手把手帶你從0完成醫療行業影像影象檢測三大經典模型InceptionV3-RestNet50-VGG16(附python原始碼及資料庫)——改變世界經典人工智慧專案實戰(一)手把手教學遷移學習
如果你想使用現在最火的ChatGPT來訓練屬於你的專屬ChatGPT模型,那你千萬不能錯過這篇文章。遷移學習是機器學習領域中的一種重要方法,它通過利用先前的學習經驗來提高當前任務的效能。本文通過3個經典的模型:InceptionV3-RestNet50-VGG16作為範例,為大家從0開始搭建了醫療影像行業遷移學習網路,並獲取到了較好的準確度與結果一致性。而掌握好遷移學習的基礎知識和應用,你就能通過模型微調(也稱遷移學習),呼叫ChatGPT介面加上你的訓練集去訓練你的模型了。
1、遷移學習簡介
遷移學習(transfer learning)是將在特定領域的一個任務中獲得的知識遷移到另一個相似領域的相關專案的過程。它允許我們將在一個特定領域的任務中獲得的知識應用到另一個相似領域的相關專案中。在深度學習中,這通常意味著使用預先訓練好的模型作為解決新問題的起點。由於計算機視覺和自然語言處理問題需要大量的資料和計算資源來訓練有效的深度學習模型,遷移學習可以減少對大量資料和時間的需求,因此在這些領域非常重要。
在2016年的NIPS教學中,Andrew Ng指出遷移學習將成為繼監督學習之後推動機器學習商業成功的重要因素。這一預測正在變為現實,因為遷移學習現在被廣泛應用於各種需要人工神經網路解決的困難問題。這引發了一個問題:為什麼會出現這種情況?
從頭開始訓練人工神經網路是一項艱鉅的任務,這主要有以下兩個原因:
- 人工神經網路的損失面是非凸的。因此,它需要一組良好的初始權重才能得到合理的收斂。
- 人工神經網路有很多引數,因此需要大量的資料進行訓練。遺憾的是,對於許多專案而言,可以被用於訓練神經網路的特定資料並不夠,但同時專案要解決的問題又非常複雜,需要依賴於神經網路的解決方案。
本專案將介紹如何使用遷移學習來解決醫療問題。
2、專案簡介
在醫療領域,糖尿病視網膜病變通常在糖尿病患者中發現,病人的高血糖會對其視網膜中的血管造成損害。糖尿病視網膜病變的檢測通常是手動檢測,即由經驗豐富的醫生通過檢查彩色的眼底視網膜影象來完成。這樣的診斷過程通過會引人一定程度的延遲,進而導致治療的延誤。在本專案中,我們將使用遷移學習建立一個用於檢測人眼中的糖尿病視網膜病變的模型,通過輸人彩色視網膜眼底影象來檢測是否存在糖尿病視網膜病變,並根據病變的嚴重程度進行分類。
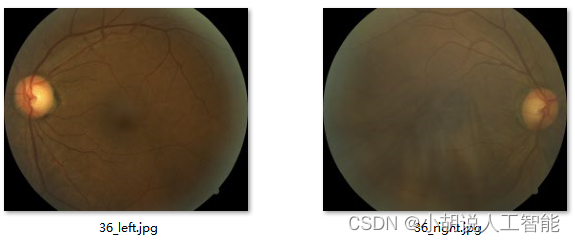
下圖左側圖片是輕度糖尿病視網膜病變的視網膜,右側圖片是正常的視網膜。
3、糖尿病視網膜病變資料集
資料集下載連結: https://pan.baidu.com/s/1hsijpCLD5oF7G5NqspWAbQ?pwd=eu0j 提取碼: eu0j
該資料集包含來自2015年糖尿病視網膜病變檢測的影象。每個影象都已調整大小和裁剪,最大尺寸為1024 px。調整大小和裁剪的程式碼可以在這裡找到。
對於2015年糖尿病視網膜病變檢測影象,為每個受試者提供左眼和右眼。影象標記有受試者ID以及左或右(例如,1_left.jpeg是患者ID 1的左眼)。
臨床醫生已經在0到4的尺度上針對糖尿病性視網膜病變的嚴重性對每個影象進行了評級:
0 - No DR 0 -沒有糖尿病視網膜病變
1 - Mild 1 -輕度糖尿病視網膜病變
2 - Moderate 2 -中度糖尿病視網膜病變
3 - Severe 3 -重度糖尿病視網膜病變
4 - Proliferative DR 4 -增生性糖尿病視網膜病變
與任何真實世界的資料集一樣,您將在影象和標籤中遇到噪聲。影象可能包含偽影、失焦、曝光不足或曝光過度。這些影象是在很長一段時間內使用各種相機從多個診所收集的,這將引入進一步的變化。
資料夾說明:
labels.zip-包含2015年的訓練和測試標籤
resized train15.zip-包含2015年已調整大小和裁剪的訓練集影象,總共35126個影象。
resized test 15.zip-包含2015年已調整大小和裁剪的測試集影象,總共53576個影象。
4、考慮類別不平衡問題
類別不平衡是分類問題中的一個主要挑戰。下圖描繪了訓練集5個嚴重性類的類密度。
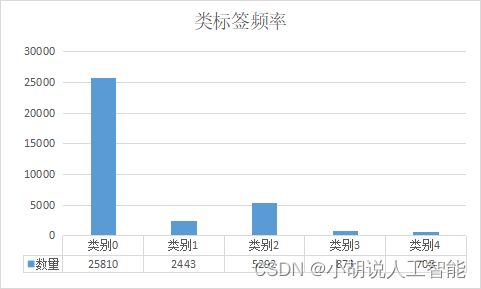
接近73%的訓練資料屬於類0,即沒有糖尿病視網膜病變。因此,如果我們碰巧將所有資料都標記為類0,那麼準確度可能會達到73%,但是在實際生活中,我們寧願在患者實際沒有某種健康問題的情況下誤判為有問題(假陽性),而不是在有某種健康問題的情況下誤判為沒有問題(假陰性)。因此,即使模型學會將所有資料歸類為類0,它的73%準確度也可能沒有太大意義。
檢測更高的嚴重性類別比檢測不嚴重類別更為重要。使用對數損失或交叉熵損失函數的分類模型的問題在於它的結果通常會有利於資料量大的類別。這是因為交叉熵誤差在最大相似性原則上更傾向於為數量更多的類別分配更高的概率。針對這個問題,我們可以兩件事:
- 從具有更多樣本的類別中丟棄資料或者對類別進行低頻率取樣以保持樣本之間的均勻分佈。
- 在損失函數中,為類別賦予與其密度成反比的權重。這可以保證當模型未能對它們進行分類時,損失函數對低頻類別賦予更高的懲罰。
我們將使用方案二,因為它不涉及生成更多的資料或者丟棄現有資料。如果我們使用類頻率的倒數作為權重,我們將得到下表所示的類別權重:
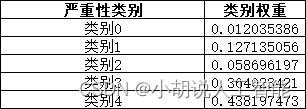
我們將在訓練分類網路時使用這些權重。詳見下面9、動態建立小批次資料進行訓練
5、定義模型質量
我們將對訓練集進行交叉驗證,使用標記的訓練資料構建模型,並在保留資料集上驗證模型。由於我們正在處理分類問題,因此準確度是一個有用的驗證指標。準確度定義如下:
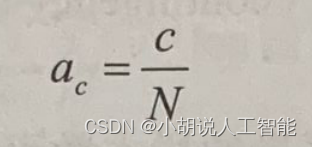
這裡,c是被正確分類的樣本的數量,N是用於評估的樣本總數。
我們還將使用二次加權kappa(quadratic weighted kappa)統計量來定義模型的質量,並與Kaggle標準相比,看我們建立的模型相較於基準是否有提升。二次加權kappa定義如下:
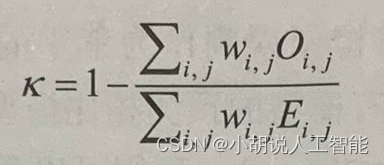
二次加權kappa表示式中的權重(wi,j)定義如下:
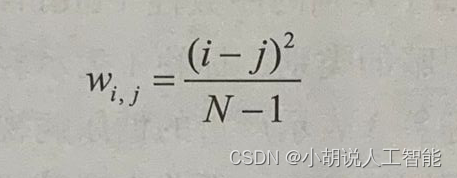
上述公式中包括以下內容:
- N表示類別的數量。
- Oi,j表示被預測為類別i且實際類別為j的影象的數量。
- Ei,j表示被預測為類別i且實際類別為j的影象的期望數量,並假設預測類別與實際類之間相互獨立。
可檢視更加詳細的關於二次加權kappa定義及範例。
6、定義損失函數
在本專案中,資料有五個類別,即沒有糖尿病視網膜病變、輕度糖尿病視網膜病變、中度糖尿病視網膜病變、嚴重的糖尿病視網膜病變和增生性糖尿病視網膜病變。因此,我們可以將其視為分類問題。對於我們的分類問題,輸出標籤需要進行獨熱編碼,如下所示:
- 無糖尿病視網膜病變:[10000]T
- 輕度糖尿病視網膜病變:[01000]T
- 中度糖尿病視網膜病變:[00100]T
- 嚴重糖尿病視網膜病變:[00010]T
- 增生性糖尿病視網膜病變:00001]T
Softmax是用於在輸出層中呈現不同類別的概率的最佳啟用函數,而每個資料點的類別交叉熵損失之和是要優化的最佳損失。對於具有輸出標籤向量y和預測概率p的單個資料點,交叉熵損失由以下公式給出:
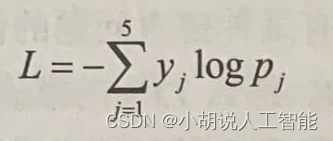
這裡,y=[y1…yj…ys]T,且p=[p1…pj…p5]T。
同樣地,M個訓練資料點的平均損失可以表示為:
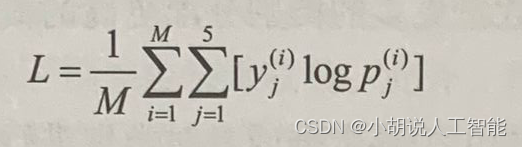
在訓練過程中,基於上式得到的平均對數損失(average log loss)來產生小批次的梯度,其中M是所選的批次的大小。對於我們將結合驗證準確度監視的驗證對數損失,M是驗證集資料點數。由於我們將在K折交叉驗證(K-foldcross-validation)的每一折進行驗證,因此我們將在每個折中使用不同的驗證資料集。
請注意,輸出中的類別具有序數性,並且嚴重性逐類遞增。因此迴歸也可能是不錯的
解決方法。大家也可以嘗試用迴歸來代替分類,看看它是否合理。迴歸的挑戰之一是將原始得分轉換為類別。
7、預處理影象
不同類別的影象將儲存在不同的資料夾中,因此可以很容易地標記它們的類別。博主寫了個分類程式碼,可以直接修改資料夾地址,然後自動處理成不同類別的資料夾。具體python程式碼如下:
#!/usr/bin/env python3.8
# -*- coding: utf-8 -*-
# @Time : 2023/3/24 10:24
# @Author : Steven Hu
# @FileName: split_data.py
# @Software: PyCharm
import os
import shutil
import random
import pandas as pd
def split_dataset(folder_path, train_folder_path, validation_folder_path):
# Get all list of files in the folder
files = []
for root, dirs, file_ in os.walk(folder_path):
# 這裡可以進行判斷,如果不是要搜尋的就跳過;
# 也可以對 `files` 列表進行遍歷,以達到具體檔案的搜尋
if len(file_):
file_path_list = [str(root) + os.sep + str(i) for i in file_]
files.extend(file_path_list)
# Split the dataset by 80%-20%
train_files = random.sample(files, round(0.8 * len(files)))
validation_files = [file for file in files if file not in train_files]
# Copy the files from original folder to training folder
if not os.path.exists(train_folder_path):
os.makedirs(train_folder_path)
for file in train_files:
shutil.copy(file, train_folder_path)
# Copy the files from original folder to validation folder
if not os.path.exists(validation_folder_path):
os.makedirs(validation_folder_path)
for file in validation_files:
shutil.copy(file, validation_folder_path)
def class_generation_from_train(csv_file, source_dir, class_list=None):
# 如果train中沒有分類,需要執行該函數,對class進行分類
# 讀取excel中的資料
if class_list is None:
class_list = ["class0", "class1", "class2", "class3", "class4"]
df = pd.read_csv(csv_file)
# 獲取指定資料夾中的所有檔名
file_list = os.listdir(source_dir)
for class_ in class_list:
path_ = os.path.join(source_dir, class_)
if not os.path.exists(path_):
os.makedirs(path_)
# 遍歷所有檔案
for filename in file_list:
# 依次在excel中查詢,如果找到對應行,則根據excel中指定列的值,將檔案移動到以該值命名的資料夾中
filename_ = filename[:-4]
if filename_ in df['image'].values:
row = df[df['image'] == filename_]
target_dir = row['level'].values[0]
target_dir = os.path.join(source_dir, "class" + str(target_dir))
source_path = os.path.join(source_dir, filename)
target_path = os.path.join(target_dir, filename)
os.rename(source_path, target_path)
if __name__ == '__main__':
# 先隨機80%-20%拆分訓練集和驗證集
folder_path = r"E:\Data\resized train 15"
train_folder_path = r"E:\Data\train_validation\train"
validation_folder_path = r"E:\Data\train_validation\validation"
split_dataset(folder_path, train_folder_path, validation_folder_path)
# 再對訓練集和驗證集內進行class分類
train_csv_file = r'E:\Data\labels\trainLabels15.csv' # 這個是訓練集的label檔案testLabels15.csv
class_generation_from_train(train_csv_file, train_folder_path,
["class0", "class1", "class2", "class3", "class4"])
class_generation_from_train(train_csv_file, validation_folder_path,
["class0", "class1", "class2", "class3", "class4"])
# 再對測試集進行class分類
test_folder_path = r"E:\Data\resized test 15"
test_csv_file = r'E:\Data\labels\testLabels15.csv' # 這個是測試集的label檔案
class_generation_from_train(test_csv_file, test_folder_path,
["class0", "class1", "class2", "class3", "class4"])
我們使用OpenCV函數讀取影象,並調整它們的尺寸,如224x224x3。我們將參照ImageNe數服集從每個影象中逐通道減去平均畫素強度。這樣可以保證在模型上訓練之前,糖尿病視像將數存的影象溼度與所處理的Imagener 影象具有相同的強度範圍。一旦完成預處理,機像將被儲存在一個numpy 陣列中。影象預處理常式可以定義如下:
def pre_process(img):
resized_img = cv2.resize(img, (224, 224), cv2.INTER_LINEAR)
resized_img[:, :, 0] = resized_img[:, :, 0] - 103.939
resized_img[:, :, 1] = resized_img[:, :, 0] - 116.779
resized_img[:, :, 2] = resized_img[:, :, 0] - 123.68
return resized_img
我們通過通過行間插值的方法將其大小調整為(224,224,3)或其他任意指定維度。
ImageNet 影象的紅色、綠色和藍色通道的平均畫素強度分別為103.939、116.779和123.68。預訓練模型是在從影象中減去這些平均值之後進行訓練的。這種減去平均值的方法是為了使資料特徵標準化,將資料集中在0附近有助於避免梯度消失和梯度爆炸問題,進而有助於模型更快地收斂。此外,每個通道標準化有助於保持梯度流均勻地進人每個通道。由於我們在這個專案中使用預訓練模型,因此合理的做法是在將影象輸人預訓練網路之前,每個通道也基於同樣的方式進行標準化。然而,使用基於預訓練網路ImageNet的平均值來校正專案中的影象並非強制要求,也可以通過專案中訓練集影象的平均畫素強度來進行標準化。
同樣,還可以選擇對整個影象進行均值歸一化,而不是分別對每個通道進行均值歸一化。這需要從影象自身中減去每個影象的平均值。想象一下,CNN中識別的物體可能來自不同的光照條件(如白天和夜晚)。而我們希望無論何種光照條件,都能正確地對物體進行分類,然而,不同的畫素強度將不同程度地啟用神經網路的神經元,這會增加物件被錯誤分類的可能性。然而,如果從影象中減去每個影象的平均值,則該影象物件將不再受到不同照明條件的影響。因此,根據具體影象的性質,我們需要自己選擇最佳的影象標準化方案,不過任何預設的標準化效能都不錯。
另外為了擴充資料,我們將使用keras的ImageDataGenerator在影象畫素座標上進行仿射變換(affine transformation)來生成額外的資料。我們主要使用的仿射變換是旋轉、平移和縮放。具體程式碼如下:
datagen = ImageDataGenerator(horizontal_flip=True,
vertical_flip=True,
width_shift_range=0.1,height_shift_range=0.1,
channel_shift_range=0, zoom_range=0.2,
rotation_range=20,
preprocessing_function=pre_process)
從定義的生成器中可以看出,我們啟用了水平和垂直翻轉,這會生成分別沿水平軸和垂直軸反射得到的影象。類似地,我們還讓影象沿寬度和高度方向平移10%畫素位警旋轉範圍限制在20度的角度範圍內,而縮放因子則定義在原始影象的0.8~1.2以內。
8、搭建遷移學習網路
我們現在將使用預訓練的ResNet50、InceptionV3和VGG16網路進行實驗,並找出能夠獲得最佳結果的網路。每個預訓練模型的權重都基於ImageNet。我在下面提供了 ResNet InceptionV3和VGG16架構的原始論文連結以供參考。建議讀者閱讀這些文章,深入瞭解這些網路架構以及它們之間細微的差別。
以下是VGG論文的連結:
論文題目:Very Deep Convolutional Networks for Large-Scale Image Recognition
以下是ResNet 論文的連結:
論文題目:Deep Residual Learning for Image Recognition
以下是InceptionV3論文的連結:
論文題目:Rethinking the Inception Architecture for Computer Vision
論文百度下載連結:
連結: https://pan.baidu.com/s/1B6XklxnrwCBCkmNd1ATOYw?pwd=tpwm 提取碼: tpwm
VGG16 遷移學習網路
VGG16是一個16層的CNN,它使用3x3的濾波器和2x2 感受野(receptive field)進行折積。整個網路中使用的啟用函數都是ReLU。VGG架構是由 Simonyan 和 Zisserman 開發的,它是2014年ILSVRC比賽的亞軍。VGG16網路由於其簡單性而獲得廣泛的普及,而且它是用於從影象中提取特徵的最流行的網路。
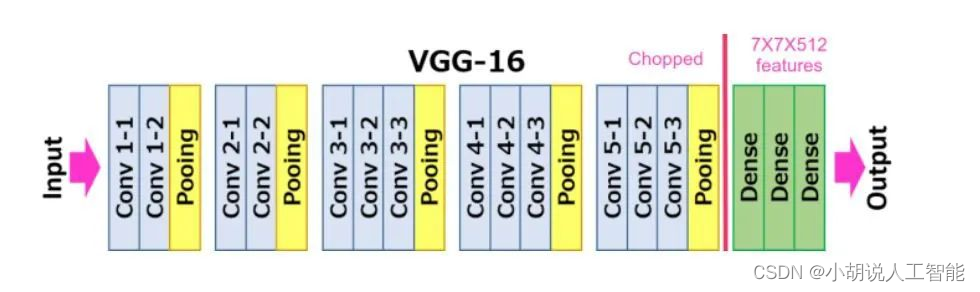
使用VGG16網路進行遷移學習,還是比較簡單,使用在ImageNet上預訓練的VGG16的權重作為模型的初始權重,然後對模型進行微調。凍結了前幾個層(預設為10層)的權重,因為在 CNN 中,前幾層會學習檢測通用的特徵,如邊緣、顏色構成等。因此,不同領域影象的通用特徵不會有很大差異。凍結層是指不訓練特定於該層的權重。我們可以嘗試不同的凍結層數量,並採用提供最佳驗證結果的凍結層數量。由於我們現在面臨的是多分類任務,因此最終輸出層選擇了softmax啟用函數。具體程式碼如下:
def VGG16_pseudo(dim=224, freeze_layers=10, full_freeze='N'):
model = VGG16(weights='imagenet', include_top=False)
# model = VGG16(weights=r'E:\learning_AI\Intelligent_projects_using_python\weights\vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5', include_top=False) # 如果上面執行出現網路下載錯誤,建議先下載權重後,使用權重地址
x = model.output # 從預訓練的網路中提取最後一個最大池化層的輸出
x = GlobalAveragePooling2D()(x) #確保池輸出是一維陣列格式,而不是二維點陣格式
x = Dense(dim, activation='relu')(x) # 連線一個全連線層,這個dim可以自定義成其它值,比如512
x = Dropout(0.5)(x) # 防止過擬合
x = Dense(dim, activation='relu')(x) # 再連線一個全連線層,這個dim可以自定義成其它值,比如512
x = Dropout(0.5)(x) # 防止過擬合
out = Dense(5, activation='softmax')(x) # 這裡輸出必須是分類數量的單元數
model_final = Model(input=model.input, outputs=out)
if full_freeze != 'N':
for layer in model.layers[0:freeze_layers]:
layer.trainable = False
return model_final
VGG16_weights下載百度連結:https://pan.baidu.com/s/1pBz70iEtHe2PTXX7Mw20uw?pwd=wic3 提取碼: wic3
InceptionV3遷移學習網路
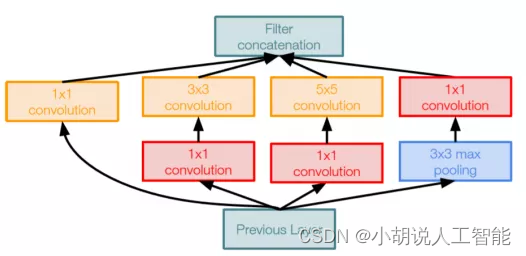
InceptionV3是來自谷歌的最先進的CNN。InceptionV3架構不是在每層使用固定大小的折積濾波器,而是使用不同大小的濾波器來提取不同粒度級別的特徵。Inception是2014年ImageNet競賽的冠軍,前五錯誤率為6.67%,非常接近人類的表現。InceptionV3層的折積塊如下圖所示。
具體程式碼如下:
def inception_pseudo(dim=224, freeze_layers=30, full_freeze='N'):
# model = InceptionV3(weights='imagenet', include_top=False) # 如果下載不了,則直接使用權重地址賦值到weights引數上
model = InceptionV3(weights=r"E:\learning_AI\Intelligent_projects_using_python\weights\inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5",
include_top=False)
x = model.output # 從預訓練的網路中提取最後一個最大池化層的輸出
x = GlobalAveragePooling2D()(x) #確保池輸出是一維陣列格式,而不是二維點陣格式
x = Dense(dim, activation='relu')(x) # 連線一個全連線層,這個dim可以自定義成其它值,比如512
x = Dropout(0.5)(x) # 防止過擬合
x = Dense(dim, activation='relu')(x) # 再連線一個全連線層,這個dim可以自定義成其它值,比如512
x = Dropout(0.5)(x) # 防止過擬合
out = Dense(5, activation='softmax')(x) # 這裡輸出必須是分類數量的單元數
model_final = Model(input=model.input, outputs=out)
if full_freeze != 'N':
for layer in model.layers[0:freeze_layers]:
layer.trainable = False
return model_final
需要注意的一點是,由於InceptionV3是一個更深的網路,因此可以擁有更多的初始層。在資料有限的情況下,不需要訓練模型中的所有層是一個優勢。如果我們使用較少的訓練資料,則整個網路的權重可能會導致過擬合。而凍結層可以減少需要訓練的權重數量,因此提供了某種形式的正則化。由於初始層學習與問題領域無關的通用特徵,因此它們是最適合凍結的層。我們還在完全連線層中使用了dropout,以防止過擬合。
InceptionV3_weights下載百度連結:https://pan.baidu.com/s/1pBz70iEtHe2PTXX7Mw20uw?pwd=wic3 提取碼: wic3
ResNet50遷移學習網路
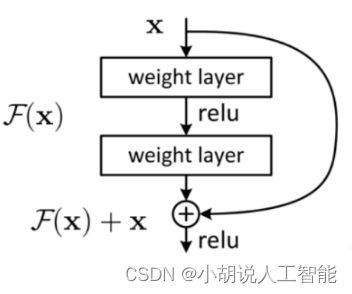
ResNet50是一個深度CNN,它實現了殘差塊(residualblock)的概念,與VGG16網路非常不同。在一系列折積-啟用-池化操作之後,塊的輸入再次反饋到輸出。ResNet構由 Kaiming He 等人開發,雖然它有152 層,但其實並沒有VGG網路複雜。該架構以3.57%的前五錯誤率贏得了 2015 年ILSVRC 競賽,這比競賽資料集的人工標註成績還要好。前五錯誤率是通過檢查目標是否在最高概率的五個預測類別中得到的。實際上,ResNet網路嘗試學習殘差對映,而不是直接從輸出對映到輸入,如下圖所示。
具體程式碼如下:
def resnet_pseudo(dim=224, freeze_layers=10, full_freeze='N'):
# model = ResNet50(weights='imagenet', include_top=False) # 如果下載不了,則直接使用權重地址賦值到weights引數上
model = ResNet50(weights=r"E:\learning_AI\Intelligent_projects_using_python\weights\resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5",
include_top=False)
x = model.output # 從預訓練的網路中提取最後一個最大池化層的輸出
x = GlobalAveragePooling2D()(x) #確保池輸出是一維陣列格式,而不是二維點陣格式
x = Dense(dim, activation='relu')(x) # 連線一個全連線層,這個dim可以自定義成其它值,比如512
x = Dropout(0.5)(x) # 防止過擬合
x = Dense(dim, activation='relu')(x) # 再連線一個全連線層,這個dim可以自定義成其它值,比如512
x = Dropout(0.5)(x) # 防止過擬合
out = Dense(5, activation='softmax')(x) # 這裡輸出必須是分類數量的單元數
model_final = Model(input=model.input, outputs=out)
if full_freeze != 'N':
for layer in model.layers[0:freeze_layers]:
layer.trainable = False
return model_final
ResNet50_weights下載百度連結:https://pan.baidu.com/s/1pBz70iEtHe2PTXX7Mw20uw?pwd=wic3 提取碼: wic3
9、動態建立小批次資料進行訓練
如果你的電腦記憶體較低,建議使用小批次載入資料進行訓練,在訓練時只載入小批次資料的方式之一是通過隨機地處理不同位置的影象來動態地建立小批次。每個小批次中處理的影象數量等於我們指定的小批次大小。當然,在訓練期間動態地建立小批次會有一些效能瓶頸,但這些瓶頸可以忽略不計,特別是諸如 keras 之類的具有高效的動態批次建立機制。我們將利用keras 的flow_from_directory數間動態建立小批次,以減少訓練過程需要的記憶體。同時使用ImageDataGenerator行影象增強。相關程式碼如下:
def train_model(train_dir, val_dir, batch_size=16, epochs=40, dim=224, lr=1e-5, model='ResNet50'):
model_final = self.inception_pseudo(dim=dim, freeze_layers=30, full_freeze='N') # 預設選擇為'InceptionV3'
if model == 'Resnet50':
model_final = self.resnet_pseudo(dim=dim, freeze_layers=10, full_freeze='N')
if model == 'VGG16':
model_final = self.VGG16_pseudo(dim=dim, freeze_layers=10, full_freeze='N')
train_file_names = glob.glob(f'{train_dir}/*/*')
val_file_names = glob.glob(f'{val_dir}/*/*')
train_steps_per_epoch = len(train_file_names) / float(batch_size)
val_steps_per_epoch = len(val_file_names) / float(batch_size)
train_datagen = ImageDataGenerator(horizontal_flip=True, vertical_flip=True, width_shift_range=0.1,
height_shift_range=0.1,
channel_shift_range=0, zoom_range=0.2, rotation_range=20,
preprocessing_function=pre_process)
val_datagen = ImageDataGenerator(preprocessing_function=pre_process)
train_generator = train_datagen.flow_from_directory(train_dir,
target_size=(dim, dim),
batch_size=batch_size,
class_mode='categorical')
val_generator = val_datagen.flow_from_directory(val_dir,
target_size=(dim, dim),
batch_size=batch_size,
class_mode='categorical')
print(train_generator.class_indices)
# 如果有GPU則直接用GPU
physical_devices = tf.config.experimental.list_physical_devices('GPU')
if physical_devices:
tf.config.experimental.set_memory_growth(physical_devices[0], True)
joblib.dump(train_generator.class_indices, f'{self.outdir}\class_indices.pkl')
adam = optimizers.Adam(lr=lr, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0)
model_final.compile(optimizer=adam, loss=["categorical_crossentropy"], metrics=['accuracy'])
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.50, patience=3, min_lr=0.000001)
early = EarlyStopping(monitor='val_loss', patience=10, mode='min', verbose=1)
logger_path = self.outdir + os.sep + 'keras-epochs_ib.log'
logger = CSVLogger(logger_path, separator=',', append=False)
model_name = self.outdir + os.sep + 'keras_transfer_learning-run.check'
checkpoint = ModelCheckpoint(
model_name,
monitor='val_loss', mode='min',
save_best_only=True,
verbose=1)
callbacks = [reduce_lr, early, checkpoint, logger]
model_final.fit_generator(train_generator, steps_per_epoch=train_steps_per_epoch, epochs=epochs, verbose=1,
validation_data=(val_generator), validation_steps=val_steps_per_epoch,
callbacks=callbacks,
class_weight={0: 0.012, 1: 0.12, 2: 0.058, 3: 0.36, 4: 0.43})
model_to_store_path = self.outdir + os.sep + model
model_final.save(model_to_store_path)
return model_to_store_path, train_generator.class_indices
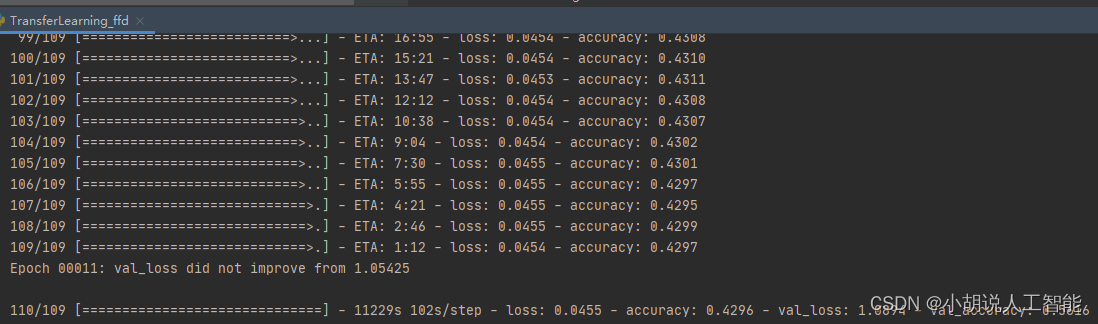
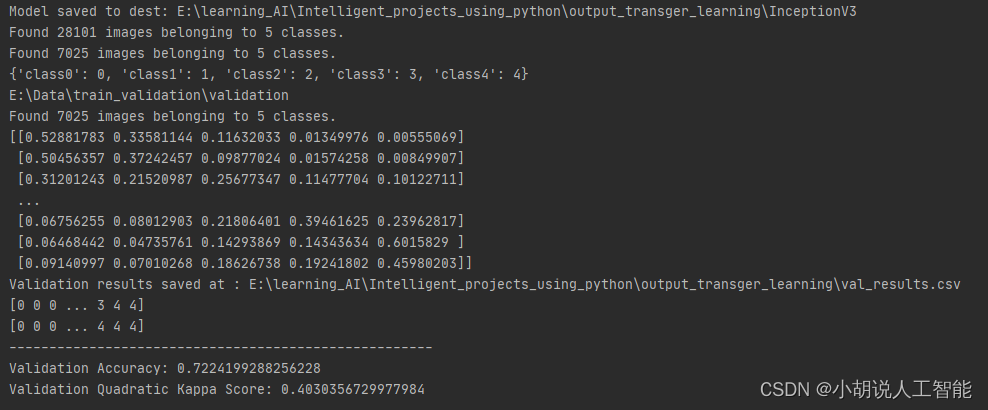
從上面紀錄檔可以看到,InceptionV3模型得到接近72%的驗證準確度和0.403的二次Kappa得分。當然讀者也可以嘗試使用其它的模型和訓練超參,最後獲得更高的驗證準確度。其它詳細訓練程式碼詳見11、全部程式碼
10、測試集預測
讀者可以通過9、動態建立小批次資料進行訓練儲存的模型,對測試集資料進行預測,然後獲取到測試集準確度和二次Kappa得分,具體程式碼如下:
# !/usr/bin/env python3.8
# -*- coding: utf-8 -*-
# @Time : 2023/3/24 9:07
# @Author : Steven Hu
# @FileName: TransferLearning.py
# @Software: PyCharm
import numpy as np
np.random.seed(1000)
import pandas as pd
import time
import warnings
warnings.filterwarnings("ignore")
from sklearn.metrics import cohen_kappa_score
from tensorflow.keras.models import load_model
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import cv2
# 平均化預處理圖片,使其能滿足ImageNet pre-trained model 圖片要求
def pre_process(img):
resized_img = cv2.resize(img, (224, 224), cv2.INTER_LINEAR)
resized_img[:, :, 0] = resized_img[:, :, 0] - 103.939
resized_img[:, :, 1] = resized_img[:, :, 0] - 116.779
resized_img[:, :, 2] = resized_img[:, :, 0] - 123.68
return resized_img
def prediction_test(model_path, test_dir, class_dict=None, dim=224):
if class_dict is None:
class_dict = {"class0": 0, "class1": 1, "class2": 2, "class3": 3, "class4": 4, }
print(test_dir)
model = load_model(model_path)
test_datagen = ImageDataGenerator(preprocessing_function=pre_process)
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(dim, dim),
shuffle=False,
class_mode='categorical',
batch_size=1)
filenames = test_generator.filenames
nb_samples = len(filenames)
pred = model.predict_generator(test_generator, steps=nb_samples)
print(pred)
df = pd.DataFrame()
df['filename'] = filenames
df['actual_class'] = df['filename'].apply(lambda x: x[:6])
df['actual_class_index'] = df['actual_class'].apply(lambda x: int(class_dict[x]))
df['pred_class_index'] = np.argmax(pred, axis=1)
k = list(class_dict.keys())
v = list(class_dict.values())
inv_class_dict = {}
for k_, v_ in zip(k, v):
inv_class_dict[v_] = k_
df['pred_class'] = df['pred_class_index'].apply(lambda x: (inv_class_dict[x]))
return df
def main():
start_time = time.time()
test_results_path = r'E:\learning_AI\Intelligent_projects_using_python\resutl_test\test_results.csv'
model_path = r"E:\learning_AI\Intelligent_projects_using_python\output_transger_learning\keras_transfer_learning-run.check"
test_dir = r'E:\Data\resized test 15'
test_results_df = prediction_test(model_path, test_dir)
test_results_df.to_csv(test_results_path, index=False)
print(f'Validation results saved at : {test_results_path}')
pred_class_index = np.array(test_results_df['pred_class_index'].values)
actual_class_index = np.array(test_results_df['actual_class_index'].values)
print(pred_class_index)
print(actual_class_index)
accuracy = np.mean(actual_class_index == pred_class_index)
kappa = cohen_kappa_score(pred_class_index, actual_class_index, weights='quadratic')
print("-----------------------------------------------------")
print(f'Validation Accuracy: {accuracy}')
print(f'Validation Quadratic Kappa Score: {kappa}')
print("-----------------------------------------------------")
print("Processing Time", time.time() - start_time, ' secs')
if __name__ == "__main__":
main()
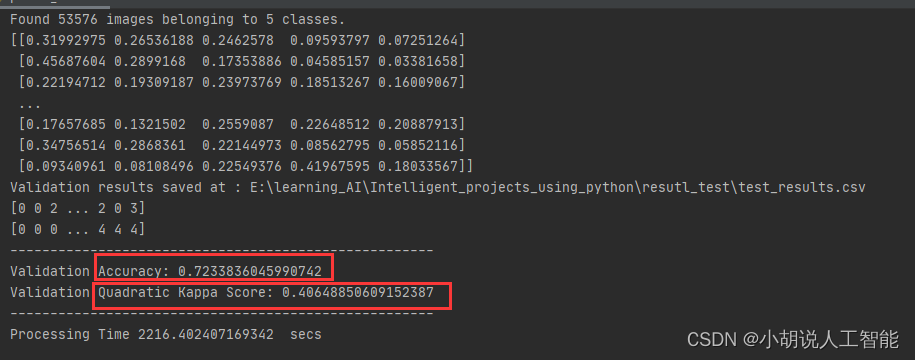
從上面紀錄檔可以看到,InceptionV3模型訓練後的模型再53576張測試圖片集中也取得接近72%的驗證準確度和0.406的二次Kappa得分。當然讀者也可以嘗試使用其它的模型和訓練超參,最後獲得更高的測試準確度。
11、全部程式碼
#!/usr/bin/env python3.8
# -*- coding: utf-8 -*-
# @Time : 2023/3/24 9:03
# @Author : Steven Hu
# @FileName: TransferLearning_ffd.py
# @Software: PyCharm
import numpy as np
np.random.seed(1000)
import os
import pandas as pd
import time
import warnings
warnings.filterwarnings("ignore")
import tensorflow as tf
from sklearn.metrics import cohen_kappa_score
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import GlobalMaxPooling2D, GlobalAveragePooling2D
from tensorflow.keras.models import load_model
from tensorflow.keras.applications.inception_v3 import InceptionV3
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras import optimizers
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint, CSVLogger
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import ReduceLROnPlateau
import joblib
import json
from pathlib import Path
import glob
import cv2
def pre_process(img):
resized_img = cv2.resize(img, (224, 224), cv2.INTER_LINEAR)
resized_img[:, :, 0] = resized_img[:, :, 0] - 103.939
resized_img[:, :, 1] = resized_img[:, :, 0] - 116.779
resized_img[:, :, 2] = resized_img[:, :, 0] - 123.68
return resized_img
class TransferLearning:
def __init__(self):
self.path = r"E:\Data\train_validation"
self.train_dir = r"E:\Data\train_validation\train"
self.val_dir = r"E:\Data\train_validation\validation"
self.class_folders = json.loads('["class0","class1","class2","class3","class4"]')
self.dim = 224
self.lr = float(1e-4)
self.batch_size = 128
self.epochs = 1
self.initial_layers_to_freeze = 10
self.model = "InceptionV3"
self.folds = 5
self.outdir = "E:\learning_AI\Intelligent_projects_using_python\output_transger_learning"
def inception_pseudo(self, dim=224, freeze_layers=30, full_freeze='N'):
# model = InceptionV3(weights='imagenet', include_top=False) # 如果下載不了,則直接使用權重地址賦值到weights引數上
model = InceptionV3(weights=r"E:\learning_AI\Intelligent_projects_using_python\weights\inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5",
include_top=False)
x = model.output # 從預訓練的網路中提取最後一個最大池化層的輸出
x = GlobalAveragePooling2D()(x) #確保池輸出是一維陣列格式,而不是二維點陣格式
x = Dense(dim, activation='relu')(x) # 連線一個全連線層,這個dim可以自定義成其它值,比如512
x = Dropout(0.5)(x) # 防止過擬合
x = Dense(dim, activation='relu')(x) # 再連線一個全連線層,這個dim可以自定義成其它值,比如512
x = Dropout(0.5)(x) # 防止過擬合
out = Dense(5, activation='softmax')(x) # 這裡輸出必須是分類數量的單元數
model_final = Model(input=model.input, outputs=out)
if full_freeze != 'N':
for layer in model.layers[0:freeze_layers]:
layer.trainable = False
return model_final
# ResNet50 Model for transfer Learning
def resnet_pseudo(self, dim=224, freeze_layers=10, full_freeze='N'):
# model = ResNet50(weights='imagenet', include_top=False) # 如果下載不了,則直接使用權重地址賦值到weights引數上
model = ResNet50(weights=r"E:\learning_AI\Intelligent_projects_using_python\weights\resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5",
include_top=False)
x = model.output # 從預訓練的網路中提取最後一個最大池化層的輸出
x = GlobalAveragePooling2D()(x) #確保池輸出是一維陣列格式,而不是二維點陣格式
x = Dense(dim, activation='relu')(x) # 連線一個全連線層,這個dim可以自定義成其它值,比如512
x = Dropout(0.5)(x) # 防止過擬合
x = Dense(dim, activation='relu')(x) # 再連線一個全連線層,這個dim可以自定義成其它值,比如512
x = Dropout(0.5)(x) # 防止過擬合
out = Dense(5, activation='softmax')(x) # 這裡輸出必須是分類數量的單元數
model_final = Model(input=model.input, outputs=out)
if full_freeze != 'N':
for layer in model.layers[0:freeze_layers]:
layer.trainable = False
return model_final
# VGG16 Model for transfer Learning
def VGG16_pseudo(self, dim=224, freeze_layers=10, full_freeze='N'):
model = VGG16(weights='imagenet', include_top=False)
# model = VGG16(weights=r'E:\learning_AI\Intelligent_projects_using_python\weights\vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5', include_top=False) # 如果上面執行出現網路下載錯誤,建議先下載權重後,使用權重地址
x = model.output # 從預訓練的網路中提取最後一個最大池化層的輸出
x = GlobalAveragePooling2D()(x) #確保池輸出是一維陣列格式,而不是二維點陣格式
x = Dense(dim, activation='relu')(x) # 連線一個全連線層,這個dim可以自定義成其它值,比如512
x = Dropout(0.5)(x) # 防止過擬合
x = Dense(dim, activation='relu')(x) # 再連線一個全連線層,這個dim可以自定義成其它值,比如512
x = Dropout(0.5)(x) # 防止過擬合
out = Dense(5, activation='softmax')(x) # 這裡輸出必須是分類數量的單元數
model_final = Model(input=model.input, outputs=out)
if full_freeze != 'N':
for layer in model.layers[0:freeze_layers]:
layer.trainable = False
return model_final
def train_model(self, train_dir, val_dir, batch_size=16, epochs=40, dim=224, lr=1e-5, model='ResNet50'):
model_final = self.inception_pseudo(dim=dim, freeze_layers=30, full_freeze='N') # 預設選擇為'InceptionV3'
if model == 'Resnet50':
model_final = self.resnet_pseudo(dim=dim, freeze_layers=10, full_freeze='N')
if model == 'VGG16':
model_final = self.VGG16_pseudo(dim=dim, freeze_layers=10, full_freeze='N')
train_file_names = glob.glob(f'{train_dir}/*/*')
val_file_names = glob.glob(f'{val_dir}/*/*')
train_steps_per_epoch = len(train_file_names) / float(batch_size)
val_steps_per_epoch = len(val_file_names) / float(batch_size)
train_datagen = ImageDataGenerator(horizontal_flip=True, vertical_flip=True, width_shift_range=0.1,
height_shift_range=0.1,
channel_shift_range=0, zoom_range=0.2, rotation_range=20,
preprocessing_function=pre_process)
val_datagen = ImageDataGenerator(preprocessing_function=pre_process)
train_generator = train_datagen.flow_from_directory(train_dir,
target_size=(dim, dim),
batch_size=batch_size,
class_mode='categorical')
val_generator = val_datagen.flow_from_directory(val_dir,
target_size=(dim, dim),
batch_size=batch_size,
class_mode='categorical')
print(train_generator.class_indices)
# 如果有GPU則直接用GPU
physical_devices = tf.config.experimental.list_physical_devices('GPU')
if physical_devices:
tf.config.experimental.set_memory_growth(physical_devices[0], True)
joblib.dump(train_generator.class_indices, f'{self.outdir}\class_indices.pkl')
adam = optimizers.Adam(lr=lr, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0)
model_final.compile(optimizer=adam, loss=["categorical_crossentropy"], metrics=['accuracy'])
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.50, patience=3, min_lr=0.000001)
early = EarlyStopping(monitor='val_loss', patience=10, mode='min', verbose=1)
logger_path = self.outdir + os.sep + 'keras-epochs_ib.log'
logger = CSVLogger(logger_path, separator=',', append=False)
model_name = self.outdir + os.sep + 'keras_transfer_learning-run.check'
checkpoint = ModelCheckpoint(
model_name,
monitor='val_loss', mode='min',
save_best_only=True,
verbose=1)
callbacks = [reduce_lr, early, checkpoint, logger]
model_final.fit_generator(train_generator, steps_per_epoch=train_steps_per_epoch, epochs=epochs, verbose=1,
validation_data=(val_generator), validation_steps=val_steps_per_epoch,
callbacks=callbacks,
class_weight={0: 0.012, 1: 0.12, 2: 0.058, 3: 0.36, 4: 0.43})
model_to_store_path = self.outdir + os.sep + model
model_final.save(model_to_store_path)
return model_to_store_path, train_generator.class_indices
def inference(self, model_path, test_dir, class_dict, dim=224):
print(test_dir)
model = load_model(model_path)
test_datagen = ImageDataGenerator(preprocessing_function=pre_process)
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(dim, dim),
shuffle=False,
class_mode='categorical',
batch_size=1)
filenames = test_generator.filenames
nb_samples = len(filenames)
pred = model.predict_generator(test_generator, steps=nb_samples)
print(pred)
df = pd.DataFrame()
df['filename'] = filenames
df['actual_class'] = df['filename'].apply(lambda x: x[:6])
df['actual_class_index'] = df['actual_class'].apply(lambda x: int(class_dict[x]))
df['pred_class_index'] = np.argmax(pred, axis=1)
k = list(class_dict.keys())
v = list(class_dict.values())
inv_class_dict = {}
for k_, v_ in zip(k, v):
inv_class_dict[v_] = k_
df['pred_class'] = df['pred_class_index'].apply(lambda x: (inv_class_dict[x]))
return df
def main(self):
start_time = time.time()
print('Data Processing..')
self.num_class = len(self.class_folders)
model_to_store_path, class_dict = self.train_model(self.train_dir, self.val_dir,
batch_size=self.batch_size,
epochs=self.epochs, dim=self.dim, lr=self.lr,
model=self.model)
print("Model saved to dest:", model_to_store_path)
# Validatione evaluate results
folder_path = Path(f'{self.val_dir}')
val_results_df = self.inference(model_to_store_path, folder_path, class_dict, self.dim)
val_results_path = f'{self.outdir}/val_results.csv'
val_results_df.to_csv(val_results_path, index=False)
print(f'Validation results saved at : {val_results_path}')
pred_class_index = np.array(val_results_df['pred_class_index'].values)
actual_class_index = np.array(val_results_df['actual_class_index'].values)
print(pred_class_index)
print(actual_class_index)
accuracy = np.mean(actual_class_index == pred_class_index)
kappa = cohen_kappa_score(pred_class_index, actual_class_index, weights='quadratic')
print("-----------------------------------------------------")
print(f'Validation Accuracy: {accuracy}')
print(f'Validation Quadratic Kappa Score: {kappa}')
print("-----------------------------------------------------")
print("Processing Time", time.time() - start_time, ' secs')
if __name__ == "__main__":
obj = TransferLearning()
obj.main()
其它資料下載
如果大家想繼續瞭解人工智慧相關學習路線和知識體系,歡迎大家翻閱我的另外一篇部落格《重磅 | 完備的人工智慧AI 學習——基礎知識學習路線,所有資料免關注免套路直接網路硬碟下載》
這篇部落格參考了Github知名開源平臺,AI技術平臺以及相關領域專家:Datawhale,ApacheCN,AI有道和黃海廣博士等約有近100G相關資料,希望能幫助到所有小夥伴們。