AIGC時代:未來已來
摘要:人工智慧的快速發展使得我們進入了AIGC時代。AIGC時代的到來,將會帶來巨大的機遇和挑戰。
本文分享自華為雲社群《GPT-4釋出,AIGC時代的多模態還能走多遠?系列之一: AIGC時代:未來已來》,作者: ModelArts 開發 。
人工智慧的快速發展使得我們進入了AIGC時代,即人工智慧與圖形計算相結合的時代。在這個時代,人們可以利用雲端計算、巨量資料分析等技術來處理和呈現多模態資訊。例如,AI系統可以通過語音和影象識別技術對多媒體檔案進行分析,從而實現智慧的分類、檢索和推薦。此外,隨著5G和物聯網技術的不斷髮展,多模態資訊的處理和應用將會越來越普及。AIGC時代的到來,將會帶來巨大的機遇和挑戰。
01 AIGC時代:萬物皆可AI生成
AIGC是一種可以廣泛應用於文字、影象、音訊和視訊生成的人工智慧技術。在文字生成方面,它可以運用多種演演算法進行創作,例如Jasper、copy.Ai、ChatGPT、Bard和GTP4等。在影象生成領域,它可以使用技術如EditGAN、Deepfake、DALL-E和Stable Diffusion等,創造出各種令人驚歎的圖片。對於音訊生成,AIGC也擁有許多強大的工具,如DeepMusic、WaveNet、Deep Voice和MusicAutoBot等,可以生成高質量的音樂和聲音效果。最後,對於視訊生成,AIGC同樣可以提供很多資源,比如Deepfake、VideoGPT、GliaCloud和ImageVideo等,能夠製作出專業級別的視覺效果和動畫。總之,AIGC在多個領域都有著廣泛的應用前景,並且將會繼續不斷地發展和完善。
(以上圖來自網路)
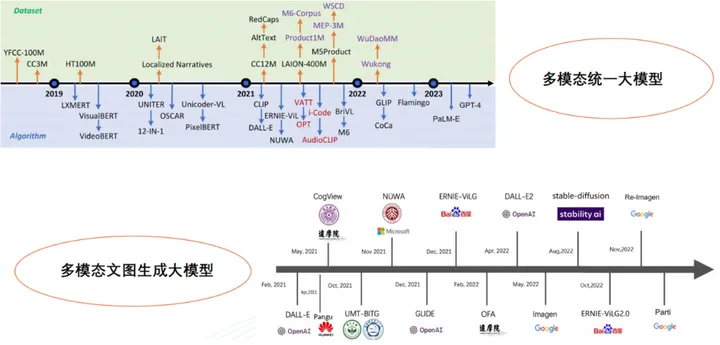
02 多模態大模型的分類與發展脈絡
在單模態模型階段(2012年前),深度學習技術沒有普及,研究人員主要關注單一型別的資料處理,例如影象分類模型AlexNet等。
緊接著進入單模態模型融合階段(2012-2018年),隨著深度學習技術的不斷髮展和應用場景的多樣化,研究人員開始嘗試將多個單模態模型進行融合,實現不同資料型別之間的交叉學習和融合,例如HT100M、LXMERT、VisualBERT、videoBERT等模型。
目前已經處於多模態統一大模型階段(2018年至今),研究人員開始提出採用單個模型處理多個資料型別的方法,這類模型通常包含多種輸入和輸出方式,需要大量的計算資源和資料支援,已經取得良好的效果。例如UNITER模型,它是一個基於Transformer結構的多模態統一大模型,能夠同時處理文字、圖片和視訊等資料型別。它在內部使用了跨模態交叉注意力機制來實現不同資料型別之間的互動,從而使得整個模型能夠更好地理解多種資料的語意資訊,並取得了領先的效能。
(以上圖來自網路)
03 文圖生成AIGC-變得精緻,可控
近年來,隨著人工智慧技術的不斷髮展,文圖生成技術也得到了顯著的進步。今天的文圖生成模型不僅能夠生成逼真高清的影象,還能夠實現更精緻的效果,並具備可控性。 在實現更精緻的效果上,研究人員針對傳統GAN模型存在的缺陷,提出了許多改進方法,如Pix2PixHD、SPADE等。這些模型能夠增強模型輸出的細節表現力,生成更加真實、精細的影象。 在提高模型的可控性上,研究人員引入了條件影象生成的思想。通過給定不同的條件資訊,包括語意標籤、風格向量等,可以使模型生成更多樣化、個性化的影象。例如,BigGAN、StyleGAN2等模型就能夠根據不同的條件生成各種風格迥異的影象。除此之外,研究人員還提出了interpolated GAN和controllable GAN等模型,使得使用者可以通過插值等方式來精細控制生成影象的各個細節。 總之,文圖生成技術在逼真高清的影象生成上取得了巨大的成功,在精細度和可控性方面也有了很大提高,這些技術的不斷進步將為我們帶來更加優秀、多樣化的文圖生成應用。

(以上圖來自網路)
然而,文圖生成AIGC的出現使得畫風變得更加逼真高清,更有風格和意境。文圖生成是利用人工智慧技術根據輸入的文字生成影象。在文圖生成的研究中,逼真高清、融合多種風格和意境的影象生成是重要的研究方向。其中,高清作畫模型如Google Imagen,能夠實現高解析度、逼真的影象生成;而意境繪畫模型如StableDiffusion,則注重於將多種風格和意境進行融合,生成更加個性化、有深度的影象。這些模型的應用場景非常廣泛,如藝術創作、平面設計等領域。

(以上圖來自網路)
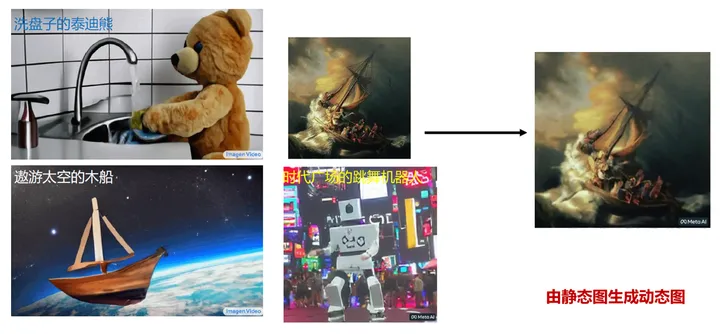
04 視訊生成AIGC – 自然流暢、栩栩如生
視訊生成AIGC(Artificial Intelligence Generated Content)技術正越來越成熟,能夠使得生成的視訊像真實一樣自然流暢、栩栩如生。 視訊生成AIGC技術所用的演演算法和模型也得到了不斷的優化和改進。新型的神經網路演演算法、光學與物理學建模等技術被引入到視訊生成AIGC中,使得生成的視訊更加逼真。 視訊生成AIGC的研究重點在於如何捕捉到影片的場景、運動和情緒,以此生成自然流暢的視訊。為此,研究人員將深度學習演演算法應用於視訊生成,使得機器可以從大量的視訊資料中學習各種動作和情感,從而產生栩栩如生的視訊。此外,生成的視訊不僅要接近真實,還要做到自然流暢。研究人員還提出了許多技術手段,比如光流分析、雙向迴圈生成模型等,能夠在不同場景下實現平滑過渡,從而使得視訊更加自然流暢。 視訊生成AIGC技術的發展使得我們可以生成更加逼真、自然流暢的視訊,應用場景非常廣泛,如影視製作、遊戲開發等領域。未來,視訊生成AIGC將會進一步推進技術的發展和創新,給我們帶來更多的驚喜和新體驗。
(以上圖來自網路)
05 多模態AIGC大模型驅動的具身智慧
多模態AIGC大模型驅動的具身智慧是一種人工智慧技術,它可以將感測器訊號和文字輸入結合起來,建立語言和感知的連結,從而操控機器人完成任務規劃和物品操作。谷歌推出的5620億引數PaLM-E就是其中的代表。 這種技術的應用場景也很廣泛,如智慧家居、無人駕駛和工業自動化等領域。通過大模型驅動的具身智慧,機器人可以更加智慧地感知周圍環境,並根據文字輸入來規劃相應的行動,實現人機協同。 PaLM-E模型採用了先進的多模態AIGC技術,它可以結合影象、聲音、觸覺等多個感測器訊號來進行深度學習,並從中提取出關鍵特徵。同時,PaLM-E還能夠將文字輸入轉換為語意表示,與感知資訊相結合進行綜合判斷和決策。這種技術的發展使得機器人可以更加智慧地感知和理解周圍環境,進而實現精準的任務執行和物品操作。 PaLM-E進一步驗證了「智慧湧現」在多模感知和具身智慧上的效果。
(以上視訊來自論文《Google’s PaLM-E is a generalist robot brain that takes commands》)
06 GPT-4 的釋出,標誌著 AIGC 邁入了多模態融合的新紀元
GPT-4的模型取得了重大突破,它擁有強大的影象識別能力,處理長達 2.5 萬字的文字輸入,讓回答準確性大幅提升,以及能夠生成歌詞、富有創意的文字,可以實現風格的多樣化。
GPT-4 作為一個強大的多模態模型,能夠接受影象和文字輸入,並輸出準確的文字回答。實驗證明,GPT-4 在各種專業測試和學術基準上的表現堪比人類水平。舉個例子,在模擬律師考試中,GPT-4 能夠取得前 10% 的成績,而 GPT-3.5 則稍顯遜色,只能排在倒數 10%。GPT-4 的新功能允許使用者指定視覺或語言任務,並以純文字設定並行處理文字和影象形式的 prompt。具體而言,當輸入包含文字和影象時,GPT-4 能生成相應的文字輸出,如自然語言、程式碼等。在許多領域,包括帶有文字和照片的檔案、圖表或螢幕截圖等,GPT-4 都展現出了與純文字輸入類似的功能。此外,它還可以利用為純文字語言模型開發的測試時間技術進行增強,如少樣本和思維鏈 prompt。GPT-4是世界第一款強有力的AI系統,會掀起一場新的工業革命,帶來新的社會分工,創造新的應用場景,全面提升人類的智慧化水平。

(以上圖來自網路)
07 Is the AI GAME OVER?
在Rich Sutton著名文章《苦澀的教訓》中,他提出了一個引人深思的觀點,即唯一導致AI進步的是更多的資料、更有效的計算。這一觀點得到了DeepMind研究主任Nando de Freitas的支援,他甚至宣稱AI現在完全取決於規模,AI領域更難的挑戰已經解決了,大模型已經(暫時)戰勝了精心設計的知識工程。這一觀點也得到了實際應用的證明,大量的資料和更強大的計算能力確實對AI技術的發展起著關鍵作用。 然而,我們也不能因此認為AI的發展已經結束了。如今,雖然大模型已經建立了基礎,但真正的挑戰仍然在於如何將其應用到實際場景中。例如,在自動駕駛領域,需要考慮不同的天氣條件、不同的交通狀況等複雜情況,這些都需要AI技術在實際應用中不斷實現迭代和優化。 此外,AI在推理、判斷和創造等方面仍面臨許多挑戰,實現真正的智慧仍然需要突破。因此,雖然大模型已經取得了重大進展,但AI的發展之路仍然任重而道遠。
GPT-4釋出,AIGC時代的多模態還能走多遠?我將釋出四個系列,還會探討AIGC的阿克琉斯之踵, 多模態認知智慧和AIGC for MMKG,敬請期待!