什麼是原子操作?深入淺析go中的原子操作

在我們前面的一些介紹 sync 包相關的文章中,我們應該也發現了,其中有不少地方使用了原子操作。
比如 sync.WaitGroup、sync.Map 再到 sync.Pool,這些結構體的實現中都有原子操作的身影。
原子操作在並行程式設計中是一種非常重要的操作,它可以保證並行安全,而且效率也很高。
本文將會深入探討一下 go 中原子操作的原理、使用場景、用法等內容。
什麼是原子操作?
原子操作是變數級別的互斥鎖。
如果讓我用一句話來說明什麼是原子操作,那就是:原子操作是變數級別的互斥鎖。簡單來說,就是同一時刻,只能有一個 CPU 對變數進行讀或寫。
當我們想要對某個變數做並行安全的修改,除了使用官方提供的 Mutex,還可以使用 sync/atomic 包的原子操作,
它能夠保證對變數的讀取或修改期間不被其他的協程所影響。
我們可以用下圖來表示:
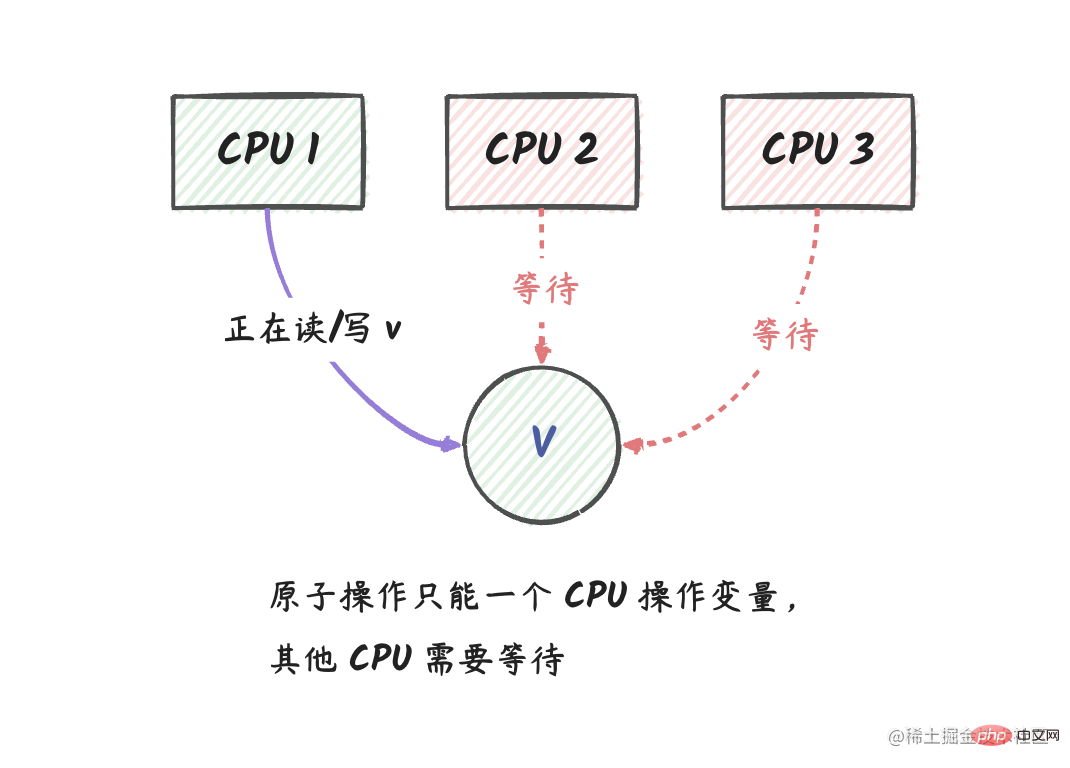
說明:在上圖中,我們有三個 CPU 邏輯核,其中 CPU 1 正在對變數 v 做原子操作,這個時候 CPU 2 和 CPU 3 不能對 v 做任何操作,
在 CPU 1 操作完成後,CPU 2 和 CPU 3 可以獲取到 v 的最新值。
從這個角度看,我們可以把
sync/atomic包中的原子操作看成是變數級別的互斥鎖。 就是說,在 go 中,當一個協程對變數做原子操作時,其他協程不能對這個變數做任何操作,直到這個協程操作完成。
原子操作的使用場景是什麼?
拿一個簡單的例子來說明一下原子操作的使用場景:
func TestAtomic(t *testing.T) {
var sum = 0
var wg sync.WaitGroup
wg.Add(1000)
// 啟動 1000 個協程,每個協程對 sum 做加法操作
for i := 0; i < 1000; i++ {
go func() {
defer wg.Done()
sum++
}()
}
// 等待所有的協程都執行完畢
wg.Wait()
fmt.Println(sum) // 這裡輸出多少呢?
}登入後複製我們可以在自己的電腦上執行一下這段程式碼,看看輸出的結果是多少。 不出意外的話,應該每次可能都不一樣,而且應該也不是 1000,這是為什麼呢?
這是因為,CPU 在對 sum 做加法的時候,需要先將 sum 目前的值讀取到 CPU 的暫存器中,然後再進行加法操作,最後再寫回到記憶體中。
如果有兩個 CPU 同時取了 sum 的值,然後都進行了加法操作,然後都再寫回到記憶體中,那麼就會導致 sum 的值被覆蓋,從而導致結果不正確。
舉個例子,目前記憶體中的 sum 為 1,然後兩個 CPU 同時取了這個 1 來做加法,然後都得到了結果 2,
然後這兩個 CPU 將各自的計算結果寫回到記憶體中,那麼記憶體中的 sum 就變成了 2,而不是 3。
在這種場景下,我們可以使用原子操作來實現並行安全的加法操作:
func TestAtomic1(t *testing.T) {
// 將 sum 的型別改成 int32,因為原子操作只能針對 int32、int64、uint32、uint64、uintptr 這幾種型別
var sum int32 = 0
var wg sync.WaitGroup
wg.Add(1000)
// 啟動 1000 個協程,每個協程對 sum 做加法操作
for i := 0; i < 1000; i++ {
go func() {
defer wg.Done()
// 將 sum++ 改成下面這樣
atomic.AddInt32(&sum, 1)
}()
}
wg.Wait()
fmt.Println(sum) // 輸出 1000
}登入後複製在上面這個例子中,我們每次執行都能得到 1000 這個結果。
因為使用原子操作的時候,同一時刻只能有一個 CPU 對變數進行讀或寫,所以就不會出現上面的問題了。
所以很多需要對變數做並行讀寫的地方,我們都可以考慮一下,是否可以使用原子操作來實現並行安全的操作(而不是使用互斥鎖,互斥鎖效率相比原子操作要低一些)。
原子操作的使用場景也是和互斥鎖類似的,但是不一樣的是,我們的鎖粒度只是一個變數而已。也就是說,當我們不允許多個 CPU 同時對變數進行讀寫的時候(保證變數同一時刻只能一個 CPU 操作),就可以使用原子操作。
原子操作是怎麼實現的?
看完上面原子操作的介紹,有沒有覺得原子操作很神奇,居然有這麼好用的東西。那它到底是怎麼實現的呢?
一般情況下,原子操作的實現需要特殊的 CPU 指令或者系統呼叫。 這些指令或者系統呼叫可以保證在執行期間不會被其他操作或事件中斷,從而保證操作的原子性。
例如,在 x86 架構的 CPU 中,可以使用 LOCK 字首來實現原子操作。LOCK 字首可以與其他指令一起使用,用於鎖定記憶體匯流排,防止其他 CPU 存取同一記憶體地址,從而實現原子操作。
在使用 LOCK 字首的指令執行期間,CPU 會將當前處理器快取中的資料寫回到記憶體中,並鎖定該記憶體地址,
防止其他 CPU 修改該地址的資料(所以原子操作總是可以讀取到最新的資料)。
一旦當前 CPU 對該地址的操作完成,CPU 會釋放該記憶體地址的鎖定,其他 CPU 才能繼續對該地址進行存取。
x86 LOCK 的時候發生了什麼
我們再來捋一下上面的內容,看看 LOCK 字首是如何實現原子操作的:
- CPU 會將當前處理器快取中的資料寫回到記憶體中。(因此我們總能讀取到最新的資料)
- 然後鎖定該記憶體地址,防止其他 CPU 修改該地址的資料。
- 一旦當前 CPU 對該地址的操作完成,CPU 會釋放該記憶體地址的鎖定,其他 CPU 才能繼續對該地址進行存取。
其他架構的 CPU 可能會略有不同,但是原理是一樣的。
原子操作有什麼特徵?
- 不會被中斷:原子操作是一個不可分割的操作,要麼全部執行,要麼全部不執行,不會出現中間狀態。這是保證原子性的基本前提。同時,原子操作過程中不會有上下文切換的過程。
- 操作物件是共用變數:原子操作通常是對共用變數進行的,也就是說,多個協程可以同時存取這個變數,因此需要採用原子操作來保證資料的一致性和正確性。
- 並行安全:原子操作是並行安全的,可以保證多個協程同時進行操作時不會出現資料競爭問題(雖然說是同時,但是實際上在操作那個變數的時候是互斥的)。
- 無需加鎖:原子操作不需要使用互斥鎖來保證資料的一致性和正確性,因此可以避免互斥鎖的使用帶來的效能損失。
- 適用場景比較侷限:原子操作適用於操作單個變數,如果需要同時並行讀寫多個變數,可能需要考慮使用互斥鎖。
go 裡面有哪些原子操作?
在 go 中,主要有以下幾種原子操作:Add、CompareAndSwap、Load、Store、Swap。
增減(Add)
- 用於進行增加或減少的原子操作,函數名以
Add為字首,字尾針對特定型別的名稱。 - 原子增被操作的型別只能是數值型別,即
int32、int64、uint32、uint64、uintptr - 原子增減函數的第一個引數為原值,第二個引數是要增減多少。
- 方法:
func AddInt32(addr *int32, delta int32) (new int32)
func AddInt64(addr *int64, delta int64) (new int64)
func AddUint32(addr *uint32, delta uint32) (new uint32)
func AddUint64(addr *uint64, delta uint64) (new uint64)
func AddUintptr(addr *uintptr, delta uintptr) (new uintptr)
登入後複製
int32和int64的第二個引數可以是負數,這樣就可以做原子減法了。
比較並交換(CompareAndSwap)
也就是我們常見的 CAS,在 CAS 操作中,會需要拿舊的值跟 old 比較,如果相等,就將 new 賦值給 addr。
如果不相等,則不做任何操作。最後返回一個 bool 值,表示是否成功 swap。
也就是說,這個操作可能是不成功的。這很正常,在並行環境下,多個協程對同一個變數進行操作,肯定會存在競爭的情況。 在這種情況下,偶爾的失敗是正常的,我們只需要在失敗的時候,重新嘗試即可。 因為原子操作需要的時間往往是比較短的,因此在失敗的時候,我們可以通過自旋的方式來再次進行嘗試。
在這種情況下,如果不自旋,那就需要將這個協程掛起,等待其他協程完成操作,然後再次嘗試。這個過程相比自旋可能會更加耗時。 因為很有可能這次原子操作不成功,下一次就成功了。如果我們每次都將協程掛起,那麼效率就會大大降低。
for + 原子操作的方式,在 go 的 sync 包中很多地方都有使用,比如 sync.Map,sync.Pool 等。
這也是使用原子操作時一個非常常見的使用模式。
CompareAndSwap 的功能:
- 用於比較並交換的原子操作,函數名以
CompareAndSwap為字首,字尾針對特定型別的名稱。 - 原子比較並交換被操作的型別可以是數值型別或指標型別,即
int32、int64、uint32、uint64、uintptr、unsafe.Pointer - 原子比較並交換函數的第一個引數為原值指標,第二個引數是要比較的值,第三個引數是要交換的值。
- 方法:
func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool)
func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool)
func CompareAndSwapUint32(addr *uint32, old, new uint32) (swapped bool)
func CompareAndSwapUint64(addr *uint64, old, new uint64) (swapped bool)
func CompareAndSwapUintptr(addr *uintptr, old, new uintptr) (swapped bool)
func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool)
登入後複製載入(Load)
原子性的讀取操作接受一個對應型別的指標值,返回該指標指向的值。原子性讀取意味著讀取值的同時,當前計算機的任何 CPU 都不會進行鍼對值的讀寫操作。
如果不使用原子 Load,當使用 v := value 這種賦值方式為變數 v 賦值時,讀取到的 value 可能不是最新的,因為在讀取操作時其他協程對它的讀寫操作可能會同時發生。
Load 操作有下面這些:
func LoadInt32(addr *int32) (val int32)
func LoadInt64(addr *int64) (val int64)
func LoadUint32(addr *uint32) (val uint32)
func LoadUint64(addr *uint64) (val uint64)
func LoadUintptr(addr *uintptr) (val uintptr)
func LoadPointer(addr *unsafe.Pointer) (val unsafe.Pointer)
登入後複製儲存(Store)
Store 可以將 val 值儲存到 *addr 中,Store 操作是原子性的,因此在執行 Store 操作時,當前計算機的任何 CPU 都不會進行鍼對 *addr 的讀寫操作。
- 原子性儲存會將
val值儲存到*addr中。 - 與讀操作對應的寫入操作,
sync/atomic提供了與原子值載入Load函數相對應的原子值儲存Store函數,原子性儲存函數均以Store為字首。
Store 操作有下面這些:
func StoreInt32(addr *int32, val int32)
func StoreInt64(addr *int64, val int64)
func StoreUint32(addr *uint32, val uint32)
func StoreUint64(addr *uint64, val uint64)
func StoreUintptr(addr *uintpre, val uintptr)
func StorePointer(addr *unsafe.Pointer, val unsafe.Pointer)
登入後複製交換(Swap)
Swap 跟 Store 有點類似,但是它會返回 *addr 的舊值。
func SwapInt32(addr *int32, new int32) (old int32)
func SwapInt64(addr *int64, new int64) (old int64)
func SwapUint32(addr *uint32, new uint32) (old uint32)
func SwapUint64(addr *uint64, new uint64) (old uint64)
func SwapUintptr(addr *uintptr, new uintptr) (old uintptr)
func SwapPointer(addr *unsafe.Pointer, new unsafe.Pointer) (old unsafe.Pointer)
登入後複製原子操作任意型別的值 - atomic.Value
從上一節中,我們知道了在 go 中原子操作可以操作 int32、int64、uint32、uint64、uintptr、unsafe.Pointer 這些型別的值。
但是在實際開發中,我們的型別還有很多,比如 string、struct 等等,那這些型別的值如何進行原子操作呢?答案是使用 atomic.Value。
atomic.Value 是一個結構體,它的內部有一個 any 型別的欄位,儲存了我們要原子操作的值,也就是一個任意型別的值。
atomic.Value 支援以下操作:
Load:原子性的讀取Value中的值。Store:原子性的儲存一個值到Value中。Swap:原子性的交換Value中的值,返回舊值。CompareAndSwap:原子性的比較並交換Value中的值,如果舊值和old相等,則將new存入Value中,返回true,否則返回false。
atomic.Value 的這些操作跟上面講到的那些操作其實差不多,只不過 atomic.Value 可以操作任意型別的值。
那 atomic.Value 是如何實現的呢?
atomic.Value 原始碼分析
atomic.Value 是一個結構體,這個結構體只有一個欄位:
// Value 提供一致型別值的原子載入和儲存。
type Value struct {
v any
}登入後複製Load - 讀取
Load 返回由最近的 Store 設定的值。如果還沒有 Store 過任何值,則返回 nil。
// Load 返回由最近的 Store 設定的值。
func (v *Value) Load() (val any) {
// atomic.Value 轉換為 efaceWords
vp := (*efaceWords)(unsafe.Pointer(v))
// 判斷 atomic.Value 的型別
typ := LoadPointer(&vp.typ)
// 第一次 Store 還沒有完成,直接返回 nil
if typ == nil || typ == unsafe.Pointer(&firstStoreInProgress) {
// firstStoreInProgress 是一個特殊的變數,儲存到 typ 中用來表示第一次 Store 還沒有完成
return nil
}
// 獲取 atomic.Value 的值
data := LoadPointer(&vp.data)
// 將 val 轉換為 efaceWords 型別
vlp := (*efaceWords)(unsafe.Pointer(&val))
// 分別賦值給 val 的 typ 和 data
vlp.typ = typ
vlp.data = data
return
}登入後複製在 atomic.Value 的原始碼中,我們都可以看到 efaceWords 的身影,它實際上代表的是 interface{}/any 型別:
// 表示一個 interface{}/any 型別
type efaceWords struct {
typ unsafe.Pointer
data unsafe.Pointer
}登入後複製看到這裡我們會不會覺得很困惑,直接返回 val 不就可以了嗎?為什麼要將 val 轉換為 efaceWords 型別呢?
這是因為 go 中的原子操作只能操作 int32、int64、uint32、uint64、uintptr、unsafe.Pointer 這些型別的值,
不支援 interface{} 型別,但是如果瞭解 interface{} 底層結構的話,我們就知道 interface{} 底層其實就是一個結構體,
它有兩個欄位,一個是 type,一個是 data,type 用來儲存 interface{} 的型別,data 用來儲存 interface{} 的值。
而且這兩個欄位都是 unsafe.Pointer 型別的,所以其實我們可以對 interface{} 的 type 和 data 分別進行原子操作,
這樣最終其實也可以達到了原子操作 interface{} 的目的了,是不是非常地巧妙呢?
Store - 儲存
Store 將 Value 的值設定為 val。對給定值的所有儲存呼叫必須使用相同具體型別的值。不一致型別的儲存會發生恐慌,Store(nil) 也會 panic。
// Store 將 Value 的值設定為 val。
func (v *Value) Store(val any) {
// 不能儲存 nil 值
if val == nil {
panic("sync/atomic: store of nil value into Value")
}
// atomic.Value 轉換為 efaceWords
vp := (*efaceWords)(unsafe.Pointer(v))
// val 轉換為 efaceWords
vlp := (*efaceWords)(unsafe.Pointer(&val))
// 自旋進行原子操作,這個過程不會很久,開銷相比互斥鎖小
for {
// LoadPointer 可以保證獲取到的是最新的
typ := LoadPointer(&vp.typ)
// 第一次 store 的時候 typ 還是 nil,說明是第一次 store
if typ == nil {
// 嘗試開始第一次 Store。
// 禁用搶佔,以便其他 goroutines 可以自旋等待完成。
// (如果允許搶佔,那麼其他 goroutine 自旋等待的時間可能會比較長,因為可能會需要進行協程排程。)
runtime_procPin()
// 搶佔失敗,意味著有其他 goroutine 成功 store 了,允許搶佔,再次嘗試 Store
// 這也是一個原子操作。
if !CompareAndSwapPointer(&vp.typ, nil, unsafe.Pointer(&firstStoreInProgress)) {
runtime_procUnpin()
continue
}
// 完成第一次 store
// 因為有 firstStoreInProgress 標識的保護,所以下面的兩個原子操作是安全的。
StorePointer(&vp.data, vlp.data) // 儲存值(原子操作)
StorePointer(&vp.typ, vlp.typ) // 儲存型別(原子操作)
runtime_procUnpin() // 允許搶佔
return
}
// 另外一個 goroutine 正在進行第一次 Store。自旋等待。
if typ == unsafe.Pointer(&firstStoreInProgress) {
continue
}
// 第一次 Store 已經完成了,下面不是第一次 Store 了。
// 需要檢查當前 Store 的型別跟第一次 Store 的型別是否一致,不一致就 panic。
if typ != vlp.typ {
panic("sync/atomic: store of inconsistently typed value into Value")
}
// 後續的 Store 只需要 Store 值部分就可以了。
// 因為 atomic.Value 只能儲存一種型別的值。
StorePointer(&vp.data, vlp.data)
return
}
}登入後複製在 Store 中,有以下幾個注意的點:
- 使用
firstStoreInProgress來確保第一次Store的時候,只有一個goroutine可以進行Store操作,其他的goroutine需要自旋等待。如果沒有這個保護,那麼儲存typ和data的時候就會出現競爭(因為需要兩個原子操作),導致資料不一致。在這裡其實可以將firstStoreInProgress看作是一個互斥鎖。 - 在進行第一次
Store的時候,會將當前的 goroutine 和P繫結,這樣拿到firstStoreInProgress鎖的協程就可以儘快地完成第一次Store操作,這樣一來,其他的協程也不用等待太久。 - 在第一次
Store的時候,會有兩個原子操作,分別儲存型別和值,但是因為有firstStoreInProgress的保護,所以這兩個原子操作本質上是對interface{}的一個原子儲存操作。 - 其他協程在看到有
firstStoreInProgress標識的時候,就會自旋等待,直到第一次Store完成。 - 在後續的
Store操作中,只需要儲存值就可以了,因為atomic.Value只能儲存一種型別的值。
Swap - 交換
Swap 將 Value 的值設定為 new 並返回舊值。對給定值的所有交換呼叫必須使用相同具體型別的值。同時,不一致型別的交換會發生恐慌,Swap(nil) 也會 panic。
// Swap 將 Value 的值設定為 new 並返回舊值。
func (v *Value) Swap(new any) (old any) {
// 不能儲存 nil 值
if new == nil {
panic("sync/atomic: swap of nil value into Value")
}
// atomic.Value 轉換為 efaceWords
vp := (*efaceWords)(unsafe.Pointer(v))
// new 轉換為 efaceWords
np := (*efaceWords)(unsafe.Pointer(&new))
// 自旋進行原子操作,這個過程不會很久,開銷相比互斥鎖小
for {
// 下面這部分程式碼跟 Store 一樣,不細說了。
// 這部分程式碼是進行第一次儲存的程式碼。
typ := LoadPointer(&vp.typ)
if typ == nil {
runtime_procPin()
if !CompareAndSwapPointer(&vp.typ, nil, unsafe.Pointer(&firstStoreInProgress)) {
runtime_procUnpin()
continue
}
StorePointer(&vp.data, np.data)
StorePointer(&vp.typ, np.typ)
runtime_procUnpin()
return nil
}
if typ == unsafe.Pointer(&firstStoreInProgress) {
continue
}
if typ != np.typ {
panic("sync/atomic: swap of inconsistently typed value into Value")
}
// ---- 下面是 Swap 的特有邏輯 ----
// op 是返回值
op := (*efaceWords)(unsafe.Pointer(&old))
// 返回舊的值
op.typ, op.data = np.typ, SwapPointer(&vp.data, np.data)
return old
}
}登入後複製CompareAndSwap - 比較並交換
CompareAndSwap 將 Value 的值與 old 比較,如果相等則設定為 new 並返回 true,否則返回 false。
對給定值的所有比較和交換呼叫必須使用相同具體型別的值。同時,不一致型別的比較和交換會發生恐慌,CompareAndSwap(nil, nil) 也會 panic。
// CompareAndSwap 比較並交換。
func (v *Value) CompareAndSwap(old, new any) (swapped bool) {
// 注意:old 是可以為 nil 的,new 不能為 nil。
// old 是 nil 表示是第一次進行 Store 操作。
if new == nil {
panic("sync/atomic: compare and swap of nil value into Value")
}
// atomic.Value 轉換為 efaceWords
vp := (*efaceWords)(unsafe.Pointer(v))
// new 轉換為 efaceWords
np := (*efaceWords)(unsafe.Pointer(&new))
// old 轉換為 efaceWords
op := (*efaceWords)(unsafe.Pointer(&old))
// old 和 new 型別必須一致,且不能為 nil
if op.typ != nil && np.typ != op.typ {
panic("sync/atomic: compare and swap of inconsistently typed values")
}
// 自旋進行原子操作,這個過程不會很久,開銷相比互斥鎖小
for {
// LoadPointer 可以保證獲取到的 typ 是最新的
typ := LoadPointer(&vp.typ)
if typ == nil { // atomic.Value 是 nil,還沒 Store 過
// 準備進行第一次 Store,但是傳遞進來的 old 不是 nil,compare 這一步就失敗了。直接返回 false
if old != nil {
return false
}
// 下面這部分程式碼跟 Store 一樣,不細說了。
// 這部分程式碼是進行第一次儲存的程式碼。
runtime_procPin()
if !CompareAndSwapPointer(&vp.typ, nil, unsafe.Pointer(&firstStoreInProgress)) {
runtime_procUnpin()
continue
}
StorePointer(&vp.data, np.data)
StorePointer(&vp.typ, np.typ)
runtime_procUnpin()
return true
}
if typ == unsafe.Pointer(&firstStoreInProgress) {
continue
}
if typ != np.typ {
panic("sync/atomic: compare and swap of inconsistently typed value into Value")
}
// 通過執行時相等性檢查比較舊版本和當前版本。
// 這允許對值型別進行比較,這是包函數所沒有的。
// 下面的 CompareAndSwapPointer 僅確保 vp.data 自 LoadPointer 以來沒有更改。
data := LoadPointer(&vp.data)
var i any
(*efaceWords)(unsafe.Pointer(&i)).typ = typ
(*efaceWords)(unsafe.Pointer(&i)).data = data
if i != old { // atomic.Value 跟 old 不相等
return false
}
// 只做 val 部分的 cas 操作
return CompareAndSwapPointer(&vp.data, data, np.data)
}
}登入後複製這裡需要特別說明的只有最後那個比較相等的判斷,也就是 data := LoadPointer(&vp.data) 以及往後的幾行程式碼。
在開發 atomic.Value 第一版的時候,那個開發者其實是將這幾行寫成 CompareAndSwapPointer(&vp.data, old.data, np.data) 這種形式的。
但是在舊的寫法中,會存在一個問題,如果我們做 CAS 操作的時候,如果傳遞的引數 old 是一個結構體的值這種型別,那麼這個結構體的值是會被拷貝一份的,
同時再會被轉換為 interface{}/any 型別,這個過程中,其實引數的 old 的 data 部分指標指向的記憶體跟 vp.data 指向的記憶體是不一樣的。
這樣的話,CAS 操作就會失敗,這個時候就會返回 false,但是我們本意是要比較它的值,出現這種結果顯然不是我們想要的。
將值作為
interface{}引數使用的時候,會存在一個將值轉換為interface{}的過程。具體我們可以看看interface{}的實現原理。
所以,在上面的實現中,會將舊值的 typ 和 data 賦值給一個 any 型別的變數,
然後使用 i != old 這種方式進行判斷,這樣就可以實現在比較的時候,比較的是值,而不是由值轉換為 interface{} 後的指標。
其他原子型別
我們現在知道了,atomic.Value 可以對任意型別做原子操作。
而對於其他的原子型別,比如 int32、int64、uint32、uint64、uintptr、unsafe.Pointer 等,
其實在 go 中也提供了包裝的型別,讓我們可以以物件的方式來操作這些型別。
對應的型別如下:
atomic.Bool:這個比較特別,但底層實際上是一個uint32型別的值。我們對atomic.Bool做原子操作的時候,實際上是對uint32做原子操作。atomic.Int32:int32型別的包裝型別atomic.Int64:int64型別的包裝型別atomic.Uint32:uint32型別的包裝型別atomic.Uint64:uint64型別的包裝型別atomic.Uintptr:uintptr型別的包裝型別atomic.Pointer:unsafe.Pointer型別的包裝型別
這幾種型別的實現的程式碼基本一樣,除了型別不一樣,我們可以看看 atomic.Int32 的實現:
// An Int32 is an atomic int32. The zero value is zero.
type Int32 struct {
_ noCopy
v int32
}
// Load atomically loads and returns the value stored in x.
func (x *Int32) Load() int32 { return LoadInt32(&x.v) }
// Store atomically stores val into x.
func (x *Int32) Store(val int32) { StoreInt32(&x.v, val) }
// Swap atomically stores new into x and returns the previous value.
func (x *Int32) Swap(new int32) (old int32) { return SwapInt32(&x.v, new) }
// CompareAndSwap executes the compare-and-swap operation for x.
func (x *Int32) CompareAndSwap(old, new int32) (swapped bool) {
return CompareAndSwapInt32(&x.v, old, new)
}登入後複製可以看到,atomic.Int32 的實現都是基於 atomic 包中 int32 型別相關的原子操作函數來實現的。
原子操作與互斥鎖比較
那我們有了互斥鎖,為什麼還要有原子操作呢?我們進行比較一下就知道了:
| 原子操作 | 互斥鎖 | |
|---|---|---|
| 保護的範圍 | 變數 | 程式碼塊 |
| 保護的粒度 | 小 | 大 |
| 效能 | 高 | 低 |
| 如何實現的 | 硬體指令 | 軟體層面實現,邏輯較多 |
如果我們只需要對某一個變數做並行讀寫,那麼使用原子操作就可以了,因為原子操作的效能比互斥鎖高很多。 但是如果我們需要對多個變數做並行讀寫,那麼就需要用到互斥鎖了,這種場景往往是在一段程式碼中對不同變數做讀寫。
效能比較
我們前面這個表格提到了原子操作與互斥鎖效能上有差異,我們寫幾行程式碼來進行比較一下:
// 系統資訊 cpu: Intel(R) Core(TM) i7-8700 CPU @ 3.20GHz
// 10.13 ns/op
func BenchmarkMutex(b *testing.B) {
var mu sync.Mutex
for i := 0; i < b.N; i++ {
mu.Lock()
mu.Unlock()
}
}
// 5.849 ns/op
func BenchmarkAtomic(b *testing.B) {
var sum atomic.Uint64
for i := 0; i < b.N; i++ {
sum.Add(uint64(1))
}
}登入後複製在對 Mutex 的效能測試中,我只是寫了簡單的 Lock() 和 UnLock() 操作,因為這種比較才算是對 Mutex 本身的測試,而在 Atomic 的效能測試中,對 sum 做原子累加的操作。最終結果是,使用 Atomic 的操作耗時大概比 Mutex 少了 40% 以上。
在實際開發中,
Mutex保護的臨界區內往往有更多操作,也就意味著Mutex鎖需要耗費更長的時間才能釋放,也就是會需要耗費比上面這個40%還要多的時間另外一個協程才能獲取到Mutex鎖。
go 的 sync 包中的原子操作
在文章的開頭,我們就說了,在 go 的 sync.Map 和 sync.Pool 中都有用到了原子操作,本節就來看一看這些操作。
sync.Map 中的原子操作
在 sync.Map 中使用到了一個 entry 結構體,這個結構體中大部分操作都是原子操作,我們可以看看它下面這兩個方法的定義:
// 刪除 entry
func (e *entry) delete() (value any, ok bool) {
for {
p := e.p.Load()
// 已經被刪除了,不需要再刪除
if p == nil || p == expunged {
return nil, false
}
// 刪除成功
if e.p.CompareAndSwap(p, nil) {
return *p, true
}
}
}
// 如果條目尚未刪除,trySwap 將交換一個值。
func (e *entry) trySwap(i *any) (*any, bool) {
for {
p := e.p.Load()
// 已經被刪除了
if p == expunged {
return nil, false
}
// swap 成功
if e.p.CompareAndSwap(p, i) {
return p, true
}
}
}登入後複製我們可以看到一個非常典型的特徵就是 for + CompareAndSwap 的組合,這個組合在 entry 中出現了很多次。
如果我們也需要對變數做並行讀寫,也可以嘗試一下這種 for + CompareAndSwap 的組合。
sync.WaitGroup 中的原子操作
在 sync.WaitGroup 中有一個型別為 atomic.Uint64 的 state 欄位,這個變數是用來記錄 WaitGroup 的狀態的。
在實際使用中,它的高 32 位用來記錄 WaitGroup 的計數器,低 32 位用來記錄 WaitGroup 的 Waiter 的數量,也就是等待條件變數滿足的協程數量。
如果不使用一個變數來記錄這兩個值,那麼我們就需要使用兩個變數來記錄,這樣就會導致我們需要對兩個變數做並行讀寫, 在這種情況下,我們就需要使用互斥鎖來保護這兩個變數,這樣就會導致效能的下降。
而使用一個變數來記錄這兩個值,我們就可以使用原子操作來保護這個變數,這樣就可以保證並行讀寫的安全性,同時也能得到更好的效能:
// WaitGroup 的 Add 函數:高 32 位加上 delta
state := wg.state.Add(uint64(delta) << 32)
// WaitGroup 的 Wait 函數:低 32 位加 1
// 等待者的數量加 1
wg.state.CompareAndSwap(state, state+1)
登入後複製CAS 操作有失敗必然有成功
當然這裡是指指向同一行 CAS 程式碼的時候(也就是有競爭的時候),如果是指向不同行 CAS 程式碼的時候,那麼就不一定了。
比如下面這個例子,我們把前面計算 sum 的例子改一改,改成用 CAS 操作來完成:
func TestCas(t *testing.T) {
var sum int32 = 0
var wg sync.WaitGroup
wg.Add(1000)
for i := 0; i < 1000; i++ {
go func() {
defer wg.Done()
// 這一行是有可能會失敗的
atomic.CompareAndSwapInt32(&sum, sum, sum+1)
}()
}
wg.Wait()
fmt.Println(sum) // 不是 1000
}登入後複製在這個例子中,我們把 atomic.AddInt32(&sum, 1) 改成了 atomic.CompareAndSwapInt32(&sum, sum, sum+1),
這樣就會導致有可能會有多個 goroutine 同時執行到 atomic.CompareAndSwapInt32(&sum, sum, sum+1) 這一行程式碼,
這樣肯定會有不同的 goroutine 同時拿到一個相同的 sum 的舊值,那麼在這種情況下,就會導致 CAS 操作失敗。
也就是說,將 sum 替換為 sum + 1 的操作可能會失敗。
失敗意味著什麼呢?意味著另外一個協程式先把 sum 的值加 1 了,這個時候其實我們不應該在舊的 sum 上加 1 了,
而是應該在最新的 sum 上加上 1,那我們應該怎麼做呢?我們可以在 CAS 操作失敗的時候,重新獲取 sum 的值,
然後再次嘗試 CAS 操作,直到成功為止:
func TestCas(t *testing.T) {
var sum int32 = 0
var wg sync.WaitGroup
wg.Add(1000)
for i := 0; i < 1000; i++ {
go func() {
defer wg.Done()
// cas 失敗的時候,重新獲取 sum 的值進行計算。
// cas 成功則返回。
for {
if atomic.CompareAndSwapInt32(&sum, sum, sum+1) {
return
}
}
}()
}
wg.Wait()
fmt.Println(sum)
}登入後複製總結
原子操作是並行程式設計中非常重要的一個概念,它可以保證並行讀寫的安全性,同時也能得到更好的效能。
最後,總結一下本文講到的內容:
- 原子操作是更加底層的操作,它保護的是單個變數,而互斥鎖可以保護一個程式碼片段,它們的使用場景是不一樣的。
- 原子操作需要通過 CPU 指令來實現,而互斥鎖是在軟體層面實現的。
- go 裡面的原子操作有以下這些:
Add:原子增減CompareAndSwap:原子比較並交換Load:原子讀取Store:原子寫入Swap:原子交換
- go 裡面所有型別都能使用原子操作,只是不同型別的原子操作使用的函數不太一樣。
atomic.Value可以用來原子操作任意型別的變數。- go 裡面有些底層實現也使用了原子操作,比如:
sync.WaitGroup:使用原子操作來保證計數器和等待者數量的並行讀寫安全性。sync.Map:entry結構體中基本所有操作都有原子操作的身影。
- 原子操作有失敗必然有成功(說的是同一行
CAS操作),如果CAS操作失敗了,那麼我們可以重新獲取舊值,然後再次嘗試CAS操作,直到成功為止。
總的來說,原子操作本身其實沒有太複雜的邏輯,我們理解了它的原理之後,就可以很容易的使用它了。
推薦學習:
以上就是什麼是原子操作?深入淺析go中的原子操作的詳細內容,更多請關注TW511.COM其它相關文章!