資料密集型應用儲存與檢索設計
本文內容翻譯自《資料密集型應用系統設計》(大名鼎鼎的 DDIA)。
高分好書
什麼是「資料密集型應用系統」?
當資料(資料量、資料複雜度、資料變化速度)是一個應用的主要挑戰,那麼可以把這個應用稱為資料密集型的。與之相對的是計算密集型——處理器速度是主要瓶頸。
其實我們平時遇到的大部分系統都是資料密集型的——應用程式碼存取記憶體、硬碟、資料庫、訊息佇列中的資料,經過業務邏輯處理,再返回給使用者。

查詢型別
Online analytical processing和Online analytical processing。
查詢型別主要分為兩大類:
|
引擎型別 |
請求數量 |
資料量 |
瓶頸 |
儲存格式 |
使用者 |
場景舉例 |
產品舉例 |
|
OLTP |
相對頻繁,側重線上交易 |
總體和單次查詢都相對較小 |
Disk Seek |
多用行存 |
比較普遍,一般應用用的比較多 |
銀行交易 |
MySQL |
|
OLAP |
相對較少,側重離線分析 |
總體和單次查詢都相對巨大 |
Disk Bandwidth |
列存逐漸流行 |
多為商業使用者 |
商業分析 |
ClickHouse |
其中,OLTP 側,常用的儲存引擎又有兩種流派:
|
流派 |
主要特點 |
基本思想 |
代表 |
|
log-structured 流 |
只允許追加,所有修改都表現為檔案的追加和檔案整體增刪 |
變隨機寫為順序寫 |
Bitcask、LevelDB、RocksDB、Cassandra、Lucene |
|
update-in-place 流 |
以頁(page)為粒度對磁碟資料進行修改 |
面向頁、查詢樹 |
B 族樹,所有主流關係型資料庫和一些非關係型資料庫 |
此外,針對 OLTP, 還探索了常見的建索引的方法,以及一種特殊的資料庫 —— 全記憶體資料庫。
對於資料倉儲,本章分析了它與 OLTP 的主要不同之處。資料倉儲主要側重於聚合查詢,需要掃描很大量的資料,此時,索引就相對不太有用。需要考慮的是儲存成本、頻寬優化等,由此引出列式儲存。
驅動資料庫的底層資料結構
本節由一個 shell 指令碼出發,到一個相當簡單但可用的儲存引擎 Bitcask,然後引出 LSM-tree,他們都屬於紀錄檔流範疇。之後轉向儲存引擎另一流派 ——B 族樹,之後對其做了簡單對比。最後探討了儲存中離不開的結構 —— 索引。
首先來看,世界上 「最簡單」 的資料庫,由兩個 Bash 函數構成:
|
1 2 3 4 5 6 7 8 |
#!/bin/bash db_set () { echo "$1,$2" >> database }
db_get () { grep "^$1," database | sed -e "s/^$1,//" | tail -n 1 } |
這兩個函數實現了一個基於字串的 KV 儲存(只支援 get/set,不支援 delete):
|
1 2 3 4 |
$ db_set 123456 '{"name":"London","attractions":["Big Ben","London Eye"]}' $ db_set 42 '{"name":"San Francisco","attractions":["Golden Gate Bridge"]}' $ db_get 42 {"name":"San Francisco","attractions":["Golden Gate Bridge"]} |
來分析下它為什麼 work,也反映了紀錄檔結構儲存的最基本原理:
- set:在檔案末尾追加一個 KV 對。
- get:匹配所有 Key,返回最後(也即最新)一條 KV 對中的 Value。
可以看出:寫很快,但是讀需要全文逐行掃描,會慢很多。典型的以讀換寫。為了加快讀,我們需要構建索引:一種允許基於某些欄位查詢的額外資料結構。
索引從原資料中構建,只為加快查詢。因此索引會耗費一定額外空間,和插入時間(每次插入要更新索引),即,重新以空間和寫換讀取。
這便是資料庫儲存引擎設計和選擇時最常見的權衡(trade off):
- 恰當的儲存格式能加快寫(紀錄檔結構),但是會讓讀取很慢;也可以加快讀(查詢樹、B 族樹),但會讓寫入較慢。
- 為了彌補讀效能,可以構建索引。但是會犧牲寫入效能和耗費額外空間。
儲存格式一般不好動,但是索引構建與否,一般交予使用者選擇。
雜湊索引
本節主要基於最基礎的 KV 索引。
依上小節的例子,所有資料順序追加到磁碟上。為了加快查詢,我們在記憶體中構建一個雜湊索引:
- Key 是查詢 Key
- Value 是 KV 條目的起始位置和
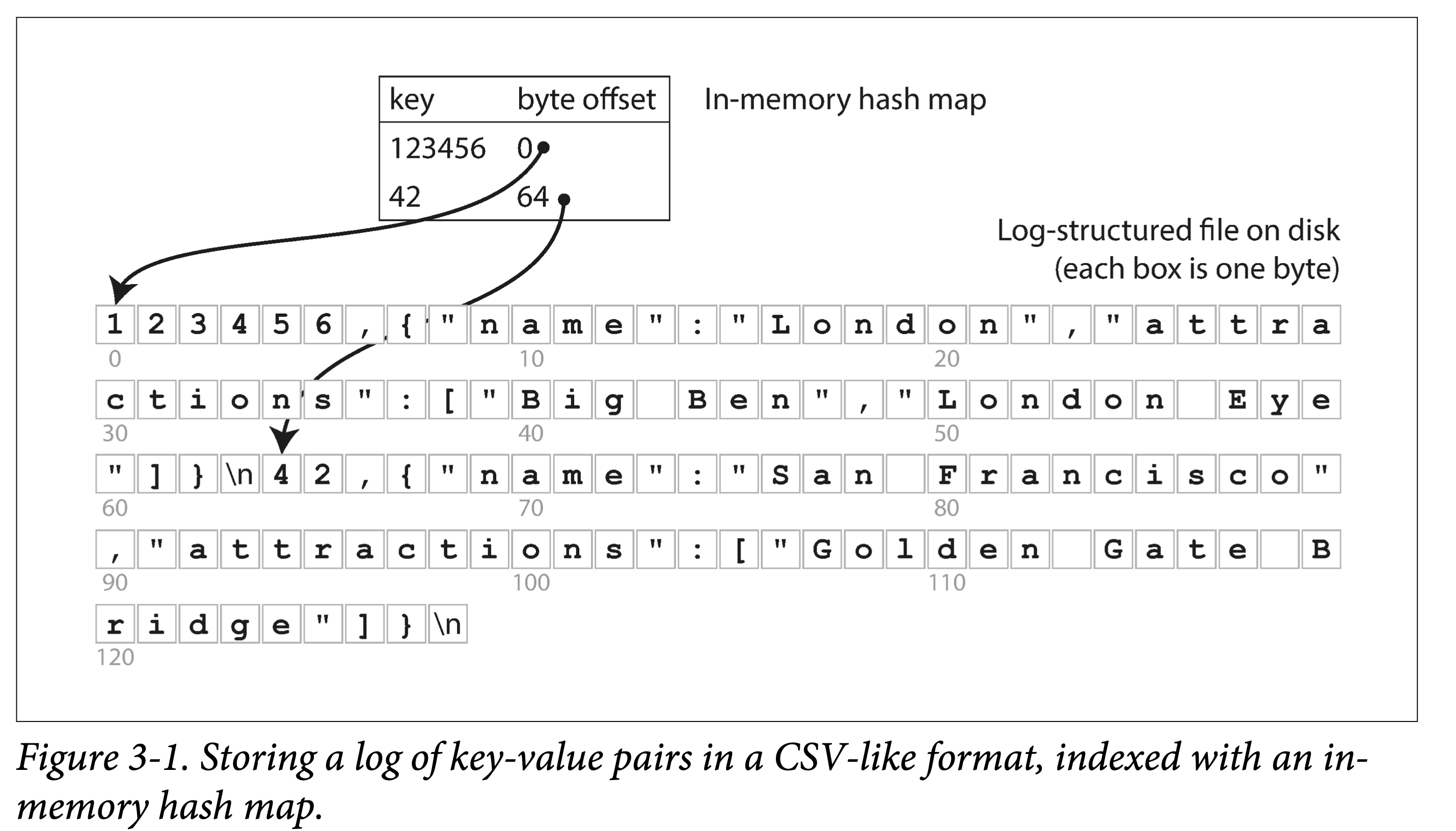
看來很簡單,但這正是 Bitcask 的基本設計,但關鍵是,他 Work(在小資料量時,即所有 key 都能存到記憶體中時):能提供很高的讀寫效能:
- 寫:檔案追加寫。
- 讀:一次記憶體查詢,一次磁碟 seek;如果資料已經被快取,則 seek 也可以省掉。
如果你的 key 集合很小(意味著能全放記憶體),但是每個 key 更新很頻繁,那麼 Bitcask 便是你的菜。舉個栗子:頻繁更新的視訊播放量,key 是視訊 url,value 是視訊播放量。
但有個很重要問題,單個檔案越來越大,磁碟空間不夠怎麼辦?
在檔案到達一定尺寸後,就新建一個檔案,將原檔案變為唯讀。同時為了回收多個 key 多次寫入的造成的空間浪費,可以將唯讀檔案進行緊縮( compact ),將舊檔案進行重寫,擠出 「水分」(被覆寫的資料)以進行垃圾回收。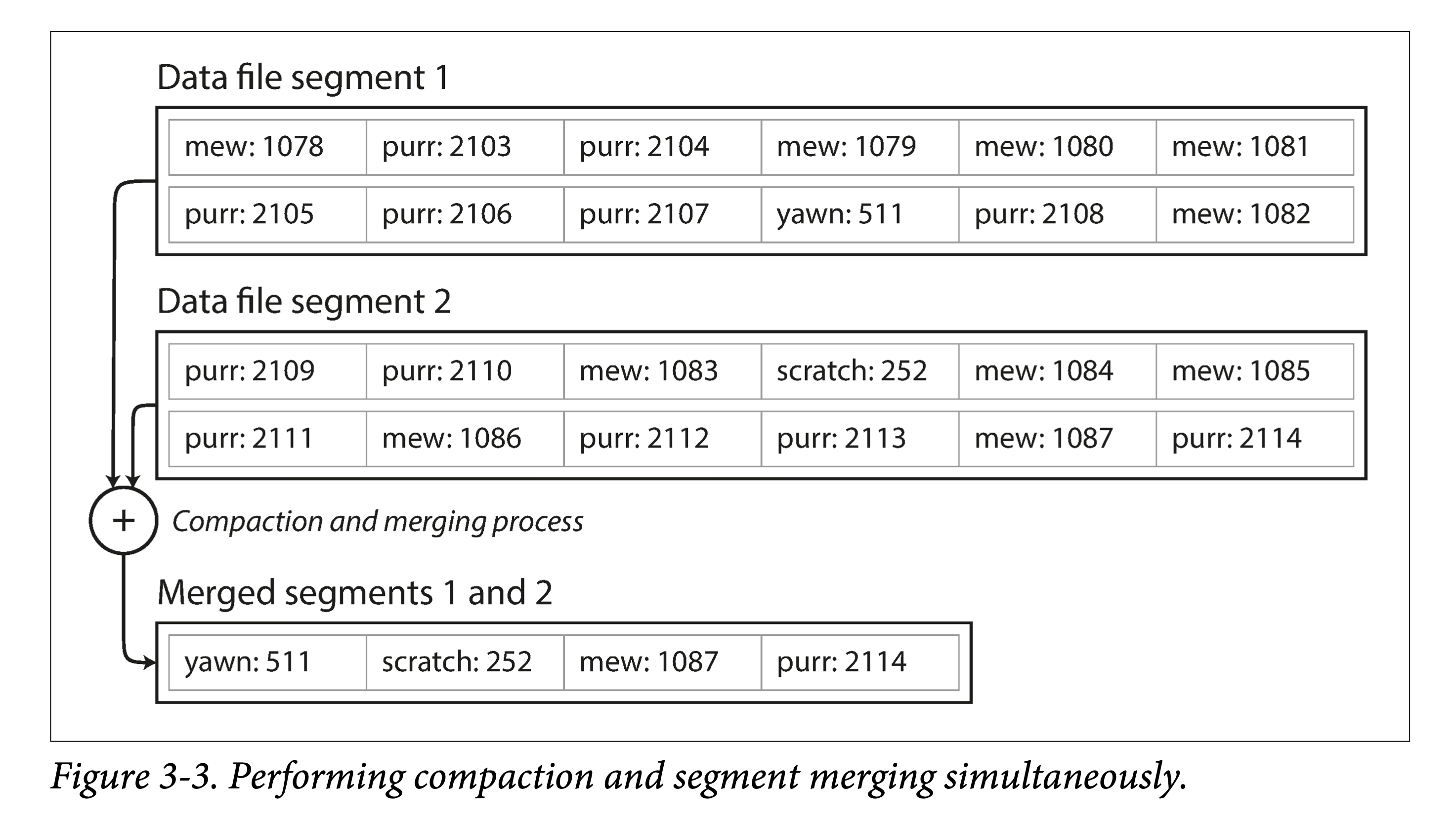
當然,如果我們想讓其工業可用,還有很多問題需要解決:
- 檔案格式。對於紀錄檔來說,CSV 不是一種緊湊的資料格式,有很多空間浪費。比如,可以用 length + record bytes 。
- 記錄刪除。之前只支援 put\get,但實際還需要支援 delete。但紀錄檔結構又不支援更新,怎麼辦呢?一般是寫一個特殊標記(比如墓碑記錄,tombstone)以表示該記錄已刪除。之後 compact 時真正刪除即可。
- 宕機恢復。在機器重啟時,記憶體中的雜湊索引將會丟失。當然,可以全盤掃描以重建,但通常一個小優化是,對於每個 segment file, 將其索引條目和資料檔案一塊持久化,重啟時只需載入索引條目即可。
- 記錄寫壞、少寫。系統任何時候都有可能宕機,由此會造成記錄寫壞、少寫。為了識別錯誤記錄,我們需要增加一些校驗欄位,以識別並跳過這種資料。為了跳過寫了部分的資料,還要用一些特殊字元來標識記錄間的邊界。
- 並行控制。由於只有一個活動(追加)檔案,因此寫只有一個天然並行度。但其他的檔案都是不可變的(compact 時會讀取然後生成新的),因此讀取和緊縮可以並行執行。
乍一看,基於紀錄檔的儲存結構存在折不少浪費:需要以追加進行更新和刪除。但紀錄檔結構有幾個原地更新結構無法做的優點:
- 以順序寫代替隨機寫。對於磁碟和 SSD,順序寫都要比隨機寫快幾個數量級。
- 簡易的並行控制。由於大部分的檔案都是不可變(immutable)的,因此更容易做並行讀取和緊縮。也不用擔心原地更新會造成新老資料交替。
- 更少的內部碎片。每次緊縮會將垃圾完全擠出。但是原地更新就會在 page 中留下一些不可用空間。
當然,基於記憶體的雜湊索引也有其侷限:
- 所有 Key 必須放記憶體。一旦 Key 的資料量超過記憶體大小,這種方案便不再 work。當然你可以設計基於磁碟的雜湊表,但那又會帶來大量的隨機寫。
- 不支援範圍查詢。由於 key 是無序的,要進行範圍查詢必須全表掃描。
後面講的 LSM-Tree 和 B+ 樹,都能部分規避上述問題。
- 想想,會如何進行規避?
SSTables 和 LSM-Trees
這一節層層遞進,步步做引,從 SSTables 格式出發,牽出 LSM-Trees 全貌。
對於 KV 資料,前面的 BitCask 儲存結構是:
- 外存上紀錄檔片段
- 記憶體中的雜湊表
其中外存上的資料是簡單追加寫而形成的,並沒有按照某個欄位有序。
假設加一個限制,讓這些檔案按 key 有序。我們稱這種格式為:SSTable(Sorted String Table)。
這種檔案格式有什麼優點呢?
高效的資料檔案合併。即有序檔案的歸併外排,順序讀,順序寫。不同檔案出現相同 Key 怎麼辦?

不需要在記憶體中儲存所有資料的索引。僅需要記錄下每個檔案界限(以區間表示:[startKey, endKey],當然實際會記錄的更細)即可。查詢某個 Key 時,去所有包含該 Key 的區間對應的檔案二分查詢即可。
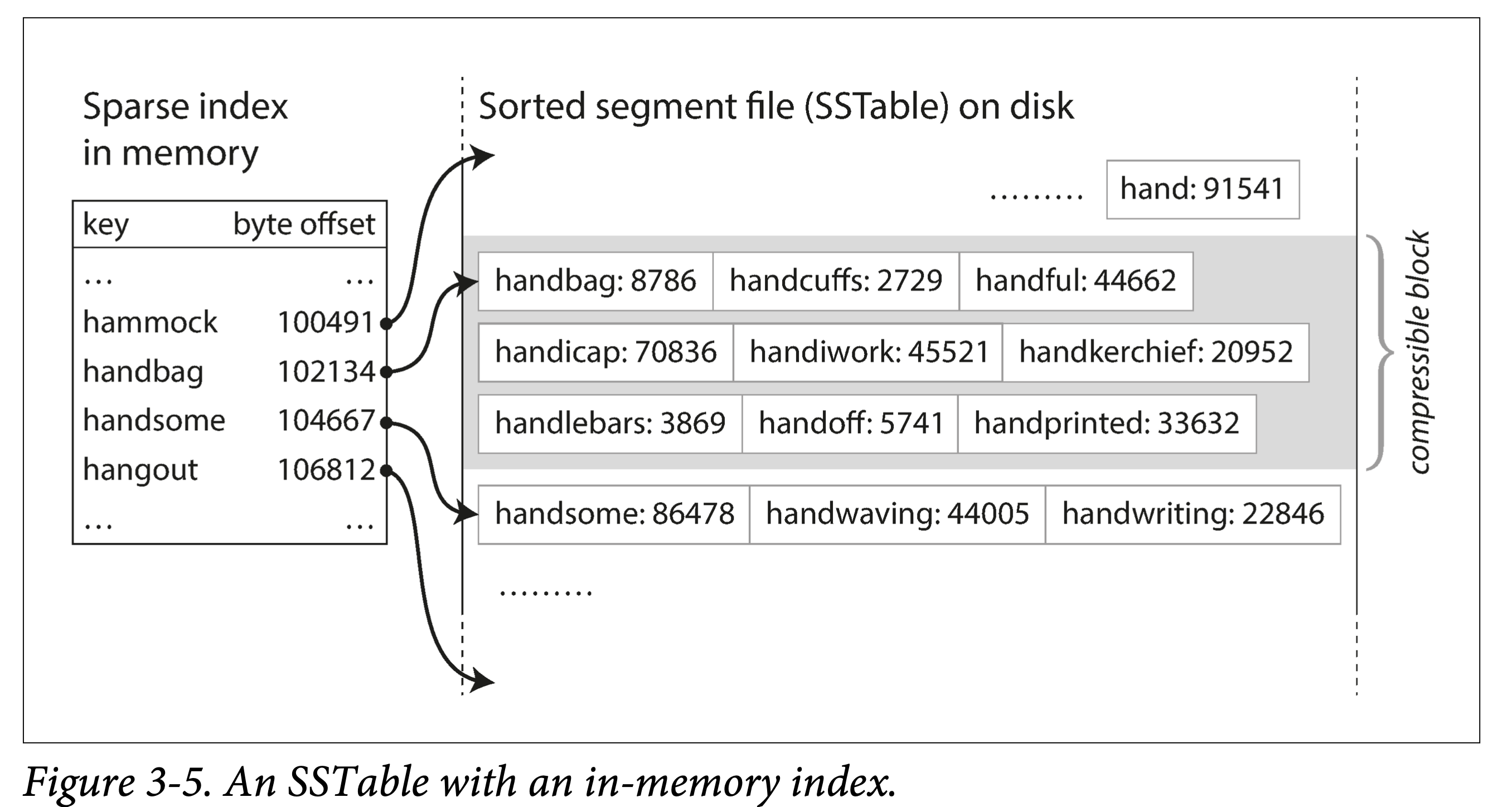
分塊壓縮,節省空間,減少 IO。相鄰 Key 共用字首,既然每次都要批次取,那正好一組 key batch 到一塊,稱為 block,且只記錄 block 的索引。
構建和維護 SSTables
SSTables 格式聽起來很美好,但須知資料是亂序的來的,我們如何得到有序的資料檔案呢?
這可以拆解為兩個小問題:
- 如何構建。
- 如何維護。
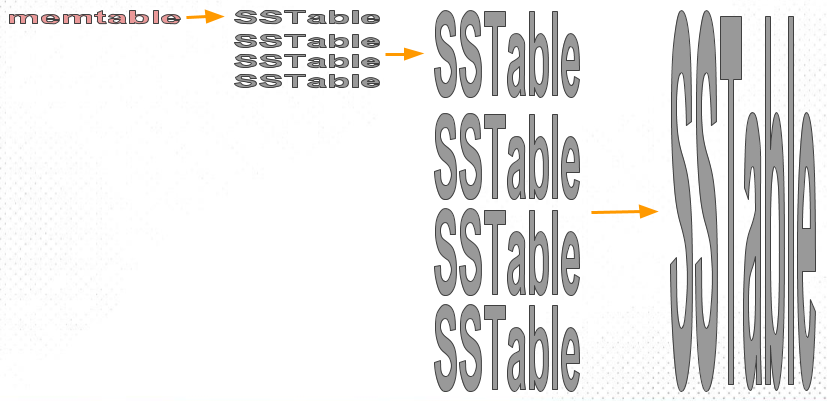
構建 SSTable 檔案。將亂序資料在外存(磁碟 or SSD)中上整理為有序檔案,是比較難的。但是在記憶體就方便的多。於是一個大膽的想法就形成了:
- 在記憶體中維護一個有序結構(稱為 MemTable)。紅黑樹、AVL 樹、條表。
- 到達一定閾值之後全量 dump 到外存。
維護 SSTable 檔案。為什麼需要維護呢?首先要問,對於上述複合結構,我們怎麼進行查詢:
- 先去 MemTable 中查詢,如果命中則返回。
- 再去 SSTable 按時間順序由新到舊逐一查詢。
如果 SSTable 檔案越來越多,則查詢代價會越來越大。因此需要將多個 SSTable 檔案合併,以減少檔案數量,同時進行 GC,我們稱之為緊縮( Compaction)。
該方案的問題:如果出現宕機,記憶體中的資料結構將會消失。 解決方法也很經典:WAL。
從 SSTables 到 LSM-Tree
將前面幾節的一些碎片有機的組織起來,便是時下流行的儲存引擎 LevelDB 和 RocksDB 後面的儲存結構:LSM-Tree:
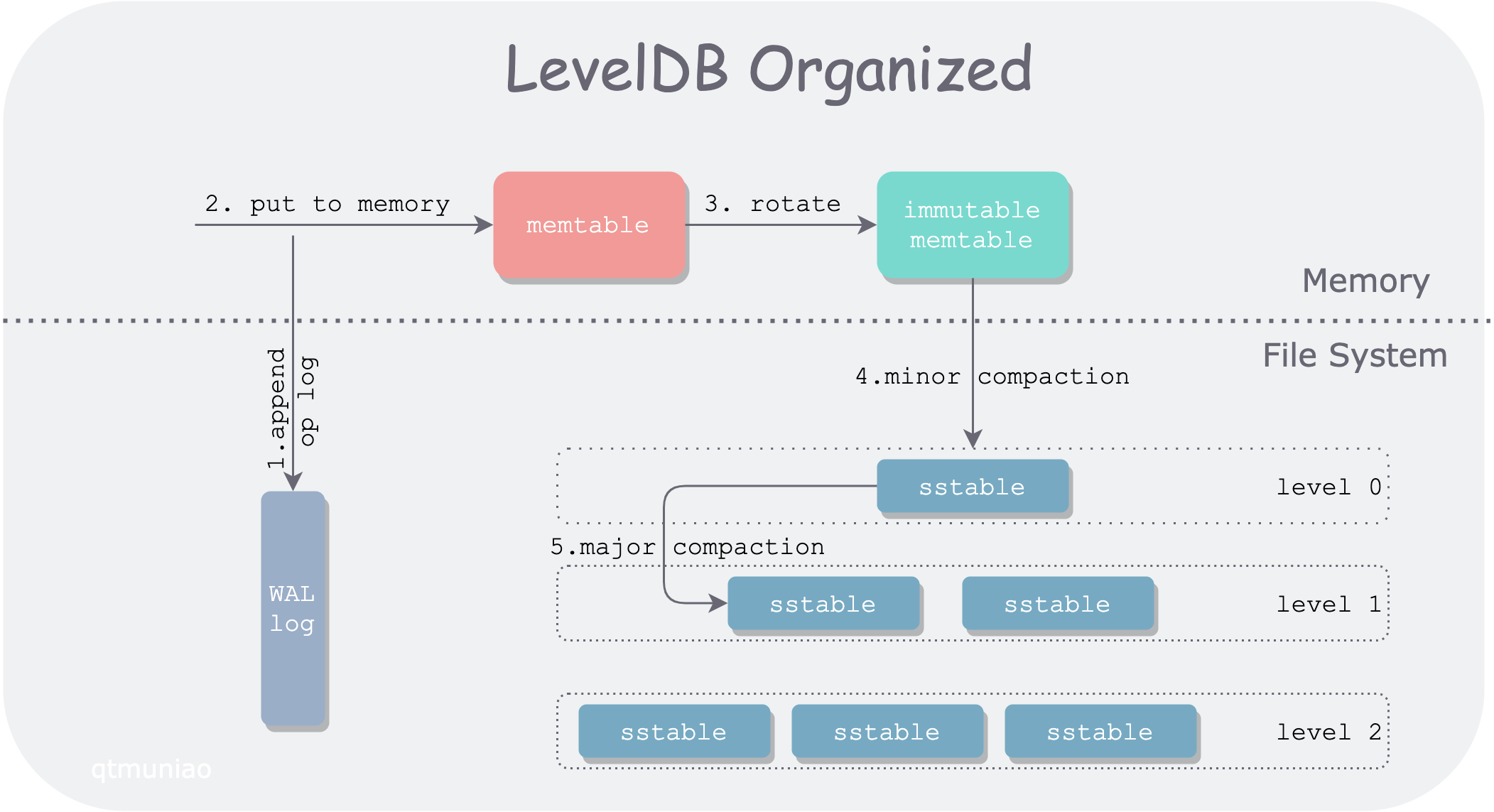
這種資料結構是 Patrick O’Neil 等人,在 1996 年提出的:The Log-Structured Merge-Tree。
Elasticsearch 和 Solr 的索引引擎 Lucene,也使用類似 LSM-Tree 儲存結構。但其資料模型不是 KV,但類似:word → document list。
效能優化
如果想讓一個引擎工程上可用,還會做大量的效能優化。對於 LSM-Tree 來說,包括:
優化 SSTable 的查詢。常用 Bloom Filter。該資料結構可以使用較少的記憶體為每個 SSTable 做一些指紋,起到一些初篩的作用。
層級化組織 SSTable。以控制 Compaction 的順序和時間。常見的有 size-tiered 和 leveled compaction。LevelDB 便是支援後者而得名。前者比較簡單粗暴,後者效能更好,也因此更為常見。
對於 RocksDB 來說,工程上的優化和使用上的優化就更多了。在其 Wiki 上隨便摘錄幾點:
- Column Family
- 字首壓縮和過濾
- 鍵值分離,BlobDB
但無論有多少變種和優化,LSM-Tree 的核心思想 —— 儲存一組合理組織、後臺合併的 SSTables —— 簡約而強大。可以方便的進行範圍遍歷,可以變大量隨機為少量順序。
B 族樹
雖然先講的 LSM-Tree,但是它要比 B+ 樹新的多。
B 樹於 1970 年被 R. Bayer and E. McCreight 提出後,便迅速流行了起來。現在幾乎所有的關係型資料中,它都是資料索引標準一般的實現。
與 LSM-Tree 一樣,它也支援高效的點查和範圍查。但卻使用了完全不同的組織方式。
其特點有:
- 以頁(在磁碟上叫 page,在記憶體中叫 block,通常為 4k)為單位進行組織。
- 頁之間以頁 ID 來進行邏輯參照,從而組織成一顆磁碟上的樹。
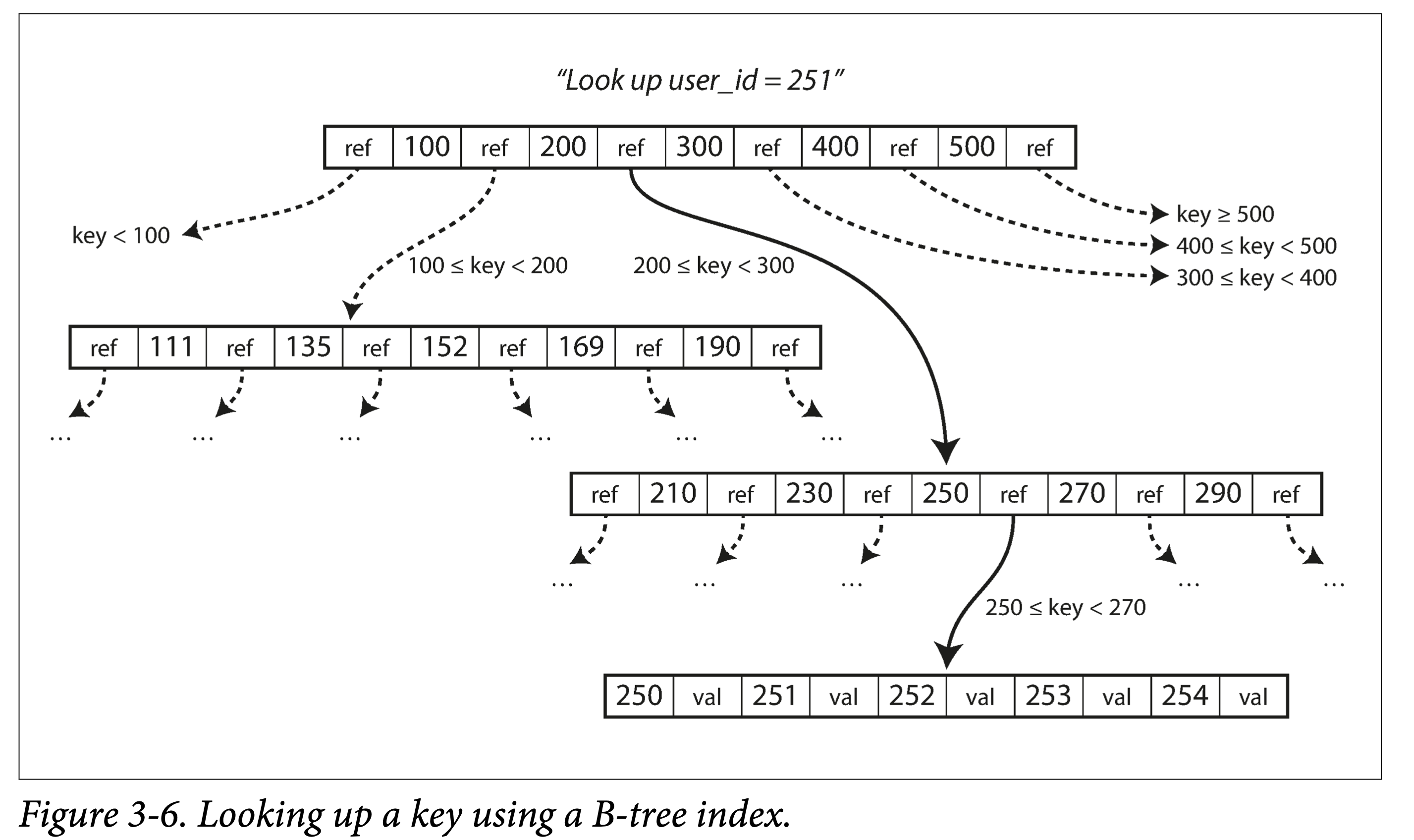
查詢。從根節點出發,進行二分查詢,然後載入新的頁到記憶體中,繼續二分,直到命中或者到葉子節點。 查詢複雜度,樹的高度 —— O (lgn),影響樹高度的因素:分支因子(分叉數,通常是幾百個)。
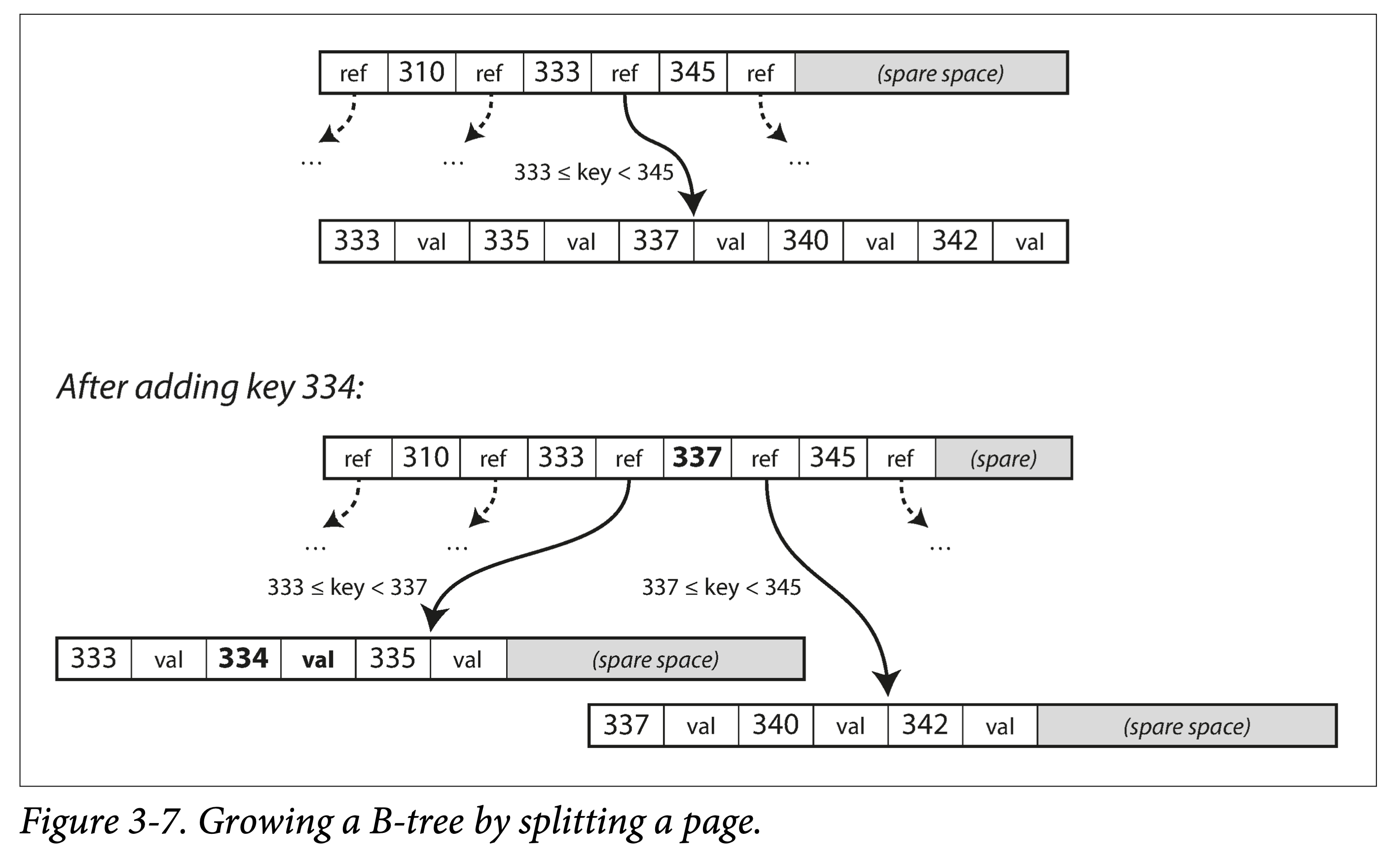
插入 or 更新。和查詢過程一樣,定位到原 Key 所在頁,插入或者更新後,將頁完整寫回。如果頁剩餘空間不夠,則分裂後寫入。
分裂 or 合併。級聯分裂和合並。
一個記錄大於一個 page 怎麼辦?
- 樹的節點是邏輯概念,page or block 是物理概念。一個邏輯節點可以對應多個物理 page。
讓 B 樹更可靠
B 樹不像 LSM-Tree ,會在原地修改資料檔案。
在樹結構調整時,可能會級聯修改很多 Page。比如葉子節點分裂後,就需要寫入兩個新的葉子節點,和一個父節點(更新葉子指標)。
- 增加預寫紀錄檔(WAL),將所有修改操作記錄下來,預防宕機時中斷樹結構調整而產生的混亂現場。
- 使用 latch 對樹結構進行並行控制。
B 樹的優化
B 樹出來了這麼久,因此有很多優化:
- 不使用 WAL,而在寫入時利用 Copy On Write 技術。同時,也方便了並行控制。如 LMDB、BoltDB。
- 對中間節點的 Key 做壓縮,保留足夠的路由資訊即可。以此,可以節省空間,增大分支因子。
- 為了優化範圍查詢,有的 B 族樹將葉子節點儲存時物理連續。但當資料不斷插入時,維護此有序性的代價非常大。
- 為葉子節點增加兄弟指標,以避免順序遍歷時的回溯。即 B+ 樹的做法,但遠不侷限於 B+ 樹。
- B 樹的變種,分形樹,從 LSM-tree 借鑑了一些思想以優化 seek。
B-Trees 和 LSM-Trees 對比
|
儲存引擎 |
B-Tree |
LSM-Tree |
備註 |
|
優勢 |
讀取更快 |
寫入更快 |
|
|
寫放大 |
1. 資料和 WAL 2. 更改資料時多次覆蓋整個 Page |
1. 資料和 WAL 2. Compaction |
SSD 不能過多擦除。因此 SSD 內部的韌體中也多用紀錄檔結構來減少隨機小寫。 |
|
寫吞吐 |
相對較低: 1. 大量隨機寫。 |
相對較高: 1. 較低的寫放大(取決於資料和設定) 2. 順序寫入。 3. 更為緊湊。 |
|
|
壓縮率 |
1. 存在較多內部碎片。 |
1. 更加緊湊,沒有內部碎片。 2. 壓縮潛力更大(共用字首)。 |
但緊縮不及時會造成 LSM-Tree 存在很多垃圾 |
|
背景流量 |
1. 更穩定可預測,不會受後臺 compaction 突發流量影響。 |
1. 寫吞吐過高,compaction 跟不上,會進一步加重讀放大。 2. 由於外存總頻寬有限,compaction 會影響讀寫吞吐。 3. 隨著資料越來越多,compaction 對正常寫影響越來越大。 |
RocksDB 寫入太過快會引起 write stall,即限制寫入,以期儘快 compaction 將資料下沉。 |
|
儲存放大 |
1. 有些 Page 沒有用滿 |
1. 同一個 Key 存多遍 |
|
|
並行控制 |
1. 同一個 Key 只存在一個地方 2. 樹結構容易加範圍鎖。 |
同一個 Key 會存多遍,一般使用 MVCC 進行控制。 |
|
本文來自部落格園,作者:邴越,轉載請註明原文連結:https://www.cnblogs.com/binyue/p/17264472.html