最強分散式搜尋引擎——ElasticSearch
最強分散式搜尋引擎——ElasticSearch
本篇我們將會介紹到一種特殊的類似資料庫儲存機制的搜尋引擎工具——ES
elasticsearch是一款非常強大的開源搜尋引擎,具備非常多強大功能,可以幫助我們從海量資料中快速找到需要的內容
我們會從下面幾個角度來講解ElasticSearch:
- ES概述
- ES索引庫操作
- ES檔案操作
- IDEA索引庫操作
- IDEA檔案操作
- ES資料搜尋
- IDEA資料搜尋
- ES資料聚合
- IDEA資料聚合
- MQ資料同步
ES概述
首先我們先來簡單介紹一下ElasticSearch
ES概念
我們首先來簡單介紹一下ES:
- ES是一款特殊的搜尋引擎工具,它在廣大場景都有所使用
- ES的本質是基於倒排索引機制,它可以快速地檢索某一個詞彙並找到對應的所屬位置
ELK技術棧
我們給出ELK的組成部分:
- ELK由四部分組成:elasticsearch,kibana、Logstash和Beats
- kibana:負責將資料視覺化展示
- elasticsearch:elastic stack的核心,負責儲存、搜尋、分析資料
- Logstash,Beats:負責資料的抓取
我們給出一張結構圖來表示ELK的整體結構:

ES核心機制
我們如果需要學習ES,那麼首先就需要了解ES的核心機制——倒排索引
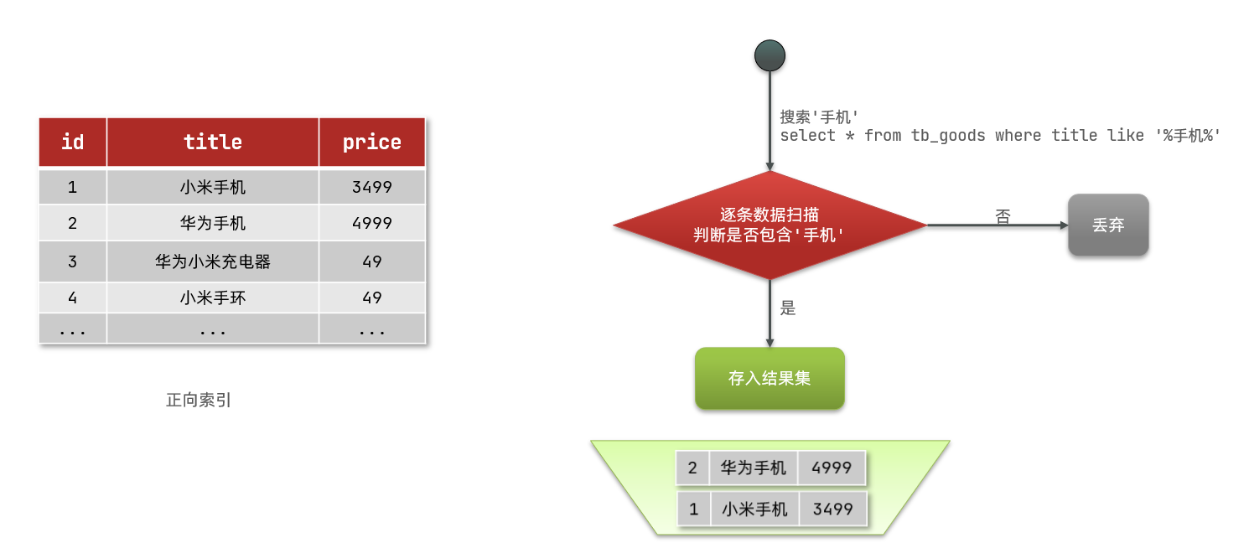
我們首先來介紹正向索引:
- MySQL資料庫中所使用的方法就是正向索引
- MySQL會首先產生一個id,然後根據這個id去生成索引 ,然後根據索引進行資料的查詢
- 簡單來說:如果我們通過id去查詢或者通過索引去查詢,速度就會非常快;但是如果我們不是通過索引或者採用模糊查詢,速度變慢
首先我們還需要了解倒排索引的一些關鍵字:
- 檔案:我們的一個物件,就被成為檔案,類似於MySQL中的一行資料,存在一個唯一id
- 詞條:對檔案資料或使用者搜尋資料,利用某種演演算法分詞,得到的具備含義的詞語就是詞條
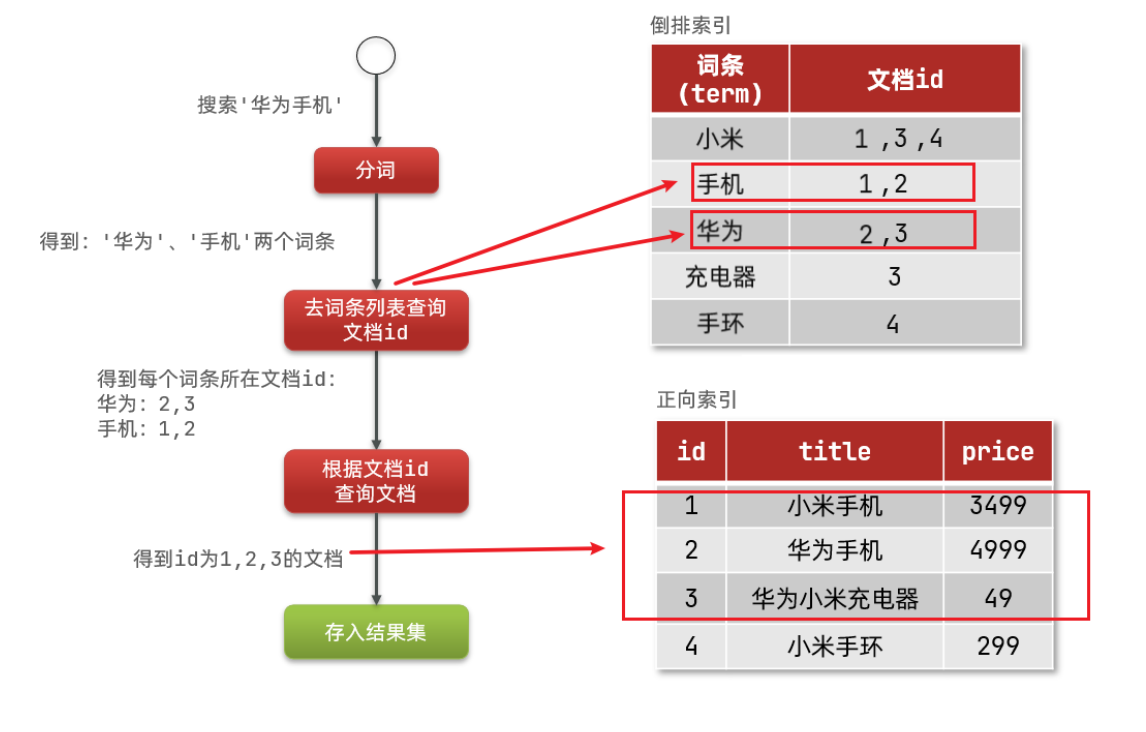
那麼我們再來介紹倒排索引:
- 倒排索引不將id作為查詢欄位,而是將儲存的資料分割作為查詢欄位,然後找到該欄位後去找對應的物件
- 例如小米手機,華為手機,華為小米充電器等一系列檔案,這些檔案都有一個唯一id
- 這時就會生成小米,手機,華為,充電器這樣的資料內容存放在ES中,這些詞彙後會跟著一個id的集合記錄哪些檔案包含該詞條
- 當我們查詢時,我們會去直接查詢欄位,然後檢視對應的id號,然後找到該id對應的物件並返回該物件結果
我們可以對兩者做出一個簡單的比較:
-
正向索引優點:可以給多個欄位建立索引;根據索引欄位搜尋、排序速度非常快
-
正向索引缺點:根據非索引欄位,或者索引欄位中的部分詞條查詢時,只能全表掃描。
-
倒排索引優點:根據詞條搜尋、模糊搜尋時,速度非常快
-
倒排索引缺點:只能給詞條建立索引,而不是欄位;無法根據欄位做排序
ES核心概念
我們來介紹一些ES中的核心概念:
- 檔案
- ES是面向檔案進行儲存的,檔案資料會被序列化為json格式後儲存在elasticsearch中
- 而Json檔案中往往包含很多的欄位(Field),類似於資料庫中的列,這些欄位就會被作為搜尋條件

- 索引和對映
-
索引實際上對標MySQL的資料庫,一個索引就是一個具體的資料庫
-
對映實際上對標MySQL的約束資訊,用於對索引進行一定條件的限制
-
通俗來講:索引就是就是相同型別的檔案的集合,對映是索引中檔案的欄位約束資訊

ES特點比較
我們將ES和MySQL進行一個簡單的對比,我們會發現兩者結構上非常相似:
| MySQL | Elasticsearch | 說明 |
|---|---|---|
| Table | Index | 索引(index),就是檔案的集合,類似資料庫的表(table) |
| Row | Document | 檔案(Document),就是一條條的資料,類似資料庫中的行(Row),檔案都是JSON格式 |
| Column | Field | 欄位(Field),就是JSON檔案中的欄位,類似資料庫中的列(Column) |
| Schema | Mapping | Mapping(對映)是索引中檔案的約束,例如欄位型別約束。類似資料庫的表結構(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON風格的請求語句,用來操作elasticsearch,實現CRUD |
而在實際使用上,兩者有不同的特點:
- Elasticsearch:擅長海量資料的搜尋、分析、計算
- Mysql:擅長事務型別操作,可以確保資料的安全和一致性
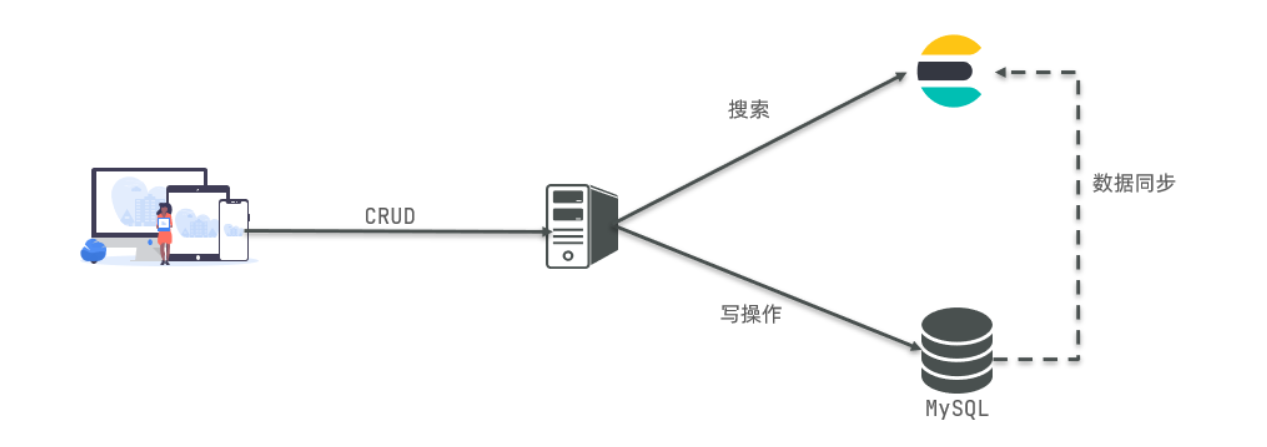
此外兩者還可以結合使用:
- 對安全性要求較高的寫操作,使用mysql實現;
- 對查詢效能要求較高的搜尋需求,使用elasticsearch實現;
- 兩者再基於某種方式,實現資料的同步,保證一致性,來實現實際開發
ES及相關產品安裝
既然要使用ES,那麼我們首先需要下載ES:
- 因為我們還需要部署kibana容器,因此需要讓es和kibana容器互聯。這裡先建立一個網路
docker network create es-net
- 下載es映象的tar包,進行載入
# 匯入資料
docker load -i es.tar
- 採用docker進行部署
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
# 命令解釋:
# - `-e "cluster.name=es-docker-cluster"`:設定叢集名稱
# - `-e "http.host=0.0.0.0"`:監聽的地址,可以外網存取
# - `-e "ES_JAVA_OPTS=-Xms512m -Xmx512m"`:記憶體大小
# - `-e "discovery.type=single-node"`:非叢集模式
# - `-v es-data:/usr/share/elasticsearch/data`:掛載邏輯卷,繫結es的資料目錄
# - `-v es-logs:/usr/share/elasticsearch/logs`:掛載邏輯卷,繫結es的紀錄檔目錄
# - `-v es-plugins:/usr/share/elasticsearch/plugins`:掛載邏輯卷,繫結es的外掛目錄
# - `--privileged`:授予邏輯卷存取權
# - `--network es-net` :加入一個名為es-net的網路中
# - `-p 9200:9200`:埠對映設定
然後我們還需要去部署一個kibana,kibana可以給我們提供一個elasticsearch的視覺化介面,便於我們學習:
- 下載kibana映象的tar包,並進行載入
# 匯入資料
docker load -i kibana.tar
- 執行docker命令,部署kibana
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
# 命令解釋:
# - `--network es-net` :加入一個名為es-net的網路中,與elasticsearch在同一個網路中
# - `-e ELASTICSEARCH_HOSTS=http://es:9200"`:設定elasticsearch的地址,因為kibana已經與elasticsearch在一個網路,因此可以用容器名直接存取elasticsearch
# - `-p 5601:5601`:埠對映設定
- 此時,在瀏覽器輸入地址存取:http://192.168.150.101:5601,即可看到結果(虛擬機器器ip:5601)
最後還需要一個IK分詞器,它可以幫助我們去完成中文的分詞功能:
- 直接安裝即可
# 進入容器內部
docker exec -it elasticsearch /bin/bash
# 線上下載並安裝
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
#退出
exit
#重啟容器
docker restart elasticsearch
ES索引庫操作
我們首先來介紹對ES索引庫的操作
對映屬性介紹
我們首先需要去介紹ES索引庫的Mapping:
- mapping是對索引庫中檔案的約束,常見的mapping屬性包括很多種
我們下面來一一介紹:
- type欄位資料型別
| TYPE名稱 | TYPE含義 |
|---|---|
| text | 字串(可以被劃分,可分詞的文字) |
| keyword | 字串(不可被劃分,精確值,例如:品牌、國家、ip地址) |
| long、integer、short、byte、double、float | 常見數值型別 |
| boolean | 布林值 |
| date | 日期值 |
| object | 物件 |
- index索引是否存在
- 預設為true,表示可以作為索引存在
- analyzer分詞器
- 後面跟具體的分詞器,用於更換分詞器種類
- properties子資源
- 該欄位的子欄位
我們給出一個簡單舉例:
{
"age": 21,// 型別為 integer;參與搜尋,因此需要index為true;無需分詞器
"weight": 52.1,
"isMarried": false,
"info": "河南師範大學",// 型別為字串,需要分詞,因此是text;參與搜尋,因此需要index為true;分詞器可以用ik_smart
"email": "[email protected]",// 型別為字串,但是不需要分詞,因此是keyword;不參與搜尋,因此需要index為false;無需分詞器
"score": [99.1, 99.5, 98.9],
"name": {
"firstName": "雲",
"lastName": "趙"
}
}
索引庫CURD
這裡我們統一使用Kibana編寫DSL的方式來演示
建立索引庫
下面我們來介紹建立索引庫的說明,架構和案例:
/*
- 請求方式:PUT
- 請求路徑:/索引庫名,可以自定義
- 請求引數:mapping對映
*/
/* 架構 */
PUT /索引庫名稱
{
"mappings": {
"properties": {
"欄位名":{
"type": "text",
"analyzer": "ik_smart"
},
"欄位名2":{
"type": "keyword",
"index": "false"
},
"欄位名3":{
"properties": {
"子欄位": {
"type": "keyword"
}
}
},
}
}
}
/* 案例 */
PUT /qiuluo
{
"mappings": {
"properties": {
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": "falsae"
},
"name":{
"properties": {
"firstName": {
"type": "keyword"
}
}
}
}
}
}
查詢索引庫
首先我們給出一個簡單案例:
/*
- 請求方式:GET
- 請求路徑:/索引庫名
- 請求引數:無
*/
/* 架構 */
GET /索引庫名
/* 案例 */
GET /qiuluo
修改索引庫
我們需要注意索引庫是無法修改已存在的結構的,但是可以對索引庫進行新增操作:
/*
- 請求方式:PUT
- 請求路徑:/索引庫名/_mapping
- 請求引數:修改內容
*/
/* 架構 */
PUT /索引庫名/_mapping
{
"properties": {
"新欄位名":{
"type": "integer"
}
}
}
刪除索引庫
刪除索引庫和前兩個的語法基本相似:
/*
- 請求方式:DELETE
- 請求路徑:/索引庫名
- 請求引數:無
*/
/* 架構 */
DELETE /索引庫名
ES檔案操作
下面我們來介紹ES的檔案操作
ES內容補充
其中在索引庫和檔案之間原本還有一層Type:
- Type類似於MySQL中的表,在ES 5.X版本中一個索引Index下可以有多個型別Type
- 在ES的後期版本中Type一般只有一個,後期就被預設為doc名稱的Type,所以我們後續的操作中會見到doc這個詞
檔案CURD
這裡我們統一使用Kibana編寫DSL的方式來演示
新增檔案
我們同樣直接給出具體的解釋和程式碼:
/*
- 請求方式:POST
- 請求路徑:/索引庫名/_doc/檔案id
- 請求引數:具體的欄位值和儲存值
*/
/* 模板 */
POST /索引庫名/_doc/檔案id
{
"欄位1": "值1",
"欄位2": "值2",
"欄位3": {
"子屬性1": "值3",
"子屬性2": "值4"
},
// ...
}
/* 舉例 */
POST /qiuluo/_doc/1
{
"info": "河南師範大學",
"email": "[email protected]",
"name": {
"firstName": "雲",
"lastName": "趙"
}
}
查詢檔案
我們同樣以DSL語句書寫查詢檔案程式碼:
/*
- 請求方式:GET
- 請求路徑:/索引庫名/_doc/檔案id
- 請求引數:無
*/
/* 模板 */
GET /{索引庫名稱}/_doc/{id}
/* 舉例 */
GET /qiuluo/_doc/1
刪除檔案
刪除檔案的格式和查詢檔案的格式基本相同:
/*
- 請求方式:DELETE
- 請求路徑:/索引庫名/_doc/檔案id
- 請求引數:無
*/
/* 模板 */
DELETE /{索引庫名}/_doc/id值
/* 舉例 */
DELETE /qiuluo/_doc/1
修改檔案
我們修改檔案大致分為兩種:全量修改和增量修改:
/*
全量修改的具體步驟:
- 根據指定的id刪除檔案,新增一個相同id的檔案
- 請求方式:PUT
- 請求路徑:/索引庫名/_doc/檔案id
- 請求引數:全部欄位內容
*/
/* 模板 */
PUT /{索引庫名}/_doc/檔案id
{
"欄位1": "值1",
"欄位2": "值2",
// ... 略
}
/* 舉例 */
PUT /qiuluo/_doc/1
{
"info": "河南師範大學",
"email": "[email protected]",
"name": {
"firstName": "雲",
"lastName": "趙"
}
}
/*
增量修改的具體步驟:
- 修改檔案中的部分欄位
- 請求方式:POST
- 請求路徑:/索引庫名/_update/檔案id
- 請求引數:只修改需要修改的部分
*/
/* 模板 */
POST /{索引庫名}/_update/檔案id
{
"doc": {
"欄位名": "新的值",
}
}
/* 舉例 */
POST /heima/_update/1
{
"doc": {
"email": "[email protected]"
}
}
IDEA索引庫操作
下面我們在IDEA上使用API去完成ES的使用
IDEA基本準備
我們在使用ES之前需要先完成幾項準備工作:
- 匯入資料
CREATE TABLE `tb_hotel` (
`id` bigint(20) NOT NULL COMMENT '酒店id',
`name` varchar(255) NOT NULL COMMENT '酒店名稱;例:7天酒店',
`address` varchar(255) NOT NULL COMMENT '酒店地址;例:航頭路',
`price` int(10) NOT NULL COMMENT '酒店價格;例:329',
`score` int(2) NOT NULL COMMENT '酒店評分;例:45,就是4.5分',
`brand` varchar(32) NOT NULL COMMENT '酒店品牌;例:如家',
`city` varchar(32) NOT NULL COMMENT '所在城市;例:上海',
`star_name` varchar(16) DEFAULT NULL COMMENT '酒店星級,從低到高分別是:1星到5星,1鑽到5鑽',
`business` varchar(255) DEFAULT NULL COMMENT '商圈;例:虹橋',
`latitude` varchar(32) NOT NULL COMMENT '緯度;例:31.2497',
`longitude` varchar(32) NOT NULL COMMENT '經度;例:120.3925',
`pic` varchar(255) DEFAULT NULL COMMENT '酒店圖片;例:/img/1.jpg',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
- 匯入專案

- 具體對映分析
/*
下述是我們需要插入的資料,我們需要對其分析並簡單瞭解,其具體思路不再解釋
我們需要介紹幾個新的內容:
1. geo_point
屬於type的一種,表示地理座標型別,裡面包含精度、緯度
geo_point屬於由兩個陣列成的一個點;而geo_shape是由多個geo_point所組成的一條線或一個區域
2. all
一個組合欄位,其目的是將多欄位的值 利用copy_to合併,提供給使用者搜尋
all欄位在最後進行標明,但在前面的某些欄位中我們採用了copy_to欄位,後面跟上了all表示將該欄位值拷貝一份到all中
也就是說all這個欄位是由name,brand,city等多個欄位連線起來的,這點是為了幫助我們在後面的按詞條快速查詢時方便
*/
PUT /hotel
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword",
"copy_to": "all"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
- 引入依賴並修改版本
<!--
我們在IDEA中參照ES去進行操作必定需要藉助工具,而這裡我們需要借用RestHighLevelClient去完成ES的操作,所以我們需要先去引入依賴
-->
<!--引入es的RestHighLevelClient依賴-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
<!--因為SpringBoot預設的ES版本是7.6.2,所以我們需要覆蓋預設的ES版本-->
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
- 生成一個RestHighLevelClient去完成ES操作
// 這裡僅是一個程式碼展示
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(// 可以看作固定生成語句
HttpHost.create("http://192.168.150.101:9200")// 這裡需要給出ES的連結地址,給出你的虛擬機器器ES埠
));
- 生成一個專門的測試類去完成後面的操作
package cn.itcast.hotel;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import java.io.IOException;
public class HotelIndexTest {
private RestHighLevelClient client;
// 執行前執行
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.150.101:9200")
));
}
// 執行後執行
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
}
建立索引庫
我們首先需要定義出具體的JSON資料內容:
package cn.itcast.hotel.constants;
public class HotelConstants {
public static final String MAPPING_TEMPLATE = "{\n" +
" \"mappings\": {\n" +
" \"properties\": {\n" +
" \"id\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"name\":{\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"address\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" },\n" +
" \"price\":{\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"score\":{\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"brand\":{\n" +
" \"type\": \"keyword\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"city\":{\n" +
" \"type\": \"keyword\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"starName\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"business\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"location\":{\n" +
" \"type\": \"geo_point\"\n" +
" },\n" +
" \"pic\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" },\n" +
" \"all\":{\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}";
}
然後我們就可以在我們先前定義的測試類中進行ES操作:
@Test
void createHotelIndex() throws IOException {
// 1.建立Request物件(建立是CreateIndexRequest)
CreateIndexRequest request = new CreateIndexRequest("hotel");// 引數是索引名稱
// 2.準備請求的引數:DSL語句(對request的source屬性進行設定)
request.source(MAPPING_TEMPLATE, XContentType.JSON);// 第一個引數是具體JSON,第二個引數是第一個引數型別
// 3.傳送請求(client.indices()是一個針對索引的物件,裡面封裝了各種索引方法)
client.indices().create(request, RequestOptions.DEFAULT);// 第一個引數是請求,第二個是預設格式
}
刪除索引庫
我們直接給出對應的程式碼展示:
@Test
void testDeleteHotelIndex() throws IOException {
// 1.建立Request物件(建立是DeleteIndexRequest)
DeleteIndexRequest request = new DeleteIndexRequest("hotel");// 引數是索引名稱
// 2.傳送請求
client.indices().delete(request, RequestOptions.DEFAULT);
}
獲得索引庫
我們這裡獲得索引庫並判斷該索引是否存在:
@Test
void testExistsHotelIndex() throws IOException {
// 1.建立Request物件(建立是GetIndexRequest)
GetIndexRequest request = new GetIndexRequest("hotel");
// 2.傳送請求(這裡呼叫的請求是exists判斷該索引是否存在,最後返回一個boolean值用於判斷)
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
// 3.輸出
System.err.println(exists ? "索引庫已經存在!" : "索引庫不存在!");
}
操作總結
我們其實可以將ES的DSL操作和IDEA的操作做一個簡單對比:
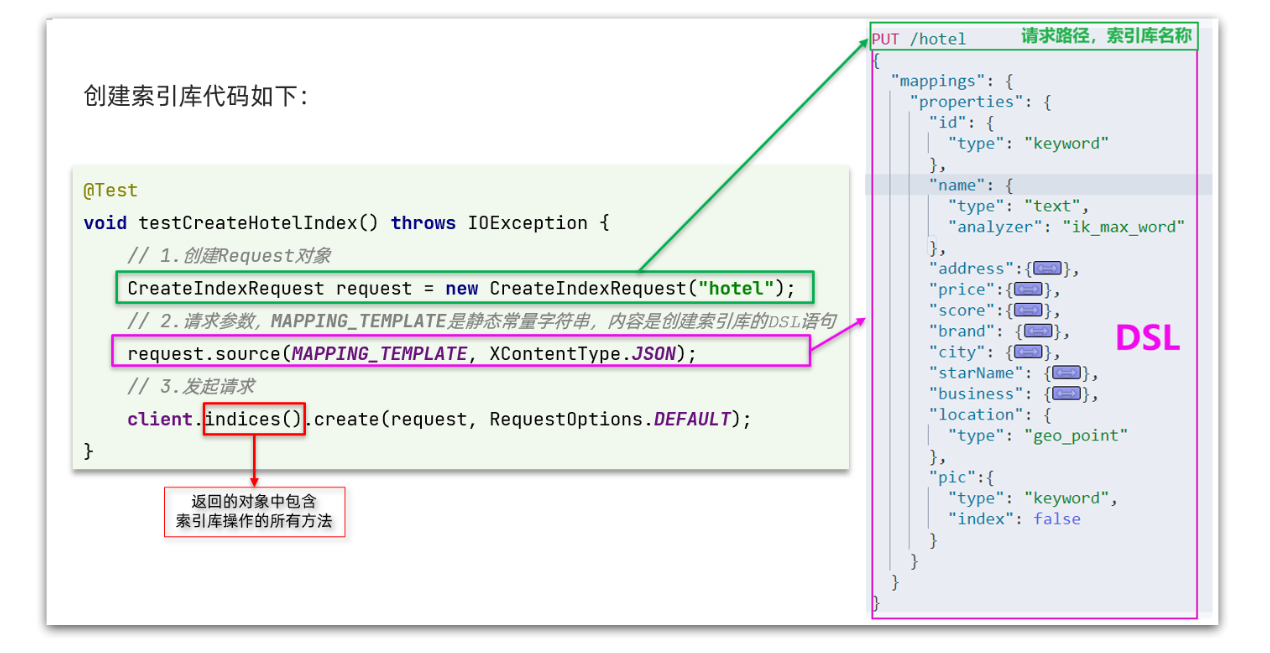
我們可以注意到:
- 建立Request物件。因為是建立索引庫的操作,因此Request是CreateIndexRequest。
- 新增請求引數,就是新增DSL的JSON引數部分,這裡是定義了靜態字串常數MAPPING_TEMPLATE
- 傳送請求,client.indices()方法的返回值是IndicesClient型別,封裝了所有與索引庫操作有關的方法。
因而我們可以給出具體的流程:
- 初始化RestHighLevelClient
- 建立IndexRequest,例如GetIndexRequest等
- 當需要DSL資料時,我們提前封裝並將其放入到request請求中
- 呼叫RestHighLevelClient的indices方法獲得IndicesClient,並呼叫其各類方法
IDEA檔案操作
下面我們來介紹IDEA的檔案操作
IDEA基本準備
我們首先需要準備一個對應的實體類:
// 這次我們主要是針對hotel旅館進行一個檔案資訊的填充
// 我們在MySQL資料庫中存放了相對應的資料,我們首先給出對應實體類
@Data
@TableName("tb_hotel")
public class Hotel {
@TableId(type = IdType.INPUT)
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String longitude;
private String latitude;
private String pic;
}
// 但是我們需要注意:我們之前索引庫中我們存在一個location屬性是將longitude和latitude結合起來形成一個座標
// 因而我們需要一個DTO來完成資訊封裝
package cn.itcast.hotel.pojo;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
}
}
我們同樣提前準備一個簡單的測試類:
package cn.itcast.hotel;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.service.IHotelService;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import java.util.List;
@SpringBootTest
public class HotelDocumentTest {
// 這裡是hotel的服務層,我們呼叫其方法來獲得mysql的相關資料來填充進ES的檔案中
@Autowired
private IHotelService hotelService;
// RestHighLevelClient
private RestHighLevelClient client;
// RestHighLevelClient封裝
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.150.101:9200")
));
}
// RestHighLevelClient釋放資源
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
}
新增檔案
我們首先給出一個簡單的案例展示:
- DSL語法展示
POST /{索引庫名}/_doc/1
{
"name": "Jack",
"age": 21
}
- Java語法展示
@Test
void testAddDocument() throws IOException {
// 1.準備Request物件(這裡是IndexRequest,Index類似於新添的概念)
IndexRequest request = new IndexRequest("indexName").id(1);// 第一個引數索引名稱,後面id跟的是檔案id
// 2.準備Json檔案
request.source("{\"name\":\"jack\",\"age\":21}", XContentType.JSON);// 同樣是對應的資料資訊
// 3.傳送請求
client.index(request, RequestOptions.DEFAULT);// 這裡檔案我們直接採用client呼叫方法即可,index就是新添操作
}
然後我們再針對MySQL資料庫資訊將其挪移到ES中:
@Test
void testAddDocument() throws IOException {
// 這裡都是Spring和MyBatisPlus的內容
// 1.根據id查詢酒店資料
Hotel hotel = hotelService.getById(61083L);
// 2.轉換為檔案型別
HotelDoc hotelDoc = new HotelDoc(hotel);
// 3.將HotelDoc轉json
String json = JSON.toJSONString(hotelDoc);
// 這裡和前面的內容完全相同,只是內容進行了包裝和更換
// 1.準備Request物件
IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());
// 2.準備Json檔案
request.source(json, XContentType.JSON);
// 3.傳送請求
client.index(request, RequestOptions.DEFAULT);
}
查詢檔案
我們首先給出對應的DSL語句:
GET /hotel/_doc/{id}
然後我們給出對應的Java程式碼:
@Test
void testGetDocumentById() throws IOException {
// 1.準備Request(這裡是GetRequest,Get就是獲得)
GetRequest request = new GetRequest("hotel", "61082");// 第一個引數是索引名稱,第二個引數是id
// 2.傳送請求,得到響應
GetResponse response = client.get(request, RequestOptions.DEFAULT);// get方法獲得response
// 3.解析響應結果
String json = response.getSourceAsString();// 我們通過response獲得對應的資料
// 4.將資料解析獲得結果
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println(hotelDoc);
}
刪除檔案
我們同樣給出DSL語句:
DELETE /hotel/_doc/{id}
然後我們給出對應的Java程式碼:
@Test
void testDeleteDocument() throws IOException {
// 1.準備Request
DeleteRequest request = new DeleteRequest("hotel", "61083");
// 2.傳送請求
client.delete(request, RequestOptions.DEFAULT);
}
修改檔案
修改檔案同樣可以劃分為兩種:
- 增量修改:修改檔案中的指定欄位值
- 全量修改:本質是先根據id刪除,再新增;全量修改與新增的API完全一致,判斷依據新增或修改依據是ID是否存在
我們直接給出增強修改對應的Java程式碼:
@Test
void testUpdateDocument() throws IOException {
// 1.準備Request
UpdateRequest request = new UpdateRequest("hotel", "61083");
// 2.準備請求引數(注意:這裡採用了doc而不是source)
request.doc(
"price", "952",
"starName", "四鑽"
);
// 3.傳送請求
client.update(request, RequestOptions.DEFAULT);
}
批次匯入檔案
下面我們將會利用BulkRequest批次將資料庫資料匯入到索引庫中:
@Test
void testBulkRequest() throws IOException {
// 批次查詢酒店資料
List<Hotel> hotels = hotelService.list();
// 1.建立Request
// BulkRequest實際上只是一個request集合體,它可以新增多種其他型別的request
// 包括IndexRequest新增,UpdateRequest修改,DeleteRequest刪除三種request請求並統一處理
BulkRequest request = new BulkRequest();
// 2.準備引數,新增多個新增的Request
for (Hotel hotel : hotels) {
// 2.1.轉換為檔案型別HotelDoc
HotelDoc hotelDoc = new HotelDoc(hotel);
// 2.2.建立新增檔案的Request物件
request.add(new IndexRequest("hotel")
.id(hotelDoc.getId().toString())
.source(JSON.toJSONString(hotelDoc), XContentType.JSON));
}
// 3.傳送請求
client.bulk(request, RequestOptions.DEFAULT);
}
操作總結
我們其實可以將ES的DSL操作和IDEA的操作做一個簡單對比:
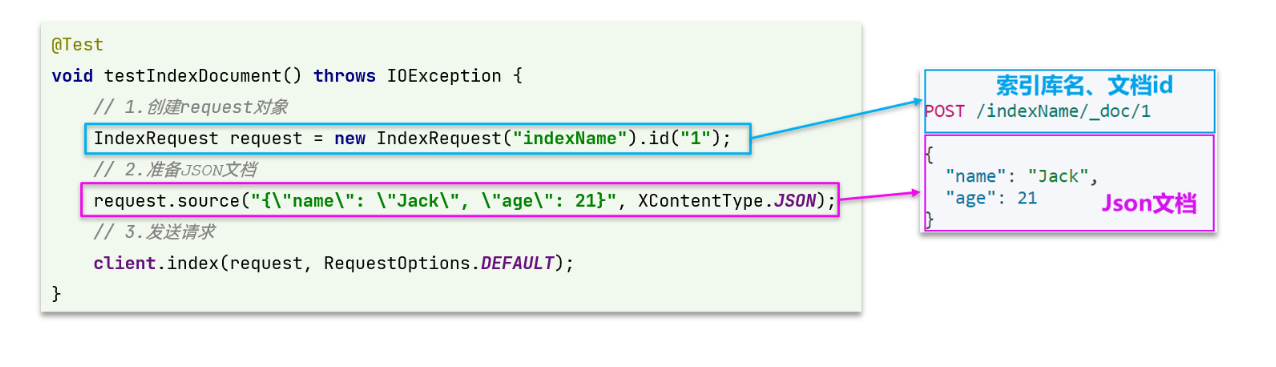
我們可以注意到同樣劃分為三步:
- 建立Request物件。因為是建立檔案的操作,因此Request是IndexRequest。
- 準備請求引數,也就是DSL中的JSON檔案
- 傳送請求,這裡是直接採用client中的方法進行檔案操作
因而我們可以給出具體的流程:
- 初始化RestHighLevelClient
- 建立Request。字首名包括有Index、Get、Update、Delete、Bulk
- 準備引數Index、Update、Bulk的Request請求時需要
- 傳送請求。呼叫RestHighLevelClient的各種方法,包括index、get、update、delete、bulk等方法
- 解析結果,例如get獲得資料後將其通過JSON的parseObject轉化為Domain實體並輸出
ES資料搜尋
在前面的章節其實只是完成了ES的一個資料儲存功能,但ES的核心功能是資料快速檢索查詢
資料查詢分類
Elasticsearch提供了基於JSON的DSL來定義查詢,大致有以下幾種查詢方式:
- 查詢所有:查詢出所有資料,一般測試用
- 全文檢索查詢:利用分詞器對使用者輸入內容分詞,然後去倒排索引庫中匹配
- 精確查詢:根據精確詞條值查詢資料,一般是查詢keyword、數值、日期、boolean等型別欄位
- 地理查詢:根據經緯度查詢
- 複合查詢:複合查詢可以將上述各種查詢條件組合起來,合併查詢條件
我們再給出一個基本查詢模板:
GET /indexName/_search
{
"query": {
"查詢型別": {
"查詢條件": "條件值"
}
}
}
查詢所有
查詢所有的關鍵字是"match_all",無查詢條件:
// 查詢所有
GET /indexName/_search
{
"query": {
"match_all": {
}
}
}
全文檢索查詢
首先我們需要了解全文檢索查詢的基礎流程:
- 對使用者搜尋的內容做分詞,得到詞條
- 根據詞條去倒排索引庫中匹配,得到檔案id
- 根據檔案id找到檔案,返回給使用者
其中全文檢索查詢可以大致分為兩種:
- match查詢:單欄位查詢
- multi_match查詢:多欄位查詢,任意一個欄位符合條件就算符合查詢條件
我們分別給出全文檢索模板:
// match查詢:僅一個欄位,一個匹配內容
GET /indexName/_search
{
"query": {
"match": {
"FIELD": "TEXT"// FIELD為對應的欄位名稱,TEXT為查詢內容
}
}
}
// multi_match查詢:多欄位查詢,任意一個欄位符合條件就算符合查詢條件
GET /indexName/_search
{
"query": {
"multi_match": {
"query": "TEXT", // TEXT為查詢內容
"fields": ["FIELD1", " FIELD12"] // FIELD1,2,3,均為查詢欄位
}
}
}
我們同時給出一個簡單案例:
// 下述兩個全文檢索含義相同
// match查詢:僅一個欄位,一個匹配內容
GET /hotel/_search
{
"query": {
"match": {
"all": "外灘" // 這裡僅針對all欄位進行"外灘"的檢索,但是all欄位是由多個欄位copy_to產生的
}
}
}
// multi_match查詢:多欄位查詢,任意一個欄位符合條件就算符合查詢條件
GET /hotel/_search
{
"query": {
"multi_match": {
"query": "外灘",
"fields": ["brand", "name","business"] // 這三個欄位均使用了copy_to至all欄位,固兩個查詢含義相同
}
}
}
// 但是查詢欄位越多其速度越慢,所以match查詢的速度是要遠高於multi_match的
精準查詢
精確查詢一般是查詢keyword、數值、日期、boolean等型別欄位,我們一般會將精準查詢分為兩部分:
- term:根據詞條精確值查詢
- range:根據值的範圍查詢
首先我們先來介紹term查詢:
// 模板
GET /indexName/_search
{
"query": {
"term": { // 表示精準查詢
"FIELD": { // 欄位名
"value": "VALUE" // 查詢欄位內容
}
}
}
}
// 案例
GET /hotel/_search
{
"query": {
"term": {
"city": {
"value": "北京" // 表示查詢地點在北京的賓館
}
}
}
}
下面我們再來介紹range查詢:
// 模板
GET /indexName/_search
{
"query": {
"range": {
"FIELD": { // 這裡更換欄位名
"gte": 10, // 這裡的gte代表大於等於,gt則代表大於
"lte": 20 // lte代表小於等於,lt則代表小於
}
}
}
}
// 案例
GET /hotel/_search
{
"query": {
"range": {
"price": {
"gte": 200,
"lte": 1000 // 這裡表示尋找價格在200~1000之間的賓館
}
}
}
}
地理查詢
所謂的地理座標查詢,其實就是根據經緯度查詢,地理查詢通常被分為兩方面:
- 矩形範圍查詢:分別規定左上角和右下角來規定矩形範圍進行區域劃分
- 附近範圍查詢:查詢到指定中心點小於某個距離值的所有檔案
我們首先來介紹矩形範圍查詢:
// geo_bounding_box查詢
GET /indexName/_search
{
"query": {
"geo_bounding_box": {
"FIELD": { // 這裡的FIELD需要修改為欄位名
"top_left": { // 左上點
"lat": 31.1,
"lon": 121.5
},
"bottom_right": { // 右下點
"lat": 30.9,
"lon": 121.7
}
}
}
}
}
下面我們再來介紹附近範圍查詢:
// 模板
GET /indexName/_search
{
"query": {
"geo_distance": { // 表示附近範圍查詢,其實就是圓形查詢
"distance": "15km", // 半徑
"FIELD": "31.21,121.5" // 圓心(前面的FIELD需要修改為具體欄位名,表示進行匹配)
}
}
}
// 案例
GET /hotel/_search
{
"query": {
"geo_distance": {
"distance": "15km",
"Location": "31.21,121.5" // 圓心修改為Location的值,當距離小於15km時匹配成功
}
}
}
複合查詢
最後我們介紹一下複合查詢:
- 複合查詢可以將其它簡單查詢組合起來,實現更復雜的搜尋邏輯
複合查詢通常被分為兩種情況:
- fuction score:算分函數查詢,可以控制檔案相關性算分,控制檔案排名
- bool query:布林查詢,利用邏輯關係組合多個其它的查詢,實現複雜搜尋
那麼在正式介紹複合查詢之前,我們需要先去了解一下檔案相關性算分:
// 檔案相關性演演算法:檔結果會根據與搜尋詞條的關聯度打分(_score),返回結果時按照分值降序排列
[
{
"_score" : 17.850193,
"_source" : {
"name" : "虹橋如家酒店真不錯",
}
},
{
"_score" : 12.259849,
"_source" : {
"name" : "外灘如家酒店真不錯",
}
},
{
"_score" : 11.91091,
"_source" : {
"name" : "迪士尼如家酒店真不錯",
}
}
]
而這種算分機制是由系統去控制,目前所延用的算分機制為BM25算分機制:

那麼我們接下來就可以去了解算分函數查詢:
// 我們平時所得出的score也許並不能完全滿足我們的正常需求
// 例如:百度的廣告通常會覆蓋掉得分高的空間而被安排到最上層
/*
function score 查詢中包含四部分內容:
- **原始查詢**條件:query部分,基於這個條件搜尋檔案,並且基於BM25演演算法給檔案打分,**原始算分**(query score)
- **過濾條件**:filter部分,符合該條件的檔案才會重新算分
- **算分函數**:符合filter條件的檔案要根據這個函數做運算,得到的**函數算分**(function score),有四種函數
- weight:函數結果是常數
- field_value_factor:以檔案中的某個欄位值作為函數結果
- random_score:以亂數作為函數結果
- script_score:自定義算分函數演演算法
- **運算模式**:算分函數的結果、原始查詢的相關性算分,兩者之間的運算方式,包括:
- multiply:相乘
- replace:用function score替換query score
- 其它,例如:sum、avg、max、min
*/
/*
function score的執行流程如下:
- 1)根據**原始條件**查詢搜尋檔案,並且計算相關性算分,稱為**原始算分**(query score)
- 2)根據**過濾條件**,過濾檔案
- 3)符合**過濾條件**的檔案,基於**算分函數**運算,得到**函數算分**(function score)
- 4)將**原始算分**(query score)和**函數算分**(function score)基於**運算模式**做運算,得到最終結果,作為相關性算分。
*/
// 我們給出一個簡單模板去解釋上述內容
GET /indexName/_search
{
"query": {
"function_score": {
"query": { .... }, // 原始查詢,可以是任意條件
"functions": [ // 算分函數
{
"filter": { // 滿足的條件
"term": { // 這裡假設採用精準查詢匹配
"FIELD": "TEXT" // 需要滿足FIELD欄位為TEXT
}
},
"weight": N // 算分權重為N
}
],
"boost_mode": "???" // 原始權重和算分權重的演演算法:有相加,乘法等
}
}
}
// 我們舉一個簡單的例子
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match":{
"all":"外灘"
}
}, // 原始查詢,我們這裡查詢在all欄位中帶"外灘"的內容
"functions": [ // 算分函數,下面是內容函數
{
"filter": { // 滿足的條件,品牌必須是如家
"term": {
"brand": "如家"
}
},
"weight": 2 // 算分權重為2
}
],
"boost_mode": "sum" // 加權模式,求和
}
}
}
最後我們還需要介紹一個布林查詢:
// 布林查詢其實就是簡單的&&,||查詢
/*
布林查詢是一個或多個查詢子句的組合,每一個子句就是一個**子查詢**。子查詢的組合方式有:
- must:必須匹配每個子查詢,類似「與」
- should:選擇性匹配子查詢,類似「或」
- must_not:必須不匹配,**不參與算分**,類似「非」
- filter:必須匹配,**不參與算分**
*/
/*
需要注意的是,搜尋時,參與**打分的欄位越多,查詢的效能也越差**。因此這種多條件查詢時,建議這樣做:
- 搜尋方塊的關鍵字搜尋,是全文檢索查詢,使用must查詢,參與算分
- 其它過濾條件,採用filter查詢。不參與算分
*/
// 我們首先給出一個模板
GET /indexName/_search
{
"query": {
"bool": { // 表示開啟bool複合查詢
"must": [ // must必須滿足
{"term": {"FIELD": "TEXT" }}
],
"should": [// 選擇性匹配子查詢,類似「或」
{"term": {"FIELD": "TEXT" }},
{"term": {"FIELD": "TEXT" }}
],
"must_not": [// 不能滿足,
{ "range": { "FIELD": { "lte": TEXT } }}
],
"filter": [// 必須滿足,但不參與到算分專案中
{ "range": {"FIELD": { "gte": TEXT } }}
]
}
}
}
// 我們給出一個簡單案例:
GET /hotel/_search
{
"query": {
"bool": {
"must": [// 必須在上海
{"term": {"city": "上海" }}
],
"should": [// 品牌必須是皇冠或華美達其中一種
{"term": {"brand": "皇冠假日" }},
{"term": {"brand": "華美達" }}
],
"must_not": [// 價格不能低於500
{ "range": { "price": { "lte": 500 } }}
],
"filter": [// 得分必須高於45
{ "range": {"score": { "gte": 45 } }}
]
}
}
}
搜尋結果處理
對於GET獲得的結果我們還可以對其進行簡單處理,其中大致包括有:
- 排序:對搜尋結果進行排序操作
- 分頁:對搜尋結果進行分頁操作
- 高亮:對搜尋結果進行高亮操作
排序
ES預設是根據相關度算分來排序,但是也支援自定義方式對搜尋結果排序,大致分為兩種:
- 普通欄位排序
- 地理座標排序
我們首先來介紹普通欄位排序:
// 普通欄位包括有:keyword、數值、日期型別排序
// 模板
// 排序條件是一個陣列,也就是可以寫多個排序條件。按照宣告的順序,當第一個條件相等時,再按照第二個條件排序,以此類推
GET /indexName/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"FIELD": "desc" // 排序欄位、排序方式ASC、DESC
}
]
}
// 案例
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"score"::"desc"
}
,{
"price": "asc"
}
]
}
我們再來介紹地理座標排序:
// 地理座標排序:指定一個座標,作為目標點,計算每一個檔案中,指定欄位的座標 到目標點的距離是多少,根據距離排序
// 模板
GET /indexName/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance" : {
"FIELD" : "緯度,經度", // 檔案中geo_point型別的欄位名、目標座標點
"order" : "asc", // 排序方式
"unit" : "km" // 排序的距離單位
}
}
]
}
// 案例
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance" : {
"location" : "31,121", // 座標在(31,121)附近的酒店按距離排序
"order" : "asc", // 排序方式
"unit" : "km" // 排序的距離單位
}
}
]
}
分頁
elasticsearch 預設情況下只返回top10的資料,如果希望返回更多隻能採用分頁模式,分頁被劃分為兩種:
- 基本分頁
- 深度分頁
我們首先來介紹基本分頁:
// 分頁主要依賴兩個引數:from和size,類似於mysql中的`limit ?, ?`
// - from:從第幾個檔案開始
// - size:總共查詢幾個檔案
// 模板
GET /indexName/_search
{
"query": {
"match_all": {}
},
"from": ?, // 分頁開始的位置,預設為0
"size": ?, // 期望獲取的檔案總數
"sort": [
{"price": "asc"} // 排序方式
]
}
// 案例
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 0, // 分頁開始的位置,預設為0
"size": 10, // 期望獲取的檔案總數
"sort": [
{"price": "asc"}
]
}
然後我們再來介紹深度分頁:
// 首先我們需要去了解一個思想,假設我們獲取990~1000的資料,那麼我們需要先去查詢0~1000的資料然後去擷取990~1000
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 990, // 分頁開始的位置,預設為0
"size": 10, // 期望獲取的檔案總數
"sort": [
{"price": "asc"}
]
}
// 如果是單點查詢,那麼我們可以只查詢資料並排序擷取就可以了
// 但如果叢集查詢,我們並非說只獲取每個節點的TOP200就可以了,因為排序未定,我們需要獲取每個節點的TOP1000再重新排序獲取
// 就會導致所查詢資料過多導致查詢緩慢,ES伺服器壓力較大,因此elasticsearch會禁止from+ size 超過10000的請求
// 針對深度分頁,ES提供了兩種解決方案,[官方檔案]:
// - search after:分頁時需要排序,原理是從上一次的排序值開始,查詢下一頁資料。官方推薦使用的方式。
// - scroll:原理將排序後的檔案id形成快照,儲存在記憶體。官方已經不推薦使用。
高亮
我們首先介紹一下高亮:
- 當我們在百度查詢時,我們的查詢詞彙通常會在查詢內容中高亮顯示出來用來確定查詢位置
高亮顯示的實現分為兩步:
- 給檔案中的所有關鍵字都新增一個標籤,例如
<em>標籤 - 頁面給
<em>標籤編寫CSS樣式
我們來簡單學習一下高亮:
// 模板
GET /indexName/_search
{
"query": {
"match": {
"FIELD": "TEXT" // 查詢條件,高亮一定要使用全文檢索查詢
}
},
"highlight": {
"fields": { // 指定要高亮的欄位
"FIELD": {
"pre_tags": "<em>", // 用來標記高亮欄位的前置標籤
"post_tags": "</em>" // 用來標記高亮欄位的後置標籤
}
}
}
}
// 案例
GET /hotel/_search
{
"query": {
"match": {
"all": "如家" // 查詢條件,高亮一定要使用全文檢索查詢
}
},
"highlight": {
"fields": { // 指定要高亮的欄位
"name": {
"require_field_match":"false",// 預設無法高亮,需要新增屬性
"pre_tags": "<em>", // 用來標記高亮欄位的前置標籤
"post_tags": "</em>" // 用來標記高亮欄位的後置標籤
}
}
}
}
/*
**注意:**
- 高亮是對關鍵字高亮,因此**搜尋條件必須帶有關鍵字**,而不能是範圍這樣的查詢。
- 預設情況下,**高亮的欄位,必須與搜尋指定的欄位一致**,否則無法高亮
- 如果要對非搜尋欄位高亮,則需要新增一個屬性:required_field_match=false
*/
IDEA資料搜尋
下面我們來使用Java程式碼去操作ES完成資料搜尋
快速入門
我們首先來簡單學習一下使用流程:
- 發起查詢請求
@Test
void testMatchAll() throws IOException {
// 1.準備Request
SearchRequest request = new SearchRequest("hotel");// 查詢統一使用SearchRequest的請求
// 2.準備DSL
request.source()
.query(QueryBuilders.matchAllQuery());
// request.source()的方法中包含了所有方法:query,sort,size,from,highlighter等
// query():代表查詢條件,利用QueryBuilders.matchAllQuery()構建一個match_all查詢的DSL
// QueryBuilders:其中包含match、term、function_score、bool等各種查詢
// 3.傳送請求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
}
- 對響應進行處理
private void handleResponse(SearchResponse response) {
// 4.解析響應
// 通過response.getHits()獲取,就是JSON中的最外層的hits,代表命中的結果
SearchHits searchHits = response.getHits();
// 4.1.獲取總條數
// `SearchHits#getTotalHits().value`:獲取總條數資訊
long total = searchHits.getTotalHits().value;
System.out.println("共搜尋到" + total + "條資料");
// 4.2.檔案陣列
// `SearchHits#getHits()`:獲取SearchHit陣列,也就是檔案陣列
SearchHit[] hits = searchHits.getHits();
// 4.3.遍歷
for (SearchHit hit : hits) {
// 獲取檔案source
// `SearchHit#getSourceAsString()`:獲取檔案結果中的_source,也就是原始的json檔案資料
String json = hit.getSourceAsString();
// 反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println("hotelDoc = " + hotelDoc);
}
}
- 整體程式碼展示
@Test
void testMatchAll() throws IOException {
// 1.準備Request
SearchRequest request = new SearchRequest("hotel");
// 2.準備DSL
request.source()
.query(QueryBuilders.matchAllQuery());
// 3.傳送請求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析響應
handleResponse(response);
}
private void handleResponse(SearchResponse response) {
// 4.解析響應
SearchHits searchHits = response.getHits();
// 4.1.獲取總條數
long total = searchHits.getTotalHits().value;
System.out.println("共搜尋到" + total + "條資料");
// 4.2.檔案陣列
SearchHit[] hits = searchHits.getHits();
// 4.3.遍歷
for (SearchHit hit : hits) {
// 獲取檔案source
String json = hit.getSourceAsString();
// 反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println("hotelDoc = " + hotelDoc);
}
}
/*
整體步驟:
1. 建立SearchRequest物件
2. 準備Request.source(),也就是DSL。
① QueryBuilders來構建查詢條件
② 傳入Request.source() 的 query() 方法
3. 傳送請求,得到結果
4. 解析結果(參考JSON結果,從外到內,逐層解析)
*/
match查詢
我們首先來介紹match查詢:
// 全文檢索的match和multi_match查詢與match_all的API基本一致,Java程式碼上的差異主要是request.source().query()中的引數
// match查詢
@Test
void testMatch() throws IOException {
// 1.準備Request
SearchRequest request = new SearchRequest("hotel");
// 2.準備DSL
request.source()// 這裡第一個引數是欄位,第二個引數是val匹配值
.query(QueryBuilders.matchQuery("all", "如家"));// QueryBuilders的matchQuery
// 3.傳送請求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析響應
handleResponse(response);
}
// MultiMatch查詢
@Test
void testMultiMatch() throws IOException {
// 1.準備Request
SearchRequest request = new SearchRequest("hotel");
// 2.準備DSL
request.source()// 這裡第一個引數是val匹配值,後面均為欄位
.query(QueryBuilders.mutilMatchQuery("如家","brand","name","business"));// mutilMatchQuery方法
// 3.傳送請求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析響應
handleResponse(response);
}
精確查詢
下面我們來介紹精準查詢:
// 精準查詢主要分為:term和range,和之前幾乎相同,只是採用的API不同
// term查詢
@Test
void testMatch() throws IOException {
// 1.準備Request
SearchRequest request = new SearchRequest("hotel");
// 2.準備DSL
request.source()// 這裡第一個引數是欄位,第二個引數是val匹配值
.query(QueryBuilders.termQuery("city", "北京"));// QueryBuilders的termQuery
// 3.傳送請求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析響應
handleResponse(response);
}
// range查詢
@Test
void testMatch() throws IOException {
// 1.準備Request
SearchRequest request = new SearchRequest("hotel");
// 2.準備DSL
request.source()// rangeQuery獲得對應QueryBuilders,後面採用gte和lte設定條件
.query(QueryBuilders.rangeQuery("price").gte(100).lte(150));
// 3.傳送請求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析響應
handleResponse(response);
}
布林查詢
下面我們來介紹布林查詢:
// 布林查詢是用must、must_not、filter等方式組合其它查詢
@Test
void testBool() throws IOException {
// 1.準備Request
SearchRequest request = new SearchRequest("hotel");
// 2.準備DSL
// 2.1.準備BooleanQuery(由於內容過多,我們提前建立並對其設定,最後新增入request即可)
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// 2.2.新增term(注意:內部使用的仍是Query,BooleanQuery僅僅是將這些Query結合起來)
boolQuery.must(QueryBuilders.termQuery("city", "杭州"));
// 2.3.新增range(注意:內部使用的仍是Query,BooleanQuery僅僅是將這些Query結合起來)
boolQuery.filter(QueryBuilders.rangeQuery("price").lte(250));
request.source().query(boolQuery);// 注入
// 3.傳送請求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析響應
handleResponse(response);
}
排序分頁
下面我們同時來介紹排序和分頁兩個操作:
// 搜尋結果的排序和分頁是與query同級的引數,因此同樣是使用request.source()來設定
@Test
void testPageAndSort() throws IOException {
// 頁碼,每頁大小
int page = 1, size = 5;
// 1.準備Request
SearchRequest request = new SearchRequest("hotel");
// 2.準備DSL
// 2.1.query
request.source().query(QueryBuilders.matchAllQuery());// 查詢所有
// 2.2.排序 sort
request.source().sort("price", SortOrder.ASC); // 按price排序,升序
// 2.3.分頁 from、size
request.source().from((page - 1) * size).size(5);// 分頁查詢
// 3.傳送請求
SearchResponse response P= client.search(request, RequestOptions.DEFAULT);
// 4.解析響應
handleResponse(response);
}
高亮查詢
最後我們介紹一下高亮查詢:
// 高亮查詢必須使用全文檢索查詢,並且要有搜尋鍵碼,將來才可以對關鍵字高亮
// - 查詢的DSL:其中除了查詢條件,還需要新增高亮條件,同樣是與query同級。
// - 結果解析:結果除了要解析_source檔案資料,還要解析高亮結果
// 首先我們處理請求問題
@Test
void testHighlight() throws IOException {
// 1.準備Request
SearchRequest request = new SearchRequest("hotel");
// 2.準備DSL
// 2.1.query
request.source().query(QueryBuilders.matchQuery("all", "如家"));// 全文檢索查詢
// 2.2.高亮
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
// 3.傳送請求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析響應
handleResponse(response);
}
// 我們還需要對高亮結果進行解析
private void handleResponse(SearchResponse response) {
// 4.解析響應
SearchHits searchHits = response.getHits();
// 4.1.獲取總條數
long total = searchHits.getTotalHits().value;
System.out.println("共搜尋到" + total + "條資料");
// 4.2.檔案陣列
SearchHit[] hits = searchHits.getHits();
// 4.3.遍歷
for (SearchHit hit : hits) {
// 獲取檔案source
String json = hit.getSourceAsString();
// 反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
// 獲取高亮結果
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
if (!CollectionUtils.isEmpty(highlightFields)) {
// 根據欄位名獲取高亮結果
HighlightField highlightField = highlightFields.get("name");
if (highlightField != null) {
// 獲取高亮值
String name = highlightField.getFragments()[0].string();
// 覆蓋非高亮結果
hotelDoc.setName(name);
}
}
System.out.println("hotelDoc = " + hotelDoc);
}
}
ES資料聚合
下面我們來學習ES的資料聚合
資料聚合
首先我們需要先來了解資料聚合:
- 聚合可以讓我們極其方便的實現對資料的統計、分析、運算
- ES實現這些統計功能的比資料庫的sql要方便的多,而且查詢速度非常快,可以實現近實時搜尋效果
ES的聚合通常被分為三種:
- 桶(Bucket)聚合:用來對檔案做分組
- 度量(Metric)聚合:用以計算一些值,比如:最大值、最小值、平均值等
- 管道(pipeline)聚合:其它聚合的結果為基礎做聚合
注意:參加聚合的欄位必須是keyword、日期、數值、布林型別
桶聚合
首先我們先來了解基本的桶聚合:
- TermAggregation:按照檔案欄位值分組,例如按照品牌值分組、按照國家分組
- Date Histogram:按照日期階梯分組,例如一週為一組,或者一月為一組
我們給出一個桶聚合的案例展示:
GET /hotel/_search
{
"size": 0, // 設定size為0,結果中不包含檔案,只包含聚合結果
"aggs": { // 表示開始定義聚合
"brandAgg": { // 聚合名稱,自定義即可
"terms": { // 聚合的型別,按照品牌值聚合,所以選擇term(TermAggregation聚合)
"field": "brand", // 參與聚合的欄位,會根據brand品牌進行聚合
"size": 20 // 希望獲取的聚合結果數量(預設情況為10,修改可展示資料數量)
}
}
}
}
預設情況下,Bucket聚合會統計Bucket內的檔案數量,記為_count,並且按照_count降序排序,但是我們可以進行修改:
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"order": { // 我們可以在aggs的對應聚合名稱內設定order來修改排序方式
"_count": "asc" // 按照_count升序排列
},
"size": 20
}
}
}
}
我們同樣可以採用資料搜尋的方式來限制聚合的範圍大小:
// 很多情況下,我們並非需要聚合所有的資料,而是聚合滿足一定條件的資料,那麼我們就需要設定限制條件
GET /hotel/_search
{
// 實際上就是採用最簡單的query方法來限制條件
"query": {
"range": {
"price": {
"lte": 200 // 只對200元以下的檔案聚合
}
}
},
"size": 0,
// 這裡仍舊採用aggs即可
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
}
}
}
}
度量聚合
我們再來介紹一下度量聚合:
- 度量(Metric)聚合:用以計算一些值,比如:最大值、最小值、平均值等
- 度量聚合通常是管道聚合,因為度量聚合的資料計算通常是建立在一層資料聚合之後
度量聚合通常會分為四種情況:
- Avg:求平均值
- Max:求最大值
- Min:求最小值
- Stats:同時求max、min、avg、sum等
我們這裡同樣給出一個簡單案例展示:
GET /hotel/_search
{
// 設定展示資料,設定為0,不允許出聚合資料外的資料展示
"size": 0,
// 第一層資料聚合,這層會按brand進行分組並且聚合展示
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
},
// 第二層資料聚合,實際上也是管道聚合!!!
"aggs": { // 是brands聚合的子聚合,也就是分組後對每組分別計算
"score_stats": { // 聚合名稱
"stats": { // 聚合型別,這裡stats可以計算min、max、avg等(也可以單寫min、max、avg其中一種)
"field": "score" // 聚合欄位,這裡是score
}
}
}
}
}
}
IDEA資料聚合
下面我們來用Java程式碼來實現資料聚合
API分析
我們下面會從兩方面分別將DSL語句和Java語句進行對比分析:
- 請求資訊設定
- 響應資料設定
資料聚合案例
我們將通過一個簡單的資料聚合案例來介紹具體API使用:
- 我們希望從ES資料中搜尋對應的資料,並將這些資料組合成陣列返回到前端進行展示
- 我們希望從ES資料中搜尋酒店使用量最多的城市,星級,品牌並進行處理,將其返回到前端頁面展示
- 同時我們還需要注意我們的搜尋存在一個搜尋方塊,我們所獲得的聚合資訊必須要滿足搜尋方塊條件,也就是Query
下面我們來具體實現其效果:
- 控制層書寫Controller
/*
相關前端請求資訊:
- 請求方式:`POST`
- 請求路徑:`/hotel/filters`
- 請求引數:`RequestParams`,與搜尋檔案的引數一致
- 返回值型別:`Map<String, List<String>>`
*/
@PostMapping("filters")
public Map<String, List<String>> getFilters(@RequestBody RequestParams params){
return hotelService.getFilters(params);
}
- 服務層介面Service
Map<String, List<String>> filters(RequestParams params);
- 服務層具體實現ServiceImpl
@Override
public Map<String, List<String>> filters(RequestParams params) {
try {
// 1.準備Request
SearchRequest request = new SearchRequest("hotel");
// 2.準備DSL
// 2.1.query
buildBasicQuery(params, request);
// 2.2.設定size
request.source().size(0);
// 2.3.聚合
buildAggregation(request);
// 3.發出請求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析結果
Map<String, List<String>> result = new HashMap<>();
Aggregations aggregations = response.getAggregations();
// 4.1.根據品牌名稱,獲取品牌結果
List<String> brandList = getAggByName(aggregations, "brandAgg");
result.put("品牌", brandList);
// 4.2.根據品牌名稱,獲取品牌結果
List<String> cityList = getAggByName(aggregations, "cityAgg");
result.put("城市", cityList);
// 4.3.根據品牌名稱,獲取品牌結果
List<String> starList = getAggByName(aggregations, "starAgg");
result.put("星級", starList);
return result;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private void buildAggregation(SearchRequest request) {
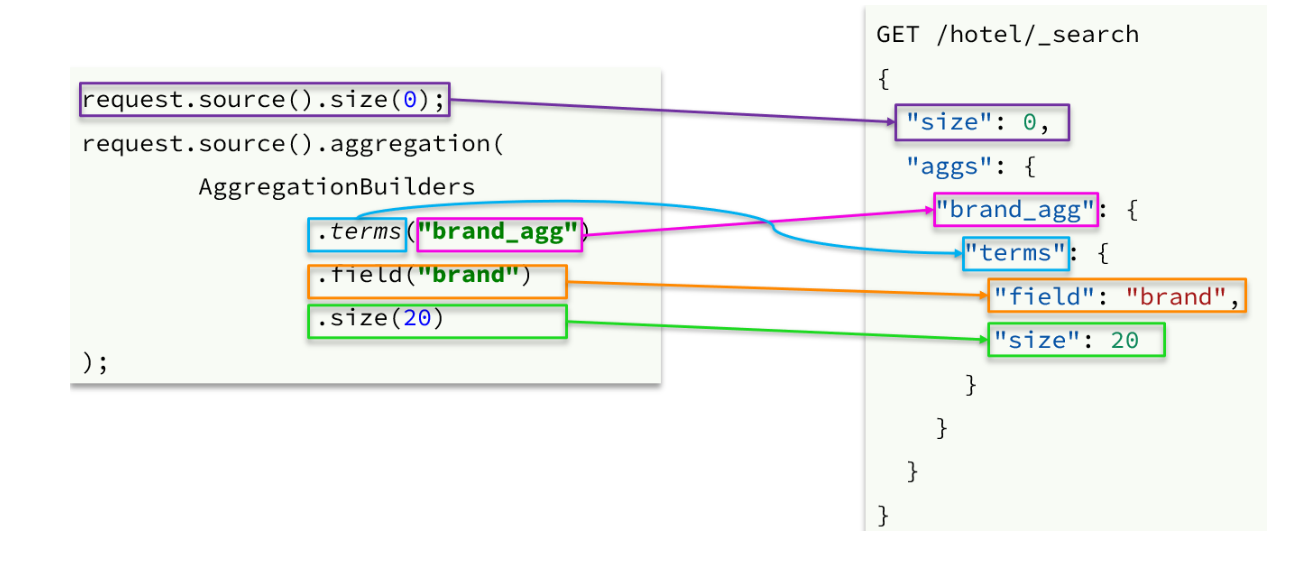
request.source().aggregation(AggregationBuilders
.terms("brandAgg")
.field("brand")
.size(100)
);
request.source().aggregation(AggregationBuilders
.terms("cityAgg")
.field("city")
.size(100)
);
request.source().aggregation(AggregationBuilders
.terms("starAgg")
.field("starName")
.size(100)
);
}
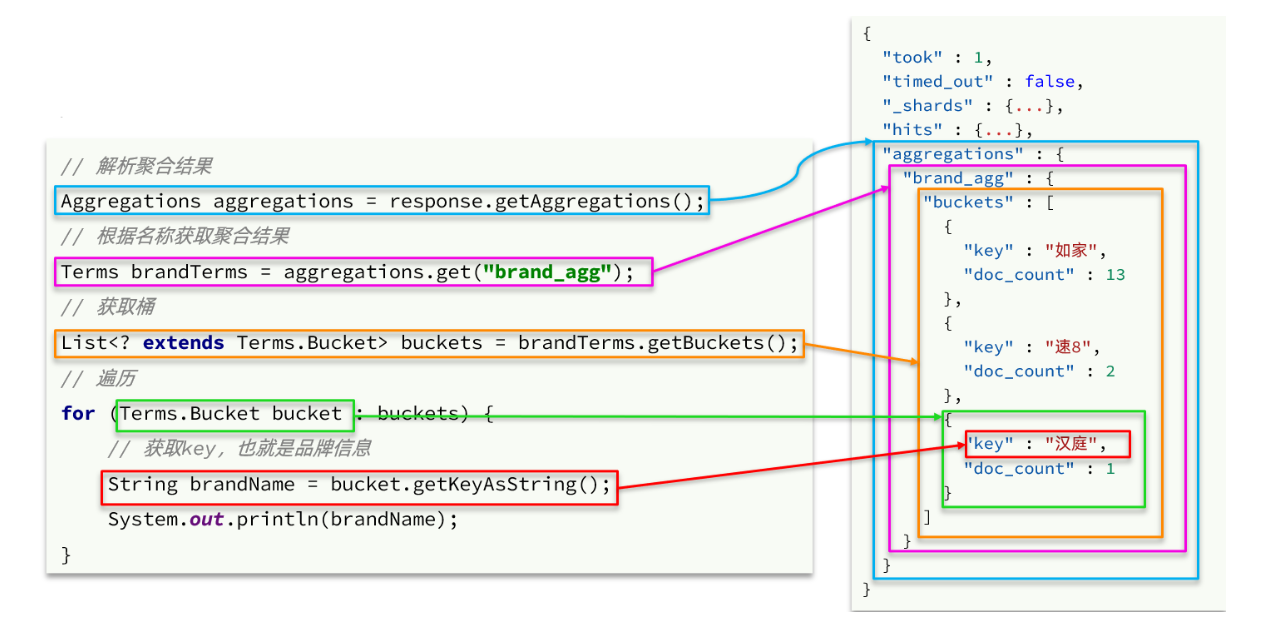
private List<String> getAggByName(Aggregations aggregations, String aggName) {
// 4.1.根據聚合名稱獲取聚合結果
Terms brandTerms = aggregations.get(aggName);
// 4.2.獲取buckets
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
// 4.3.遍歷
List<String> brandList = new ArrayList<>();
for (Terms.Bucket bucket : buckets) {
// 4.4.獲取key
String key = bucket.getKeyAsString();
brandList.add(key);
}
return brandList;
}
MQ資料同步
最後我們來介紹ES和MySQL資料同步的具體實現
資料同步問題
首先我們需要明白為什麼要實現資料同步:
- elasticsearch中的酒店資料來自於mysql資料庫
- 因此mysql資料發生改變時,elasticsearch也必須跟著改變,這個就是elasticsearch與mysql之間的資料同步
資料同步的實現具體來說有三種方式:
- 同步呼叫
- hotel-demo對外提供介面,用來修改elasticsearch中的資料
- 酒店管理服務在完成資料庫操作後,直接呼叫hotel-demo提供的介面

- 非同步通知
- hotel-admin對mysql資料庫資料完成增、刪、改後,傳送MQ訊息
- hotel-demo監聽MQ,接收到訊息後完成elasticsearch資料修改
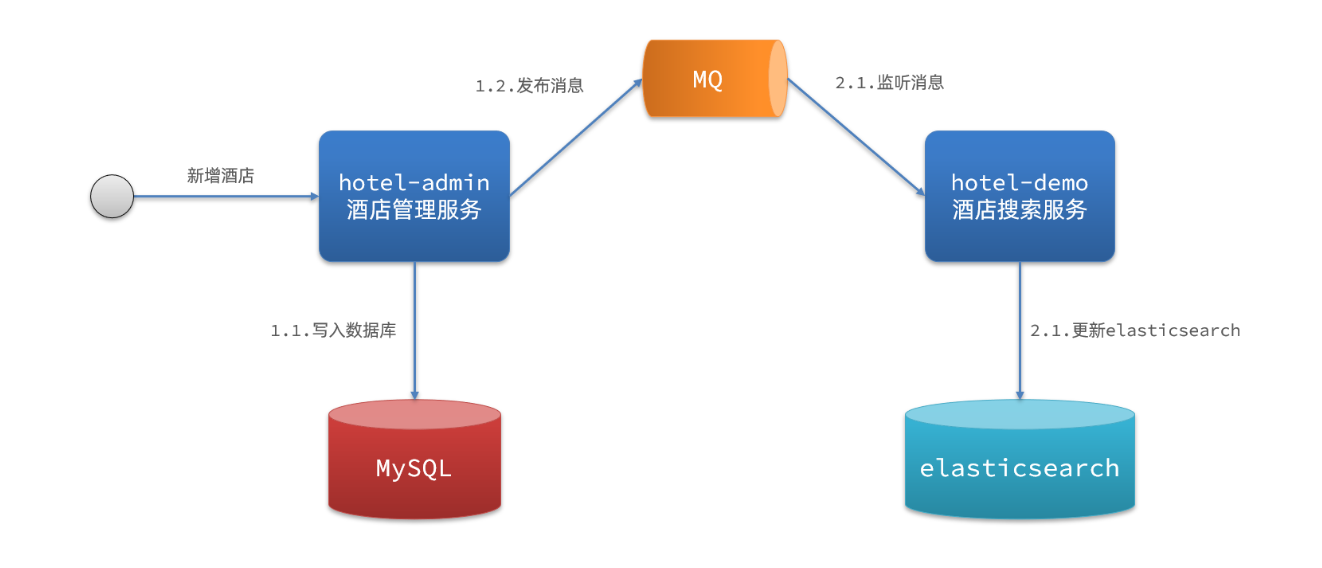
- 監聽binlog
- 給mysql開啟binlog功能
- mysql完成增、刪、改操作都會記錄在binlog中
- hotel-demo基於canal監聽binlog變化,實時更新elasticsearch中的內容

但是不同的方式存在有不同的優缺點:
- 同步方式:實現簡單,粗暴但業務耦合度高
- 非同步方式:低耦合,實現難度一般但依賴於MQ的可靠性
- 監聽方式:完全解除服務間耦合但開啟binlog增加資料庫負擔、實現複雜度高
MQ實現資料同步
在ES和MySQL的資料同步問題上非同步方式在一定程度優於同步方式且我們之前已經學習過MQ,所以這裡採用MQ實現資料同步
在實現資料同步之前我們先來簡單介紹一下具體專案內容:
- hotel-admin:賓館專案的後端處理服務,內部封裝了針對hotel的MySQL的資料處理
- hotel-demo:賓館專案的後端處理服務,內部封裝了針對hotel的ES資料處理
下面讓我們來逐步完成MQ資料同步操作:
- 思索整體MQ框架
- 引入依賴
<!--注意:在hotel-admin、hotel-demo中引入rabbitmq的依賴-->
<!--amqp-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
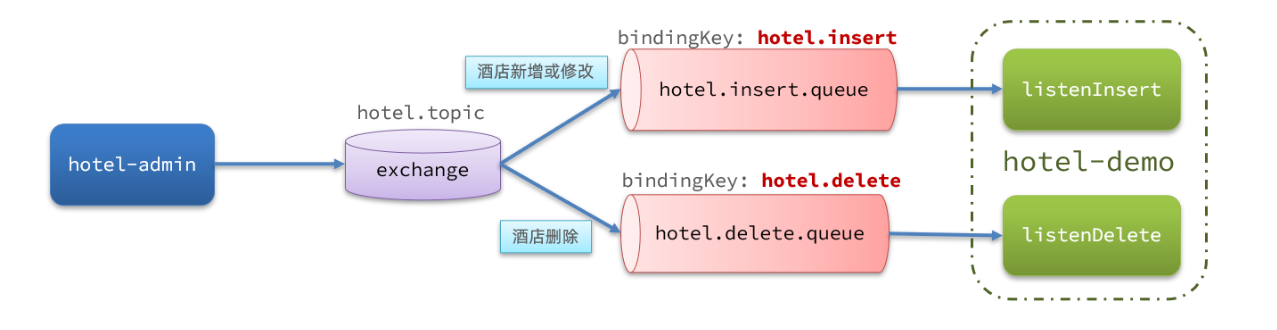
- 宣告佇列交換機名稱
// 為了保證兩個服務的交換機機制相同,我們在兩個服務中都宣告以下類,採用常數去定義具體交換機和佇列以及key
package cn.itcast.hotel.constatnts;
public class MqConstants {
/**
* 交換機
*/
public final static String HOTEL_EXCHANGE = "hotel.topic";
/**
* 監聽新增和修改的佇列
*/
public final static String HOTEL_INSERT_QUEUE = "hotel.insert.queue";
/**
* 監聽刪除的佇列
*/
public final static String HOTEL_DELETE_QUEUE = "hotel.delete.queue";
/**
* 新增或修改的RoutingKey
*/
public final static String HOTEL_INSERT_KEY = "hotel.insert";
/**
* 刪除的RoutingKey
*/
public final static String HOTEL_DELETE_KEY = "hotel.delete";
}
- 宣告佇列交換機
// 在hotel-demo中宣告即可
package cn.itcast.hotel.config;
import cn.itcast.hotel.constants.MqConstants;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.TopicExchange;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MqConfig {
// 宣告交換機
@Bean
public TopicExchange topicExchange(){
return new TopicExchange(MqConstants.HOTEL_EXCHANGE, true, false);
}
// 宣告佇列
@Bean
public Queue insertQueue(){
return new Queue(MqConstants.HOTEL_INSERT_QUEUE, true);
}
// 宣告佇列
@Bean
public Queue deleteQueue(){
return new Queue(MqConstants.HOTEL_DELETE_QUEUE, true);
}
// 宣告繫結關係
@Bean
public Binding insertQueueBinding(){
return BindingBuilder.bind(insertQueue()).to(topicExchange()).with(MqConstants.HOTEL_INSERT_KEY);
}
// 宣告繫結關係
@Bean
public Binding deleteQueueBinding(){
return BindingBuilder.bind(deleteQueue()).to(topicExchange()).with(MqConstants.HOTEL_DELETE_KEY);
}
}
- 傳送MQ訊息
// 在hotel-admin的mysql操作中順便傳送MQ資訊
@PostMapping
public void saveHotel(@RequestBody Hotel hotel){
// 服務層具體實現
hotelService.save(hotel);
// 我們主要看這部分,MQ的資訊傳送(這裡僅傳送id為了節省MQ記憶體)
rabbitTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE,OTEL_INSERT_KEY,hotel.getId());
}
@PostMapping
public void updateHotel(@RequestBody Hotel hotel){
// 服務層具體實現
hotelService.update(hotel);
// 由於ES的新增和更新相同,所以這裡採用同一個key
rabbitTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE,OTEL_INSERT_KEY,hotel.getId());
}
@PostMapping
public void deleteHotel(@PathVariable Long id){
// 服務層具體實現
hotelService.delete(hotel);
// 這裡傳送不同的key,進入不同Listener
rabbitTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE,OTEL_DELETE_KEY,id);
}
- 接收MQ並實現具體邏輯
// 首先在hotel-demo的`cn.qiuluo.hotel.service`包下的`IHotelService`中新增新增、刪除業務
void deleteById(Long id);
void insertById(Long id);
// 給hotel-demo中的`cn.qiuluo.hotel.service.impl`包下的HotelService中實現業務
@Override
public void deleteById(Long id) {
try {
// 1.準備Request
DeleteRequest request = new DeleteRequest("hotel", id.toString());
// 2.傳送請求
client.delete(request, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Override
public void insertById(Long id) {
try {
// 0.根據id查詢酒店資料
Hotel hotel = getById(id);
// 轉換為檔案型別
HotelDoc hotelDoc = new HotelDoc(hotel);
// 1.準備Request物件
IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());
// 2.準備Json檔案
request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
// 3.傳送請求
client.index(request, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
// 監聽類書寫
package cn.qiuluo.hotel.mq;
import cn.qiuluo.hotel.constants.MqConstants;
import cn.qiuluo.hotel.service.IHotelService;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class HotelListener {
@Autowired
private IHotelService hotelService;
/**
* 監聽酒店新增或修改的業務
* @param id 酒店id
*/
@RabbitListener(queues = MqConstants.HOTEL_INSERT_QUEUE)
public void listenHotelInsertOrUpdate(Long id){
hotelService.insertById(id);
}
/**
* 監聽酒店刪除的業務
* @param id 酒店id
*/
@RabbitListener(queues = MqConstants.HOTEL_DELETE_QUEUE)
public void listenHotelDelete(Long id){
hotelService.deleteById(id);
}
}
結束語
這篇文章中詳細介紹了ES以及關於ES的相關API展示,希望能為你帶來幫助
這裡推薦一篇ElasticSearch的非常詳細的部落格文章,為我帶來很多幫助:Elasticsearch學習筆記_巨輪的部落格-CSDN部落格
附錄
該文章屬於學習內容,具體參考B站黑馬程式設計師的微服務課程
這裡附上視訊連結:01-今日內容介紹7_嗶哩嗶哩_bilibili