如何用Python對股票資料進行LSTM神經網路和XGboost機器學習預測分析(附原始碼和詳細步驟),學會的小夥伴們說不定就成為炒股專家一夜暴富了
前言
最近調研了一下我做的專案受歡迎程度,巨量資料分析方向竟然排第一,尤其是這兩年受疫情影響,大家都非常擔心自家公司裁員或倒閉,都想著有沒有其他副業搞搞或者炒炒股、投資點理財產品,未雨綢繆,所以不少小夥伴要求我這邊分享下關於股票預測分析的技巧。
基於股票資料是一個和時間序列相關的巨量資料,所以我打算給大家分享時下最受歡迎的時序模型:LSTM、XGBoost兩大經典模型。
@
一、模型簡介
1.1 LSTM神經網路模型
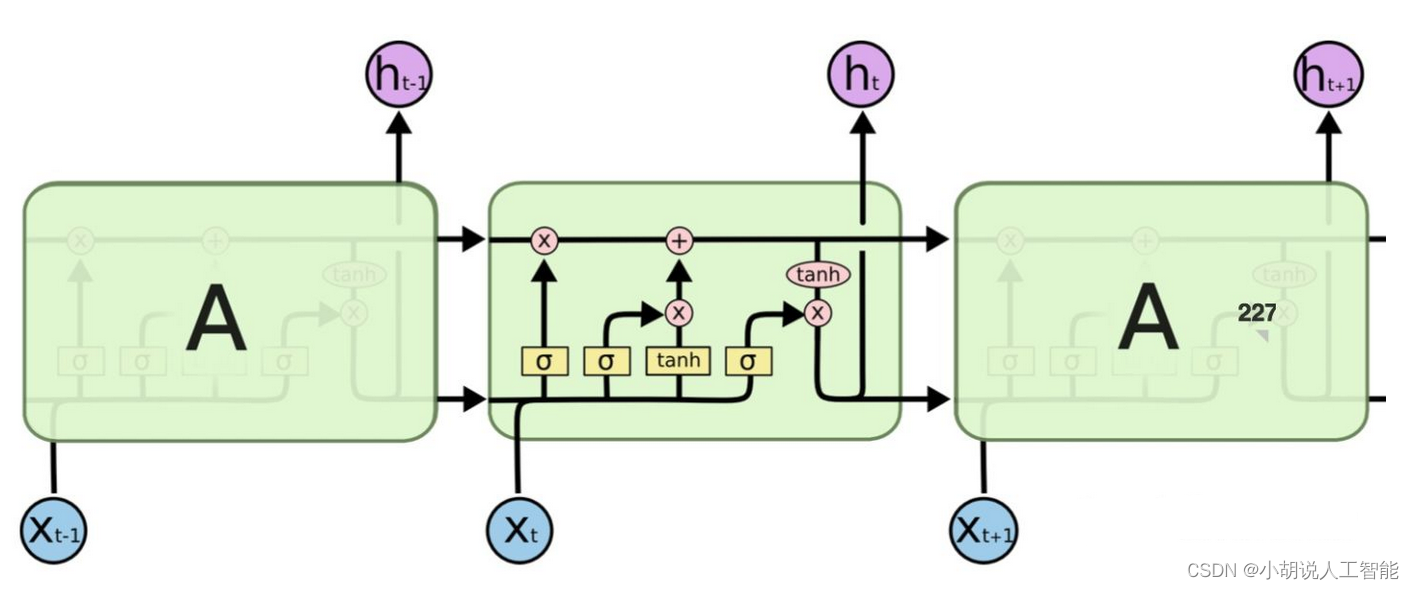
根據百度百科定義:長短期記憶網路(LSTM,Long Short-Term Memory)是一種時間迴圈神經網路,是為了解決一般的RNN(迴圈神經網路)存在的長期依賴問題而專門設計出來的,所有的RNN都具有一種重複神經網路模組的鏈式形式。在標準RNN中,這個重複的結構模組只有一個非常簡單的結構,例如一個tanh層。
LSTM 能夠進行一次多步預測,對於時間序列預測有一定的參考價值。LSTM的難點在於設定不方便。
1.2 XGBoost機器學習模型
XGBoost全稱是eXtreme Gradient Boosting,根據百度百科定義:XGBoost是一個優化的分散式梯度增強庫,旨在實現高效,靈活和便攜。它在 Gradient Boosting 框架下實現機器學習演演算法。XGBoost提供並行樹提升(也稱為GBDT,GBM),可以快速準確地解決許多資料科學問題。相同的程式碼在主要的分散式環境(Hadoop,SGE,MPI)上執行,並且可以解決數十億個範例之外的問題。
可能大家光看定義,不能太理解XGBoost的牛逼之處,瞭解過Kaggle競賽的小夥伴應該知道,由於XGBoost 庫專注於計算速度和模型效能,因此幾乎沒有多餘的裝飾,演演算法的實現也旨在提高計算時間和記憶體資源的效率,所以它目前已經在 Kaggle 競賽資料科學平臺上成為競賽獲勝者的首選演演算法。
例如,有一個不完整的一、二、三等獎獲獎名單,標題為: XGBoost: Machine Learning Challenge Winning Solutions。
為了使這一點更加具體,以下是 Kaggle 競賽獲勝者的一些有見地的引述:
作為越來越多的 Kaggle 比賽的獲勝者,XGBoost 再次向我們展示了它是一種出色的全能演演算法。
——拿督優勝者訪談:第一名,瘋狂教授
如有疑問,請使用 xgboost。
— Avito 優勝者訪談:第一名,Owen Zhang
我喜歡錶現良好的單個模型,我最好的單個模型是 XGBoost,它可以單獨獲得第 10 名。
—卡特彼勒獲獎者訪談:第一名
我只用過 XGBoost。
— Liberty Mutual Property Inspection,優勝者訪談:第一名,王清臣
我使用的唯一監督學習方法是梯度提升,在優秀的 xgboost 中實現。
— Recruit Coupon Purchase 優勝者訪談:第二名,Halla Yang
同時XGBoost 是免費的開源軟體,可在 Apache-2 許可下使用,尤其是支援多種介面,如命令列介面 (CLI)、C++(編寫庫的語言)、Python 介面以及 scikit-learn 中的模型、R 介面以及 caret 包中的模型、Julia、Java 和 JVM 語言(如 Scala)和平臺(如 Hadoop)。所以它應用得也越來越廣泛,它也是我學習監督機器學習的最重要演演算法。
關於它的原理實現,我這就不詳細介紹了,這篇主要是講其應用,感興趣的小夥伴們可以自己搜尋學習下,當然你也可以登入它的github地址來詳細學習。

二、專案詳細介紹
任何一個巨量資料分析專案,我覺得都應該先了解清楚專案目的,在做分析,所以我們先來簡單明確下本次專案的主要目的:
專案目的
本次專案是使用LSTM神經網路模型、XGBoost模型,來對股票資料中的某個關鍵價格,進行預測分析。資料來源,搜狐財經中的某個可轉債Zclose相關資料。
下面我就按照巨量資料分析的一般步驟給大家演示下具體專案實現過程,該分析步驟基本適用於大部分資料分析流程,覺得有用的小夥伴們可以收藏關注哈。
2.1 匯入資料
主要使用Pandas庫進行資料匯入
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
all_data_set_path = r'csv_export\csv_data_1m_begin_40d_博22轉債_SHSE.113650_SHSE.603916.csv'
all_data_set = pd.read_csv(all_data_set_path)
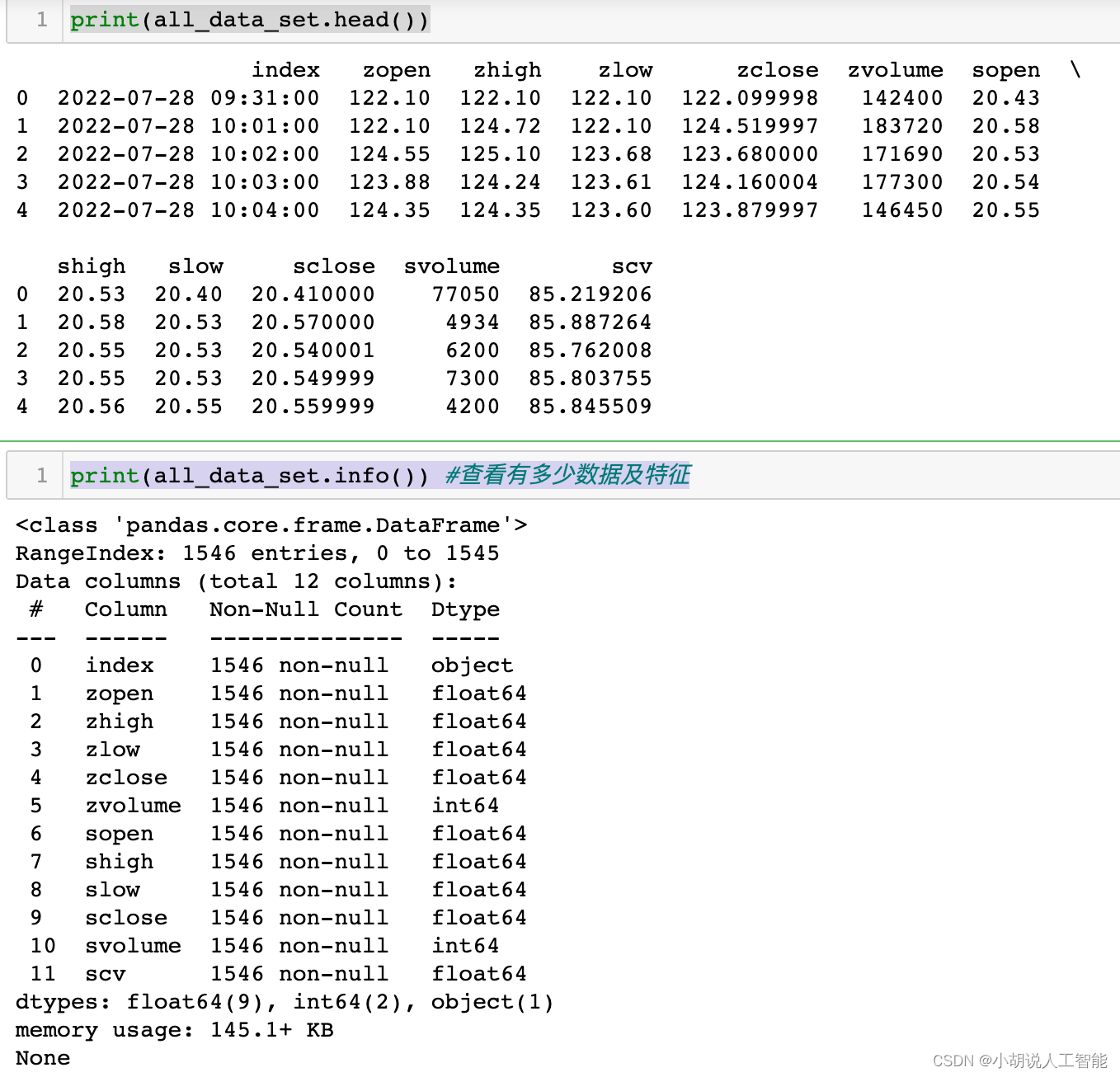
print(all_data_set.head())
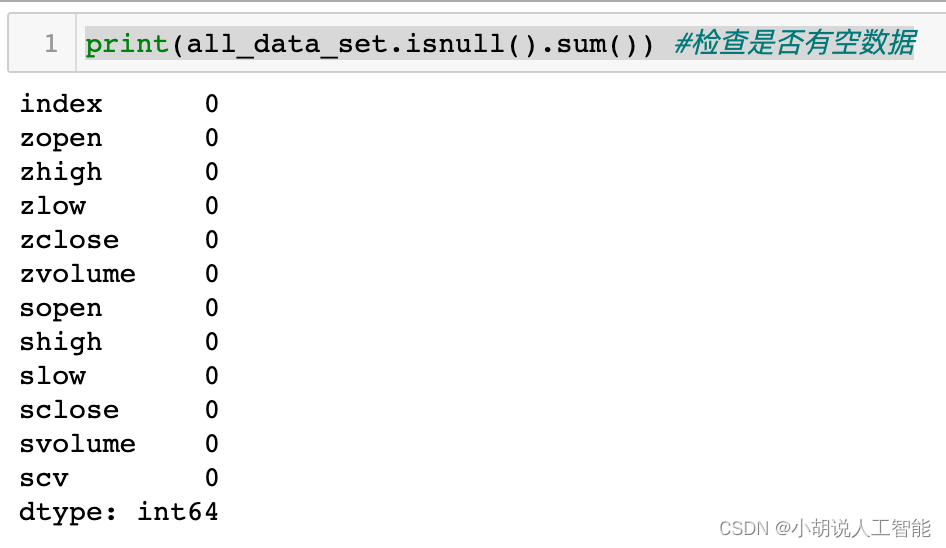
print(all_data_set.info()) #檢視有多少資料及特徵
print(all_data_set.isnull().sum()) #檢查是否有空資料
2.2 研究資料
主要使用matplotlib庫對資料進行初步特徵研究分析
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
# 特徵熱力圖 相關性分析
list_columns = all_data_set.columns
plt.figure(figsize=(15,10))
sns.heatmap(all_data_set[list_columns].corr(), annot=True, fmt=".2f")
plt.show()
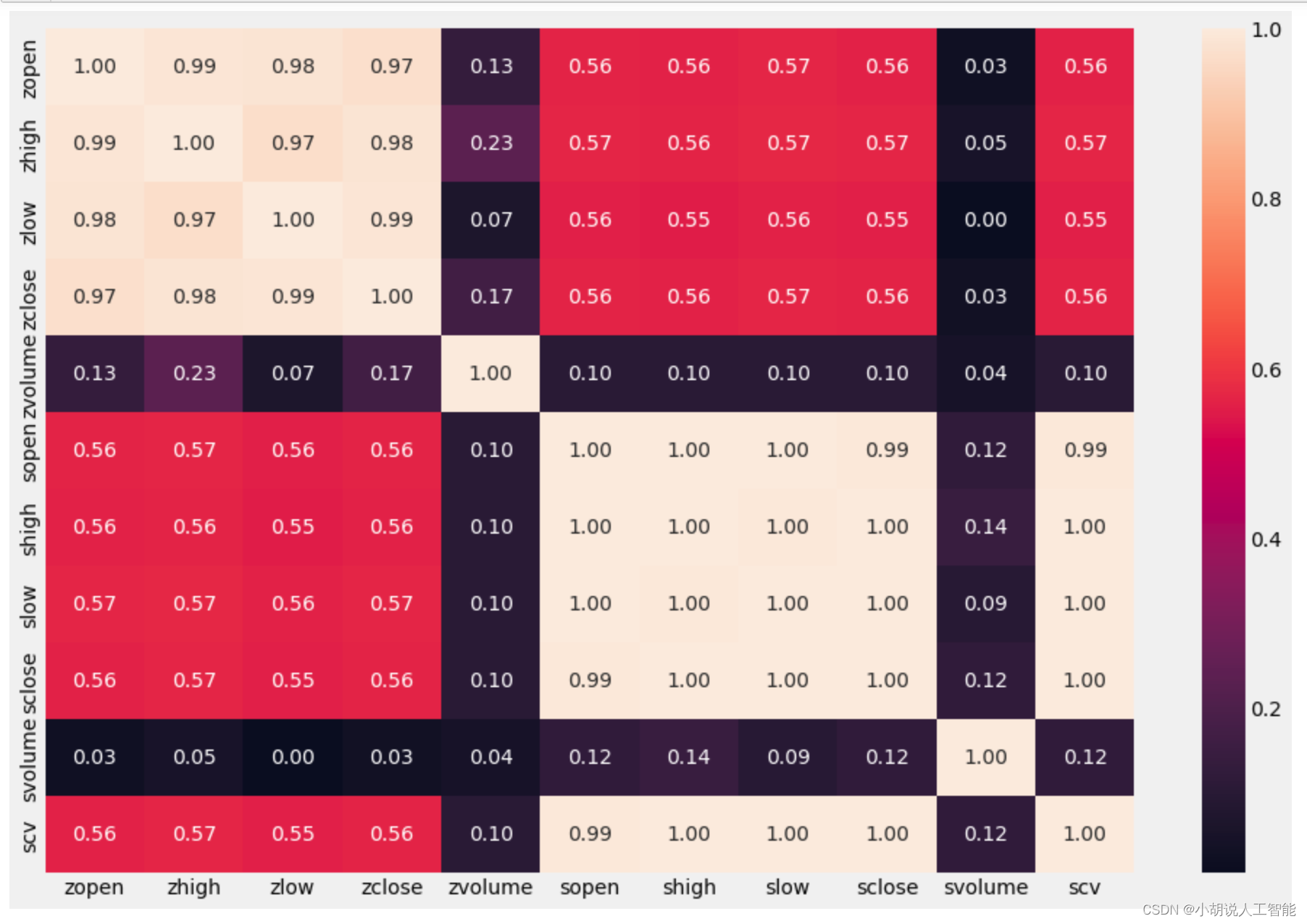 從熱力圖可以大概看出,與zclose相關性比較高的幾個特徵,接下來就是對特徵重要性進行排序,選擇出相關性較高的特徵。可以看出zlow、zhigh、zopen與zclose特徵的相關性最高,都達到了98%左右,所以我們可以優先選取這3個特徵,進行分析。
從熱力圖可以大概看出,與zclose相關性比較高的幾個特徵,接下來就是對特徵重要性進行排序,選擇出相關性較高的特徵。可以看出zlow、zhigh、zopen與zclose特徵的相關性最高,都達到了98%左右,所以我們可以優先選取這3個特徵,進行分析。
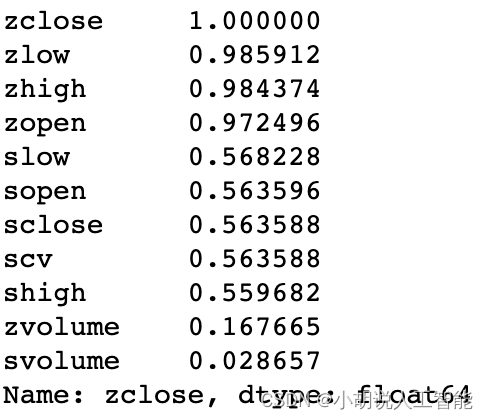
# 對特徵重要性進行排序
corr_1 = all_data_set.corr()
corr_1["zclose"].sort_values(ascending=False)
2.3 資料預處理
資料預處理是整個資料分析過程中最重要的一個步驟,都說"資料和特徵決定了機器學習的上限,而模型和演演算法只是逼近這個上限而已"。如果資料和關鍵特徵處理的好,使用不同的模型和演演算法,都可以取得比較好的效果。
而且資料預處理往往要佔整個資料分析的大部分時間,有些甚至佔到80%-90%的時間。所以想深入學習巨量資料分析的小夥伴們,要熟練掌握各種資料預處理的方法哈,比如常用的空值、缺失值、異常值處理、資料不平衡處理、特徵組合等等。
由於未來股票受近期股票價格波動的影響較大,所以為了能充分利用近期的股票資料,博主編寫了一個預處理常式,組合歷史前幾次的資料生成更多的特徵來進行預測。這也是時序特徵資料的常用方法,大概可以理解為滑動視窗取值吧,具體如下:
len_ = len(['zopen','zhigh','zlow','zclose'])*3
col_numbers_drop = []
for i in range(3):
col_numbers_drop.append(len_+i)
print(col_numbers_drop)
# 依據特徵重要性,選擇zlow zhigh zopen來進行預測zclose
# 資料選擇t-n, ...., t-2 t-1 與 t 來預測未來 t+1
# 轉換原始資料為新的特徵列來進行預測,time_window可以用來偵錯用前幾次的資料來預測
def series_to_supervised(data,time_window=3):
data_columns = ['zopen','zhigh','zlow','zclose']
data = data[data_columns] # Note this is important to the important feature choice
cols, names = list(), list()
for i in range(time_window, -1, -1):
# get the data
cols.append(data.shift(i)) #資料偏移量
# get the column name
if ((i-1)<=0):
suffix = '(t+%d)'%abs(i-1)
else:
suffix = '(t-%d)'%(i-1)
names += [(colname + suffix) for colname in data_columns]
# concat the cols into one dataframe
agg = pd.concat(cols,axis=1)
agg.columns = names
agg.index = data.index.copy()
# remove the nan value which is caused by pandas.shift
agg = agg.dropna(inplace=False)
# remove unused col (only keep the "close" fied for the t+1 period)
# Note col "close" place in the columns
len_ = len(data_columns)*time_window
col_numbers_drop = []
for i in range(len(data_columns)-1):
col_numbers_drop.append(len_+i)
agg.drop(agg.columns[col_numbers_drop],axis=1,inplace = True)
return agg
all_data_set2 = all_data_set.copy()
all_data_set2["index"] = pd.to_datetime(all_data_set2["index"]) # 日期object: to datetime
all_data_set2.set_index("index", inplace=True, drop=True) # 把index設為索引
all_data_set2 = all_data_set2[116:] # 這裡把7月28日的資料全部刪掉了,主要是資料缺失較多
data_set_process = series_to_supervised(all_data_set2,10) #取近10分鐘的資料
print(data_set_process.columns.values)
print(data_set_process.info())
到此,我們資料集就生成了,接下來就可以搭建模型,訓練模型和預測資料了。
2.4 搭建模型
2.4.1 LSTM神經網路模型
我們可以直接使用Tensorflow 和 Keras中封裝好的LSTM模型來進行模型搭建,這裡要告訴大家的是,之所以很多小夥伴都用python來做資料分析,是因為很多開發者已經用python搭建了各種各樣的wheel/package方便大家直接使用。
所以我們就可以直接站在巨人的肩膀上,快速搭建我們需要的各種模型,同時也可以自己對模型進行調參,獲取最優引數組合,從而生成一個高精度的資料模型。
這裡要注意:LSTM要求資料格式為numpy格式的陣列,所以要將pandas的Dataframe資料轉換一下,同時LSTM模型對於不同資料範圍的特徵較為敏感,一般都要進行相同的範圍內資料縮放避免預測錯誤,所以使用了MinMaxScaler進行縮放資料。(也可以使用StandardScaler)。後面資料預測後,再進行資料逆縮放就可以獲得最後結果了。
具體模型搭建如下:
# 注意這裡要安裝Tensorflow 和 Keras才能使用
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(data_set_process)
# split the train and test data
train_size = int(len(data_set_process) * 0.8)
test_size = len(data_set_process) - train_size
train_LSTM, test_LSTM = scaled_data[0:train_size, :], scaled_data[train_size:len(data_set_process), :]
train_LSTM_X, train_LSTM_Y = train_LSTM[:, :(len(data_set_process.columns) - 1)], train_LSTM[:,
(len(data_set_process.columns) - 1)]
test_LSTM_X, test_LSTM_Y = test_LSTM[:, :(len(data_set_process.columns) - 1)], test_LSTM[:,
(len(data_set_process.columns) - 1)]
# reshape input to be [samples, time steps, features]
train_LSTM_X2 = np.reshape(train_LSTM_X, (train_LSTM_X.shape[0], 1, train_LSTM_X.shape[1]))
test_LSTM_X2 = np.reshape(test_LSTM_X, (test_LSTM_X.shape[0], 1, test_LSTM_X.shape[1]))
print(train_LSTM_X.shape, train_LSTM_Y.shape, test_LSTM_X.shape, test_LSTM_Y.shape)
print(train_LSTM_X2.shape, test_LSTM_X2.shape)
# creat and fit the LSTM network
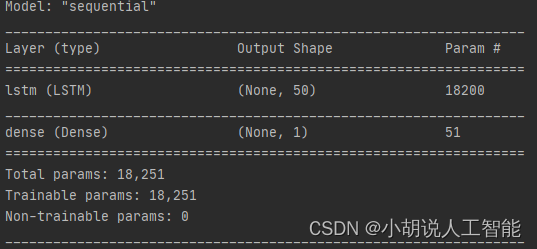
model = Sequential()
model.add(LSTM(50, input_shape=(train_LSTM_X2.shape[1], train_LSTM_X2.shape[2])))
# model.add(LSTM(50))
model.add(Dense(1))
model.compile(loss="mae", optimizer="Adam")
print(model.summary()) #這裡是列印模型基本資訊
print("start to fit the model")
history = model.fit(train_LSTM_X2, train_LSTM_Y, epochs=50, batch_size=50, validation_data=(test_LSTM_X2, test_LSTM_Y),
verbose=2, shuffle=False)
plt.plot(history.history['loss'], label='train') #視覺化模型訓練的損失函數
plt.plot(history.history['val_loss'], label='test')
plt.legend()
plt.show()
model.save('LSTM_model.h5') # 這裡儲存模型,以便以後可以不用再訓練,直接使用
# model的使用
# from tensorflow.keras.models import load_model
# del model # 刪除已存在的model
# model = load_model('LSTM_model.h5')
# make prediction
yPredict = model.predict(test_LSTM_X2) #進行模型預測,注意這裡要進行資料逆縮放,獲取最後結果,同時注意逆縮放資料時必須與scaler的資料維度保持一致
print(yPredict.shape)
testPredict = scaler.inverse_transform(np.concatenate((test_LSTM_X, yPredict), axis=1))[:, -1:]

2.4.2 XGBoost模型搭建
XGBoost的模型可以說是非常成熟了,我們可以直接安裝xgboost庫來搭建模型,博主選了一組初始引數進行模型訓練,小夥伴們也可以使用網格搜尋GridSearchCV()或者隨機搜尋RandomizedSearchCV()來進行引數調優操作,具體如下:
import xgboost as xgb
from xgboost import plot_importance, plot_tree
train_size = int(len(data_set_process)*0.8)
test_size = len(data_set_process) - train_size
train_XGB, test_XGB = scaled_data[0:train_size,:],scaled_data[train_size:len(data_set_process),:]
train_XGB_X, train_XGB_Y = train_XGB[:,:(len(data_set_process.columns)-1)],train_XGB[:,(len(data_set_process.columns)-1)]
test_XGB_X, test_XGB_Y = test_XGB[:,:(len(data_set_process.columns)-1)],test_XGB[:,(len(data_set_process.columns)-1)]
# 演演算法引數
params = {
'booster':'gbtree',
'objective':'binary:logistic', # 此處為迴歸預測,這裡如果改成multi:softmax 則可以進行多分類
'gamma':0.1,
'max_depth':5,
'lambda':3,
'subsample':0.7,
'colsample_bytree':0.7,
'min_child_weight':3,
'slient':1,
'eta':0.1,
'seed':1000,
'nthread':4,
}
#生成資料集格式
xgb_train = xgb.DMatrix(train_XGB_X,label = train_XGB_Y)
xgb_test = xgb.DMatrix(test_XGB_X,label = test_XGB_Y)
num_rounds = 300
watchlist = [(xgb_test,'eval'),(xgb_train,'train')]
#xgboost模型訓練
model_xgb = xgb.train(params,xgb_train,num_rounds,watchlist)
#對測試集進行預測
y_pred_xgb = model_xgb.predict(xgb_test)
2.5 資料視覺化及評估
資料視覺化就相對簡單了,類似於我們用excel來生成各種圖表,直觀地來看資料分佈情況。
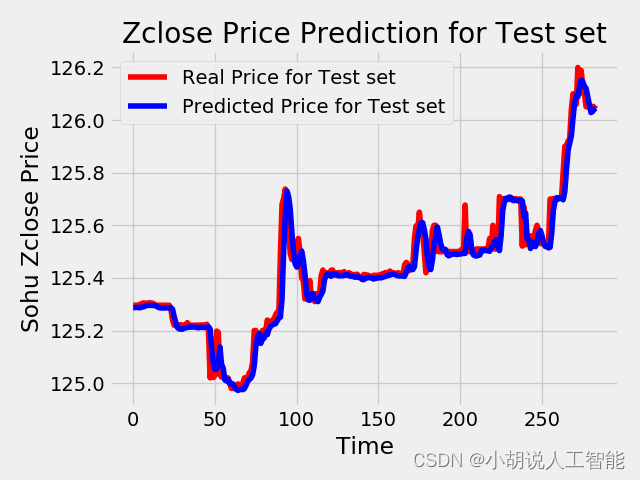
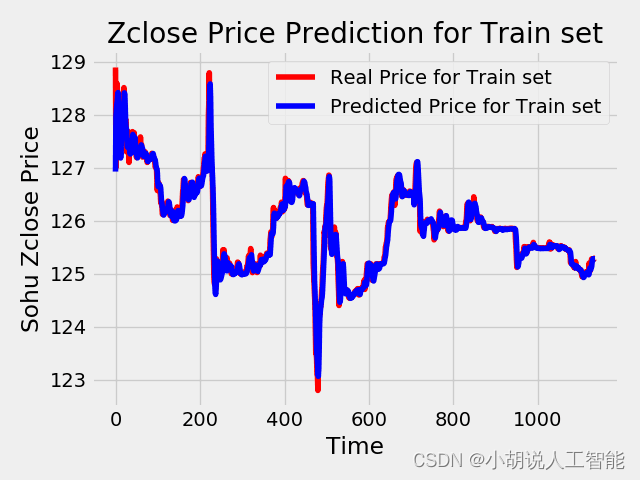
除了對資料直觀展示外,我們也常使用MAPE、MAE、RMSE、R2對資料預測結果準確性進行評估,這裡我就簡單使用了MAPE(平均絕對誤差率)給大家演示,其中LSTM模型下的測試集、訓練集的MAPE都在0.07%之內,也就是說準確率在99.9%以上,可以說效果很好了。XGBoost模型的測試集MAPE在1.2%之內,也就是說準確率在98.8%左右,也可以說效果不錯。
具體LSTM模型結果視覺化及評估如下:
# make prediction
yPredict = model.predict(test_LSTM_X2)
print(yPredict.shape)
testPredict = scaler.inverse_transform(np.concatenate((test_LSTM_X, yPredict), axis=1))[:, -1:]
test_LSTM_Y2 = scaler.inverse_transform(np.concatenate((test_LSTM_X, test_LSTM_Y.reshape(len(test_LSTM_Y),1)), axis=1))[:, -1:]
print(testPredict.shape)
# print(testPredict)
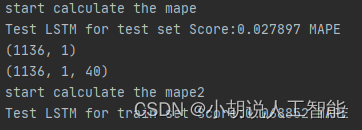
print("start calculate the mape")
mape = np.mean(np.abs(test_LSTM_Y2.flatten()-testPredict.flatten())/test_LSTM_Y2.flatten())*100 # 這裡計算測試集預測結果與真實結果的誤差率
print('Test LSTM for test set Score:%.6f MAPE' %(mape)) #0.027897%的誤差
yPredict_train = model.predict(train_LSTM_X2)
print(yPredict_train.shape)
print(train_LSTM_X2.shape)
trainPredict = scaler.inverse_transform(np.concatenate((train_LSTM_X, yPredict_train), axis=1))[:, -1:]
train_LSTM_Y2 = scaler.inverse_transform(np.concatenate((train_LSTM_X, train_LSTM_Y.reshape(len(train_LSTM_Y),1)), axis=1))[:, -1:]
print("start calculate the mape2")
mape2 = np.mean(np.abs(train_LSTM_Y2.flatten()-trainPredict.flatten())/train_LSTM_Y2.flatten())*100 # 這裡計算訓練集預測結果與真實結果的誤差率
print('Test LSTM for train set Score:%.6f MAPE' %(mape2)) #0.068852%的誤差
plt.plot(train_LSTM_Y2, color = 'red', label = 'Real Price for Train set')
plt.plot(trainPredict, color = 'blue', label = 'Predicted Price for Train set')
plt.title('Zclose Price Prediction for Train set')
plt.xlabel('Time')
plt.ylabel('Sohu Zclose Price')
plt.legend()
plt.show()
plt.plot(test_LSTM_Y2, color = 'red', label = 'Real Price for Test set')
plt.plot(testPredict, color = 'blue', label = 'Predicted Price for Test set')
plt.title('Zclose Price Prediction for Test set')
plt.xlabel('Time')
plt.ylabel('Sohu Zclose Price')
plt.legend()
plt.show()
具體XGBoost模型結果視覺化及評估如下:
plt.plot(test_XGB_Y, color = 'red', label = 'Real Price for Test set')
plt.plot(y_pred_xgb, color = 'blue', label = 'Predicted Price for Test set')
plt.title('Zclose Price Prediction for Test set')
plt.xlabel('Time')
plt.ylabel('Sohu Zclose Price')
plt.legend()
plt.show()
mape_xgb = np.mean(np.abs(y_pred_xgb-test_XGB_Y)/test_XGB_Y)*100
print('XGBoost平均誤差率為:{}%'.format(mape_xgb)) #平均誤差率為1.1974%
程式碼
所有資料集、程式碼都已經上傳到我的github,歡迎大家前往fork、下載。
建議
博主有位朋友在大的金融公司專門做量化投資的,他嘗試過加入各種相關因子、特徵,使用不同的模型,調參來獲取最高的準確度,但由於股票、債券、基金這些金融產品都受各種政治、經濟、社會等綜合因素的影響,經常會有突發情況導致預測出現較大波動。最後他發現,最好的方法是在每天晚上利用當天的資料重新來訓練下,往往能獲取到最好的模型。
所以說想嘗試往量化投資、機器學習巨量資料分析這塊發展的話,一定要根據實際情況,不斷地根據最新的資料,去實時更新自己的模型,才能獲取到最好的效果。當然也奉勸大家常年不變的真理:金融有風險,投資需謹慎。
如果大家想繼續瞭解人工智慧相關學習路線和知識體系,歡迎大家翻閱我的另外一篇部落格《重磅 | 完備的人工智慧AI 學習——基礎知識學習路線,所有資料免關注免套路直接網路硬碟下載》
這篇部落格參考了Github知名開源平臺,AI技術平臺以及相關領域專家:Datawhale,ApacheCN,AI有道和黃海廣博士等約有近100G相關資料,希望能幫助到所有小夥伴們。