在一張 24 GB 的消費級顯示卡上用 RLHF 微調 20B LLMs
我們很高興正式釋出 trl 與 peft 的整合,使任何人都可以更輕鬆地使用強化學習進行大型語言模型 (LLM) 微調!在這篇文章中,我們解釋了為什麼這是現有微調方法的有競爭力的替代方案。
請注意, peft 是一種通用工具,可以應用於許多 ML 用例,但它對 RLHF 特別有趣,因為這種方法特別需要記憶體!
如果你想直接深入研究程式碼,請直接在 TRL 的檔案頁面 直接檢視範例指令碼。
介紹
LLMs & RLHF
LLM 結合 RLHF (人類反饋強化學習) 似乎是構建非常強大的 AI 系統 (例如 ChatGPT) 的下一個首選方法。
使用 RLHF 訓練語言模型通常包括以下三個步驟:
- 在特定領域或指令和人類示範語料庫上微調預訓練的 LLM;
- 收集人類標註的資料集,訓練一個獎勵模型;
- 使用 RL (例如 PPO),用此資料集和獎勵模型進一步微調步驟 1 中的 LLM。

ChatGPT 的訓練協定概述,從資料收集到 RL 部分。 資料來源: OpenAI 的 ChatGPT 博文
基礎 LLM 的選擇在這裡是至關重要的。在撰寫本文時,可以「開箱即用」地用於許多工的「最佳」開源 LLM 是指令微調 LLMs。著名的模型有: BLOOMZ Flan-T5、Flan-UL2 和 OPT-IML。這些模型的缺點是它們的尺寸。要獲得一個像樣的模型,你至少需要玩 10B+ 級別的模型,在全精度情況下這將需要高達 40GB GPU 記憶體,只是為了將模型裝在單個 GPU 裝置上而不進行任何訓練!
什麼是 TRL?
trl 庫的目的是使 RL 的步驟更容易和靈活,讓每個人可以在他們自己的資料集和訓練設定上用 RL 微調 LM。在許多其他應用程式中,你可以使用此演演算法微調模型以生成 正面電影評論、進行 受控生成 或 降低模型的毒性。
使用 trl 你可以在分散式管理器或者單個裝置上執行最受歡迎的深度強化學習演演算法之一: PPO。我們利用 Hugging Face 生態系統中的 accelerate 來實現這一點,這樣任何使用者都可以將實驗擴大到一個有趣的規模。
使用 RL 微調語言模型大致遵循下面詳述的協定。這需要有 2 個原始模型的副本; 為避免活躍模型與其原始行為/分佈偏離太多,你需要在每個優化步驟中計算參考模型的 logits 。這對優化過程增加了硬約束,因為你始終需要每個 GPU 裝置至少有兩個模型副本。如果模型的尺寸變大,在單個 GPU 上安裝設定會變得越來越棘手。

TRL 中 PPO 訓練設定概述
在 trl 中,你還可以在參考模型和活躍模型之間使用共用層以避免整個副本。 模型解毒範例中展示了此功能的具體範例。
大規模訓練
大規模訓練是具有挑戰性的。第一個挑戰是在可用的 GPU 裝置上擬合模型,及其優化器狀態。 單個引數佔用的 GPU 記憶體量取決於其「精度」(或更具體地說是 dtype)。 最常見的 dtype 是 float32 (32 位) 、 float16 和 bfloat16 (16 位)。 最近,「奇異的」精度支援開箱即用的訓練和推理 (具有特定條件和約束),例如 int8 (8 位)。 簡而言之,要在 GPU 裝置上載入一個模型,每十億個引數在 float32 精度上需要 4GB,在 float16 上需要 2GB,在 int8 上需要 1GB。 如果你想了解關於這個話題的更多資訊,請檢視這篇研究深入的文章: https://huggingface.co/blog/hf-bitsandbytes-integration。
如果您使用 AdamW 優化器,每個引數需要 8 個位元組 (例如,如果您的模型有 1B 個引數,則模型的完整 AdamW 優化器將需要 8GB GPU 記憶體 來源)。
許多技術已經被採用以應對大規模訓練上的挑戰。最熟悉的正規化是管道並行、張量並行和資料並行。
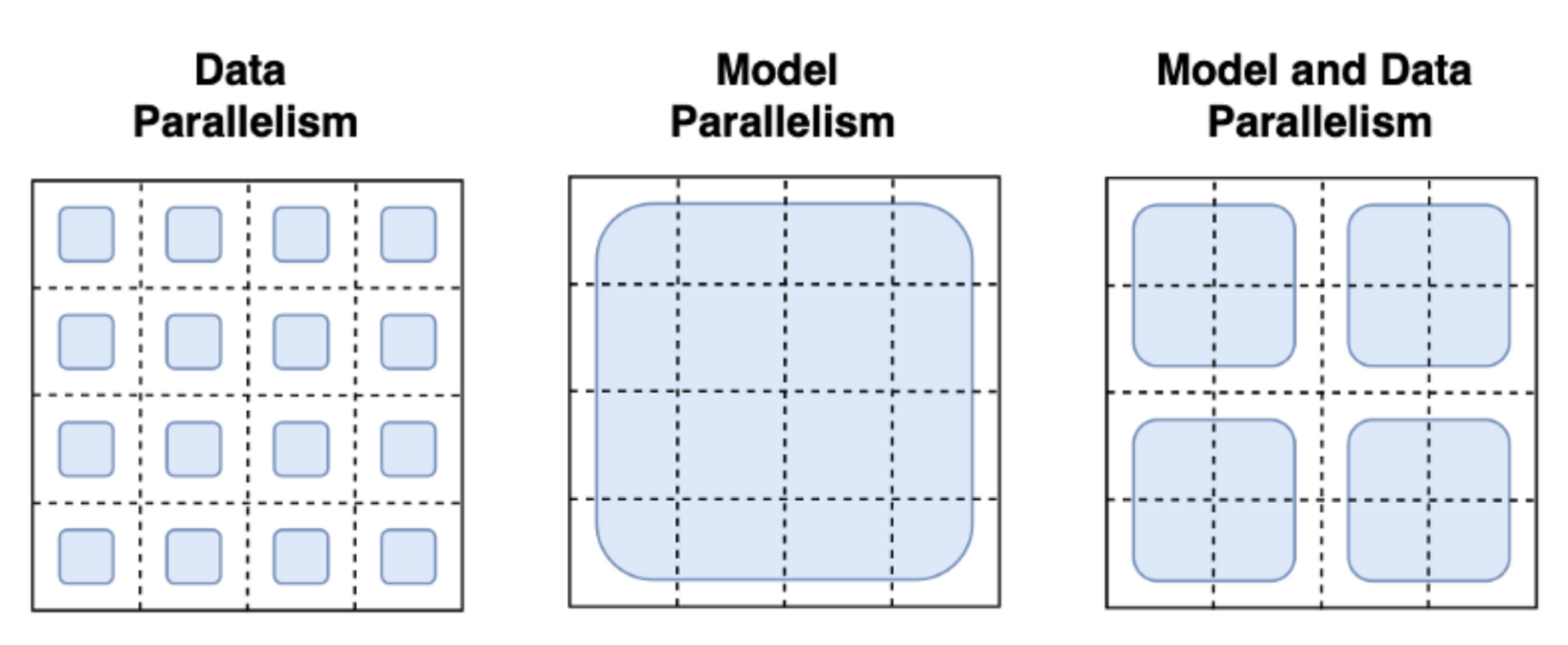
圖片來自 這篇博文
通過資料並行性,同一模型並行託管在多臺機器上,並且每個範例都被提供不同的資料批次。 這是最直接的並行策略,本質上是複製單 GPU 的情況,並且已經被 trl 支援。 使用管道並行和張量並行,模型本身分佈在機器上: 在管道並行中,模型按層拆分,而張量並行則跨 GPU 拆分張量操作 (例如矩陣乘法)。使用這些模型並行策略,你需要將模型權重分片到許多裝置上,這需要你定義跨程序的啟用和梯度的通訊協定。 這實現起來並不簡單,可能需要採用一些框架,例如 Megatron-DeepSpeed 或 Nemo。其他對擴充套件訓練至關重要的工具也需要被強調,例如自適應啟用檢查點和融合核心。 可以在 擴充套件閱讀 找到有關並行正規化的進一步閱讀。
因此,我們問自己下面一個問題: 僅用資料並行我們可以走多遠?我們能否使用現有的工具在單個裝置中適應超大型訓練過程 (包括活躍模型、參考模型和優化器狀態)? 答案似乎是肯定的。 主要因素是: 介面卡和 8 位矩陣乘法! 讓我們在以下部分中介紹這些主題:
8 位矩陣乘法
高效的 8 位矩陣乘法是論文 LLM.int8() 中首次引入的一種方法,旨在解決量化大規模模型時的效能下降問題。 所提出的方法將線上性層中應用的矩陣乘法分解為兩個階段: 在 float16 中將被執行的異常值隱藏狀態部分和在 int8 中被執行的「非異常值」部分。
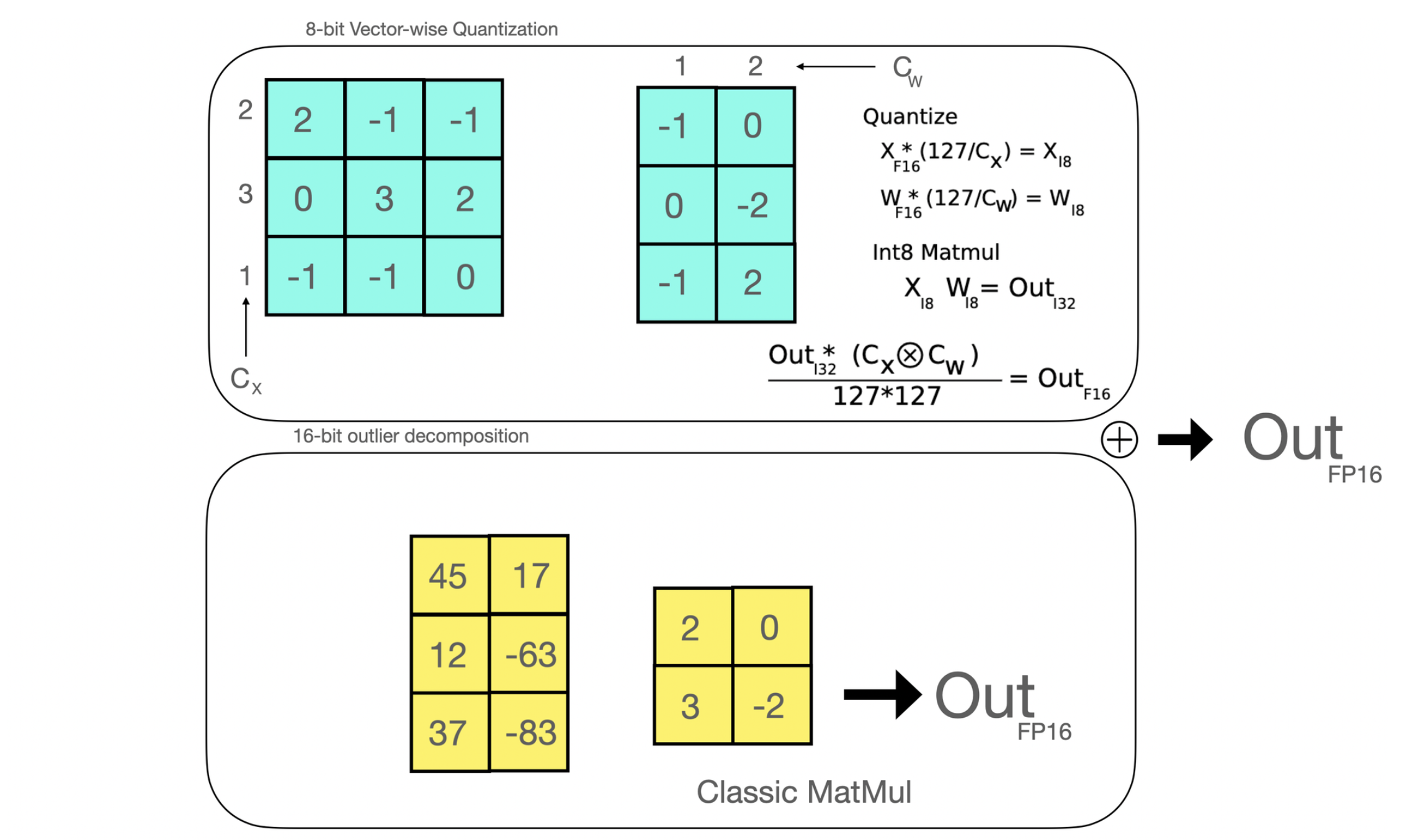
高效的 8 位矩陣乘法是論文 LLM.int8() 中首次引入的一種方法,旨在解決量化大規模模型時的效能下降問題。 所提出的方法將線上性層中應用的矩陣乘法分解為兩個階段: 在 float16 中被執行的異常值隱藏狀態部分和在 int8 中被執行的「非異常值」部分。
簡而言之,如果使用 8 位矩陣乘法,則可以將全精度模型的大小減小到 4 分之一 (因此,對於半精度模型,可以減小 2 分之一)。
低秩適配和 PEFT
在 2021 年,一篇叫 LoRA: Low-Rank Adaption of Large Language Models 的論文表明,可以通過凍結預訓練權重,並建立查詢和值層的注意力矩陣的低秩版本來對大型語言模型進行微調。這些低秩矩陣的引數遠少於原始模型,因此可以使用更少的 GPU 記憶體進行微調。 作者證明,低階介面卡的微調取得了與微調完整預訓練模型相當的結果。
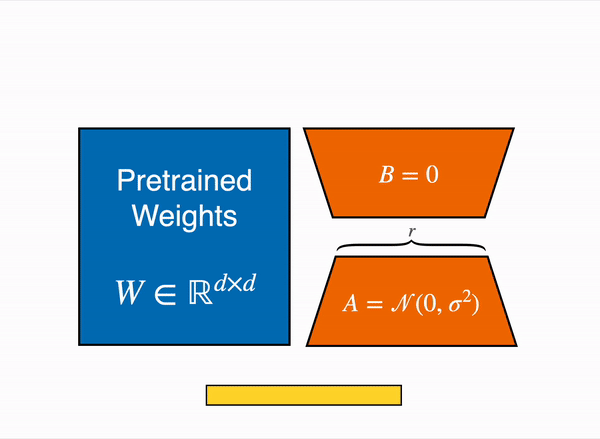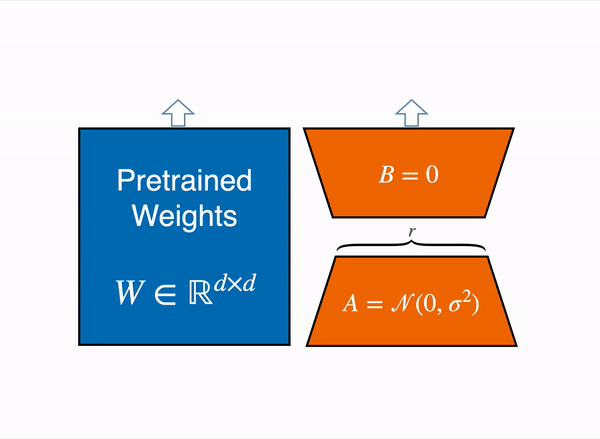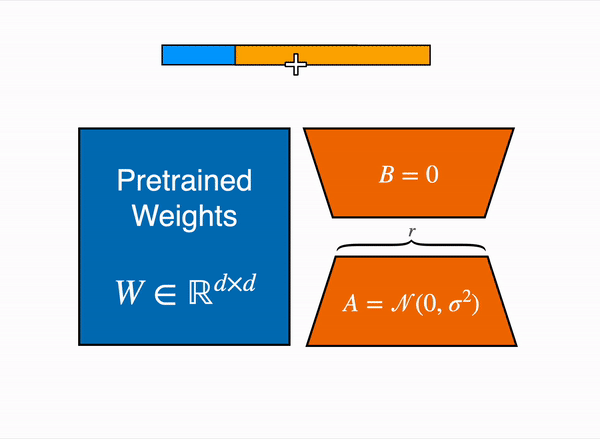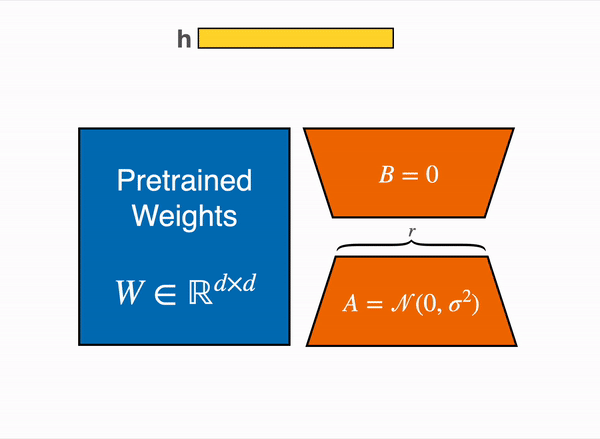
原始 (凍結的) 預訓練權重 (左) 的輸出啟用由一個由權重矩陣 A 和 B 組成的低秩介面卡 (右) 增強。
這種技術允許使用一小部分記憶體來微調 LLM。 然而,也有一些缺點。由於介面卡層中的額外矩陣乘法,前向和反向傳遞的速度大約是原來的兩倍。
什麼是 PEFT?
Parameter-Efficient Fine-Tuning (PEFT) 是一個 Hugging Face 的庫,它被創造出來以支援在 LLM 上建立和微調介面卡層。 peft 與