精準測試之分散式呼叫鏈底層邏輯
作者:京東工業 宛煜昕
概要: 1. 調⽤鏈系統概述; 2. 調⽤鏈系統的演進; 3. 調⽤鏈的底層實現邏輯; 4. Span內容組成。
⼀、分散式調⽤鏈系統概述
客戶打電話給客服說:「優惠券使⽤不了」。 -客服告訴運營⼈員 --運營打電話給技術負責⼈ ---技術負責⼈通知會員系統開發⼈員 ----會員找到行銷系統開發⼈員 -----行銷系統開發⼈員找到DBA ------DBA找到運維⼈員 -------運維⼈員找到機房負責⼈ --------機房負責⼈找到⼀只⽼⿏ ,因為就是它把⽹線咬斷了。
分散式架構所帶來的問題
定位⼀個問題怎麼會如此複雜?竟然動⽤了公司⼀半以上的職能部⻔。但其實這只是當我係統變成分散式之後,當我們把服務進⾏細粒度的拆份之後的⼀⼩部分問題,更多問題在哪⾥?⽐如: 1. 開發成本增加。 2. 測試成本增加。 3. 產品迭代週期將變⻓。 4. 運維成本增加。

問題產⽣原因
在傳統制造業,分⼯越精細,專業化程度越⾼,產能就越⾼。⽐如⼀臺汽⻋平均將近3萬個零部件,來⾃全球各個供應商,最後再由汽⻋⼚商統⼀拼裝檢測出⼚。不僅⼤件是精細分⼯完成,⼩件也是如此,在浙江溫州 有⼀個打⽕機村,⼀個⼩⼩的打⽕機⽣產,是由20多個⼚家共同作業完成,有的做打⽕機燃料有的做點⽕器。
反觀軟體⾏業,這種精細分⼯很難實現, 你⻅過哪家某個系統是由⼗⼏家企業共同作業完成的麼?你覺得淘寶的電商系統可以讓⽇本⼈去開發 購物⻋模組、讓法國⼈實現評論模組、讓印度⼈去實現下單功能、美國⼈實現商品模組,最後在由中國⼈拼裝整合?究期原因再於三個字:「標準化」,剛說的汽⻋3萬個零件,每個都有其標準化規格,所以才能夠順利的拼裝成品,但軟體組成很難標準,就連開發個接⼝都沒有指定標準,就連⼀個規範都難於推⾏。沒有標準化,不能分⼯共同作業,那怎麼實現軟體的⼤規模⽣產呢?就是⽤更多的⼈,更多⼯作時⻓去衝抵。軟體開發就此成為⼀個勞動密集型產業,新⽣代資訊化農⺠⼯群體誕⽣。這對企業⽽⾔是不利的,因為它要為資訊化付出更多的成本。所以相應管理辦法與開發⼯具都要升級,管理辦法是類似於敏捿開發、⼯程師⽂化建設、開發形為準則。另外⼀個就是⼯具:⾃動化構建、⾃動化部署、⾃動化運維、⾃動化擴容等、線上鏈路監控等等。
分散式鏈路監控的作用
1. 定位線上問題; 2. 分極效能問題; 3. 降紙軟體複雜度; 4. 提供決策資料⽀持。
⼆、呼叫鏈系統的演進

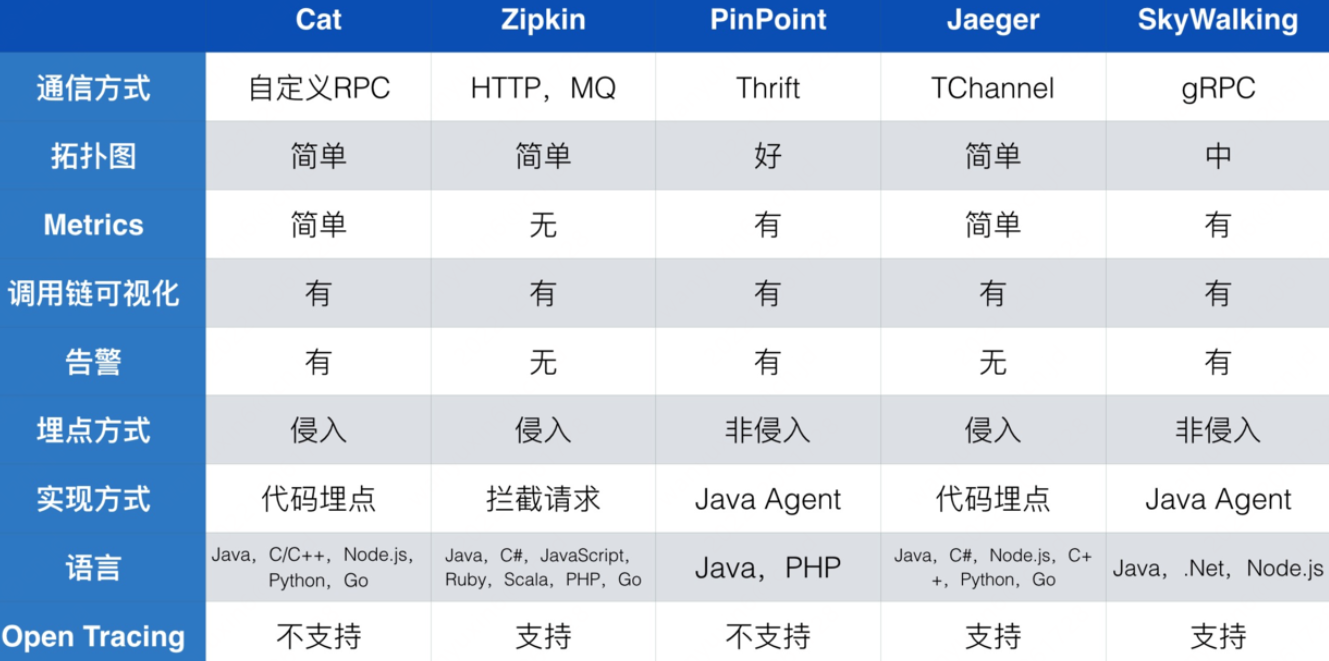
⼀般我們認為鏈路監控產品是從 2010 年 Google 發表名為 《Dapper⼤規模分散式系統的跟蹤系統》論⽂開始流⾏起來的。之後出現的很多開源或者閉源的產品都是以 Dapper 為理論基礎。下表列出已知的鏈路監控系統。
鏈路監控系統列表
| 公司 | 系統名稱 |
|---|---|
| Dapper | |
| 阿里巴巴 | 鷹眼 |
| 騰訊 | 天機 |
| 百度 | 鳳睛 |
| 京東 | CallGraph,hydra |
| 美團點評 | CAT(Central Application Tracking) |
| 美團 | MTRace |
| 鏈家 | LTrace |
| 蘇寧易購 | Hiro |
| Uber | Jaeger |
| Zipkin | |
| 網易 | Pylon |
| 個人開源 | PinPoint |
| Apache | Apache SkyWalking |
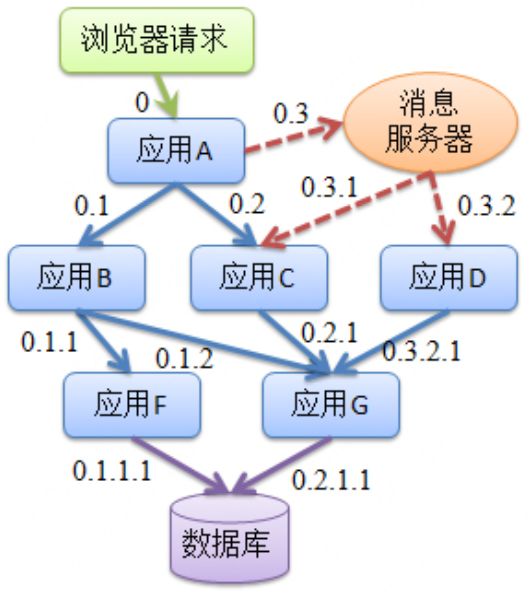
淘寶鷹眼 鷹眼介面
鷹眼架構
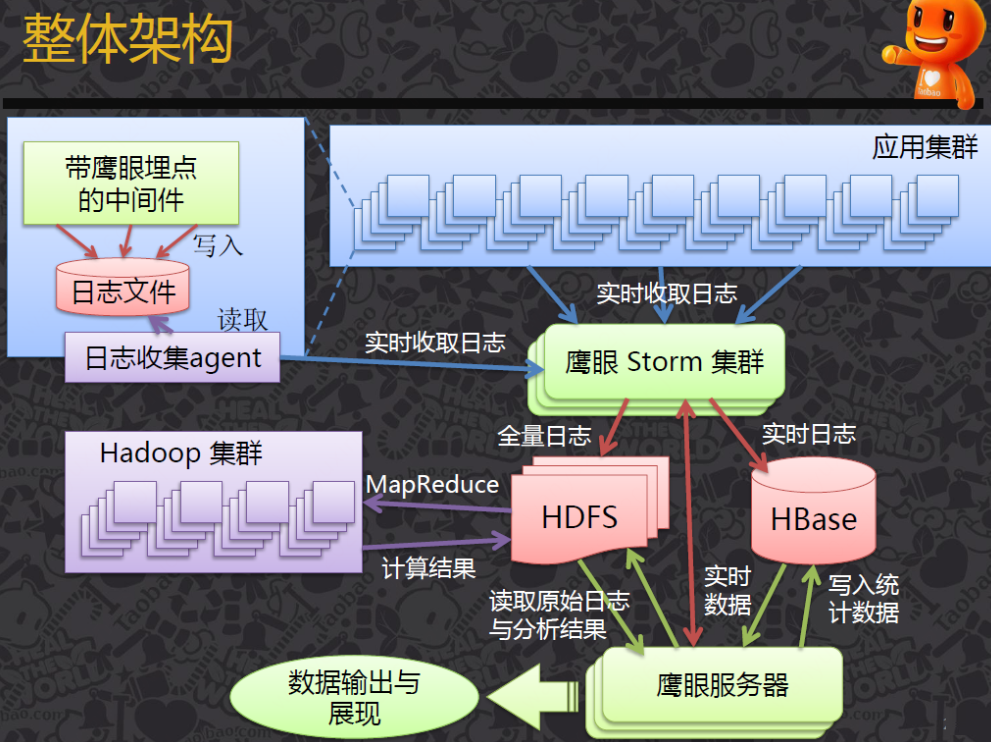
Google Dapper
Dapper 界⾯

Dapper架構圖
開源鏈路監控
三、呼叫鏈系統的底層實現邏輯
呼叫鏈系統的本質
⼀張⽹⻚,要經歷怎樣的過程,才能抵達⽤戶⾯前?
⽹絡傳輸層


負載均衡層
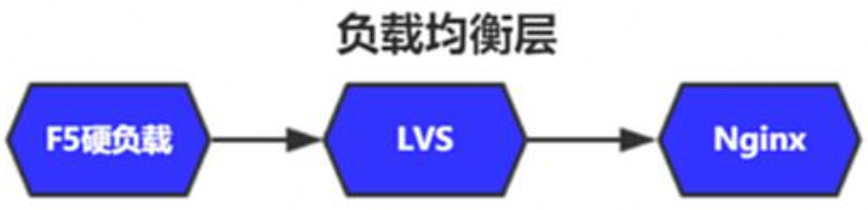
系統服務層

呼叫鏈基本元素
-
事件:請求處理過程當中的具體動作。
-
節點:請求所經過的系統節點,即事件的空間屬性。
-
時間:事件的開始和結束時間。
-
關係:事件與上⼀個事件關係。
調⽤鏈系統本質上就是⽤來回答這⼏問題:
-
什麼時間?
-
在什麼節點上?
-
發⽣了什麼事情?
-
這個事情由誰發起?
事件捕捉
-
寫死埋點捕捉
-
AOP埋點捕捉
-
公開元件埋點捕捉
-
位元組碼插樁捕捉
事件串聯
事件串聯的⽬的:
-
所有事件都關聯到同⼀個調⽤
-
各個事件之間層級關係
為了到達這兩個⽬的地,⼏乎所有的調⽤鏈系統都會有以下兩個屬性:
traceID:在整個系統中唯⼀,該值相同的事件表示同⼀次調⽤。
spanD:在⼀次調⽤中唯⼀、並展出事件的層級關係
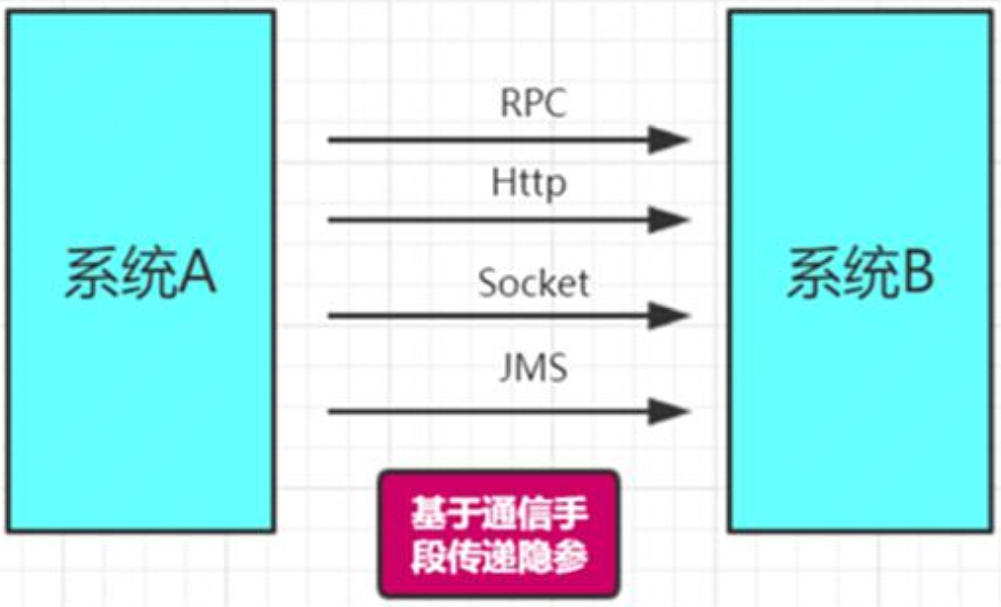
1、怎麼⽣成TraceID
2、怎麼傳遞引數
3、怎麼並行情況下不允響傳遞的結果
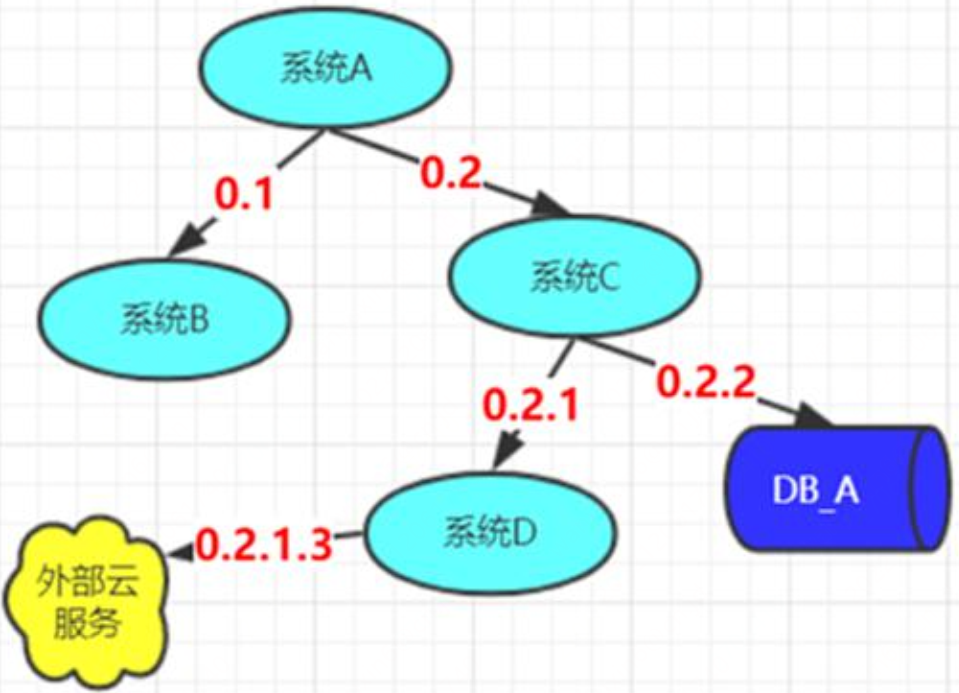
串聯的過程:
-
由跟蹤的起點⽣成⼀個TraceId, ⼀直傳遞⾄所有節點,並儲存在事件屬性值當中。
-
由跟蹤的起點⽣成初始SpanId,每捕捉⼀個事件ID加1,每傳遞⼀次,層級加1。
trackId與SpanId 的傳遞
SpanId ⾃增⽣成⽅式
我們的埋點是埋在具體某個實現⽅法類,當多執行緒調⽤該⽅法時如何保證⾃增正確性?
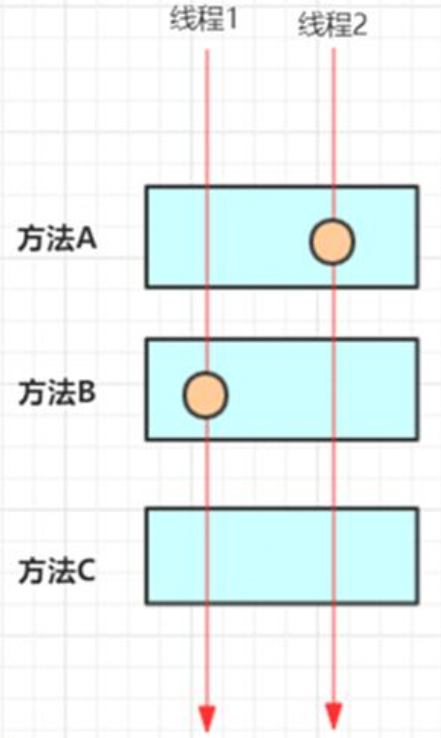
解決辦法是每個跟蹤請求建立⼀個互相獨⽴的對談,SpanId的⾃增都基於該對談實現。通常對談物件的儲存基於ThreadLocal實現。
事件的開始與結束
我們知道⼀個事件是⼀個時間段內系統執⾏的若⼲動作,所以對於事件捕捉必須包含開啟監聽和結束監聽兩個動作?如果⼀個事件在⼀個⽅法內完成的,這個問題是⽐較好解決的,我們只要在⽅法的開始建立⼀個Event物件,在⽅法結束時調⽤該對像的close ⽅法即可。

但如果⼀個事件的開始和結束觸發分佈在多個物件或⽅法當中,情況就會變得異常複雜。
⽐如⼀個JDBC執⾏事件,應該是在構建 Statement 時開始,在Statement 關閉時結束。怎樣把這兩個觸發動作對應到同⼀個事件當中去呢(即傳遞Event物件)?在這⾥的解決辦法是對返回結果進⾏動態代理,把Event放置到代理物件的屬性當中,以達到付遞的⽬標。當這個⽅法只是適應JDBC這⼀個場景,其它場景需要重新設計Event 傳遞路徑,⽬前還沒有通⽤的解決辦法。

上傳
上傳有兩種⽅式
-
基於RPC直接上傳
-
列印⽇志,然後在基於Flume或Logstash採集上傳。
第⼀種相對簡單,直接把資料傳送服務進⾏持久化,但如果系統流量較⼤的情況下,會影響系統本身的效能,造成壓力。
第⼆種相對複雜,但可以應對⼤流量,通常情況下會採⽤第⼆種解決辦法。
四、Span內容組成
Span基本內容
在調⽤鏈中⼀個Span,即代表⼀個時間跨度下的行為動作,它可以是在⼀個系統內的時間跨度,也可能是跨多個服務系統的。下圖即是Dapper中關於Span的描述。
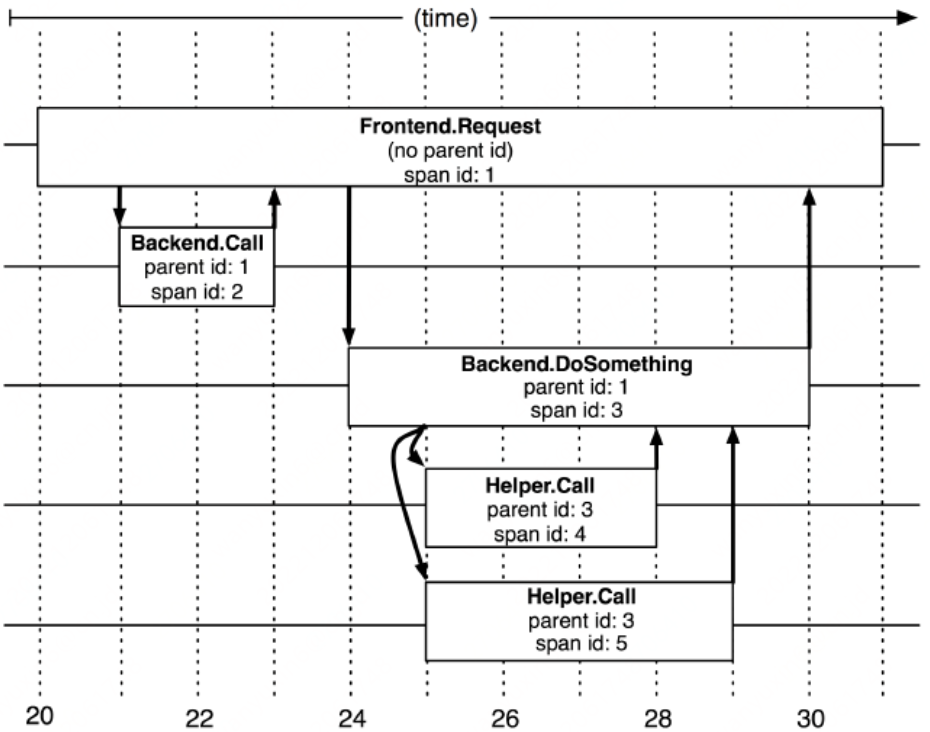
通常情況下⼀個Span組成包括: 1. 名稱:即操作的名稱,必須簡單可讀性⾼,它應該是⼀個抽像通⽤的標識,不能太具體。 2. SpanId:當調⽤中唯⼀ID 3. ParentId:表示其⽗Span 4. 開始與結束時間
端到端Span
一次遠端呼叫需要記錄幾個Span呢?
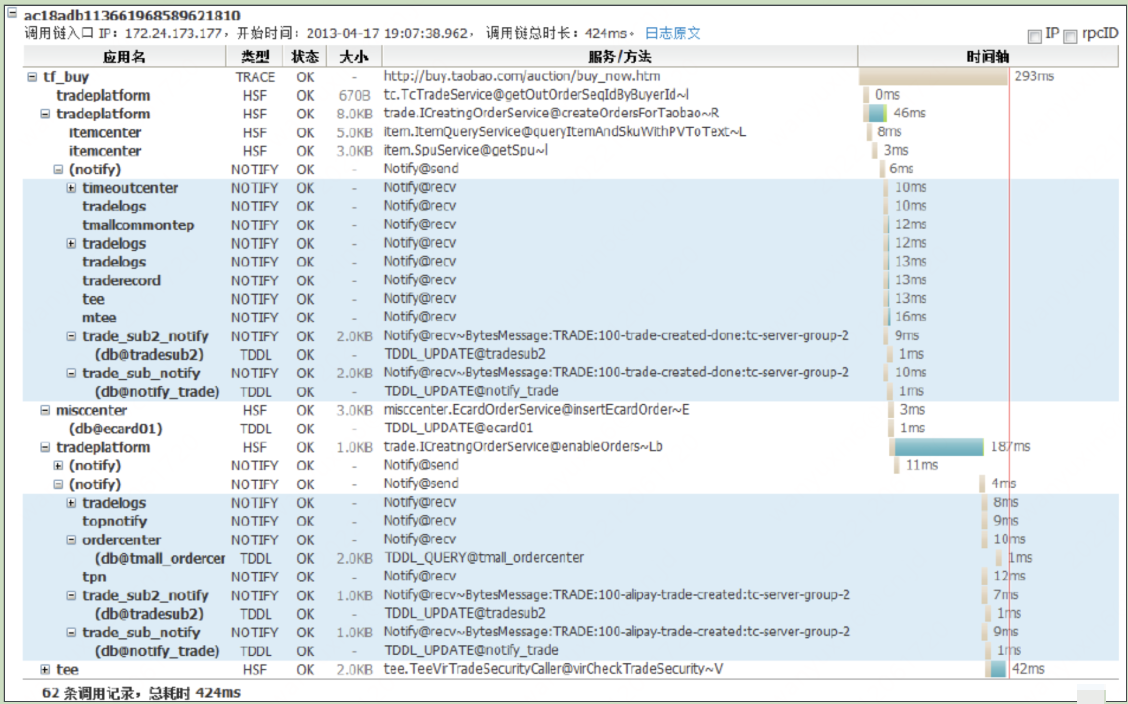
我們需要在使用者端和伺服器端分別記錄Span資訊,這樣才能計在兩個端的視角分別記錄資訊。比如計算中間的網路IO。

在Dapper 中分散式請求起碼包含如下四個核⼼埋點階段:
-
使用者端傳送 cs(Client Send):使用者端發起請求時埋點,記錄使用者端發起請求的時間戳
-
伺服器端接收 sr(Server Receive):伺服器端接受請求時埋點,記錄伺服器端接收到請求的時間戳
-
伺服器端響應 ss(Server Send):伺服器端返回請求時埋點,記錄伺服器端響應請求的時間戳
-
使用者端接收 cr(Client Receive):使用者端接受返回結果時埋點,記錄使用者端接收到響應時的時間戳
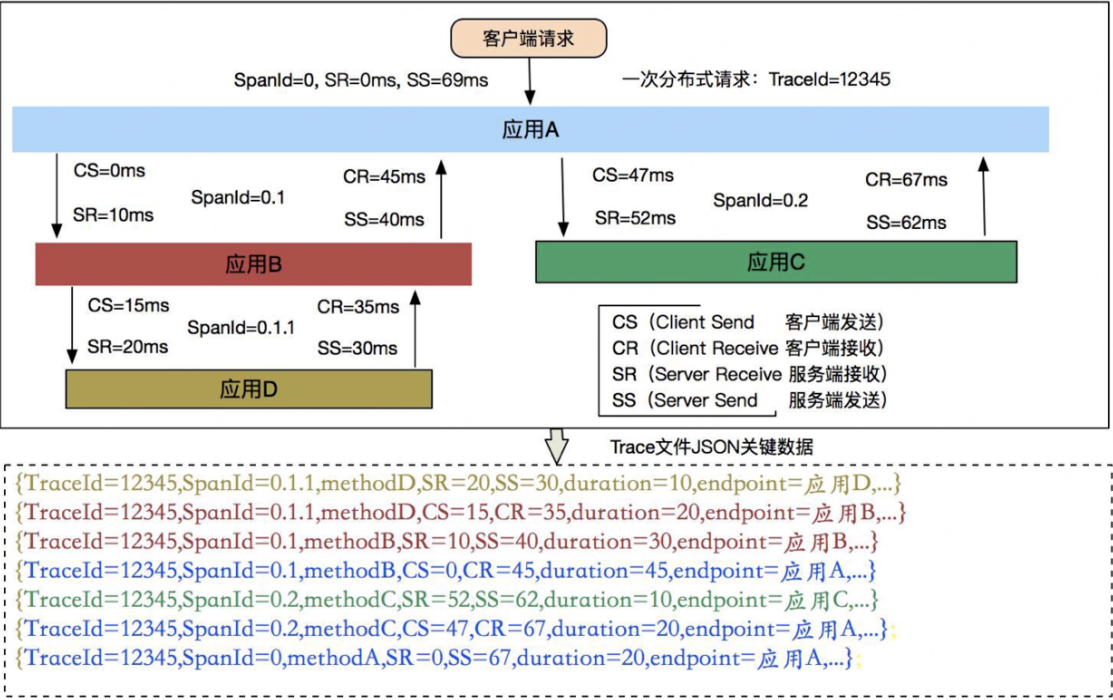
通過這四個埋點資訊,我們可以得到如下資訊:
使用者端請求伺服器端的網路耗時:sr-cs
伺服器端處理請求的耗時:ss-sr
伺服器端傳送響應給使用者端的網路耗時:cr-ss
本次請求在這兩個服務之間的總耗時:cr-cs
以上這些埋點在 Dapper 中有個專業的術語,叫做 Annotation。如果 Dapper 論⽂中的圖示你還沒有看太懂的話,那麼可以再看看下⾯這張圖,⽐較清楚的展示出整個過程。
參考
Dapper論文:https://research.google/pubs/pub36356/
Dapper大規模分散式系統跟蹤基礎設施論文:https://storage.googleapis.com/pub-tools-public-publication-data/pdf/36356.pdf