循序漸進講解負載均衡vivoGateway(VGW)
作者:vivo 網際網路運維團隊- Duan Chengping
在大規模業務場景中,已經不可能通過單機提供業務,這就衍生出了負載均衡的需求。為了滿足合適可靠的負載,本文將從簡單的基礎需求出發,一步步推進並解釋如何建立負載均衡平臺。
一、怎麼保證你的業務可靠
想一個問題:假設你有10臺伺服器對外提供相同的服務,你如何保證這10臺伺服器能穩定處理外部請求?
這裡可能有很多種解決方案,但本質上都是處理下述兩個問題:
① 使用者端的請求應該分配去哪一臺伺服器比較好?
② 萬一其中某些伺服器故障了,如何隔離掉故障伺服器?
問題① 處理不好,可能會導致10臺伺服器中的一部分伺服器處於飢餓狀態,沒有被分配使用者端請求或者是分配得很少;而另一部分則一直在處理大量的請求,導致不堪負重。
問題② 處理不好,則CAP原則中的可用性(A)可能就沒法保證,除非系統不需要A。
要解決上述問題,你必須實現一套控制器,能排程業務請求和管理業務伺服器。很不幸的是,大多數情況下這個控制器往往就是整個系統的瓶頸。因為控制系統如果不深入到使用者端上,就必須依賴一個集中式的決策機構,這個機構必然要承載所有使用者端的請求。這時候你又得去考慮這個控制器的冗餘和故障隔離的問題,這就變得無休無止。
二、業務和控制隔離
那麼,如何解決上述問題?
那就是專業的事情交給專業平臺去做,即,我們需要獨立的負載均衡提供上述2點的解決方案。
對於使用者端來說,每次請求一個站點,最終都會轉變成對某個IP發起請求。所以只要能控制使用者端存取的IP地址,我們就能控制請求應該落到哪個後端伺服器上,從而達到排程效果,這是DNS在做的事情。或者,劫持使用者端所有請求流量,對流量重新分配請求到後端伺服器上。這個是Nginx、LVS等的處理方式。
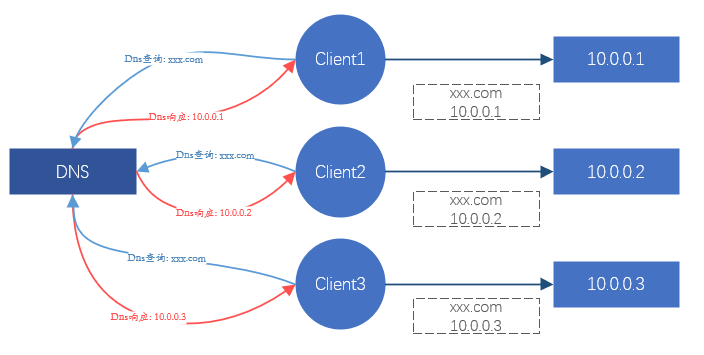
圖1、通過DNS實現負載均衡的效果示意圖
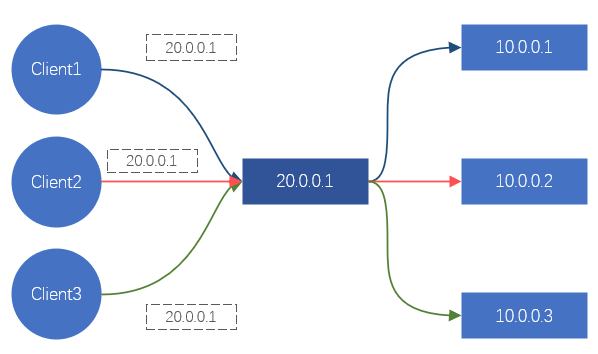
圖2、通過LVS/Nginx實現負載均衡的效果示意圖
這兩個方式都能達到負載均衡的效果。但這裡面有個嚴重的問題,DNS、Nginx、LVS等服務在網際網路時代不可能單機就能提供業務,都是叢集式(也就是有N臺伺服器組成),那這些叢集的可靠性和穩定性又該如何保證呢?
DNS主要負責域名解析,有一定的負載均衡效果,但往往負載效果很差,不作為主要考慮手段。Nginx提供7層負載均衡,主要靠域名來做業務區分和負載。LVS是4層負載均衡,主要靠TCP/UDP協定、IP地址、TCP/UDP埠來區分服務和負載。
為了解決Nginx、LVS這些負載均衡器叢集的負載均衡及可靠性,我們可以做下述簡單的方案:
-
業務伺服器的負載和可靠性由Nginx保障;
-
Nginx的負載和可靠性由LVS保障。
上述方案是遵循了業務 <-- 7層負載 <-- 4層負載的邏輯,實際上是在網路分層模型中的應用層 <-- 傳輸層的做兩級負載。可以看出,其實這個方案是用另一層負載均衡來解決當前層級的負載和可靠性的問題。但這個方案還是有問題,業務和Nginx叢集這兩層的負載和可靠性是有保障了,但LVS叢集這一層的可靠性怎麼辦?
既然我們在網路分層模型中應用層 <-- 傳輸層做了兩級負載,那有沒有可能做到應用層 <-- 傳輸層 <-- 網路層的三級負載?很幸運的是,基於IP路由的方式,網路裝置(交換機、路由器)天然具備了網路層負載均衡功能。
到此,我們可以實現整個負載均衡鏈條:業務 <-- 7層負載(Nginx) <-- 4層負載(LVS) <-- 3層負載(NetworkDevices);
從這裡可以看出,要確保整個負載均衡體系是有效可靠的,必須從網路層開始構築。處於高層級的業務,可以為低層級的業務提供負載。相對於低層級,高層級的業務都可以認為是低層級業務的控制面,可以交給專業團隊去實現和管理,低層級業務側只需要關注業務本身實現即可。
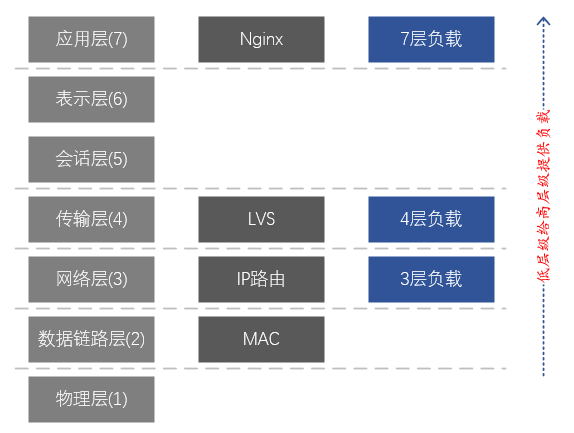
圖3、網路7層模型和LVS、Nginx之間的對應關係
網路7層分層模型說明:
7、應用層: 支援網路應用,應用協定僅僅是網路應用的一個組成部分,執行在不同主機上的程序則使用應用層協定進行通訊。主要的協定有:HTTP、FTP、Telnet、SMTP、POP3等。
6、表示層: 資料的表示、安全、壓縮。(實際運用中該層已經合併到了應用層)
5、對談層: 建立、管理、終止對談。(實際運用中該層已經合併到了應用層)
4、傳輸層: 負責為信源和信宿提供應用程式程序間的資料傳輸服務,這一層上主要定義了兩個傳輸協定,傳輸控制協定即TCP和使用者資料包協定UDP。
3、網路層: 負責將資料包獨立地從信源傳送到信宿,主要解決路由選擇、擁塞控制和網路互聯等問題。
2、資料鏈路層: 負責將IP資料包封裝成合適在物理網路上傳輸的幀格式並傳輸,或將從物理網路接收到的幀解封,取出IP資料包交給網路層。
1、物理層: 負責將位元流在結點間傳輸,即負責物理傳輸。該層的協定既與鏈路有關也與傳輸媒介有關。
三、如何實現4層負載均衡
上面說過,3層負載由網路裝置天然提供,但實際使用中是和4層負載緊耦合的,一般不獨立提供服務。4層負載可以直接為業務層提供服務,而不依賴7層負載(7層負載主要面向HTTP/HTTPS等業務),所以我們這裡主要針對4層負載來講。
3.1 如何轉發流量
實現負載均衡,言外之意就是實現流量重定向,那麼,首要解決的問題是如何轉發流量。
4個問題要解決:
① 如何把使用者端的流量吸引到負載均衡器上?
② 負載均衡器如何選擇合適的後端伺服器?
③ 負載均衡器如何將請求資料傳送到後端伺服器上?
④ 後端伺服器如何響應請求資料?
對於①,
解決方案很簡單,給一批後端伺服器提供一個獨立的IP地址,我們稱之為Virtual IP(也即VIP)。所有使用者端不用直接存取後端IP地址,轉而存取VIP。對於使用者端來說,相當於遮蔽了後端的情況。
對於②,
考慮到處於低層級的負載均衡通用性,一般不做複雜的負載策略,類似RR(輪詢)、WRR(帶權重輪詢)的方案更合適,可以滿足絕大多數場景要求。
對於③,
這裡的選擇會往往會影響這④的選擇。理想情況下,我們期望是使用者端的請求資料應該原封不動的傳送到後端,這樣能避免封包被修改。前面提到的網路七層分層模型中,資料鏈路層的轉發可以做到不影響更上層的封包內容,所以可以滿足不修改使用者端請求資料的情況下轉發。這就是網路常說的二層轉發(資料鏈路層,處在七層網路模型中的第二層),依靠的是網路卡的MAC地址定址來轉發資料。
那麼,假設把使用者端的請求封包當成一份應用資料打包送到後端伺服器是不是可行?該方式相當於負載均衡器和後端建立了一個隧道,在隧道中間傳輸使用者端的請求資料,所以也可以滿足需求。
上述兩種解決方案中,依賴資料鏈路層轉發的方案稱之為直接路由方式(Direct Route),即DR模式;另一種需要隧道的方案稱之為隧道(Tunnel)模式。DR模式有一個缺點,因為依賴MAC地址轉發,後端伺服器和負載均衡器必須在同一個子網中(可以不嚴謹認為是同一個網段內),這就導致了只有和負載均衡伺服器在同子網的伺服器能接入,不在同一個子網的這部分就沒有使用負載均衡的機會了,這顯然不可能滿足當前大規模的業務。Tunnel模式也有缺點:既然資料轉發依賴隧道,那就必須在後端伺服器和負載均衡器之間建立隧道。如何確保不同業務人員能正確在伺服器上設定隧道,並且能監控隧道正常執行,難度都很大,需要一套完成的管理平臺,言外之意即管理成本過高。
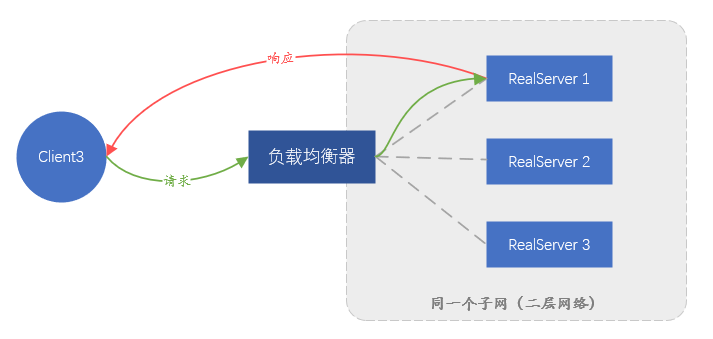
圖4、DR模式的轉發示意圖,響應流量不會經過負載均衡器
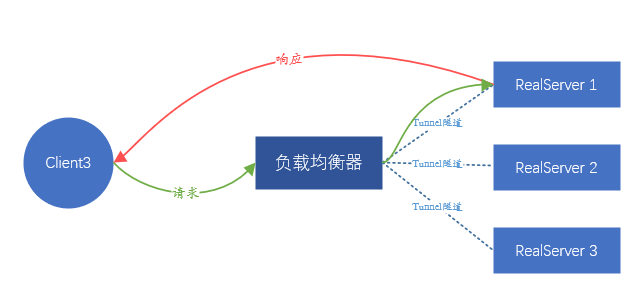
圖5、Tunnel模式轉發示意圖,和DR一樣,響應流量不會經過負載均衡器
既然都不是很理想,那還有沒有其他方案?
我們期望的是後端伺服器不感知前端有負載均衡存在,服務可以放在任何地方,且不做任何過多設定。既然做不到原封不動傳送使用者端的封包,那就代理使用者端的請求。也就是對使用者端發出來的封包的源IP和目的IP分別做一次IP地址轉換。
詳細來說,負載均衡器收到使用者端A的請求後,自己以使用者端的角色向後端伺服器發起相同的請求,請求所帶的payload來自於使用者端A的請求payload,這樣保證了請求資料一致。
此時,負載均衡器相當於發起了一個新連線(不同於使用者端A發起的連線),新建的連線將會使用負載均衡器的IP地址(稱之為LocalIP)作為源地址直接和後端伺服器IP通訊。
當後端返回資料給負載均衡器時,再用使用者端A的連線將資料返回給使用者端A。整個過程涉及了兩個連線,對應兩次IP地址轉換,
-
請求時刻:CIP→VIP, 轉換成了LocalIP→後端伺服器IP,
-
資料返回時刻:後端伺服器IP→ LocalIP, 轉換成了VIP→ CIP。
使用者端該過程完全基於IP地址轉發資料,而不是MAC地址,只要網路可達,資料就可以順暢在使用者端和後端之間傳輸。
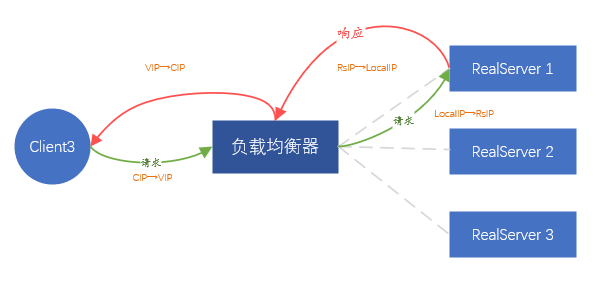
圖6、FULLNAT轉發模式
上述方案稱之為FULLNAT轉發模式,也就是實現了兩次地址轉換。顯然,這種方式足夠簡單,不需要後端伺服器做任何調整,也不限制後端部署在何處。但也有個明顯問題,那就是後端看到的請求全部來自於負載均衡器,真實的使用者端IP資訊完全看不到了,這就相當於遮蔽了真實使用者端的情況。幸運的是資料中心中絕大多數應用並不需要明確知道真實使用者端的IP地址資訊,即便是需要真實使用者端IP資訊,負載均衡器也可以將這部分資訊載入在TCP/UDP協定資料中,通過按需安裝一定的外掛獲取。
綜合上述幾種方案來說,FULLNAT模式對我們的業務場景(非虛擬化環境)適合度是最佳的。
既然我們打算使用FULLNAT模式, 則④的解決就沒有任何困難了,因為負載均衡器間接充當了使用者端角色,後端的資料必然要全部轉發給負載均衡器,由負載均衡器再發給真正的使用者端即可。

表1:各種模式之間的優劣勢分析
3.2 如何剔除異常後端伺服器
負載均衡一般提供對後端的健康檢查探測機制,以便能快速剔除異常的後端IP地址。理想情況下,基於語意的探測是最好的,能更有效的檢測到後端是不是異常。但這種方式一來會帶來大量的資源消耗,特別是後端龐大的情況下;這還不是特別嚴重的,最嚴重的是後端可能執行了HTTP、DNS、Mysql、Redis等等很多種協定,管理設定非常多樣化,太複雜。兩個問題點加起來導致健康檢查太過於笨重,會大量佔用本來用於轉發資料的資源,管理成本過高。所以一個簡單有效的方式是必要的,既然作為4層負載,我們都不去識別上游業務是什麼,只關注TCP或者UDP埠是不是可達即可。識別上層業務是什麼的工作交給Nginx這型別的7層負載去做。
所以只要定期檢查所有後端的TCP/UDP埠是否開放,開放就認為後端服務是正常的,沒有開放就認為是服務異常,後端列表中剔除,後續將不再往該異常後端轉發任何資料。
那麼如何探測?既然只是判斷TCP埠是不是正常開放,我們只要嘗試建立一個TCP連線即可,如果能建立成功,則表明埠是正常開放的。但是對於UDP來說,因為UDP是無連線的,沒有新建連線的這種說法,但同樣能夠靠直接傳送資料來達到探測的目的。即,直接傳送一份資料,假設UDP埠是正常開放的,所以後端通常不會做響應。如果埠是沒有開放的,作業系統會返回一個icmp port unreachable狀態,可以藉此判斷埠不可達。但有個問題,如果UDP探測封包裡帶了payload,可能會導致後端認為是業務資料導致收取到無關資料。
3.3 如何實現負載均衡器的故障隔離
前面我們說過,4層負載均衡依賴於網路層衡來確保4層負載均衡器之間的負載是平衡的,那麼負載均衡器的故障隔離就是依賴於網路層來做。
具體如何做?
實際上,我們是依賴於路由的方式來做網路層的負載均衡,負載均衡叢集中每臺伺服器都把相同的VIP地址通過路由協定BGP通告給網路裝置(交換機或者路由器),網路裝置收到相同的一個VIP來自不同的伺服器,就會形成一個等價路由(ECMP),言外之意就是形成負載均衡。所以如果我們想要隔離掉某臺負載均衡器的話,只要在該伺服器上把通過BGP路由協定釋出的VIP復原即可,這樣,上游交換機就認為該伺服器已經被隔離,從而不再轉發資料到對應裝置上。
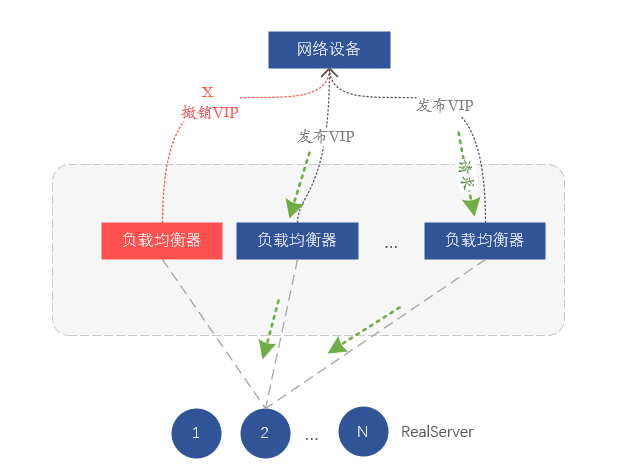
圖7、通過復原VIP路由進行故障隔離
至此,我們已經實現了一個基於FULLNAT,主要依賴三層協定埠做健康檢查,通過BGP和網路裝置對接實現VIP收發的方式實現負通用載均衡架構模型。
四、VGW的實現方案
基於上述4層負載的架構,我們建設了VGW(vivo Gateway),主要對內網和外網業務提供4層負載均衡服務。下面我們將從邏輯架構、物理架構、冗餘保障、如何提高管理性轉發效能等方面進行說明。
4.1 VGW元件
VGW核心功能是複雜均衡,同時兼具健康檢查,業務引流等功能,所以組成VGW的元件主要就是核心的負載均衡轉發模組、健康檢查模組、路由控制模組。
-
負載均衡轉發模組:主要負責負載計算和資料轉發;
-
健康檢查模組:主要負責檢測後端(RealServer)的可用狀態,並及時清除不可用後端,或者恢復可用後端;
-
路由控制模組:主要進行VIP釋出引流和隔離異常VGW伺服器。
4.2 邏輯架構方案
為了方便理解,我們把使用者端到VGW環節的部分稱之為外部網路(External),VGW到後端(RealServer)之間的環節較內部網路(Internal)。從邏輯架構上將,VGW功能很簡單,就是把External的業務請求均勻分發到Internal的RealServer上。
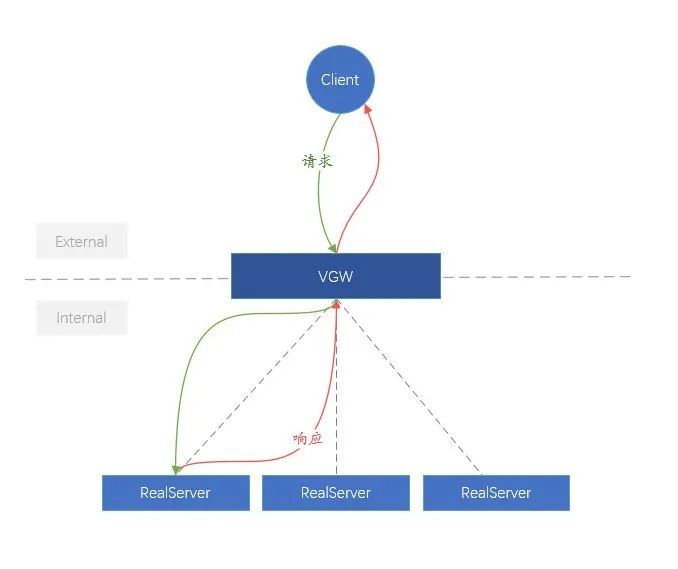
圖8、VGW邏輯示意圖
4.3 物理架構方案
物理架構上,對於提供內網的VGW和外網的VGW會有一定差異。
外網VGW叢集使用了至少2張網路卡,分別接外網側網路裝置和內網側網路裝置。對於VGW伺服器來說,兩個網口延伸出兩條鏈路,類似人的一雙手臂,所以稱這種模式為雙臂模式,一個封包只經過VGW伺服器的單張網路卡一次。
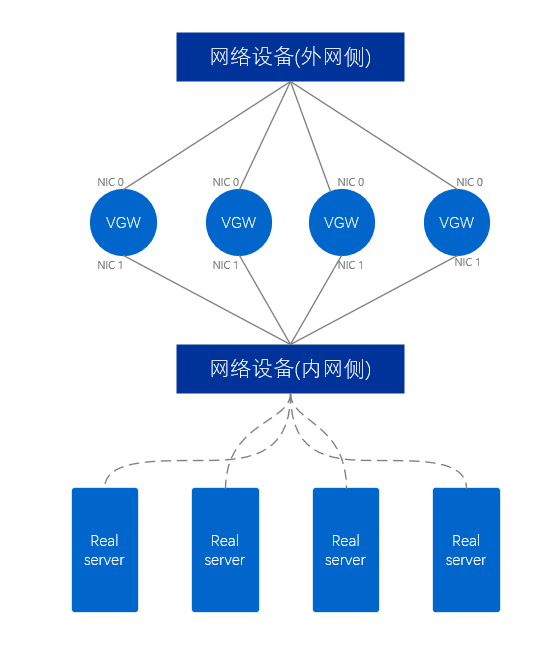
圖9、外網VGW物理示意圖
而內網VGW和外網不同,內網VGW則只用使用了1張網路卡,直接內網側網路裝置。相對應的,該方式稱為單臂模式,一個封包需要需要先從僅有的一張網路卡進,然後再從網路卡出,最後轉發到外部,總計穿過網路卡2次。
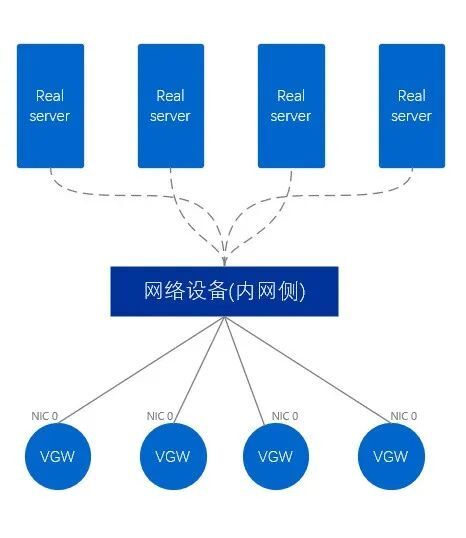
圖10、內網VGW物理示意圖
4.4 VGW現有業務模型
前面我們說過,負載均衡可以為7層負載提供更上一層的負載均衡。
-
當前VGW最大的業務流量來自於7層接入接出平臺(也就是Nginx)的流量,而Nginx基本承載了公司絕大部分核心業務。
-
當然Nginx並不能支援所有型別的業務,直接構建於TCP、UDP之上的非HTTP型別這一部分流量7層Nginx並不支援,這類業務直接有VGW將資料轉發至業務伺服器上,中間沒有其他環節,比如kafka、Mysql等等。
-
還有一部分業務是使用者自建了各種代理平臺,類似於Nginx等等,但也由VGW為其提供4層負載均衡。
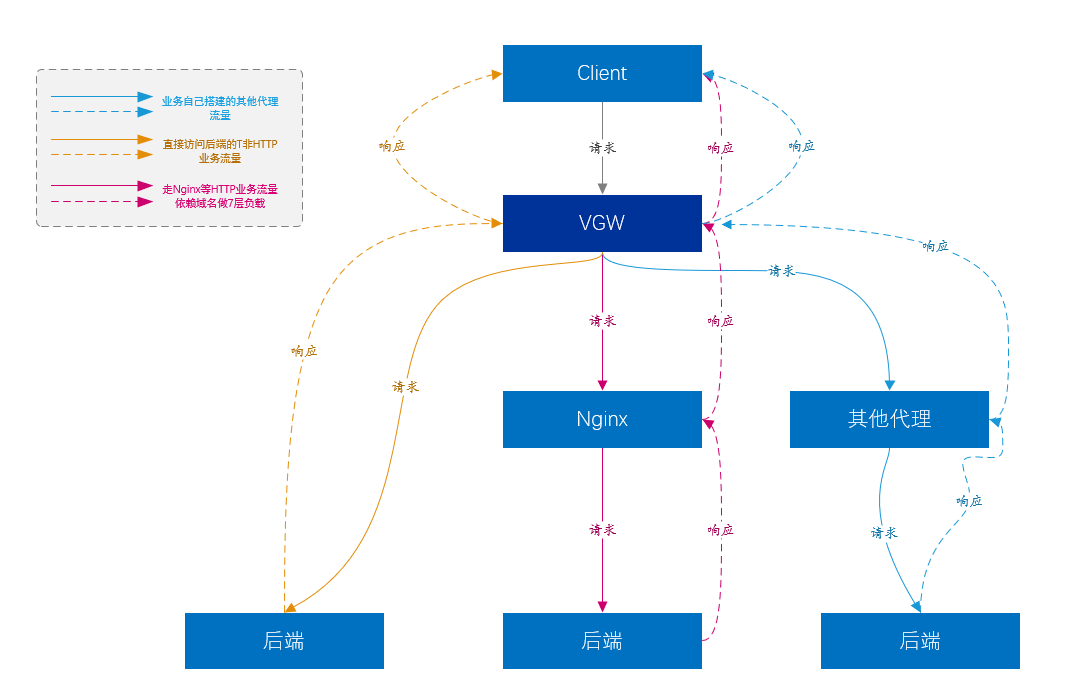
圖11、VGW業務模型圖
4.5 VGW的冗餘保障
為了提高可用性,那麼考慮哪些風險?大家自然而然的考慮到伺服器故障、程序故障等場景。但VGW場景需要考慮更多,因為VGW整個系統包括了鏈路、網路裝置、伺服器、程序等。而且還不能只考慮裝置宕機這種簡單的場景,實際上,上述任何裝置出現不宕機但轉發異常的情況才是最麻煩的。
所以監控VGW服務轉發是不是正常是第一步,我們通過布放在不同機房和地區的探測節點定期和VIP建立連線,通過建立連線的失敗比列來作為衡量VGW是不是正常的標準。實際上,該監控相當於檢測了整個涉及VGW的所有環節的鏈路和轉發是不是良好的。
上面的監控覆蓋到的是叢集級別的探測,當然我們也建立了其他更細粒度的監控來發現具體問題點。
在有監控一手資料之後,我們就能提供伺服器級別故障處理和叢集級別的故障處理能力。
-
所有裝置級別的直接宕機,VGW做到自動隔離;
-
所有鏈路級別的異常,一部分能自動隔離;
-
所有程序級別的異常,能達到自動隔離;
-
其他非完全故障的異常,人工介入隔離。
伺服器級別故障隔離是將某一些VGW伺服器通過路由調整將取消VIP的釋出,從而達到隔離目的;
叢集級別故障隔離是將整個VGW叢集的VIP取消釋出,讓流量自動被備用叢集牽引,由備用叢集接管所有業務流量。
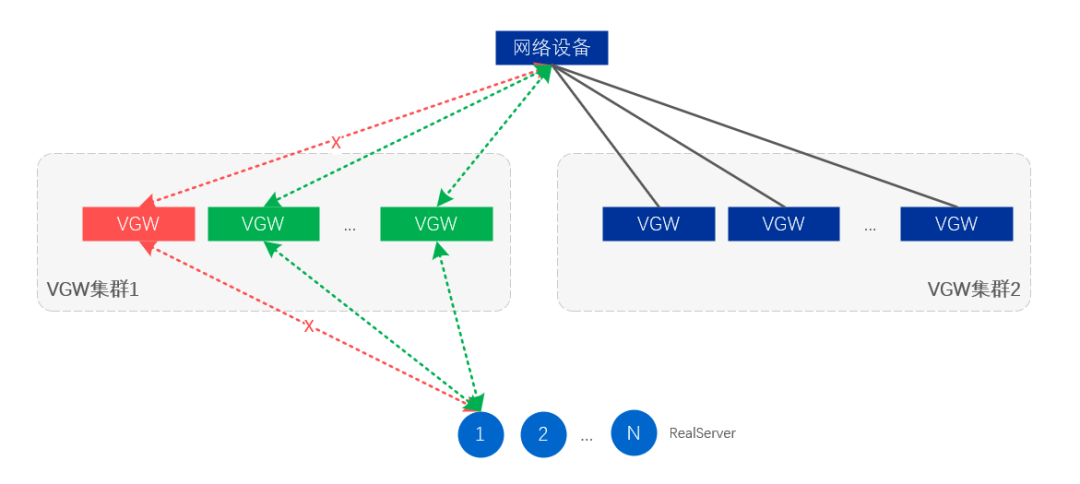
圖12、伺服器、鏈路級別故障隔離

圖13、叢集級別的故障隔離
4.6 如何提高VGW效能
隨著業務量級越來越大,VGW單機要接收近百萬的QPS請求,同時要達到500W/s以上的包處理能力。顯然一般伺服器根本無法達到這麼大量的請求和包處理速度,主要原因在於Linux的網路處理機制。網路封包都必須經過Linux核心,網路卡收到封包後都要傳送中斷給CPU,由CPU在核心處理,然後再拷貝一份副本給應用程式。傳送資料也要經過核心進行處理一遍。頻繁的中斷、使用者空間和核心空間之間不斷的拷貝資料,導致CPU時長嚴重被消耗在了網路資料處理上,包速率越大,效能越差。當然還有其他諸如Cache Miss,跨CPU的資料拷貝消耗等等問題。
這裡會很容易想到,能不能把上面CPU乾的這些髒活累活扔網路卡去幹了,CPU就純粹處理業務資料就行。目前很多方案就是根據這個想法來的,硬體方案有智慧網路卡,純軟體方案當前用的較多的是DPDK(Intel Data Plane Development Kit)。顯然智慧網路卡的成本會偏高,而且還在發展階段,應用有一定成本。而DPDK純軟體來說在成本和可控方面要好得多,我們選擇了DPDK作為底層的包轉發元件(實際上是基於愛奇藝開源的DPVS的二次開發)。
DPDK主要是攔截了核心的包處理流程,將使用者封包直接上送至應用程式中,而不是由核心進行處理。同時擯棄了依靠網路卡中斷的方式處理資料的行為,轉而採用輪詢的方式從網路卡中讀取資料,從達到降低CPU中斷的目的。當然還利用了CPU親和性,使用固定的CPU處理網路卡資料,減少程序的切換消耗。另外還有很多關於Cache、記憶體等方面的優化技術。總體上能夠將伺服器網路卡包處理速度達到千萬PPS,極大提升網路卡的包處理能力,進而能提升伺服器的CPS(每秒新建連線數目)。當前我們在100G網路卡下,能夠達到 100w+的CPS和1200w+PPS的業務處理量(有限條件下的測試結果,非理論值)。
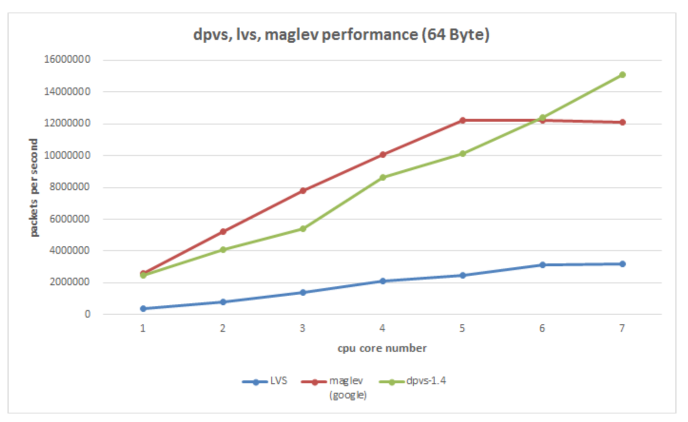
圖14、VGW使用的底層工具DPVS(DPDK+LVS)對比幾種現有的負載均衡方案效能
五、總結
通過上述講解,我們逐步從一個業務可靠性的需求推演出一套可行的負載均衡方案,同時結合vivo的實際需求,落地了我們的VGW負載均衡接入平臺。當然,當前的負載均衡方案都是大量取捨後的結果,不可能做到完美。同時我們未來還面臨著新的業務協定支援的問題,以及資料中心去中心化的業務模型對負載均衡的集中式控制之間衝突的問題。但技術一直在進步,但總會找到合適的方案的!