資料遷移工具,用這8種就夠了!
前言
最近有些小夥伴問我,ETL資料遷移工具該用哪些。
ETL(是Extract-Transform-Load的縮寫,即資料抽取、轉換、裝載的過程),對於企業應用來說,我們經常會遇到各種資料的處理、轉換、遷移的場景。
今天特地給大家彙總了一些目前市面上比較常用的ETL資料遷移工具,希望對你會有所幫助。
1.Kettle
Kettle是一款國外開源的ETL工具,純Java編寫,綠色無需安裝,資料抽取高效穩定 (資料遷移工具)。
Kettle 中有兩種指令碼檔案,transformation 和 job,transformation 完成針對資料的基礎轉換,job 則完成整個工作流的控制。
Kettle 中文名稱叫水壺,該專案的主程式設計師 MATT 希望把各種資料放到一個壺裡,然後以一種指定的格式流出。
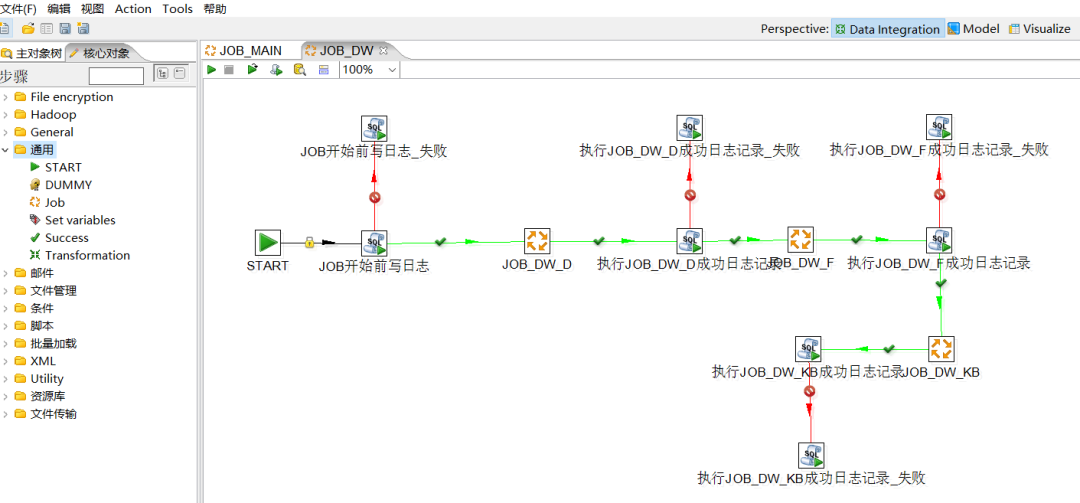
Kettle 這個 ETL 工具集,它允許你管理來自不同資料庫的資料,通過提供一個圖形化的使用者環境來描述你想做什麼,而不是你想怎麼做。
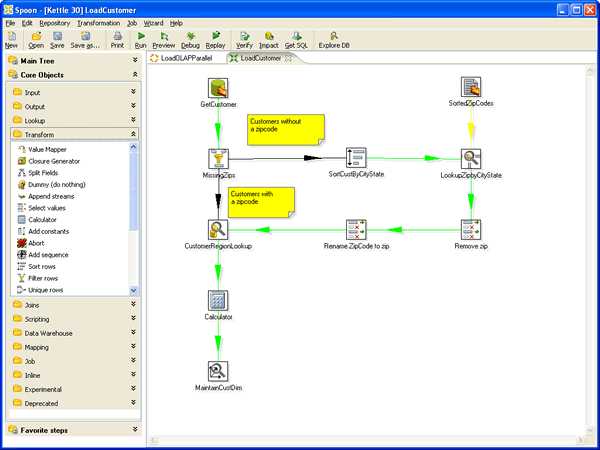
Kettle 家族目前包括 4 個產品:Spoon、Pan、CHEF、Kitchen。
SPOON:允許你通過圖形介面來設計 ETL 轉換過程(Transformation)。PAN:允許你批次執行由 Spoon 設計的 ETL 轉換 (例如使用一個時間排程器)。Pan 是一個後臺執行的程式,沒有圖形介面。CHEF:允許你建立任務(Job)。 任務通過允許每個轉換,任務,指令碼等等,更有利於自動化更新資料倉儲的複雜工作。任務通過允許每個轉換,任務,指令碼等等。任務將會被檢查,看看是否正確地執行了。KITCHEN:允許你批次使用由 Chef 設計的任務 (例如使用一個時間排程器)。KITCHEN 也是一個後臺執行的程式。
2.Datax
DataX是阿里雲 DataWorks資料整合的開源版本,在阿里巴巴集團內被廣泛使用的離線資料同步工具/平臺。
DataX 是一個異構資料來源離線同步工具,致力於實現包括關係型資料庫(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各種異構資料來源之間穩定高效的資料同步功能。
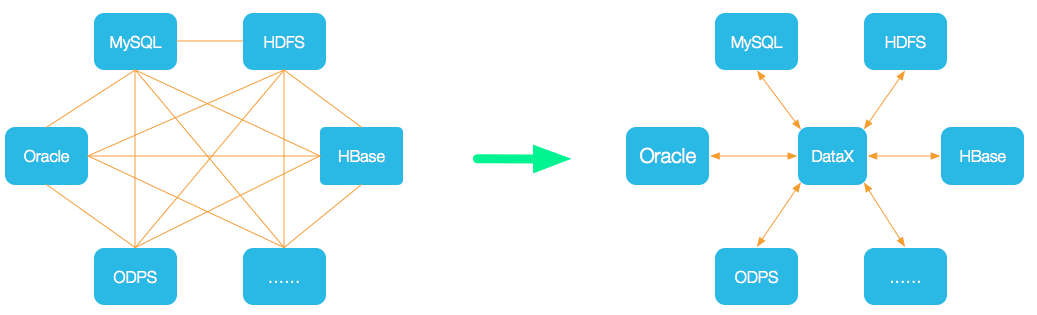
設計理念:為了解決異構資料來源同步問題,DataX將複雜的網狀的同步鏈路變成了星型資料鏈路,DataX作為中間傳輸載體負責連線各種資料來源。當需要接入一個新的資料來源的時候,只需要將此資料來源對接到DataX,便能跟已有的資料來源做到無縫資料同步。
當前使用現狀:DataX在阿里巴巴集團內被廣泛使用,承擔了所有巨量資料的離線同步業務,並已持續穩定執行了6年之久。目前每天完成同步8w多道作業,每日傳輸資料量超過300TB。
DataX本身作為離線資料同步框架,採用Framework + plugin架構構建。將資料來源讀取和寫入抽象成為Reader/Writer外掛,納入到整個同步框架中。

DataX 3.0 開源版本支援單機多執行緒模式完成同步作業執行,本小節按一個DataX作業生命週期的時序圖,從整體架構設計非常簡要說明DataX各個模組相互關係。
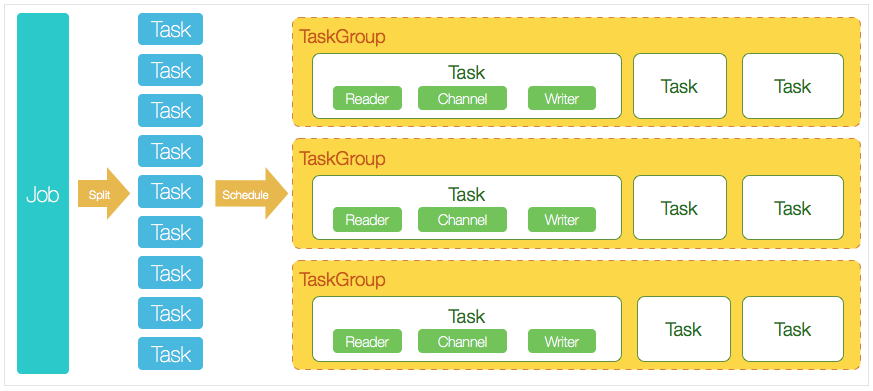
DataX 3.0六大核心優勢:
- 可靠的資料質量監控
- 豐富的資料轉換功能
- 精準的速度控制
- 強勁的同步效能
- 健壯的容錯機制
- 極簡的使用體驗
3.DataPipeline
DataPipeline採用基於紀錄檔的增量資料獲取技術( Log-based Change Data Capture ),支援異構資料之間豐富、自動化、準確的語意對映構建,同時滿足實時與批次的資料處理。
可實現 Oracle、IBM DB2、MySQL、MS SQL Server、PostgreSQL、GoldenDB、TDSQL、OceanBase 等資料庫準確的增量資料獲取。
平臺具備「資料全、傳輸快、強協同、更敏捷、極穩定、易維護」六大特性。
在支援傳統關係型資料庫的基礎上,對巨量資料平臺、國產資料庫、雲原生資料庫、API 及物件儲存也提供廣泛的支援,並在不斷擴充套件。
DataPipeline 資料融合產品致力於為使用者提供企業級資料融合解決方案,為使用者提供統一平臺同時管理異構資料節點實時同步與批次資料處理任務,在未來還將提供對實時流計算的支援。
採用分散式叢集化部署方式,可水平垂直線性擴充套件的,保證資料流轉穩定高效,讓客戶專注資料價值釋放。
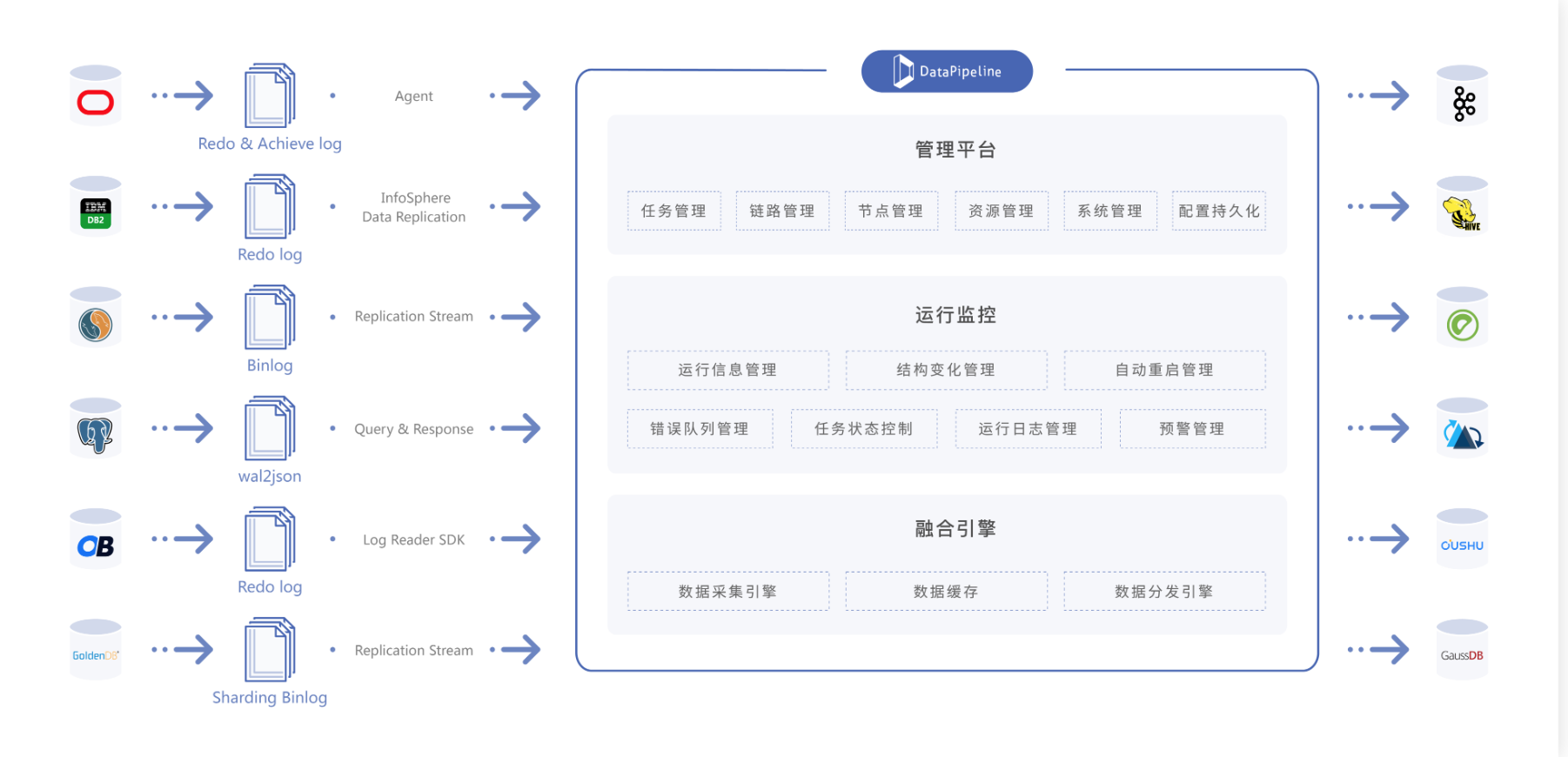
產品特點:
全面的資料節點支援:支援關係型資料庫、NoSQL資料庫、國產資料庫、資料倉儲、巨量資料平臺、雲端儲存、API等多種資料節點型別,可自定義資料節點。高效能實時處理:針對不同資料節點型別提供TB級吞吐量、秒級低延遲的增量資料處理能力,加速企業各類場景的資料流轉。分層管理降本增效:採用「資料節點註冊、資料鏈路設定、資料任務構建、系統資源分配」的分層管理模式,企業級平臺的建設週期從三到六個月減少為一週。無程式碼敏捷管理:提供限制設定與策略設定兩大類十餘種高階設定,包括靈活的資料物件對映關係,資料融合任務的研發交付時間從2周減少為5分鐘。極穩定高可靠:採用分散式架構,所有元件均支援高可用,提供豐富容錯策略,應對上下游的結構變化、資料錯誤、網路故障等突發情況,可以保證系統業務連續性要求。全鏈路資料可觀測:配備容器、應用、執行緒、業務四級監控體系,全景駕駛艙守護任務穩定執行。自動化運維體系,靈活擴縮容,合理管理和分配系統資源。
4.Talend
Talend (踏藍) 是第一家針對的資料整合工具市場的 ETL (資料的提取 Extract、傳輸 Transform、載入 Load) 開源軟體供應商。
Talend 以它的技術和商業雙重模式為 ETL 服務提供了一個全新的遠景。它打破了傳統的獨有封閉服務,提供了一個針對所有規模的公司的公開的,創新的,強大的靈活的軟體解決方案。
5.DataStage
DataStage,即IBM WebSphere DataStage,是一套專門對多種運算元據源的資料抽取、轉換和維護過程進行簡化和自動化,並將其輸入資料市集或資料倉儲目標資料庫的整合工具,可以從多個不同的業務系統中,從多個平臺的資料來源中抽取資料,完成轉換和清洗,裝載到各種系統裡面。
其中每步都可以在圖形化工具裡完成,同樣可以靈活地被外部系統排程,提供專門的設計工具來設計轉換規則和清洗規則等,實現了增量抽取、任務排程等多種複雜而實用的功能。其中簡單的資料轉換可以通過在介面上拖拉操作和呼叫一些 DataStage 預定義轉換函數來實現,複雜轉換可以通過編寫指令碼或結合其他語言的擴充套件來實現,並且 DataStage 提供偵錯環境,可以極大提高開發和偵錯抽取、轉換程式的效率。
Datastage 操作介面
- 對後設資料的支援:Datastage 是自己管理 Metadata,不依賴任何資料庫。
- 引數控制:Datastage 可以對每個 job 設定引數,並且可以 job 內部參照這個引數名。
- 資料質量:Datastage 有配套用的 ProfileStage 和 QualityStage 保證資料質量。
- 客製化開發:提供抽取、轉換外掛的客製化,Datastage 內嵌一種類 BASIC 語言,可以寫一段批次程式來增加靈活性。
- 修改維護:提供圖形化介面。這樣的好處是直觀、傻瓜式的;不好的地方就是改動還是比較費事(特別是批次化的修改)。
Datastage 包含四大部件:
Administrator:新建或者刪除專案,設定專案的公共屬性,比如許可權。Designer:連線到指定的專案上進行 Job 的設計;Director:負責 Job 的執行,監控等。例如設定設計好的 Job 的排程時間。Manager:進行 Job 的備份等 Job 的管理工作。
6.Sqoop
Sqoop 是 Cloudera 公司創造的一個資料同步工具,現在已經完全開源了。
目前已經是 hadoop 生態環境中資料遷移的首選
Sqoop 是一個用來將 Hadoop 和關係型資料庫中的資料相互轉移的工具,可以將一個關係型資料庫(例如 : MySQL ,Oracle ,Postgres 等)中的資料匯入到 Hadoop 的 HDFS 中,也可以將 HDFS 的資料匯入到關係型資料庫中。
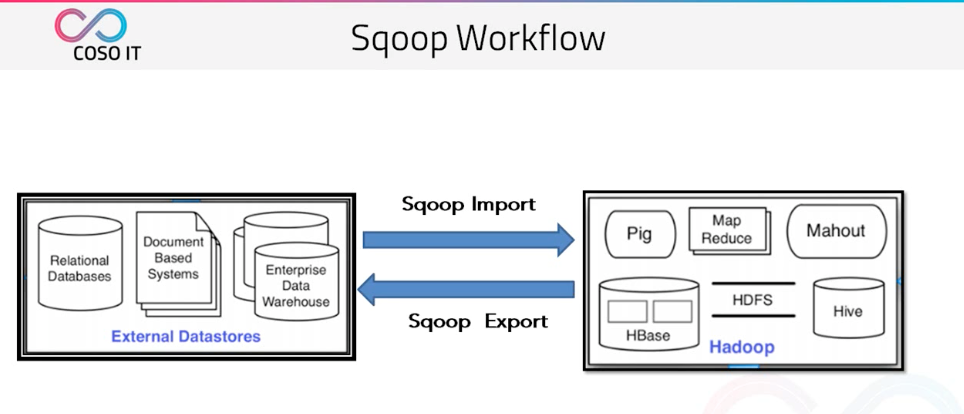
他將我們傳統的關係型資料庫 | 檔案型資料庫 | 企業資料倉儲 同步到我們的 hadoop 生態叢集中。
同時也可以將 hadoop 生態叢集中的資料導回到傳統的關係型資料庫 | 檔案型資料庫 | 企業資料倉儲中。
那麼 Sqoop 如何抽取資料呢?
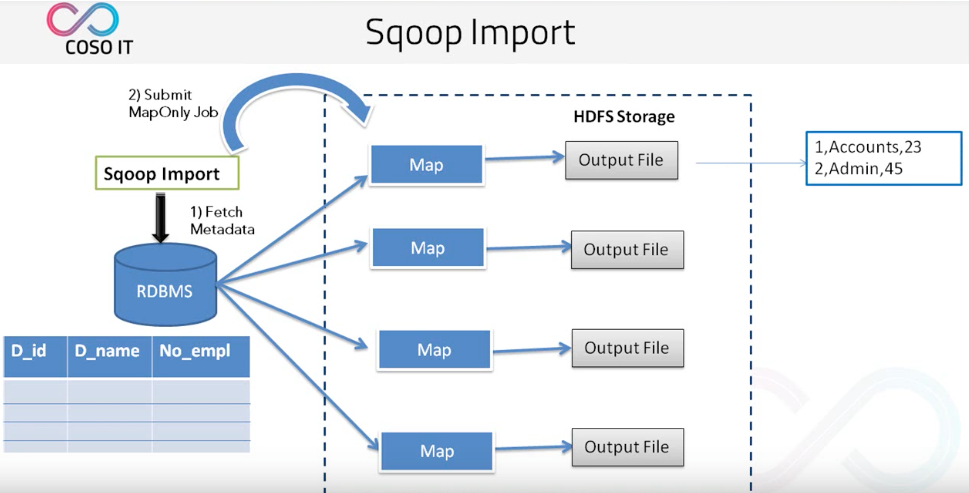
- 首先 Sqoop 去 rdbms 抽取後設資料。
- 當拿到後設資料之後將任務切成多個任務分給多個 map。
- 然後再由每個 map 將自己的任務完成之後輸出到檔案。
7.FineDataLink
FineDataLink是國內做的比較好的ETL工具,FineDataLink是一站式的資料處理平臺,具備高效的資料同步功能,可以實現實時資料傳輸、資料排程、資料治理等各類複雜組合場景的能力,提供資料匯聚、研發、治理等功能。
FDL擁有低程式碼優勢,通過簡單的拖拽互動就能實現ETL全流程。
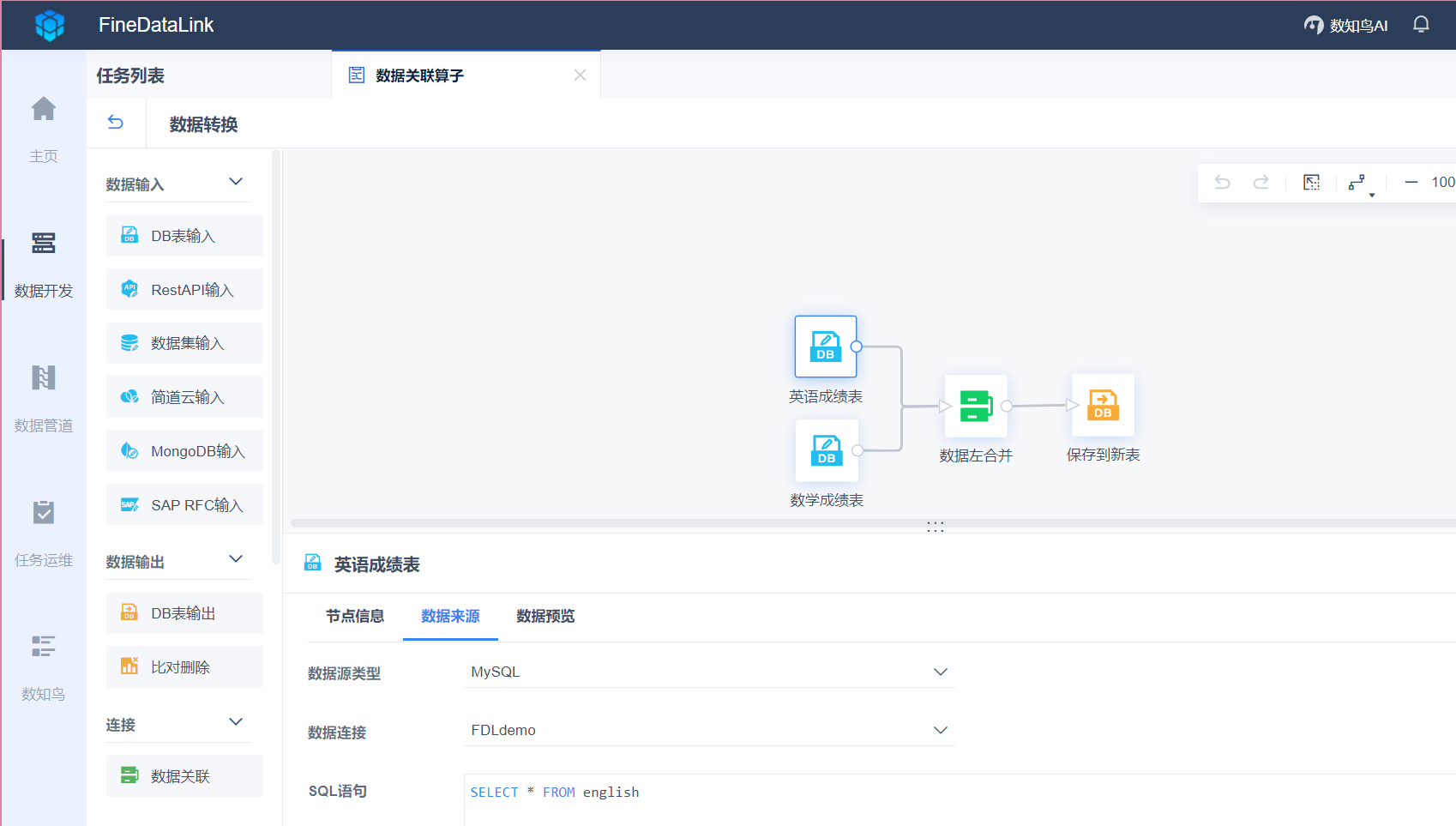
FineDataLink——中國領先的低程式碼/高時效資料整合產品,能過為企業提供一站式的資料服務,通過快速連線、高時效融合多種資料,提供低程式碼Data API敏捷釋出平臺,幫助企業解決資料孤島難題,有效提升企業資料價值。
8.canal
canal [kə'næl],譯意為水道/管道/溝渠,主要用途是基於 MySQL 資料庫增量紀錄檔解析,提供增量資料訂閱和消費。
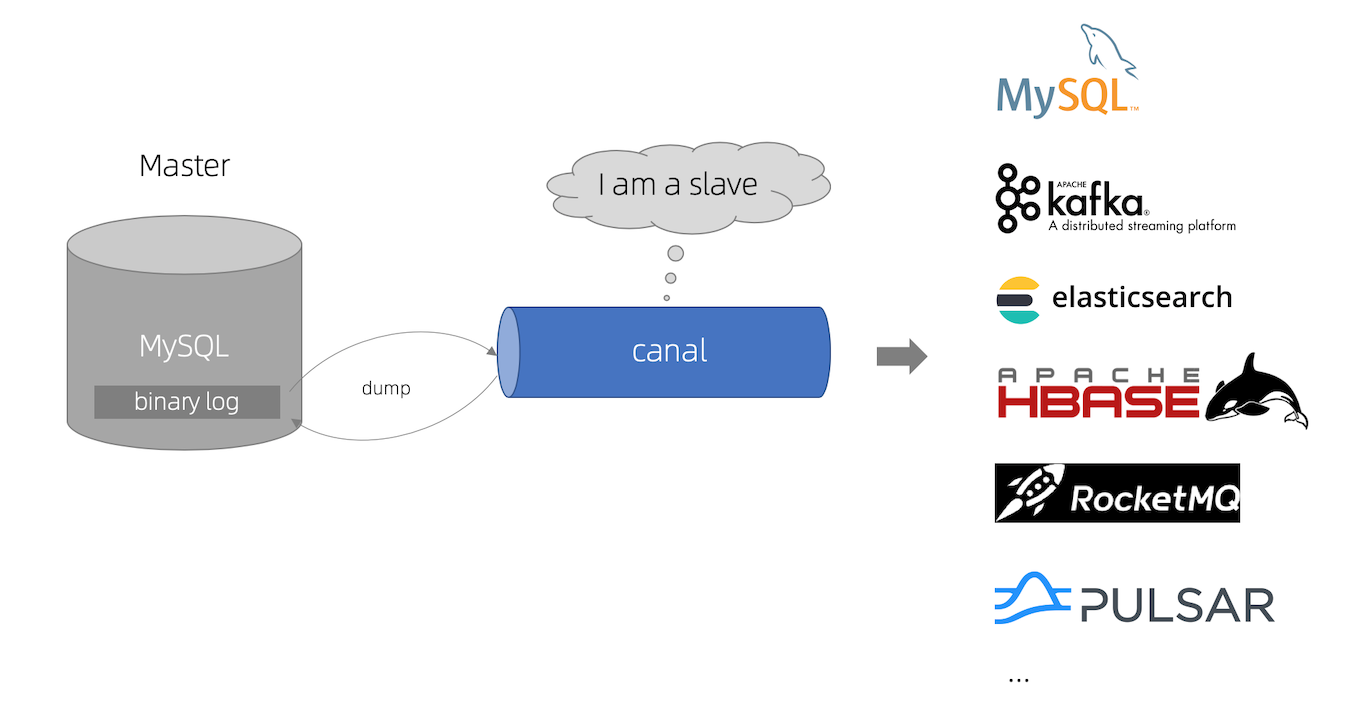
早期阿里巴巴因為杭州和美國雙機房部署,存在跨機房同步的業務需求,實現方式主要是基於業務 trigger 獲取增量變更。從 2010 年開始,業務逐步嘗試資料庫紀錄檔解析獲取增量變更進行同步,由此衍生出了大量的資料庫增量訂閱和消費業務。
基於紀錄檔增量訂閱和消費的業務包括:
- 資料庫映象
- 資料庫實時備份
- 索引構建和實時維護(拆分異構索引、倒排索引等)
- 業務 cache 重新整理
- 帶業務邏輯的增量資料處理
當前的 canal 支援源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x。
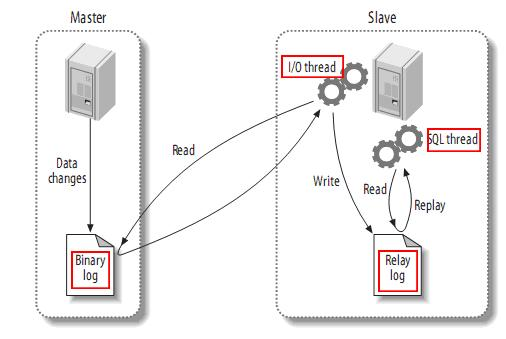
- MySQL master 將資料變更寫入二進位制紀錄檔( binary log, 其中記錄叫做二進位制紀錄檔事件binary log events,可以通過 show binlog events 進行檢視)。
- MySQL slave 將 master 的 binary log events 拷貝到它的中繼紀錄檔(relay log)。
- MySQL slave 重放 relay log 中事件,將資料變更反映它自己的資料。
canal 工作原理:
- canal 模擬 MySQL slave 的互動協定,偽裝自己為 MySQL slave ,向 MySQL master 傳送dump 協定
- MySQL master 收到 dump 請求,開始推播 binary log 給 slave (即 canal )
- canal 解析 binary log 物件(原始為 byte 流)
最後說一句(求關注,別白嫖我)
如果這篇文章對您有所幫助,或者有所啟發的話,幫忙掃描下發二維條碼關注一下,您的支援是我堅持寫作最大的動力。
求一鍵三連:點贊、轉發、在看。
關注公眾號:【蘇三說技術】,在公眾號中回覆:面試、程式碼神器、開發手冊、時間管理有超讚的粉絲福利,另外回覆:加群,可以跟很多BAT大廠的前輩交流和學習。