遊戲AI——GOAP技術要點
什麼是GOAP(Goal-Oriented Action Planning)
在遊戲中設計敵人的AI一直是很大的一塊需求,在需求的最開始,我們可能就是寫了一堆的if分支,然後通過一系列方法各種讀取環境的資訊,根據環境的資訊做反應,或者是是給AI一個相對固定、迴圈的模式。
後來大家注意到AI的行為大量耦合在一起不便於快速開發迭代,便誕生了狀態機,分割了所有的狀態,後來又對狀態機通過transition的狀態間相互耦合感到不滿意,於是誕生了複用一系列transition條件的行為樹,其實也可以稱為樹形狀態機。
但是這些AI的特點都很明顯,他們都是讀取環境資訊,然後根據資訊找到分支然後找到執行的行為,屬於 應激式AI。
在2003年,Jeff Orkin 釋出的論文 Applying Goal-Oriented Action Planning to Games,他給我們闡述了一種基於目標的規劃行為的 慎思型AI。
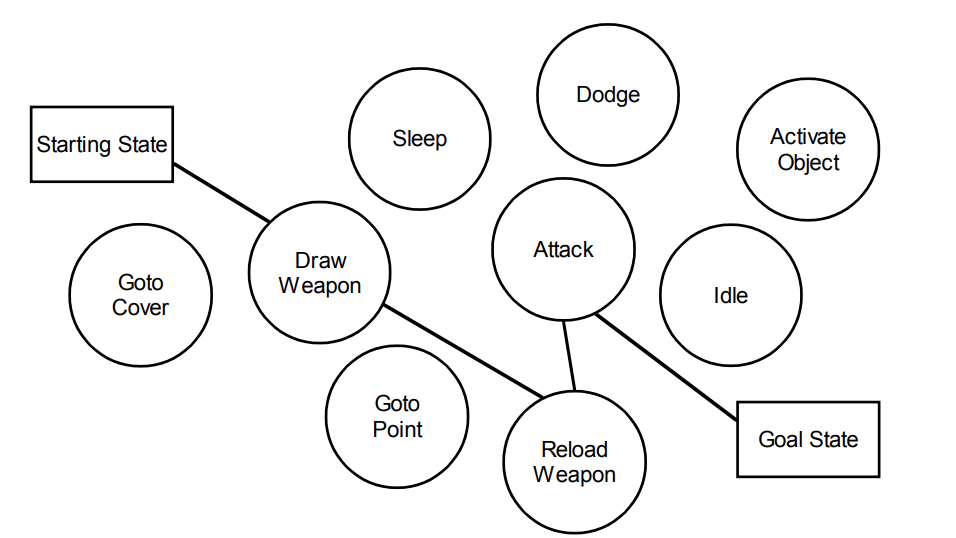
- 反應型AI(Reactive AI) :先接受刺激輸入,然後執行對應行為
- 慎思型AI(Deliberative AI):將環境和背景條件納入決策考量,可以勝任複雜決策
這個方案下的AI會制定自己的計劃以滿足他的目標,AI角色將會表現出較少重複的、可預測的行為,並且可以調整他的行為以適應他當前的情況。
這個方案的好處就是令狀態機的狀態們完全解耦,便於設計師在面臨超大複雜度AI的設計中處理太多狀態間的關係問題,也可以採用一些分模組、分等級的思路來更好的管理AI。
如果想要NPC對特定輸入進行特定反應,那麼可能GOAP並不適合,因為決策、規劃需要時間。狀態機和行為樹在這點需求上比GOAP更合適,但是如果想要了各種互動和湧現式體驗,那麼GOAP是一個不錯的選擇。
細節
An agent uses a planner to formulate a sequence of actions that will satisfy some goal.
解釋一下GOAP中基礎的概念:
- Goal:一個目標,一個世界狀態資料,純粹的資料,各個goal之間有優先順序
- Action:一個改變世界狀態資料的行為
- Precondition:執行這個行為的條件,也是世界狀態資料
- Effect:執行成功後對世界狀態資料的影響
- Plan:為了達到目標制定的一系列Action列表
同一時刻,只有一個目標啟動,控制著玩家行為。
GOAP 中的Goal不包括Plan,也沒有寫死某個Goal的處理流程,他的Goal只是定義了資料,滿足條件的過程是通過規劃器實時決定的。Plan就是為了達到Goal State而規劃出的Action list。
Action是一個獨立的原子的Step,會讓角色做某件事,去某個點、和xx互動、攻擊。action有長有短,有的依賴於動畫是否播完,每個action都有一定的條件和影響。
有時候我們對一扇門可以 輕輕推開、也可以用力把它砸開,我們應該有一個外部的機制決定對門行為的前置條件。
而一些Memory、Sensor,這些其實是規劃器之外的都可以理解為給規劃器的資料來源。

因為goap把目標定義成了數學結構,是定量的表達的,然後就得到一個基於完成目標的規劃問題,給所有的action都定義cost,Plan其實就是一個在圖裡找最短路徑的問題。
原文中作者推薦了使用A* 的啟發式搜尋,goap中走的一個反向的規劃,起點是Goal的世界狀態,終點是當前狀態,一定要規劃到終點,以終為始的規劃方法。
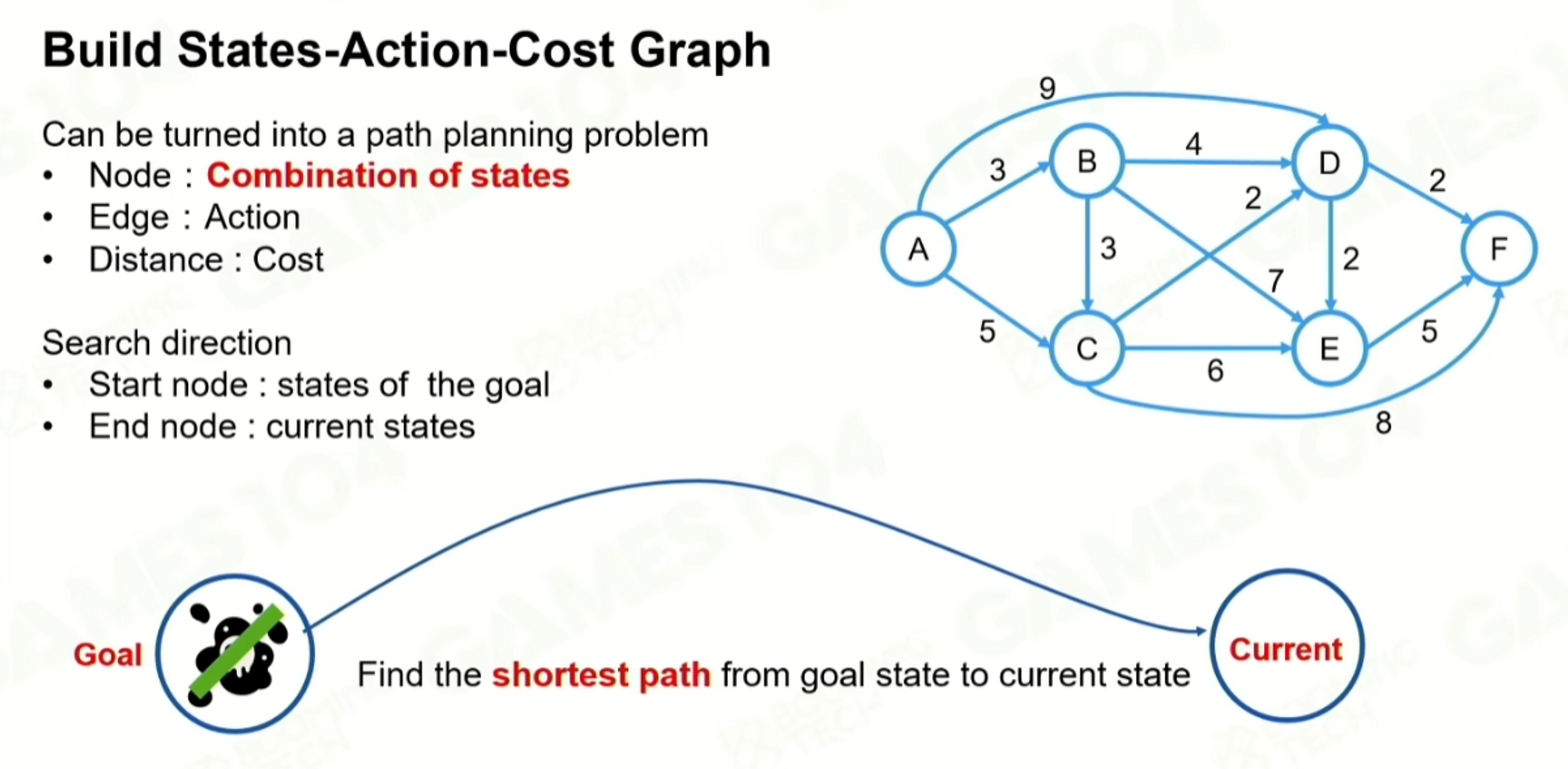
根據cost得到最小cost路徑,但是實際上不一定是最短的方式,人定義的cost,cost最小也不一定是最快抵達的路徑,cost通常會加上一些修改係數,給一些動態執行的action去有改變cost大小的能力。
難點與挑戰
這part我們主要分析了gdc2015 goap十年、gdc2021 育碧goap的關鍵內容。順帶一提,2023年SE在GDC上也有GOAP的分享,相信很快他們的研究也會放出 。
goap十年中主要包含 《中土世界:摩多之影》、《古墓麗影》,育碧則是從奧德賽之後,大的AI架構往GOAP遷移。
世界表達
我們需要的世界狀態並不是簡單指的遊戲的地圖環境,而是指所有可用於決策規劃的資訊,可以理解為智慧體的所能感覺到的東西。
世界表示 比如使用一個世界屬性的陣列,世界屬性包括 鍵值對,鍵可以是列舉,這個世界屬性有時候還要標記出屬於哪個object。

以這種狀態表示的世界是一個超大的、不切實際的任務,我們其實只需要表示可以規劃的最小的世界屬性集合就行了,隔離雜亂的干擾屬性是規劃的關鍵,因為狀態數量越多,每個狀態加入有true或者false,n個屬性總共的狀態數量就是2^n的尋路的節點數量。
這樣如果我們要支援一個高度複雜的AI的話要定義世界的資訊就非常多,所有的資料都放在一層規劃就會效率很低,並且很多資料不好量化,實現上也要注意效能。
具體型別表示
舉個例子,在Regoap(一個Unity GOAP) 開源庫裡,他的state表達就是一個字典,裡面就是string to object的一個pair。這個object裡面可以放vector、bool、等任意型別。可以隨時往字典裡插入新的state。其實他就沒有控制複雜度,並且這個值型別轉object有裝箱開銷,並且他後面直接呼叫的Object.Equal來判斷狀態是否滿足,其他子型別都重寫了這個Equal方法並且使用了RTTI,效率較低。
育碧在這裡其實把世界狀態表述的和行為樹的黑板一樣,在編輯器下可以設定字串到具體型別的表,規劃器可以從黑板裡讀取資料然後進行規劃,遊戲中其他的元件單位和邏輯則可能改寫黑板的資料。
字串表示
在作者2004年的文章有提到關於世界狀態的內容,他覺得可以使用類似術語的方式來定義行為,說白了就是使用字串,然後用字串進行比對,將規劃中所有會出現的內容全部定義為字串,而很多語言其實在處理字串的時候有編譯期優化,編譯期確定的相同字串的內容會指向同一個地址,這樣比對速度會快很多。其實這種模式就有點像人類的符號學,用符號指代一個東西,通過符號來判斷非常快速,目前來說我比較看好這種方案。
這種方案的一個問題在於,要想比較的快速,就要依賴編譯期優化,意味著所有的字串都不好定義在程式碼檔案外部,其實可以通過外部檔案生成程式碼的方式來解決,最後會得到string to string的一個pair。同時這種方案對於執行時的資料(比如一個隨時變化的位置點)就不是很好處理,要動態生成字串 ,這種方案其實適合放在頂層,value比較固定的情況,做複雜AI最上層的策略判斷。
bool轉化為列舉
這是Middle-earth™: Shadow of Mordor™的一個優化方法,他們注意到有大量的bool變數,通過合併一些bool變數成列舉的方式降低狀態數量級,降低了節點數量就減少了A* 尋路的負擔

規劃器
Regoap流程
在前面我們已經聊到過規劃器,這裡簡單說一下Unity ReGoap的規劃器和智慧體執行流程,借煙雨一圖。
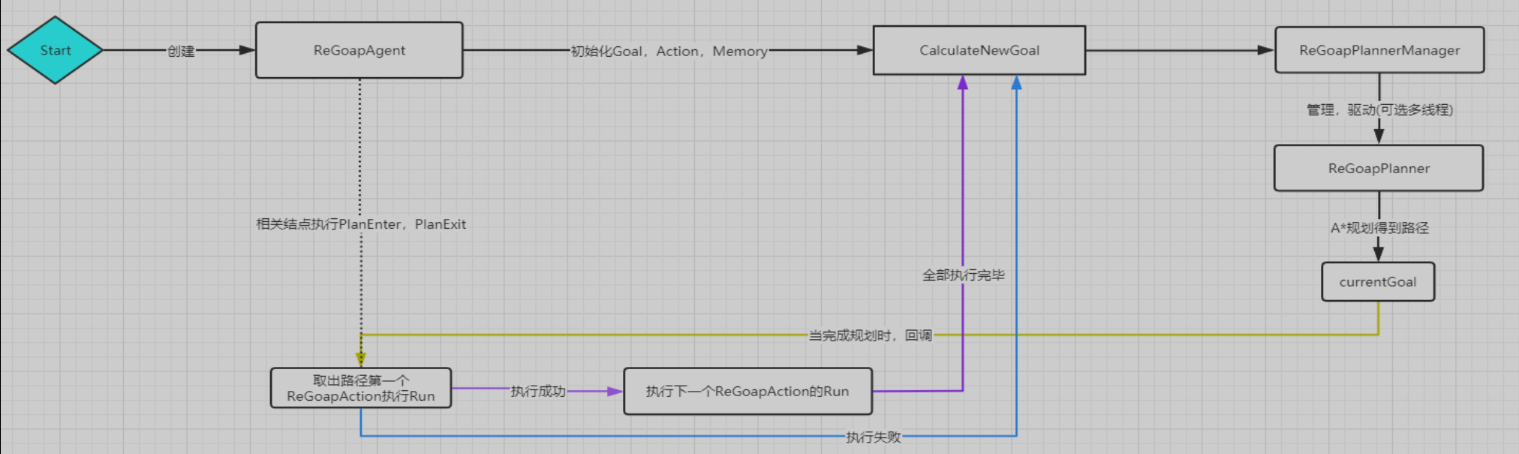
Agent就是負責控制AI邏輯的載體,Awake時候所有的Action、Goal、Memory元件都彙總到agent身上工作。
Start開始,CalculateNewGoal會從可行的Goal列表裡選一個優先順序最高的出來,如果在plannnig則不選擇。
Plan開始,起點是Goal的滿足,終點是 當前的entity狀態。根據State資料建立A* 尋路使用的節點,第一個節點是NoAction的,我們將其加入優先佇列,然後進入迴圈,直到優先佇列為空、尋路演演算法迭代次數過多、達到了目標節點就停止迴圈。
每次迴圈首先將優先佇列裡第一個節點彈出,也就是cost最低的state Node,第一次就是彈出Goal的StateNode。
然後尋找一個可能的鄰居節點,這時候他遍歷了所有的Action,然後檢查Action是否滿足:
- 1、action有effect可以達到goal需要的State
- 2、Action沒有precondition和goal衝突,假如有precondition有衝突同時effect又可以修復衝突,那麼也可以當做鄰居
- 3、沒有effect和goal衝突
- 4、程式上允許你這麼幹,程式碼執行的可行性檢測
都滿足則這個Action可以作為當前State的鄰居,生成鄰居Node的時候同時得到鄰居node的cost值。
在節點圖裡搜尋需要定義cost,
cost = g + h
g是plan到此經過的action的的cost,h是尚未滿足的狀態數量,可以乘一個係數,ReGoap經常會出現g很大,h較小的情況。
如果h的係數為0,則全為g,A* 退化成dijkstra演演算法,如果h很大,g很小,A* 則更傾向於貪婪演演算法。
初始化鄰居Node的時候要將當前的Node的Goal State更新,因為每個鄰居node其實都代表了 一路採用了什麼Action才到達目前的State的過程,一個ActionEffect會滿足之前的Goal的State,於是我們Effect滿足的Goal State刪除,然後將Action的Precondition和這個Goal State合併,就得到了新的Goal State。
把所有的鄰居遍歷一遍,然後,我們需要檢查當前這個state在之前的迭代中是否出現過,相同的State的cost可能會存在不同,我們需要取最小cost的node,要將之前的高cost node給刪掉,把這個小cost node扔進優先佇列作為替代。
最後我們plan會得到一個玩家起始狀態一樣的Node,若沒有得到,則說明規劃失敗了。
規劃成功了就會得到一個Plan,就是Action陣列,就讓我們的智慧體去執行這一系列Action。
在ReGoap裡作者提供了許多單元測試,可以方便的測試作者的規劃程式碼,感興趣的讀者也可以試試。
Middle-earth™: Shadow of Mordor™的系統分層
Middle-earth™: Shadow of Mordor™也談到了有關優化器的其他優化方法,因為資料量越大節點越多規劃器的負擔越重。
第一個做法就是分層,分層的目的是要儘量將Plan的路徑變短。
他們將很多的邏輯從Planner系統中移除,Planner不會做每件事,他只會做高層的規劃,剩下的交給其他底層系統來執行負擔。

比如他們做了LowLevelSystem

比如在已經在播某個動畫,武器可能會自動收起來,equip unequip系統,把很多的Action簡化到了LowLevelSystem裡,做成自動動作。其實有點像大腦和小腦的關係。
可能攻擊方案會做成一個單獨的LowLevel系統、移動方案會做成一個單獨LowLevelSystgem、動畫選擇也會做成LowLevelSystem。
他們還做了一些MiddleLevel,稱為planner driving system 就是用來影響規劃器的system

本來你可能有一個Goal——吃著火鍋唱著歌要開開心心去上任縣長了,但是突然身邊有一個人被殺了,你的情緒就變得很恐懼、很緊張,然後你的Goal就變成了 活下去,開始小心翼翼探查周邊的情況。
然後這些planner driving system,還可以在團隊之間給各個小隊成員們傳遞資訊,像一個群體系統,同時這個系統可能包含Sensor,給Planner提供資料來源。
然後是HighLevelSystem,這塊個人理解較多,說的不好建議去看原視訊,

以調查為例,比如一個獸人,發現隊友倒了,感到不對,然後開始調查的Plan,
我們希望一個小隊的獸人是各有各的反應的,但是把這些東西全部加到planner裡又會增加planner的複雜度,我們的做法是讓獸人把觀察到的資訊上報到highlevelsystem,highlevelsystem,他會有一個角色系統,plan完之後會給小隊裡獸人分配角色,不同角色有不同的interest,也會有不同的反應。
可能有的角色不做規劃而只是跟著那幾個做了規劃的角色行動,這也是一個優化點,快取複用別人規劃過的流程。
古墓麗影2013的Motive系統
古墓麗影給goap system加入了一些針對gameplay需求的改變,個人理解這都是為了更加自由、方便設計而做出的改變,其實他的Planning在整體的地位就感覺明顯不如前面的遊戲。

一個經驗:plan一個cost不高的action可能會因為各種runtime下情況而變得開銷很高
比如這裡range attack 11比melee attack 21要cost低,拿著範圍武器的時候才可以讓AI執行範圍攻擊。
其實他可以把這些邏輯放進Goap規劃的,但是為了減少節點數量可以將這些固定的邏輯抽出來,所以有時候也會使用這種在外部的條件來影響規劃器。比如這裡對range attack施加硬性攻擊約束就是有必要的,這時候在外部可能就會寫一些hard code的邏輯可能讓他在某些case下更傾向於做什麼。
他們做了一套motive系統,一言以蔽之就是他們想在外部有修改動態規劃流程的能力,和之前的planner driving system很像,不過他們多做到了Action的資料根據情況改變而改變。
Action的Cost可能會因為一些case而變化。
Action的Precondition也可能跟著實際的情況變化而變化,個人理解這都是方便設計而做的東西。
Action之間甚至可以有父子關係,父Action完成了子Action的cost可能會受到影響,某些action可能會觸發plan system的重新plan,但其實這裡已經和之前GOAP的設計思路分開了,原本的版本可能各個Action越獨立越好,但有時有依賴也不錯達成設計目的會方便。
古墓麗影的goap還會追蹤Goal、action成功率會用來影響Plan的規劃。
分享者指出了開發中兩個常問的問題:
- 當前Plan的細節
- 到底是怎麼觸發的plan
- Action什麼時候執行的
- 需要Plan的每一步的計算流程
- 每一部分的完成情況
- 為什麼 NPC 現在不做點別的事
- 主要講的是NPC的閒置問題
工具
渡神紀針對GOAP開發了完善的Debug工具,分享者在這裡提到了兩種工具
規劃管理器(Planner Monitor)
規劃管理器會輸出每次規劃評估的所有分支的Log,包括各種最終選擇執行的規劃,以及其他評估的規劃分支,以及更詳細的各個行動條件的滿足情況以及成本等。
古墓麗影也有生成的Behavior Graph,個人感覺這種視覺化的圖更好。
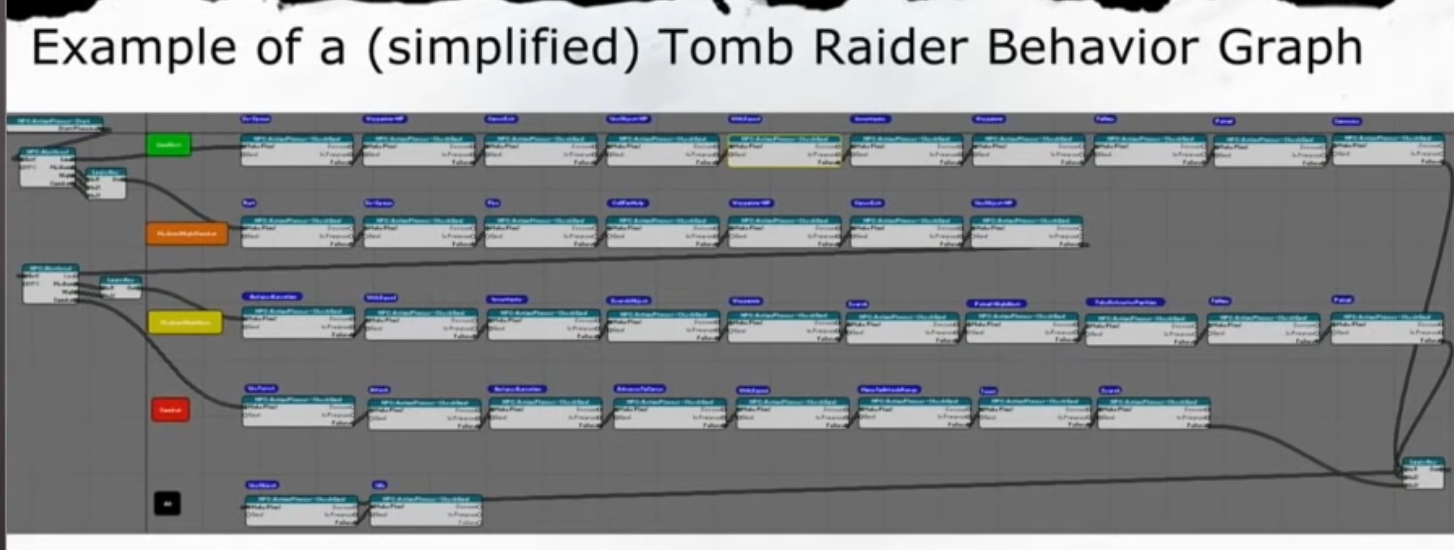
包括用於規劃的可用目標(Available Goals)、可用行動(Available Actions),以及事先被過濾掉的行動(Discarded Actions),包括這些行動是哪個條件不滿足才被過濾掉的。
GOAP自動化統計模組
此工具是一個執行模式,可以記錄下各種條件在GOAP規劃中的情況(成功、失敗、被選入最終規劃),輔助設計的功用,可以方便的進行剖析。

這裡會記錄哪些行動從來沒有被選取過,從而方便開發者瞭解是不是某些條件過於嚴格,或者是行動本身不合理,或者是資料存在錯誤。分享者指出,最終他們會優化到沒有任何一個行動是從未被選取過的。

思考
我們需要解決很多問題,包括:
1、高效的世界表達
2、分層減少規劃器的負擔
3、行為模組化利於維護
4、更加自由的設計方法
5、完善的Debug工具
6、解決AI反應慢的問題
7、要給智慧體足夠多的選擇,並且每個選擇有各自不同的意義
GOAP因為需要規劃,所以反應相對慢,可能通過一些LowLevelSystem可以解決部分問題。
我們可以通過替換planner的方式來實現不同風格的AI,可能AI不一定能規劃到終點,規劃器可能不一定使用反向規劃法,使用正向規劃也不錯,從當前狀態出發,就算沒有規劃到目標,AI也要可能也要先動起來,可能這樣會更加有複雜的人的感覺,但是這樣也可能帶來一些永遠完不成目標的情況,關於複雜 像人 好不好,還是看需求想要什麼樣的。
GOAP這個結構其實可以理解為一種思想,通過指定一些規劃的規則 來生成一些包含許多變化的結果,但是這個變化又具備一定的可控制性。這個結構我與人討論,設想中感覺用來做一些基於目的的故事生成感覺也可行,相當有意思的結構。
相關資料
【GDC挖了它!】刺客信條奧德賽和渡神紀的AI行為規劃
目標導向的AI系統(Goal Oriented Action Planning)技術分享
GOAP總站
ReGoap
2023.3.30