THFuse: An infrared and visible image fusion network using transformer and hybrid feature extractor
THFuse: An infrared and visible image fusion network using transformer and hybrid feature extractor
一種基於Transformer和混合特徵提取器的紅外與可見光影象融合網路
研究背景:
- 現有的影象融合方法主要是基於折積神經網路(CNN),由於CNN的感受野較小,很難對影象的長程依賴性進行建模,忽略了影象的長程相關性,導致融合網路不能生成具有良好互補性的影象,感受野的限制直接影響融合影象的質量。
研究方法:
- 考慮到transformer的全域性注意力機制,提出了一種結合CNN和vision transformer的端到端影象融合方法來解決上述問題。
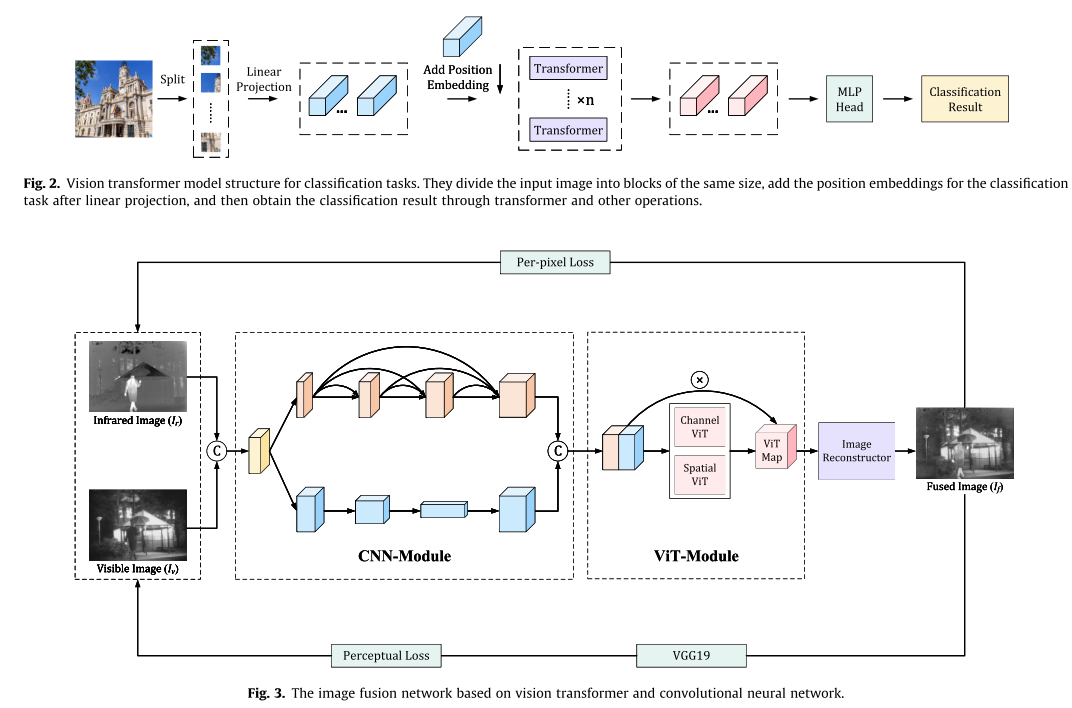
整體框架
網路是一個端到端的架構,框架包括三個部分:折積神經網路模組(CNN-module)、Vision Transformer模組(VIT-module)和影象重建模組。 前兩個模組稱為混合塊,即混合特徵提取器。
折積神經網路模組(CNN-module):由細節分支和結構分支兩部分組成。
- 細節分支:四個折積層,折積層之間有密集的連線操作來提取影象的深層特徵。 輸入特徵數為16,每層折積後的通道數為8、16、24、32。 每個折積層的核大小為3 3,步幅為1。 為了保持特徵的大小不變,我們使用反射模式來填充影象。 細節將最終輸出一組大小為256x256的特徵,包含32個通道。
- 結構分支:三個折積層。 每次折積運算後,特徵的大小是前一步的一半,以達到下取樣的目的。 每個折積層的核大小為3 x3,步幅為2。 輸入特徵的大小為256x256,通道數為16。 每次折積運算後特徵的大小分別為128x128、64x64和32x32,特徵的通道數分別為32、64和32。 為了保證該分支的通道大小和數目與前一分支一致,這裡增加了一個雙線性上取樣層,輸出32個通道、大小為256x256的特徵。
Vision Transformer模組:有空間transformer和通道transformer兩部分組成。如下圖
- 空間transformer:將影象劃分成許多patch塊(每個通道都劃分patch塊,其中一個patch與所有通道的patch進行注意力操作),將每個patch拉成向量,patch塊之間進行注意力操作。
- 通道transformer:按照影象的通道進行劃分,將通道拉成向量,不同通道之間進行注意力操作。

影象重建模組: 因為前面影象的大小沒有進行下取樣,所以重建的時候不需要上取樣,只要把影象的通道維度降下來。影象重建器設定了四個折積層,輸入特徵數為64個,每層折積後的特徵通道數為64、32、16、8和1。 每個折積層的核大小為3 3,步幅為1。 為了保持特徵的大小不變,我們使用反射模式來填充影象。

損失函數
損失函數由畫素損失和感知損失兩部分組成。
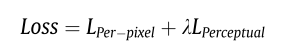
畫素損失:由三部分組成,其中LMSE是均方誤差(MSE)損失函數。LSSIM表示結構相似度(SSIM)損失函數。LTV表示總方差(TV)損失函數。
- LMSE是均方誤差(MSE)損失函數:對融合影象與源影象的每一點畫素求差值然後平方,最後平均。
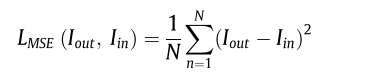
- LSSIM表示結構相似度(SSIM)損失函數:融合影象與源影象的結構相似程度。
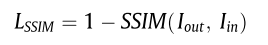
- LTV表示總方差(TV)損失函數:該函數是抑制噪聲和保留梯度資訊。 噪聲體現在影象中就是某一點梯度突變或者畫素強度突變。
p,q是影象某一點的座標,R(p,q)是融合影象與源影象之間的畫素強度差值,R(p+1,q)和R(p,q+1)是臨近點。通過約束融合影象這一點和臨近點的差值,來保留原影象的梯度資訊,並且抑制噪聲資訊。
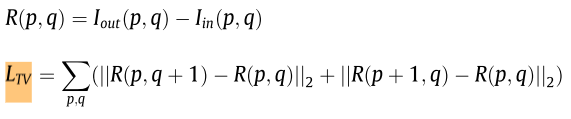
畫素損失無法代替感知損失。 例如,兩個相距僅幾個畫素的相同影象,儘管在感知上相似,但當按每個畫素的損失來衡量時,可能會有很大的不同。或者畫素損失不大,但是影象感知差別很大。
我們通過兩個影象特徵圖中的語意資訊來判斷兩個影象的最後的感知,所以我們要從特徵圖入手,上面畫素損失沒有考慮到特徵圖的畫素的重要性。
感知損失:使用預訓練的VGG19網路去提取(融合影象,源影象)多尺度的特徵。主要是想用兩個特徵的語意資訊來確定兩個特徵的感知資訊,進而確定兩個影象的感知資訊。

融合影象和可見光影象的感知損失: 使用提取的相對淺層特徵(第一層)進行計算,由於淺層特徵包含較多的結構資訊和細節資訊。
計算融合影象與紅外影象的感知損失: 使用深層次的特徵(第四層)來計算。因為紅外影象中由更多的顯著特徵,語意資訊。

結論
提出了一種基於VIT和折積神經網路的紅外與可見光影象融合方法。 由於我們的網路是端到端的型別,所以不需要對融合結果進行後期處理。 混合塊整合了CNN-模組和VIT-模組,雙分支CNN-模組具有更強的特徵提取能力。 VIT-module的加入使網路能夠同時考慮影象的區域性資訊和全域性資訊,避免了傳統CNN網路遠端依賴性差的問題。 另外,我們利用預訓練的VGG19網路提取不同的特徵來計算損失,有針對性地保留不同型別的影象資訊。
影象融合的最終目的是與其他計算機視覺任務相結合並使之更好,因此我們接下來將嘗試在其他計算機視覺任務的驅動下利用影象融合來改善原有的結果。
雖然本文的重點是紅外和可見光影象融合,但本文提出的網路可以用於其他影象融合領域。 今後我們將嘗試將該方法應用於多曝光和醫學影象融合。
貢獻點
-
提出了一種混合特徵提取器,將雙分支CNN和VIT相結合,實現了影象區域性資訊和全域性資訊的同時提取。
-
對VIT的網路結構進行了改進,使其更適合於影象融合。 另外,將transfomer使用在影象的通道維度上。
-
設計了一個有針對性的感知損失函數。 通過計算不同深度特徵的損失,融合影象可以保留更多的紋理細節和顯著資訊。
參考原文:https://www.x-mol.com/paper/1613633839666642944?adv