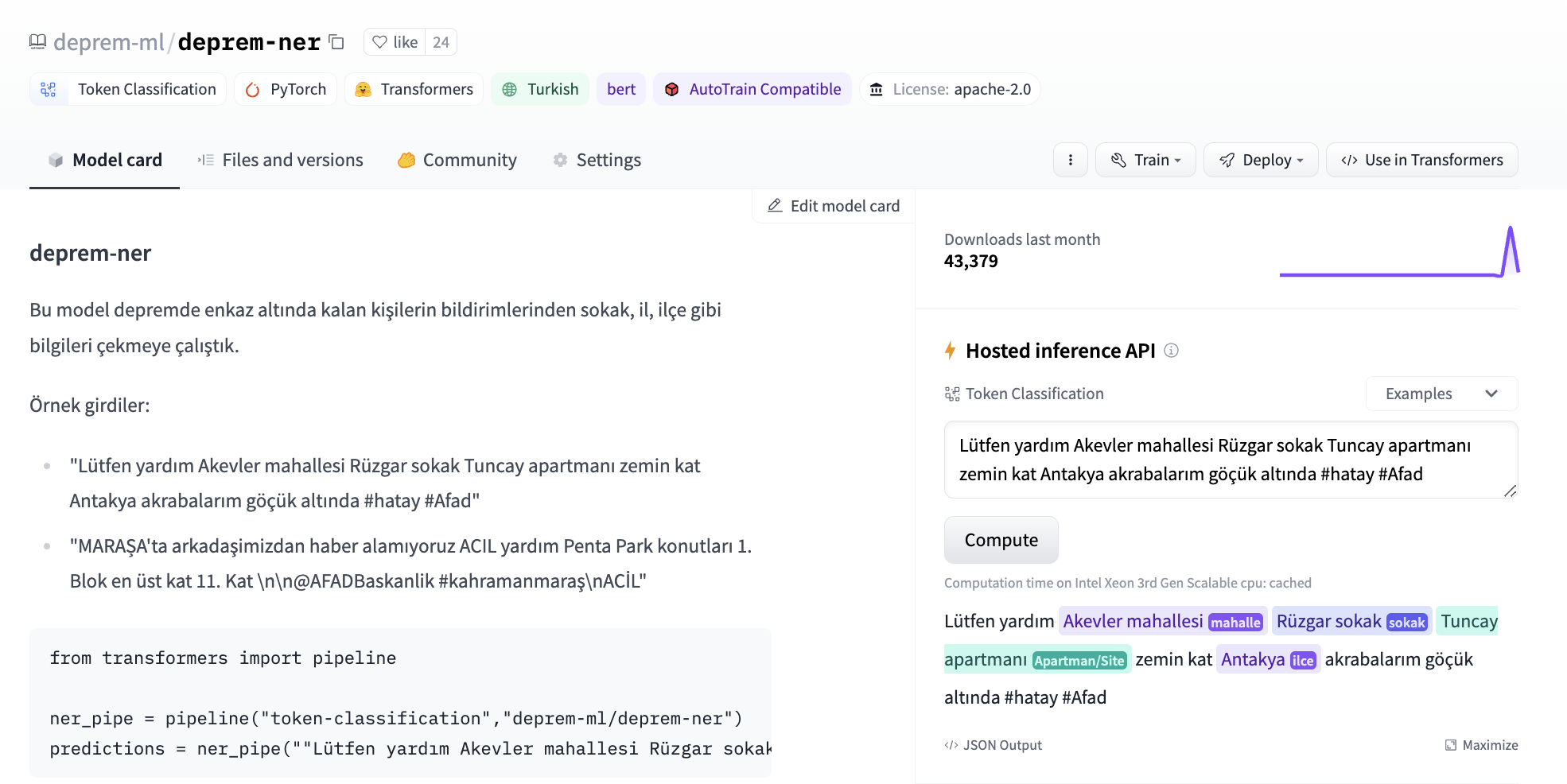
後來,我們從各種渠道 (例如 Twitter、Discord) 獲得了帶有標籤的內容,其中包括倖存者求救電話的原始推文,以及從中提取的地址和個人資訊。我們開始嘗試使用閉源模型的少量提示和微調來自 transformers 的我們自己的 token 分類模型。我們使用 bert-base-turkish-cased 作為 token 分類的基礎模型,並提出了第一個地址提取模型。
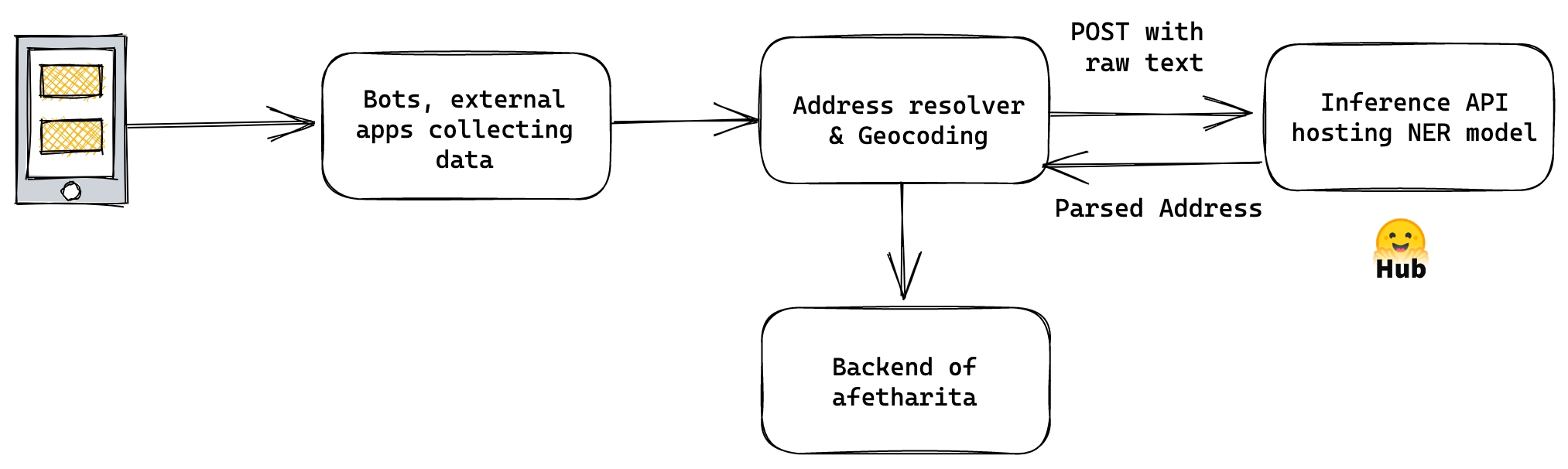
該模型後來用於 afetharita 提取地址。解析後的地址將被傳送到地理編碼 API 以獲取經度和緯度,然後地理定位將顯示在前端地圖上。對於推理,我們使用了 Inference API,這是一個託管模型進行推理的 API,當模型被推播到 Hugging Face Hub 時會自動啟用。使用 Inference API 進行服務使我們免於拉取模型、編寫應用程式、構建 Docker 映象、設定 CI/CD 以及將模型部署到雲範例,這些對於 DevOps 和雲團隊來說都是額外的開銷工作以及。Hugging Face 團隊為我們提供了更多的副本,這樣就不會出現停機時間,並且應用程式可以在大量流量下保持健壯。
後來,我們被問及是否可以從給定的推文中提取地震倖存者的需求。在給定的推文中,我們獲得了帶有多個標籤的資料,用於滿足多種需求,這些需求可能是住所、食物或物流,因為那裡很冷。我們首先開始在 Hugging Face Hub 上使用開源 NLI 模型進行零樣本實驗,並使用閉源生成模型介面進行少量樣本實驗。我們已經嘗試過 xlm-roberta-large-xnli 和 convbert-base-turkish-mc4-cased-allnli_tr. NLI 模型非常有用,因為我們可以直接推斷出候選標籤,並在資料漂移時更改標籤,而生成模型可能會編造標籤,在向後端提供響應時導致不匹配。最初,我們沒有標記的資料,因此任何東西都可以使用。
最後,我們決定微調我們自己的模型,在單個 GPU 上微調 BERT 的文字分類頭大約需要三分鐘。我們進行了標記工作來開發資料集去訓練該模型。我們在模型卡的後設資料中記錄了我們的實驗,這樣我們以後就可以出一個 leaderboard 來跟蹤應該將哪個模型部署到生產環境中。對於基本模型,我們嘗試了 bert-base-turkish-uncased 和 bert-base-turkish-128k-cased 並行現它們的效能優於 bert-base-turkish-cased 。你可以在 下面的連結 找到我們的 leaderboard。
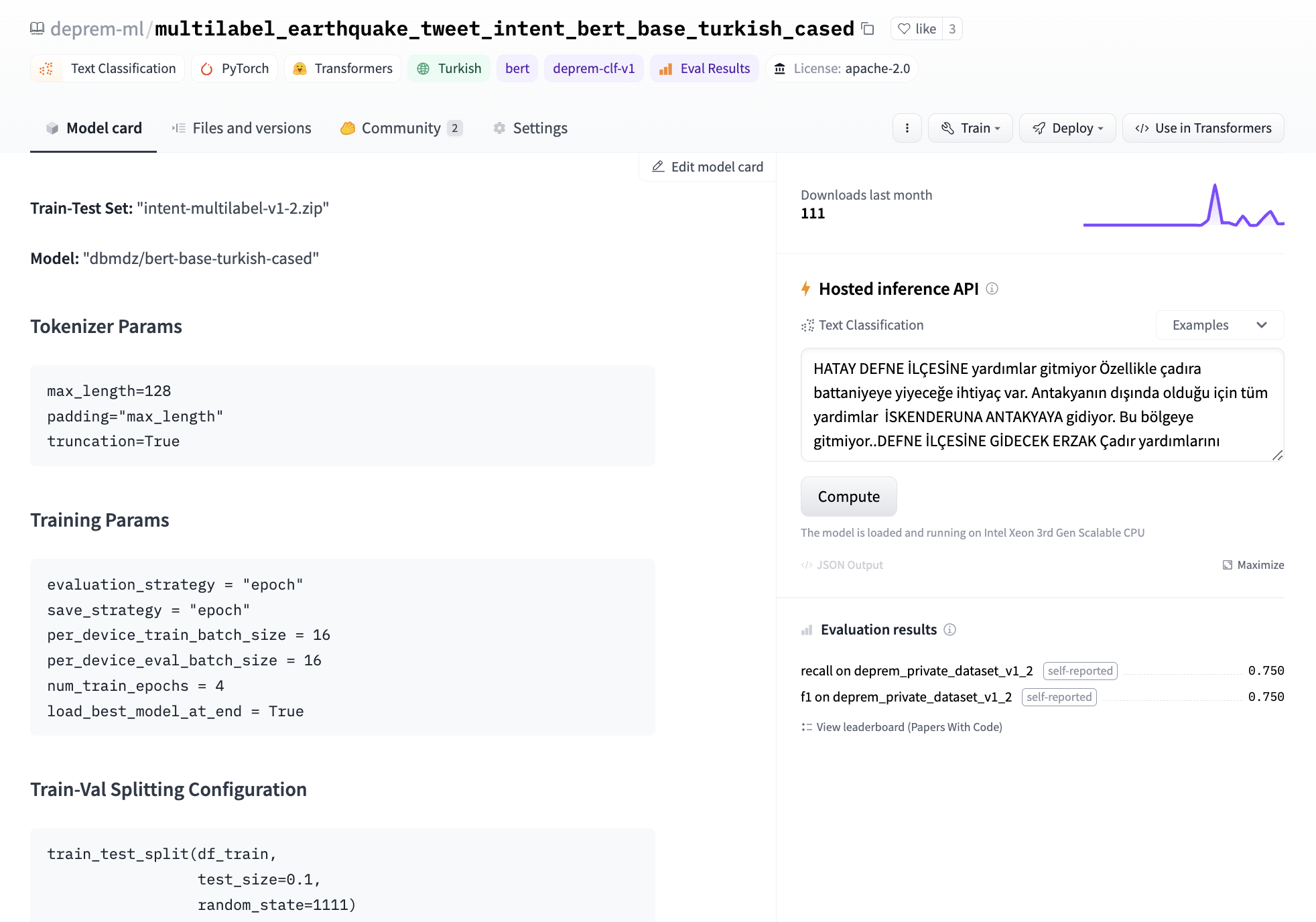
考慮到手頭的任務和我們資料類別的不平衡,我們專注於消除假陰性並建立了一個 Space 來對所有模型的召回率和 F1 分數進行基準測試。為此,我們將後設資料標籤新增 deprem-clf-v1 到所有相關模型儲存庫中,並使用此標籤自動檢索記錄的 F1 和召回分數以及模型排名。我們有一個單獨的基準測試集,以避免洩漏到訓練集,並始終如一地對我們的模型進行基準測試。我們還對每個模型進行了基準測試,以確定每個標籤的最佳部署閾值。
我們希望對我們的命名實體識別模型進行評估,並行起了眾包努力,因為資料標記者正在努力為我們提供更好和更新的意圖資料集。為了評估 NER 模型,我們使用 Argilla 和 Gradio 搭建了一個標註介面,人們可以輸入一條推文,並將輸出標記為正確/不正確/模糊。
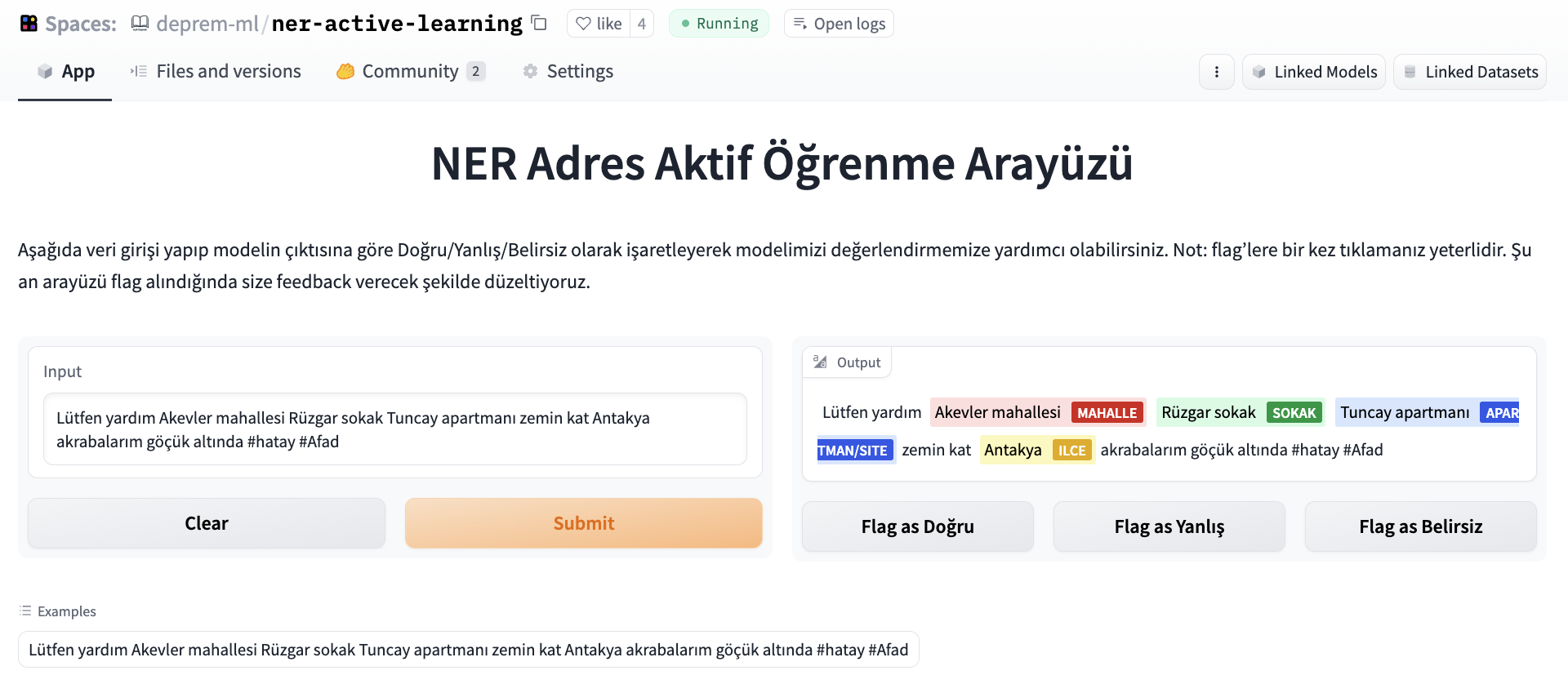
後來,資料集被去重並用於基準測試我們的進一步實驗。
機器學習團隊中的另一個小組使用生成模型 (通過門控 API) 來獲取特定需求 (因為標籤過於寬泛) 的自由文字,並將文字作為每個貼文的附加上下文傳遞。為此,他們進行了提示工程,並將 API 介面包裝為單獨的 API ,並將它們部署在雲端。我們發現,使用 LLM 的少樣本提示有助於在快速發展的資料漂移存在的情況下適應細粒度的需求,因為我們需要調整的唯一的東西是提示,而且我們不需要任何標記的資料。
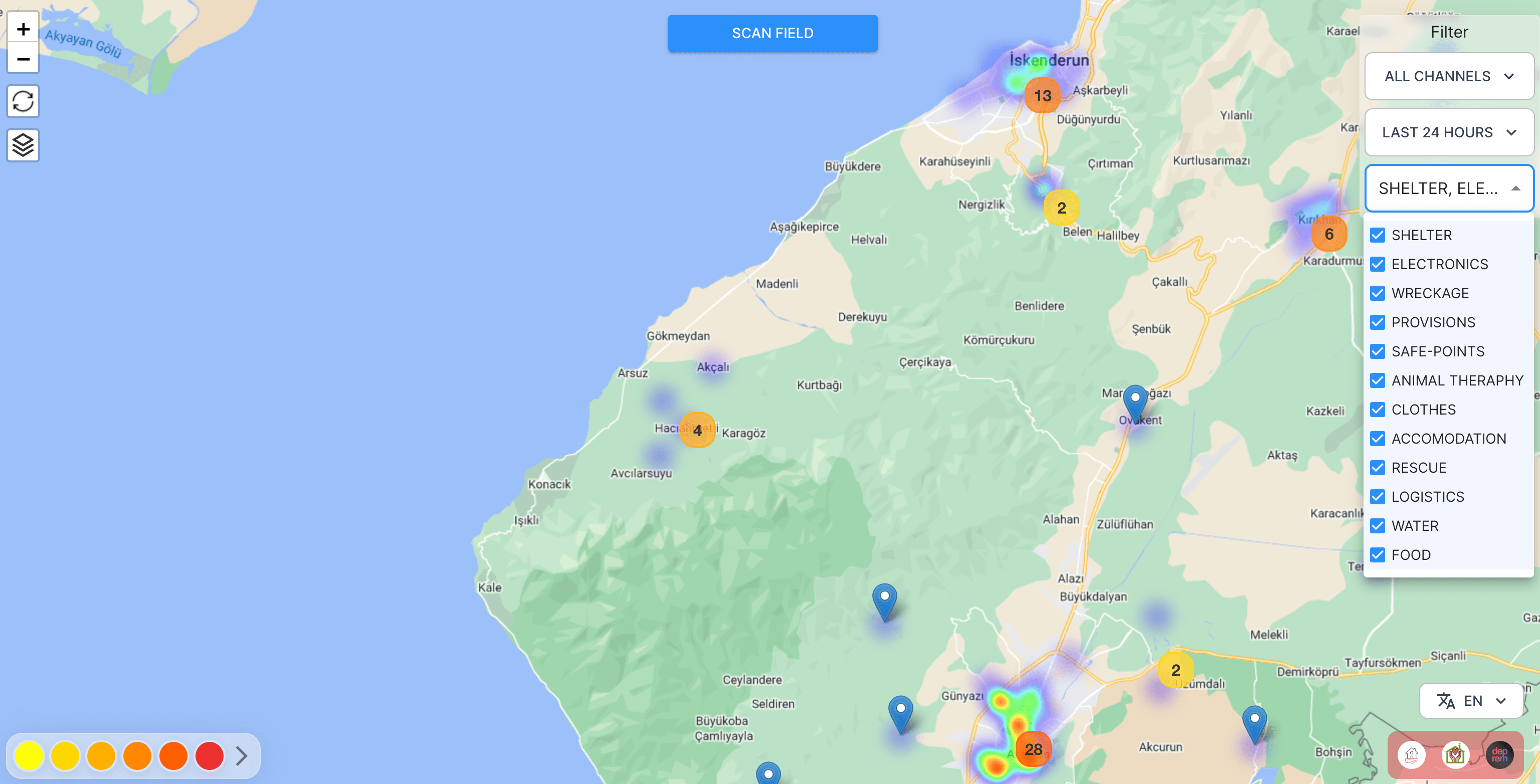
這些模型目前正在生產中使用,以建立下面熱圖中的點,以便志願者和搜救團隊可以將需求帶給倖存者。
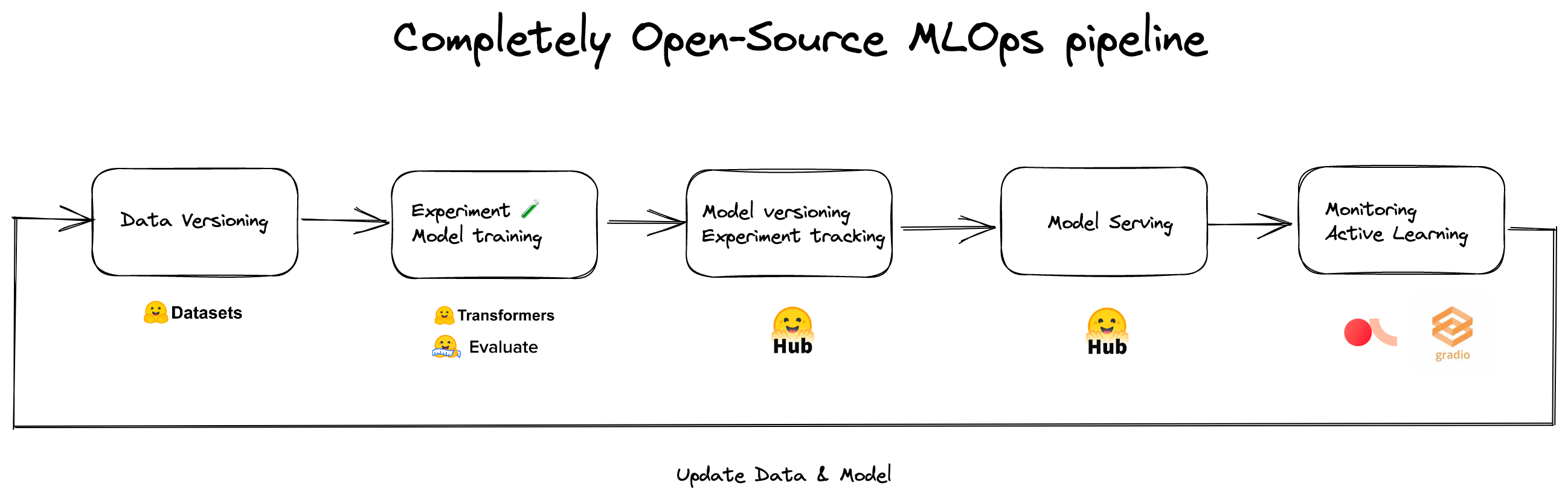
我們已經意識到,如果沒有 Hugging Face Hub 和其生態系統,我們將無法如此快速地共同作業、製作原型和部署。下面是我們用於地址識別和意圖分類模型的 MLOps 流水線。
這個應用程式及其各個元件背後有數十名志願者,他們不眠不休地工作以在如此短的時間內就完成了。
遙感應用
其他團隊致力於遙感應用,以評估建築物和基礎設施的損壞情況,以指導搜尋和救援行動。地震發生後的最初 48 小時內,電力和行動網路都沒有穩定,再加上道路倒塌,這使得評估損壞程度和需要幫助的地方變得極其困難。由於通訊和運輸困難,搜救行動也因建築物倒塌和損壞的虛假報告而受到嚴重影響。
為了解決這些問題並建立可在未來利用的開源工具,我們首先從 Planet Labs、Maxar 和 Copernicus Open Access Hub 收集受影響區域的震前和震後衛星影象。

我們最初的方法是快速標記衛星影象以進行目標檢測和實體分割,並使用「建築物」的單一類別。目的是通過比較從同一地區收集的震前和震後影象中倖存建築物的數量來評估損壞程度。為了更容易訓練模型,我們首先將 1080x1080 的衛星影象裁剪成更小的 640x640 塊。接下來,我們微調了用於建築物檢測的 YOLOv5、YOLOv8 和 EfficientNet 模型以及用於建築物語意分割的 SegFormer 模型,並將這些應用部署到 Hugging Face Spaces。
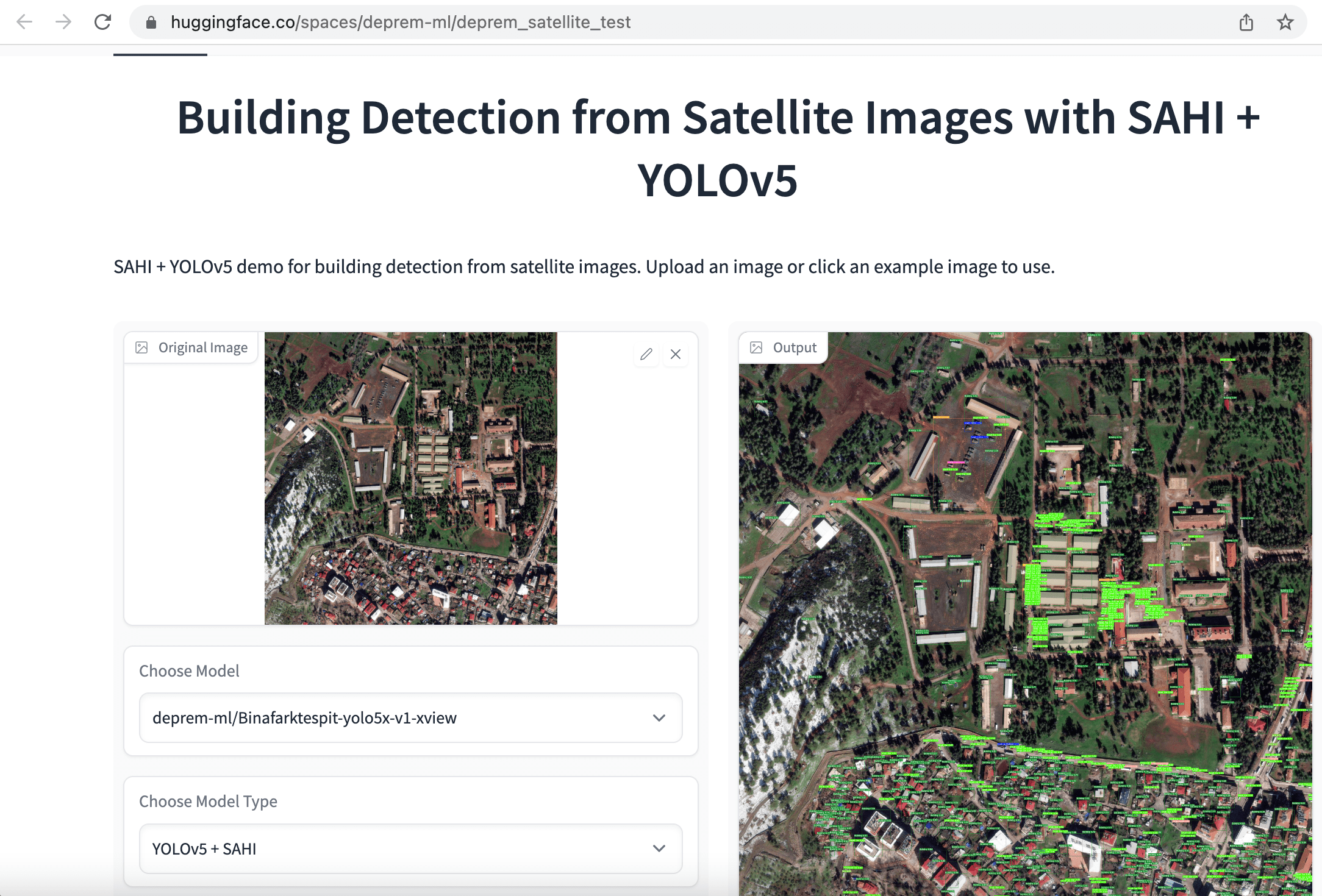
同樣,數十名志願者致力於標記、準備資料和訓練模型。除了個人志願者外,像 Co-One 這樣的公司也自願為衛星資料進行更詳細的建築和基礎設施註釋標記,包括 無失真傷、被摧毀、受損、受損設施 和 未受損設施 標籤。我們當前的目標是釋出一個廣泛的開源資料集,以便在未來加快全球的搜救行動。

總結
對於這種極端應用案例,我們必須迅速行動,並優化分類指標,即使 1% 的改進也很重要。在此過程中有許多倫理討論,因為甚至選擇要優化的指標也是一個倫理問題。我們已經看到了開源機器學習和民主化是如何使個人能夠構建挽救生命的應用程式。
我們感謝 Hugging Face 社群釋出這些模型和資料集,以及 Hugging Face 團隊提供的基礎架構和 MLOps 支援。
原文: https://hf.co/blog/using-ml-for-disasters
作者: Merve Noyan、Alara Dirik
譯者: innovation64(李洋)
審校: zhongdongy (阿東)