容器雲平臺監控告警體系(三)—— 使用Prometheus Operator部署並管理Prometheus Server
1、概述
Prometheus Operator是一種基於Kubernetes的應用程式,用於管理Prometheus範例和相關的監控元件。它是由CoreOS開發的開源工具,旨在簡化Prometheus和相關監控元件的部署和設定。
容器雲平臺通過使用Prometheus Operator簡化在Kubernetes下部署和管理Prmetheus的複雜度,其通過prometheuses.monitoring.coreos.com資源宣告式建立和管理Prometheus Server範例;其通過servicemonitors.monitoring.coreos.com和podmonitors.monitoring.coreos.com資源宣告式的管理監控設定;其通過prometheusrules.monitoring.coreos.com資源進行規則記錄,實現對複雜查詢的 PromQL 語句的效能優化,提高查詢效率。
2、先決條件
截止2023年3月30日Prometheus Operator最新版本為0.64.0,對於0.39.0及以上版本需要Kubernetes叢集的版本>=1.16.0,如果您剛剛開始使用Prometheus Operator,強烈建議使用最新版本。
如果您有舊版本的Kubernetes和正在執行的Prometheus Operator,建議先升級 Kubernetes,然後再升級 Prometheus Operator。
注意:Prometheus Operator安裝和解除安裝比較簡單,直接參考 Prometheus Operator 工程的 README.md 檔案即可,推薦使用Helm方式進行安裝,本文不再講解。在容器雲平臺中是將Prometheus Operator中安裝相關的yaml檔案下載下來,然後通過Kubectl apply方式進行安裝。
3、Prometheus Operator的工作原理
簡單來說Prometheus Operator是一組自定義的CRD資源以及Controller的實現,Prometheus Operator負責監聽這些自定義資源的變化,並且根據這些資源的定義自動化的完成Prometheus範例和相關的監控元件的自動化管理工作,Prometheus Operator 官方提供的架構圖如下:
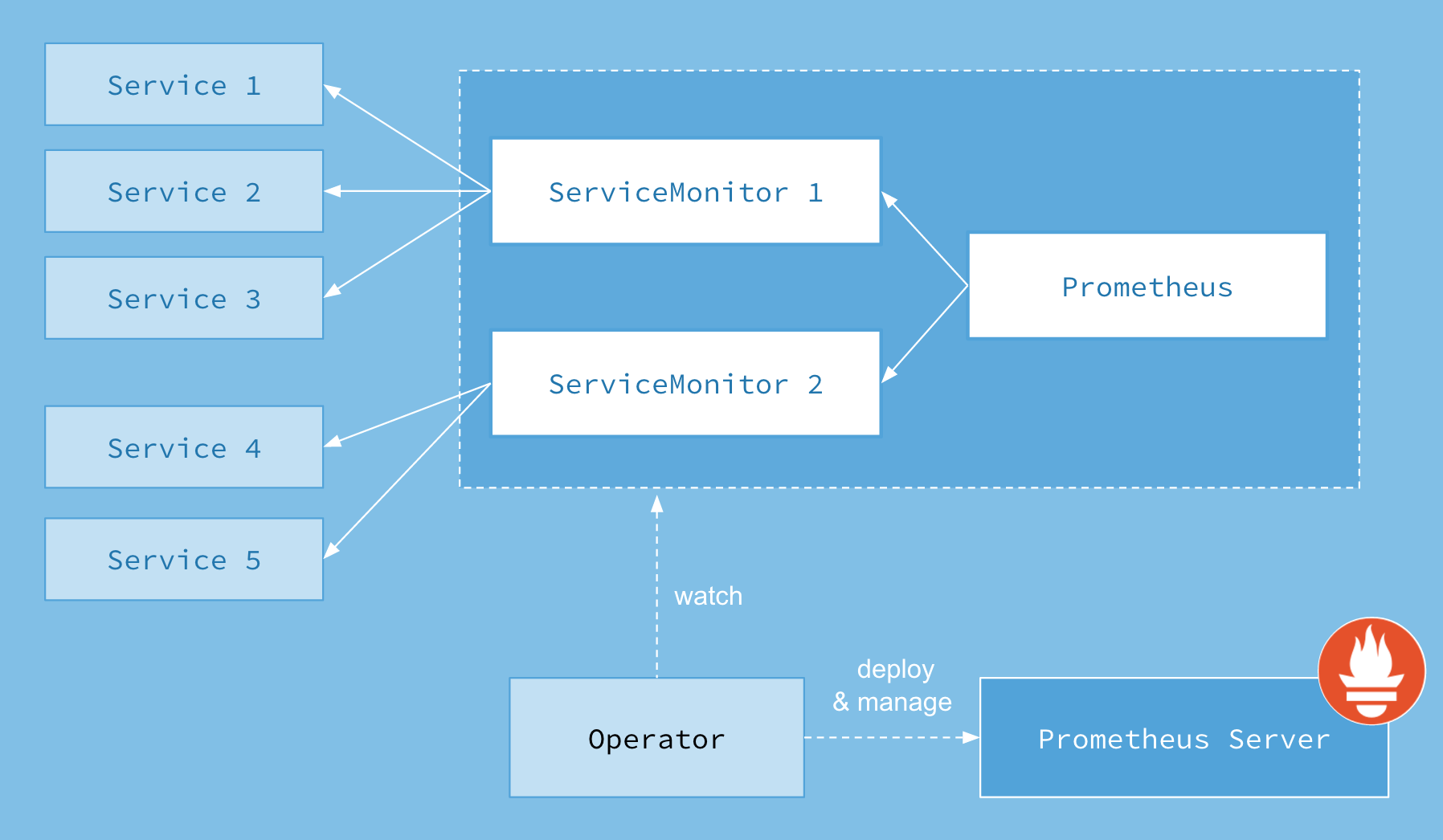
從下向上看,Operator可以部署並且管理Prometheus Server,並且Operator可以監聽Prometheus和ServiceMonitor這兩種自定義資源物件的變化。當Operator監聽到Prometheus資源物件變化時,會對應部署或者管理Prometheus Server;當Operator監聽到ServiceMonitor資源物件變化時,會對應修改Prometheus Server組態檔。上圖中Service1 - Service5是Kubernetes中的Service資源,ServiceMonitor資源物件通過labelSelector的方式去匹配一類Service(一般來說,一個ServiceMonitor資源物件對應一個Service資源物件),Prometheus也通過labelSelector去匹配一個或多個ServiceMonitor。
- Operator : Operator是整個系統的主要控制器,會以Deployment的方式執行於Kubernetes叢集上,並根據自定義資源(Custom Resources Definition)CRD 來負責部署與管理Prometheus Server,Operator會通過監聽這些CRD的變化來做出相對應的處理。
- Prometheus : Operator會觀察叢集內的Prometheus CRD資源物件,並在指定名稱空間下(預設是monitoring名稱空間下)建立一個StatefulSet資源物件來管理Prometheus Server,並且掛載了一個名為prometheus-"name"(Prometheus自定義資源名稱)的Secret為Volume到/etc/prometheus/config目錄,Secret的data包含了以下內容:
-
- configmaps.json:指定了rule-files在configmap的名字
- prometheus.yaml.gz:為Prometheus Server主組態檔,Operator監聽到Prometheus Server設定變更會更新secret(檔案prometheus-yaml.gz,使用gz保證<1M),config-reloader監控到prometheus-yaml.gz檔案有變更,將其解壓至prometheus-env.yaml,然後傳送reload給prometehus。
- ServiceMonitor :Operator會通過監聽ServiceMonitor資源物件的變化來動態生成Prometheus的組態檔中的Scrape targets(抓取目標),並讓這些設定實時生效,Operator通過將生成的監控目標更新到上面的prometheus-k8s這個Secret的Data的prometheus.yaml.gz欄位裡,然後Prometheus Server這個Pod裡的Sidecar容器
prometheus-config-reloader當檢測到掛載路徑的檔案發生改變後自動去執行HTTP Post請求到/api/-reload-路徑去reload設定。該自定義資源(CRD)通過labels選取對應的Service,並讓Prometheus Server通過選取的Service拉取對應的監控資訊(metrics)。
- Service :Service其實就是指Kubernetes的Service資源,簡單的說就是 Prometheus 監控的物件,比如部署在Kbernetes上的Mysql-Exporter的Service。
想象一下,我們以傳統的方式去監控一個Mysql服務,首先需要安裝Mysql-Exporter,獲取Mysql Metrics,並且暴露一個埠,等待Prometheus Server服務來拉取監控資訊,然後去Prometheus Server的prometheus.yaml檔案中在scarpe_config中新增Mysql-Exporter的job,設定Mysql-Exporter的地址和埠等資訊,再然後,需要重啟Prometheus服務,就完成新增一個mysql監控的任務。
現在我們以Prometheus-Operator的方式來部署Prometheus,當我們需要新增一個Mysql監控我們會怎麼做,首先第一步和傳統方式一樣,部署一個Mysql-Exporter來獲取Mysql監控項,然後編寫一個ServiceMonitor通過labelSelector選擇剛才部署的Mysql-Exporter,由於Operator在部署Prometheus的時候預設指定了Prometheus選擇label為:prometheus: kube-prometheus的ServiceMonitor,所以只需要在ServiceMonitor上打上prometheus: kube-prometheus標籤就可以被Prometheus選擇了,完成以上兩步就完成了對Mysql的監控,不需要改Prometheus Server組態檔,也不需要重啟Prometheus Server服務,是不是很方便,Operator觀察到ServiceMonitor發生變化,會動態生成Prometheus Server組態檔,並保證組態檔實時生效。
kubectl get secrets -n=名稱空間 prometheus-k8s -o json| jq -r '.data."prometheus.yaml.gz"' | base64 -d | gzip -d #先取出 data.「xxx.xxx.gz」 的值,再做 base64 解密和 gzip 還原, 得到最終組態檔
4、自定義資源
截止當前,Prometheus Operator對以下自定義資源定義 (CRD) 進行操作:
- prometheuses.monitoring.coreos.com
- servicemonitors.monitoring.coreos.com
- podmonitors.monitoring.coreos.com
- prometheusrules.monitoring.coreos.com
- alertmanagers.monitoring.coreos.com
- alertmanagerconfigs.monitoring.coreos.com
- thanosrulers.monitoring.coreos.com
- probes.monitoring.coreos.com
Prometheus Operator 官方提供根據Prometheus Operator CRD自動管理Prometheus Server的工作機制原理圖如下:
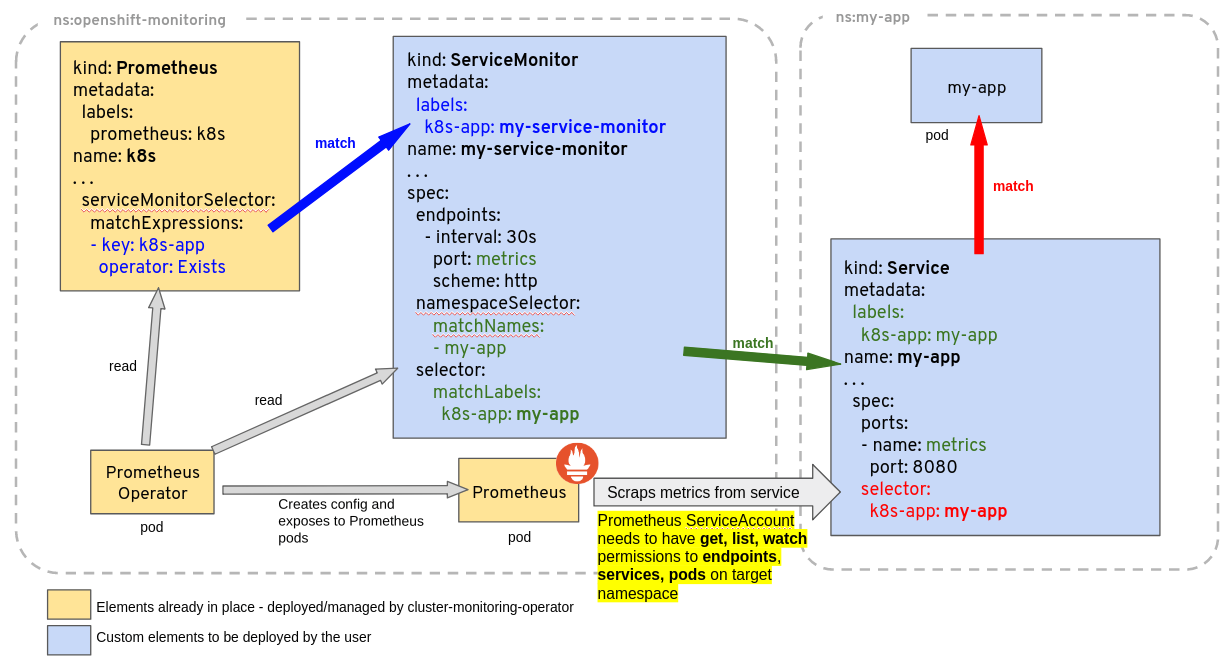
ServiceMonitor 可以通過 labelSelector 的方式去匹配一類 Service,Prometheus 也可以通過 labelSelector 去匹配多個ServiceMonitor。Prometheus Operator 自動檢測 Kubernetes API 伺服器對上述任何物件的更改,並確保匹配的部署和設定保持同步。
4.1 prometheuses.monitoring.coreos.com
Prometheus 自定義資源(CRD)宣告了在 Kubernetes 叢集中執行的 Prometheus 的期望設定。包含了副本數量,持久化儲存,serviceMonitorSelector,podMonitorSelector,ruleSelector 以及 Prometheus 範例傳送警告到的 Alertmanagers等設定選項。
每一個 Prometheus 資源,Operator 都會在相同 namespace 下部署成一個正確設定的 StatefulSet,Prometheus 的 Pod 都會掛載一個名為 <prometheus-name> 的 Secret,裡面包含了 Prometheus 的設定。Operator 根據包含的 ServiceMonitor/PodMonitor等CRD資源物件生成設定,並且更新含有設定的 Secret。無論是對 ServiceMonitors 或者 PodMonitor 的修改,Operator 都會實時更新在Secret裡。
一個樣例設定如下:
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata: # 略。。。。
spec:
alerting:
alertmanagers: #Prometheus 對接的 Alertmanager 叢集的名字, 在 monitor 這個 namespace 中
- apiVersion: v2
name: prometheus-kube-prometheus-alertmanager
namespace: monitor
pathPrefix: /
port: web
arbitraryFSAccessThroughSMs: {}
externalUrl: http://prometheus-dev.rencaiyoujia.cn/
image: quay.io/prometheus/prometheus:v2.26.0
logFormat: logfmt
logLevel: info
podMonitorNamespaceSelector: {} # podMonitor選擇名稱空間,空為所有
podMonitorSelector: #podMonitor 選擇標籤, 必須帶有這個標籤才能被Prometheus 匹配到。
matchLabels:
release: prometheus
portName: web
replicas: 2 # 定義該 Proemtheus 「叢集」有兩個副本,說是叢集,其實 Prometheus 自身不帶叢集功能,這裡只是起兩個完全一樣的 Prometheus 來避免單點故障
resources: {}
retention: 10d
routePrefix: /
ruleNamespaceSelector: {} # PrometheusRule 選擇的名稱空間,空為所有
ruleSelector: # PrometheusRule 必須帶有這兩個標籤才能被 Prometheus 匹配到。
matchLabels:
app: kube-prometheus-stack
release: prometheus
rules:
alert: {}
securityContext:
fsGroup: 2000
runAsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-kube-prometheus-prometheus
serviceMonitorNamespaceSelector: {} # serviceMonitor 選擇的名稱空間,空為所有
serviceMonitorSelector: # serviceMonitor 必須帶有這個標籤才能被 Prometheus 匹配到。
matchLabels:
release: prometheus
version: v2.26.0
4.2 servicemonitors.monitoring.coreos.com
ServiceMonitor 也是一個自定義資源,它描述了一組被 Prometheus 監控的 targets 列表。該資源通過 Labels 來選取對應的 Service Endpoint,讓 Prometheus Server 通過選取的 Service 來獲取 Metrics 資訊。
Operator 能夠動態更新 Prometheus 的 Target 列表,ServiceMonitor 就是 Target 的抽象。比如想監控 Kubernetes Scheduler,使用者可以建立一個與 Scheduler Service 相對映的 ServiceMonitor 物件。Operator 則會發現這個新的 ServiceMonitor,並將 Scheduler 的 Target 新增到 Prometheus 的監控列表中。
要想使用 Prometheus Operator 監控 Kubernetes 叢集中的應用,Endpoints 物件必須存在。Endpoints 物件本質是一個 IP 地址列表。通常,Endpoints 物件由 Service 構建。Service 物件通過物件選擇器發現 Pod 並將它們新增到 Endpoints 物件中。
Prometheus Operator 引入 ServiceMonitor 物件,它發現 Endpoints 物件並設定 Prometheus 去監控這些 Pods。
ServiceMonitorSpec 的 endpoints 部分用於設定需要收集 metrics 的 Endpoints 的埠和其他引數。在一些用例中會直接監控不在服務 endpoints 中的 pods 的埠。因此,在 endpoints 部分指定 endpoint 時,請嚴格使用,不要混淆。
注意:endpoints(小寫)是 ServiceMonitor CRD 中的一個欄位,而 Endpoints(大寫)是 Kubernetes 資源型別。
ServiceMonitor 和發現的目標可能來自任何 namespace。這對於跨 namespace 的監控十分重要,比如 meta-monitoring。使用 Prometheus.spec 下 ServiceMonitorNamespaceSelector, 通過各自 Prometheus server 限制 ServiceMonitors 作用 namespece。使用 ServiceMonitor.spec 下的 namespaceSelector 可以現在允許發現 Endpoints 物件的名稱空間。要發現所有名稱空間下的目標,namespaceSelector 必須為空。
一個樣例設定如下:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor #自定義資源
metadata:
annotations:
meta.helm.sh/release-name: prometheus
meta.helm.sh/release-namespace: monitor
creationTimestamp: "2021-04-19T08:12:35Z"
generation: 1
labels:
app: kube-prometheus-stack-alertmanager
app.kubernetes.io/managed-by: Helm
chart: kube-prometheus-stack-14.9.0
heritage: Helm
release: prometheus #必須帶有此標籤才能被prometheus 選擇到,在prometheus 自定義資源中設定。
name: prometheus-kube-prometheus-alertmanager
namespace: monitor
resourceVersion: "57106409"
selfLink: /apis/monitoring.coreos.com/v1/namespaces/monitor/servicemonitors/prometheus-kube-prometheus-alertmanager
uid: 06d6df58-ebc5-4e6d-afd8-d551afe8ad4e
spec:
endpoints:
- path: /metrics
port: web
namespaceSelector:
matchNames:
- monitor
selector: # 要監控的 Endpoints 必須帶有以下標籤。
matchLabels:
app: kube-prometheus-stack-alertmanager
release: prometheus
self-monitor: "true"
4.3 alertmanagers.monitoring.coreos.com
Alertmanager 自定義資源(CRD)宣告在 Kubernetes 叢集中執行的 Alertmanager 的期望設定。它也提供了設定副本集和持久化儲存的選項。Alertmanager自定義資源在Kubernetes中以StatefulSet執行由Operator建立和Operator同一namespace。Alertmanager Pod 都會掛載一個名為 的 Secret,該Secret是 Alertmanager 的相關設定,Operator 根據相關設定會實時更新相關Secret。一個樣例設定如下:
apiVersion: monitoring.coreos.com/v1
kind: Alertmanager #自定義資源
metadata:
annotations:
meta.helm.sh/release-name: prometheus
meta.helm.sh/release-namespace: monitor
creationTimestamp: "2021-04-19T08:12:34Z"
generation: 2
labels:
app: kube-prometheus-stack-alertmanager
app.kubernetes.io/managed-by: Helm
chart: kube-prometheus-stack-14.9.0
heritage: Helm
release: prometheus
name: prometheus-kube-prometheus-alertmanager
namespace: monitor
resourceVersion: "57305495"
selfLink: /apis/monitoring.coreos.com/v1/namespaces/monitor/alertmanagers/prometheus-kube-prometheus-alertmanager
uid: aa997233-0341-413f-adde-45746e43ccdc
spec:
alertmanagerConfigNamespaceSelector: {}
alertmanagerConfigSelector: {}
externalUrl: http://alertmanager-dev.rencaiyoujia.cn/
image: quay.io/prometheus/alertmanager:v0.21.0
listenLocal: false
logFormat: logfmt
logLevel: info
paused: false
portName: web
replicas: 1
retention: 120h
routePrefix: /
securityContext:
fsGroup: 2000
runAsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-kube-prometheus-alertmanager
version: v0.21.0
4.4 prometheusrules.monitoring.coreos.com
PrometheusRule CRD 能夠定義了一組所需的 Prometheus 警報或記錄規則。Alerts 和 recording rules 可以儲存並應用為 yaml 檔案,可以被動態載入而不需要重啟。
一個樣例設定如下:
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule #自定義資源
metadata:
labels: ## 必須帶有以下標籤才能被prometheus 選擇到,在prometheus 自定義資源中設定。
app: kube-prometheus-stack
release: prometheus
name: disk-free-rules
namespace: monitor
spec:
groups:
- name: disk
rules: # 定義了一組報警規則,
- alert: diskFree
annotations:
summary: "{{ $labels.job }} 專案範例 {{ $labels.instance }} 磁碟使用率大於 80%"
description: "{{ $labels.instance }} {{ $labels.mountpoint }} 磁碟使用率大於80% (當前的值: {{ $value }}%),請及時處理"
expr: |
(1-(node_filesystem_free_bytes{fstype=~"ext4|xfs",mountpoint!="/boot"} / node_filesystem_size_bytes{fstype=~"ext4|xfs",mountpoint!="/boot"}) )*100 > 85
for: 3m
labels:
level: disaster
severity: warning
4.5 其他CRD資源
以上介紹了比較常用的4個Prometheus Operator CRD資源,下面簡要說下Prometheus Operator提供的另外4個CRD資源。
PodMonitor: Prometheus Operator 通過PodMonitor和ServiceMonitor實現對資源的監控,PodMonitor用於對 Pod 進行監控,推薦首選ServiceMonitor.PodMonitor宣告性地指定了應該如何監視一組 pod。Operator 根據 API 伺服器中物件的當前狀態自動生成 Prometheus 刮擦設定。Probe: 它宣告性地指定了應該如何監視 ingress 或靜態目標組。Operator 根據定義自動生成 Prometheus 刮擦設定。AlertmanagerConfig: 用於管理 AlertManager 組態檔,主要是告警發給誰;它宣告性地指定 Alertmanager 設定的子部分,允許將警報路由到自定義接收器,並設定禁止規則。ThanosRuler: 它定義了 ThanosRuler 期望的部署;如果有多個 Prometheus 範例,則通過ThanosRuler進行告警規則的統一管理。
5、Prometheus Operator 優點
Prometheus Operator 中所有的 API 物件都是 CRD 中定義好的 Schema,API Server會校驗。當開發者使用 ConfigMap 儲存設定沒有任何校驗,組態檔寫錯時,自表現為功能不可用,問題排查複雜。在 Prometheus Operator 中,所有在 Prometheus 物件、ServiceMonitor 物件、PrometheusRule 物件中的設定都是有 Schema 校驗的,校驗失敗 apply 直接出錯,這就大大降低了設定異常的風險。
Prometheus Operator 藉助 K8S 將 Prometheus 服務平臺化。有了 Prometheus、Thanos Ruler、AlertManager 這樣的CRD資源物件,非常簡單、快速的可以在 K8S 叢集中建立和管理 Prometheus 服務、Thanos Ruler 服務和 AlertManager 服務,以應對不同業務部門,不同領域的監控需求。
ServiceMonitor 和 PrometheusRule 解決了 Prometheus 設定難維護問題,開發者不再需要通過 CI 和 k8s ConfigMap 等手段把組態檔更新到 Pod 內再觸發 webhook 熱更新,只需要修改這兩個物件資源就可以了。
6、總結
Prometheus Operator是一組自定義的CRD資源以及Controller的實現,Prometheus Operator負責監聽這些自定義資源的變化,並且根據這些資源的定義自動化的完成Prometheus範例和相關的監控元件的自動化管理工作。
容器雲平臺通過使用Prometheus Operator簡化在Kubernetes下部署和管理Prmetheus的複雜度,其通過prometheuses.monitoring.coreos.com資源宣告式建立和管理Prometheus Server範例;其通過servicemonitors.monitoring.coreos.com和podmonitors.monitoring.coreos.com資源宣告式的管理監控設定;其通過prometheusrules.monitoring.coreos.com資源進行規則記錄,實現對複雜查詢的 PromQL 語句的效能優化,提高查詢效率。
注意:容器雲平臺使用的是自研的告警系統,並未接入Alertmanager,因此並沒有使用Prometheus Operator提供的告警通知相關的CRD資源宣告式的管理告警通知設定。
參考:https://github.com/prometheus-operator/prometheus-operator
參考:kube-prometheus 監控kubernetes叢集
參考:Prometheus-operator 介紹和設定解析