美團外賣離線數倉建設實踐
導讀:美團外賣資料倉儲主要是收集各種使用者終端業務、行為資料,通過統一口徑加工處理,通過多種資料服務支撐主題報表、資料分析等多種方式的應用。資料組作為資料基礎部門,支援使用者端、商家端、銷售、廣告、演演算法等各個團隊的資料需求。本文主要介紹美團外賣離線數倉的歷史發展歷程,在發展過程中碰到的痛點問題,以及針對痛點做的一系列優化解決方案。01業務介紹

首先介紹下美團外賣的業務場景, 核心交易鏈路為:使用者可以通過美團的各種使用者終端(包括美團外賣的APP或者美團 APP、QQ/微信等)下單,然後商家接單、騎手配送,三個階段完成一筆交易。這一系列交易過程,由包括使用者端、商家端、配送平臺、資料組、廣告組等各個系統協同完成。
這裡主要介紹外賣資料組在整個業務中角色。外賣資料組主要是:
- 給使用者端、商家端提供業務需求,
- 給前端提供需要展示的資料,
- 給廣告、演演算法團隊提供特徵等資料,提高演演算法效率
- 向城市團隊提供業務開展所需資料
- 前端提供埋點指標、埋點規範相關資料
1. 整體架構介紹
美團外賣整體分為四層:資料來源層、資料加工層、資料服務層、資料應用層。
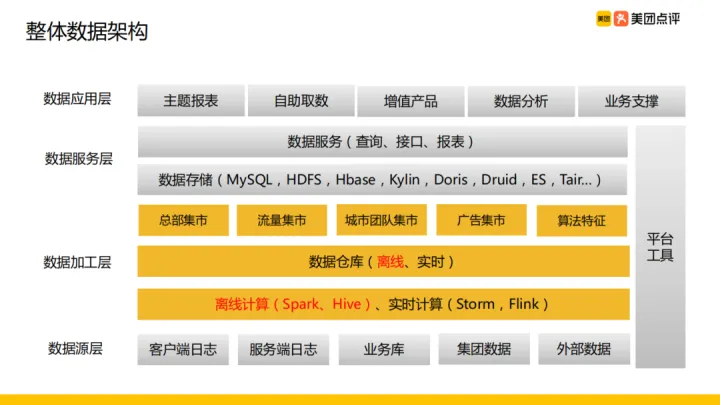
資料來源層:包含接入的原始資料,包括使用者端紀錄檔、伺服器端紀錄檔、業務庫、集團資料、外部資料等。
資料加工層:使用 Spark、Hive 構建離線數倉、使用 Storm、 Flink 實時數倉。在數倉之上針對服務物件建設各種資料市集,比如:
- 面向總部使用的總部資料市集
- 面向行為資料的流量資料市集
- 面向線下城市團隊的城市團隊集市
- 面向廣告的廣告集市
- 面向演演算法的演演算法特徵
資料服務層:主要包括儲存媒介的使用和資料服務的方式。
- 儲存:主要使用開源元件,如 Mysql, HDFS, HBase, Kylin, Doris, Druid, ES, Tair 等
- 資料服務:對外資料查詢、介面以及報表服務
資料應用層:主要包括主題報表、自助取數工具、增值產品、資料分析等支撐業務開展,同時依賴公司平臺提供的一些工具建設整體資料應用。
2. ETL on Spark

我們離線計算從 17 年開始從 Hive 遷移到 Spark, 目前大部分任務已經遷移到 Spark 上執行,任務遷移後,相比之前使用 Hive 整體資源節省超過 20%。相比之下 Spark 的主要優勢是:
- 運算元豐富,支援更復雜的業務邏輯
- 迭代計算,中間結果可以存記憶體,相比 MR 充分利用了記憶體,提高計算效率
- 資源複用,申請資源後重複利用
這裡簡單介紹寫 Spark Sql 的任務解析流程:使用者端提交任務後,通過 Sql 解析先生成語法樹,然後從 Catalog 獲取後設資料資訊,通過分析得到邏輯執行計劃,進行優化器規則進行邏輯執行的優化,最後轉成物理執行計劃提交到 spark 叢集執行。
02數倉建設
1. 資料倉儲V1.0
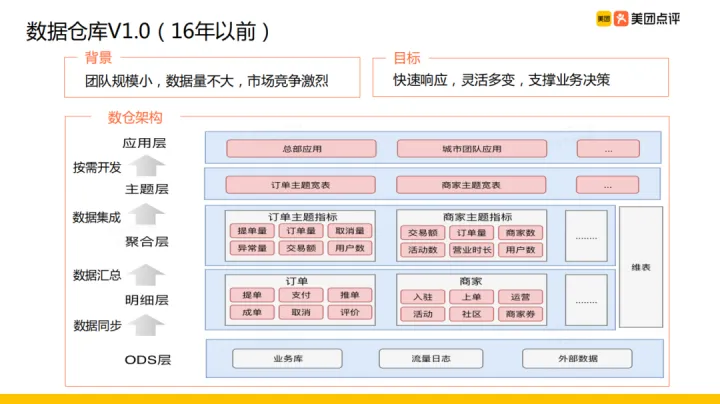
2016 年之前。外賣資料組的情況是:團隊不大,資料量不多,但是市場競品較多(餓了麼、百度等),競爭激烈, 因此當時資料組的目標是:快速響應業務需求,同時做到靈活多變,支撐業務業務決策,基於這種業務背景和實現目標,當時數倉架構設計如圖所示主要分了四層,分別是:ODS層/明細層/聚合層/主題層/應用層(具體如圖示)。

隨著資料量、業務複雜度與團隊規模的增長, 為更好完成業務需求資料組團隊按照應用做拆分,比如面向總部的總部團隊、面向城市業務的城市團隊,各個團隊都做一份自己的明細資料、指標和主題寬表資料,指標和主題寬表很多出現重疊的情況,這時候就像是」煙囪式「開發。這在團隊規模較小時,大家相互瞭解對方做的事情,基本不會有問題;但是在團隊規模增長到比較大的時候,多團隊「煙囪式」獨立作戰也暴露出了這種架構的問題,主要是:
- 開發效率低
- 資料口徑不統一
- 資源成本高
2. 資料倉儲V2.0
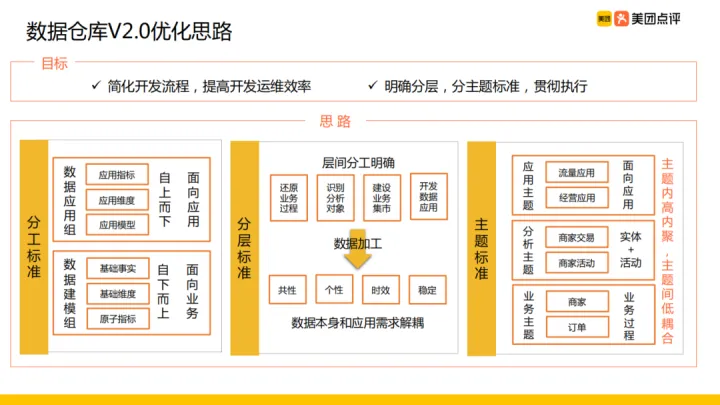
針對上述問題,資料組做了架構的升級,就是資料倉儲V2.0版本。此次升級優化的目標主要是:
- 簡化開發流程,提高開發運維效率
- 明確分層,分主題標準,貫徹執行
完成這個目標的思路如下三個方面:
① 分工標準:
之前面向不同應用建立不同團隊完全縱向切分,會導致可以公用的部分明細資料重複開發。為改變這種情況將資料團隊改為:資料應用組和資料建模組。各組職責如下:
- 資料應用組:負責應用指標、應用維度、應用模型,這一組的資料建模特點是:自上而下、面向應用。
- 資料建模組:負責基礎事實、基礎維度、原子指標的資料開發,這一組的資料建模特點是:自下而上、面向業務。
② 分層標準:
在原有分層的基礎上,再次明確各層的職責,比如:明細層用來還原業務過程,輕度彙總曾用來識別分析物件;同時資料加工時考慮資料的共性、個性、時效性、穩定性四個方面的因素,基於以上原則明確數倉各層達到資料本身和應用需求的解耦的目標。具體各層細節在文章接下來的內容會展開來講。
③ 主題標準:
根據數倉每層的特性使用不同的主題劃分方式,總體原則是:主題內部高內聚、不同主題間低耦合。主要有:明細層按照業務過程劃分主題,彙總層按照「實體+活動」劃分不同分析主題,應用層根據應用需求劃分不同應用主題。
2.1 數倉規範
① 資料倉儲建模規範

根據前述三個方面的思路,將數倉分為以下幾個層次:
- ODS:資料來源層,主要職責是接入資料來源,並做多資料來源的整合
- IDL:資料整合層,主要職責是:業務主題的劃分、資料規範化,比如商家、交易、使用者等多個主題。這一層主要起到緩衝的作用,遮蔽底層影響,儘量還原業務,統一標準。
- CDL:資料元件層,主要職責是劃分分析主題、建設各個主題的基礎指標,比如商家交易、使用者活動等多個主題。這樣針對同一個分析物件統一了指標口徑,同時避免重複計算。
- MDL:資料市集層,主要職責是建設寬表模型、彙總表模型,比如商家寬表、商家時段彙總表等。主要作用是支撐資料分析查詢以及支援應用所需資料。
- ADL:資料應用層,主要職責是建設應用分析、支撐多維分析應用,比如城市經營分析等。
其中 ODS/IDL/CDL,以及部分 MDL 集市由資料基建組來做,另外部分資料市集以及 ADL 應用層由資料應用組支撐,分工標準是涉及一些公共的資料市集由資料基建組來完成;資料應用組會圍繞應用建設應用資料市集,如流量集市、城市經營集市。
② 資料來源層
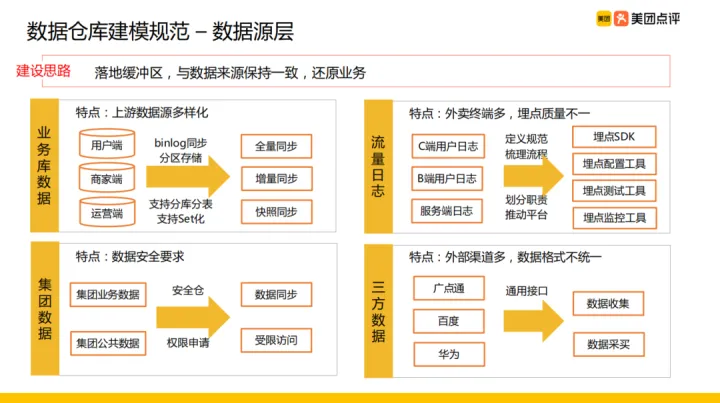
整體建設思路:從資料來源落地到 Hive 表,同時與資料來源保持一致,儘量還原業務。主要由四類資料來源:業務庫資料、流量紀錄檔、集團資料、三方資料。
- 業務庫資料:主要是將各個使用者端的資料同步 Hive ,主要有使用者端、商家端、運營端,同步方法主要採用 binlog 同步,同步方式有全量同步、增量、快照同步三種方式。同時支援業務庫分庫分表、分叢集等不同部署方式下的資料同步。
- 流量紀錄檔:特點是外賣終端多,埋點質量不一,比如單 C 端分類就超過十種。為此公司統一了終端埋點 SDK,保證不同終端埋點上報的資料規範一致,同時使用一些設定工具、測試工具、監控工具保證埋點的質量。整理建設思路是:定義埋點規範、梳理埋點流程、完善埋點工具。
- 集團資料:包含集團業務資料、集團公共資料,特點是資料安全要求高。目前公司建立了統一的安全倉,用於儲存跨 BU 的資料,同時定義許可權申請流程。這樣對於需要接入的資料,直接走許可權申請流程申請資料然後匯入業務數倉即可。
- 三方資料:外部渠道資料,特點是外部渠道多、資料格式不統一,對此我們提供了通用介面對於收集或者採買的三方資料在接入數倉前進行了規範化的清洗。
③ 資料整合層
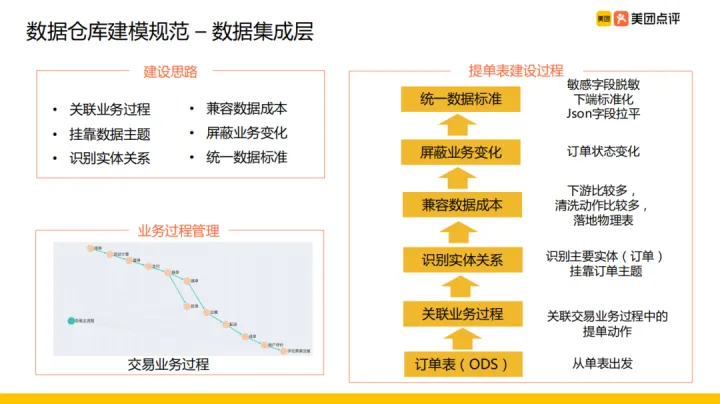
資料整合層主要是明細資料,與上一層資料來源層是有對應關係的。資料整合表的整體建設思路為:
- 抽象業務過程
- 識別實體關係,掛靠業務主題,比如交易過程包括提單、支付等過程,把這些業務行為涉及的事實表進行關聯,識別出裡面的實體關係
- 相容資料成本
- 遮蔽業務變化,比如訂單狀態變化
- 統一資料標準,敏感欄位脫敏,欄位名稱標準化等
如圖中範例為提單表建設過程。
④ 資料元件層

資料元件層,主要建設多維明細模型、輕度彙總模型。總體建設思路與建設原則為:
建設思路:
- 識別分析物件,包含分析物件實體以及物件行為
- 圈定分析邊界
- 豐富物件屬性
建設原則:
資料元件層生成的指標主要是原子指標,原子指標形成資料元件,方便下游的集市層以及應用層拼接資料表。
- 分析物件包括業務實體和業務行為
- 分析物件的原子指標和屬性的惟一封裝
- 為下一層提供可共用和複用的元件
多維明細模型:
以商家資訊表建設過程為例:
- 識別分析物件:首先明確分析物件為商家實體,
- 圈定分析邊界:多維明細不需要關聯實體行為,只需要識別出實體之後圈定商家屬性資訊作為分析邊界;
- 豐富物件屬性:提取商家屬性資訊,比如商家的品類資訊、組織結構資訊等
以上資訊就形成了一個由商家主鍵和商家多維資訊組成的商家實體的多維明細模型。
輕度彙總模型:
以商家交易表假設過程為例:
- 識別分析物件:分析實體是商家,業務行為是交易,分析物件是商家交易
- 圈定分析邊界:圈定提交表、商家資訊表、訂單狀態表、會員表作為商家交易的邊界
- 豐富物件屬性:將城市、組織結構等維度資訊冗餘進來,豐富維度屬性資訊
彙總商家粒度、交易額等原子指標最終建立商家交易表。
⑤ 資料市集層
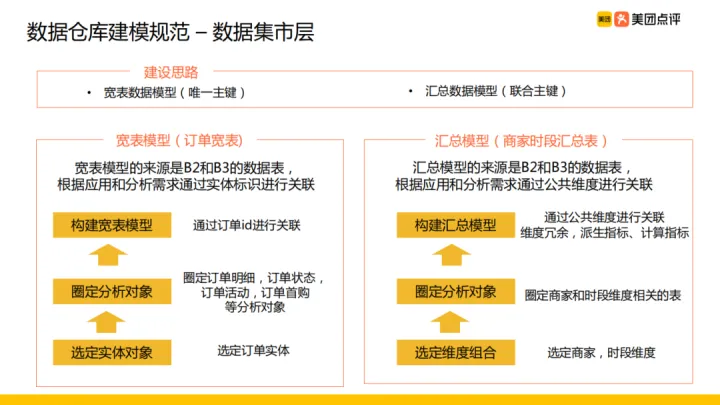
建設思路:
建立寬表模型和彙總模型。兩者區別為寬表模型是唯一主鍵,基於主鍵拼接各種資訊;彙總模型的主鍵型別為聯合主鍵,根據公共維度關聯生成派生指標,豐富資訊。
- 寬表模型:訂單寬表為例,建設過程為:選定訂單實體作為實體物件,然後圈定訂單明細、訂單狀態、訂單活動、訂單收購等分析對現象通過訂單 id 進行關聯。這裡的寬表模型與資料元件層的多維明細模型的區別在於多維明細模型裡的實體物件粒度更細,例如訂單寬表中分析物件:訂單明細、訂單狀態、訂單活動等都是多維明細模型裡的一個個資料元件,這幾個資料元件通過訂單 id 關聯拼接形成了寬表模型。
- 彙總模型:商家時段彙總表為例,建設過程為:選定商家、時段維度作為維度組合,圈定商家和時段維度相關的表,通過公共維度進行關聯、維度冗餘,支援派生指標、計算指標的建設。這裡區別於元件層的輕度彙總模型,在資料元件層建設的是原子指標,而資料市集層建設的是派生指標。
⑥ 資料應用層
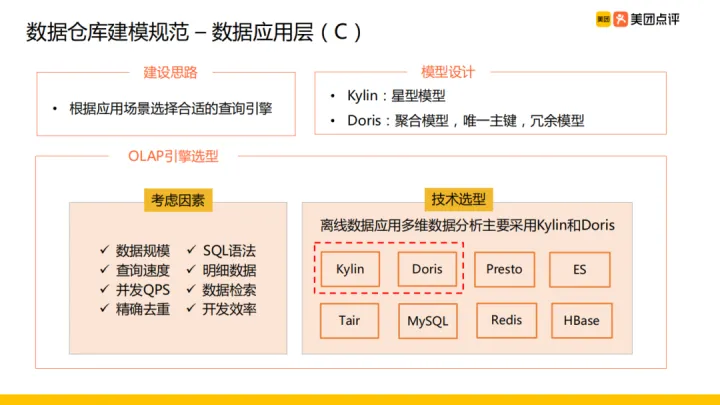
建設思路:根據應用場景選擇合適的查詢引擎
選型考慮因素:OLAP 引擎選型考慮以下 8 個方面的因素:
- 資料規模是否適合
- SQL 語法的支援程度如何
- 查詢速度怎麼樣
- 是否支援明細資料
- 是否支援高並行
- 是否支援資料檢索
- 是否支援精確去重
- 是否方便使用,開發效率如何
技術選型:早期主要使用 Kylin ,近期部分應用開始遷移 Doris。
模型:根據不同 OLAP 引擎使用不同資料模型來支援資料應用。基於 Kylin 引擎會使用星型模型的方式構建資料模型,在 Doris 支援聚合模型,唯一主鍵以及冗餘模型。
2.2 數倉 V2.0 的缺點

前面幾小節對數倉 2.0 做了詳細的介紹,在數倉 2.0 版本的建設過程中我們也遇到了一些問題。前面有提到資料整合層與元件層由資料基建組來統一運維,資料應用層是由資料應用組來運維,這樣導致雖然在整合層和元件做了收斂但是在應用層和集市層卻產生了膨脹,缺乏管理。
面對這個問題,我們在 2019 年對數倉進行了新的迭代,即數倉 V3.0,下面將對此做詳細介紹。
3. 資料倉儲V3.0
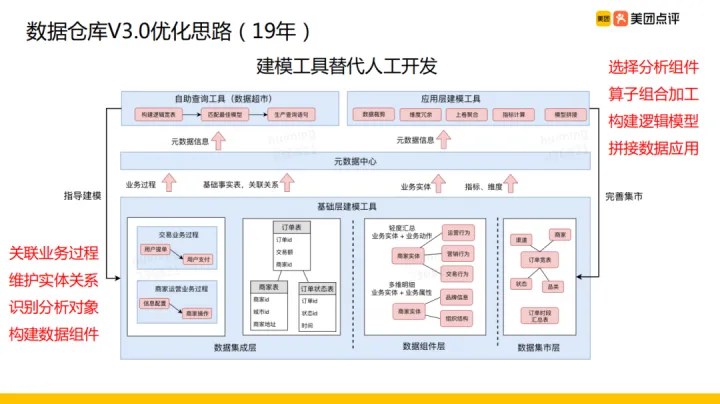
總體願景:數倉 3.0 優化思路主要是使用建模工具替代人工開發。
建模工具:分為基礎的建模工具和應用層建模工具。
- 基礎層建模工具:主要是在後設資料中心記錄維護業務過程、表的關聯關係、實體物件、識別的分析物件,基於維護的資訊構建資料元件以供應用層和集市層拼接
- 自助查詢工具:根據資料元件和使用者選取的需要查詢的指標維度資訊構建邏輯寬表,根據邏輯寬表匹配最佳模型從而生成查詢語句將查詢出來的資料反饋給使用者。同時根據使用者查詢情況反過來指導建模,告訴我們需要把哪些指標和哪些維度經常會放在一起查詢,根據常用的指標、維度組合建設資料元件
- 應用層建模工具:依賴資料元件,包括資料元件層的多維明細資料、輕度彙總資料以及集市層的寬表等構建構建資料應用。主要過程是獲取所需資料元件,進行資料裁剪,與維表關聯後冗餘維度屬性,按需進行上卷聚合、複合指標的計算,最終把獲取到的多個小模型拼接起來構建資料應用
通過整套工具的使得資料元件越來越完善,應用建模越來越簡單,以上就是數倉 3.0 的整體思路。
03資料治理
1. 資料開發流程
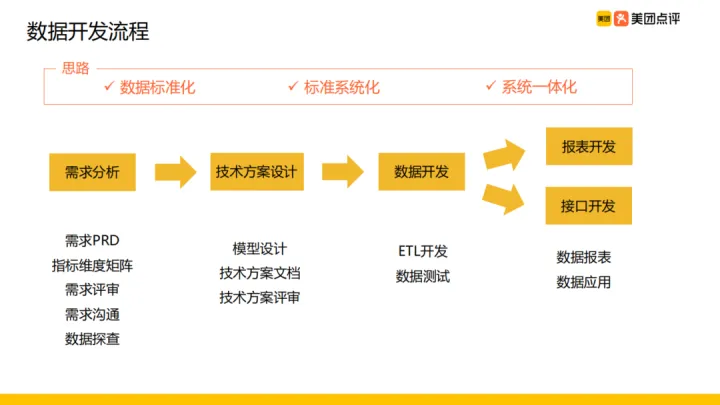
先說下我們資料開發流程,資料開發流程主要分為四個階段:需求分析、技術方案設計、資料開發、報表開發&介面開發,具體內容如下:
- 需求分析:在需求分析階段,產品會設計一個需求 PRD 以及列出指標維度矩陣,然後需求評審與需求相關人員進行溝通,做一些資料的探查
- 技術方案設計:完成需求分析之後,形成模型設計的技術方案,同時將方案落地到檔案進行技術方案的評審
- 資料開發:完成技術方案的設計與評審就正式進入了資料開發以及測試階段
- 報表開發&介面開發:資料開發完成之後進入具體應用的開發
在整個資料開發流程中,我們遵循的整體思路是:
- 資料標準化
- 標準系統化
- 系統一體化
即資料符合標準規範,同時將標準規範落地到系統裡,最後系統要和周邊應用打通,形成一體。下面對各個思路做詳細的描述。
① 資料標準化

在資料標準化這塊,資料產品團隊、資料開發團隊、資料分析團隊聯合建立了資料標準化委員會。資料標準委員會制定了《指標標準規範》、《維度標準規範》以及一些新增指標、維度的流程等一系列規範標準,這樣做的好處是:指標維度管理有據可依,指標維度管理有組織保障,保障各業務方指標維度口徑清晰統一。
② 標準系統化
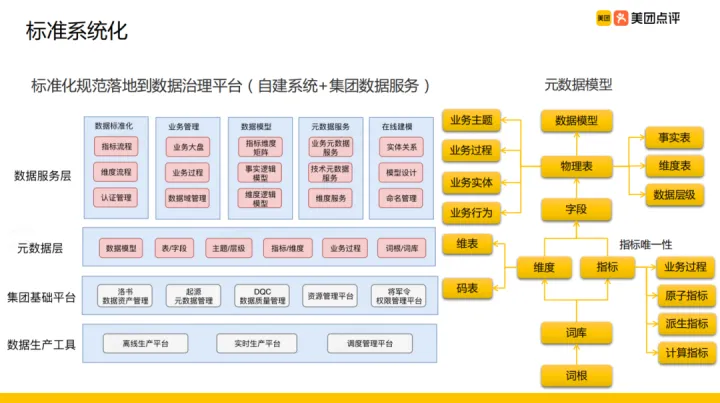
明確了資料標準各項規範,需要將這些標準化規範落地到系統,就是我們的資料治理平臺,我們的資料治理平臺由自建系統 + 集團資料服務構成。這裡面主要有四層:資料生產工具、集團基礎平臺、後設資料層、資料服務層。
- 資料生產工具:資料生產主要依靠平臺的計算能力,包括離線生產平臺、實時生產平臺、排程管理平臺
- 集團基礎平臺:資料生產工具之上是集團基礎平臺,包括資料資產管理、後設資料管理、資料質量管理、資源管理以及許可權管理
- 後設資料層:後設資料與資料服務都是美團外賣自己業務做的一些工作,後設資料層包括資料模型、表/欄位、主題/層級、指標/維度、業務過程、詞根/詞庫
- 資料服務層:服務層包含有資料標準化,前面提到的指標流程、維度流程、認證管理都是在這裡落地;同時把業務管理起來,包括理業務大盤、業務過程、資料域管理;然後還管理我們的資料模型包括指標維度矩陣、事實邏輯模型、維度邏輯模型;同時提供後設資料服務,包含業務後設資料、技術後設資料以及維度服務;還有剛才提到的一些線上建模工具
圖片右邊展示了我們的後設資料模型,從下而上,我們首先維護詞根組成的詞庫,同時詞根、詞庫組成我們的指標和維度,其中維度分為維表和碼錶,指標在確保唯一性的前提下劃分業務過程,同時區分原子指標、派生指標、計算指標;然後由維度和指標拼接成欄位、欄位組成表,表再和業務主題、業務過程相關聯,識別出實體、行為,區分事實表、維度表同時確定表所在的層級,最後由一張張的表組成我們的資料模型,整個過程就是我們的後設資料模型。
③ 系統一體化

有了前面的資料資訊之後,我們和下游對接就比較方便。使用到資料治理平臺的資料下游有:
- 報表系統:報表展示所需的指標維度資訊、模型資訊都是來自於資料治理平臺,
- 資料超市:資料超市的自助取數里根據指標、維度、資料元件構建資料查詢,這些資訊都是來自資料治理平臺,
- 海豚資料平臺:海豚資料平臺是我們的外賣資料門戶
- 異常分析平臺:對指標維度的波動進行監測分析
- CRM 系統:面向一線城市團隊的資料展示
- 演演算法平臺:向演演算法平臺提供標籤、特徵資料的管理
- 畫像平臺:管理畫像平臺的人群標籤
- 資料 API 服務:對外提供的 API 模型以及介面的資訊
- 到家資料檢索:到家業務後設資料聯通,統一檢索後設資料資訊
- 公司後設資料平臺:向公司後設資料平臺提供後設資料資訊
通過與各個下游不同形式的對接,資料治理平臺完成了整個下游資料應用的聯通,以及支援資料使用與生產,形成了一體化的系統。
2. 資源優化
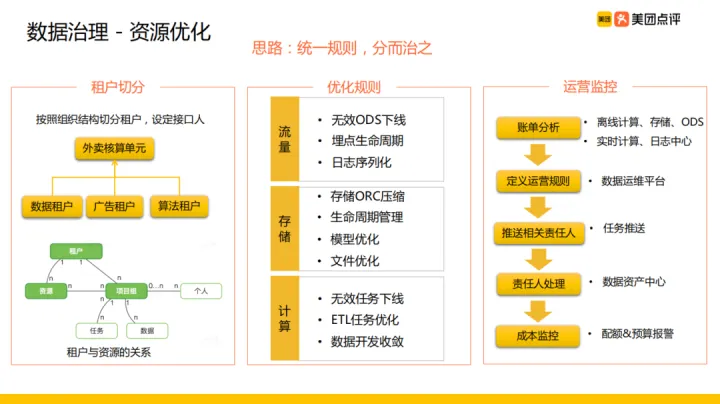
資源優化方面,在美團會把核算單元分成若干個租戶 ,然後把資源分配給各個租戶,在同一個租戶裡各個專案組協調分割分配到資源,專案組由任務和資料組成。
我們把租戶與對應主題進行掛靠,這樣就可讓租戶有對應的介面人管理,比如把外賣核算單元分為:數倉租戶、廣告租戶、演演算法租戶以及其他的業務租戶,讓每個租戶對應一個介面人,與介面人對接資源優化方案、規則,最後由介面人推動。
我們的優化規則主要分為三個方向:
- 流量:流量方面,主要是對無效 ODS 下線從而降低儲存與傳輸成本;同時埋點資料生命週期減少成本浪費,目前使用者日活幾千萬,上報的流量紀錄檔是有上百億,埋點若不再使用對儲存與傳輸成本浪費較大;另外對紀錄檔進行序列化壓縮處理降低成本
- 儲存:儲存方面我們使用 ORC 進行壓縮,同時對冷熱資料做了生命週期管理,另外也通過模型的優化以及檔案的優化把儲存成本控制住
- 計算:計算方面對無效任務進行下線、 ETL 任務優化;同時對資料開發收斂,把業務中公共部分收斂到資料組
有了優化規則,針對規則的運營監控流程為:首先對賬單分析,賬單主要有離線/實時計算資源、儲存資源、ODS 資料收集使用的資源、紀錄檔中心所使用的資源, 分析帳單後定義運營規則並將規則落地到資料運維平臺,由資料運維平臺將任務推播到相關責任人,責任人收到通知後,在資料資產中心做相關處理,同時資料運維平臺會做成本監控,對超出配額&預算異常進行報警。
這樣我們通過建立統一規則並將規則分發到不同租戶落地執行,完成資料資源優化的目標。
3. 資料安全
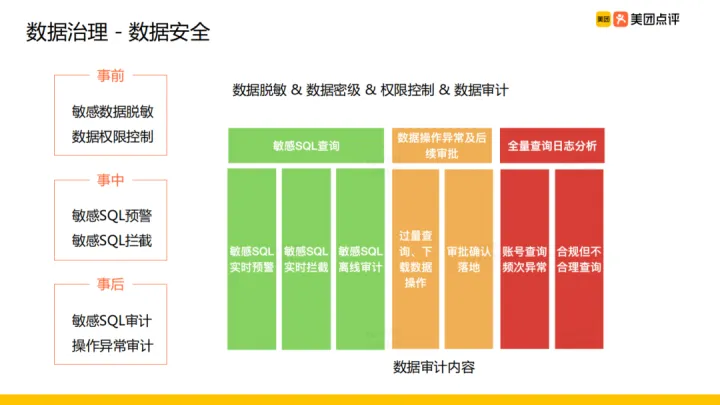
資料安全方面主要是對資料脫敏,資料保密等級的設定 (C1~C4),資料申請做許可權控制,審計資料使用的方式,我們分三個階段完成資料安全的治理:
- 事前:包括敏感資料脫敏、資料許可權控制。針對事業部內、事業部外使用不同的許可權流程控制。
- 事中:包括敏感 SQL 的預警與攔截,針對敏感 SQL 我們進行攔截並由資料安全人員進行審批
- 事後:包括敏感 SQL 審計,操作異常審計。輸出敏感 SQL 審計的月報發到對應的部門負責人,稽核內容主要有敏感 SQL 的查詢、資料操作異常及後續審批還有全量查詢紀錄檔分析。
04未來規劃
1. 未來規劃思考

最後介紹下,我們對未來的規劃,對未來規劃的思考主要是在業務和技術兩個方面:
- 業務目標:通過資料賦能業務,幫助完成未來實現業務訂單量和收入的高速增長的目標
- 技術目標:提高高效、易用、高質量、低成本的資料服務
這裡面資料價值的具體體現,總結為以下幾點:
- 基礎的資料能力:保障資料服務的穩定性,以及資料的時效性越來越高,以及資料服務的覆蓋度足夠廣、足夠全,擴巨量資料服務內容
- 運營決策支援:及時洞察業務變化,直到業務完成運營決策
- 資料商業變現:通過增值型資料產品,把資料進行商業變現
- 業務資料支援:更好的支援對接的各個業務系統,從而提高整體資料價值
- 演演算法效率提升:針對演演算法加工特徵所需的資料提供更好的支援,以提高演演算法模型效率,完成使用者轉化率的提高
- 社會影響力:通過我們的 PR 團隊做一些對外的分析報告,擴大行業影響力
2. 未來規劃實施
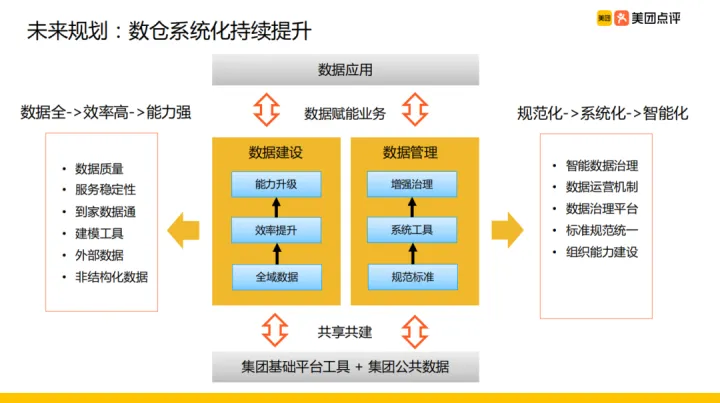
針對對未來規劃的思考,我們具體實施措施計劃是:與集團基礎平臺工具共用共建,在資料應用方面更好做到資料賦能業務,然後就是具體的資料建設、資料管理。
資料建設:
資料建設主要圍繞以下幾個方面:
- 資料全:我們希望我們的資料足夠全,包括外賣的資料以及團購、點評的線下資料和外部採買的資料等,只要是外賣需要的資料我們都儘量採集過來
- 效率高:效率提升方面,我們剛剛提到我們的使用建模工具替代人工工作從而提高我們的效率
- 能力強:在足夠全的資料、提升效率的基礎上提高我們的能力,包括服務的穩定性、資料質量
資料管理:
通過完善資料標準規範,並將規範落地到工具以及增強資料治理,另外通過演演算法的手段發現資料裡隱藏的問題完成資料資料治理。這主要需要我們組織能力建設、標準規範的統一、完善資料治理平臺與資料運營機制、探索智慧資料治理,最終達到資料管理的規範化、系統化、智慧化的目的。
-------------------------------------------
個性簽名:獨學而無友,則孤陋而寡聞。做一個靈魂有趣的人!
如果覺得這篇文章對你有小小的幫助的話,記得在右下角點個「推薦」哦,博主在此感謝!
萬水千山總是情,打賞一分行不行,所以如果你心情還比較高興,也是可以掃碼打賞博主,哈哈哈(っ•?ω•?)っ???!