一個有效的圖表影象資料提取框架
一、簡要介紹

在本文中,作者通過採用最先進的計算機視覺技術,在資料探勘系統的資料提取階段,填補了研究的空白。如圖1所示,該階段包含兩個子任務,即繪製元素檢測和資料轉換。為了建立一個魯棒的Box detector,作者綜合比較了不同的基於深度學習的方法,並找到了一種合適的高精度的邊框檢測方法。為了建立魯棒point detector,採用了帶有特徵融合模組的全折積網路,與傳統方法相比,可以區分近點。該系統可以有效地處理各種圖表資料,而不需要做出啟發式的假設。在資料轉換方面,作者將檢測到的元素轉換為具有語意值的資料。提出了一種網路來測量圖例匹配階段圖例和檢測元素之間的特徵相似性。此外,作者還提供了一個關於從資訊圖表中獲取原始表格的baseline,並行現了一些關鍵的因素來提高各個階段的效能。實驗結果證明了該系統的有效性。
二、研究背景
圖表資料是一種重要的資訊傳輸媒介,它能簡潔地分類和整合困難資訊。近年來,越來越多的圖表影象出現在多媒體、科學論文和商業報告中。因此,從圖表影象中自動提取資料的問題已經引起了大量的研究關注。
如圖1所示,圖表資料探勘系統一般包括以下六個階段:圖表分類、文字檢測和識別、文字角色分類、軸分析、圖例分析和資料提取。在上述所有階段中,資料提取是最關鍵、最困難的部分,其效能取決於定位的質量。在本工作中,作者主要討論了資料提取階段。本階段的目標是檢測地塊區域中的元素,並將它們轉換為具有語意的資料標記。

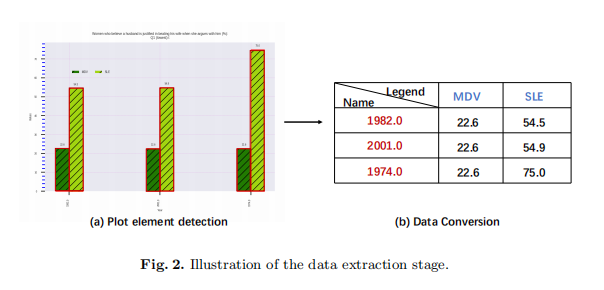
如圖2所示,該任務有兩個子任務:繪圖元素檢測和資料轉換
作者從目標檢測領域學習方法,建立了一個魯棒的資料提取系統。然而,應該清楚的是,圖表影象與自然影象有明顯的不同。如圖3所示,(a)是來自COCO資料集的影象,(b)是來自合成圖表資料集的影象。首先,與一般物件相比,圖表影象中的元素具有很大範圍的長寬比和大小。圖表影象包含了不同元素的組合。這些元素可以是非常短的,比如數位點,也可以是長的,比如標題。其次,圖表影象對定位精度高度敏感。雖然在0.5到0.7範圍內的IoU值對於一般的目標檢測是可接受的,但對於圖表影象則是不可接受的。如圖3b所示,即使當IoU為0.9時,在條形影象上仍有較小的數值偏差,這顯示了圖表影象對IoU的敏感性。因此,對於圖表資料的提取,檢測系統需要高精度的邊框或點,即具有較高的IoU值。
因此,對於圖表資料的提取,檢測系統需要高精度的邊界邊框或點,即具有較高的IoU值。

目前,最先進的計算機視覺技術還沒有被圖表挖掘方法完全採用。此外,使用基於深度學習的方法進行圖表挖掘的比較也很少。人們認為,基於深度學習的方法可以避免硬啟發式假設,並且在處理各種真實圖表資料時更穩健。在本研究中,作者使用已發表的真實資料集,試圖填補資料提取階段的這一研究空白。在所提出的框架中,首先檢測到主區域中的元素。基於資料探勘系統中前幾個階段的軸分析和圖例分析結果,作者將檢測到的元素轉換為具有語意值的資料標記。這項工作的貢獻可以總結如下。(i)為了構建一個魯棒的Box detector,作者綜合比較了不同的基於深度學習的方法。作者主要研究現有的目標檢測方法是否適用於條型元素檢測。特別是,它們應該能夠(1)檢測具有較大長寬比範圍的元素,並能夠(2)定位具有較高IoU值的物件。(ii)為了構建一個魯棒的point detector,作者使用一個帶有特徵融合模組的全折積網路(FCN)來輸出一個熱圖掩模。它能很好地區分近點,而傳統的方法和基於檢測的方法很容易失敗。(iii)在資料轉換的圖例匹配階段,一個網路被訓練來測量特徵相似性。當特徵提取階段存在噪聲時,它比基於影象的特徵具有魯棒性。最後,作者提供了一個公共資料集的baseline,這可以促進進一步的研究。
三、方法介紹
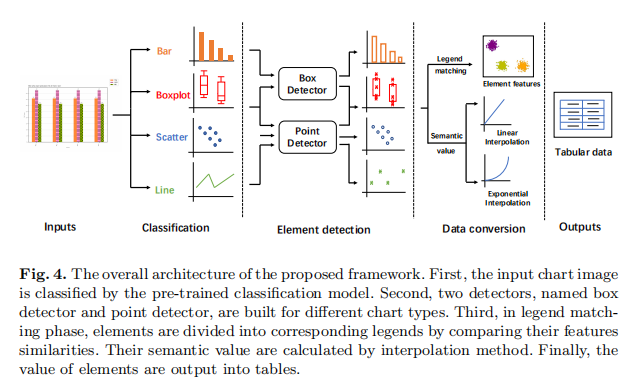
作者所提出的方法的總體架構如圖4所示。在功能上,該框架由三個組成部分組成:一個預先訓練好的圖表分類模型,用於檢測邊框或點的元素檢測模組,以及用於確定元素值的資料轉換。在下面的部分中,作者首先介紹box detector和point detector的細節。接下來,作者將提供資料轉換的實現細節。
3.1 Box detector
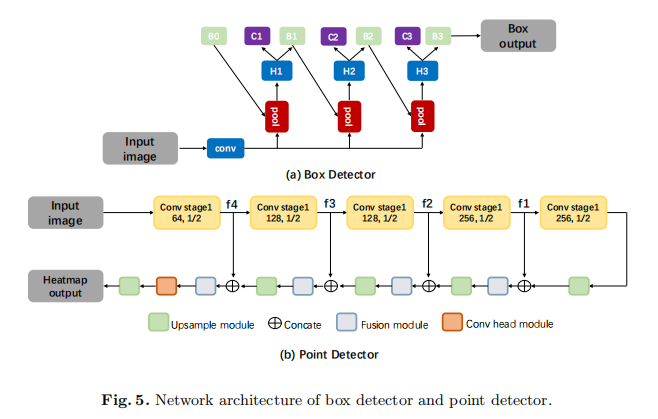
為了提取不同尺度上的魯棒特徵,作者使用了帶有FPN的ResNet-50 。FPN使用帶有橫向連線的自頂向下體系結構,以融合來自單一尺度輸入的不同解析度的特性,使其能夠檢測具有大高寬比範圍的元素。為了檢測具有高IoU的邊框,作者選擇CascadeR-CNN作為作者的box detector。如圖5(a)所示,box detector有四個階段,一個區域候選網路(RPN),三個用於檢測。第一個檢測階段的取樣遵循Faster R-CNN。在接下來的階段中,通過簡單地使用上one-stage的迴歸輸出來實現重新取樣。
3.2 Point detector
點是圖表資料中的另一個常見的圖表元素。如前所述,相應的圖表型別包括散點、線和麵。一般來下,點密集分佈在地塊區域,資料以(x,y)的格式表示。在這項工作中,作者使用基於分割的方法來檢測點,這可以幫助區分近點。
網路結構
如圖5(b)所示,從主幹網路中提取了四級的特徵圖,記為,其大小分別為輸入影象的1/16、1/8、1/4和1/2。然後,在上取樣階段,對來自不同深度的特徵進行融合。在每個合併階段中,來自最後一個階段的特徵對映首先被輸入到上取樣模組,使其大小增加一倍,然後與當前的特徵對映連線起來。接下來,使用由兩個連續的層構建的融合模組,生成這個合併階段的最終輸出。在最後一個合併階段之後,然後使用由兩個層構建的頭模組。最後,將特徵圖上取樣到原圖大小。
標籤生成
為了訓練FCN網路,作者生成了一個熱圖掩模。二進位制對映將輪廓內的所有畫素設定為相同的值,但不能反映每個畫素之間的關係。與二值分割圖相比,作者為掩模上的這些點繪製高斯熱圖。利用高斯核函數計算了高斯值。如果兩個高斯分佈重疊,而一個點有兩個值,作者使用最大值。
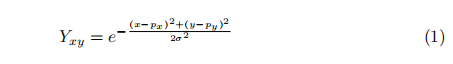
其中(x、y)是掩模上的點座標,(、)是目標點的中心。σ是一個決定大小的高斯核引數。在這裡,作者將σ的值設為2。
後處理
在測試階段,Point detector輸出一個熱圖掩模。作者首先過濾主繪圖區域外的輸出噪聲。然後,作者使用一個高置信度閾值來輸出正區域。通過尋找連線分量的中心,得到最終的點輸出。在連通分量分析過程中,對於較大的連通區域,作者也隨機選擇該區域內的點作為輸出。
3.3 資料變換

在檢測到元素之後,作者需要確定元素的值。在這個階段,目標是將繪圖區域中檢測到的元素轉換為具有語意值的資料標記。如圖6所示,本階段進行了圖例匹配和值計算。
圖例匹配:
根據在資料探勘系統中從第五階段得到的圖例分析結果,作者可以得到圖例的位置。如果存在圖例,作者需要提取元素和圖例的特徵。然後利用l2距離來度量特徵的相似性,並將元素劃分為相應的圖例。基於影象的特徵,如RGB特徵和HSV特徵,在檢測結果不夠緊密時不魯棒。因此,作者提出訓練一個特徵模型來度量特徵相似性。
該網路直接從patch輸入影象x學習對映到嵌入向量。它由多個模組組成,使用conv-BN-ReLU層構建,最後為每個patch輸入輸出一個128d的嵌入向量。在訓練階段,網路使用三倍的損失進行優化。這種損失的目的是通過一個距離邊際將正對和負對分開。同一叢集的嵌入向量應該距離較小,不同的叢集應該距離較大。在測試階段,將裁剪後的圖例修補程式和元素修補程式輸入到模型中。對於每個元素,在特徵維度上距離最小的圖例是對應的類。
數值計算:
根據第四階段得到的軸分析結果,作者可以得到檢測到的勾選點的位置及其對應的語意值。然後,作者分析了相鄰勾選點之間的數值關係,包括線性或指數的情況。最後,作者計算了單位尺度的值,並使用插值方法來確定元素的值。
四、實驗
4.1資料集
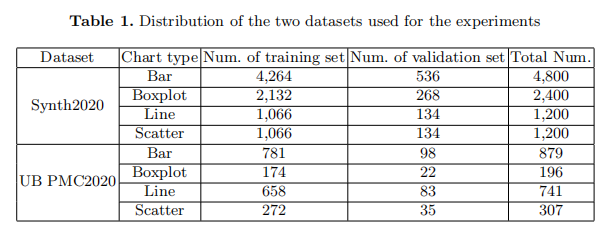
本研究中使用了兩組資料集,分別為Synth2020和UB PMC2020。第一個資料集Synth2020,是Synth2019的擴充套件版本。使用Matplotlib庫建立了多個不同型別的圖表。第二個資料集是來自PubMedCentral的科學出版物中的真實圖表,它具有不同的影象解析度和更多的影象不確定性。作者將ICPR2020官方訓練資料集隨機分為訓練集和驗證集。表1給出了這兩個資料集分割的詳細資訊。
4.2設定細節
在Box detector實驗中,作者選擇條形資料進行訓練。主特徵提取器是在ImageNet上預先訓練過的ResNet-50。在迴歸階段,作者採用RoIAlign抽樣候選到7x7的固定大小。batch size為8,初始學習率設定為0.01。採用隨機梯度下降(SGD)對模型進行優化,訓練的最大週期為20。在推理階段,利用非最大抑制(NMS)來抑制冗餘輸出。
在point detector實驗中,作者選擇散點型資料進行訓練。在訓練階段,作者使用MSE損失來優化網路。採用多種資料增強,包括隨機裁剪、隨機旋轉、隨機翻轉和影象失真,以避免過擬合。作者採用OHEM 策略來學習困難樣本。正樣本和負樣本的比例為1:3。使用Adam優化器對模型進行優化,最大迭代次數為30k,batch size為4。
在資料轉換實驗中,作者訓練模型提取特徵進行聚類。訓練的輸入大小為24x24,嵌入維數設定為128。採用Adam優化器對模型進行優化,最大迭代次數為50k。batch size為8,初始學習率設定為0.001。
4.3結果分析
Box detector的評估:
當IoU的值分別設定為0.5、0.7、0.9時,用Score_a和f-measure來評估Box detector的效能。Score_a使用ICPR2020競賽的評價機制。訓練後的模型分別在Synth2020驗證集和UB PMC2020測試集上進行了測試。由於Synth2020的測試集目前不可用,所以作者使用驗證集來測試Synth2020資料集上的模型效能。
為了進行比較,作者實現了不同的檢測模型,包括one-stage和two-stage的檢測模型。one-stage模型是SSD 和YOLO-v3而two-stage模型是Faster R-CNN。如表2所示,one-stage模型的效能表現最差,多級迴歸磁頭有助於獲得較高的精度。此外,附加的FPN接面構有效地有助於檢測具有較大高寬比範圍的元素。在Synth2020和UB PMC2020資料集上,具有FPN接面構的Cascade R-CNN模型表現最好。因此,對於條形資料檢測,具有多元迴歸頭和FPN接面構的模型取得了令人印象深刻的效能。
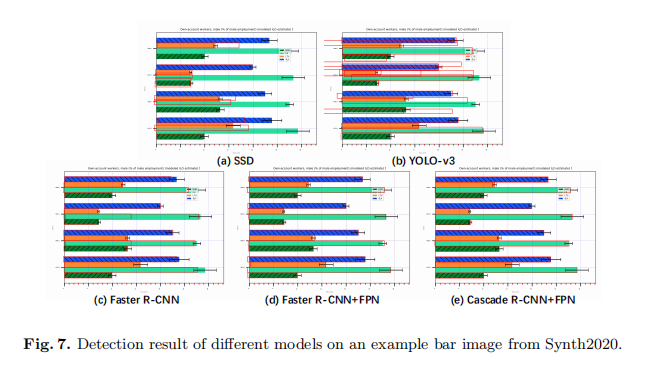
One-stage模型在早期的迭代中輸出了糟糕的結果。同時,NMS不能有效地過濾這些誤差輸出,如圖7(b).所示NMS不能抑制這些輸出,因為這些長矩形之間的離子值單位小於0.5由於這些原因,該模型不能達到全域性最優解。

Point detector的評估:
在本節中,將根據競賽中釋出的評價機制來評估point detector的效能。訓練後的模型在Synth2020驗證、UB PMC2020驗證和測試集上進行了測試。
作者將作者的方法與傳統的影象處理方法,如連線元件分析和基於檢測的方法。該檢測模型是基於faster R-CNN。為了訓練faster R-CNN模型,作者將點(x,y)擴充套件為一個矩形(x −r,y −r,x+r,y +r),其資料格式為(left,top,right,bottom)。作者還實現了另一種基於分割的方法Pose ResNet,該方法最初被提出用於pose point檢測。Pose ResNet模型採用了下取樣和上取樣的結構,沒有考慮不同深度的特徵融合。
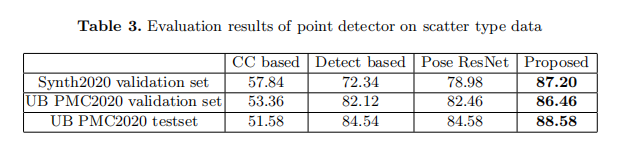
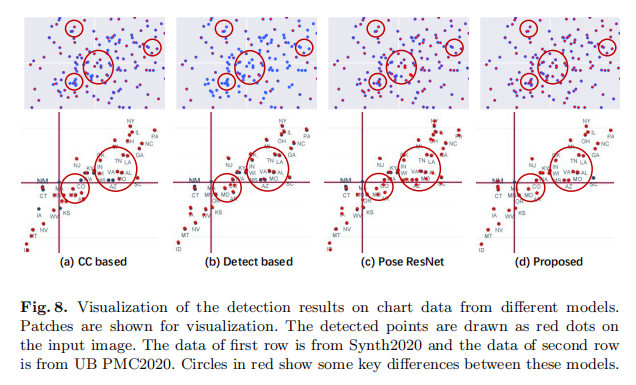
如表3所示,該方法簡單而有效,在三個測試集上都優於其他方法。如圖8所示,在Synth2020驗證集上,有許多情況下,散點被連線並形成一個更大的連線分量。在UB PMC2020測試集上,在情節區域有許多噪聲,如文字元素。傳統的影象處理方法不能區分構成較大分量的近點。當點數較大或相鄰點連線時,基於檢測的方法失敗。與Pose ResNet相比,特徵融合方法有助於區分相鄰點,如圖8(d).所示該方法能有效地處理這些情況,並準確地定位相鄰點。
資料轉換特徵的魯棒性:
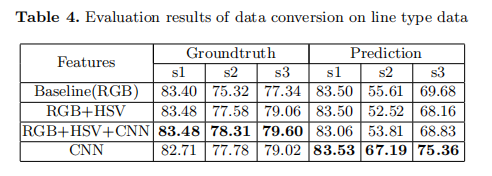
作者選擇行型資料來評估資料轉換的效能。資料轉換的效能取決於圖例匹配階段和值計算階段。值計算階段的效能取決於OCR引擎是否能正確識別勾點值。忽略了OCR引擎引起的誤差,作者討論了從訓練網路的圖例匹配階段提取的特徵的魯棒性。如表4所示,作者比較了對ground truth和預測結果進行圖例匹配階段時的效能。對於簡短的表示法,這裡的s1、s2、s3分別表示平均名稱得分、平均資料序列得分和平均得分,這在評估指令碼中宣告。
當使用ground truth作為輸入時,元素的位置是相當準確的。從訓練網路中提取的特徵與RGB和HSV特徵連線後的特徵具有可比性。通過考慮特徵的級聯,可以進一步提高效能。當使用預測檢測結果時,元素的位置可能不夠緊湊,這可能會在提取特徵時引入噪聲。實驗結果表明,該方法的特徵比基於影象的特徵更具有魯棒性。
擬建系統的評價結果:
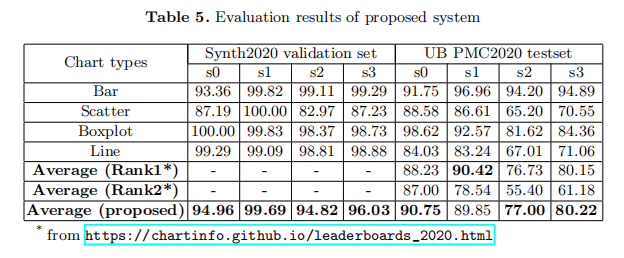
如表5所示,作者提供了作者提出的ICPR2020比賽的系統效能,這可以作為一個baseline,便於進一步的研究。對於簡短的表示法,這裡的s0、s1、s2和s3分別表示視覺元素檢測得分、平均名稱得分、平均資料序列得分和平均得分。在本工作中,沒有采用額外的資料或模型整合策略。結果表明,作者的系統在UB PMC2020測試集上的效能優於Rank1和Rank2的結果,證明了該系統的有效性。
五、總結與討論
在本工作中,作者討論了一個資料探勘系統中的資料提取階段。為了建立一個可靠的Box detector,作者比較了不同的目標檢測方法,並找到了一個合適的方法來解決表徵圖表資料的特殊問題。具有多元迴歸頭和FPN接面構的模型取得了令人印象深刻的效能。為了建立魯棒的point detector,與基於影象處理的方法和基於檢測的方法相比,該基於分割的方法可以避免困難的啟發式假設,並很好地區分近點。對於資料轉換,作者提出了一種測量特徵相似性的網路,它比基於影象的特徵更穩健。在實驗中,作者在資料提取的每個階段都進行了實驗。作者找到了提高每個階段效果的關鍵因素。在公共資料集上的整體效能證明了該系統的有效性。由於近年來出現的圖表越來越多,作者相信從圖表資料的自動提取領域將迅速發展。作者希望這項工作能夠提供有用的見解,併為比較提供一個baseline。