如何評估大語言模型
2023-03-29 12:00:48
大家可以使用 Hugging Face Space 上的 Evaluation on the Hub 應用在零樣本分類任務上評估大語言模型啦!
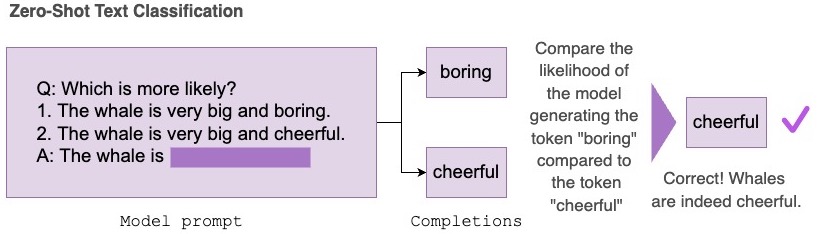
零樣本評估是研究人員衡量大語言模型效能的一種流行方法。因為大語言模型已經在訓練過程中 顯示 出了對無標註資料的學習能力。反向縮放獎 是近期社群的一項工作,通過在各種尺寸和結構的模型上進行大規模零樣本評估,以發現哪些大模型的表現比小模型還差。
在 Hub 上零樣本評估語言模型
Evaluation on the Hub 無需編寫程式碼即可幫助你評估 Hub 上的任何模型,這個能力是由 AutoTrain 賦予的。現在,Hub 上的任何因果語言模型都可以以零樣本的方式進行評估。零樣本評估會度量訓得的模型生成一組特定補全詞的可能性,且不需要任何標註訓練資料,這使得研究人員可以跳過昂貴的標註工作。
我們已經為該專案升級了 AutoTrain 基礎設施,使之可以免費評估大模型