火山引擎 A/B 測試產品——DataTester 私有化架構分享
作為一款面向 ToB 市場的產品——火山引擎A/B測試(DataTester)為了滿足客戶對資料安全、合規問題等需求,探索私有化部署是產品無法繞開的一條路。
在面向 ToB 客戶私有化的實際落地中,火山引擎A/B測試(DataTester)也遇到了位元組內部服務和企業 SaaS 服務都不容易遇到的問題。在解決這些問題的落地實踐中,火山引擎 A/B 測試團隊沉澱了一些流程管理、效能優化等方面的經驗。
本文主要分享火山引擎A/B測試當前的私有化架構,遇到的主要問題以及從業務角度出發的解決思路。
火山引擎 A/B 測試私有化架構
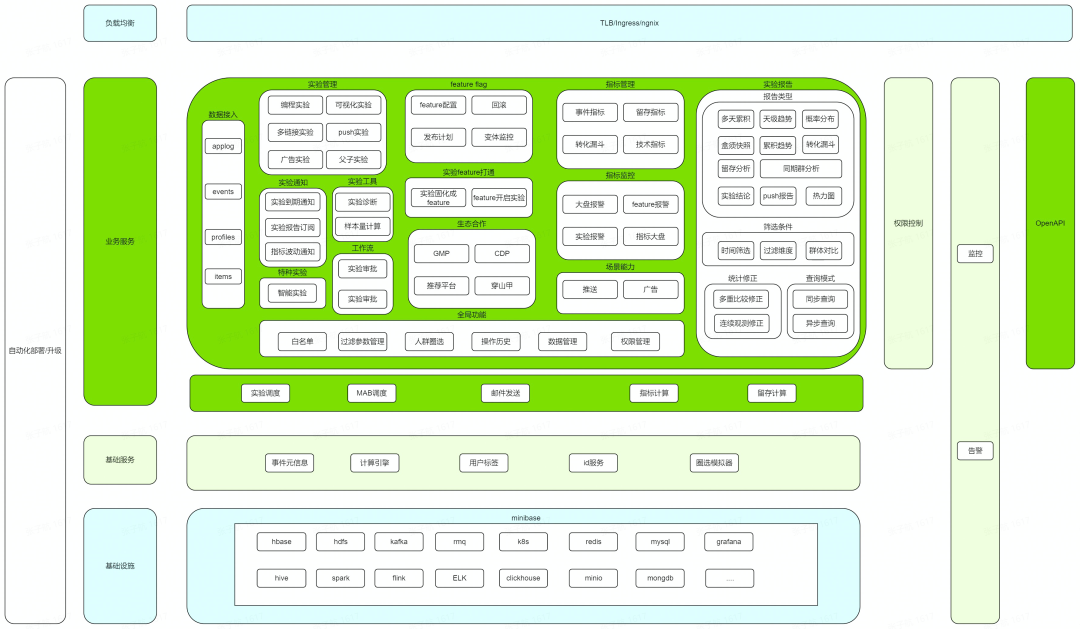
架構圖整套系統採用 Ansible+Bash 的方式構建,為了適應私有化小叢集部署,既允許各範例對等部署,複用資源,實現最小三節點交付的目標,,又可以做線上、離線資源隔離提高叢集穩定性。叢集內可以劃分為三部分:
-
業務服務: 主要是直接向用戶提供介面或者功能服務的, 例如實驗管理、實驗報告、OpenAPI、資料接入等。
-
基礎服務: 不直接面向用戶,為上層服務的執行提供支撐,例如支援實驗報告的計算引擎、為指標建立提供元資訊的元資訊服務;基礎服務同時還會充當一層對基礎設施的適配,用來遮蔽基礎設施在 SaaS 和私有化上的差異, 例如 SaaS 採用的實時+離線的 Lambda 架構, 私有化為了減少資源開銷,適應中小叢集部署只保留實時部分, 計算引擎服務向上層遮蔽了這一差異。
-
基礎設施: 內部團隊提供統一私有化基礎設施底座 minibase,採用宿主機和 k8s 結合的部署方式,由 minibase 適配底層作業系統和硬體, 上層業務直接對接 minibase。
私有化帶來的挑戰
挑戰 1:版本管理
傳統 SaaS 服務只需要部署維護一套產品供全部客戶使用,因此產品只需要針對單個或幾個服務更新,快速上線一個版本特性,而不需要考慮從零開始搭建一套產品。SaaS 服務的版本釋出週期往往以周為單位,保持每週 1-2 個版本更新頻率。但是,在私有化交付中,我們需要確定一個基線版本並且繫結每個服務的小版本號以確保相同版本下每套環境中的交付物等價,以減輕後續升級運維成本。通常,基線版本的釋出週期往往以雙月為單位。
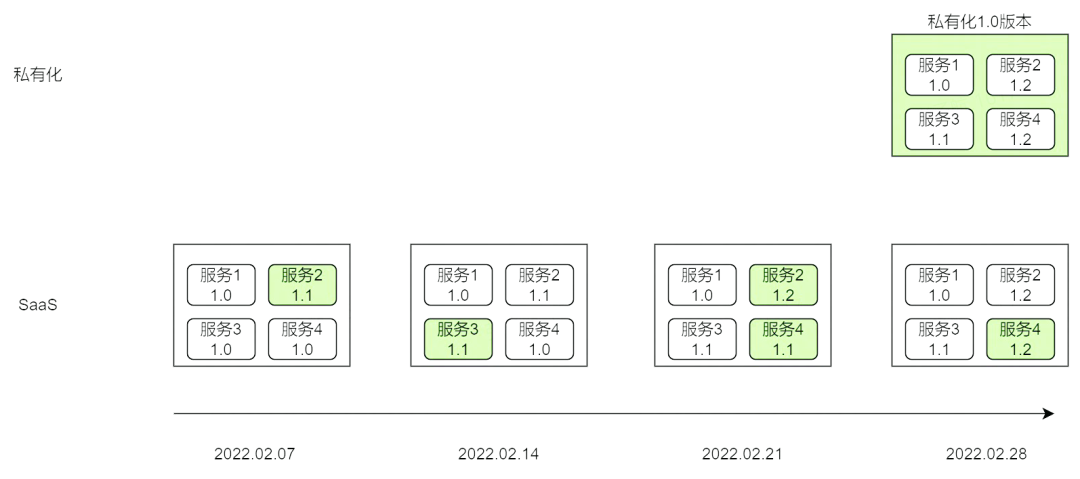
版本釋出週期
由於私有化和 SaaS 服務在架構、實現、基礎底座上均存在不同,上述的釋出節奏會帶來一個明顯的問題:
團隊要投入大量的開發和測試人力集中在發版週期內做歷史 Feature 的私有化適配、私有化特性的開發、版本釋出的整合測試,擠佔其他需求的人力排期。
為了將週期內集中完成的工作分散到 Feature 開發階段,重新規範了分支使用邏輯、完善私有化流水線和上線流程,讓研發和測試的介入時間前移。
解法:
1、分支邏輯
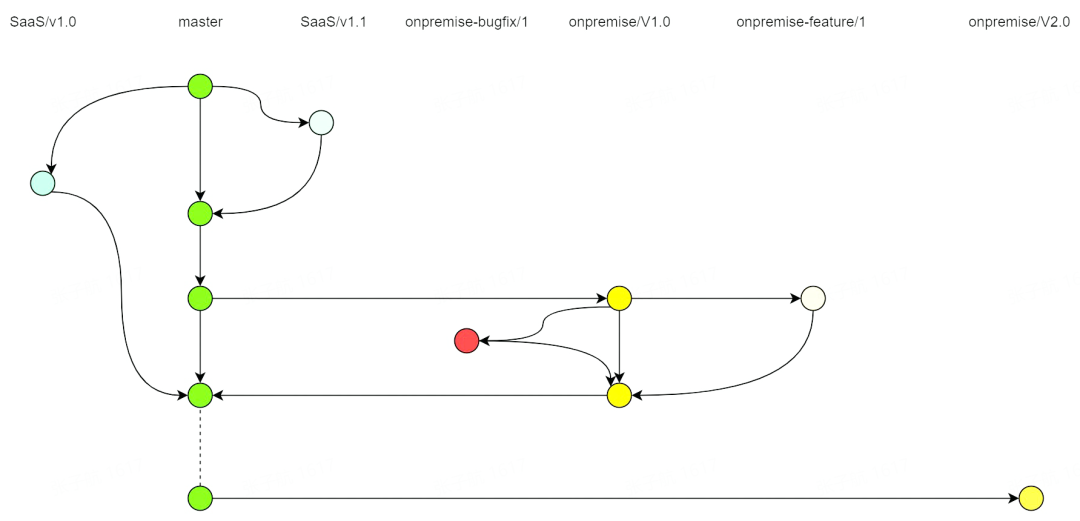
分支管理
SaaS 和私有化均基於 master 分支釋出,非私有化版本週期內不特別區分 SaaS 和私有化。
私有化釋出週期內單獨建立對應版本的私有化分支,釋出完成後向 master 分支合併。這樣保證了 master 分支在任何情況下都應當能同時在 SaaS 環境和私有化環境中正常工作。
2、釋出流水線
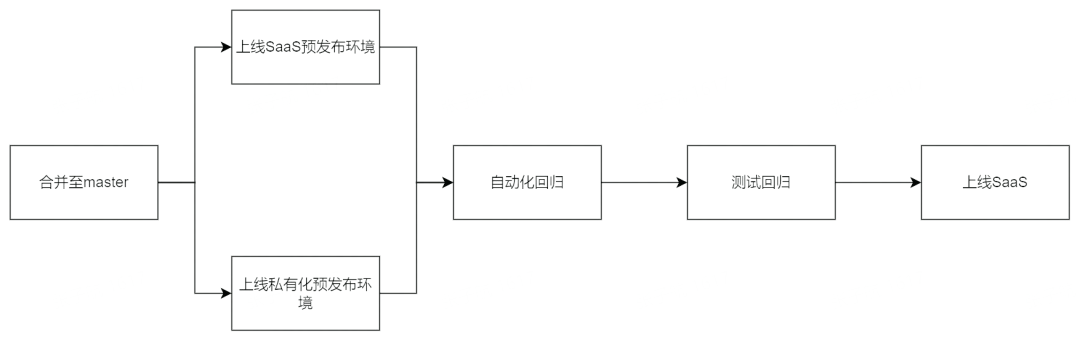
功能上線流程

釋出流水線
內部搭建一套私有化預釋出環境,建設了一套流水線,對 master 分支的 mr 會觸發流水線同時在 SaaS 預釋出環境和私有化預釋出環境更新最新 master 分支程式碼,並執行自動化迴歸和人工迴歸測試。這樣做的好處在於:
-
推動了具體 Feature 的研發從技術方案設計層面考慮不同環境的 Diff 問題,減少了後期返工的成本
-
測試同學的工作化整為零,避免短時間內的密集測試
-
減少研發和測試同學的上下文切換成本,SaaS 和私有化都在 Feature 開發週期內完成
挑戰 2:效能優化
火山引擎 A/B 測試工具的報告計算是基於 ClickHouse 實現的實時分析。SaaS 採用多租戶共用多個大叢集的架構,資源彈性大,可以合理地複用不同租戶之間的計算資源。
私有化則大部分為小規模、獨立叢集,不同客戶同時執行的實驗個數從幾個到幾百個不等,報告觀測時間和使用者習慣、公司作息相關,有明顯的峰谷現象。因此實驗報告產出延遲、實時分析慢等現象在私有化上更加容易暴露。
解法:
1、 實驗報告體系
首先,介紹下火山引擎 A/B 測試產品的實驗報告體系。以下圖的實驗報告為例:
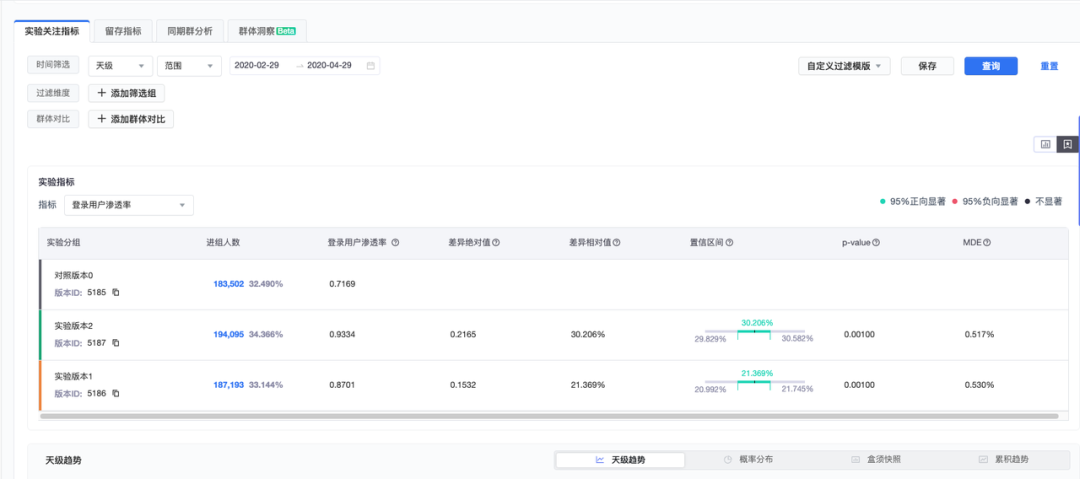
從上往下看產出一個實驗報告必要的輸入包含:
-
分析的日期區間及過濾條件
-
選擇合適的指標來評估實驗帶來的收益
-
實驗版本和對照版本
-
報告型別, 例如:做多天累計分析、單天的趨勢分析等
指標如何定義呢?
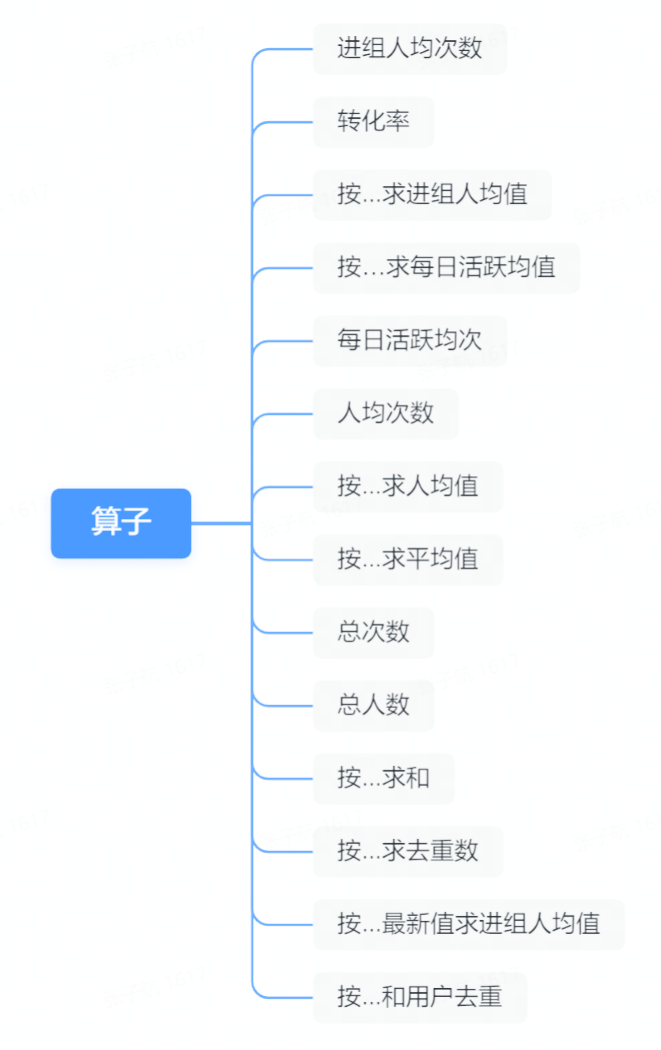
組成指標的核心要素包括:
-
由使用者行為產生的事件及屬性
-
預置的運算元
-
四則運運算元
即對於一個使用者的某幾個行為按照運算元的規則計算 value 並使用四則運算組合成一個指標。
由此,我們可以大概想象出一個常規的 A/B 實驗報告查詢是通過實驗命中情況圈出實驗組或對照組的人群,分析這類群體中在實驗週期內的指標值。
由於 A/B 特有的置信水平計算需求,統計結果中需要體現方差等其他特殊統計值,所有聚合類計算如:求和、PV 數均需要聚合到人粒度計算。
2、 模型優化
如何區分使用者命中哪一組呢?
整合 SDK 呼叫 A/B 分流方法的同時會上報一條實驗曝光事件記錄使用者的進組資訊,後續指標計算認為發生在進組之後的事件受到了實驗版本的影響。舉個例子:
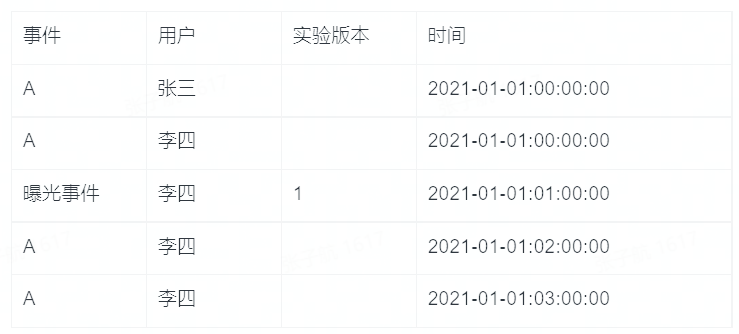
進入實驗版本 1 的事件 A 的 PV 數是 2,UV 數是 1,轉化為查詢模型是:
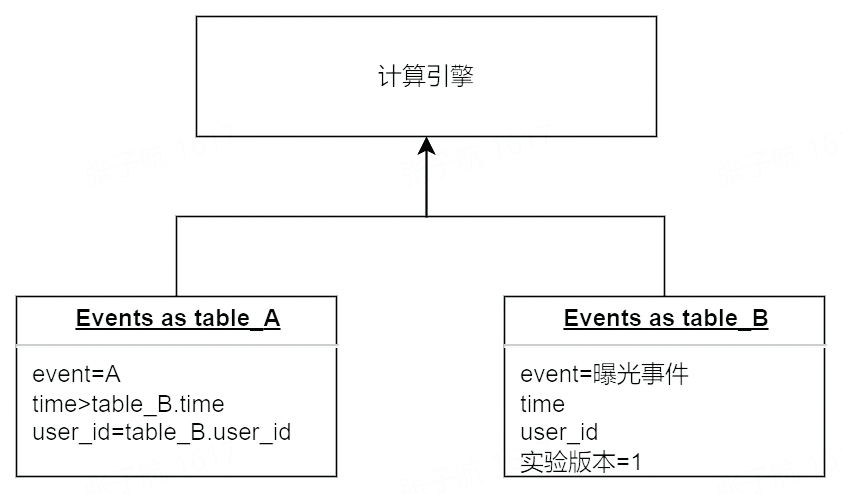
上述模型雖然最符合直覺,但是存在較多的資源浪費:
-
曝光事件和普通事件儲存在一張事件表中量級大
-
曝光事件需要搜尋第一條記錄,掃描的分割區數會隨著實驗時間的增加而增加
-
曝光事件可能反覆上報,計算口徑中僅僅第一條曝光為有效事件
針對上述問題對計算模型做出一些優化,把曝光事件轉化為屬性記錄在使用者表中,新的模型變化為:
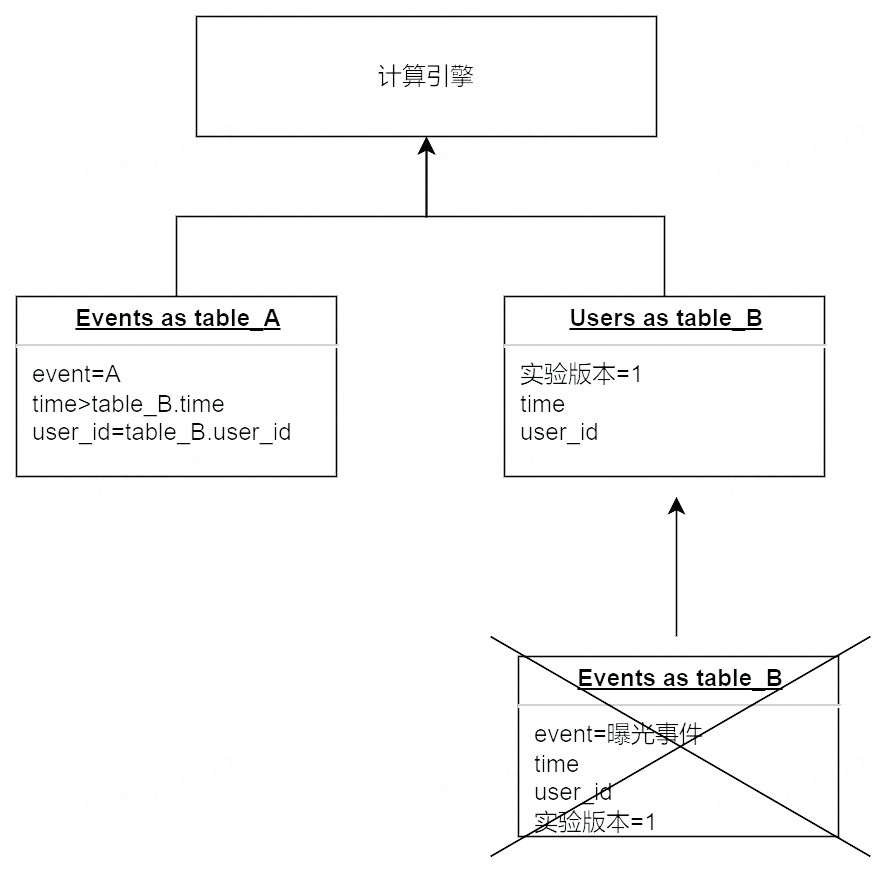
這麼做帶來的優點是:
-
使用者表不存在時間的概念,資料增長=新使用者增速,規模可控
-
使用者表本身會作為維度表在原模型中引入,這類情況下減少一次 join 運算 模型優化後經測試 14 天以上實驗指標多天累計報告查詢時長減少 50%以上,且隨實驗時長增加提升。
3、 預聚合
私有化部署實施前會做前期的資源預估,現階段的資源預估選擇了「日活使用者」和「日事件量」作為主要輸入引數。這裡暫時沒有加入同時執行的實驗數量是因為:
一是,我們希望簡化資源計算的模型。
二是,同時執行的實驗數量在大多數情況下無法提前預知。
但是該公式會引入一個問題:相同資源的叢集在承載不同數量級的實驗時計算量相差較大。實驗數量少的場景下,當下資料處理架構輕量化,計算邏輯後置到查詢側,,指標計算按需使用,大大減輕了資料流任務的壓力。
但是假設叢集中同時執行 100 個實驗,平均每個實驗關注 3 個指標加上實驗的進組人數統計,在當前查詢模型下每天至少掃描事件表 100*(3+1)次,如果再疊加使用自定義過濾模板等預計算條件,這個計算量會被成倍放大,直到導致查詢任務堆積資料產出延遲。
重新觀察實驗報告核心元素以及指標構成能發現:
-
指標、報告型別、實驗版本是可列舉且預先知曉的
-
實驗命中和人繫結,版本對比先劃分出進入對照組和實驗組的人,然後做指標比較
-
基於假設檢驗的置信水平計算需要按人粒度計算方差
-
現有的指標運算元均可以先按人粒度計算(按....去重除外)
是否能夠通過一次全量資料的掃描計算出人粒度的所有指標和實驗版本?
答案是可以的:掃描當天的事件資料,根據實驗、指標設定計算一張人粒度的指標表 user_agg。
通過 user_agg 表可以計算出指標計算需要的 UV 數、指標的統計值、指標的方差。如果對 user_agg 表的能力做進一步拓展,幾乎可以代替原始表完成實驗報告中 80%以上的指標計算,同時也很好地支援了天級時間選擇切換、使用者屬性標籤過濾等。
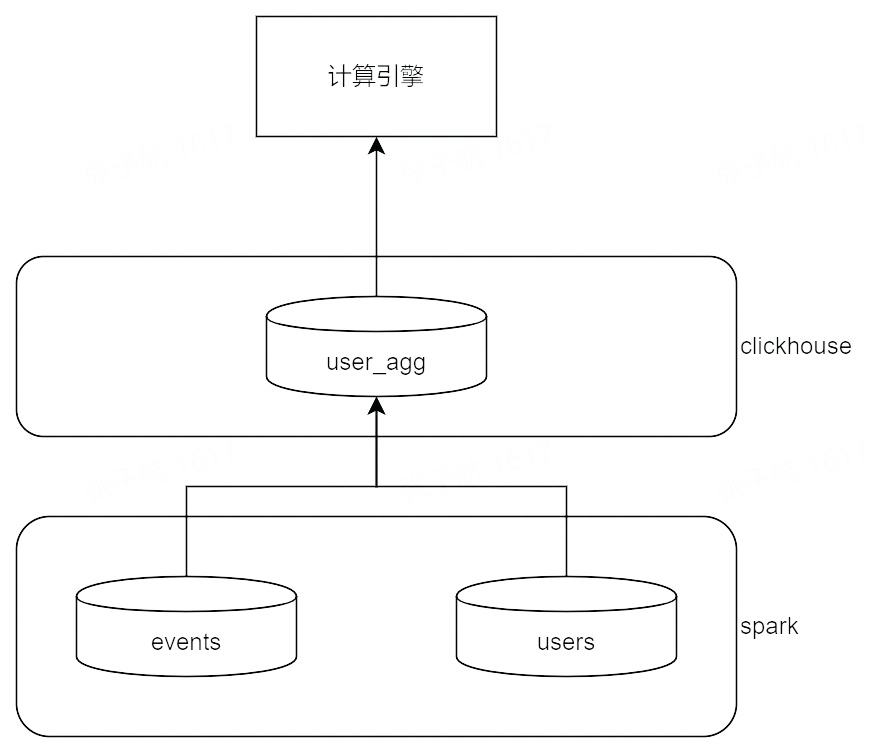
修改後的指標計算模型
通過經驗資料,一個使用者平均每天產生的事件量在 100-500 條不等,聚合模型通過少數幾次對當天資料的全表掃描得到一張 1/100-1/500 大小的中間表,後續的指標計算、使用者維度過濾均可以使用聚合表代替原始表參與運算。當然考慮到聚合本身的資源開銷,收益會隨著執行實驗數增加而提高,而實驗數量過少時可能會造成資源浪費,是否啟用需要在兩者之間需求平衡點。
挑戰 3:穩定性
私有化服務的運維通道複雜、運維壓力大,因此對服務的可用性要求更加嚴格。A/B 測試穩定性要求最高的部分是分流服務,直接決定了線上使用者的版本命中情況。
分流服務本身面向故障設計, 採用降級的策略避免呼叫鏈路上的失敗影響全部實驗結果,犧牲一部分實時性使用多級快取保障單一基礎設施離線的極端情況下分流結果依然穩定。
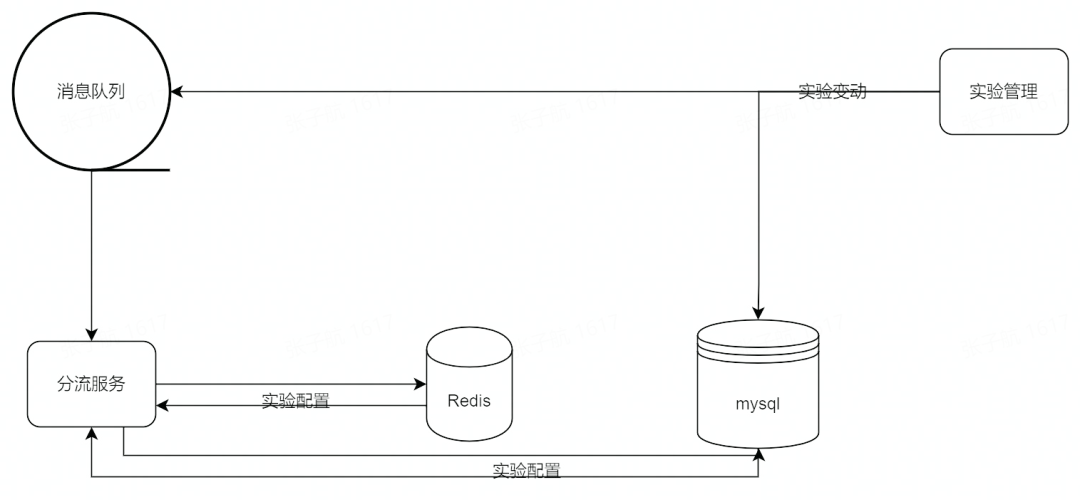
分流服務總體架構
我們將分流服務作為一個整體,一共使用了 3 級儲存,分別是服務記憶體、Redis 快取、關係型資料庫。實驗變動落庫的同時,將變動訊息寫入訊息佇列,分流服務消費訊息佇列修改記憶體和 Redis 快取中的實驗設定,保證多節點之間的一致性和實時性。同時分流服務開啟一個額外協程定期全量更新實驗設定資料作為兜底策略,防止因為訊息佇列故障導致的設定不更新;將 Redis 視作 Mysql 的備元件,任意失效其中之一,這樣分流服務即使重啟依然可以恢復最新版本的分流設定,保障客戶側分流結果的穩定。
總結
火山引擎 A/B 測試(DataTester)脫胎於位元組跳動內部工具,整合了位元組內部豐富的業務場景中的 A/B 測實驗經驗;同時它又立足於 B 端市場,不斷通過 ToB 市場的實踐經驗沉澱打磨產品來更好為內外部客戶創造價值。
本文是火山引擎 A/B 測試(DataTester)團隊在當前面向 ToB 客戶的私有化實踐中的實踐分享,文中所遇到的私有化問題的破解過程也是這一產品不斷打磨成熟,從 0-1 階段走向 1-N 階段的過程。
點選跳轉 火山引擎A/B測試DataTester 瞭解更多