ChatGPT 開源了第一款外掛,都來學習一下原始碼吧!
3 月 23 日,OpenAI 又投出了一枚重磅炸彈:為 ChatGPT 推出外掛系統!
此舉意味著 ChatGPT 將迎來「APP Store」時刻,也就是圍繞它的能力,形成一個開發者生態,打造出基於 AI 的「作業系統」!
外掛系統將為 ChatGPT 帶來質的飛躍,因為藉助於外掛服務,它可以獲取實時的網際網路資訊、呼叫第三方應用(預定酒店航班、點外賣、購物、查詢股票價格等等)。
ChatGPT 是一個無比聰明的大腦,而外掛會成為它的眼睛、耳朵、手腳、甚至於翅膀,能力驚人,未來不敢想象!
官方目前提供了兩個外掛:
- 一個網頁瀏覽器。利用新必應瀏覽器的 API,實時搜尋網際網路內容,並給出答案和連結
- 一個程式碼直譯器。利用 Python 直譯器,可以解決數學問題、做資料分析與視覺化、編輯圖片、剪輯視訊等等,還支援下載處理後的檔案
另外,OpenAI 還開源了一個知識庫檢索外掛 chatgpt-retrieval-plugin ,這個外掛通過自然語言從各種資料來源(如檔案、筆記、郵件和公共檔案)檢索資訊。有了開原始碼後,開發者可以部署自己的外掛版本。
想象一下,假如我提供了一個「Python 知識庫外掛」,以所有官方檔案作為資料來源,那以後有任何 Python 使用上的問題,我就只需詢問 ChatGPT,然後它呼叫外掛並解析資料,最後返回給我準確的答案。這將節省大量的時間!
不僅如此,你還可以用書籍作為資料來源,打造出「西遊記知識庫」、「紅樓夢知識庫」、「百科全書知識庫」、「個人圖書館知識庫」,等等;以專業領域的論文與學術期刊為資料來源,創造出一個專家助手,從此寫論文查資料將無比輕鬆;以蘇格拉底、喬布斯、馬斯克等名人的資料為資料來源,創造出人格化的個人顧問……
作為第一個開源的 ChatGPT 外掛,chatgpt-retrieval-plugin 專案一經發布,就登上 Github 趨勢榜第一,釋出僅一週就獲得 11K stars。
這個專案完全是用 Python 寫的,不管是出於學習程式設計的目的,還是為了將來開發別的外掛作借鑑,這都值得我們花時間好好研究一下。
接下來,我將分享自己在閱讀專案檔案和原始碼時,收穫到的一些資訊。
首先,該專案含 Python 程式碼約 3 K,規模不算大。專案結構也很清晰,目錄如下:
| 目錄 | 描述 |
|---|---|
datastore |
包含使用各種向量資料庫提供程式儲存和查詢檔案嵌入的核心邏輯 |
examples |
包括設定範例、身份驗證方法和麵向程式提供方的範例 |
models |
包含外掛使用的資料模型,例如檔案和後設資料模型 |
scripts |
存放實用的指令碼,用於處理和上傳來自不同資料來源的檔案 |
server |
存放主要的 FastAPI 伺服器端實現 |
services |
包含用於任務(如分塊、後設資料提取和 PII 檢測)的實用服務 |
tests |
包括各種向量資料庫提供程式的整合測試 |
.well-known |
儲存外掛清單檔案和 OpenAPI 格式,定義外掛設定和 API 規範等資訊 |
除去範例、測試、組態檔等內容外,最主要的三個目錄如下:
datastore 資料儲存
資料來源的文字資料會被對映到低維度向量空間,然後儲存到向量資料庫中。官方已提供 Pinecone、Weaviate、Zilliz、Milvus、Qdrant、Redis 這幾種資料儲存方案的範例。另外,有幾個 pull requests 想要加入 PostgreSQL 的支援,大概率將來會合入。
這裡使用了抽象工廠設計模式 ,DataStore 是一個抽象類,每種資料儲存庫是具體的實現類,需要實現三個抽象方法:
(1)_upsert(chunks: Dict[str, List[DocumentChunk]]) -> List[str] 方法,接收一個字典引數,包含有 DocumentChunk 物件列表,將它們插入到資料庫中。返回值為檔案 ID 的列表。
(2)_query(queries: List[QueryWithEmbedding]) -> List[QueryResult] 方法,接收一個列表引數,包含被 embedding 的查詢文字。返回一個包含匹配檔案塊和分數的查詢結果列表。
(3)delete(ids: Optional[List[str]] = None, filter: Optional[DocumentMetadataFilter] = None, delete_all: Optional[bool] = None, ) -> bool 方法,根據 id 和其它過濾條件刪除,或者全部刪除。返回操作是否成功。
值得注意的是,該目錄下的factory.py 模組使用了 Python 3.10 新引入的 match-case 語法,緊跟著 Python 社群的新潮流呢~
server 伺服器端介面
這個目錄只有一個main.py 檔案,是整個專案的啟動入口。它使用了目前主流的 FastAPI 框架,提供了增刪改查的幾個 API,另外使用 uvicorn 模組來啟動服務。
/upsert-file介面,用於上傳單個檔案,將其轉換為 Document 物件,再進行新增或更新/upsert介面,上傳一系列的檔案物件,用於新增或更新/query介面,傳入一系列的文字條件,轉成 QueryWithEmbedding 物件後,再從向量資料庫查詢/delete介面,根據條件刪除或者全部刪除資料庫中的資料
在這幾個介面中,增改刪功能主要是給開發者/維護者使用的,ChatGPT 只需呼叫外掛的查詢介面。因此,程式碼中還建立了一個「/sub」子應用,只包含/query 介面,提供給 ChatGPT 呼叫。
另外,它使用 FastAPI 的 mount 方法掛載了一個「/.well-known」靜態檔案目錄,暴露了關於本外掛的基本資訊,例如名稱、描述、作者、logo、郵箱、提供給 OpenAPI 的介面檔案等等。
services 任務處理方法
這個目錄下是一些通用的函數,比如下面這些:
(1)chunks.py 檔案包含了將字串和 Document 物件分割成小塊、以及為每個塊獲取嵌入向量的函數。
(2)file.py 檔案提供了從上傳的檔案中提取文字內容及後設資料的函數。目前支援解析的檔案型別包括 PDF、純文字、Markdown、Word、CSV 和 PPTX。
(3)openai.py 檔案包含兩個函數:get_embeddings 函數使用 OpenAI 的 text-embedding-ada-002 模型對給定的文字進行嵌入。get_chat_completion 函數使用 OpenAI 的 ChatCompletion API 生成對話。
整個而言,這個外掛的幾個介面功能很清晰,程式碼邏輯也不算複雜。核心的文字嵌入操作是藉助於 openai 的 Embedding 介面,文字分塊資訊的儲存及查詢操作,則是依賴於各家向量資料庫的功能。
YouTube 上有博主手畫了一張示意圖,字型雖潦草,但大家可以意會一下:
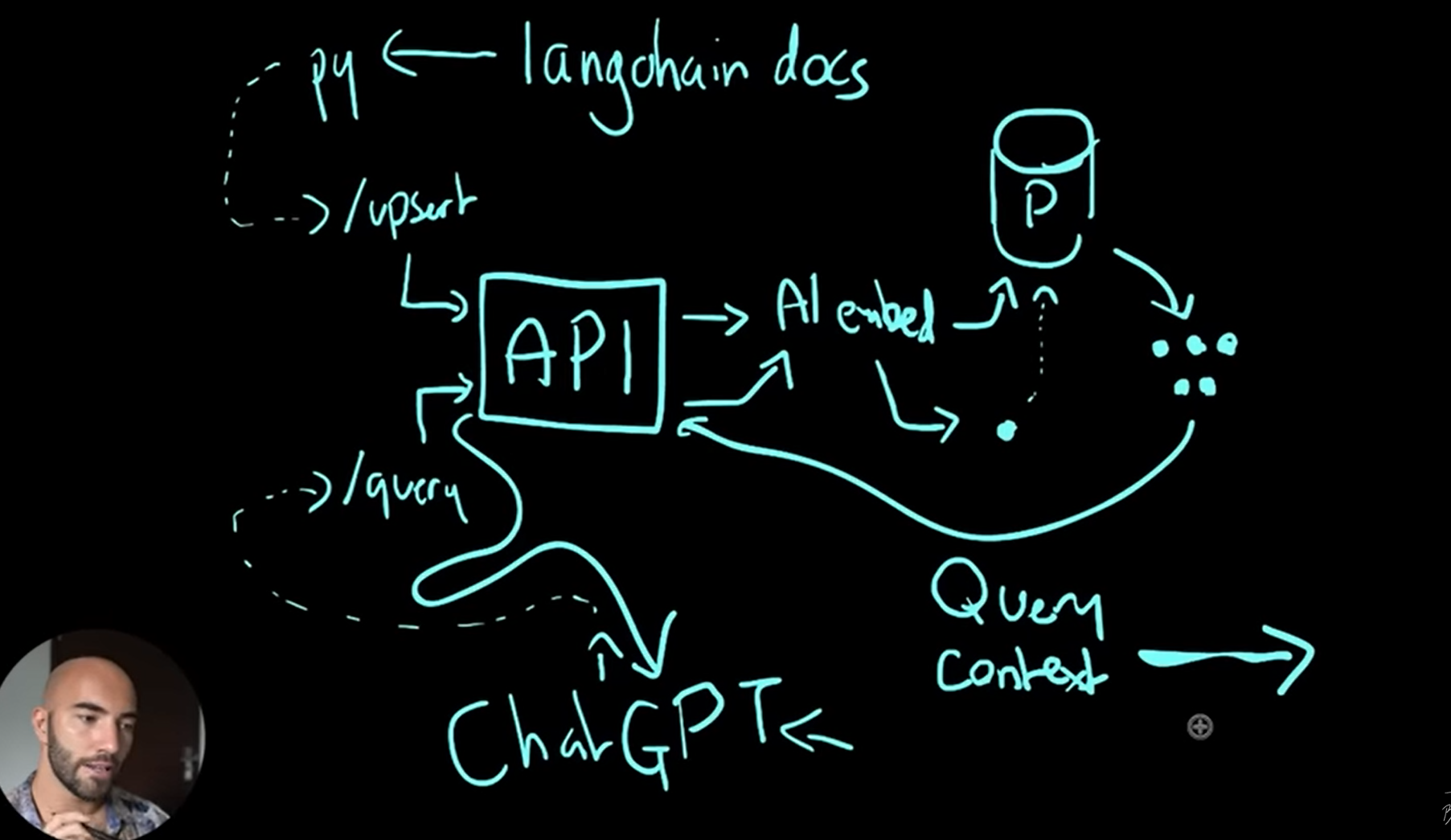
他這個視訊 值得推薦一看,因為 up 主不僅簡明地介紹了外掛的工作原理,還手把手演示如何部署到 Digital Ocean、如何修改設定、如何偵錯,而且他有 ChatGPT 的外掛許可權,可以將自己部署的外掛接入 ChatGPT,現場演示了知識庫外掛的使用!
目前,關於 ChatGPT 外掛的介紹、開發及設定等資料還比較少,畢竟是新推出的。但是,申請 waitlist 的個人和組織已經數不勝數了,一旦開放使用,各式各樣的外掛一定會像 Python 社群豐富的開源庫一樣,也將極大擴充套件 ChatGPT 的生態。
最後,外掛 chatgpt-retrieval-plugin 的官方檔案是最為詳細的一手資料,推薦大家研究一番。