解密Prompt系列4. 升級Instruction Tuning:Flan/T0/InstructGPT/TKInstruct
這一章我們聊聊指令微調,指令微調和前3章介紹的prompt有什麼關係呢?哈哈只要你細品,你就會發現大家對prompt和instruction的定義存在些出入,部分認為instruction是prompt的子集,部分認為instruction是句子型別的prompt。
對比前三章介紹過的主流prompt正規化,指令微調有如下特點
- 面向大模型:指令微調任務的核心是釋放模型已有的指令理解能力(GPT3中首次提出),因此指令微調是針對大模型設計的,因為指令理解是大模型的湧現能力之一。而prompt部分是面向常規模型例如BERT
- 預訓練:與其說是instruction tunning,更像是instruction pretraining,是在預訓練階段融入多樣的NLP指令微調,而非針對特定下游任務進行微調,而之前的promp主要服務微調和zeroshot場景
- multitask:以下模型設計了不同的指令微調資料集,但核心都是多樣性,差異化,覆蓋更廣泛的NLP任務,而之前的prompt模型多數有特定的任務指向
- 泛化性:在大模型上進行指令微調有很好的泛化性,在樣本外指令上也會存在效果提升
- 適用模型:考慮指令都是都是sentence形式的,因此只適用於En-Dn,Decoder only類的模型。而之前的prompt部分是面向Encoder的完形填空型別
下面我們介紹幾個指令微調相關的模型,模型都還是那個熟悉的模型,核心的差異在於微調的指令資料集不同,以及評估側重點不同,每個模型我們只側重介紹差異點。按時間順序分別是Flan, T0,InstructGPT, TK-Instruct
Google: Flan
- paper: 2021.9 Finetuned Langauge Models are zero-shot learners
- github:https://github.com/google-research/FLAN
- 模型:137B LaMDA-PT
- 一言以蔽之:搶佔先機,Google第一個提出指令微調可以解鎖大模型指令理解能力
谷歌的Flan是第一個提出指令微調正規化的,目的和標題相同使用指令微調來提升模型的zero-shot能力。論文使用的是137B的LAMDA-PT一個在web,程式碼,對話, wiki上預訓練的單向語言模型。
指令集
在構建資料集上,谷歌比較傳統。直接把Tensorflow Dataset上12個大類,總共62個NLP任務的資料集,通過模板轉換成了指令資料集

為了提高指令資料集的多樣性,每個任務,會設計10個模板,所以總共是620個指令,並且會有最多3個任務改造模板。所謂的任務改造就是把例如影評的情感分類任務,轉化成一個影評生成任務,更充分的發揮已有標註資料構建更豐富的指令資料集。哈哈感覺這裡充滿了人工的力量。
為了保證資料集的多樣性和均衡性,每個資料集的訓練樣本限制在3萬,並且考慮模型對一個任務的適應速度取決於任務資料集大小,因此按使用資料集樣本大小佔比按比例取樣混合訓練。
效果
效果上137B的指令微調模型大幅超越GPT3 few-shot, 尤其是在NLI任務上,考慮NLI的句子對基本不會在預訓練文字中自然作為連續上下句出現。而指令微調中設計了更自然地模板帶來了大幅的效果提升。
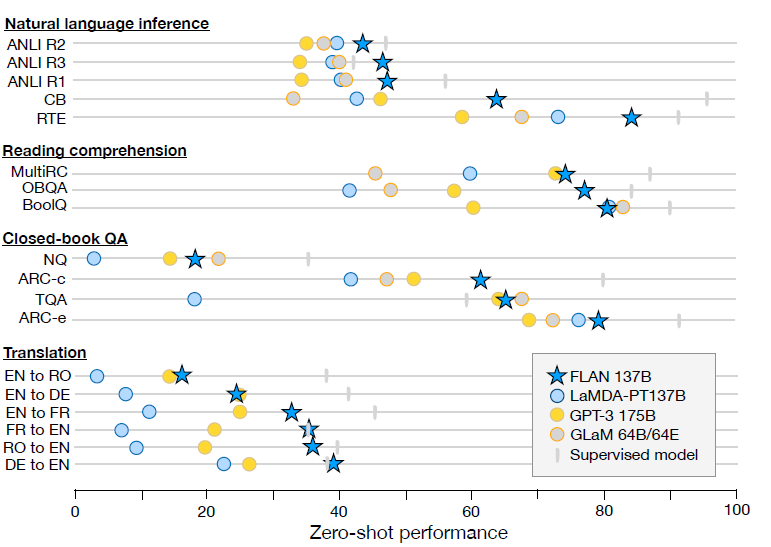
除了以上存在明顯效果提升的任務,在一些任務本身就和指令相似的任務,例如常識推理和指代消歧任務,指令微調並不能帶來顯著的效果提升。
作者做了更多的消融實驗,驗證指令微調中以下幾個變數
- 模型規模:
作者進一步論證了指令微調帶來的效果提升存在明顯的大模型效應,只有當模型規模在百億左右,指令微調才會在樣本外任務上帶來提升。作者懷疑當模型規模較小時,在較多工上微調可能會佔用模型本就不多的引數空間,造成預訓練時的通用知識遺忘,降低在新任務上的效果。
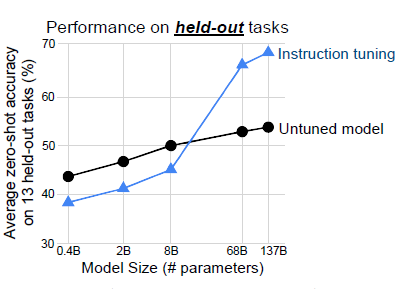
-
多工影響:
考慮指令微調是在多工上進行,作者希望剔除指令微調中多工微調帶來的影響。因此嘗試進行多工非指令微調(使用資料集名稱代替指令),效果上指令微調顯著更優,說明指令模板的設計確實存在提升模型指令理解力的效果。 -
few-shot:
除了zero-shot,Flan同時驗證了few-shot的效果。整體上few-shot的效果優於zero-shot。說明指令微調對few-shot也有效果提升。 -
結合prompt-tunning
既然指令微調提升模型對指令的理解能力,作者認為應該對進一步使用soft-prompt也應該有提升。因此進一步使用了prompt-tunning對下游任務進行微調,不出意外Flan比預訓練LaMDA的效果有顯著的提升。
BigScience: T0
- paper: 2021.10 Multitask prompted training enables zero-shot task generation
- T0: https://github.com/bigscience-workshop/t-zero
- Model: 11B T5-LM
- 一言以蔽之: Flan你想到的我也想到了! 不過我的指令資料集更豐富多樣
T0是緊隨Flan釋出的論文,和FLan對比有以下以下幾個核心差異:
- 預訓練模型差異:Flan是Decoder-only, T0是Encoder-Decoder的T5,並且考慮T5的預訓練沒有LM目標,因此使用了prompt-tunning中以LM任務繼續預訓練的T5-LM
- 指令多樣性:T0使用的是PromptSource的資料集,指令要比Flan更豐富
- 模型規模:Flan在消融實驗中發現8B以下指令微調效果都不好,而3B的T0通過指令微調也有效果提升。可能影響是En-Dn的預訓練目標差異,以及T0的指令集更多樣更有創意
- 樣本外泛化任務: Flan為了驗證指令微調泛化性是每次預留一類任務在剩餘任務訓練,訓練多個模型。T0是固定了4類任務在其餘任務上微調
下面我們細說下T0的指令資料和消融實驗
指令集
T0構建了一個開源Prompt資料集P3(Public Pool of Prompts),包括173個資料集和2073個prompt。從豐富程度上比Flan提升了一整個數量級,不過只包含英文文字,更多資料集的構建細節可以看PromptSource的論文。
作者在指令集的多樣性上做了2個消融實驗
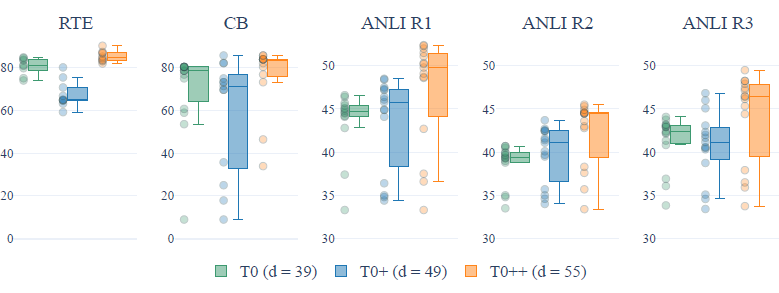
- 指令集包括的資料集數:
在T0原始指令集的基礎上,作者分別加入GPT-3的驗證集,以及SuperGLUE,訓練了T0+和T0++模型。在5個hold-out任務上,更多的資料集並不一定帶來效果的提升,並且在部分推理任務上,更多的資料集還會帶來spread的上升(模型在不同prompt模板上表現的穩定性下降)
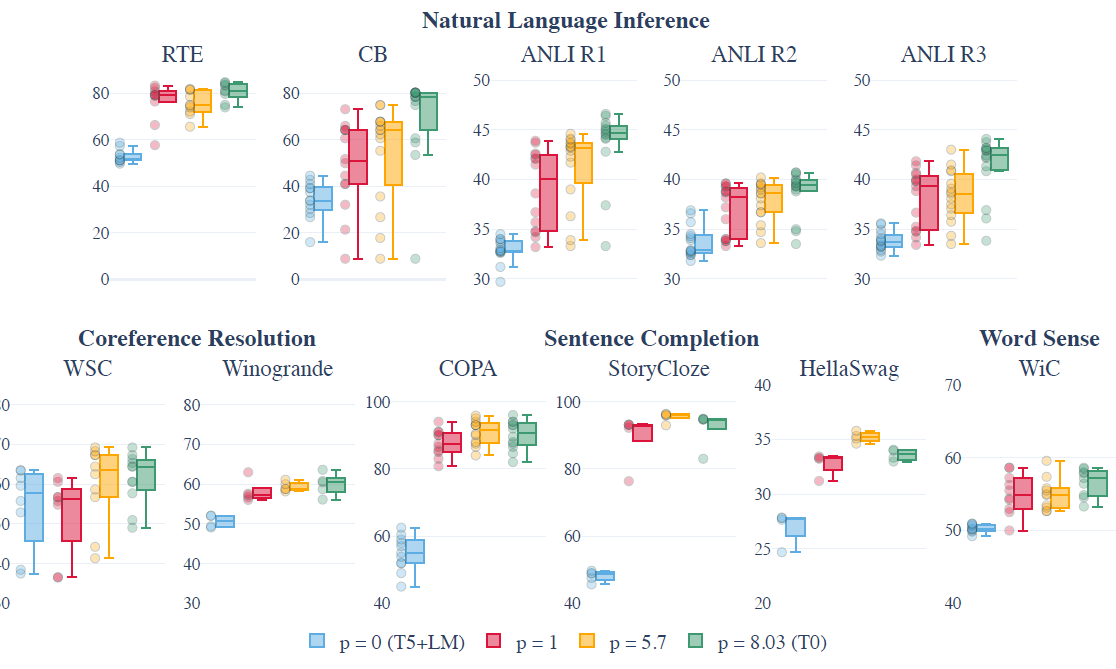
- 每個資料集的prompt數(p):通過每個資料集取樣不同數量的prompt進行訓練,作者發現隨prompt數提升,模型表現的中位數會有顯著提升,spread存在不同程度的下降,不過看起來存在邊際遞減的效應。
OpenAI: InstructGPT
- paper: 2022.3 Training Language Model to follow instructions with human feedback
- Model: (1.3B, 6B, 175B) GPT3
- 一言以蔽之:你們還在刷Benchamrk?我們已經換玩法了!更好的AI才是目標
這裡把InstructGPT拆成兩個部分,本章只說指令微調的部分,也就是訓練三部曲中的第一步,論文中叫SFT(Supervised fine-tuning)。從論文的資料構建和評估中,不難發現OpenAI對於什麼是一個更好的模型的定義和大家出現了差異,當谷歌,BigScience聯盟還在各種不同的標準任務上評估LM模型能力提升時,OpenAI的重點已經變成了更好的AI,也就是能更好幫助人類解決問題的人工智慧。簡化成3H原則就是
- Helpful:模型能幫助使用者解決問題
- Honest: 模型能輸出真實資訊
- Harmless: 模型輸出不能以任何形式傷害人類
於是正文部分的評估基本沒有常見的Accuracy,F1等,而是變成了各種人工評估的打分,例如LikeScore,Hallucinations等等。指令微調資料集的分佈也從標準NLP任務向用戶在playground中提交的問題偏移。下面我們細說下這兩部分
指令集
先說下SFT指令集的構建,InstructGPT構建了訓練12725+驗證1653條prompt指令,由標註員的標註樣本和使用者在playground中和模型互動的指令共同構成,相比T0指令的多樣性又有大幅提升。不過以下的指令數量包括了few-shot取樣,也就是1個instruction取樣不同的few-shot算多條指令。
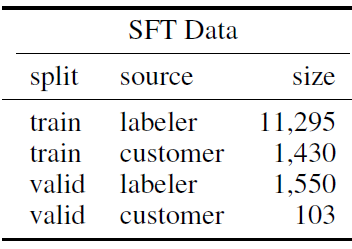
除了豐富程度,和T0以及Flan指令集最大的差異在於指令型別的分佈。 標註人員標註了以下三類樣本
- Plain: 標註同學自由構建任務指令
- Few-shot:自由構建任務的同時給出few-shot樣例
- User-Based: 基於使用者申請waitlist時給出的使用用途,讓標註同學構建對應的指令任務
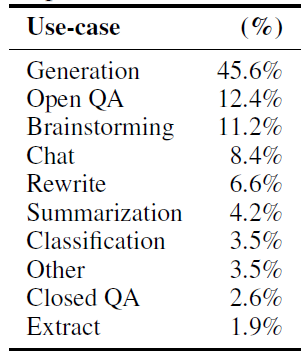
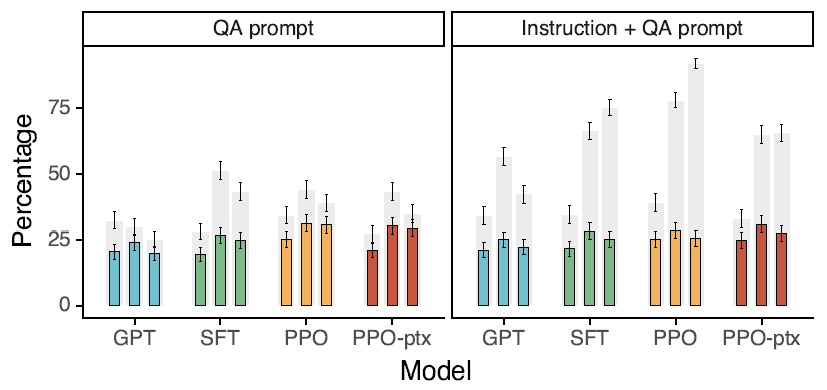
整體上會更偏向於使用者在真實場景下和模型互動可能提問的問題,自由式生成例如腦暴,改寫,聊天,自由創作類的任務佔了絕大多數。 而T0,Flan的指令集集中在NLP的分類和QA任務,這類任務的在實際互動中佔比其實很小。下圖是OpenAI play ground中收集的使用者指令的分佈
以及從論文的表述中存在迭代 ,也就是標註同學標註的指令集用於訓練第一版InstructGPT,然後釋出到playground,收集更多的使用者和模型互動的指令,再使用使用者指令來訓練後續的模型。因此在使用者導向的資料集上OpenAI相比所有競爭對手都有更深厚的積累,你以為在白嫖人家的playground?人家也在收集資料提升他們的模型。
SFT使用cosine rate decay 例如微調了16個epoch,但是發現在第一個epoch上驗證集就已經過擬合了,但是過擬合會提升後續RLHF的模型效果。這部分我們放到RLHF章節再討論,也就是什麼樣的模型更合適作為RLHF的起點
評估指標
從論文對如何把3H原則轉化成客觀的模型評估指標的討論上,不難感受到OpenAI對於標註標準有過很長期的討論和迭代,包括3個方向
- Helpful有用性
主要評價模型是否理解了指令意圖,考慮有些指令本身意圖的模糊性,因此有用性被泛化成標註同學1-7分的偏好打分。
- Harmless有害性
針對模型輸出是否有害其實取決於模型的輸出被用在什麼場景中。OpenAI最初是用疑似有害性作為判斷標註,不過看起來可能雙審一致率不高,不同標註同學對疑似有害的認知存在較大差異。因此OpenAI設計了幾條明確的有害標準,和風控類似,包括涉黃,涉暴,有侮辱性言語等等。
- Honest事實性
相比Honest的含義 ,Truthfulness更適合用與沒有價值觀的模型,論文使用封閉域上模型偽造事實的概率,和在QA問題上的準確率來評估。
以上的標註標準,具體反映在以下的標註頁面中

模型效果
評估資料也分成了兩部分,標準NLP資料集,和API收集的指令資料進行標註得到,也就是OpenAI獨有資料。
- API資料集
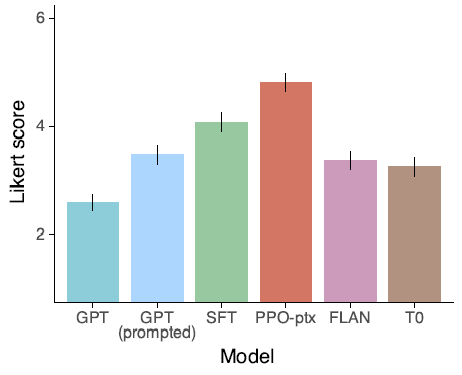
有用性上,不論是在請求GPT,還是在請求InstructGPT的指令樣本中,不論是使用新的標註同學,還是和標註訓練樣本相同的標註同學,對比原始GPT3,SFT之後的模型like score都顯著更高,並且存在模型規模效應。
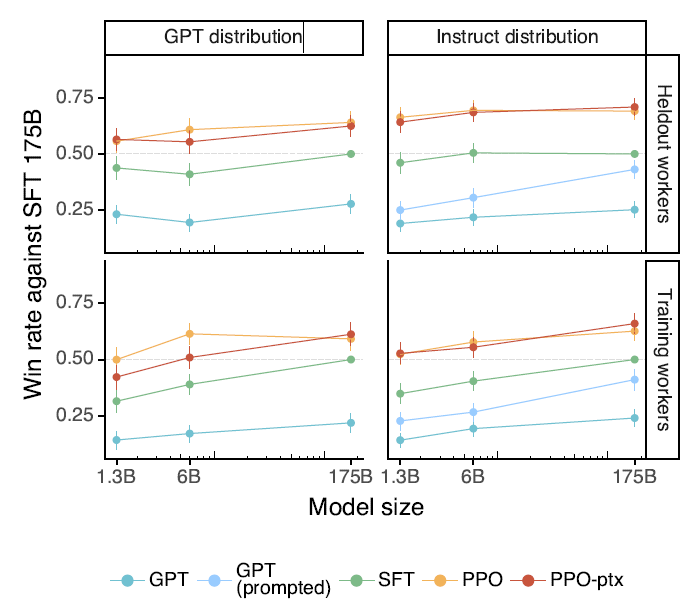
具體拆分到是否遵循指令,是否給出偽事實,以及能否對使用者起到幫助作用上,SFT微調後的模型都有顯著提升。
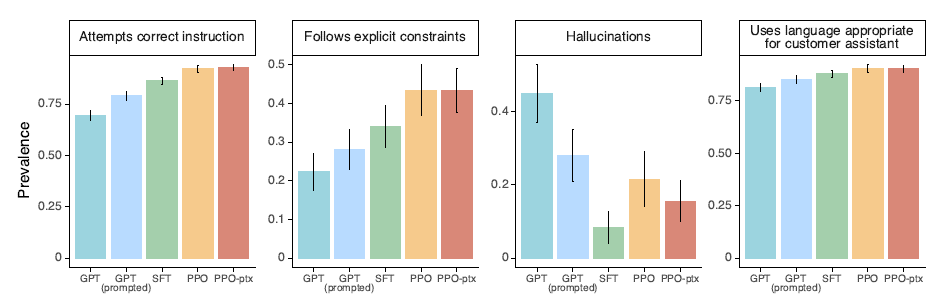
同時論文對比了使用Flan和T0的指令集對GPT3進行微調,發現雖然比原始GPT3有提升,但是效果會顯著差於使用更接近人類偏好的指令集微調的SFT。論文給出了兩個可能的原因
- 公開NLP任務型別集中在分類和QA,這和OpenAI playground中收集的任務分佈存在較大的差異
- 公開NLP資料集的指令豐富程度 << 人們實際輸入的指令多樣性
- 標準NLP任務
在TruthfulQA任務上,SFT模型相比GPT有微小但是顯著的提升,整體事實性還是有待提高。
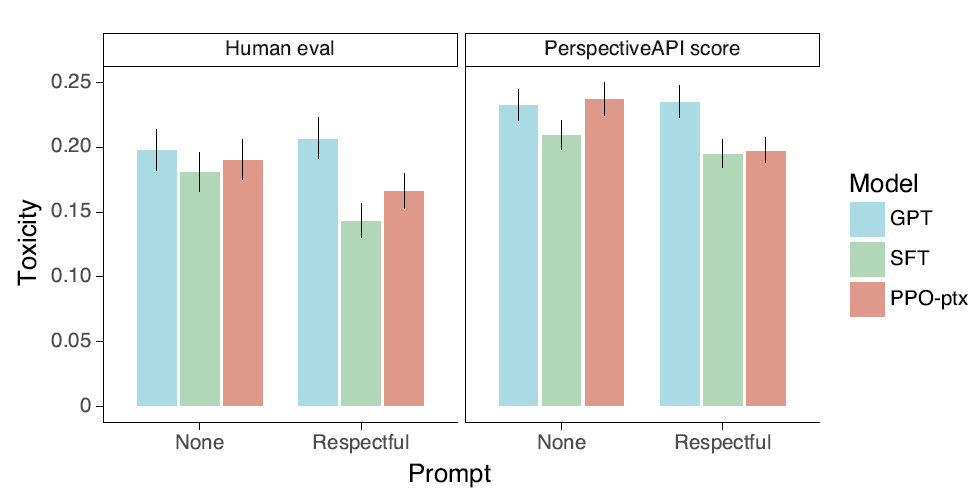
在RealToxicityPrompts資料集上,不管是人工打分還是Perspective模型打分都顯示,SFT相比GPT3,在產出有害內容上比例有顯著的下降。
綜上所述,InstructGPT在指令微調上最大突破是指令資料集分佈的差異性,標準NLP任務更少,自由開放類任務更多,以及依賴Openai免費開放的playground,可以持續收集使用者的指令用於模型迭代。同時在評估標準上,在語言模型之外引入3H體系來評價模型作為AI的能力效果。
AllenAI:TK-Instruct
- paper: 2022.4 SUPER-NATURAL INSTRUCTIONS:Generalization via Declarative Instructions on 1600+ NLP Tasks
- 開源指令集:https://instructions.apps.allenai.org/
- Model: 11B T5
- 一言以蔽之:沒有最大隻有更大的指令集,在英文和非英文的各類任務上超越InstructGPT?
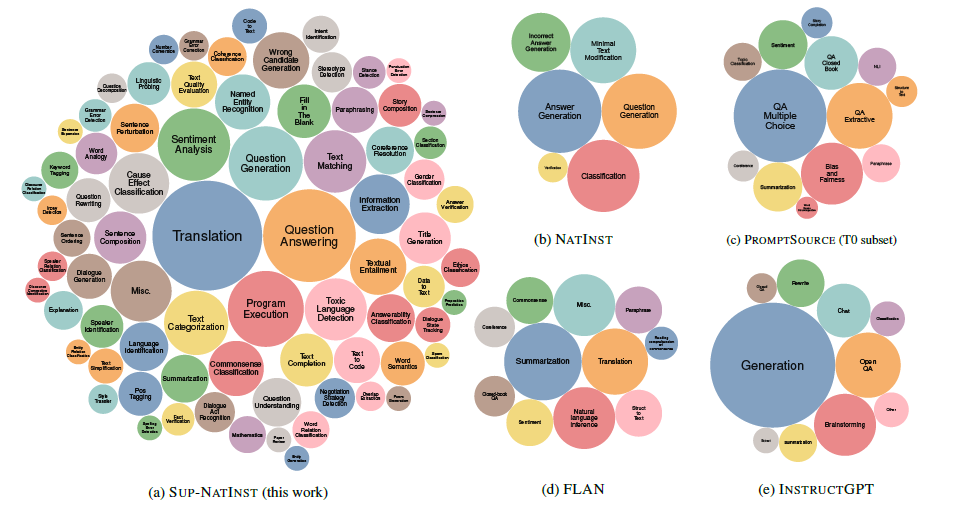
Tk-Instruct最大的貢獻在於開源了更大規模的指令資料集,並且對上述提到的T0(promptSource),Flan,InstructGPT指令集進行了對比總結,如下
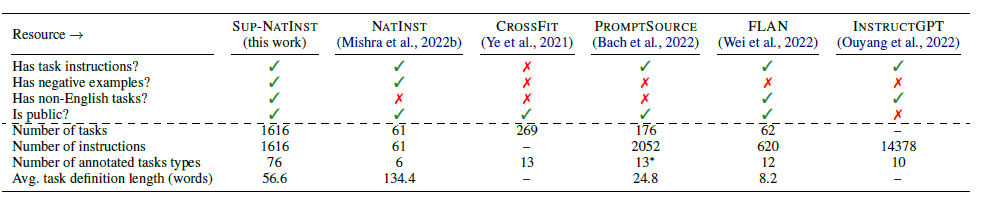
TK-Instruct在76大類,總共1616個任務上構建了指令集,任務分佈比T0和Flan更加多樣和廣泛,比InstructGPT要小(不過因為Instruct GPT的指令更多是開放生成類的使用者指令所以不太可比),且佔比上還是更偏向標準NLP任務型別。
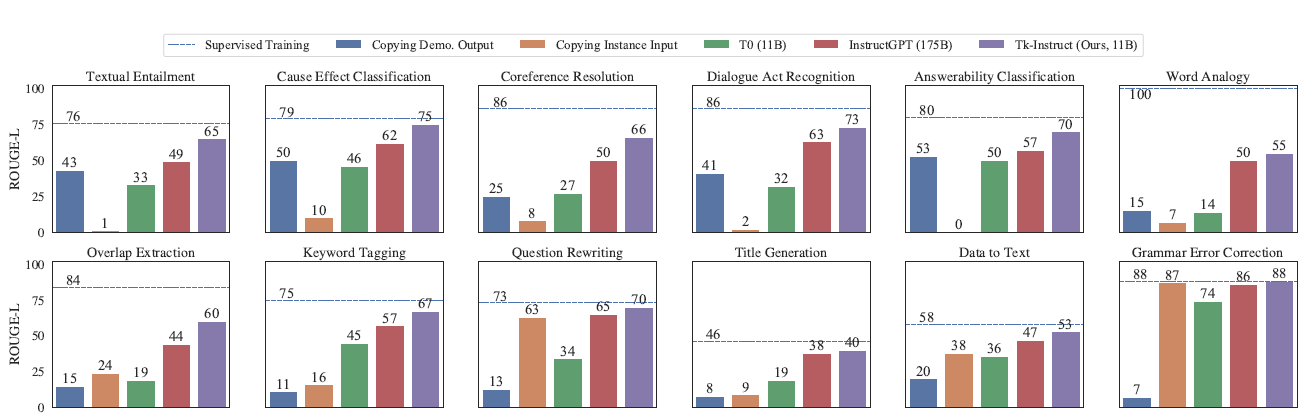
其他細節這裡不再贅述,這裡放TK-InstructGPT更多是想看下以上T0,InstructGPT,TK-Instruct的效果對比。可以發現在內容理解任務上Tk-Instruct是要顯著超越InstructGPT的,在生成類任務上二者差不多。但整體和有監督微調(虛線)相比還有很大的提升空間。這裡其實也是我對Chatgpt能力的一些疑慮,不可否認它在擬人化和對話上的成功,但是在標準NLP任務上ChatGPT的水平如何,這一點有待評估,好像又看到最近有類似的論文出來,後面再補上這部分
更多Prompt相關論文·教學,AIGC相關玩法戳這裡DecryptPrompt