【深入淺出 Yarn 架構與實現】5-2 Yarn 三種排程器
本篇文章將深入介紹 Yarn 三種排程器。Yarn 本身作為資源管理和排程服務,其中的資源排程模組更是重中之重。下面將介紹 Yarn 中實現的排程器功能,以及內部執行邏輯。
一、簡介
Yarn 最主要的功能就是資源管理與分配。本篇文章將對資源分配中最核心的元件排程器(Scheduler)進行介紹。
排程器最理想的目標是有資源請求時,立即滿足。然而由於物理資源是有限的,就會存在資源如何分配的問題。針對不同資源需求量、不同優先順序、不同資源型別等,很難找到一個完美的策略可以解決所有的應用場景。因此,Yarn提供了多種排程器和可設定的策略供我們選擇。
Yarn 資源排程器均實現 ResourceScheduler 介面,是一個插拔式元件,使用者可以通過設定引數來使用不同的排程器,也可以自己按照介面規範編寫新的資源排程器。在 Yarn 中預設實現了三種調速器:FIFO Scheduler 、Capacity Scheduler、Fair Scheduler。
官方對三種排程器的介紹圖。看個大概意思就行,隨著排程器的不斷更新迭代,這個圖不再符合當下的情況。

二、FIFO
最簡單的一個策略,僅做測試用。
用一個佇列來儲存提交等待的任務,先提交的任務就先分資源,有剩餘的資源就給後續排隊等待的任務,沒有資源了後續任務就等著之前的任務釋放資源。
優點:
簡單,開箱即用,不需要額外的設定。早些版本的 Yarn 用 FIFO 作為預設排程策略,後續改為 CapacityScheduler 作為預設排程策略。
缺點:
除了簡單外都是缺點,無法設定你各種想要的排程策略(限制資源量、限制使用者、資源搶奪等)。
三、CapacityScheduler
一)CS 簡介
Capacity Scheduler(後以 CS 簡寫代替)以佇列為單位劃分資源。會給每個佇列設定最小保證資源和最大可用資源。最小設定資源保證佇列一定能拿到這麼多資源,有空閒可共用給其他佇列使用;最大可用資源限制佇列最多能使用的資源,防止過度消耗。
佇列內部可以再巢狀,形成層級結構。佇列內資源預設採用 FIFO 的方式分配。如下圖所示。
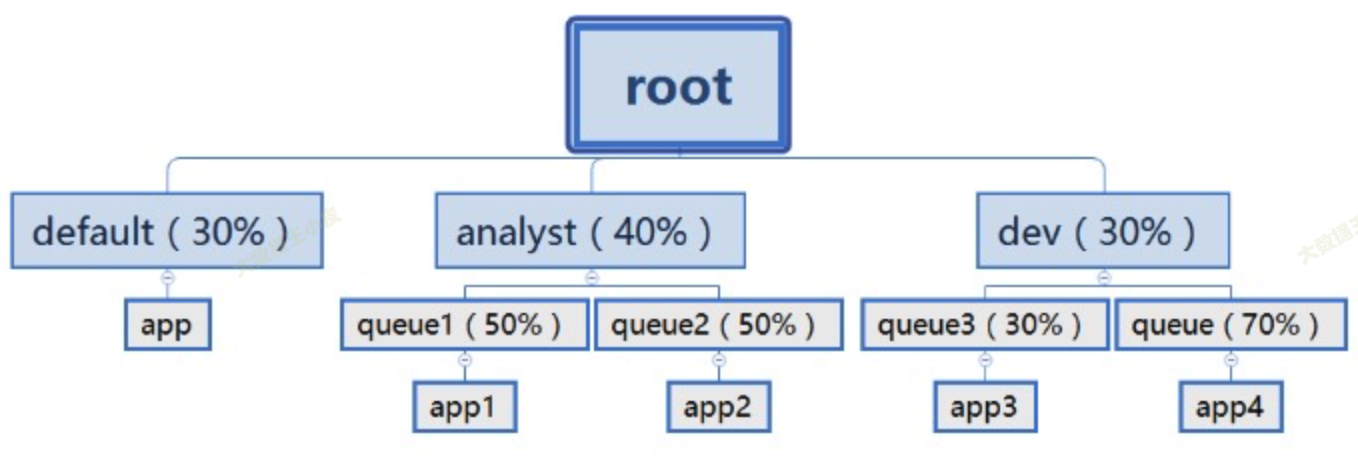
優點:
- 佇列最低資源保障,防止小應用餓死;
- 空閒容量共用,當佇列設定資源有空閒時可共用給其他佇列使用
缺點:
- 佇列設定繁瑣,父佇列、子佇列都要單獨設定優先順序、最大資源、最小資源、使用者最大資源、使用者最小資源、使用者許可權設定等等。工程中會寫個程式,自動生成該設定;
二)CS 特徵
- 分層佇列 (Hierarchical Queues):支援佇列分層結構,子佇列可分配父佇列可用資源。
- 容量保證 (Capacity Guarantees):每個佇列都會設定最小容量保證,當叢集資源緊張時,會保證每個佇列至少能分到的資源。
- 彈性 (Elasticity):當佇列設定資源有空閒時,可以分配給其他有資源需求的佇列。當再次需要這些資源時可以搶奪回這些資源。
- 安全性 (Security):每個佇列都有嚴格的 ACL,用於控制哪些使用者可以向哪些佇列提交應用程式。
- 多租戶 (Multi-tenancy):提供全面的限制以防止單個應用程式、使用者和佇列從整體上獨佔佇列或叢集的資源。
- 優先順序排程 (Priority Scheduling):此功能允許以不同的優先順序提交和排程應用程式。同時佇列間也支援優先順序設定(2.9.0 後支援)。
- 絕對資源設定 (Absolute Resource Configuration):管理員可以為佇列指定絕對資源,而不是提供基於百分比的值(3.1.0 後支援)。
- 資源池設定:可將 NodeManager 分割到不同的資源池中,資源池中設定佇列,進行資源隔離。同時資源池有共用和獨立兩種模式。在共用情況下,多餘的資源會共用給 default 資源池。
三)CS 設定
假設佇列層級如下:
root
├── prod
└── dev
├── eng
└── science
可以通過設定 capacity-scheduler.xml 來實現:
<configuration>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>prod,dev</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.queues</name>
<value>eng,science</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.prod.capacity</name>
<value>40</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.capacity</name>
<value>60</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.eng.capacity</name>
<value>50</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.science.capacity</name>
<value>50</value>
</property>
</configuration>
除了容量設定外,還可以設定單個使用者或者程式能夠使用的最大資源數,同時可以執行幾個應用,許可權ACL控制等,不是本篇重點,不再展開。可參考:cloudera - Capacity Scheduler、Hadoop doc - Capacity Scheduler、Hadoop: Capacity Scheduler yarn容量排程設定。
四)CS 實現
這裡僅關注 CS 資源分配的過程。
CS 分配的是各 NM 節點上的空閒資源,NM 資源彙報請到之前的文章《4-3 RM 管理 NodeManager》中瞭解。
1、資源請求描述
AM 通過心跳彙報資源請求,包含的資訊如下。
message ResourceRequestProto {
optional PriorityProto priority = 1; // 優先順序
optional string resource_name = 2; // 期望資源所在節點或機架
optional ResourceProto capability = 3; // 資源量
optional int32 num_containers = 4; // Container 數目
optional bool relax_locality = 5 [default = true]; // 是否鬆弛本地性
optional string node_label_expression = 6; // 所在資源池
}
2、資源更新入口
NM 傳送心跳給 RM 後,RM 會傳送 NODE_UPDATE 事件,這個事件會由 CapacityScheduler 進行處理。
case NODE_UPDATE:
{
NodeUpdateSchedulerEvent nodeUpdatedEvent = (NodeUpdateSchedulerEvent)event;
RMNode node = nodeUpdatedEvent.getRMNode();
setLastNodeUpdateTime(Time.now());
nodeUpdate(node);
if (!scheduleAsynchronously) {
// 重點
allocateContainersToNode(getNode(node.getNodeID()));
}
}
重點在 allocateContainersToNode(),內部邏輯如下:
- 從根佇列往下找,找到 most 'under-served' 佇列(即 已分配資源/設定資源 最小的);
- 先滿足已經預留資源(RESERVED)的容器
- 再處理未預留的資源請求,如果資源不夠,則進行 RESERVE,等待下次分配
這裡有個預留的概念(之後會有文章專門介紹 reserve 機制):
- RESERVED 是為了防止容器餓死;
- 傳統排程:比如一堆 1G 和 2G 的容器請求,當前叢集全被 1G 的佔滿了,當一個 1G 的容器完成後,下一個還是會排程 1G,因為 2G 資源不夠;
- RESERVED 就是為了防止這種情況發生,所以先把這個資源預留出來,誰也別用,等下次有資源了再補上,直到滿足這個容器資源請求。
四、FairScheduler
一、Fair 簡介
同 Capacity Seheduler 類似,Fair Scheduler 也是一個多使用者排程器,它同樣新增了多層級別的資源限制條件以更好地讓多使用者共用一個 Hadoop 叢集,比如佇列資源限制、使用者應用程式數目限制等。
在 Fair 排程器中,我們不需要預先佔用一定的系統資源,Fair 排程器會為所有執行的 job 動態的調整系統資源。如下圖所示,當第一個大 job 提交時,只有這一個 job 在執行,此時它獲得了所有叢集資源;當第二個小任務提交後,Fair 排程器會分配一半資源給這個小任務,讓這兩個任務公平的共用叢集資源。
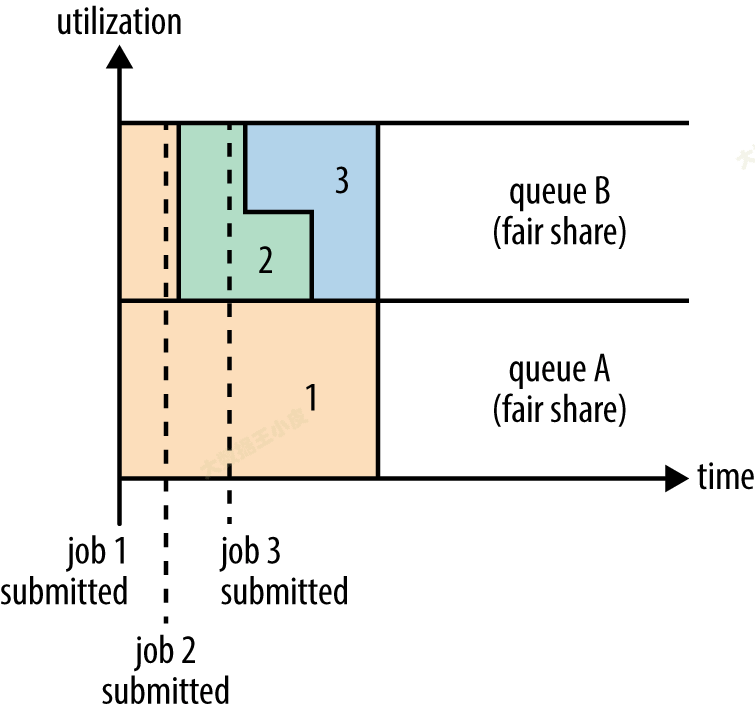
Fair 排程器的設計目標是為所有的應用分配公平的資源(對公平的定義可以通過引數來設定)。
優點:
- 分配給每個應用程式的資源取決於其優先順序;
- 它可以限制特定池或佇列中的並行執行任務。
二)Fair 特徵
- 公平排程器,就是能夠共用整個叢集的資源
- 不用預先佔用資源,每一個作業都是共用的
- 每當提交一個作業的時候,就會佔用整個資源。如果再提交一個作業,那麼第一個作業就會分給第二個作業一部分資源,第一個作業也就釋放一部分資源。再提交其他的作業時,也同理。也就是說每一個作業進來,都有機會獲取資源。
- 權重屬性,並把這個屬性作為公平排程的依據。如把兩個佇列權重設為 2 和 3,當排程器分配叢集 40:60 資源給兩個佇列時便視作公平。
- 每個佇列內部仍可以有不同的排程策略。佇列的預設排程策略可以通過頂級元素
進行設定,如果沒有設定,預設採用公平排程。
三)Fair 設定
在 FairScheduler 中是通過在 fair-scheduler.xml 中設定佇列權重,來實現「公平」的。
計算時是看(當前佇列權重 / 總權重)得到當前佇列能分得資源的百分比。
更詳細引數設定,可參考:Yarn 排程器Scheduler詳解
<queue name="first">
<minResources>512mb, 4vcores</minResources>
<maxResources>30720nb, 30vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>2.0</weight>
</queue>
<queue name="second">
<minResources>512mb, 4vcores</minResources>
<maxResources>30720nb, 30vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>1.0</weight>
</queue>
五、Fair Scheduler與Capacity Scheduler區別
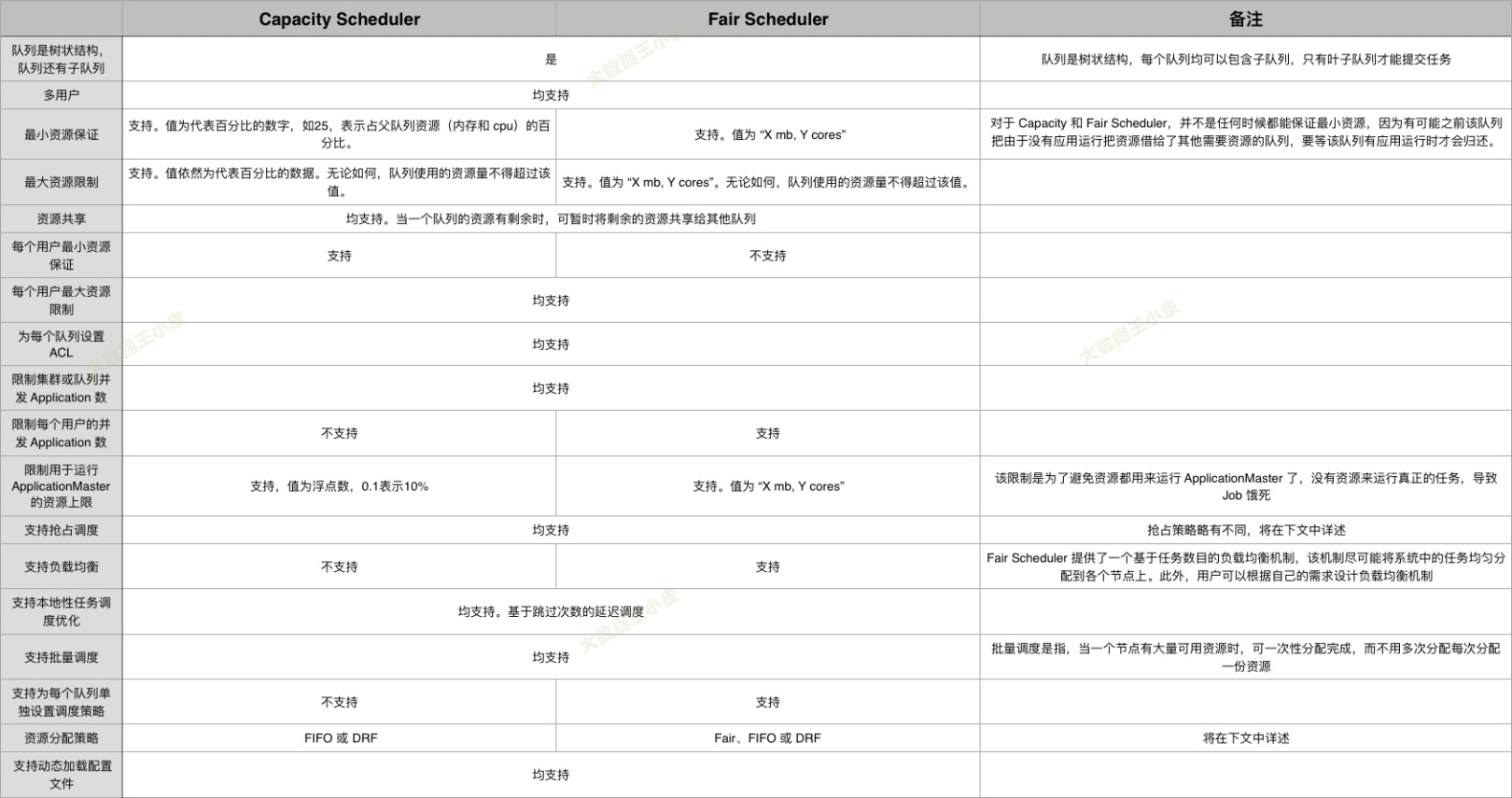
相同點
- 都支援多使用者多佇列,即:適用於多使用者共用叢集的應用環境
- 都支援層級佇列
- 支援設定動態修改,更好的保證了叢集的穩定執行。
- 均支援資源共用,即某個佇列中的資源有剩餘時,可共用給其他缺資源的佇列
- 單個佇列均支援優先順序和FIFO排程方式
不同點
- Capacity Scheduler的排程策略是,可以先選擇資源利用率低的佇列,然後在佇列中通過FIFO或DRF進行排程。
- Fair Scheduler的排程策略是,可以使用公平排序演演算法選擇佇列,然後再佇列中通過Fair(預設)、FIFO或DRF的方式進行排程。
六、小結
本篇介紹了 Yarn 中組重要的資源排程模組 ResourceScheduler,作為一個可插拔元件,預設有三種實現方式 Fifo、CapacityScheduler、FairScheduler。
文中對三個排程器的功能、特徵、設定、實現進行了較為詳細的分析。各位同學若對其中實現細節有興趣可深入原始碼,進一步探究。
參考文章:
YARN Capacity Scheduler (容量排程器) 不完全指南 | Bambrow's Blog - 對 CS 中設定屬性有較詳細講解
Capacity Scheduler - vs - Fair Scheduler
Yarn 排程器Scheduler詳解 - 對 Fair 佇列設定有較詳細講解
YARN排程器(Scheduler)詳解
詳解Yarn中三種資源排程器(FIFO Scheduler、Capacity Scheduler、Fair Scheduler)和設定自定義佇列實現任務提交不同佇列
Yarn Fair Scheduler詳解 - 原始碼分析
Yarn原始碼分析6-Reserve機制 | 亞坤的部落格 (yoelee.github.io)
YARN資源排程原理剖析
Hadoop 三大排程器原始碼分析及編寫自己的排程器