golang pprof 監控系列(1) —— go trace 統計原理與使用
golang pprof 監控系列(1) —— go trace 統計原理與使用
關於go tool trace的使用,網上有相當多的資料,但拿我之前初學golang的經驗來講,很多資料都沒有把go tool trace中的相關指標究竟是統計的哪些方法,統計了哪段區間講解清楚。所以這篇文章不僅僅會介紹go tool trace的使用,也會對其統計的原理進行剖析。
golang版本 go1.17.12
先簡單說下go tool trace 的使用場景,在分析延遲性問題的時候,go tool trace能起到很重要的作用,因為它會記錄各種延遲事件並且對其進行時長分析,連關鍵程式碼位置也能找出來。
關於trace的實戰案例,之前有出過一個視訊(一次系統延遲分析案例),歡迎瀏覽
接著我們簡單看下golang 裡如何使用trace 功能。
go trace 使用
package main
import (
_ "net/http/pprof"
"os"
"runtime/trace"
)
func main() {
f, _ := os.Create("trace.out")
defer f.Close()
trace.Start(f)
defer trace.Stop()
......
}
使用trace的功能其實比較容易,用trace.Start 便可以開啟trace的事件取樣功能,trace.Stop 則停止採用,取樣的資料會記錄到trace.Start 傳來的輸出流引數裡,這裡我是將一個名為trace.out 的檔案作為輸出流引數傳入。
取樣結束後便可以通過 go tool trace trace.out命令對取樣檔案進行分析了。
go tool trace 命令預設會使用本地隨機一個埠來啟動一個http服務,頁面顯示如下:

接著我會分析下各個連結對應的統計資訊以及背後進行統計的原理,好的,接下來,正戲開始。
統計原理介紹
平時在使用prometheus對應用服務進行監控時,我們主要還是採用埋點的方式,同樣,go runtime內部也是採用這樣的方式對程式碼執行過程中的各種事件進行埋點,最後讀取 整理後的埋點資料,形成我們在網頁上看的trace監控圖。
// src/runtime/trace.go:517
func traceEvent(ev byte, skip int, args ...uint64) {
mp, pid, bufp := traceAcquireBuffer()
.....
}
每次要記錄相應的事件時,都會呼叫traceEvent方法,ev代表的是事件列舉,skip 是看棧幀需要跳躍的層數,args 在某些事件需要傳入特定引數時傳入。
在traceEvent 內部同時也會獲取到當前事件發生時的執行緒資訊,協程資訊,p執行佇列資訊,並把這些資訊同事件一起記錄到一個緩衝區裡。
// src/runtime/trace/trace.go:120
func Start(w io.Writer) error {
tracing.Lock()
defer tracing.Unlock()
if err := runtime.StartTrace(); err != nil {
return err
}
go func() {
for {
data := runtime.ReadTrace()
if data == nil {
break
}
w.Write(data)
}
}()
atomic.StoreInt32(&tracing.enabled, 1)
return nil
}
在我們啟動trace.Start方法的時候,同時會啟動一個協程不斷讀取緩衝區中的內容到strace.Start 的引數中。
在範例程式碼裡,trace.Start 方法傳入名為trace.out檔案的輸出流引數,所以在取樣過程中,runtime會將採集到的事件位元組流輸出到trace.out檔案,trace.out檔案在被讀取出的時候 是用了一個叫做Event的結構體來表示這些監控事件。
// Event describes one event in the trace.
type Event struct {
Off int // offset in input file (for debugging and error reporting)
Type byte // one of Ev*
seq int64 // sequence number
Ts int64 // timestamp in nanoseconds
P int // P on which the event happened (can be one of TimerP, NetpollP, SyscallP)
G uint64 // G on which the event happened
StkID uint64 // unique stack ID
Stk []*Frame // stack trace (can be empty)
Args [3]uint64 // event-type-specific arguments
SArgs []string // event-type-specific string args
// linked event (can be nil), depends on event type:
// for GCStart: the GCStop
// for GCSTWStart: the GCSTWDone
// for GCSweepStart: the GCSweepDone
// for GoCreate: first GoStart of the created goroutine
// for GoStart/GoStartLabel: the associated GoEnd, GoBlock or other blocking event
// for GoSched/GoPreempt: the next GoStart
// for GoBlock and other blocking events: the unblock event
// for GoUnblock: the associated GoStart
// for blocking GoSysCall: the associated GoSysExit
// for GoSysExit: the next GoStart
// for GCMarkAssistStart: the associated GCMarkAssistDone
// for UserTaskCreate: the UserTaskEnd
// for UserRegion: if the start region, the corresponding UserRegion end event
Link *Event
}
來看下Event事件裡包含哪些資訊:
P 是執行佇列,go在執行協程時,是將協程排程到P上執行的,G 是協程id,還有棧id StkID ,棧幀 Stk,以及事件發生時可以攜帶的一些引數Args,SArgs。
Type 是事件的列舉欄位,Ts是事件發生的時間戳資訊,Link 是與事件關聯的其他事件,用於計算關聯事件的耗時。
拿計算系統呼叫耗時來說,系統呼叫相關的事件有GoSysExit,GoSysCall 分別是系統呼叫退出事件和系統呼叫開始事件,所以GoSysExit.Ts - GoSysCall.Ts 就是系統呼叫的耗時。
特別提示: runtime 內部用到的監控事件列舉在src/runtime/trace.go:39 位置 ,而 在讀取檔案中的監控事件用到的列舉是 在src/internal/trace/parser.go:1028 ,雖然是兩套,但是值是一樣的。
很明顯Link 欄位不是在runtime 記錄監控事件時設定的,而是在讀取trace.out裡的監控事件時,將事件資訊按照協程id分組後 進行設定的。同一個協程的 GoSysExit.Ts - GoSysCall.Ts 就是該協程的系統呼叫耗時。
接下來我們來挨個分析下trace頁面的統計資訊以及背後的統計原理。
View trace是每個事件的時間線構成的監控圖,在生產環境下1s都會產生大量的事件,我認為直接看這張圖還是會讓人眼花繚亂。 所以還是跳過它吧,從Goroutine analysis開始分析。
Goroutine analysis
go tool trace最終參照的程式碼位置是在go/src/cmd/trace 包下,main函數會啟動一個http服務,並且註冊一些處理常式,我們點選Goroutine analysis 其實就是請求到了其中一個處理常式上。
下面這段程式碼是註冊的goroutine的處理常式點選Goroutine analysis 就會對映到 /goroutines 路由上。
// src/cmd/trace/goroutines.go:22
func init() {
http.HandleFunc("/goroutines", httpGoroutines)
http.HandleFunc("/goroutine", httpGoroutine)
}
讓我們點選下 Goroutine analysis

進入到了一個顯示程式碼呼叫位置的列表,列表中的每個程式碼位置都是事件EvGoStart 協程開始執行時的位置,其中N代表 在採用期間 在這個位置上有N個協程開始過執行。
你可能會好奇,是怎樣確定這10個協程是由同一段程式碼執行的?runtime在記錄協程開始執行的事件EvGoStart 時,是會把棧幀也記錄下來的,而棧幀中包含函數名和程式計數器(PC)的值,在Goroutine analysis 頁面 中就是協程就是按PC的值進行分組的。 以下是PC賦值的程式碼片段。
// src/internal/trace/goroutines.go:176
case EvGoStart, EvGoStartLabel:
g := gs[ev.G]
if g.PC == 0 {
g.PC = ev.Stk[0].PC
g.Name = ev.Stk[0].Fn
}
我們再點選第一行連結 nfw/nfw_base/fw/routine.(*Worker).TryRun.func1 N=10 ,這裡點選第一行的連結將會對映到 /goroutine 的路由上(注意路由已經不是s結尾了),由它的處理常式進行處理。點選後如圖所示:
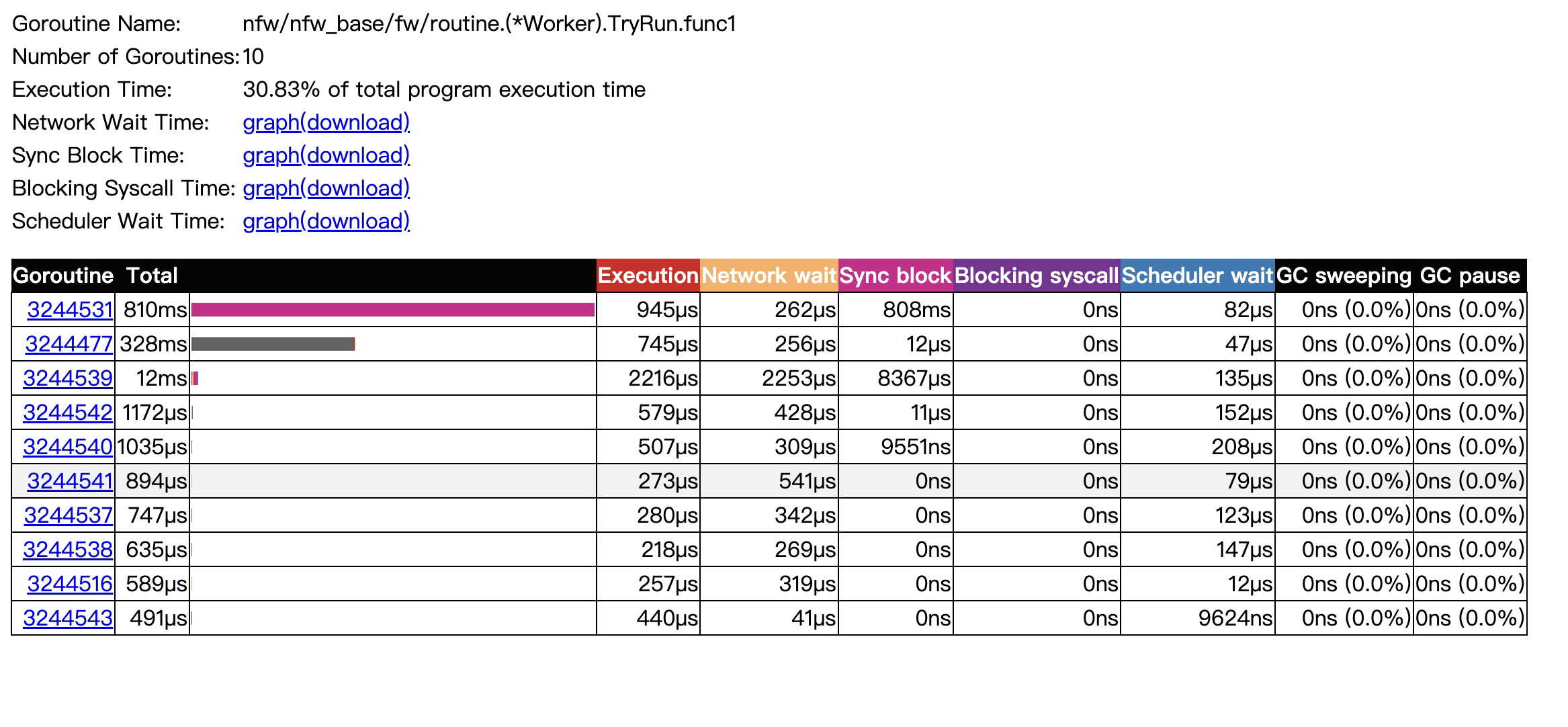
現在看到的就是針對這10個協程分別的系統呼叫,阻塞,排程延遲,gc這些統計資訊。
接著我們從上到下挨個分析:
Execution Time 是指著10個協程的執行時間佔所有協程執行的比例。
接著是用於分析網路等待時間,鎖block時間,系統呼叫阻塞時間 ,排程等待時間的圖片,這些都是分析系統延遲,阻塞問題的利器。 這裡就不再分析圖了,相信網上會有很多這種資料。
然後來看下 表格裡的各項指標:
Execution
是協程在取樣這段時間內的執行時間。
記錄的方式也很簡單,在讀取event事件時,是按時間線從前往後讀取,每次讀取到協程開始執行的時間時,會記錄下協程的開始執行的時間戳(時間戳是包含在Event結構裡的),讀取到協程停頓事件時,則會把停頓時刻的時間戳減去開始執行的時間戳 得到 一小段的執行時間,將這小段的時間 累加到該協程的總執行時間上。
停頓則是由鎖block,系統呼叫阻塞,網路等待,搶佔排程造成的。
Network wait
顧名思義,網路等待時長, 其實也是和Execution類似的記錄方式,首先記錄下協程在網路等待時刻的時間戳,由於event是按時間線讀取的,當讀取到unblock事件時,再去看協程上一次是不是網路等待事件,如果是的話,則將當前時刻時間戳減去 網路等待時刻的時間戳,得到的這一小段時間,累加到該協程的總網路等待時長上。
Sync block,Blocking syscall,Scheduler wait
這三個時長 計算方式和前面兩張也是類似的,不過注意下與之相關聯的事件的觸發條件是不同的。
Sync block 時長是由於 鎖 sync.mutex ,通道channel,wait group,select case語句產生的阻塞都會記錄到這裡。 下面是相關程式碼片段。
// src/internal/trace/goroutines.go:192
case EvGoBlockSend, EvGoBlockRecv, EvGoBlockSelect,
EvGoBlockSync, EvGoBlockCond:
g := gs[ev.G]
g.ExecTime += ev.Ts - g.lastStartTime
g.lastStartTime = 0
g.blockSyncTime = ev.Ts
Blocking syscall 就是系統呼叫造成的阻塞了。
Scheduler wait 是協程從可執行狀態到執行狀態的時間段,注意協程是可執行狀態時 是會放到p 執行佇列等待被排程的,只有被排程後,才會真正開始執行程式碼。 這裡涉及到golang gpm模型的理解,這裡就不再展開了。
後面兩欄就是GC 佔用total時間的一個百分比了,golang 的gc相關的知識也不繼續展開了。
各種profile 圖
還記得最開始分析trace.out生成的網頁時,Goroutine analysis 下面是什麼嗎?是各種分析延遲相關的profile 圖,資料的來源和我們講Goroutine analysis 時分析單個Goroutine 的等待時間的指標是一樣的,不過這裡是針對所有goroutine而言。
Network blocking profile (⬇)
Synchronization blocking profile (⬇)
Syscall blocking profile (⬇)
Scheduler latency profile (⬇)
關於golang 的這個trace工具,還允許使用者可以自定義監控事件 ,生成的trace網頁裡,User-defined tasks,User-defined regions 就是記錄使用者自定義的一些監控事件,這部分的應用等到以後再講了。
Minimum mutator utilization 是一個看gc 對程式影響情況的曲線圖,這個等以後有機會講gc時再詳細談談了。
關於trace的實戰案例,之前有出過一個視訊(一次系統延遲分析案例),歡迎瀏覽。