拒絕「爆雷」!GaussDB(for MySQL)新上線了這個功能
摘要:智慧把控巨量資料量查詢,防患系統奔潰於未然。
本文分享自華為雲社群《拒絕「爆雷」!GaussDB(for MySQL)新上線了這個功能》,作者:GaussDB 資料庫。
什麼是最大讀取行
一直以來,巨量資料量查詢是資料庫DBA們調優的重點,DBA們通常十八般武藝輪番上陣以期提升巨量資料查詢的效能:例如分庫分表、給表增加索引、設定合理的WHERE查詢條件、限定單次查詢的條數……
然而,DBA再厲害,應用程式千千萬,寫程式碼的程式設計師萬碼奔騰,巨量資料量的查詢像地雷,不定什麼時候就爆了。比如隱藏在某段程式碼裡的查詢,因為一個新手程式設計師的經驗不足,查詢程式碼寫得欠佳,沒有WHERE子句或缺少索引引發了不必要的多行讀取,甚至全表掃描,給伺服器帶來了過度的壓力,導致業務執行緩慢,甚至最後伺服器OOM崩潰。
為了避免這種「爆雷」,GaussDB(for MySQL)近期上線了最大讀取行特性。優化器產生執行計劃後,如果優化器預估的讀取行數超過了所設定的最大讀取行閾值,則自動中止查詢,將雷的導火索切斷。
這種機制的優點在於:執行計劃階段就對查詢進行了干預,而不是語句開始執行後在執行過程中進行中斷。既杜絕了劣質查詢對伺服器和業務執行造成的風險,又大大節省了時間和資源。
如何設定最大讀取行
在GaussDB(for MySQL)中,設定rds_max_row_read,指定查詢允許讀取的最大行數。GaussDB(for MySQL)收到查詢指令,執行查詢之前,會對查詢要讀取的行數進行估計。當估值超過所設定的最大讀取行時,將中止查詢,即查詢沒有機會執行,提前規避不必要的資源消耗。
下面是一份測試資料,說明了開啟最大讀取行前後的差異。
假設表t1有4M大小的行,當開發人員或應用程式嘗試執行以下查詢時,執行需要7分鐘。
mysql> SELECT * FROM t1;
WHERE子句的缺失致使需要全表掃描,查詢耗時長。對於更大的表,這類查詢將需要更多的耗時,使伺服器消耗更多資源,查詢耗時甚至可能高達數小時。
最大讀取行特性的使用,可以節省寶貴的時間和資源。比如假設將最大讀取行數指定為1000000:
mysql> set rds_max_row_read =1000000; Query OK, 0 rows affected (0.00 sec)
修改後,重新執行不含WHERE子句的查詢,收到了讀取行超限的提示,查詢被停止。
mysql> SELECT * FROM t1;
ERROR HY000: Expected number of read rows exceeds the maximum allowed (see @@rds_max_row_read)
通過最大讀取行,相當於擁有了一個工具,DBA或者軟體工程師根據業務情況可以自如設定和調整限制規則,保證業務正常執行的同時,限制次優查詢,避免效能異常。
適用範圍
適用於SELECT、CREATE SELECT和INSERT SELECT。
功能開啟
預設情況下,該功能是禁用的,只有當rds_max_row_read設定了值時,該功能才會被啟用。
為了功能的穩定,避免無心的錯誤設定對業務造成不必要的影響,rds_max_row_read做了最低值限制,不允許使用者設定比最低值更低的值。
實現原理
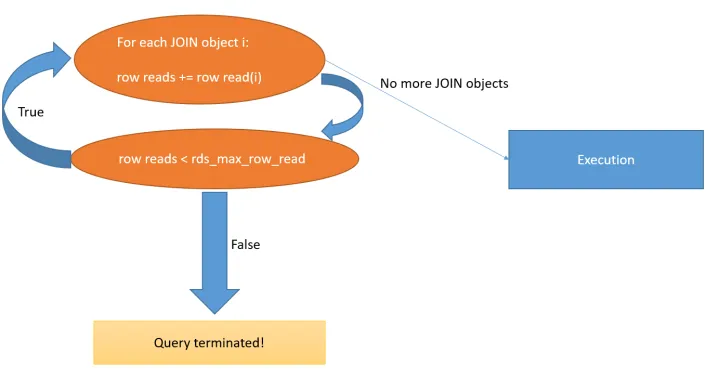
GaussDB(for MySQL)通過遍歷每個查詢塊並聚合各查詢塊的貢獻來整體評估查詢的讀取行數:也就是對各join物件的讀取行數評估後累加。
如果在累加評估過程中的某一刻,估計值超過了所設定的限制,查詢將被終止。
對於關聯子查詢,評估辦法為:評估子查詢的讀取行數,然後乘以查詢被執行的次數。
需要特別說明的是,對每個JOIN物件的估計是執行計劃預估返回的行數,可能與真實執行返回的行數有偏差。這雖然是一個相對簡單的評估模型,但是我們堅信其具有足夠的魯棒性。
對於複雜查詢,GaussDB(for MySQL)還通過optimizer trace提供了更多資訊以幫助您確定優化器做決策的原因及如何優化查詢。
範例
範例1
mysql> EXPLAIN format=tree SELECT * FROM table_1, table_2; +---------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | EXPLAIN | +---------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | -> Inner hash join (no condition) (cost=6.50 rows=54) -> Table scan on table_1 (cost=0.19 rows=9) -> Hash -> Table scan on table_2 (cost=0.85 rows=6) | +---------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) mysql> SET rds_max_row_read =20; Query OK, 0 rows affected (0.00 sec) mysql> SELECT * FROM table_1, table_2; ERROR 1888 (HY000): The expected number of read rows exceeds the allowed maximum (see @@rds_max_row_read)
查詢讀取的行太多,我們嘗試在optimizer trace的幫助下尋找原因:
SET optimizer_trace="enabled=on"; SELECT * from table_1, table_2; SELECT * FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE;
在optimizer trace中,可以找到:
{ "Max_row_read": { "select#": 1, "current_estimate_of_rows": 54, "rows_contributed_by_this_query_block": 54 } }
這表示此查詢中的唯一查詢塊,行讀取數為54。
執行計劃中的這個評估有多準確呢?
執行如下查詢檢視語句實際被執行的次數:
mysql> show status like "handler_read_rnd_next"; +----------------------------+-------+ | Variable_name | Value | +----------------------------+-------+ | Handler_read_rnd_next | 17 | +----------------------------+-------+ 1 rows in set (0.00 sec)
handler_read_rnd_next顯示實際上的讀取是17行,而不是54行。
這個17是怎麼來的呢?
這是一個雜湊連線:
-遍歷整張表時,左表有9行資料+1行額外行。
-右表有6行+1行額外行。
優化器中會預估返回讀取行,例如,54。在這個範例中,它並沒有很好地猜測到返回的行數,它高估了行讀取的數量。在大多數情況下,讀取行數的估計不夠精確,但可以肯定的是,它是足夠穩健的,能達到相應的目的。
範例2
建立例表t1:
mysql> CREATE TABLE t1(a INT);
在表中填充1536行資料後。將rds_max_row_read設定為500,進行以下測試查詢:
mysql> SELECT * FROM t1 WHERE a>6; ERROR HY000: Expected number of read rows exceeds the maximum allowed (see @@rds_max_row_read)
在optimizer trac的幫助下,可以看到優化器估計的讀取行數是512行,因此查詢被終止。如果在a欄位上新增索引(這是一件明智的事情),同一查詢的估計讀取行數是1,查詢檢測順利通過。
這個簡單的範例說明:最大讀取行能幫助您編寫更加優質的查詢語句。
結論
最大讀取行特性針對讀取過多行的查詢,識別和過濾出效率低下的查詢。使用者可以為讀取行數設定閾值,超過該閾值則終止查詢。為了識別此類查詢,GaussDB(for MySQL)在優化器中進行了讀取總行數的粗略估計。當查詢終止時,可以檢查optimizer trace,從中收集線索,以幫助重寫更高效的查詢。
簡而言之,最大讀取行為使用者提供了一個工具,使他們可以更充分地利用手上的資源。